Diagnosticare un evento imprevisto usando Advisor metriche
Importante
A partire dal 20 settembre 2023 non sarà possibile creare nuove risorse di Advisor metriche. Il servizio Advisor metriche viene ritirato il 1° ottobre 2026.
Che cos'è un evento imprevisto?
Quando vengono rilevate anomalie in più serie temporali all'interno di una metrica in un determinato timestamp, Advisor metriche raggruppa automaticamente le anomalie che condividono la stessa causa radice in un evento imprevisto. Un evento imprevisto indica in genere un problema reale, Advisor metriche esegue analisi su di esso e fornisce informazioni dettagliate automatiche sull'analisi della causa radice.
Ciò consente di rimuovere significativamente lo sforzo del cliente di visualizzare ogni singola anomalia e di trovare rapidamente il fattore più importante che contribuisce a un problema.
Un avviso generato da Advisor metriche può contenere più eventi imprevisti e ogni evento imprevisto può contenere più anomalie acquisite in serie temporali diverse contemporaneamente.
Percorsi per diagnosticare un evento imprevisto
Diagnosticare da una notifica di avviso
Se è stato configurato un hook del tipo di posta elettronica/Teams e si è applicata almeno una configurazione di avviso. Si riceveranno quindi notifiche di avviso continue che inoltrano gli eventi imprevisti analizzati da Advisor metriche. All'interno della notifica è presente un elenco di eventi imprevisti e una breve descrizione. Per ogni evento imprevisto, è presente un pulsante "Diagnostica", selezionandolo si verrà indirizzati alla pagina dei dettagli dell'evento imprevisto per visualizzare le informazioni di diagnostica.
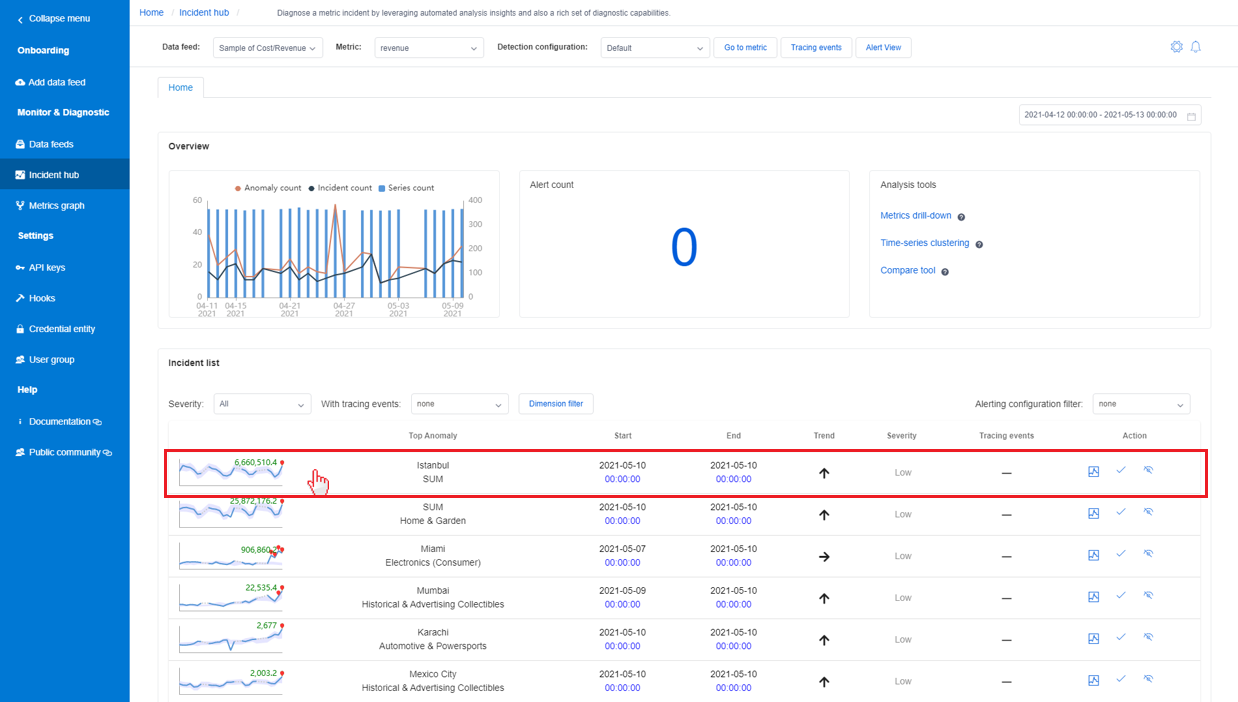
Diagnosticare da un evento imprevisto in "Hub eventi imprevisti"
C'è una posizione centrale in Advisor metriche che raccoglie tutti gli eventi imprevisti acquisiti e semplifica la traccia di eventuali problemi in corso. Selezionando la scheda Hub eventi imprevisti nella barra di spostamento a sinistra verranno elencati tutti gli eventi imprevisti all'interno delle metriche selezionate. Nell'elenco degli eventi imprevisti selezionare una di esse per visualizzare informazioni dettagliate sulla diagnostica.
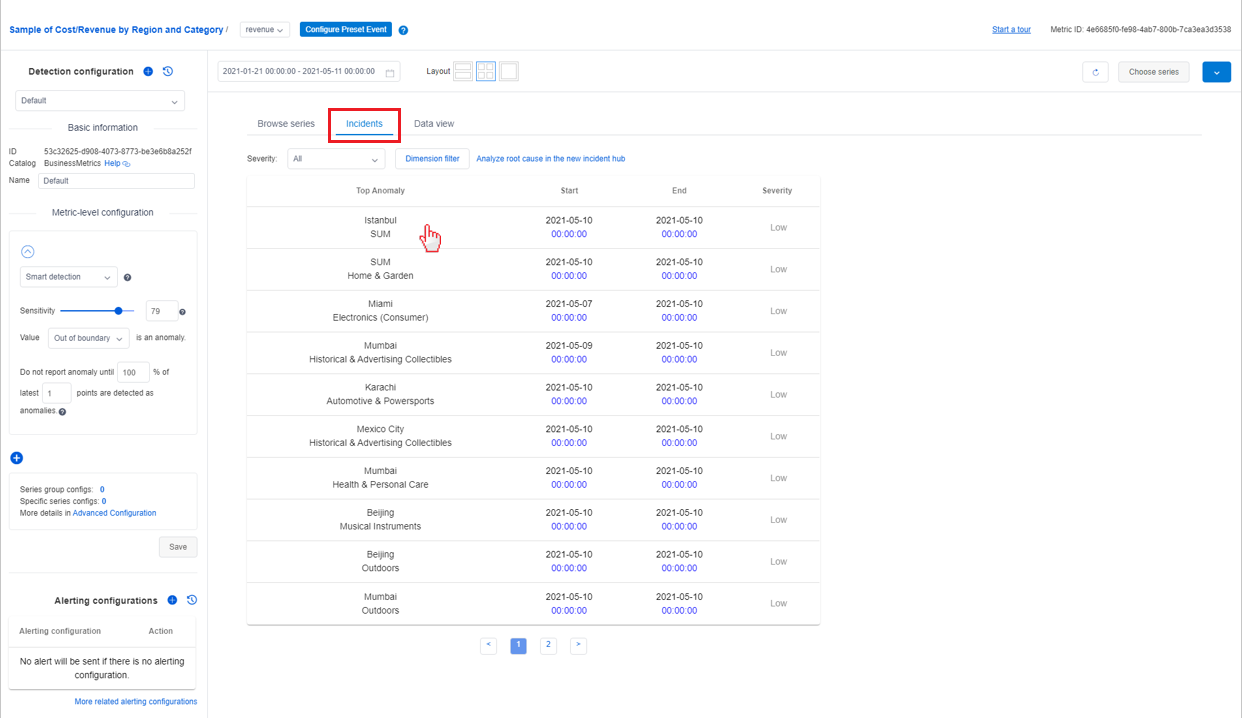
Diagnosticare da un evento imprevisto elencato nella pagina delle metriche
Nella pagina dei dettagli delle metriche è presente una scheda denominata Eventi imprevisti che elenca gli eventi imprevisti più recenti acquisiti per questa metrica. L'elenco può essere filtrato in base alla gravità degli eventi imprevisti o al valore della dimensione delle metriche.
Se si seleziona un evento imprevisto nell'elenco, si verrà indirizzati alla pagina dei dettagli dell'evento imprevisto per visualizzare le informazioni di diagnostica.
Flusso di diagnostica tipico
Dopo essere stati indirizzati alla pagina dei dettagli dell'evento imprevisto, è possibile sfruttare le informazioni dettagliate analizzate automaticamente da Advisor metriche per individuare rapidamente la causa radice di un problema o usare lo strumento di analisi per valutare ulteriormente l'impatto del problema. Nella pagina dei dettagli dell'evento imprevisto sono disponibili tre sezioni che corrispondono a tre passaggi principali per la diagnosi di un evento imprevisto.
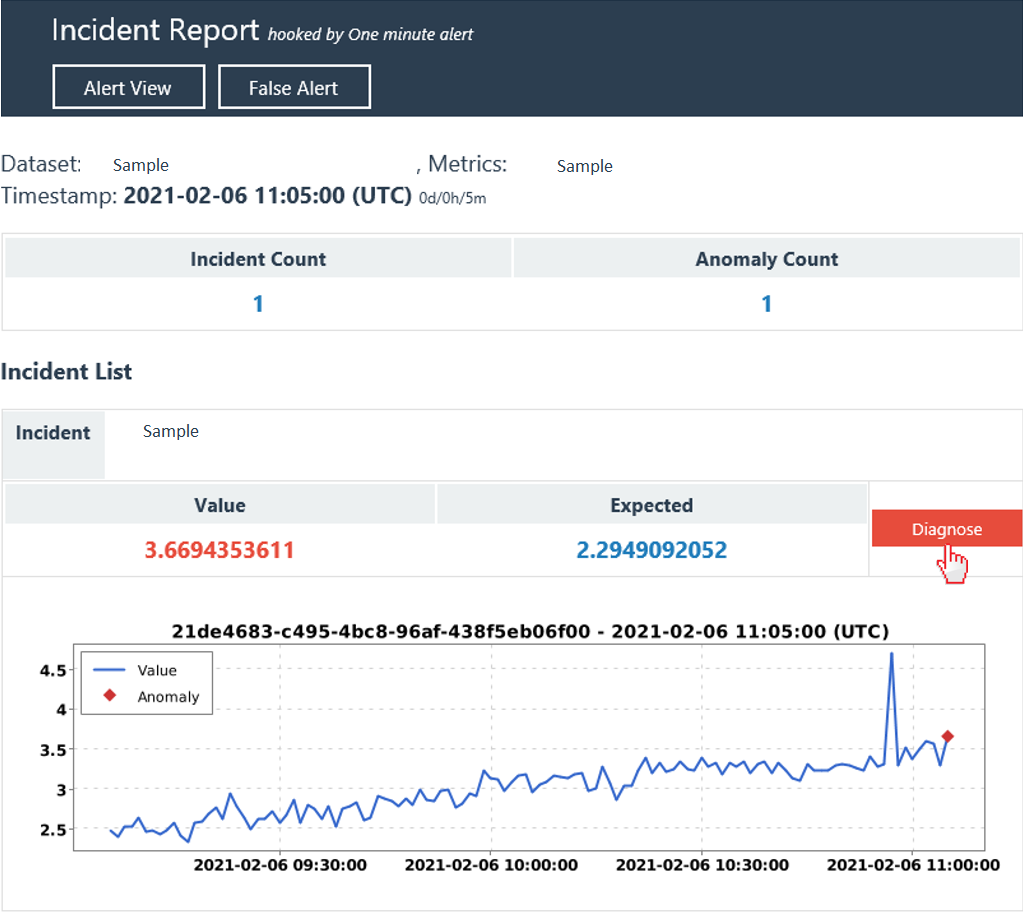
Passaggio 1: Controllare il riepilogo dell'evento imprevisto corrente
La prima sezione elenca un riepilogo dell'evento imprevisto corrente, incluse informazioni di base, azioni e tracce e una causa radice analizzata.
Le informazioni di base includono la "serie più interessata" con un diagramma, "impatto inizio e ora di fine", "gravità dell'evento imprevisto" e "anomalie totali incluse". Leggendo questo, è possibile ottenere una conoscenza di base di un problema in corso e l'impatto di esso.
Azioni e tracce, che viene usata per facilitare la collaborazione del team su un evento imprevisto in corso. A volte un evento imprevisto potrebbe dover coinvolgere il lavoro dei membri del team incrociato per analizzarlo e risolverlo. Tutti gli utenti autorizzati a visualizzare l'evento imprevisto possono aggiungere un'azione o un evento di traccia.
Ad esempio, dopo aver identificato l'evento imprevisto e la causa radice, un tecnico può aggiungere un elemento di traccia con tipo "personalizzato" e immettere la causa radice nella sezione del commento. Lasciare lo stato "Attivo". Altri compagni di squadra possono quindi condividere le stesse informazioni e sapere che c'è qualcuno che sta lavorando alla correzione. È anche possibile aggiungere un elemento "Azure DevOps" per tenere traccia dell'evento imprevisto con un'attività o un bug specifico.
La causa radice analizzata è un risultato analizzato automaticamente. Advisor metriche analizza tutte le anomalie acquisite in serie temporali all'interno di una metrica con valori di dimensione diversi contemporaneamente timestamp. Esegue quindi la correlazione, il clustering per raggruppare le anomalie correlate e genera consigli sulla causa radice.
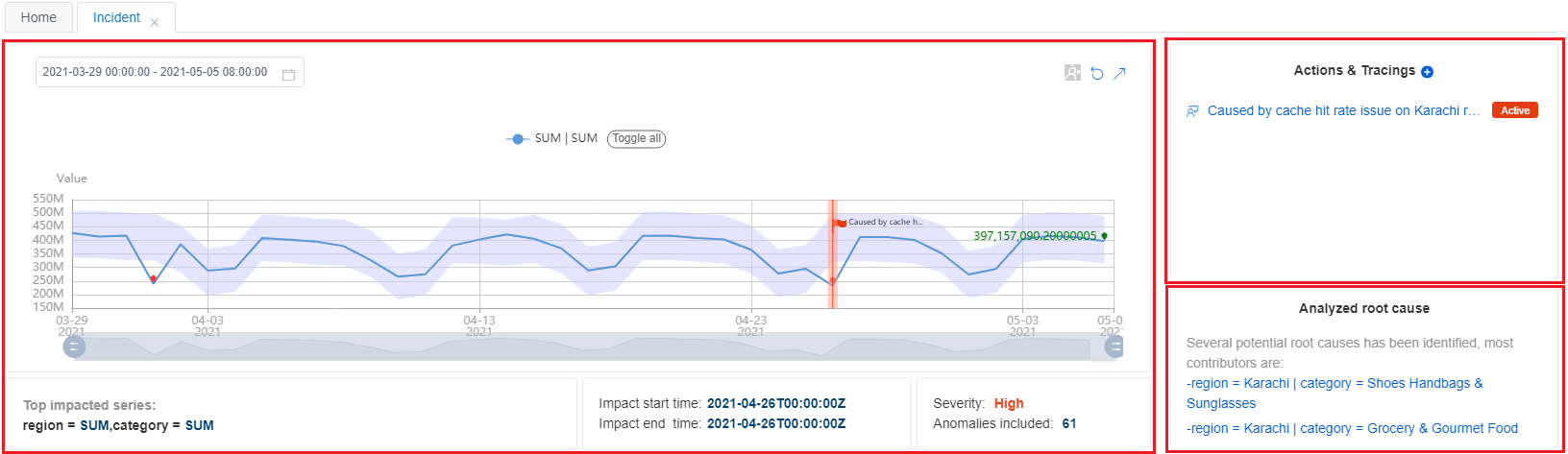
Per le metriche con più dimensioni, è un caso comune in cui verranno rilevate più anomalie contemporaneamente. Tuttavia, queste anomalie possono condividere la stessa causa radice. Invece di analizzare tutte le anomalie una alla volta, l'uso della causa radice analizzata deve essere il modo più efficiente per diagnosticare l'evento imprevisto corrente.
Passaggio 2: Visualizzare le informazioni di diagnostica tra dimensioni
Dopo aver ottenuto informazioni di base e informazioni dettagliate sull'analisi automatica, è possibile ottenere informazioni più dettagliate sullo stato anomalo di altre dimensioni all'interno della stessa metrica in modo olistico usando l'albero di diagnostica.
Per le metriche con più dimensioni, Advisor metriche classifica la serie temporale in una gerarchia, denominata albero di diagnostica. Ad esempio, una metrica "revenue" viene monitorata da due dimensioni: "region" e "category". Nonostante i valori delle dimensioni concrete, è necessario avere un valore di dimensione aggregato, ad esempio "SUM". La serie temporale "region" = "SUM" e "category" = "SUM" verrà quindi categorizzata come nodo radice all'interno dell'albero. Ogni volta che è presente un'anomalia acquisita nella dimensione "SUM", è possibile eseguire il drill-down e analizzare per individuare il valore specifico della dimensione che ha contribuito maggiormente all'anomalia del nodo padre. Selezionare ogni nodo per espandere e visualizzare informazioni dettagliate.
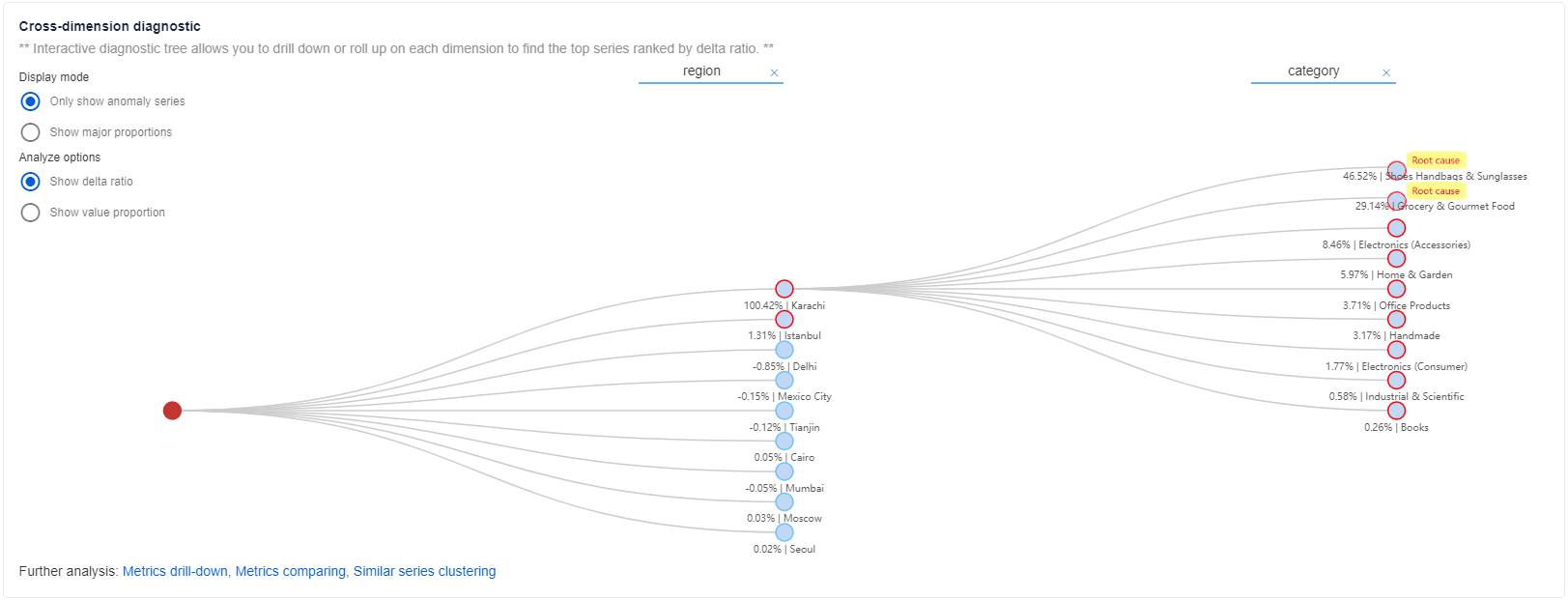
Per abilitare un valore di dimensione "aggregato" nelle metriche
Advisor metriche supporta l'esecuzione di "Roll-up" sulle dimensioni per calcolare un valore di dimensione "aggregato". L'albero di diagnostica supporta la diagnosi sulle aggregazioni "SUM", "AVG", "MAX","MIN","COUNT". Per abilitare un valore di dimensione "aggregato", è possibile abilitare la funzione "Roll-up" durante l'onboarding dei dati. Assicurarsi che le metriche siano calcolabili matematicamente e che la dimensione aggregata abbia un valore aziendale reale.

Se non è presente alcun valore di dimensione "aggregato" nelle metriche
Se non è presente alcun valore di dimensione "aggregato" nelle metriche e la funzione "Roll-up" non è abilitata durante l'onboarding dei dati. Non verrà calcolato alcun valore della metrica per la dimensione "aggregata", verrà visualizzato come nodo grigio nell'albero e potrebbe essere espanso per visualizzare i nodi figlio.
Legenda dell'albero di diagnostica
Esistono tre tipi di nodi nell'albero di diagnostica:
- Nodo blu, che corrisponde a una serie temporale con valore di metrica reale.
- Nodo grigio, che corrisponde a una serie temporale virtuale senza valore metrico, è un nodo logico.
- Nodo rosso, che corrisponde alla serie temporale più interessata dell'evento imprevisto corrente.
Per ogni stato anomalo del nodo viene descritto dal colore del bordo del nodo
- Bordo rosso indica che è presente un'anomalia acquisita nella serie temporale corrispondente al timestamp dell'evento imprevisto.
- Bordo non rosso indica che non è stata acquisita alcuna anomalia nella serie temporale corrispondente al timestamp dell'evento imprevisto.
Display mode
Esistono due modalità di visualizzazione per un albero di diagnostica: mostra solo una serie di anomalie o mostra proporzioni principali.
- Mostra solo la modalità serie di anomalie consente al cliente di concentrarsi sulle anomalie correnti acquisite su serie diverse e diagnosticare la causa radice della serie più interessata.
- Mostra proporzioni principali consente al cliente di controllare lo stato anomalo delle proporzioni principali della serie con impatto superiore. In questa modalità, l'albero visualizzerebbe entrambe le serie con anomalie rilevate e serie senza anomalie. Ma più focus su serie importanti.
Opzioni di analisi
Mostra rapporto differenziale
"Rapporto differenziale" è la percentuale del delta del nodo corrente rispetto al delta del nodo padre. Ecco la formula:
(valore reale del nodo corrente - valore previsto del nodo corrente) / (valore reale del nodo padre - valore previsto del nodo padre) * 100%
Viene usato per analizzare il contributo principale del delta del nodo padre.
Mostra percentuale valore
"Percentuale valore" è la percentuale del valore del nodo corrente rispetto al valore del nodo padre. Ecco la formula:
(valore reale del nodo corrente/valore reale del nodo padre) * 100%
Viene usato per valutare la proporzione del nodo corrente all'interno dell'intero.
Usando "Albero di diagnostica", i clienti possono individuare la causa radice dell'evento imprevisto corrente in una dimensione specifica. In questo modo si elimina significativamente lo sforzo del cliente di visualizzare ogni singola anomalia o pivot attraverso dimensioni diverse per trovare il contributo principale dell'anomalia.
Passaggio 3: Visualizzare le informazioni di diagnostica sulle metriche incrociate usando "Grafico metriche"
In alcuni casi, è difficile analizzare un problema controllando lo stato anomalo di una singola metrica, ma è necessario correlare più metriche insieme. I clienti sono in grado di configurare un grafico delle metriche, che indica la relazione tra le metriche. Per iniziare, vedere Come creare un grafico delle metriche.
Controllare lo stato delle anomalie nella dimensione della causa radice all'interno di "Grafico metriche"
Utilizzando il risultato di diagnostica della dimensione incrociata precedente, la causa radice è limitata a un valore di dimensione specifico. Usare quindi il "grafico delle metriche" e filtrare in base alla dimensione della causa radice analizzata per controllare lo stato delle anomalie in altre metriche.
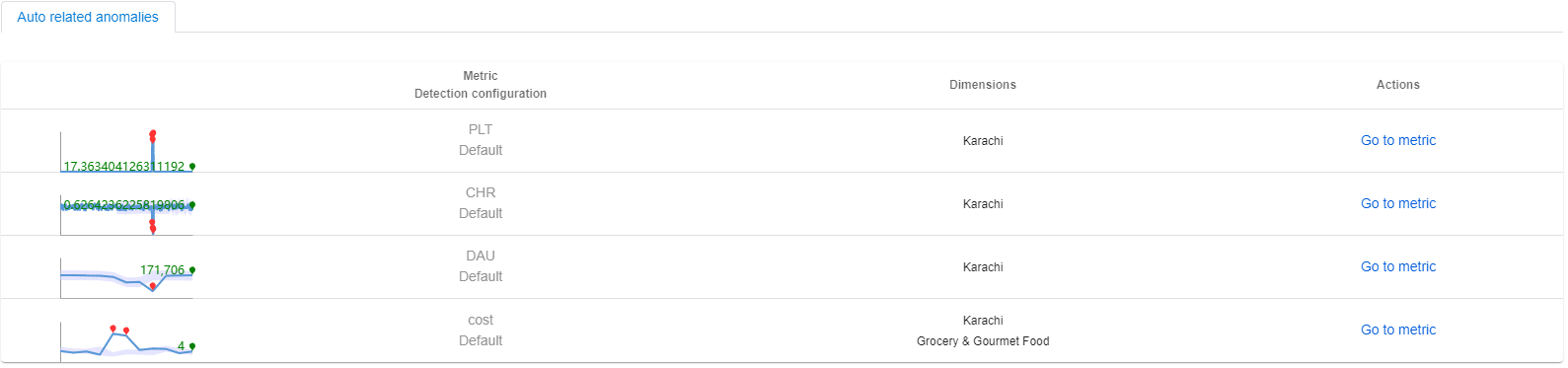
Ad esempio, se si verifica un evento imprevisto acquisito nelle metriche dei "ricavi". La serie più interessata è nell'area globale con "region" = "SUM". Usando la diagnostica tra dimensioni, la causa radice si trova in "region" = "Karachi". È disponibile un grafico delle metriche preconfigurato, incluse le metriche di "revenue", "cost", "DAU", "PLT(page load time)" e "CHR(cache hit rate)".
Advisor metriche filtra automaticamente il grafico delle metriche in base alla dimensione della causa radice "region" = "Karachi" e visualizza lo stato anomalie di ogni metrica. Analizzando la relazione tra le metriche e lo stato delle anomalie, i clienti possono ottenere ulteriori informazioni dettagliate su ciò che è la causa radice finale.

Anomalie correlate automaticamente
Applicando il filtro della dimensione della causa radice nel grafico delle metriche, le anomalie in ogni metrica al timestamp dell'evento imprevisto corrente verranno correlate automaticamente. Tali anomalie devono essere correlate alla causa radice identificata dell'evento imprevisto corrente.