Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo contenuto si applica a:![]() v4.0 (GA) | Versioni precedenti:
v4.0 (GA) | Versioni precedenti:![]() v3.1 (GA) v3.0 (GA)
v3.1 (GA) v3.0 (GA)![]()
![]() v2.1
v2.1
I modelli personalizzati di Informazioni sui documenti richiedono solo alcuni documenti di training per iniziare. Se si hanno almeno cinque documenti, è possibile iniziare a eseguire il training di un modello personalizzato. È possibile eseguire il training di un modello di modello personalizzato (modulo personalizzato) o di un modello neurale personalizzato (documento personalizzato). Questo documento illustra il processo di training dei modelli personalizzati.
Requisiti di input per il modello personalizzato
Prima di tutto, assicurarsi che il set di dati di training segua i requisiti di input per Informazioni sui documenti.
Formati di file supportati:
| Modello | Immagine: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lettura | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Documento generale | ✔ | ✔ | |
| Predefinito | ✔ | ✔ | |
| Estrazione personalizzata | ✔ | ✔ | |
| Classificazione personalizzata | ✔ | ✔ | ✔ |
Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e
4MB per il livello gratuito (F0).Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e
1GB per il modello neurale.Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GB con un massimo di 10.000 pagine. Per 2024-11-30 (GA), le dimensioni totali dei dati di training sono2GB con un massimo di 10.000 pagine.
Suggerimenti per i dati di training
Seguire questi suggerimenti per ottimizzare ulteriormente il set di dati per il training:
- Utilizzare documenti PDF basati su testo anziché documenti basati su immagini. I PDF sottoposti a scansione vengono gestiti come immagini.
- Per i moduli con campi di input, usare esempi con tutti i campi completati.
- Usa moduli con valori diversi in ogni campo.
- Se le immagini del modulo sono di qualità inferiore, usare un set di dati più grande (10-15 immagini).
Caricare i dati di training
Dopo aver raccolto un set di moduli o documenti per il training, è necessario caricarlo in un contenitore di archiviazione BLOB di Azure. Se non si sa come creare un account di archiviazione di Azure con un contenitore, seguire la guida di avvio rapido di Archiviazione di Azure per il portale di Azure. È possibile usare il piano tariffario gratuito (F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione.
Video: Eseguire il training del modello personalizzato
- Dopo aver raccolto e caricato il set di dati di training, è possibile eseguire il training del modello personalizzato. Nel video seguente si creerà un progetto e si esamineranno alcuni dei concetti fondamentali per l'etichettatura e il training di un modello.
Creare un progetto in Studio di Informazioni sui documenti
Lo Studio di Informazioni sui documenti fornisce e orchestra tutte le chiamate API necessarie per completare il set di dati ed eseguire il training del modello.
Per iniziare, passare a Studio di Informazioni sui documenti. La prima volta che si usa lo studio, è necessario inizializzare la sottoscrizione, il gruppo di risorse e la risorsa. Seguire quindi i prerequisiti per i progetti personalizzati per configurare lo studio per accedere al set di dati di training.
In Studio selezionare il riquadro Modello di estrazione personalizzata e selezionare il pulsante Crea un progetto.
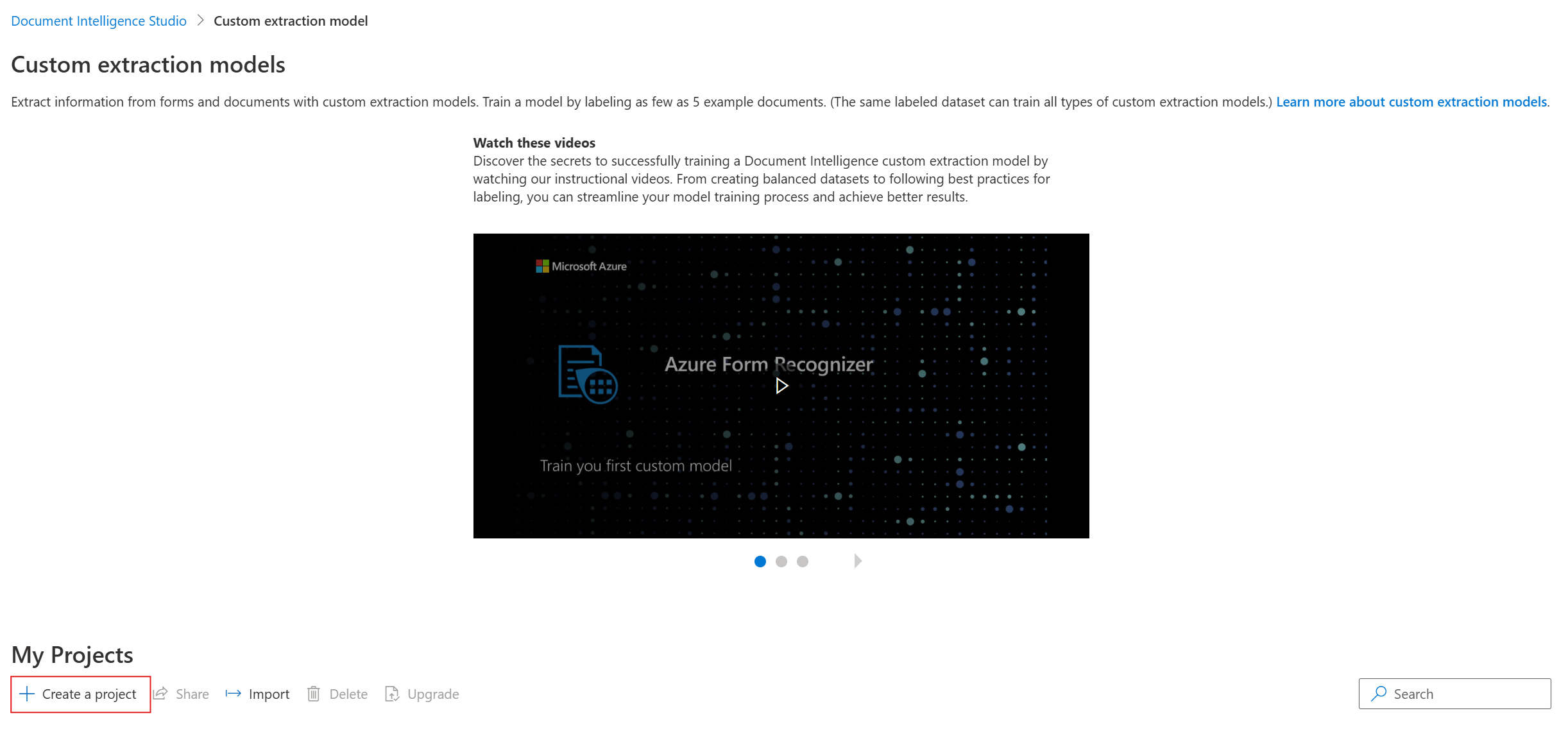
Nella finestra di dialogo
create projectspecificare un nome per il progetto, facoltativamente una descrizione e selezionare Continua.Nel passaggio successivo del flusso di lavoro, scegliere o creare una risorsa di Informazioni sui documenti prima di selezionare Continua.
Importante
I modelli neurali personalizzati sono disponibili solo in alcune aree. Se si prevede di eseguire il training di un modello neurale, selezionare o creare una risorsa in una di queste aree supportate.
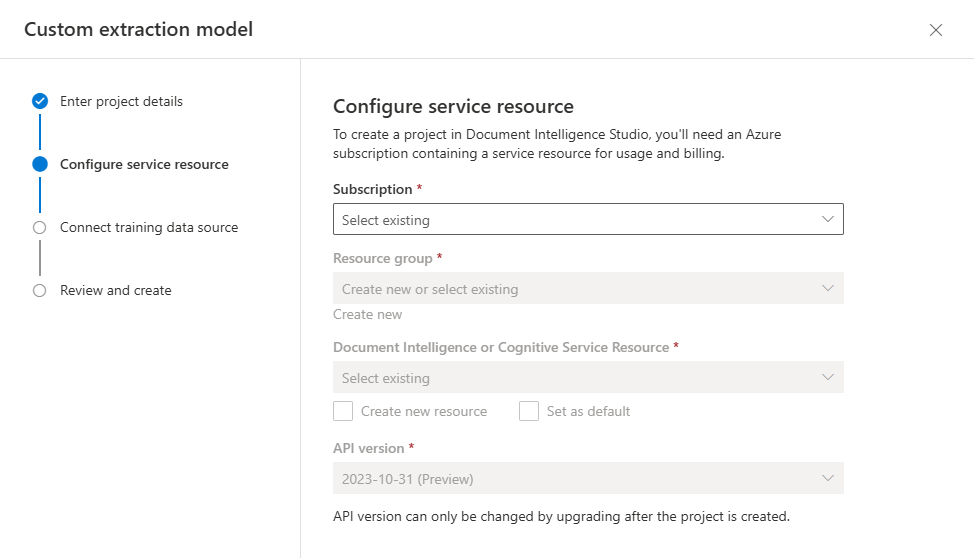
Selezionare quindi l'account di archiviazione usato per caricare il set di dati di training del modello personalizzato. Il Percorso cartella deve essere vuoto se i documenti di training si trovano nella radice del contenitore. Se i documenti si trovano in una sottocartella, immettere il percorso relativo dalla radice del contenitore nel campo Percorso cartella. Dopo aver configurato l'account di archiviazione, selezionare Continua.
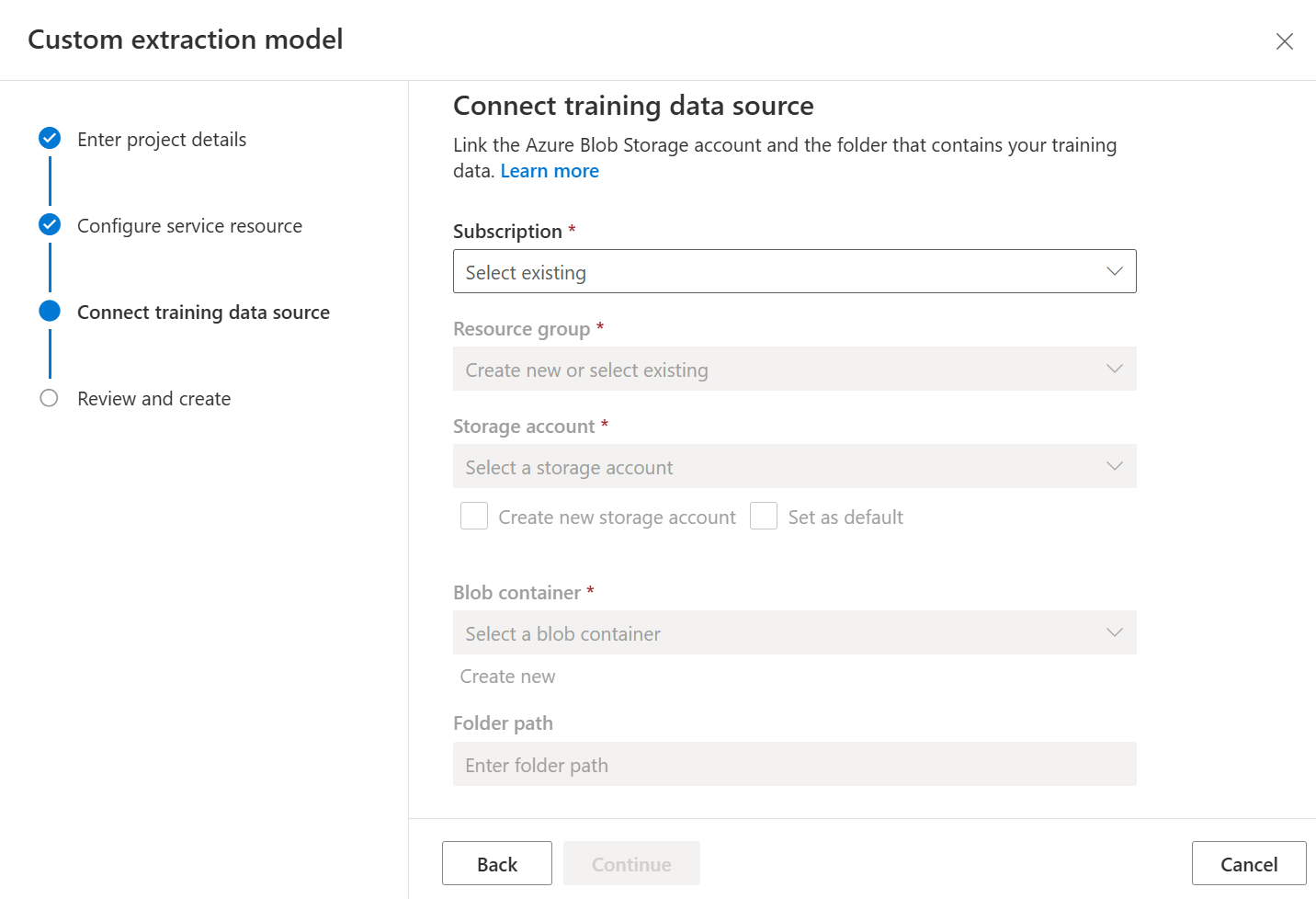
Esaminare infine le impostazioni del progetto e selezionare Crea progetto per creare un nuovo progetto. A questo punto, verrà visualizzata la finestra di etichettatura con l'elenco dei file nel set di dati.
Assegnare etichette ai dati
Nel progetto, la prima attività prevede l'etichettatura del set di dati con i campi da estrarre.
I file caricati nella risorsa di archiviazione sono elencati a sinistra della schermata, con il primo file pronto per essere etichettato.
Per iniziare a etichettare il set di dati e a creare il primo campo, selezionare il pulsante più (➕) nella parte superiore destra della schermata.
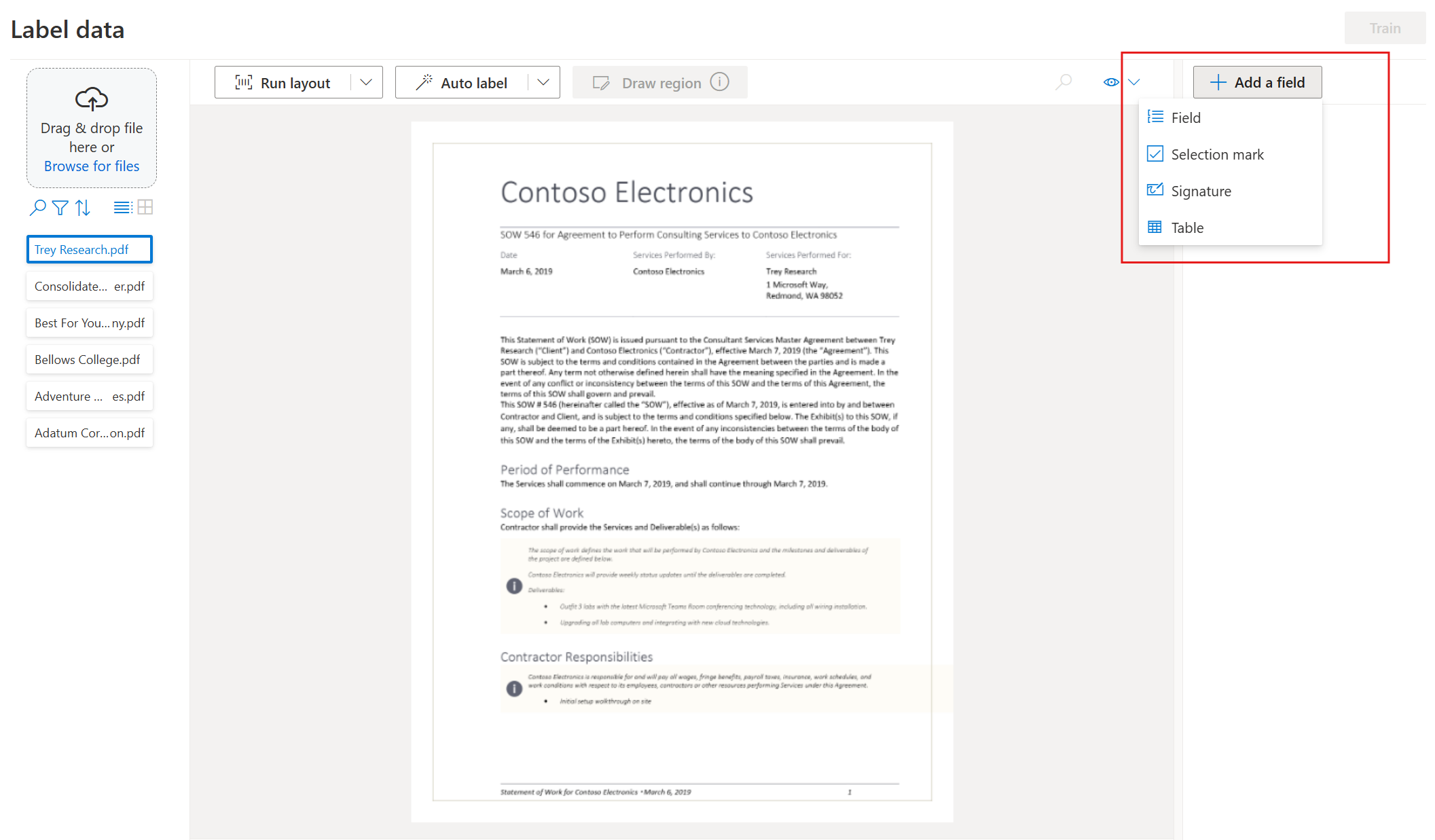
Immettere un nome per il campo.
Assegnare un valore al campo scegliendo una o più parole nel documento. Selezionare il campo nell'elenco a discesa o nell'elenco dei campi sulla barra di spostamento a destra. Il valore etichettato è mostrato sotto il nome del campo nell'elenco dei campi.
Ripetere il processo per tutti i campi da etichettare per il set di dati.
Etichettare i documenti rimanenti nel set di dati selezionando ogni documento e quindi il testo da etichettare.
A questo punto, tutti i documenti nel set di dati sono etichettati. I file .labels.json e .ocr.json corrispondono a ogni documento nel set di dati di training e a un nuovo file fields.json. Questo set di dati di training viene inviato per eseguire il training del modello.
Eseguire il training del modello
Dopo aver etichettato il set di dati, è possibile eseguire il training del modello. Selezionare il pulsante Training nell'angolo superiore destro.
Nella finestra di dialogo Esegui training del modello specificare un ID modello univoco e, facoltativamente, una descrizione. L'ID modello accetta un tipo di dati stringa.
Per la modalità di compilazione, selezionare il tipo di modello di cui si vuole eseguire il training. Altre informazioni sui tipi e sulle funzionalità del modello.
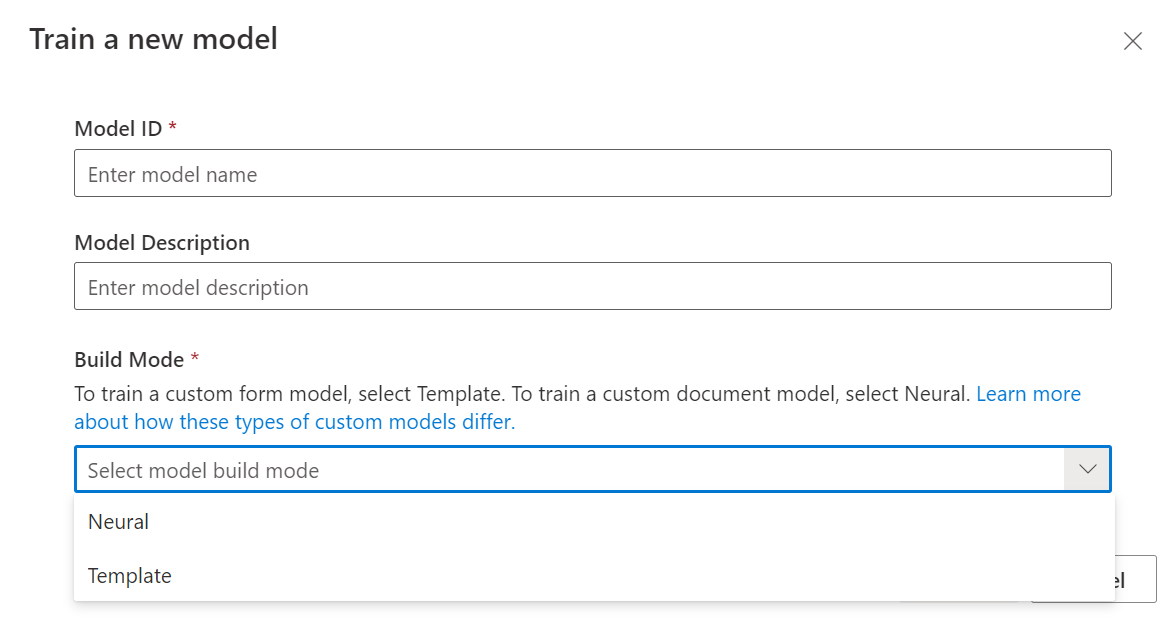
Selezionare Training per avviare il processo di training.
Il training dei modelli impiega pochi minuti. Il training dei modelli neurali può richiedere fino a 30 minuti.
Passare al menu modelli per visualizzare lo stato dell'operazione di training.
Test del modello
Al termine del training del modello, è possibile testare il modello selezionando il modello nella pagina dell'elenco dei modelli.
Selezionare il modello e selezionare il pulsante Test.
Selezionare il pulsante
+ Addper selezionare un file per testare il modello.Con un file selezionato, scegliere il pulsante Analizza per testare il modello.
I risultati del modello vengono visualizzati nella finestra principale e i campi estratti sono elencati nella barra di spostamento a destra.
Convalidare il modello valutando i risultati per ogni campo.
La barra di spostamento a destra include anche il codice di esempio per richiamare il modello e i risultati JSON dall'API.
Si è appreso come eseguire il training di un modello personalizzato nello Studio di Informazioni sui documenti. Il modello è pronto per l'uso con l'API REST o l'SDK per l'analisi dei documenti.
Si applica a:![]() v2.1.
Altre versioni:v3.0
v2.1.
Altre versioni:v3.0
Quando si usa il modello personalizzato di Informazioni sui documenti, si forniscono i propri dati di training all'operazione Training del modello personalizzato, affinché il modello possa eseguire il training dei moduli specifici del settore. Seguire questa guida per informazioni su come raccogliere e preparare i dati per eseguire il training del modello in modo efficace.
Sono necessari almeno cinque moduli completati dello stesso tipo.
Se si desidera usare dati di training etichettati manualmente, è necessario iniziare con almeno cinque moduli completati dello stesso tipo. È comunque possibile usare moduli non etichettati oltre al set di dati richiesto.
Requisiti di input per il modello personalizzato
Prima di tutto, assicurarsi che il set di dati di training segua i requisiti di input per Informazioni sui documenti.
Formati di file supportati:
| Modello | Immagine: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lettura | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Documento generale | ✔ | ✔ | |
| Predefinito | ✔ | ✔ | |
| Estrazione personalizzata | ✔ | ✔ | |
| Classificazione personalizzata | ✔ | ✔ | ✔ |
Per risultati ottimali, fornire una foto chiara o una scansione di alta qualità per ogni documento.
Per i formati PDF e TIFF, possono essere elaborate fino a 2.000 pagine (con una sottoscrizione di livello gratuito vengono elaborate solo le prime due pagine).
Le dimensioni del file per l'analisi dei documenti sono di 500 MB per il livello a pagamento (S0) e
4MB per il livello gratuito (F0).Per le immagini, le dimensioni devono essere comprese tra 50 x 50 pixel e 10.000 x 10.000 pixel.
Se i file PDF sono bloccati da password, è necessario rimuovere il blocco prima dell'invio.
L'altezza minima del testo da estrarre è di 12 pixel per un'immagine 1024 x 768 pixel. Queste dimensioni corrispondono approssimativamente a un testo con dimensioni di
8punti e 150 punti per pollice (DPI).Per il training di modelli personalizzati, il numero massimo di pagine per i dati di training è 500 per il modello personalizzato e 50.000 per il modello neurale personalizzato.
Per il training di modelli di estrazione personalizzati, le dimensioni totali dei dati di training sono di 50 MB per il modello e
1GB per il modello neurale.Per il training del modello di classificazione personalizzato, le dimensioni totali dei dati di training sono
1GB con un massimo di 10.000 pagine. Per 2024-11-30 (GA), le dimensioni totali dei dati di training sono2GB con un massimo di 10.000 pagine.
Suggerimenti per i dati di training
Seguire questi suggerimenti per ottimizzare ulteriormente il set di dati per il training.
- Utilizzare documenti PDF basati su testo anziché documenti basati su immagini. I PDF sottoposti a scansione vengono gestiti come immagini.
- Per i moduli completati, usare esempi con tutti i campi compilati.
- Usa moduli con valori diversi in ogni campo.
- Usare un set di dati di dimensioni maggiori (10-15 immagini) per i moduli completati.
Caricare i dati di training
Dopo aver raccolto il set di documenti per il training, è necessario caricarlo in un contenitore di archiviazione BLOB di Azure. Se non si sa come creare un account di archiviazione di Azure con un contenitore, seguire la guida di avvio rapido di Archiviazione di Azure per il portale di Azure. Usare il livello di prestazioni Standard.
Per usare dati etichettati manualmente, caricare i file .labels.json e .ocr.json corrispondenti ai documenti di training. Per generare questi file, è possibile usare lo strumento di etichettatura campioni (o l'interfaccia utente in uso).
Organizzare i dati in sottocartelle (facoltativo)
Per impostazione predefinita, l'API Training del modello personalizzato usa solo i documenti che si trovano nella radice del contenitore di archiviazione. Tuttavia, è possibile eseguire il training con i dati nelle sottocartelle se lo si specifica nella chiamata API. In genere, il corpo della chiamata Training del modello personalizzato ha il formato seguente, dove <SAS URL> è l'URL della firma di accesso condiviso del contenitore:
{
"source":"<SAS URL>"
}
Se si aggiunge il contenuto seguente al corpo della richiesta, l'API eseguirà il training con i documenti che si trovano nelle sottocartelle. Il campo "prefix" è facoltativo e limita il set di dati di training ai file i cui percorsi iniziano con la stringa specificata. Di conseguenza, un valore di "Test", ad esempio, farà in modo che l'API esamini solo i file o le cartelle che iniziano con la parola Test.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Passaggi successivi
Dopo aver appreso come creare un set di dati di training, seguire una guida introduttiva per eseguire il training di un modello di Informazioni sui documenti personalizzato e iniziare a usarlo nei moduli.