Supporto di documenti nativi per Il linguaggio di intelligenza artificiale di Azure (anteprima)
Importante
Il supporto dei documenti nativi è un'anteprima controllata. Per richiedere l'accesso alla funzionalità di supporto dei documenti nativi, completare e inviare il modulo Applica per l'accesso alle anteprime del servizio di linguaggio.
Le versioni di anteprima pubblica del linguaggio di intelligenza artificiale di Azure offrono l'accesso anticipato alle funzionalità in fase di sviluppo attivo.
Le funzionalità, gli approcci e i processi possono cambiare, prima della disponibilità generale, in base al feedback degli utenti.
Il linguaggio di intelligenza artificiale di Azure è un servizio basato sul cloud che applica le funzionalità di elaborazione del linguaggio naturale ai dati basati su testo. La funzionalità di supporto del documento nativo consente di inviare richieste API in modo asincrono, usando un corpo della richiesta HTTP POST per inviare i dati e la stringa di query di richiesta HTTP GET per recuperare i dati elaborati.
Un documento nativo fa riferimento al formato di file usato per creare il documento originale, ad esempio Microsoft Word (docx) o un file di documento portatile (pdf). Il supporto nativo dei documenti elimina la necessità di pre-elaborazione del testo prima di usare le funzionalità delle risorse del linguaggio di intelligenza artificiale di Azure. Attualmente, il supporto per i documenti nativi è disponibile per le funzionalità seguenti:
Informazioni personali. La funzionalità di rilevamento delle informazioni personali consente di identificare, classificare e redattire le informazioni riservate in testo non strutturato. L'API supporta l'elaborazione
PiiEntityRecognitionnativa dei documenti.Riepilogo dei documenti. Il riepilogo dei documenti usa l'elaborazione del linguaggio naturale per generare riepiloghi estrattivi (estrazione di frasi salienti) o astrattivi (estrazione di parole contestuali) per i documenti. Entrambe
AbstractiveSummarizationleExtractiveSummarizationAPI supportano l'elaborazione di documenti nativi.
Formati di documento supportati
Le applicazioni usano formati di file nativi per creare, salvare o aprire documenti nativi. Attualmente le funzionalità di riepilogo delle informazioni personali e dei documenti supportano i formati di documento nativi seguenti:
| Tipo di file | Estensione di file | Descrizione |
|---|---|---|
| Testo | .txt |
Documento di testo non formattato. |
| Adobe PDF | .pdf |
Documento formattato con file di documento portabile. |
| Microsoft Word | .docx |
Un file di documento di Microsoft Word. |
Linee guida per l'input
Formati di file supportati
| Type | supporto e limitazioni |
|---|---|
| I PDF a scansione completa non sono supportati. | |
| Testo all'interno delle immagini | Le immagini digitali con testo in formato imbeded non sono supportate. |
| Tabelle digitali | Le tabelle nei documenti analizzati non sono supportate. |
Dimensioni documento
| Attributo | Limite di input |
|---|---|
| Numero totale di documenti per richiesta | ≤ 20 |
| Dimensioni totali del contenuto per richiesta | ≤ 1 MB |
Includere documenti nativi con una richiesta HTTP
Iniziamo:
Per questo progetto viene usato lo strumento da riga di comando cURL per effettuare chiamate API REST.
Nota
Il pacchetto cURL è preinstallato nella maggior parte delle distribuzioni di Windows 10 e Windows 11 e della maggior parte delle distribuzioni macOS e Linux. È possibile controllare la versione del pacchetto con i comandi seguenti: Windows:
curl.exe -VmacOScurl -VLinux:curl --versionSe cURL non è installato, ecco i collegamenti di installazione per la piattaforma:
Un account Azure attivo. Se non si ha un account, è possibile crearne uno gratuito.
Un account di Archiviazione BLOB di Azure. È anche necessario creare contenitori nell'account Archiviazione BLOB di Azure per i file di origine e di destinazione:
- Contenitore di origine. Questo contenitore consente di caricare i file nativi per l'analisi (obbligatorio).
- Contenitore di destinazione. Questo contenitore è il percorso in cui vengono archiviati i file analizzati (obbligatorio).
Una risorsa del linguaggio a servizio singolo (non una risorsa di Servizi di intelligenza artificiale di Azure multiservizio):
Completare i campi Dei dettagli del progetto di risorse lingua e dell'istanza come indicato di seguito:
Sottoscrizione. Selezionare una delle sottoscrizioni di Azure disponibili.
Gruppo di risorse. È possibile creare un nuovo gruppo di risorse o aggiungere la risorsa a un gruppo di risorse preesistente che condivide lo stesso ciclo di vita, autorizzazioni e criteri.
Area risorse. Scegliere Globale a meno che l'azienda o l'applicazione non richieda un'area specifica. Se si prevede di usare un'identità gestita assegnata dal sistema per l'autenticazione, scegliere un'area geografica come Stati Uniti occidentali.
Nome. Immettere il nome scelto per la risorsa. Il nome scelto deve essere univoco all'interno di Azure.
Piano tariffario. È possibile usare il piano tariffario gratuito (
Free F0) per provare il servizio ed eseguire in un secondo momento l'aggiornamento a un livello a pagamento per la produzione.Selezionare Rivedi e crea.
Esaminare le condizioni del servizio e selezionare Crea per distribuire la risorsa.
Dopo la distribuzione della risorsa, selezionare Vai alla risorsa.
Recuperare la chiave e l'endpoint del servizio di linguaggio
Le richieste al servizio lingua richiedono una chiave di sola lettura e un endpoint personalizzato per autenticare l'accesso.
Se è stata creata una nuova risorsa, dopo la distribuzione selezionare Vai alla risorsa. Se si dispone di una risorsa del servizio linguistico esistente, passare direttamente alla pagina della risorsa.
Nella barra sinistra, in Gestione risorse, selezionare Chiavi ed endpoint.
È possibile copiare e incollare
keyelanguage service instance endpointnegli esempi di codice per autenticare la richiesta al servizio di linguaggio. Per effettuare una chiamata API è necessaria una sola chiave.
Creare contenitori Archiviazione BLOB di Azure
Creare contenitori nell'account Archiviazione BLOB di Azure per i file di origine e di destinazione.
- Contenitore di origine. Questo contenitore consente di caricare i file nativi per l'analisi (obbligatorio).
- Contenitore di destinazione. Questo contenitore è il percorso in cui vengono archiviati i file analizzati (obbligatorio).
Autenticazione
Per poter creare, leggere o eliminare BLOB, è necessario concedere all'account di archiviazione l'accesso alla risorsa di linguaggio. Esistono due metodi principali che è possibile usare per concedere l'accesso ai dati di archiviazione:
Token di firma di accesso condiviso . I token di firma di accesso condiviso della delega utente sono protetti con le credenziali di Microsoft Entra. I token di firma di accesso condiviso forniscono accesso sicuro e delegato alle risorse nell'account di archiviazione di Azure.
Controllo degli accessi in base al ruolo dell'identità gestita. Le identità gestite per le risorse di Azure sono entità servizio che creano un'identità Microsoft Entra e autorizzazioni specifiche per le risorse gestite di Azure.
Per questo progetto, l'accesso source location agli URL e target location viene autenticato con token di firma di accesso condiviso (SAS) aggiunti come stringhe di query. Ogni token viene assegnato a un BLOB specifico (file).

- Il contenitore o il BLOB di origine devono designare l'accesso in lettura ed elenco .
- Il contenitore o il BLOB di destinazione devono designare l'accesso in scrittura ed elenco .
Suggerimento
Poiché si sta elaborando un singolo file (BLOB), è consigliabile delegare l'accesso sas a livello di BLOB.
Intestazioni e parametri della richiesta
| parameter | Descrizione |
|---|---|
-X POST <endpoint> |
Specifica l'endpoint della risorsa lingua per l'accesso all'API. |
--header Content-Type: application/json |
Il tipo di contenuto per l'invio di dati JSON. |
--header "Ocp-Apim-Subscription-Key:<key> |
Specifica la chiave della risorsa lingua per l'accesso all'API. |
-data |
File JSON contenente i dati da passare con la richiesta. |
I comandi cURL seguenti vengono eseguiti da una shell BASH. Modificare questi comandi con il nome e la chiave della risorsa e con i valori del file JSON. Provare ad analizzare i documenti nativi selezionando il Personally Identifiable Information (PII) progetto di esempio di codice o Document Summarization :
Documento di esempio di informazioni personali
Per questa guida introduttiva, è necessario un documento di origine caricato nel contenitore di origine. È possibile scaricare il documento di esempio di Microsoft Word o Adobe PDF per questo progetto. La lingua di origine è inglese.
Compilare la richiesta POST
Usando l'editor o l'IDE preferito, creare una nuova directory per l'app denominata
native-document.Creare un nuovo file JSON denominato pii-detection.json nella directory native-document .
Copiare e incollare il seguente esempio di richiesta di informazioni personali (PII) nel
pii-detection.jsonfile. Sostituire{your-source-container-SAS-URL}e{your-target-container-SAS-URL}con i valori dell'istanza di contenitori dell'account portale di Azure Archiviazione:
Esempio di richiesta
{
"displayName": "Extracting Location & US Region",
"analysisInput": {
"documents": [
{
"language": "en-US",
"id": "Output-excel-file",
"source": {
"location": "{your-source-blob-with-SAS-URL}"
},
"target": {
"location": "{your-target-container-with-SAS-URL}"
}
}
]
},
"tasks": [
{
"kind": "PiiEntityRecognition",
"parameters":{
"excludePiiCategories" : ["PersonType", "Category2", "Category3"],
"redactionPolicy": "UseRedactionCharacterWithRefId"
}
}
]
}
Eseguire la richiesta POST
Ecco la struttura preliminare della richiesta POST:
POST {your-language-endpoint}/language/analyze-documents/jobs?api-version=2023-11-15-previewPrima di eseguire la richiesta POST, sostituire
{your-language-resource-endpoint}e{your-key}con i valori dell'istanza del servizio language portale di Azure.Importante
Al termine, ricordarsi di rimuovere la chiave dal codice e non renderlo mai pubblico. Per l'ambiente di produzione, usare un modo sicuro per archiviare e accedere alle credenziali, ad esempio Azure Key Vault. Per altre informazioni, vedere Sicurezza dei servizi di intelligenza artificiale di Azure.
PowerShell
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2023-11-15-preview" -i -X POST --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@pii-detection.json"prompt dei comandi/terminale
curl -v -X POST "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2023-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@pii-detection.json"Ecco una risposta di esempio:
HTTP/1.1 202 Accepted Content-Length: 0 operation-location: https://{your-language-resource-endpoint}/language/analyze-documents/jobs/f1cc29ff-9738-42ea-afa5-98d2d3cabf94?api-version=2023-11-15-preview apim-request-id: e7d6fa0c-0efd-416a-8b1e-1cd9287f5f81 x-ms-region: West US 2 Date: Thu, 25 Jan 2024 15:12:32 GMT
Risposta POST (jobId)
Si riceve una risposta 202 (Operazione riuscita) che include un'intestazione Operation-Location di sola lettura. Il valore di questa intestazione contiene un jobId che può essere sottoposto a query per ottenere lo stato dell'operazione asincrona e recuperare i risultati usando una richiesta GET :
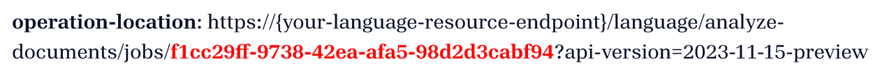
Ottenere i risultati dell'analisi (richiesta GET)
Dopo aver completato la richiesta POST , eseguire il polling dell'intestazione operation-location restituita nella richiesta POST per visualizzare i dati elaborati.
Ecco la struttura preliminare della richiesta GET :
GET {your-language-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2023-11-15-previewPrima di eseguire il comando, apportare queste modifiche:
Sostituire {jobId} con l'intestazione Operation-Location dalla risposta POST.
Sostituire {your-language-resource-endpoint} e {your-key} con i valori dell'istanza del servizio di linguaggio nel portale di Azure.
Richiesta GET
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2023-11-15-preview" -i -X GET --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
curl -v -X GET "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2023-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
Esaminare i risultati
Si riceve una risposta 200 (Operazione riuscita) con l'output JSON. Il campo stato indica il risultato dell'operazione. Se l'operazione non è completa, il valore di stato è "in esecuzione" o "notStarted" ed è necessario chiamare di nuovo l'API, manualmente o tramite uno script. Si consiglia di attendere almeno un secondo tra le chiamate.
Risposta di esempio
{
"jobId": "f1cc29ff-9738-42ea-afa5-98d2d3cabf94",
"lastUpdatedDateTime": "2024-01-24T13:17:58Z",
"createdDateTime": "2024-01-24T13:17:47Z",
"expirationDateTime": "2024-01-25T13:17:47Z",
"status": "succeeded",
"errors": [],
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "PiiEntityRecognitionLROResults",
"lastUpdateDateTime": "2024-01-24T13:17:58.33934Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "doc_0",
"source": {
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-input/input.pdf"
},
"targets": [
{
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-output/df6611a3-fe74-44f8-b8d4-58ac7491cb13/PiiEntityRecognition-0001/input.result.json"
},
{
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-output/df6611a3-fe74-44f8-b8d4-58ac7491cb13/PiiEntityRecognition-0001/input.docx"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2023-09-01"
}
}
]
}
}
Al termine dell'operazione:
- I documenti analizzati sono disponibili nel contenitore di destinazione.
- Il metodo POST riuscito restituisce un
202 Acceptedcodice di risposta che indica che il servizio ha creato la richiesta batch. - La richiesta POST ha restituito anche intestazioni di risposta, incluse
Operation-Locationle intestazioni che forniscono un valore usato nelle richieste GET successive.
Pulire le risorse
Se si vuole pulire e rimuovere una sottoscrizione dei servizi di intelligenza artificiale di Azure, è possibile eliminare la risorsa o il gruppo di risorse. L'eliminazione del gruppo di risorse comporta anche l'eliminazione di tutte le altre risorse associate.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per