Eseguire il training di un modello di rilevamento anomalie multivariato
Importante
A partire dal 20 settembre 2023 non sarà possibile creare nuove risorse Rilevamento anomalie. Il servizio Rilevamento anomalie viene ritirato il 1° ottobre 2026.
Per testare rapidamente il rilevamento anomalie multivariate, provare l'esempio di codice. Per altre istruzioni su come eseguire un notebook di Jupyter, vedere Installare ed eseguire un notebook di Jupyter.
Panoramica API
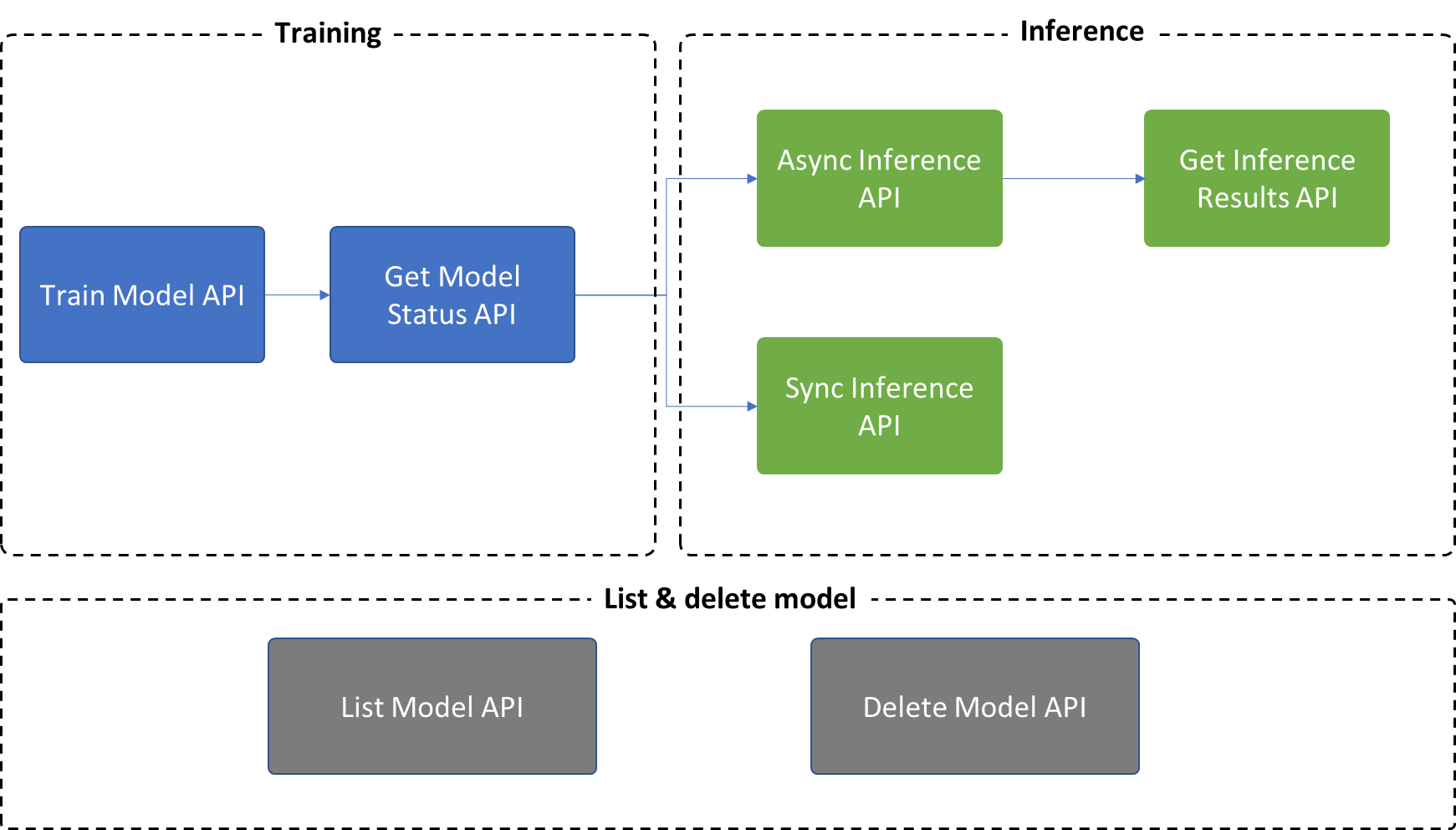
Sono disponibili 7 API in Rilevamento anomalie multivariato:
- Training: usare
Train Model APIper creare ed eseguire il training di un modello, quindi usareGet Model Status APIper ottenere lo stato e i metadati del modello. - Inferenza:
- Usare
Async Inference APIper attivare un processo di inferenza asincrona e usareGet Inference results APIper ottenere i risultati del rilevamento in un batch di dati. - È anche possibile usare
Sync Inference APIper attivare un rilevamento su un timestamp ogni volta.
- Usare
- Altre operazioni:
List Model APIeDelete Model APIsono supportate nel modello rilevamento anomalie multivariato per la gestione dei modelli.
| Nome API | metodo | Percorso | Descrizione |
|---|---|---|---|
| Eseguire il training del modello | POST | {endpoint}/anomalydetector/v1.1/multivariate/models |
Creare ed eseguire il training di un modello |
| Ottenere lo stato del modello | GET | {endpoint}anomalydetector/v1.1/multivariate/models/{modelId} |
Ottenere lo stato del modello e i metadati del modello con modelId |
| Inferenza batch | POST | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId}: detect-batch |
Attivare un'inferenza asincrona con modelId, che funziona in uno scenario batch |
| Ottenere i risultati dell'inferenza batch | GET | {endpoint}/anomalydetector/v1.1/multivariate/detect-batch/{resultId} |
Ottenere i risultati dell'inferenza batch con resultId |
| Inferenza di streaming | POST | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId}: detect-last |
Attivare un'inferenza sincrona con modelId, che funziona in uno scenario di streaming |
| Elencare il modello | GET | {endpoint}/anomalydetector/v1.1/multivariate/models |
Elencare tutti i modelli |
| Elimina modello | DELET | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId} |
Eliminare un modello con modelId |
Eseguire il training di un modello
In questo processo si useranno le informazioni seguenti create in precedenza:
- Chiave della risorsa Rilevamento anomalie
- Endpoint della risorsa di Rilevamento anomalie
- URL BLOB dei dati nell'account Archiviazione
Per le dimensioni dei dati di training, il numero massimo di timestamp è 1000000 e un numero minimo consigliato è 5000 timestamp.
Richiedi
Ecco un corpo di richiesta di esempio per eseguire il training di un modello rilevamento anomalie multivariato.
{
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0
},
"dataSource": "{{dataSource}}", //Example: https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest"
}
Parametri obbligatori
Questi tre parametri sono necessari nelle richieste api di training e inferenza:
- dataSource: URL BLOB collegato alla cartella o al file CSV che si trova nella Archiviazione BLOB di Azure.
- dataSchema: indica lo schema in uso:
OneTableoMultiTable. - startTime: ora di inizio dei dati usati per il training o l'inferenza. Se è precedente al timestamp effettivo dei dati, il timestamp effettivo verrà usato come punto iniziale.
- endTime: ora di fine dei dati usati per il training o l'inferenza, che deve essere successiva o uguale a
startTime. SeendTimeè successivo al timestamp più recente effettivo nei dati, il timestamp più recente effettivo verrà usato come punto finale. SeendTimeè uguale astartTime, significa inferenza di un singolo punto dati, che viene spesso usato negli scenari di streaming.
Parametri facoltativi
Altri parametri per l'API di training sono facoltativi:
slidingWindow: numero di punti dati usati per determinare le anomalie. Intero compreso tra 28 e 2.880. Il valore predefinito è 300. Se
slidingWindowèkper il training del modello, almeno ikpunti devono essere accessibili dal file di origine durante l'inferenza per ottenere risultati validi.Il rilevamento anomalie multivariato accetta un segmento di punti dati per decidere se il punto dati successivo è un'anomalia. La lunghezza del segmento è .
slidingWindowTenere presenti due aspetti quando si sceglie unslidingWindowvalore:- Le proprietà dei dati, indipendentemente dal fatto che siano periodiche e la frequenza di campionamento. Quando i dati sono periodici, è possibile impostare la lunghezza di 1 - 3 cicli come
slidingWindow. Quando i dati hanno una frequenza elevata (granularità ridotta) come il livello di minuto o il secondo livello, è possibile impostare un valore relativamente più elevato dislidingWindow. - Compromesso tra tempo di training/inferenza e potenziale impatto sulle prestazioni. Un valore maggiore
slidingWindowpuò causare tempi di training/inferenza più lunghi. Non c'è garanzia che più grandislidingWindowporteranno a miglioramenti di accuratezza. Una piccolaslidingWindowpuò rendere difficile per il modello convergere su una soluzione ottimale. Ad esempio, è difficile rilevare anomalie quandoslidingWindowha solo due punti.
- Le proprietà dei dati, indipendentemente dal fatto che siano periodiche e la frequenza di campionamento. Quando i dati sono periodici, è possibile impostare la lunghezza di 1 - 3 cicli come
alignMode: come allineare più variabili (serie temporali) ai timestamp. Sono disponibili due opzioni per questo parametro,
InnereOutere il valore predefinito èOuter.Questo parametro è fondamentale quando si verifica un errore di allineamento tra le sequenze di timestamp delle variabili. Il modello deve allineare le variabili alla stessa sequenza di timestamp prima di continuare l'elaborazione.
Innerindica che il modello invierà i risultati del rilevamento solo sui timestamp in cui ogni variabile ha un valore, ovvero l'intersezione di tutte le variabili.Outerindica che il modello segnala i risultati del rilevamento sui timestamp in cui qualsiasi variabile ha un valore, ovvero l'unione di tutte le variabili.Ecco un esempio per spiegare valori diversi
alignModel.Variabile-1
timestamp value 2020-11-01 1 2020-11-02 2 2020-11-04 4 2020-11-05 5 Variabile-2
timestamp value 2020-11-01 1 2020-11-02 2 2020-11-03 3 2020-11-04 4 Innerjoin di due variabilitimestamp Variabile-1 Variabile-2 2020-11-01 1 1 2020-11-02 2 2 2020-11-04 4 4 Outerjoin di due variabilitimestamp Variabile-1 Variabile-2 2020-11-01 1 1 2020-11-02 2 2 2020-11-03 nan3 2020-11-04 4 4 2020-11-05 5 nanfillNAMethod: come compilare
nanla tabella unita. Potrebbero essere presenti valori mancanti nella tabella unita e devono essere gestiti correttamente. Forniamo diversi metodi per riempirli. Le opzioni sonoLinear,PreviousSubsequent,Zero, eFixedil valore predefinito èLinear.Opzione metodo LinearRiempire nani valori in base all'interpolazione linearePreviousPropagare l'ultimo valore valido per riempire le lacune. Esempio: [1, 2, nan, 3, nan, 4]->[1, 2, 2, 3, 3, 4]SubsequentUsare il valore valido successivo per riempire le lacune. Esempio: [1, 2, nan, 3, nan, 4]->[1, 2, 3, 3, 4, 4]ZeroCompilare nani valori con 0.FixedCompilare nani valori con un valore valido specificato che deve essere specificato inpaddingValue.paddingValue: il valore di riempimento viene usato per riempire
nanquandofillNAMethodèFixede deve essere specificato in questo caso. In altri casi, è facoltativo.displayName: parametro facoltativo, usato per identificare i modelli. Ad esempio, è possibile usarlo per contrassegnare parametri, origini dati e altri metadati relativi al modello e ai relativi dati di input. Il valore predefinito è una stringa vuota.
Response
All'interno della risposta, la cosa più importante è , modelIdche verrà usata per attivare l'API Get Model Status (Ottieni stato modello).
Esempio di risposta:
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-11-01T00:00:00Z",
"lastUpdatedTime": "2022-11-01T00:00:00Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "CREATED",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [],
"trainLosses": [],
"validationLosses": [],
"latenciesInSeconds": []
},
"variableStates": []
}
}
}
Ottenere lo stato del modello
È possibile usare l'API precedente per attivare un training e usare l'API Get model status (Ottieni stato modello) per sapere se il training del modello è stato eseguito correttamente o meno.
Richiedi
Nel corpo della richiesta non è presente alcun contenuto, è necessario inserire solo modelId nel percorso API, che sarà in un formato: {{endpoint}}anomalydetector/v1.1/multivariate/models/{{modelId}}
Response
- status:
statusnel corpo della risposta indica lo stato del modello con questa categoria: CREATED, RUNNING, READY, FAILED. - trainLosses & validationLosses: si tratta di due concetti di Machine Learning che indicano le prestazioni del modello. Se i numeri diminuiscono e infine a un numero relativamente piccolo come 0,2, 0,3, significa che le prestazioni del modello sono buone in qualche misura. Tuttavia, le prestazioni del modello devono comunque essere convalidate tramite inferenza e il confronto con le etichette, se presenti.
- epochIds: indica quante epoche il modello è stato sottoposto a training su un totale di 100 periodi. Ad esempio, se il modello è ancora in stato di training,
epochIdpotrebbe essere[10, 20, 30, 40, 50], il che significa che ha completato il suo 50° periodo di training e quindi è a metà strada. - latenciesInSeconds: contiene il costo del tempo per ogni periodo e viene registrato ogni 10 periodi. In questo esempio, il 10° periodo richiede circa 0,34 secondi. Questo sarebbe utile per stimare il tempo di completamento del training.
- variableStates: riepiloga le informazioni su ogni variabile. È un elenco classificato
filledNARatioin ordine decrescente. Indica il numero di punti dati usati per ogni variabile efilledNARatioindica il numero di punti mancanti. Di solito dobbiamo ridurrefilledNARatioil più possibile. Troppi punti dati mancanti peggiorano l'accuratezza del modello. - errori: gli errori durante l'elaborazione
errorsdei dati verranno inclusi nel campo .
Esempio di risposta:
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-11-01T00:00:12Z",
"lastUpdatedTime": "2022-11-01T00:00:12Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "READY",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [
10,
20,
30,
40,
50,
60,
70,
80,
90,
100
],
"trainLosses": [
0.30325182933699,
0.24335388161919333,
0.22876543213020673,
0.2439815090461211,
0.22489577260884372,
0.22305156764659015,
0.22466289590705524,
0.22133831883018668,
0.2214335961775346,
0.22268397090109912
],
"validationLosses": [
0.29047123109451445,
0.263965221366497,
0.2510373182971068,
0.27116744686858824,
0.2518718700216274,
0.24802495975687047,
0.24790137705176768,
0.24640804830223623,
0.2463938973166726,
0.24831805566344597
],
"latenciesInSeconds": [
2.1662967205047607,
2.0658926963806152,
2.112030029296875,
2.130472183227539,
2.183091640472412,
2.1442034244537354,
2.117824077606201,
2.1345198154449463,
2.0993552207946777,
2.1198465824127197
]
},
"variableStates": [
{
"variable": "series_0",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_1",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_2",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_3",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_4",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
}
]
}
}
}
Elencare i modelli
È possibile fare riferimento a questa pagina per informazioni sull'URL della richiesta e sulle intestazioni della richiesta. Si noti che vengono restituiti solo 10 modelli ordinati in base all'ora di aggiornamento, ma è possibile visitare altri modelli impostando i $skip parametri e $top nell'URL della richiesta. Ad esempio, se l'URL della richiesta è https://{endpoint}/anomalydetector/v1.1/multivariate/models?$skip=10&$top=20, verranno ignorati i 10 modelli più recenti e verranno restituiti i 20 modelli successivi.
Una risposta di esempio è
{
"models": [
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-10-26T18:00:12Z",
"lastUpdatedTime": "2022-10-26T18:03:53Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "READY",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [
10,
20,
30,
40,
50,
60,
70,
80,
90,
100
],
"trainLosses": [
0.30325182933699,
0.24335388161919333,
0.22876543213020673,
0.2439815090461211,
0.22489577260884372,
0.22305156764659015,
0.22466289590705524,
0.22133831883018668,
0.2214335961775346,
0.22268397090109912
],
"validationLosses": [
0.29047123109451445,
0.263965221366497,
0.2510373182971068,
0.27116744686858824,
0.2518718700216274,
0.24802495975687047,
0.24790137705176768,
0.24640804830223623,
0.2463938973166726,
0.24831805566344597
],
"latenciesInSeconds": [
2.1662967205047607,
2.0658926963806152,
2.112030029296875,
2.130472183227539,
2.183091640472412,
2.1442034244537354,
2.117824077606201,
2.1345198154449463,
2.0993552207946777,
2.1198465824127197
]
},
"variableStates": [
{
"variable": "series_0",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_1",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_2",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_3",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_4",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
}
]
}
}
}
],
"currentCount": 42,
"maxCount": 1000,
"nextLink": ""
}
La risposta contiene quattro campi, models, currentCount, maxCounte nextLink.
- models: contiene l'ora creata, l'ora dell'ultimo aggiornamento, l'ID modello, il nome visualizzato, i conteggi delle variabili e lo stato di ogni modello.
- currentCount: contiene il numero di modelli multivariati sottoposti a training nella risorsa Rilevamento anomalie.
- maxCount: il numero massimo di modelli supportati dalla risorsa Rilevamento anomalie, che verrà differenziata in base al piano tariffario scelto.
- nextLink: può essere usato per recuperare più modelli perché il numero massimo di modelli che verranno elencati in questa risposta API è 10.