Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'API di sintesi batch può eseguire in modo asincrono la sintesi di un volume elevato di input di testo (lungo e breve). Gli editori e le piattaforme di contenuti audio possono creare contenuti audio lunghi in un batch. Ad esempio: libri audio, articoli di notizie e documenti. L'API di sintesi batch può creare audio sintetizzato di lunghezza superiore a 10 minuti.
Importante
L'API di sintesi batch è disponibile a livello generale. L'API Audio lungo verrà ritirata il 1° aprile 2027. Per altre informazioni, vedere Eseguire la migrazione all'API di sintesi batch.
L'API di sintesi batch è asincrona e non restituisce l'audio sintetizzato in tempo reale. È necessario inviare file di testo per la sintesi, eseguire il polling dello stato e scaricare l'output audio quando lo stato indica l'esito positivo dell'operazione. Gli input di testo devono essere in formato di testo normale o SSML (Speech Synthesis Markup Language).
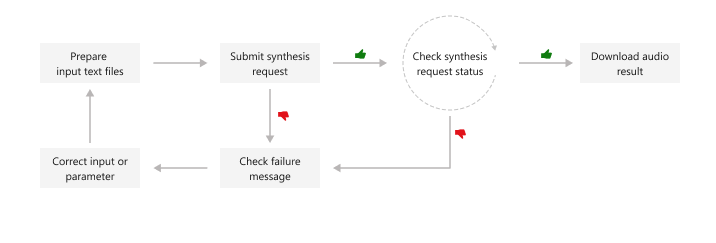
Questo diagramma offre una panoramica generale del flusso di lavoro.
Suggerimento
È anche possibile usare Speech SDK per creare audio sintetizzato di oltre 10 minuti eseguendo l'iterazione sul testo e sintetizzandolo in blocchi. Per un esempio in C#, vedere GitHub.
Per la sintesi batch è possibile usare le operazioni API REST seguenti:
| Operazione | Metodo | Chiamata API REST |
|---|---|---|
| Creare la sintesi batch | PUT |
texttospeech/sintesi_batch/YourSynthesisId |
| Ottenere la sintesi batch | GET |
texttospeech/sintesi_batch/YourSynthesisId |
| Elencare la sintesi batch | GET |
sintesivocale/elaborazionilotto |
| Eliminare la sintesi batch | DELETE |
texttospeech/sintesi_batch/YourSynthesisId |
Per esempi di codice, vedere GitHub.
Creare la sintesi batch
Per inviare una richiesta di sintesi batch, costruire il percorso e il corpo della richiesta HTTP PUT in base alle istruzioni seguenti:
- Impostare la proprietà
inputKindobbligatoria. - Se la proprietà
inputKindè impostata su "PlainText", è necessario impostare anche la proprietàvoiceinsynthesisConfig. Nell'esempio seguente, l'oggettoinputKindè impostato su "SSML", quindi l'oggettosynthesisConfignon è impostato. - Facoltativamente, è possibile impostare le proprietà
description,timeToLiveInHourse altre. Per altre informazioni, vedere le proprietà di sintesi batch.
Nota
La dimensione massima del payload JSON accettata è di 2 megabyte.
Impostare il YourSynthesisId necessario nel percorso. Il valore per YourSynthesisId deve essere univoco. Deve essere lungo 3-64, contenere solo numeri, lettere, trattini, caratteri di sottolineatura e punti, iniziare e terminare con una lettera o un numero.
Effettuare una richiesta HTTP PUT usando l'URI, come illustrato nell'esempio seguente. Sostituire YourSpeechKey con la chiave della risorsa Voce e YourSpeechRegion con l'area della risorsa Voce, quindi impostare le proprietà del corpo della richiesta come descritto in precedenza.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourSpeechKey" -H "Content-Type: application/json" -d '{
"description": "my ssml test",
"inputKind": "SSML",
"inputs": [
{
"content": "<speak version=\"1.0\" xml:lang=\"en-US\"><voice name=\"en-US-JennyNeural\">The rainbow has seven colors.</voice></speak>"
}
],
"properties": {
"outputFormat": "riff-24khz-16bit-mono-pcm",
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false,
"concatenateResult": false,
"decompressOutputFiles": false
}
}' "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses/YourSynthesisId?api-version=2024-04-01"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"id": "YourSynthesisId",
"status": "Running",
"createdDateTime": "2024-03-12T07:23:18.0097387Z",
"lastActionDateTime": "2024-03-12T07:23:18.0097388Z",
"inputKind": "SSML",
"customVoices": {},
"properties": {
"timeToLiveInHours": 168,
"outputFormat": "riff-24khz-16bit-mono-pcm",
"concatenateResult": false,
"decompressOutputFiles": false,
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false
}
}
La status proprietà deve passare dallo Running stato a Succeeded o Failed. È possibile chiamare periodicamente l'API di sintesi batch GET finché lo stato restituito non è Succeeded o Failed.
Ottenere la sintesi batch
Per ottenere lo stato del processo di sintesi batch, eseguire una richiesta HTTP GET usando l'URI, come illustrato nell'esempio seguente. Sostituire YourSpeechKey con la chiave della risorsa Voce e sostituire YourSpeechRegion con l'area della risorsa Voce.
curl -v -X GET "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses/YourSynthesisId?api-version=2024-04-01" -H "Ocp-Apim-Subscription-Key: YourSpeechKey"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"id": "YourSynthesisId",
"status": "Succeeded",
"createdDateTime": "2024-03-12T07:23:18.0097387Z",
"lastActionDateTime": "2024-03-12T07:23:18.7979669",
"inputKind": "SSML",
"customVoices": {},
"properties": {
"timeToLiveInHours": 168,
"outputFormat": "riff-24khz-16bit-mono-pcm",
"concatenateResult": false,
"decompressOutputFiles": false,
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false,
"sizeInBytes": 120000,
"succeededAudioCount": 1,
"failedAudioCount": 0,
"durationInMilliseconds": 2500,
"billingDetails": {
"neuralCharacters": 29
}
},
"outputs": {
"result": "https://stttssvcuse.blob.core.windows.net/batchsynthesis-output/29f2105f997c4bfea176d39d05ff201e/YourSynthesisId/results.zip?SAS_Token"
}
}
Da outputs.result è possibile scaricare un file ZIP contenente l'audio, ad esempio 0001.wav, il riepilogo e i dettagli di debug. Per altre informazioni, vedere Risultati della sintesi batch.
Elencare la sintesi batch
Per elencare tutti i processi di sintesi batch per la risorsa Voce, eseguire una richiesta HTTP GET usando l'URI, come illustrato nell'esempio seguente. Sostituire YourSpeechKey con la chiave della risorsa Voce e YourSpeechRegion con l'area della risorsa Voce. Facoltativamente, è possibile impostare i parametri di query skip e maxpagesize (fino a 100) in URL. Il valore predefinito per skip è 0 e quello per maxpagesize è 100.
curl -v -X GET "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses?api-version=2024-04-01&skip=1&maxpagesize=2" -H "Ocp-Apim-Subscription-Key: YourSpeechKey"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"value": [
{
"id": "my-job-03",
"status": "Succeeded",
"createdDateTime": "2024-03-12T07:28:32.5690441Z",
"lastActionDateTime": "2024-03-12T07:28:33.0042293",
"inputKind": "SSML",
"customVoices": {},
"properties": {
"timeToLiveInHours": 168,
"outputFormat": "riff-24khz-16bit-mono-pcm",
"concatenateResult": false,
"decompressOutputFiles": false,
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false,
"sizeInBytes": 120000,
"succeededAudioCount": 1,
"failedAudioCount": 0,
"durationInMilliseconds": 2500,
"billingDetails": {
"neuralCharacters": 29
}
},
"outputs": {
"result": "https://stttssvcuse.blob.core.windows.net/batchsynthesis-output/29f2105f997c4bfea176d39d05ff201e/my-job-03/results.zip?SAS_Token"
}
},
{
"id": "my-job-02",
"status": "Succeeded",
"createdDateTime": "2024-03-12T07:28:29.6418211Z",
"lastActionDateTime": "2024-03-12T07:28:30.0910306",
"inputKind": "SSML",
"customVoices": {},
"properties": {
"timeToLiveInHours": 168,
"outputFormat": "riff-24khz-16bit-mono-pcm",
"concatenateResult": false,
"decompressOutputFiles": false,
"wordBoundaryEnabled": false,
"sentenceBoundaryEnabled": false,
"sizeInBytes": 120000,
"succeededAudioCount": 1,
"failedAudioCount": 0,
"durationInMilliseconds": 2500,
"billingDetails": {
"neuralCharacters": 29
}
},
"outputs": {
"result": "https://stttssvcuse.blob.core.windows.net/batchsynthesis-output/29f2105f997c4bfea176d39d05ff201e/my-job-02/results.zip?SAS_Token"
}
}
],
"nextLink": "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses?skip=3&maxpagesize=2&api-version=2024-04-01"
}
Da outputs.result è possibile scaricare un file ZIP contenente l'audio, ad esempio 0001.wav, il riepilogo e i dettagli di debug. Per altre informazioni, vedere Risultati della sintesi batch.
La proprietà value nella risposta JSON elenca le richieste di sintesi. L'elenco è suddiviso in pagine di dimensione massima pari a 100. La proprietà "nextLink" viene specificata in base alle esigenze e consente di ottenere la pagina successiva dell'elenco.
Eliminare la sintesi batch
Eliminare la cronologia dei processi di sintesi batch dopo che i risultati dell'output audio sono stati recuperati. Il servizio Voce mantiene la cronologia di sintesi batch per 168 ore (7 giorni) per impostazione predefinita. In alternativa, è possibile specificare questo periodo di conservazione usando la timeToLiveInHours proprietà , fino a 744 ore (31 giorni). La data e l'ora dell'eliminazione automatica (per i processi di sintesi con stato "Succeeded" o "Failed") è uguale alle proprietà lastActionDateTime + timeToLiveInHours.
Per eliminare un processo di sintesi batch, eseguire una richiesta HTTP DELETE usando l'URI, come illustrato nell'esempio seguente. Sostituire YourSynthesisId con l'ID di sintesi batch, YourSpeechKey con la chiave della risorsa Voce e YourSpeechRegion con l'area della risorsa Voce.
curl -v -X DELETE "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses/YourSynthesisId?api-version=2024-04-01" -H "Ocp-Apim-Subscription-Key: YourSpeechKey"
Le intestazioni della risposta includeranno HTTP/1.1 204 No Content se la richiesta di eliminazione ha avuto esito positivo.
Risultati della sintesi batch
Dopo aver ottenuto un processo di sintesi batch con status "Succeeded", è possibile scaricare i risultati dell'output audio. Usare l’URL della proprietà outputs.result della risposta GET di sintesi batch.
Per ottenere il file dei risultati della sintesi batch, eseguire una richiesta HTTP GET usando l'URI, come illustrato nell'esempio seguente. Sostituire YourOutputsResultUrl con l’URL della proprietà outputs.result della risposta GET di sintesi batch. Sostituire YourSpeechKey con la chiave della risorsa Voce.
curl -v -X GET "YourOutputsResultUrl" -H "Ocp-Apim-Subscription-Key: YourSpeechKey" > results.zip
I risultati si trovano in un file ZIP che contiene l'audio, ad esempio 0001.wav, il riepilogo e i dettagli di debug. Il prefisso numerato di ogni nome file (illustrato di seguito come [nnnn]) rispetta lo stesso ordine degli input di testo usati al momento della creazione della sintesi batch.
Nota
Il file [nnnn].debug.json contiene l'ID dei risultati della sintesi e altre informazioni che possono essere utili per la risoluzione dei problemi. Le proprietà che contiene potrebbero cambiare, quindi non è consigliabile accettare dipendenze dal formato JSON.
Il file di riepilogo contiene i risultati della sintesi per ogni input di testo. Di seguito è riportato un esempio di un file summary.json:
{
"jobID": "7ab84171-9070-4d3b-88d4-1b8cc1cb928a",
"status": "Succeeded",
"results": [
{
"contents": ["<speak version=\"1.0\" xml:lang=\"en-US\"><voice name=\"en-US-JennyNeural\">The rainbow has seven colors.</voice></speak>"],
"status": "Succeeded",
"audioFileName": "0001.wav",
"properties": {
"sizeInBytes": "120000",
"durationInMilliseconds": "2500"
}
}
]
}
Se erano richiesti dati sui limiti di frase ("sentenceBoundaryEnabled": true), nei risultati è incluso un file [nnnn].sentence.json corrispondente. Analogamente, se erano richiesti dati sui limiti di parola ("wordBoundaryEnabled": true), nei risultati è incluso un file [nnnn].word.json corrispondente.
Ecco un esempio di file di dati relativi alle parole con offset audio e durata in millisecondi:
[
{
"Text": "The",
"AudioOffset": 50,
"Duration": 137
},
{
"Text": "rainbow",
"AudioOffset": 200,
"Duration": 350
},
{
"Text": "has",
"AudioOffset": 562,
"Duration": 175
},
{
"Text": "seven",
"AudioOffset": 750,
"Duration": 300
},
{
"Text": "colors",
"AudioOffset": 1062,
"Duration": 625
},
{
"Text": ".",
"AudioOffset": 1700,
"Duration": 100
}
]
Latenza di sintesi batch e procedure consigliate
Quando si usa la sintesi batch per generare la sintesi vocale sintetizzata, è importante considerare la latenza coinvolta e seguire le procedure consigliate per ottenere risultati ottimali.
Latenza nella sintesi batch
La latenza nella sintesi batch dipende da vari fattori, tra cui la complessità del testo di input, il numero di input nel batch e le funzionalità di elaborazione dell'hardware sottostante.
La latenza per la sintesi batch è la seguente (approssimativamente):
La latenza del 50% degli output vocali sintetizzati è compresa tra 10 e 20 secondi.
La latenza del 95% degli output vocali sintetizzati è compresa tra 120 secondi.
Procedure consigliate
Quando si considera la sintesi batch per l'applicazione, è consigliabile valutare se la latenza soddisfa i requisiti. Se la latenza è allineata alle prestazioni desiderate, la sintesi batch può essere una scelta adatta. Tuttavia, se la latenza non soddisfa le proprie esigenze, è possibile prendere in considerazione l'uso dell'API in tempo reale.
Codici di stato HTTP
Questa sezione descrive in dettaglio i codici di risposta HTTP e i messaggi dell'API di sintesi batch.
HTTP 200 OK
HTTP 200 OK indica che la richiesta ha avuto esito positivo.
HTTP 201 Creato
HTTP 201 creato indica che la richiesta di creazione di sintesi batch (tramite HTTP PUT) è riuscita.
Errore HTTP 204
Un errore HTTP 204 indica che la richiesta ha avuto esito positivo, ma la risorsa non esiste. Ad esempio:
- Si è tentato di ottenere o eliminare un processo di sintesi che non esiste.
- Si è eliminato correttamente un processo di sintesi.
Errore HTTP 400
Ecco alcuni esempi che possono generare l'errore 400:
- Il valore di
outputFormatnon è supportato o non è valido. Specificare un valore di formato valido oppure lasciare vuotooutputFormatper usare l'impostazione predefinita. - Il numero di input di testo richiesti ha superato il limite di 10.000.
- Si è tentato di usare un ID di distribuzione non valido o una voce personalizzata non distribuita correttamente. Assicurarsi che la risorsa Voce abbia accesso alla voce personalizzata e che la voce personalizzata sia distribuita correttamente. È inoltre necessario assicurarsi che nella richiesta di sintesi batch il mapping di
{"your-custom-voice-name": "your-deployment-ID"}sia corretto. - Si è tentato di usare una risorsa Voce F0, ma l'area supporta solo il piano tariffario per le risorse Voce Standard.
Errore HTTP 404
Non è possibile trovare l'entità specificata. Assicurarsi che l'ID sintesi sia corretto.
Errore HTTP 429
Ci sono troppe richieste recenti. Ogni applicazione client può inviare fino a 100 richieste ogni 10 secondi per ogni risorsa Voce. Ridurre il numero di richieste al secondo.
Errore HTTP 500
L'errore interno del server HTTP 500 indica che la richiesta non è riuscita. Il messaggio di errore è riportato nel corpo della risposta.
Esempio di errore HTTP
Ecco una richiesta di esempio che genera un errore HTTP 400, perché la proprietà inputs è necessaria per creare un processo.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourSpeechKey" -H "Content-Type: application/json" -d '{
"inputKind": "SSML"
}' "https://YourSpeechRegion.api.cognitive.microsoft.com/texttospeech/batchsyntheses/YourSynthesisId?api-version=2024-04-01"
In questo caso, le intestazioni di risposta includono HTTP/1.1 400 Bad Request.
Il corpo della risposta è simile all'esempio JSON seguente:
{
"error": {
"code": "BadRequest",
"message": "The inputs is required."
}
}