Eseguire il training di un modello personalizzato con lo strumento di etichettatura di esempio
Questo contenuto si applica a: ![]() v2.1.
v2.1.
Suggerimento
- Per un'esperienza e una qualità avanzate del modello, provare Document Intelligence v3.0 Studio.
- Studio v3.0 supporta qualsiasi modello sottoposto a training con dati con etichette v2.1.
- Per informazioni dettagliate sulla migrazione da v2.1 a v3.0, vedere la Guida alla migrazione delle API.
- Vedere le guide di avvio rapido relative ad API REST o SDK C#, Java, JavaScript o Python per iniziare a usare la versione 3.0.
In questo articolo si usa l'API REST di Document Intelligence con lo strumento di etichettatura campioni per eseguire il training di un modello personalizzato con dati etichettati manualmente.
Prerequisiti
Per completare questo progetto, sono necessarie le risorse seguenti:
- Sottoscrizione di Azure: creare un account gratuito
- Una volta in possesso della sottoscrizione di Azure, creare una risorsa Document Intelligence nel portale di Azure per ottenere la chiave e l'endpoint. Al termine della distribuzione, fare clic su Vai alla risorsa.
- La chiave e l'endpoint della risorsa creata saranno necessari per connettere l'applicazione all'API Informazioni sui documenti. La chiave e l'endpoint verranno incollati nel codice più avanti nell'avvio rapido.
- È possibile usare il piano tariffario gratuito (
F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione.
- Un set di almeno sei moduli dello stesso tipo. Questi dati vengono usati per eseguire il training del modello e testare un modulo. È possibile usare un set di dati di esempio (scaricare ed estrarre il file sample_data.zip) per questa guida di avvio rapido. Caricare i file di training nella radice di un contenitore di archiviazione BLOB in un account di archiviazione di Azure con livello di prestazioni Standard.
Creare una risorsa di Informazioni sui documenti
Andare al portale di Azure e creare una nuova risorsa Document Intelligence. Nel riquadro Crea specificare le informazioni seguenti:
| Dettagli di progetto | Descrizione |
|---|---|
| Abbonamento | Selezionare la sottoscrizione di Azure a cui è stato concesso l'accesso. |
| Gruppo di risorse | Il gruppo di risorse di Azure che contiene la risorsa. È possibile creare un nuovo gruppo o aggiungerla a un gruppo già esistente. |
| Area | La posizione della risorsa Servizi di Azure AI. Posizioni diverse possono introdurre latenza, ma non hanno alcun impatto sulla disponibilità di runtime della risorsa. |
| Nome | Nome per la risorsa. È consigliabile usare un nome descrittivo, ad esempio MyNameFormRecognizer. |
| Piano tariffario | Il costo della risorsa varia a seconda del piano tariffario selezionato e dell'utilizzo. Per altre informazioni, vedere i dettagli sui prezzi delle API. |
| Rivedi e crea | Selezionare il pulsante Rivedi e crea per distribuire la risorsa nel portale di Azure. |
Recuperare la chiave e l'endpoint
Quando la distribuzione della risorsa Document Intelligence termina, individuarla e selezionarla dall'elenco Tutte le risorse nel portale. La chiave e l'endpoint si trovano nella pagina Chiave ed endpoint della risorsa in Gestione risorse. Salvarli entrambi in un percorso temporaneo prima di procedere.
Prova
Provare lo Strumento di etichettatura campioni Document Intelligence online:
È necessaria una sottoscrizione di Azure (crearne una gratuitamente) e un endpoint della risorsa di Document Intelligence e una chiave per provare il servizio Document Intelligence.
Configurare lo strumento di etichettatura di esempio
Nota
Se i dati di archiviazione si trovano nell’ambito di una rete virtuale o protetti da un firewall, è necessario distribuire lo strumento di etichettatura campioni di Document Intelligence oltre la rete virtuale o il firewall e concedere l'accesso creando un'identità gestita assegnata dal sistema.
Per eseguire lo strumento di etichettatura di esempio, viene usato il motore Docker. Per configurare il contenitore Docker, seguire questa procedura. Per una panoramica dei concetti fondamentali relativi a Docker e ai contenitori, vedere Docker overview (Panoramica di Docker).
Suggerimento
È inoltre disponibile lo strumento OCR Form Labeling Tool come progetto open source in GitHub. Si tratta di un'applicazione Web TypeScript creata con React + Redux. Per altre informazioni o per contribuire, vedere il repository dello strumento OCR Form Labeling Tool. Per provare lo strumento online, andare al sito Web strumento di etichettatura campioni di Document Intelligence.
Installare prima di tutto Docker in un computer host. Questa guida illustra come usare un computer locale come host. Se si vuole usare un servizio di hosting Docker in Azure, vedere la guida pratica Distribuire lo strumento di etichettatura di esempio.
Il computer host deve soddisfare i requisiti hardware seguenti:
Contenitore Requisiti minimi Requisiti consigliati Strumento di etichettatura di esempio 2core, 4 GB di memoria4core, 8 GB di memoriaInstallare Docker nel computer seguendo le istruzioni appropriate per il sistema operativo in uso:
Ottenere il contenitore dello strumento di etichettatura di esempio con il comando
docker pull.docker pull mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1Ora è possibile eseguire il contenitore con
docker run.docker run -it -p 3000:80 mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1 eula=acceptQuesto comando rende disponibile lo strumento di etichettatura di esempio tramite un Web browser. Vai a
http://localhost:3000.
Nota
È inoltre possibile etichettare documenti ed eseguire il training dei modelli usando l'API REST di Document Intelligence. Per eseguire il training e l'analisi con l'API REST, vedere Eseguire il training con le etichette usando l'API REST e Python.
Configurare i dati di input
Prima di tutto, assicurarsi che tutti i documenti di training abbiano lo stesso formato. Se si usano moduli in più formati, organizzarli in sottocartelle basate sul formato comune. Quando si esegue il training, è necessario indirizzare l'API a una sottocartella.
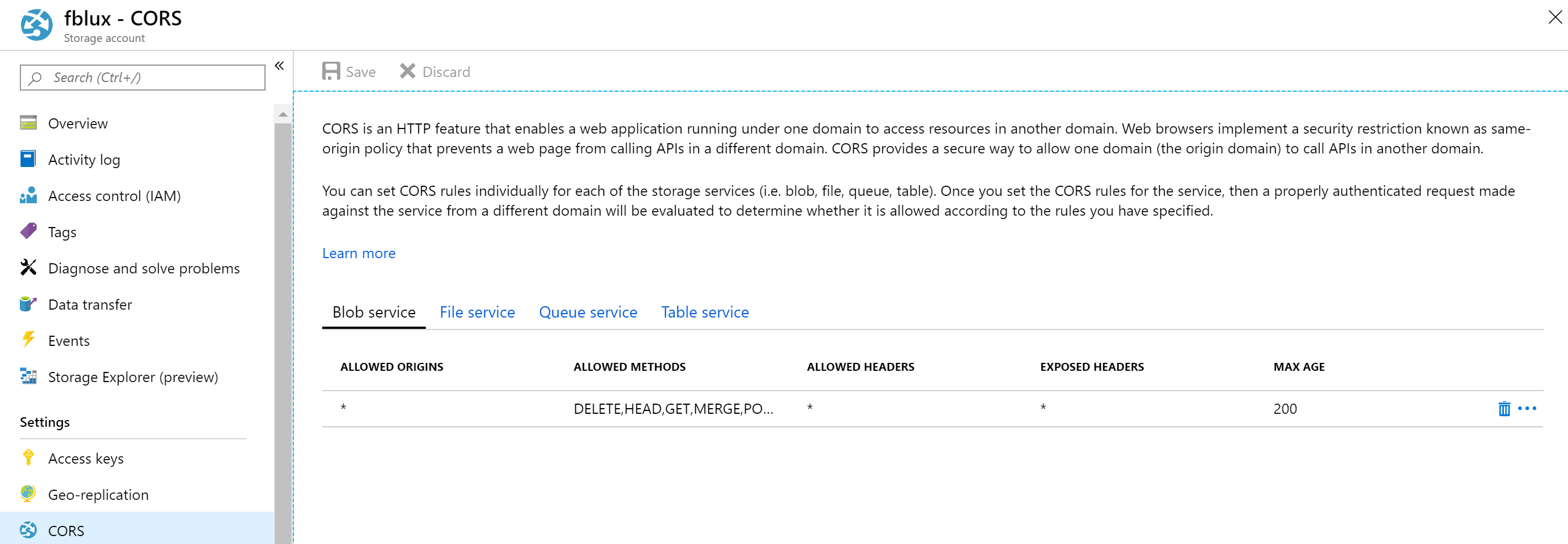
Configurare la condivisione di risorse tra domini (CORS)
Abilitare CORS nell'account di archiviazione. Selezionare l'account di archiviazione nel portale di Azure e quindi scegliere la scheda CORS nel riquadro sinistro. Nella riga inferiore inserire i valori seguenti. Seleziona Salva in alto.
- Origini consentite = *
- Metodi consentiti = [seleziona tutto]
- Intestazioni consentite = *
- Intestazioni esposte = *
- Età massima = 200
Connettere lo strumento di etichettatura di esempio
Lo strumento di etichettatura di esempio si connette a un'origine (i moduli originali caricati) e a una destinazione (le etichette create e i dati di output).
Le connessioni possono essere configurate e condivise tra progetti. Si basano su un modello di provider estendibile, quindi è possibile aggiungere facilmente nuovi provider di origine/destinazione.
Per creare una nuova connessione, selezionare l'icona Nuove connessioni (spina) sulla barra di spostamento sinistra.
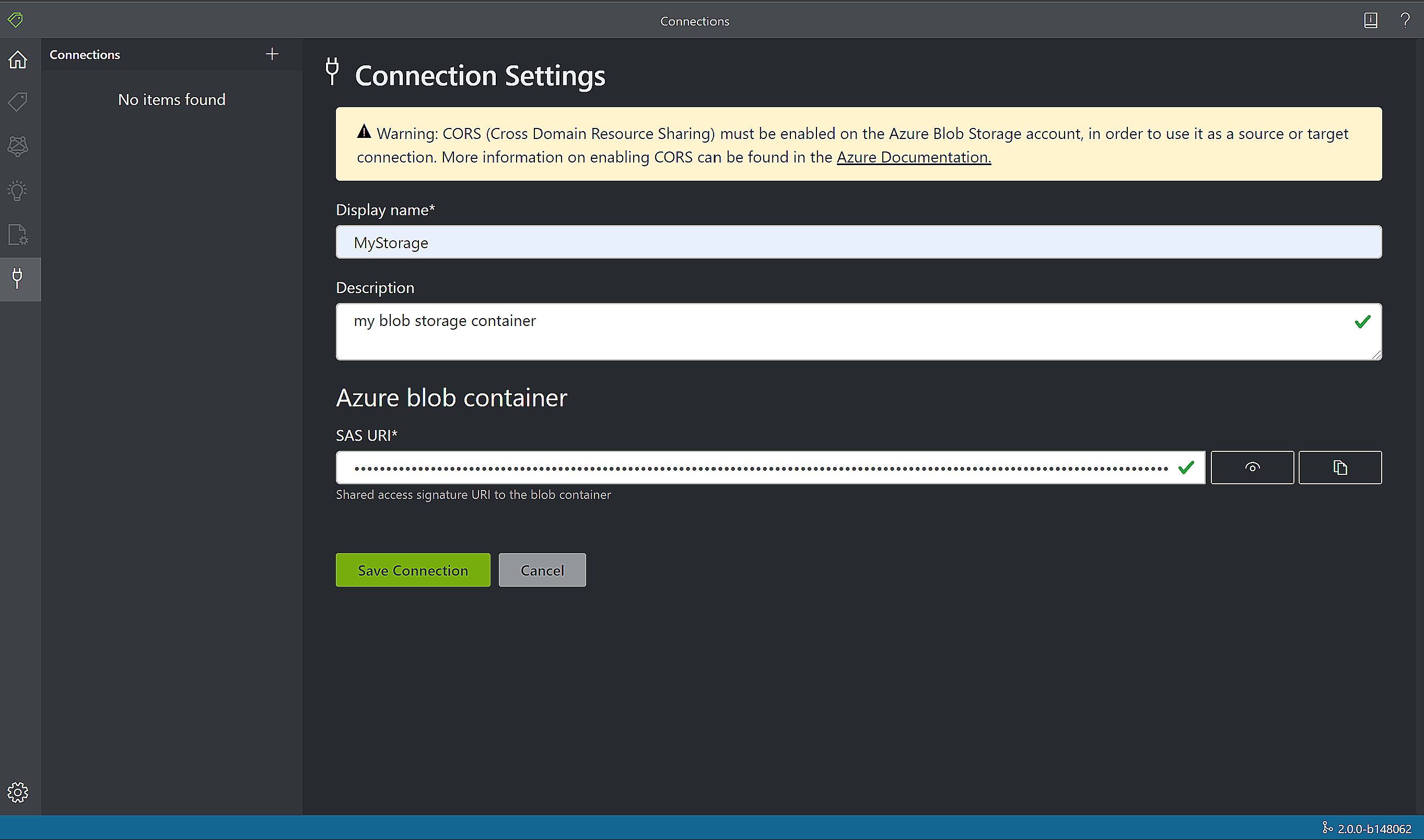
Compilare i campi con i valori seguenti:
Nome visualizzato: il nome visualizzato della connessione.
Descrizione: la descrizione del progetto.
URL di firma di accesso condiviso: l'URL di firma di accesso condiviso del contenitore di archiviazione BLOB di Azure. Per recuperare l'URL di firma di accesso condiviso per i dati di training del modello personalizzato, passare alla risorsa di archiviazione nel portale di Azure e selezionare la scheda Storage Explorer. Passare al contenitore, fare clic con il pulsante destro del mouse e scegliere Ottieni firma di accesso condiviso. È importante ottenere la firma di accesso condiviso per il contenitore, non per l'account di archiviazione. Assicurarsi che le autorizzazioni Lettura, Scrittura, Eliminazione ed Elenco siano selezionate e fare clic su Crea. A questo punto, copiare il valore dalla sezione URL in una posizione temporanea. Dovrebbe essere in questo formato:
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>.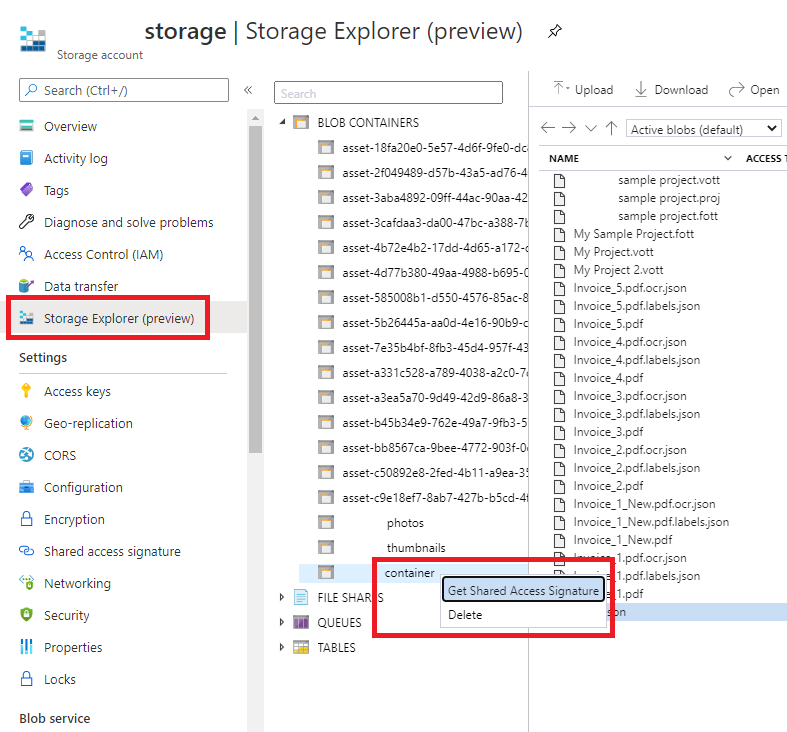
Crea un nuovo progetto
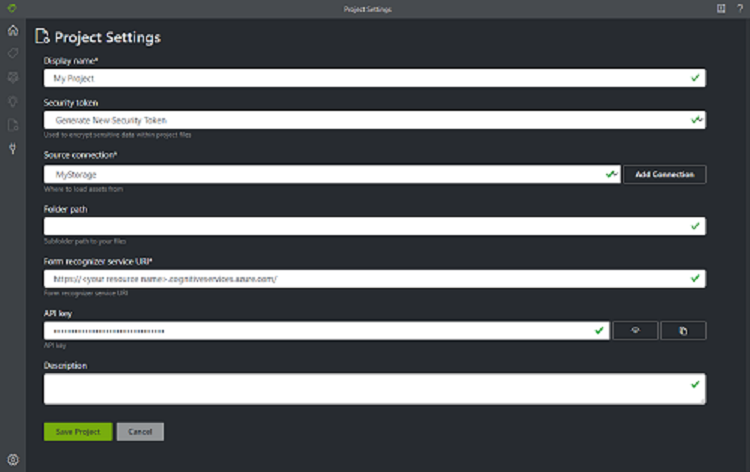
Nello strumento di etichettatura di esempio vengono archiviate le configurazioni e le impostazioni dei progetti. Creare un nuovo progetto e compilare i campi con i valori seguenti:
- Nome visualizzato: il nome visualizzato del progetto
- Token di sicurezza: alcune impostazioni del progetto possono includere valori sensibili, ad esempio chiavi o altri segreti condivisi. Ogni progetto genera un token di sicurezza che è possibile usare per crittografare/decrittografare le impostazioni sensibili del progetto. I token di sicurezza si trovano nelle Impostazioni applicazione, selezionando l'icona dell'ingranaggio nella parte inferiore della barra di spostamento sinistra.
- Connessione protetta: la connessione ad archiviazione BLOB di Azure creata nel passaggio precedente che si vuole usare per questo progetto.
- Percorso cartella (facoltativo): se i moduli di origine si trovano in una cartella del contenitore BLOB, specificare qui il relativo nome
- URI del servizio di Document Intelligence: URL dell'endpoint di Document Intelligence.
- Chiave: chiave di Document Intelligence.
- Descrizione (facoltativo): la descrizione del progetto
Etichettare i moduli
Quando si crea o si apre un progetto, viene visualizzata la finestra principale dell'editor di tag. L'editor di tag è costituito da tre parti:
- Un riquadro ridimensionabile v3.0 che contiene un elenco scorrevole di moduli provenienti dalla connessione di origine.
- Il riquadro principale dell'editor che consente di applicare tag.
- Il riquadro dell'editor di tag che consente di modificare, bloccare, riordinare ed eliminare tag.
Identificare testo e tabelle
Selezionare Esegui layout su documenti non visitati nel riquadro sinistro per ottenere le informazioni sul layout del testo e della tabella per ogni documento. Lo strumento di etichettatura disegna rettangoli di selezione intorno a ogni elemento di testo.
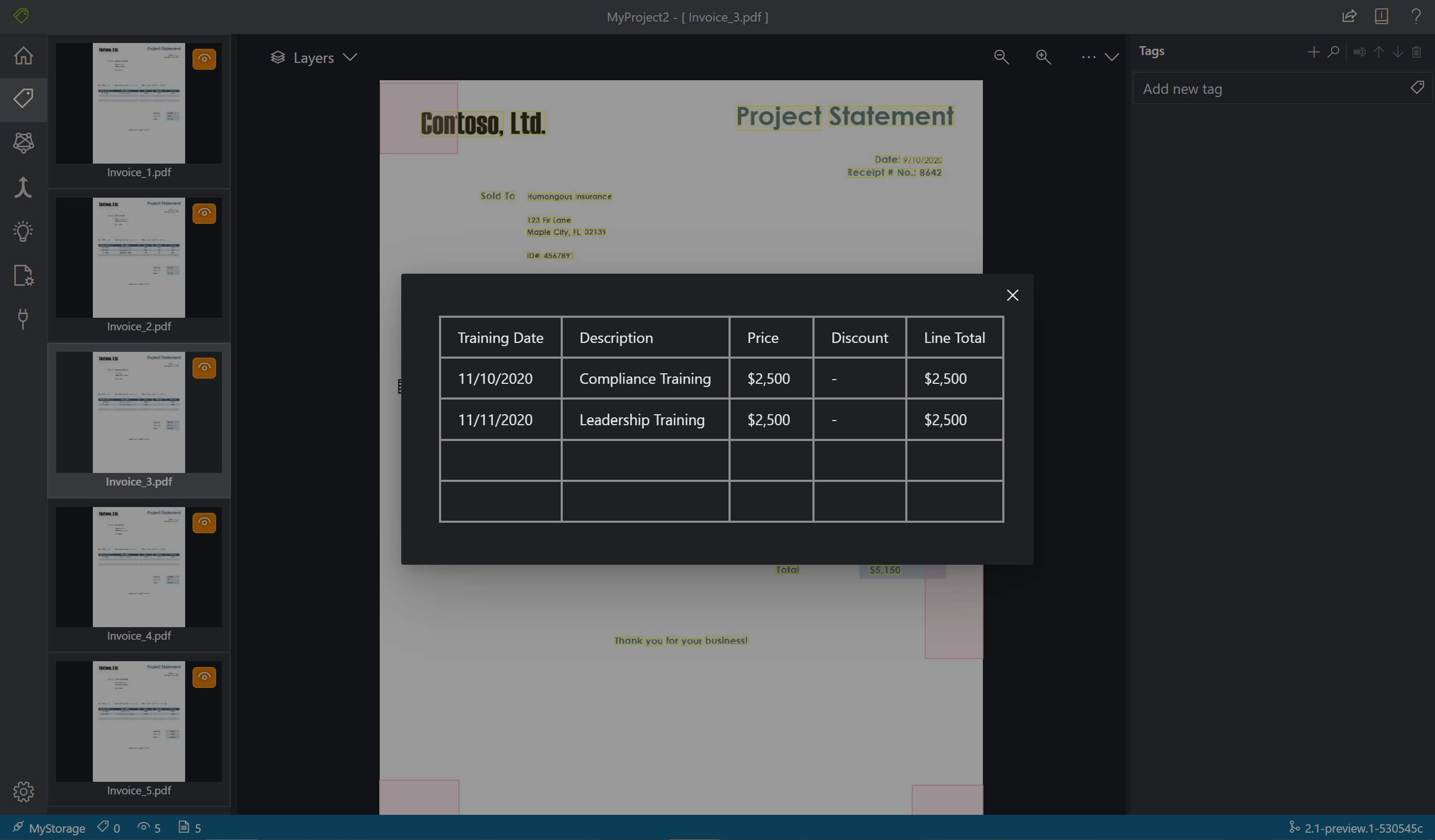
Lo strumento di etichettatura mostra anche quali tabelle sono state estratte automaticamente. Selezionare l'icona della tabella o della griglia sul lato sinistro del documento per visualizzare la tabella estratta. In questa guida di avvio rapido il contenuto della tabella, poiché viene estratto automaticamente, non viene etichettato, ma ci si basa sull'estrazione automatica.
Nella versione 2.1, se il documento di training non contiene un valore compilato, è possibile disegnare una riquadro al posto del valore. Usare Disegna area nell'angolo in alto a sinistra della finestra per contrassegnare l'area con tag.
Applicare le etichette al testo
Creare quindi i tag (etichette) e applicarli agli elementi di testo che dovranno essere analizzati dal modello.
- Usare prima di tutto il riquadro dell'editor di tag per creare i tag da identificare.
- Selezionare + per creare un nuovo tag.
- Immettere il nome del tag.
- Premere INVIO per salvare il tag.
- Nell'editor principale selezionare le parole dagli elementi di testo evidenziati o dall'area disegnata.
- Selezionare il tag da applicare oppure premere il tasto corrispondente della tastiera. I tasti numerici vengono assegnati come tasti di scelta rapida per i primi 10 tag. È possibile riordinare i tag usando le icone delle frecce su e giù nel riquadro dell'editor di tag.
- Seguire questi passaggi per etichettare almeno cinque moduli.
Suggerimento
Per l'etichettatura dei moduli, tenere presenti i suggerimenti seguenti:
- È possibile applicare un unico tag a ogni elemento di testo selezionato.
- Ogni tag può essere applicato una sola volta per pagina. Se un valore viene visualizzato più volte nella stessa pagina, creare tag diversi per ogni istanza. Ad esempio: "invoice# 1", "invoice# 2" e così via.
- I tag non possono estendersi in più pagine.
- Etichettare i valori così come appaiono nel modulo. Non provare a dividere un valore in due parti con due tag diversi. Ad esempio, un campo di indirizzo deve essere etichettato con un singolo tag anche se si estende su più righe.
- Non includere le chiavi nei campi etichettati, ma solo i valori.
- I dati delle tabelle dovrebbero essere rilevati automaticamente e saranno disponibili nel file JSON finale di output. Tuttavia, se il modello non riesce a rilevare tutti i dati di una tabella, è anche possibile etichettare manualmente questi campi. Assegnare un'etichetta diversa a ogni cella della tabella. Se i moduli includono tabelle con un numero variabile di righe, assicurarsi di etichettare almeno un modulo con la tabella più grande possibile.
- Usare i pulsanti a destra del segno + per cercare, rinominare, riordinare ed eliminare i tag.
- Per rimuovere un tag applicato senza eliminarlo, selezionare il rettangolo con tag nella visualizzazione del documento e premere CANC.
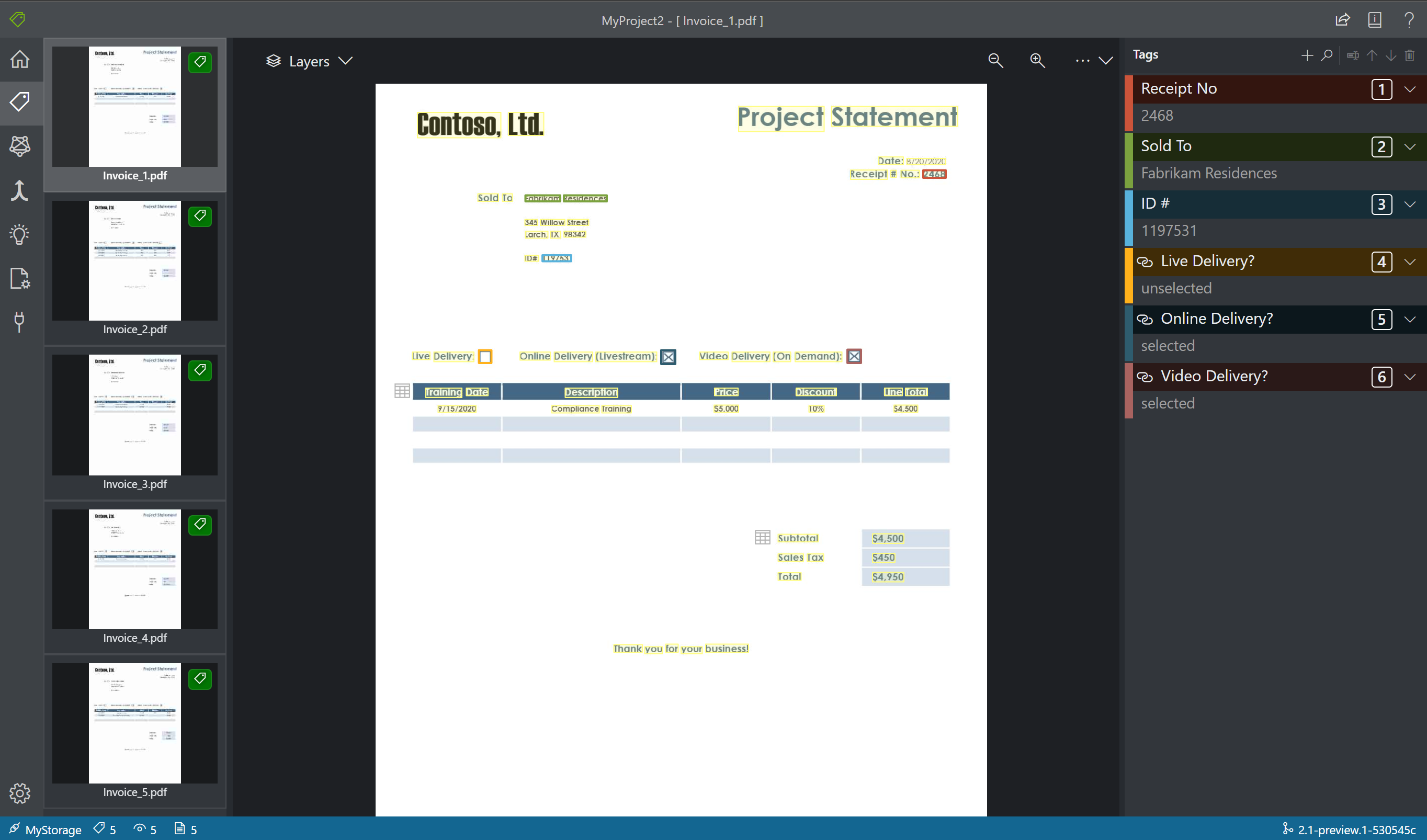
Specificare i tipi di valore di tag
È possibile impostare il tipo di dati previsto per ogni tag. Aprire il menu di scelta rapida a destra di un tag e selezionare un tipo dal menu. Questa funzionalità consente all'algoritmo di rilevamento di formulare ipotesi che migliorano l'accuratezza del rilevamento del testo. Garantisce inoltre che i valori rilevati vengano restituiti in un formato standardizzato nell'output JSON finale. Le informazioni sul tipo di valore vengono salvate nel file fields.json nello stesso percorso dei file di etichette.
Sono attualmente supportati i tipi di valore e le varianti seguenti:
string- predefinito,
no-whitespaces,alphanumeric
- predefinito,
number- predefinito,
currency - Formattato come valore a virgola mobile.
- Esempio: 1234.98 nel documento è formattato in 1234.98 nell'output
- predefinito,
date- predefinito,
dmy,mdy,ymd
- predefinito,
timeinteger- Formattato come valore intero.
- Esempio: 1234.98 nel documento è formattato in 123498 nell'output
selectionMark
Nota
Vedere queste regole per la formattazione della data:
Per il corretto funzionamento della formattazione della data, è necessario specificare un formato (dmy, mdy, ymd).
I seguenti caratteri possono essere utilizzati come delimitatori di data: , - / . \. Non è possibile usare uno spazio come delimitatore. Ad esempio:
- 01,01,2020
- 01-01-2020
- 01/01/2020
Il giorno e il mese possono essere scritti ciascuno come una o due cifre e l'anno può essere due o quattro cifre:
- 1-1-2020
- 1-01-20
Se una stringa di data ha otto cifre, il delimitatore è facoltativo:
- 01012020
- 01 01 2020
Il mese può anche essere scritto come nome completo o breve. Se viene utilizzato il nome, i caratteri delimitatori sono facoltativi. Tuttavia, questo formato potrebbe essere riconosciuto in modo meno accurato rispetto ad altri.
- 01/Gen/2020
- 01Gen2020
- 01 Gen 2020
Etichettare le tabelle (solo v2.1)
A volte, i dati si prestano meglio a essere etichettati come tabelle piuttosto che come coppie chiave-valore. In questo caso, è possibile creare un tag di tabella selezionando Aggiungi un nuovo tag di tabella. Specificare se la tabella ha un numero fisso di righe o un numero variabile di righe a seconda del documento e definire lo schema.
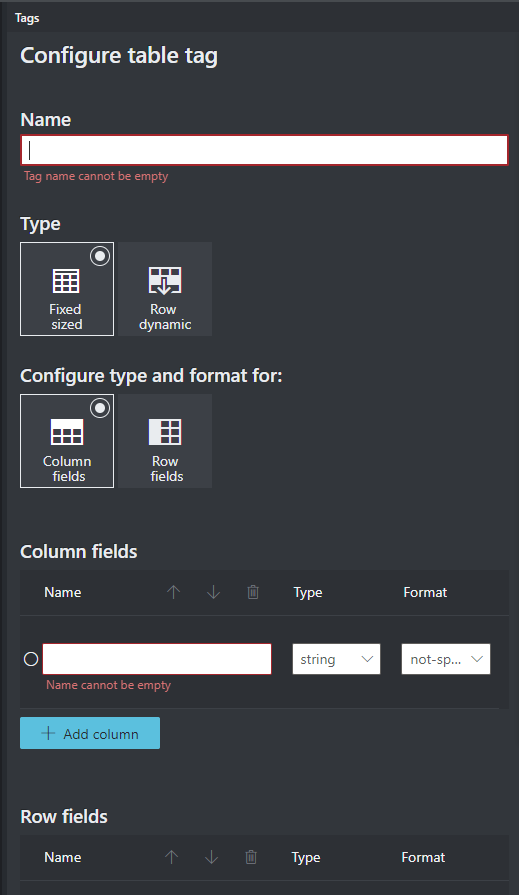
Dopo aver definito il tag di tabella, contrassegnare i valori delle celle.
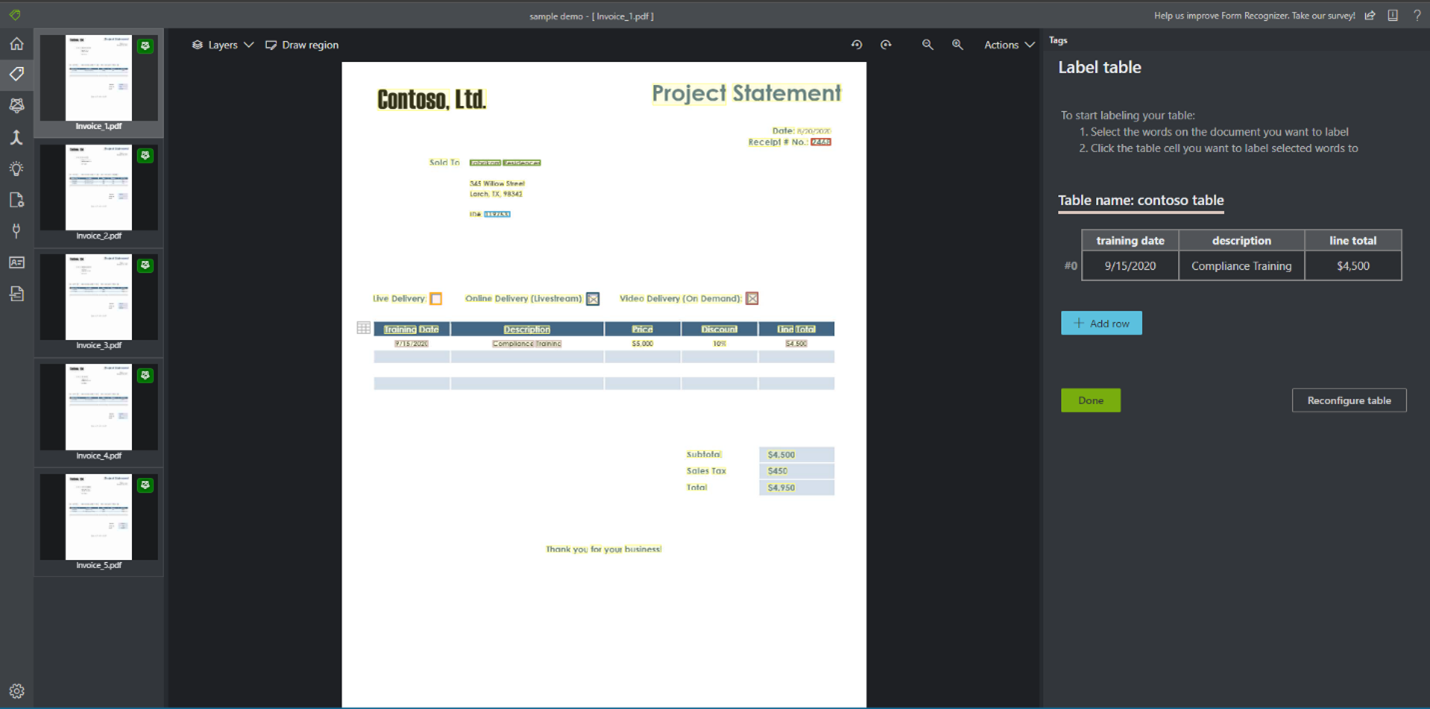
Eseguire il training di un modello personalizzato
Scegliere l'icona del training nel riquadro sinistro per aprire la pagina corrispondente. Quindi selezionare il pulsante Training per iniziare il training del modello. Al termine del processo di training, vengono visualizzate le informazioni seguenti:
- ID modello: l'ID del modello creato e sottoposto a training. Ogni chiamata al training crea un nuovo modello con un proprio ID. Copiare questa stringa in un posto sicuro, perché è necessaria per eseguire le chiamate di previsione tramite l'API REST o la guida della libreria client.
- Average Accuracy (Accuratezza media): l'accuratezza media del modello. È possibile migliorare l'accuratezza del modello aggiungendo ed etichettando altri moduli, quindi eseguendo di nuovo il training per creare un nuovo modello. Per iniziare, è consigliabile etichettare cinque moduli ed aggiungerne altri se necessario.
- L'elenco dei tag e l'accuratezza stimata per ognuno.
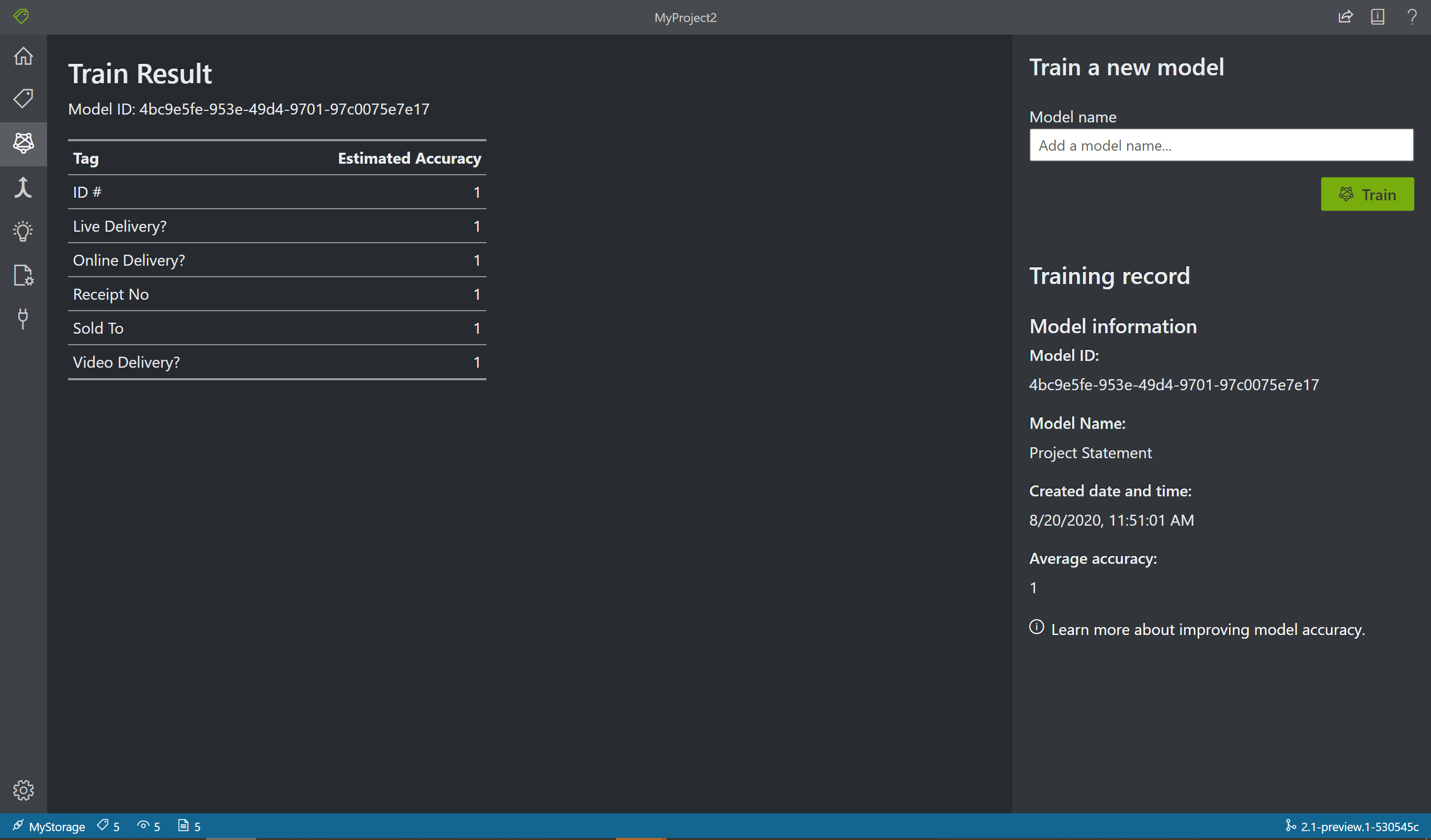
Al termine del training, esaminare il valore di Average Accuracy (Accuratezza media). Se è basso, è necessario aggiungere altri documenti di input e ripetere i passaggi di etichettatura. I documenti già etichettati rimangono nell'indice del progetto.
Suggerimento
È anche possibile eseguire il processo di training con una chiamata API REST. Per informazioni su come eseguire questa operazione, vedere Eseguire il training con le etichette usando Python.
Comporre modelli con training
Con lo strumento di composizione modelli è possibile comporre fino a 200 modelli in un solo ID modello. Quando si esegue l'analisi con l'oggetto modelID composto, Document Intelligence classifica il modulo inviato, sceglie il modello più corrispondente e quindi restituisce i risultati per tale modello. Questa operazione è utile nel caso in cui i moduli in ingresso appartengano a uno dei diversi modelli.
- Per comporre modelli nello strumento di etichettatura di esempio, selezionare l'icona a forma di freccia di unione dello strumento di composizione modelli dalla barra di spostamento.
- Selezionare i modelli da comporre insieme. I modelli contrassegnati con l'icona della freccia sono già composti.
- Scegliere il pulsante Componi. Nella finestra popup assegnare un nome al nuovo modello composto e selezionare Componi.
- Al termine dell'operazione, il nuovo modello composto verrà visualizzato nell'elenco.
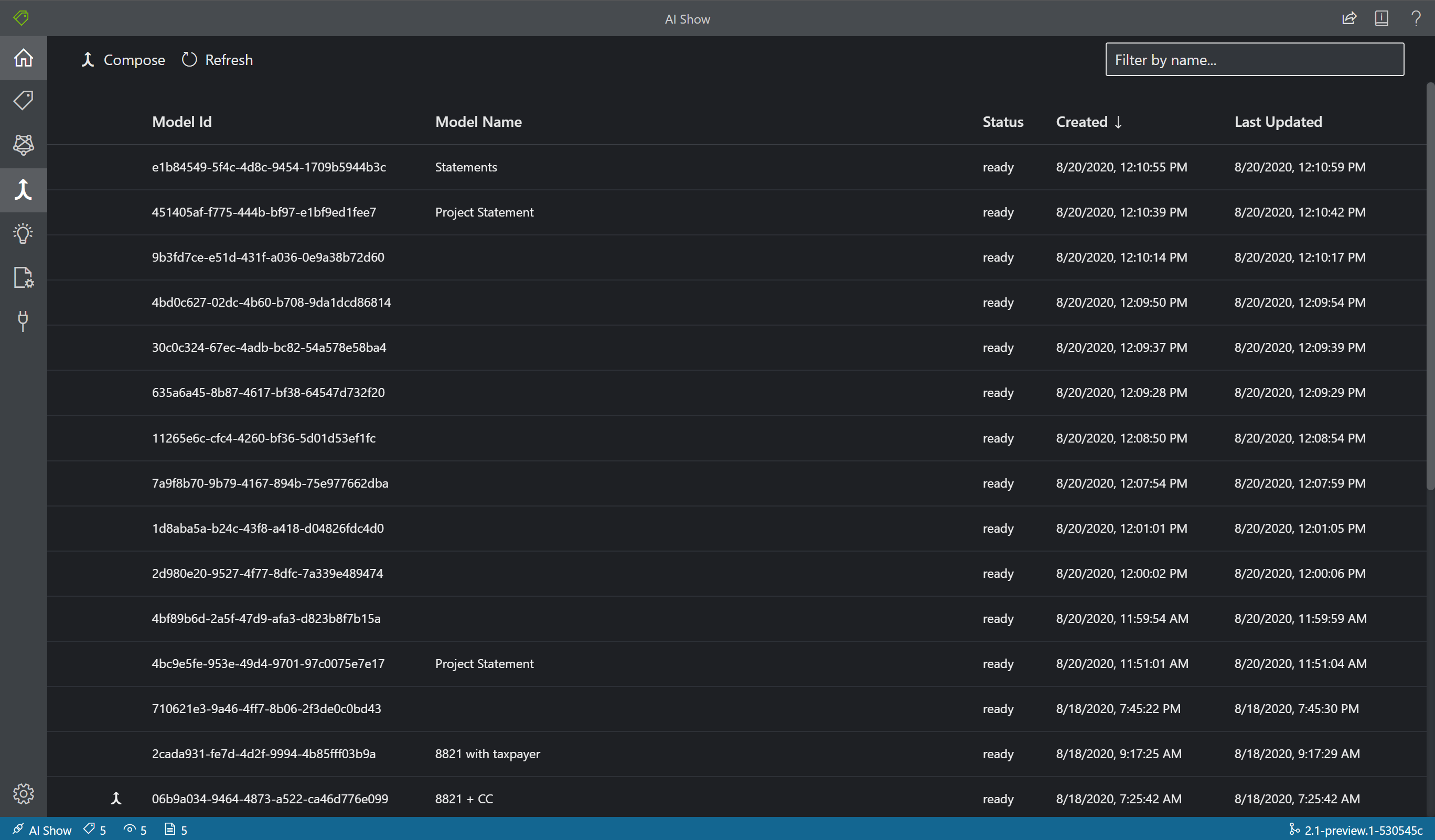
Analizzare un modulo
Selezionare l'icona Analizza nella barra di spostamento per testare il modello. Selezionare il File locale di origine. Cercare un file da selezionare dal set di dati di esempio decompresso nella cartella di test. Scegliere quindi il pulsante Esegui analisi per ottenere le previsioni di coppie chiave/valore, testo e tabelle per il modulo. Lo strumento applica i tag nei riquadri di selezione e segnala l'attendibilità di ognuno.
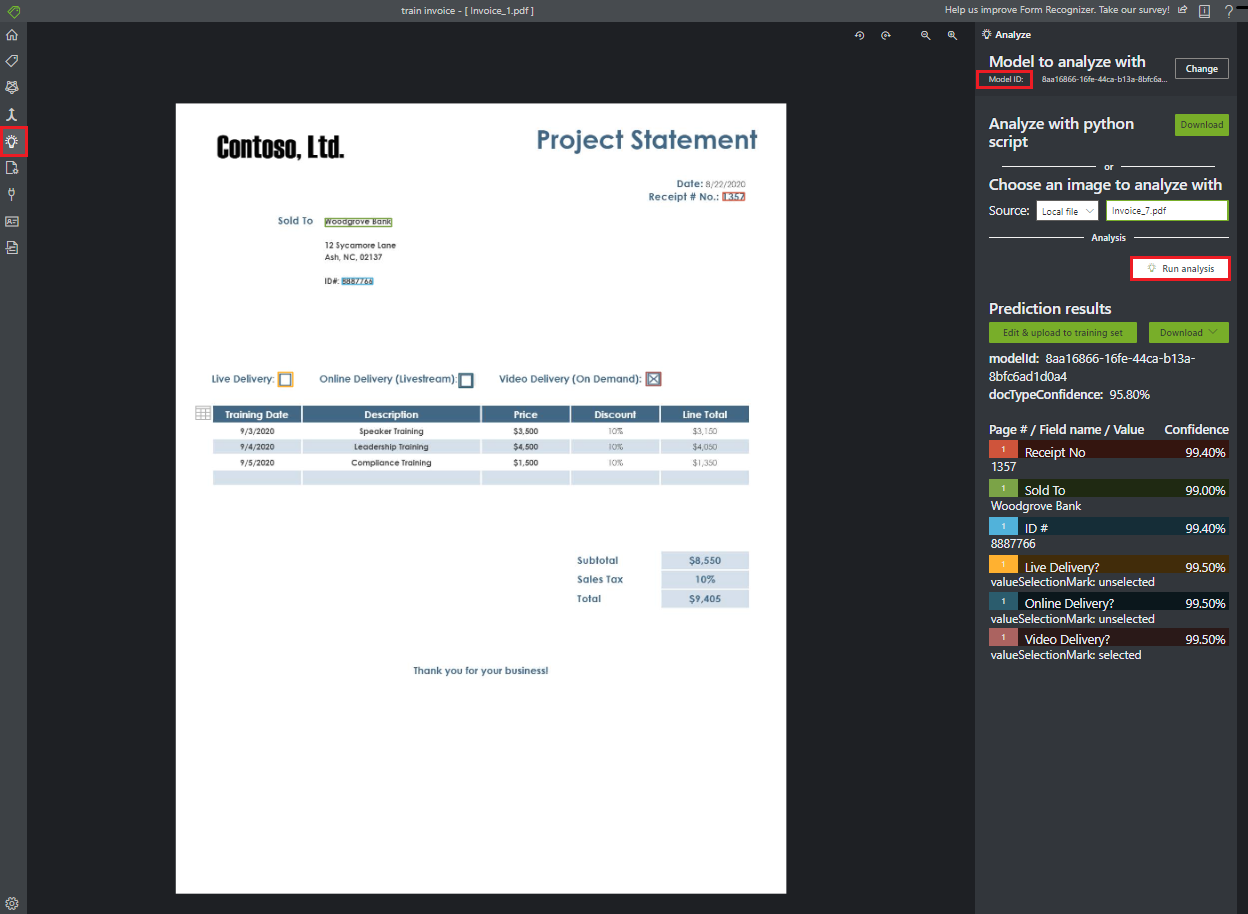
Suggerimento
È anche possibile eseguire l'API di analisi con una chiamata REST. Per informazioni su come eseguire questa operazione, vedere Eseguire il training con le etichette usando Python.
Migliorare i risultati
A seconda dell'accuratezza indicata, è possibile scegliere di eseguire ulteriori processi di training per migliorare il modello. Dopo aver eseguito una previsione, esaminare i valori di attendibilità per ognuno dei tag applicati. Se il valore dell'accuratezza media del training è alto, ma i punteggi di attendibilità sono bassi (o i risultati non sono accurati), aggiungere il file di previsione al set di training, etichettarlo e ripetere il training.
L'accuratezza media indicata, i punteggi di attendibilità e l'accuratezza effettiva possono essere incoerenti se i documenti analizzati sono diversi da quelli usati per il training. Tenere presente che alcuni documenti hanno un aspetto simile quando vengono visualizzati dalle persone ma sembrano diversi per il modello di intelligenza artificiale. Ad esempio, è possibile eseguire il training con un tipo di modulo con due varianti, in cui il set di training è costituito per il 20% dalla variante A e per l'80% dalla variante B. Durante la previsione, è probabile che i punteggi di attendibilità per i documenti della variante A siano inferiori.
Salvare un progetto e riprenderlo in seguito
Per riprendere il progetto in un secondo momento o in un altro browser, è necessario salvare il relativo token di sicurezza e reimmetterlo in seguito.
Ottenere le credenziali del progetto
Passare alla pagina delle impostazioni del progetto (icona del dispositivo di scorrimento) e prendere nota del nome del token di sicurezza. Passare quindi alle impostazioni dell'applicazione (icona dell'ingranaggio), che visualizzano tutti i token di sicurezza nell'istanza del browser corrente. Trovare il token di sicurezza del progetto e copiarne il nome e il valore della chiave in un posto sicuro.
Ripristinare le credenziali del progetto
Quando si vuole riprendere il progetto, è prima di tutto necessario creare una connessione allo stesso contenitore di archiviazione BLOB. A tale scopo, ripetere i passaggi. Quindi, passare alla pagina di impostazioni dell'applicazione (icona dell'ingranaggio) e verificare se il token di sicurezza del progetto è presente. Se non lo è, aggiungere un nuovo token di sicurezza e sovrascrivere il nome e la chiave del token del passaggio precedente. Selezionare Salva per conservare le impostazioni.
Riprendere un progetto
Infine, passare alla pagina principale (icona della casa) e selezionare Apri progetto cloud. Selezionare quindi la connessione all'archiviazione BLOB e il file .fott del progetto. L'applicazione carica tutte le impostazioni del progetto perché contiene il token di sicurezza.
Passaggi successivi
In questo argomento di avvio rapido si è appreso come usare lo strumento di etichettatura di esempio di Document Intelligence per eseguire il training di un modello con dati etichettati manualmente. Per creare un'utilità personalizzata per etichettare i dati di training, usare le API REST relative ai dati di training etichettati.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per