Modello di contratto di Document Intelligence
Importante
- Le versioni di anteprima pubblica di Document Intelligence consentono l'accesso anticipato alle funzionalità in fase di sviluppo attivo.
- Le funzionalità, gli approcci e i processi possono cambiare prima della disponibilità generale, a seconda del feedback degli utenti.
- Per impostazione predefinita, la versione di anteprima pubblica delle librerie client di Document Intelligence è la versione dell'API REST 29-02-2024-anteprima.
- La versione di anteprima pubblica 29-02-2024-anteprima è al momento disponibile solo nelle aree di Azure seguenti:
- Stati Uniti orientali
- Stati Uniti occidentali 2
- Europa occidentale
Questo contenuto si applica a:![]() v4.0 (anteprima) | Versione precedenti:
v4.0 (anteprima) | Versione precedenti: ![]() v3.1 (disponibilità generale)
v3.1 (disponibilità generale)
Questo contenuto si applica a: ![]() v3.1 (disponibilità generale) | Ultima versione:
v3.1 (disponibilità generale) | Ultima versione: ![]() v4.0 (anteprima)
v4.0 (anteprima)
Il modello di contratto di Document Intelligence usa potenti funzionalità di riconoscimento ottico dei caratteri (OCR) per analizzare ed estrarre campi chiave e voci da un gruppo selezionato di entità contrattuali. I contratti possono essere di vari formati e qualità, tra cui immagini acquisite dal telefono, documenti digitalizzati e PDF digitali. L'API analizza il testo del documento, estrae le informazioni chiave, come le parti, la giurisdizione, l'ID contratto e il titolo. Restituisce quindi una rappresentazione di dati JSON strutturati. Il modello al momento supporta i formati di documenti in lingua inglese.
Elaborazione automatica dei contratti
L'elaborazione automatica dei contratti è il processo di estrazione dei campi chiave del contratto dai documenti. Il processo di analisi dei contratti è stato sempre eseguito manualmente e, di conseguenza, risulta molto dispendioso in termini di tempo. L'estrazione accurata dei dati chiave del contratto è in genere il primo e uno dei passaggi più critici del processo di automazione dei contratti.
Opzioni di sviluppo
Document Intelligence v4.0 29-02-2024-anteprima supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di contratto | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-contract |
Document Intelligence v3. 1 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di contratto | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-contract |
Document Intelligence v3.0 supporta gli strumenti, le applicazioni e le librerie seguenti:
| Funzionalità | Risorse | Model ID |
|---|---|---|
| Modello di contratto | • Document Intelligence Studio • API REST • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-contract |
Requisiti di input
Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Formati di file supportati:
Modello PDF Immagine:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) e HTMLLettura ✔ ✔ ✔ Layout ✔ ✔ ✔ (29-02-2024-anteprima, 31-10-2023-anteprima) Documento generale ✔ ✔ Predefinito ✔ ✔ Estrazione personalizzata ✔ ✔ Classificazione personalizzata ✔ ✔ ✔ (2024-02-29-anteprima) Per i formati PDF e TIFF, possono essere elaborate fino a 2000 pagine (con una sottoscrizione di livello gratuito, vengono elaborate solo le prime due pagine).
La dimensione del file per l'analisi dei documenti è di 500 MB per il livello a pagamento (S0) e 4 MB per il livello gratuito (F0).
Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e 1G MB per il modello neurale.
Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GBcon un massimo di 10.000 pagine.
Provare l'estrazione dei dati dei documenti del contratto
Vedere in che modo i dati, incluse le informazioni sul cliente, i dettagli del fornitore e le voci, vengono estratti dai contratti. Sono necessarie le risorse seguenti:
Sottoscrizione di Azure: è possibile crearne una gratuitamente.
Un'Document Intelligence sui documenti nel portale di Azure. Per provare il servizio, è possibile usare il piano tariffario gratuito (
F0). Dopo la distribuzione della risorsa, selezionare Vai alla risorsa per recuperare la chiave e l'endpoint.
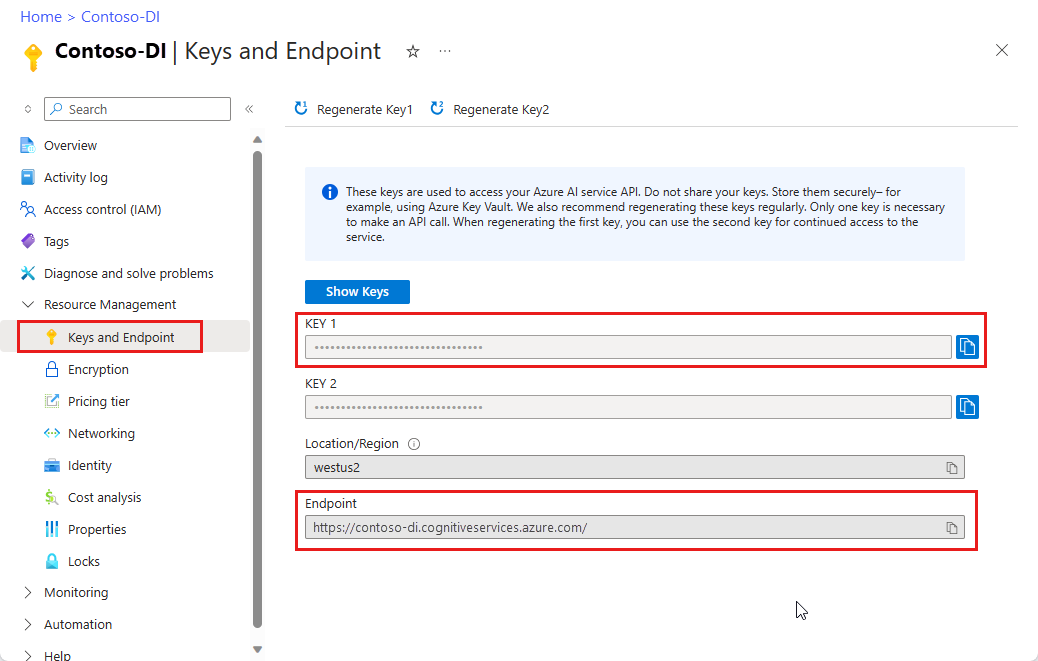
Document Intelligence Studio
Nella home page di Document Intelligence Studio selezionare Documenti fiscali.
È possibile analizzare documenti fiscali di esempio o caricare i propri file.
Selezionare il pulsante Esegui analisi e, se necessario, configurare Analizza opzioni:

Lingue e impostazioni locali supportate
Vedere la pagina Lingue supportate - Modelli predefiniti per un elenco completo delle lingue supportate.
Estrazione di campi
Di seguito sono riportati i campi estratti da un contratto nella risposta di output JSON.
| Nome | Tipo | Descrizione | Output di esempio |
|---|---|---|---|
| Title | String | Titolo contratto | Contratto di assistenza |
| ContractId | String | Titolo contratto | AB12956 |
| Entità | Matrice | Elenco delle parti | |
| ExecutionDate | Data | Data in cui il contratto è stato sottoscritto e accettato dalle parti | On this twenty-third day of February two thousand and twenty two |
| ExpirationDate | Data | Data di scadenza del contratto | Un anno |
| RenewalDate | Data | Data di rinnovo del contratto | On this twenty-third day of February two thousand and twenty two |
| Giurisdizioni | Matrice | Elenco delle giurisdizioni |
Le coppie chiave-valore del contratto e le voci estratte si trovano nella sezione documentResults dell'output JSON.
Passaggi successivi
Provare a elaborare moduli e documenti personalizzati con Document Intelligence Studio.
Completare un avvio rapido di Document Intelligence e iniziare a creare un'app per l'elaborazione di documenti nel linguaggio di sviluppo preferito.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per