Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa guida illustra come usare l'API di rilevamento della fondatezza. Questa funzionalità rileva e corregge automaticamente il testo corrispondente ai documenti di origine forniti, assicurandosi che il contenuto generato sia allineato ai riferimenti effettivi o previsti. Di seguito vengono esaminati diversi scenari comuni per comprendere come e quando applicare queste funzionalità per ottenere i risultati migliori.
Prerequisiti
- Un profilo Azure. Se non hai un account, puoi crearlo gratuitamente.
- Una risorsa di Intelligenza artificiale di Azure.
Configurazione
Segui questi passaggi per utilizzare la pagina prova la sicurezza dei contenuti:
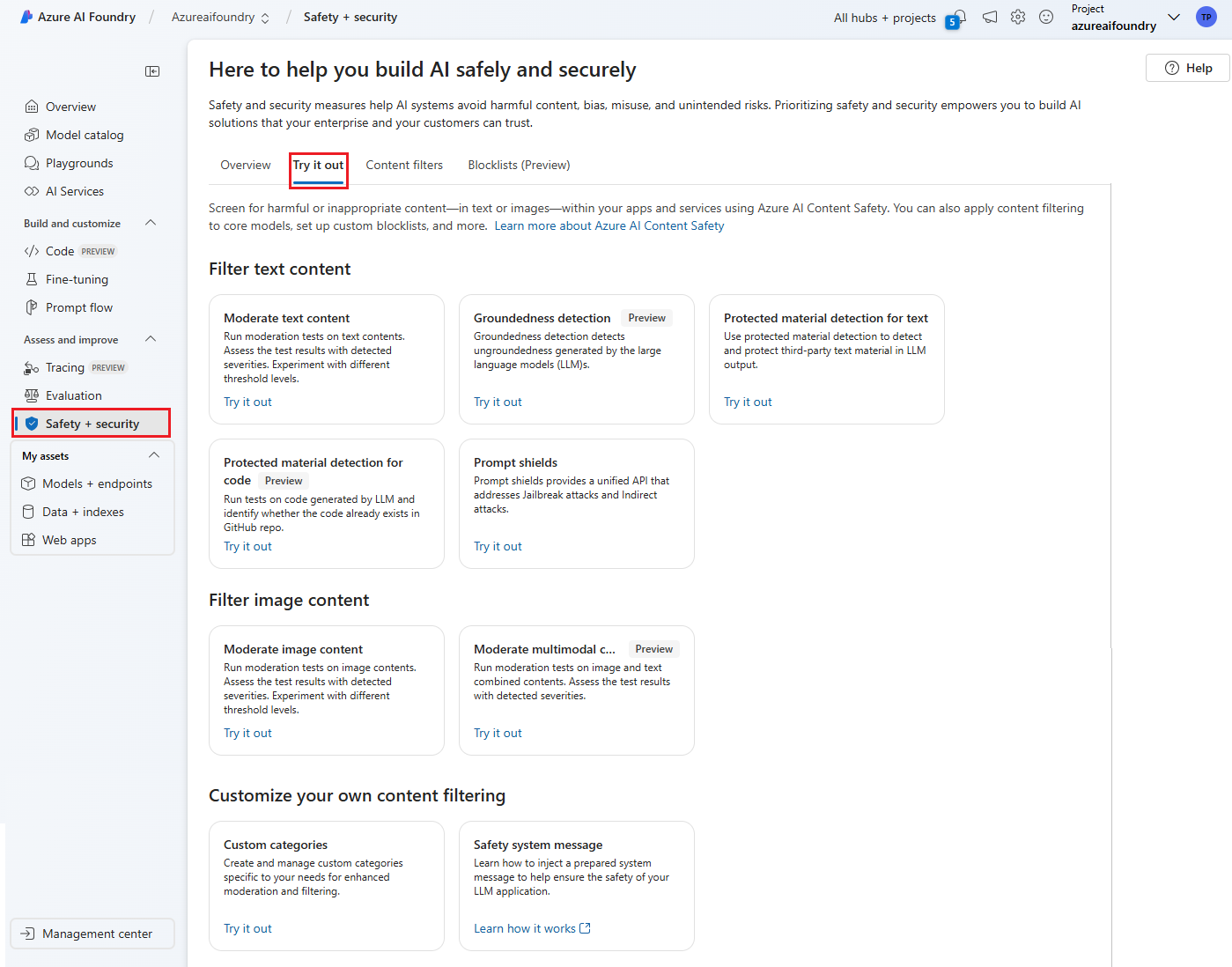
- Passare ad Azure AI Foundry e passare al progetto/hub. Selezionare quindi la scheda Guardrails + controls nel riquadro di spostamento sinistro e selezionare la scheda Provalo.
- Nella pagina Prova è possibile sperimentare diverse funzionalità di guardrails e controlli, ad esempio il testo e il contenuto dell'immagine, usando soglie regolabili per filtrare contenuti inappropriati o dannosi.
Usare il rilevamento della fondatezza
Il pannello di rilevamento della fondatezza consente di rilevare se le risposte testuali dei modelli linguistici di grandi dimensioni (LLM) sono fondate sui materiali di origine forniti dagli utenti.
- Selezionare il pannello Rilevazione della fondatezza.
- Selezionare un insieme di contenuti di esempio nella pagina o immettere il proprio contenuto per il test.
- Facoltativamente, abilitare la funzionalità di ragionamento e selezionare la risorsa di Azure OpenAI dall'elenco a discesa.
- Selezionare Esegui test. Il servizio restituisce il risultato del rilevamento della fondatezza.
Per altre informazioni, vedere la Guida concettuale di rilevamento della fondatezza.
Prerequisiti
- Una sottoscrizione di Azure - Crearne una gratuitamente
- Una volta disponibile la sottoscrizione di Azure, creare una risorsa di sicurezza dei contenuti nel portale di Azure per ottenere la chiave e l'endpoint. Immettere un nome univoco per la risorsa, selezionare la sottoscrizione, quindi selezionare un gruppo di risorse, un'area supportata e un piano tariffario supportato. Selezionare quindi Crea.
- La distribuzione della risorsa richiede alcuni minuti. Al termine, passare alla nuova risorsa. Nel riquadro a sinistra, selezionare Gestione delle risorse e quindi selezionare Chiavi API ed endpoint. Copiare uno dei valori della chiave della sottoscrizione e dell'endpoint in un percorso temporaneo per poterlo utilizzare in un secondo momento.
- (Facoltativo) Se si vuole usare la funzionalità di ragionamento , creare una risorsa Azure OpenAI in Azure AI Foundry Models con un modello GPT distribuito.
- cURL o Python installato.
Autenticazione
Per una maggiore sicurezza, è necessario usare l'identità gestita (MI) per gestire l'accesso alle risorse. Per altri dettagli, vedere Sicurezza.
Verificare la fondatezza senza ragionamento
Nel caso semplice, ovvero senza l’uso della funzionalità di ragionamento, l'API di Rilevamento della fondatezza classifica la non fondatezza del contenuto inviato come true o false.
La sezione seguente illustra una richiesta di esempio con cURL. Incollare il comando seguente in un editor di testo e apportare le modifiche seguenti.
Sostituire
<endpoint>con l'URL dell'endpoint associato alla risorsa.Sostituire
<your_subscription_key>con una delle chiavi per la risorsa.Facoltativamente, sostituire i campi
"query"o"text"nel corpo con il testo personalizzato da analizzare.curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. IF they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": false }'
Aprire una finestra del prompt dei comandi ed eseguire il comando cURL.
Per testare un'attività di riepilogo anziché un'attività di risposta alle domande (QnA), usare il corpo JSON di esempio seguente:
{
"domain": "Medical",
"task": "Summarization",
"text": "Ms Johnson has been in the hospital after experiencing a stroke.",
"groundingSources": [
"Our patient, Ms. Johnson, presented with persistent fatigue, unexplained weight loss, and frequent night sweats. After a series of tests, she was diagnosed with Hodgkin’s lymphoma, a type of cancer that affects the lymphatic system. The diagnosis was confirmed through a lymph node biopsy revealing the presence of Reed-Sternberg cells, a characteristic of this disease. She was further staged using PET-CT scans. Her treatment plan includes chemotherapy and possibly radiation therapy, depending on her response to treatment. The medical team remains optimistic about her prognosis given the high cure rate of Hodgkin’s lymphoma."
],
"reasoning": false
}
Nell'URL devono essere inclusi i campi seguenti:
| Nome | Obbligatorio | Descrizione | Tipo |
|---|---|---|---|
| Versione dell'API | Obbligatorio | Questa è la versione dell'API da usare. La versione corrente è: api-version=2024-09-15-preview. Esempio: <endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview |
String |
I parametri nel corpo della richiesta sono definiti in questa tabella:
| Nome | Descrizione | Tipo |
|---|---|---|
| domain | (Facoltativo) MEDICAL o GENERIC. Valore predefinito: GENERIC. |
Enum |
| task | (Facoltativo) Tipo di attività: QnA, Summarization. Valore predefinito: Summarization. |
Enum |
| qna | (Facoltativo) Contiene i dati QnA quando il tipo di attività è QnA. |
String |
- query |
(Facoltativo) Rappresenta la domanda in un'attività QnA. Limite di caratteri: 7.500. | String |
| text | (Obbligatorio) Il testo di output del modello LLM da controllare. Limite di caratteri: 7.500. | String |
| fontiDiFondazione | (Obbligatorio) Usa un array di origini fondatezza per convalidare il testo generato dall'intelligenza artificiale. Vedere Requisiti di input per i limiti. | Array di stringhe |
| ragionamento | (Facoltativo) Specifica se utilizzare la funzionalità di ragionamento. Il valore predefinito è false. Se true, è necessario usare il proprio Azure OpenAI GPT-4o (versione 0513, 0806) per fornire una spiegazione. Attenzione: l'uso del ragionamento aumenta il tempo di elaborazione. |
Boolean |
Interpretare la risposta dell'API
Dopo l’invio della richiesta, si riceverà una risposta JSON che riflette l'analisi della fondatezza eseguita. Ecco come appare un output tipico:
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour."
}
]
}
Gli oggetti JSON nell'output sono definiti qui:
| Nome | Descrizione | Tipo |
|---|---|---|
| ungroundedDetected | Indica se il testo presenta elementi infondati. | Boolean |
| ungroundedPercentage | Specifica la proporzione del testo identificato come infondato, espressa come numero compreso tra 0 e 1, dove 0 indica che non è presente alcun contenuto infondato e 1 indica contenuto completamente infondato. Questo non è un livello di attendibilità. | Float |
| dettagliSenzaFondamento | Fornisce informazioni dettagliate sul contenuto infondato con esempi e percentuali specifici. | Array |
-text |
Testo specifico non fondato. | String |
Verificare la fondatezza con il ragionamento
L'API di Rilevamento della fondatezza permette di includere il ragionamento nella risposta dell'API. Se il ragionamento è abilitato, la risposta include un campo "reasoning" che descrive in dettaglio istanze specifiche e spiegazioni per qualsiasi elemento infondato rilevato.
Connettere una propria distribuzione GPT
Suggerimento
Sono supportate solo le risorse di Azure OpenAI GPT-4o (versioni 0513, 0806) e non supportano altri modelli. È possibile distribuire le risorse di Azure OpenAI GPT-4o (versioni 0513, 0806) in qualsiasi area. Tuttavia, per ridurre al minimo la latenza potenziale ed evitare eventuali problemi di privacy e rischio per i dati relativi ai limiti geografici, è consigliabile inserirli nella stessa area delle risorse di Sicurezza dei contenuti per intelligenza artificiale di Azure. Per informazioni dettagliate sulla privacy dei dati, vedere le linee guida su dati, privacy e sicurezza per Azure OpenAI e dati, privacy e sicurezza per La sicurezza dei contenuti di Azure per intelligenza artificiale.
Per usare la risorsa Azure OpenAI GPT-4o (versioni 0513, 0806) per abilitare la funzionalità di ragionamento, usare l'identità gestita per consentire alla risorsa Content Safety di accedere alla risorsa OpenAI di Azure:
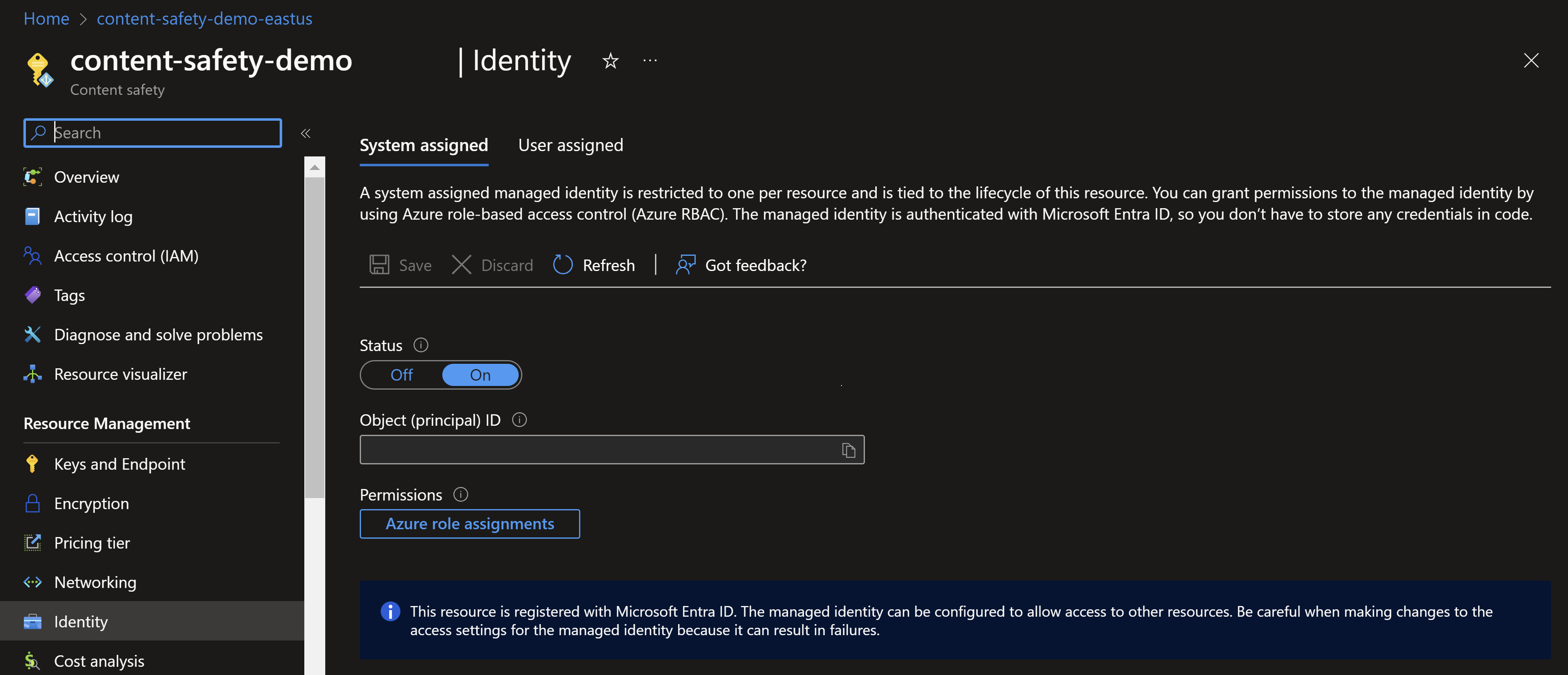
Abilitare l'identità gestita per Sicurezza dei contenuti di Azure AI.
Passare all'istanza di Sicurezza dei contenuti di Azure AI nel portale di Azure. Individuare la sezione Identità nella categoria Impostazioni. Abilitare l’identità gestita assegnata dal sistema. Questa azione concede all'istanza di Sicurezza dei contenuti di Azure AI un'identità che può essere riconosciuta e usata in Azure per l'accesso ad altre risorse.
Assegnare il ruolo a Identità gestita.
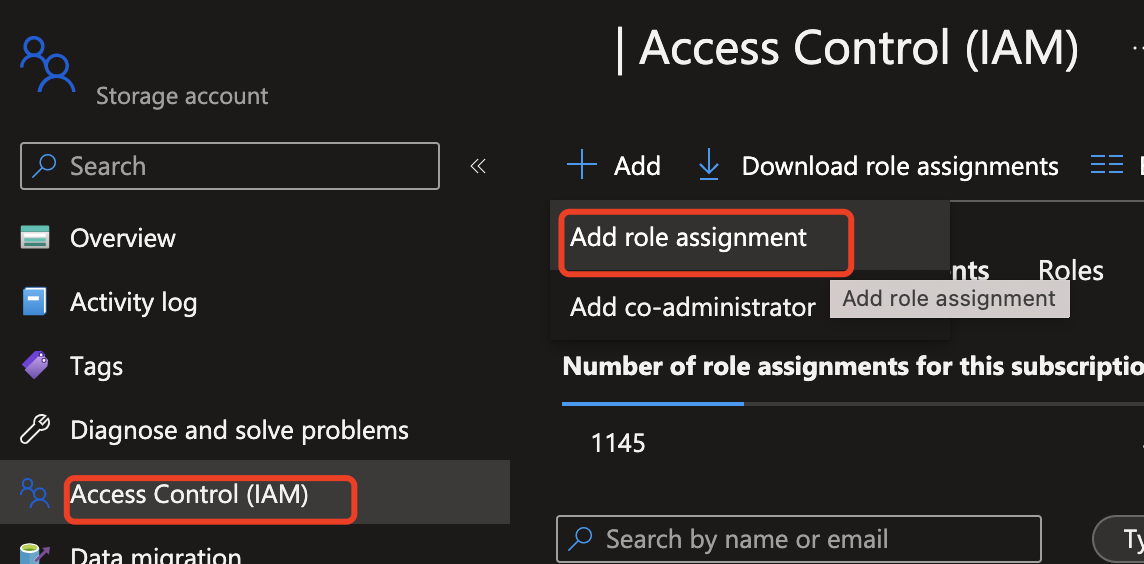
Passare all'istanza di Azure OpenAI, selezionare Aggiungi assegnazione di ruolo per avviare il processo di assegnazione di un ruolo Azure OpenAI all'identità Sicurezza dei contenuti di Azure AI.
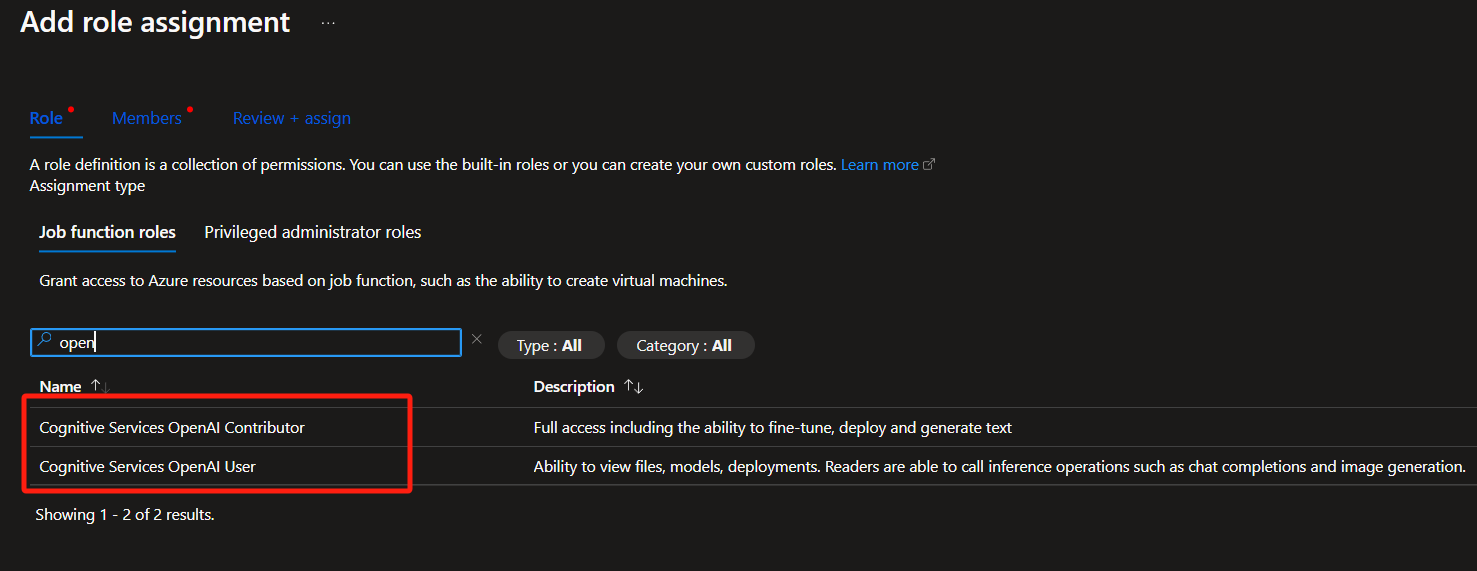
Scegliere il ruolo Utente o Collaboratore.


Effettuare la richiesta API
Nella richiesta all'API di Rilevamento della fondatezza impostare il parametro del corpo "reasoning" su truee specificare gli altri parametri necessari:
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"reasoning": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
La sezione seguente illustra una richiesta di esempio con cURL. Incollare il comando seguente in un editor di testo e apportare le modifiche seguenti.
Sostituire
<endpoint>con l'URL dell'endpoint associato alla risorsa di Sicurezza dei contenuti di Azure AI.Sostituire
<your_subscription_key>con una delle chiavi per la risorsa.Sostituire
<your_OpenAI_endpoint>con l'URL dell'endpoint associato alla risorsa di Azure OpenAI.Sostituire
<your_deployment_name>con il nome della distribuzione di Azure OpenAI.Facoltativamente, sostituire i campi
"query"o"text"nel corpo con il testo personalizzato da analizzare.curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. If they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": true, "llmResource": { "resourceType": "AzureOpenAI", "azureOpenAIEndpoint": "<your_OpenAI_endpoint>", "azureOpenAIDeploymentName": "<your_deployment_name>" }'Aprire una finestra del prompt dei comandi ed eseguire il comando cURL.
I parametri nel corpo della richiesta sono definiti in questa tabella:
| Nome | Descrizione | Tipo |
|---|---|---|
| domain | (Facoltativo) MEDICAL o GENERIC. Valore predefinito: GENERIC. |
Enum |
| task | (Facoltativo) Tipo di attività: QnA, Summarization. Valore predefinito: Summarization. |
Enum |
| qna | (Facoltativo) Contiene i dati QnA quando il tipo di attività è QnA. |
String |
- query |
(Facoltativo) Rappresenta la domanda in un'attività QnA. Limite di caratteri: 7.500. | String |
| text | (Obbligatorio) Il testo di output del modello LLM da controllare. Limite di caratteri: 7.500. | String |
| fontiDiFondazione | (Obbligatorio) Usa un array di origini fondatezza per convalidare il testo generato dall'intelligenza artificiale. Vedere Requisiti di input per i limiti. | Array di stringhe |
| ragionamento | (Facoltativo) Impostare su true; il servizio usa le risorse di Azure OpenAI per fornire una spiegazione. Attenzione: l'uso del ragionamento aumenta il tempo di elaborazione e comporta costi aggiuntivi. |
Boolean |
| llmResource | (Obbligatorio) Se si vuole usare la propria risorsa Azure OpenAI GPT-4o (versioni 0513, 0806) per abilitare il ragionamento, aggiungere questo campo e includere i sottocampi per le risorse usate. | String |
- resourceType |
Specifica il tipo di risorsa usata. Attualmente consente solo AzureOpenAI. Sono supportate solo le risorse di Azure OpenAI GPT-4o (versioni 0513, 0806) e non supportano altri modelli. |
Enum |
- azureOpenAIEndpoint |
URL dell'endpoint per il servizio Azure OpenAI. | String |
- azureOpenAIDeploymentName |
Il nome della distribuzione del modello specifica da usare. | String |
Interpretare la risposta dell'API
Dopo l’invio della richiesta, si riceverà una risposta JSON che riflette l'analisi della fondatezza eseguita. Ecco come appare un output tipico:
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour.",
"offset": {
"utf8": 0,
"utf16": 0,
"codePoint": 0
},
"length": {
"utf8": 8,
"utf16": 8,
"codePoint": 8
},
"reason": "None. The premise mentions a pay of \"10/hour\" but does not mention \"12/hour.\" It's neutral. "
}
]
}
Gli oggetti JSON nell'output sono definiti qui:
| Nome | Descrizione | Tipo |
|---|---|---|
| ungroundedDetected | Indica se il testo presenta elementi infondati. | Boolean |
| ungroundedPercentage | Specifica la proporzione del testo identificato come infondato, espressa come numero compreso tra 0 e 1, dove 0 indica che non è presente alcun contenuto infondato e 1 indica contenuto completamente infondato. Questo non è un livello di attendibilità. | Float |
| dettagliSenzaFondamento | Fornisce informazioni dettagliate sul contenuto infondato con esempi e percentuali specifici. | Array |
-text |
Testo specifico non fondato. | String |
-offset |
Un oggetto che descrive la posizione del testo infondato in varie codifiche. | String |
- offset > utf8 |
Posizione di offset del testo non fondato nella codifica UTF-8. | Integer |
- offset > utf16 |
Posizione di offset del testo non fondato nella codifica UTF-16. | Integer |
- offset > codePoint |
La posizione di offset del testo infondato in termini di punti di codice Unicode. | Integer |
-length |
Oggetto che descrive la lunghezza del testo non fondato in varie codifiche. (utf8, utf16, codePoint), simile all'offset. | Oggetto |
- length > utf8 |
Lunghezza del testo non fondato nella codifica UTF-8. | Integer |
- length > utf16 |
Lunghezza del testo non fondato nella codifica UTF-16. | Integer |
- length > codePoint |
Lunghezza del testo non fondato in termini di punti di codice Unicode. | Integer |
-reason |
Offre spiegazioni per gli elementi non fondati rilevati. | String |
Verificare la fondatezza con la funzionalità di correzione
L'API di rilevamento della fondatezza include una funzionalità di correzione che corregge automaticamente eventuali mancanze di fondatezza rilevate nel testo in base alle origini di fondatezza fornite. Quando la funzionalità di correzione è abilitata, la risposta include un campo "correction Text" che presenta il testo corretto allineato alle origini di fondatezza.
Connettere una propria distribuzione GPT
Suggerimento
Attualmente, la funzionalità di correzione supporta solo le risorse azure OpenAI GPT-4o (versioni 0513, 0806). Per ridurre al minimo la latenza e rispettare le linee guida sulla privacy dei dati, è consigliabile distribuire Azure OpenAI GPT-4o (versioni 0513, 0806) nella stessa area delle risorse di Sicurezza dei contenuti per intelligenza artificiale di Azure. Per altre informazioni sulla privacy dei dati, vedere le linee guida su dati, privacy e sicurezza per Azure OpenAI e Dati, privacy e sicurezza per La sicurezza dei contenuti di Azure per intelligenza artificiale.
Per usare la risorsa Azure OpenAI GPT-4o (versioni 0513, 0806) per abilitare la funzionalità di correzione, usare Identità gestita per consentire alla risorsa Content Safety di accedere alla risorsa OpenAI di Azure. Seguire i passaggi riportati nella sezione precedente per configurare l'identità gestita.
Effettuare la richiesta API
Nella richiesta all'API di rilevamento fondatezza, impostare il parametro del corpo "correction" su true e specificare gli altri parametri necessari:
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
Questa sezione illustra una richiesta di esempio usando cURL. Sostituire i segnaposto in base alle esigenze:
- Sostituire
<endpoint>con l'URL dell'endpoint della risorsa. - Sostituire
<your_subscription_key>con la chiave di sottoscrizione. - Facoltativamente, sostituire il campo "text" con il testo da analizzare.
curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \
--header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"domain": "Generic",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}'
I parametri nel corpo della richiesta sono definiti in questa tabella:
| Nome | Descrizione | Tipo |
|---|---|---|
| domain | (Facoltativo) MEDICAL o GENERIC. Valore predefinito: GENERIC. |
Enum |
| task | (Facoltativo) Tipo di attività: QnA, Summarization. Valore predefinito: Summarization. |
Enum |
| qna | (Facoltativo) Contiene i dati QnA quando il tipo di attività è QnA. |
String |
- query |
(Facoltativo) Rappresenta la domanda in un'attività QnA. Limite di caratteri: 7.500. | String |
| text | (Obbligatorio) Il testo di output del modello LLM da controllare. Limite di caratteri: 7.500. | String |
| fontiDiFondazione | (Obbligatorio) Usa un array di origini fondatezza per convalidare il testo generato dall'intelligenza artificiale. Vedere Requisiti di input per i limiti. | Array di stringhe |
| correzione | (Facoltativo) Se è impostato su true, il servizio usa le risorse di Azure OpenAI per fornire il testo corretto, garantendo la coerenza con le origini di fondatezza. Attenzione: l'uso della correzione aumenta il tempo di elaborazione e comporta costi aggiuntivi. |
Boolean |
| llmResource | (Obbligatorio) Se si vuole usare la propria risorsa Azure OpenAI GPT-4o (versioni 0513, 0806) per abilitare il ragionamento, aggiungere questo campo e includere i sottocampi per le risorse usate. | String |
- resourceType |
Specifica il tipo di risorsa usata. Attualmente consente solo AzureOpenAI. Sono supportate solo le risorse di Azure OpenAI GPT-4o (versioni 0513, 0806) e non supportano altri modelli. |
Enum |
- azureOpenAIEndpoint |
URL dell'endpoint per il servizio Azure OpenAI. | String |
- azureOpenAIDeploymentName |
Il nome della distribuzione del modello specifica da usare. | String |
Interpretare la risposta dell'API
La risposta include un campo "correction Text" contenente il testo corretto, in modo da garantire la coerenza con le origini di fondatezza fornite.
La funzionalità di correzione rileva che Kevin è privo di fondatezza perché è in conflitto con l'origine di fondatezza Jane. L'API restituisce il testo corretto: "The patient name is Jane."
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "The patient name is Kevin"
}
],
"correction Text": "The patient name is Jane"
}
Gli oggetti JSON nell'output sono definiti qui:
| Nome | Descrizione | Tipo |
|---|---|---|
| ungroundedDetected | Indica se è stato rilevato contenuto infondato. | Boolean |
| ungroundedPercentage | Percentuale di contenuto infondato nel testo. Questo non è un livello di attendibilità. | Float |
| dettagliSenzaFondamento | Dettagli del contenuto infondato, inclusi segmenti di testo specifici. | Array |
-text |
Testo specifico non fondato. | String |
-offset |
Un oggetto che descrive la posizione del testo infondato in varie codifiche. | String |
- offset > utf8 |
Posizione di offset del testo non fondato nella codifica UTF-8. | Integer |
- offset > utf16 |
Posizione di offset del testo non fondato nella codifica UTF-16. | Integer |
-length |
Oggetto che descrive la lunghezza del testo non fondato in varie codifiche. (utf8, utf16, codePoint), simile all'offset. | Oggetto |
- length > utf8 |
Lunghezza del testo non fondato nella codifica UTF-8. | Integer |
- length > utf16 |
Lunghezza del testo non fondato nella codifica UTF-16. | Integer |
- length > codePoint |
Lunghezza del testo non fondato in termini di punti di codice Unicode. | Integer |
-correction Text |
Testo corretto, in modo da garantire la coerenza con le origini di fondatezza. | String |
Pulire le risorse
Se si vuole pulire e rimuovere una sottoscrizione a Servizi di Azure AI, è possibile eliminare la risorsa o il gruppo di risorse. Eliminando il gruppo di risorse, vengono eliminate anche tutte le altre risorse associate.
Contenuto correlato
- Concetti di rilevamento della fondatezza
- Combinare il rilevamento della fondatezza con altre funzionalità di sicurezza dei modelli LLM, ad esempio Prompt Shields.