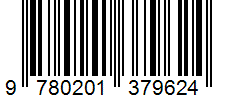Funzionalità dei componenti aggiuntivi di Document Intelligence
Articolo
Importante
Le versioni di anteprima pubblica di Informazioni sui documenti consentono accesso anticipato alle funzionalità in fase di sviluppo attivo.
Le funzionalità, gli approcci e i processi possono cambiare prima della disponibilità generale, a seconda del feedback degli utenti.
Per impostazione predefinita, la versione di anteprima pubblica delle librerie client di Informazioni sui documenti è la versione dell'API REST 2024-02-29-preview.
La versione di anteprima pubblica 2024-02-29-preview è attualmente disponibile solo nelle aree di Azure seguenti:
Questo contenuto si applica a:v3.1 (disponibilità generale) | Ultime versioni:v4.0 (anteprima)
Nota
Le funzionalità dei componenti aggiuntivi sono disponibili all'interno di tutti i modelli, ad eccezione del modello del biglietto da visita.
Funzionalità
Document Intelligence supporta funzionalità di analisi più sofisticate e modulari. Usare le funzionalità del componente aggiuntivo per estendere i risultati per includere altre funzionalità estratte dai documenti. Alcune funzionalità del componente aggiuntivo comportano un costo aggiuntivo. Queste funzionalità facoltative possono essere abilitate e disabilitate a seconda dello scenario di estrazione dei documenti. Per abilitare una funzionalità, aggiungere il nome della funzionalità associata alla proprietà della stringa di query features. È possibile abilitare più funzionalità del componente aggiuntivo in una richiesta fornendo un elenco delimitato da virgole di funzionalità. Le funzionalità aggiuntive seguenti sono disponibili per 2023-07-31 (GA) e per le versioni successive.
Non tutte le funzionalità dei componenti aggiuntivi sono supportate da tutti i modelli. Per altre informazioni, vedere l’estrazione dei dati del modello.
Le funzionalità dei componenti aggiuntivi non sono attualmente supportate per i tipi di file di Microsoft Office.
Le funzionalità aggiuntive seguenti sono disponibili per 2024-02-29-preview, 2024-02-29-preview e per le versioni successive:
L'implementazione dei campi di query nell'API 2023-10-30-preview è diversa dall'ultima versione di anteprima. La nuova implementazione è meno costosa e funziona bene con i documenti strutturati.
✱ Componente aggiuntivo - I campi di query vengono distribuiti in modo diverso rispetto alle altre funzionalità del componente aggiuntivo. Per informazioni dettagliate, vedere i prezzi.
Formati di file supportati
PDF
Immagini: JPEG/JPG, PNG, BMP, TIFF, HEIF
.✱ i file di Microsoft Office non sono attualmente supportati.
Estrazione ad alta risoluzione
Il riconoscimento di testo piccolo in documenti di grandi dimensioni, ad esempio disegni di progettazione, è un'attività complessa. Spesso il testo è combinato con altri elementi grafici e ha tipi di carattere, dimensioni e orientamenti variabili. Inoltre, il testo può essere suddiviso in parti separate o collegate con altri simboli. Document Intelligence supporta ora l'estrazione di contenuto da questi tipi di documenti con la funzionalità ocr.highResolution. È possibile estrarre contenuto con una qualità migliore da documenti A1/A2/A3 abilitando questa funzionalità aggiuntiva.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
La funzionalità ocr.formula estrae tutte le formule identificate, ad esempio equazioni matematiche, nella raccolta formulas come oggetto di primo livello in content. All'interno di content, le formule rilevate vengono rappresentate come :formula:. Ogni voce di questa raccolta rappresenta una formula che include il tipo di formula, come inline o display, e la relativa rappresentazione LaTeX come value insieme alle coordinate polygon. Inizialmente, le formule vengono visualizzate alla fine di ogni pagina.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Estrazione delle proprietà dei tipi di carattere
La funzionalità ocr.font estrae tutte le proprietà del tipo di carattere del testo estratto nella raccolta styles come oggetto di primo livello in content. Ogni oggetto stile specifica una singola proprietà del tipo di carattere, l'intervallo di testo a cui si applica e il punteggio di attendibilità corrispondente. La proprietà style esistente viene estesa con più proprietà dei tipi di carattere, ad esempio similarFontFamily per il tipo di carattere del testo, fontStyle per stili come corsivo e normale, fontWeight per il grassetto o normale, color per il colore del testo e backgroundColor per il colore del riquadro delimitatore del testo.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
La funzionalità ocr.barcode estrae tutti i codici a barre identificati di testo nella raccolta barcodes come oggetto di primo livello in content. All'interno di content i codici a barre rilevati vengono rappresentati come :barcode:. Ogni voce di questa raccolta rappresenta un codice a barre e include il tipo di codice a barre come kind e il contenuto di codice a barre incorporato come value insieme alle coordinate polygon. Inizialmente, i codici a barre vengono visualizzati alla fine di ogni pagina. Il confidence è hardcoded per come 1.
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
L'aggiunta della funzionalità di languages alla richiesta di analyzeResult consente di fare una stima della lingua primaria rilevata per ogni riga di testo insieme al confidence nella raccolta languages in analyzeResult.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
Nelle versioni precedenti dell'API, il modello di documento predefinito ha estratto coppie chiave-valore da moduli e documenti. Con l'aggiunta della funzionalità di keyValuePairs al layout predefinito, il modello di layout produce ora gli stessi risultati.
Le coppie chiave-valore sono intervalli specifici all'interno del documento che identificano un'etichetta o una chiave e la risposta o il valore associato. In un modulo strutturato, queste coppie possono essere l'etichetta e il valore immessi dall'utente per tale campo. In un documento non strutturato, possono essere la data di esecuzione di un contratto o possono essere basate sul testo di un paragrafo. Il modello di intelligenza artificiale viene sottoposto a training per estrarre chiavi e valori identificabili in base a un'ampia gamma di tipi, formati e strutture di documenti.
Le chiavi possono esistere anche in isolamento quando il modello rileva che esiste una chiave senza alcun valore associato o quando vengono elaborati campi facoltativi. Ad esempio, un campo del secondo nome può essere lasciato vuoto in un modulo in alcuni casi. Le coppie chiave-valore sono intervalli di testo contenuti nel documento. Per i documenti in cui lo stesso valore viene descritto in modi diversi, ad esempio cliente/utente, la chiave associata è cliente o utente (in base al contesto).
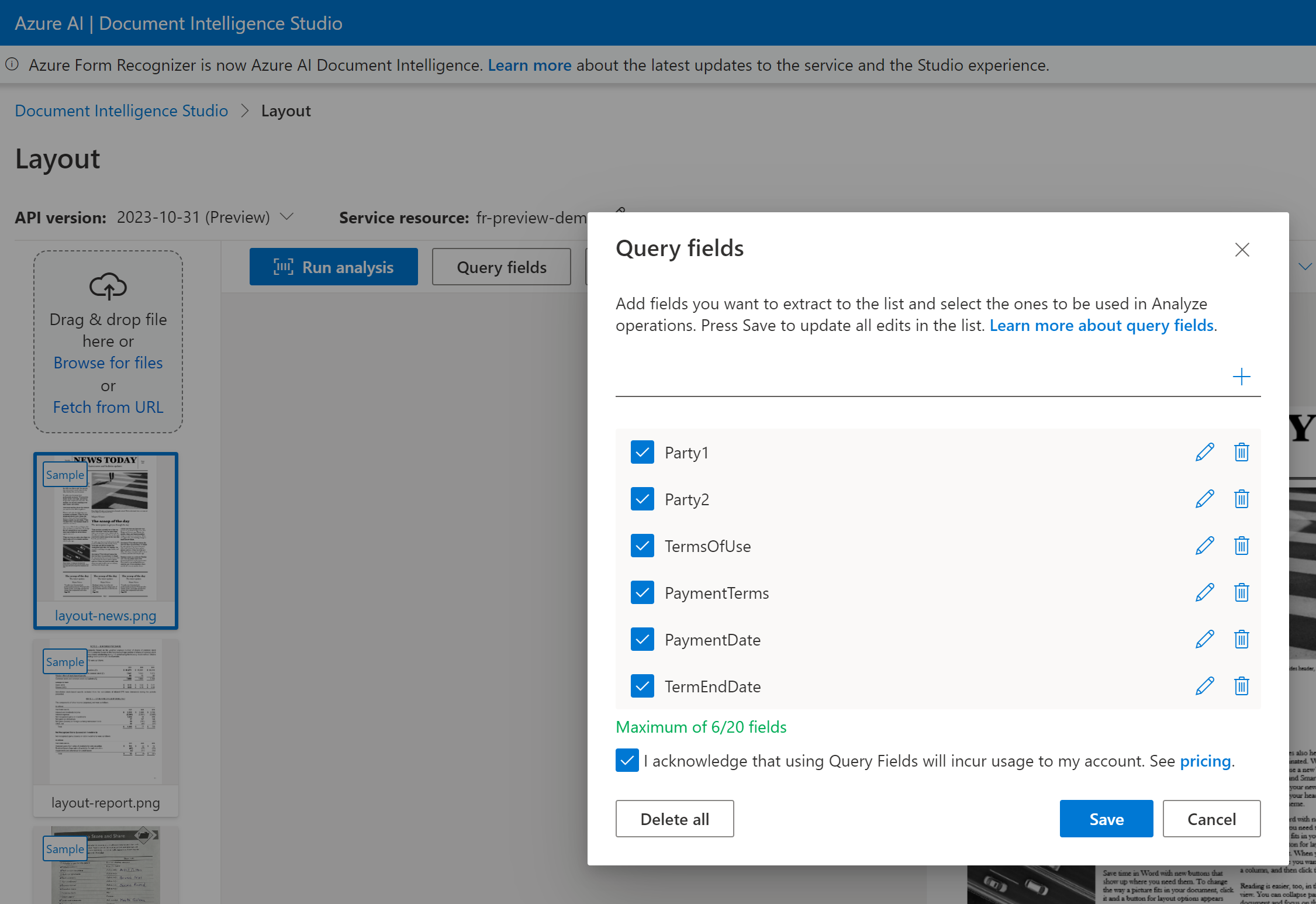
I campi di query sono una funzionalità del componente aggiuntivo per estendere lo schema estratto da qualsiasi modello predefinito o definire un nome di chiave specifico quando il nome della chiave è variabile. Per usare i campi di query, impostare le funzionalità su queryFields e fornire un elenco delimitato da virgole di nomi di campo nella proprietà queryFields.
Document Intelligence supporta ora le estrazioni di campi di query. Con l'estrazione dei campi di query, è possibile aggiungere campi al processo di estrazione usando una richiesta di query senza la necessità di aggiungere training.
Usare i campi di query quando è necessario estendere lo schema di un modello predefinito o personalizzato oppure è necessario estrarre alcuni campi con l'output del layout.
I campi di query sono una funzionalità di componente aggiuntivo Premium. Per ottenere risultati ottimali, definire i campi da estrarre usando le lettere maiuscole o le lettere pascal per i nomi di campo composti da più parole.
I campi di query supportano un massimo di 20 campi per richiesta. Se il documento contiene un valore per il campo, vengono restituiti il campo e il valore.
In questa versione è disponibile una nuova implementazione della funzionalità dei campi di query con prezzi inferiori rispetto all'implementazione precedente e dovrebbe essere convalidata.
Nota
L'estrazione dei campi di query di Document Intelligence Studio è attualmente disponibile con le API per i modelli predefiniti e layout 2024-02-29-preview2023-10-31-preview e le versioni successive, ad eccezione dei modelli di US tax (W2, 1098 e 1099).
Estrazione di campi di query
Specificare i campi da estrarre e Document Intelligence analizzerà il documento di conseguenza. Ecco un esempio:
Se si elabora un contratto in Document Intelligence Studio, usare le versioni 2024-02-29-preview o 2023-10-31-preview:
È possibile passare un elenco di etichette di campo come Party1, Party2, TermsOfUse, PaymentTerms, PaymentDate e TermEndDate come parte della richiesta di analyze document.
Document Intelligence è in grado di analizzare ed estrarre i dati dei campi e restituire i valori in un output JSON strutturato.
Oltre ai campi di query, la risposta include testo, tabelle, segni di selezione e altri dati pertinenti.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.