Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come misurare e migliorare quantitativamente l'accuratezza del modello di riconoscimento vocale o dei propri modelli personalizzati. Per verificare l'accuratezza sono necessariAudio + trascrizione con etichetta umana. È consigliabile fornire dai 30 minuti alle 5 ore di audio rappresentativo.
Importante
Durante il test, il sistema esegue una trascrizione. Questo aspetto è importante da tenere presente, in quanto i prezzi variano in base all'offerta di servizio e al livello della sottoscrizione. Fare sempre riferimento ai prezzi ufficiali di Servizi di Azure AI per i dettagli più recenti.
Creazione di un test
È possibile testare l'accuratezza del modello personalizzato creando un test. Un test richiede una raccolta di file audio e le trascrizioni corrispondenti. È possibile confrontare l'accuratezza di un modello personalizzato con un modello di base di riconoscimento vocale o con un altro modello personalizzato. Dopo aver ottenuto i risultati del test, valutare la percentuale di errori delle parole (WER) rispetto ai risultati del riconoscimento vocale.
Dopo aver caricato set di dati di training e test, è possibile creare un test.
Per testare il modello di riconoscimento vocale personalizzato ottimizzato, seguire questa procedura:
Accedere al portale di Azure AI Foundry.
Selezionare Ottimizzazione nel riquadro sinistro e quindi selezionare Ottimizzazione dei servizi di intelligenza artificiale.
Selezionare l'attività di ottimizzazione vocale personalizzata (in base al nome del modello) avviata come descritto nell'articolo su come avviare l'ottimizzazione della voce personalizzata.
Selezionare Modelli di test>+ Crea test.
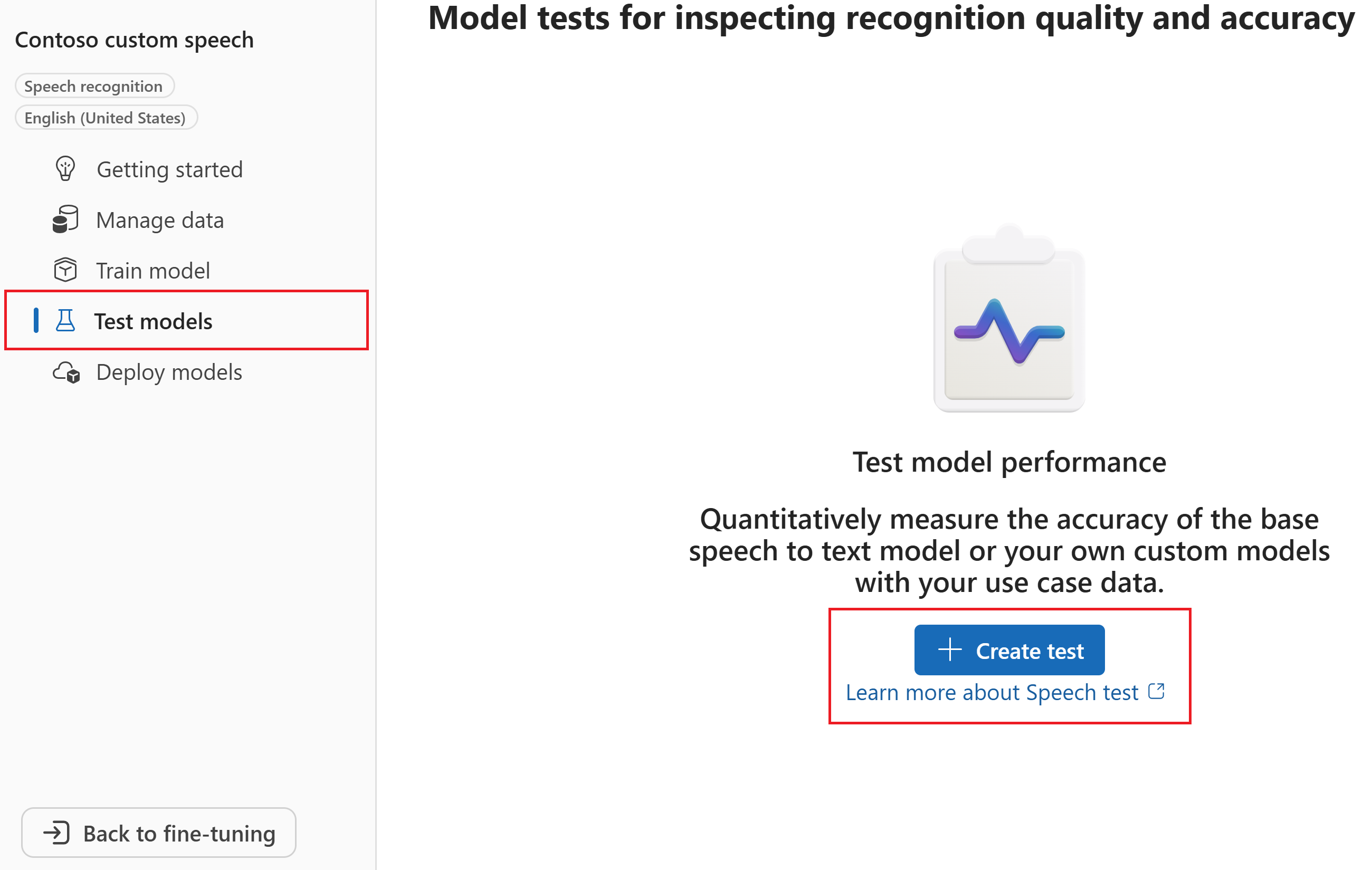
Nella procedura guidata Crea un nuovo test selezionare il tipo di test. Per un test di accuratezza (quantitativo), selezionare Valuta l'accuratezza (dati audio + trascrizione). Quindi seleziona Avanti.
Selezionare i dati da usare per i test. Quindi seleziona Avanti.
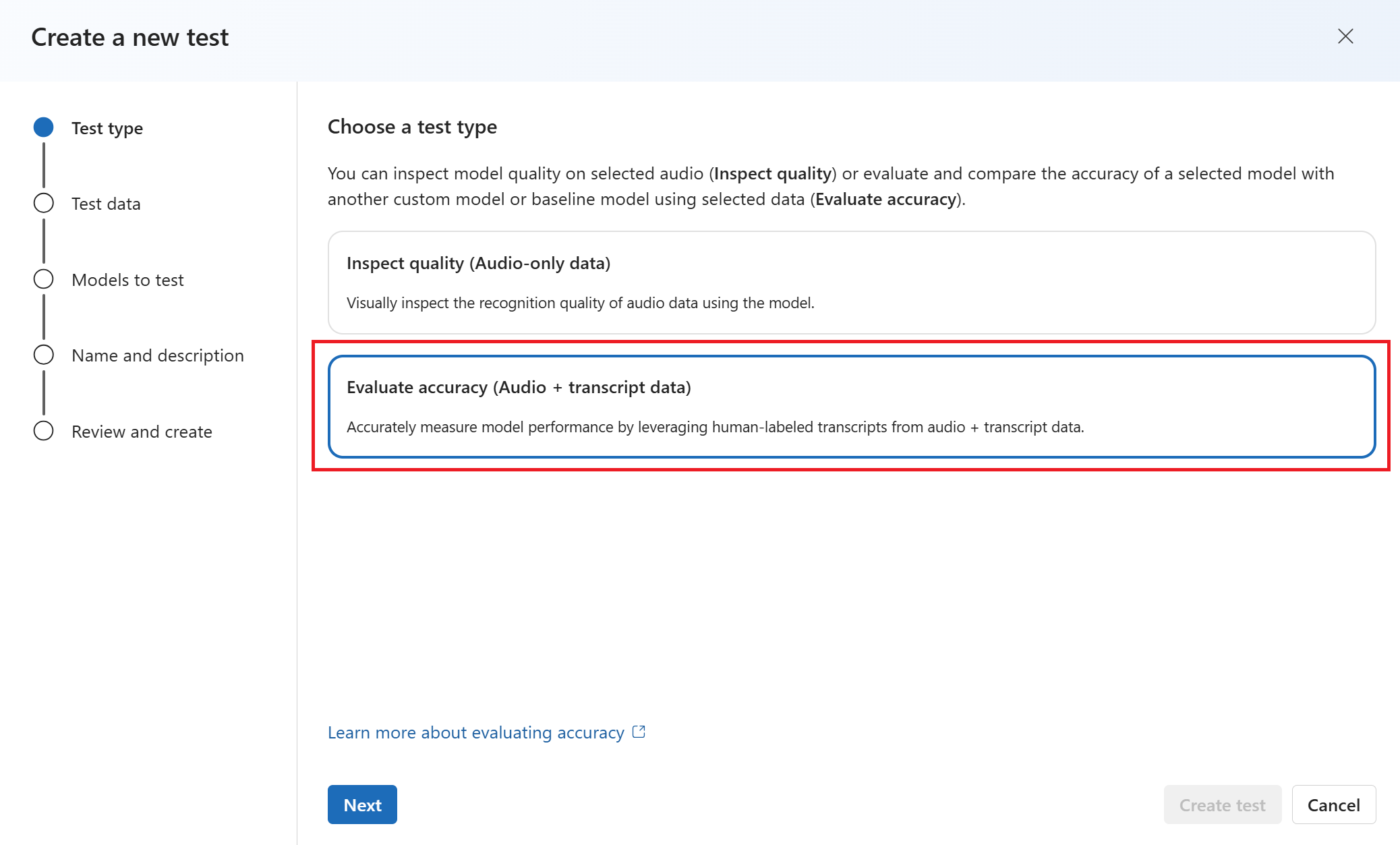
Selezionare fino a due modelli per valutare e confrontare l'accuratezza. In questo esempio viene selezionato il modello sottoposto a training e il modello di base. Quindi seleziona Avanti.
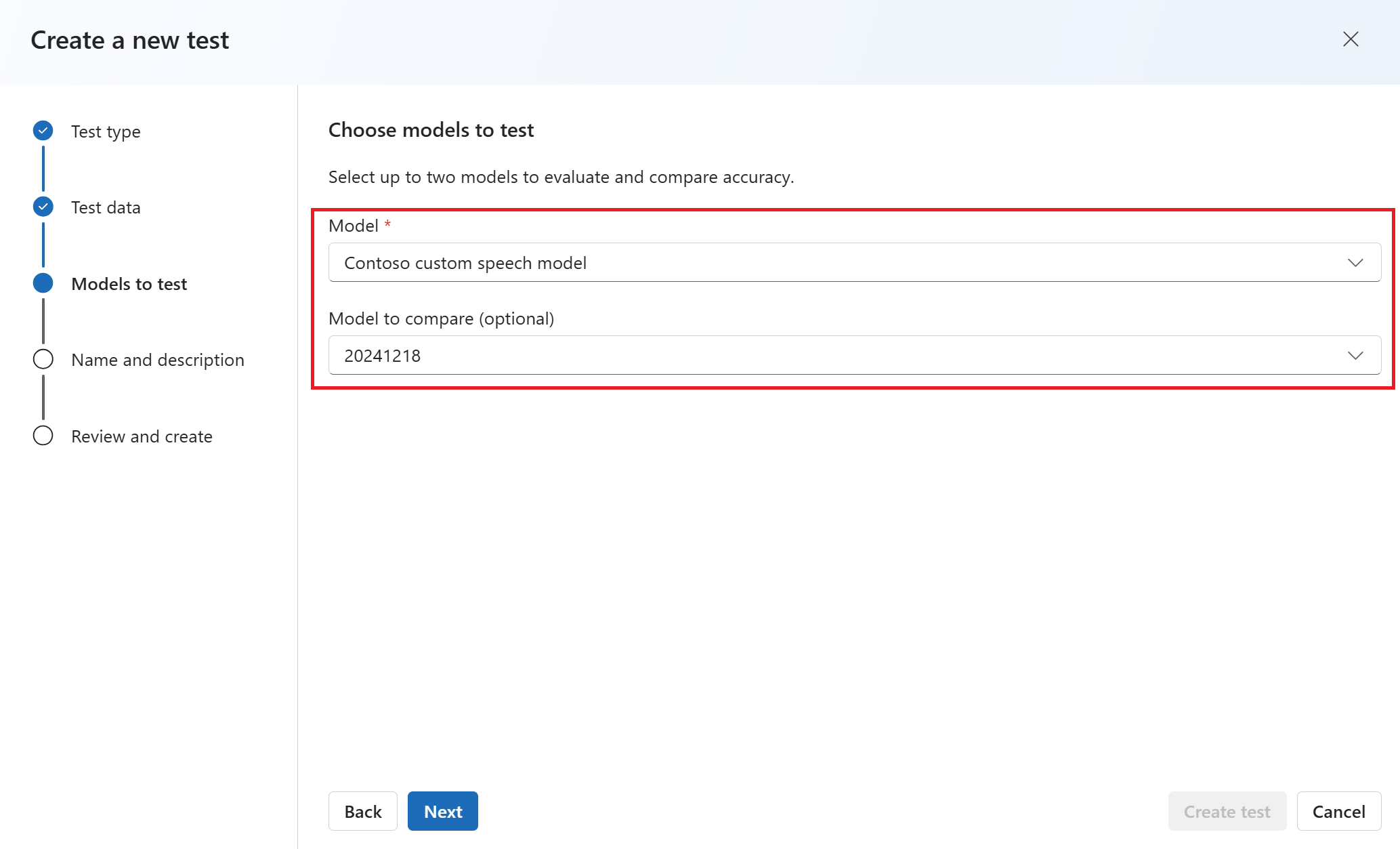
Immettere un nome e una descrizione per il test. Quindi seleziona Avanti.
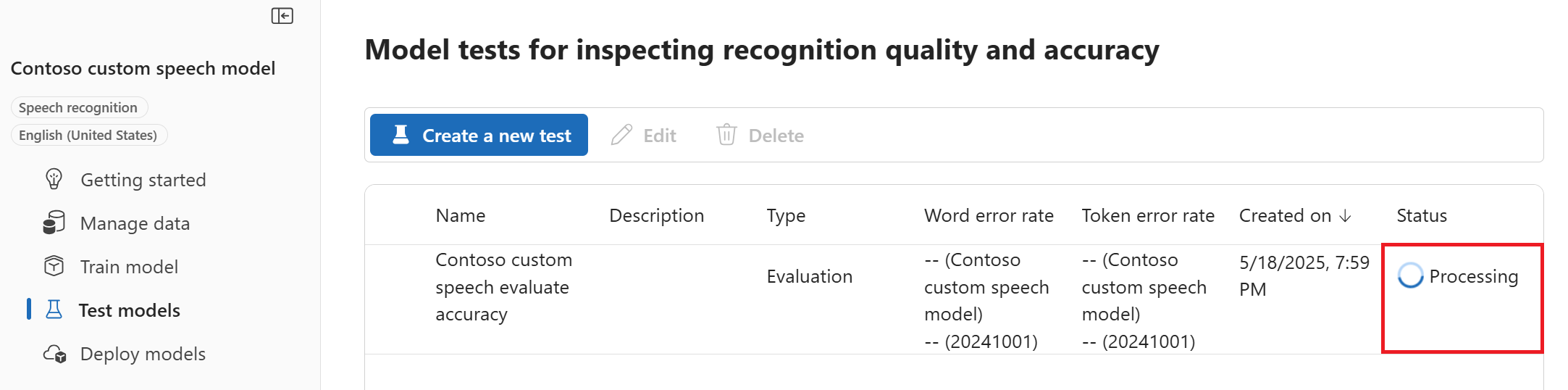
Esaminare le impostazioni e selezionare Crea test. Si torna alla pagina Modelli di test. Lo stato dei dati è Elaborazione.




Per creare un test di accuratezza, seguire questa procedura:
Accedere a Speech Studio.
Selezionare Riconoscimento vocale personalizzato> Nome del progetto >Modelli di test.
Selezionare Crea nuovo test.
Selezionare Valuta accuratezza>Avanti.
Selezionare un set di dati di trascrizione audio + trascrizione con etichetta umana, quindi selezionare Avanti. Se non sono disponibili set di dati, annullare la configurazione, quindi passare al menu set di dati di Voce per caricare set di dati.
Nota
È importante selezionare un set di dati acustici diverso da quello usato per il modello. Questo approccio può offrire un'idea più realistica delle prestazioni del modello.
Selezionare fino a due modelli da valutare, quindi selezionare Avanti.
Immettere il nome e la descrizione del test, quindi selezionare Avanti.
Esaminare i dettagli del test, quindi selezionare Salva e chiudi.
Per creare un test, usare il comando spx csr evaluation create. Creare i parametri della richiesta in base alle istruzioni seguenti:
- Impostare la
projectproprietà sull'ID di un progetto esistente. Questa proprietà è consigliata per consentire anche di visualizzare il test nel portale di Azure AI Foundry. È possibile eseguire il comandospx csr project listper ottenere i progetti disponibili. - Impostare la proprietà obbligatoria
model1sull'ID di un modello da testare. - Impostare la proprietà obbligatoria
model2sull'ID di un altro modello da testare. Se non si vogliono confrontare due modelli, usare lo stesso modello permodel1e permodel2. - Impostare la proprietà obbligatoria
datasetsull'ID di un set di dati da usare per il test. - Impostare la proprietà
language, altrimenti la CLI del discorso imposta "en-US" per impostazione predefinita. Usare le impostazioni locali del contenuto del set di dati per il parametro. Le impostazioni locali non possono essere modificate in un secondo momento. La proprietàlanguagedella CLI del discorso corrisponde alla proprietàlocalenella richiesta e nella risposta JSON. - Impostare la proprietà
nameobbligatoria. Questo parametro è il nome visualizzato nel portale di Azure AI Foundry. La proprietànamedella CLI del discorso corrisponde alla proprietàdisplayNamenella richiesta e nella risposta JSON.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce che crea un test:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 ff43e922-e3e6-4bf0-8473-55c08fd68048 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Evaluation" --description "My Evaluation Description"
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
La proprietà self di primo livello nel corpo della risposta è l'URI della valutazione. Usare questo URI per ottenere informazioni dettagliate sul progetto e sui risultati del test. È anche possibile usare questo URI per aggiornare o eliminare la valutazione.
Per ottenere la guida dell'interfaccia della riga di comando di Voce per le valutazioni, eseguire il comando seguente:
spx help csr evaluation
Per creare un test, usare l'operazione Evaluations_Create dell'API REST Riconoscimento vocale. Creare il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà
projectsull'URI di un progetto esistente. Questa proprietà è consigliata per consentire anche di visualizzare il test nel portale di Azure AI Foundry. È possibile effettuare una richiesta di Projects_List per ottenere i progetti disponibili. - Impostare la proprietà
testingKindsuEvaluationall'interno dicustomProperties. Se non si specificaEvaluation, il test viene considerato come un test di ispezione della qualità. Indipendentemente dal fatto che latestingKindproprietà sia impostata su oEvaluationo non sia impostataInspection, è possibile accedere ai punteggi di accuratezza tramite l'API, ma non nel portale di Azure AI Foundry. - Impostare la proprietà
model1obbligatoria sull'URI di un modello da testare. - Impostare la proprietà
model2obbligatoria sull'URI di un altro modello da testare. Se non si vogliono confrontare due modelli, usare lo stesso modello permodel1e permodel2. - Impostare la proprietà
datasetobbligatoria sull'URI di un set di dati da usare per il test. - Impostare la proprietà
localeobbligatoria. Usare le impostazioni locali del contenuto del set di dati per la proprietà. Le impostazioni locali non possono essere modificate in un secondo momento. - Impostare la proprietà
displayNameobbligatoria. Questa proprietà è il nome visualizzato nel portale di Azure AI Foundry.
Eseguire una richiesta HTTP POST usando l'URI, come illustrato nell'esempio seguente. Sostituire YourSpeechResoureKey con la chiave della risorsa Voce e YourServiceRegion con l'area della risorsa Voce, quindi impostare le proprietà del corpo della richiesta come descritto in precedenza.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
},
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
La proprietà self di primo livello nel corpo della risposta è l'URI della valutazione. Usare questo URI per ottenere dettagli sul progetto di valutazione e sui risultati del test. È anche possibile usare questo URI per aggiornare o eliminare la valutazione.
Ottenere i risultati dei test
È consigliabile ottenere i risultati del test e valutare la percentuale di errori delle parole (WER) rispetto ai risultati del riconoscimento vocale.
Quando lo stato del test è Succeeded, è possibile visualizzare i risultati. Selezionare il test per visualizzare i risultati.
Per ottenere i risultati dei test, seguire questa procedura:
- Accedere a Speech Studio.
- Selezionare Riconoscimento vocale personalizzato> Nome del progetto >Modelli di test.
- Selezionare il collegamento in base al nome del test.
- Al termine del test, come indicato dallo stato impostato su Operazione completata, verranno visualizzati i risultati che includono il numero di WER per ogni modello testato.
Questa pagina elenca tutte le espressioni del set di dati e i risultati del riconoscimento, insieme alla trascrizione del set di dati inviato. È possibile attivare o disattivare vari tipi di errore, tra cui inserimento, eliminazione e sostituzione. Ascoltando l'audio e confrontando i risultati del riconoscimento in ogni colonna, è possibile decidere quale modello soddisfa le proprie esigenze e determinare dove sono necessari ulteriori training e miglioramenti.
Per ottenere i risultati del test, usare il comando spx csr evaluation status. Creare i parametri della richiesta in base alle istruzioni seguenti:
- Imposta la proprietà obbligatoria
evaluationsull'ID della valutazione per cui si desiderano ottenere i risultati del test.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce che ottiene i risultati del test:
spx csr evaluation status --api-version v3.2 --evaluation 8bfe6b05-f093-4ab4-be7d-180374b751ca
La percentuale di errori delle parole e altri dettagli vengono restituiti nel corpo della risposta.
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Per ottenere la guida dell'interfaccia della riga di comando di Voce per le valutazioni, eseguire il comando seguente:
spx help csr evaluation
Per ottenere i risultati del test, iniziare usando l'operazione Evaluations_Get dell'API REST di riconoscimento vocale.
Effettuare una richiesta HTTP GET usando l'URI come illustrato nell'esempio seguente. Sostituire YourEvaluationId con l'ID di valutazione, sostituire YourSpeechResoureKey con la chiave della risorsa Voce e sostituire YourServiceRegion con l'area della risorsa Voce.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
La percentuale di errori delle parole e altri dettagli vengono restituiti nel corpo della risposta.
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Valutare il WER (tasso di errore parole)
Lo standard di settore per misurare l'accuratezza del modello è la percentuale di errori delle parole (WER). Il WER conta il numero di parole errate identificate durante il riconoscimento e divide la somma per il numero totale di parole fornite nella trascrizione con etichetta umana (N).
Le parole identificate in modo errato rientrano in tre categorie:
- Inserimento (I): parole aggiunte erroneamente nella trascrizione dell'ipotesi
- Eliminazione (D): parole non rilevate nella trascrizione dell'ipotesi
- Sostituzione (S): parole sostituite tra il riferimento e l'ipotesi
Nel portale di Azure AI Foundry e Speech Studio il quoziente viene moltiplicato per 100 e visualizzato come percentuale. I risultati dell'interfaccia della riga di comando di Riconoscimento vocale e dell'API REST non vengono moltiplicati per 100.
$$ WER = {{I+D+S} N}\over\times 100 $$
Ecco un esempio che mostra le parole identificate in modo errato, se confrontate con la trascrizione con etichetta umana:

Il risultato del riconoscimento vocale non è corretto come indicato di seguito:
- Inserimento (I): aggiunta della parola "a"
- Eliminazione (D): eliminata la parola "are"
- Sostituzione (S): sostituita la parola "Jones" per "John"
La percentuale di errori delle parole dell'esempio precedente è del 60%.
Se si desidera replicare le misurazioni WER in locale, è possibile usare lo strumento sclite di NIST Scoring Toolkit (SCTK).
Risolvere gli errori e migliorare il WER
È possibile usare il calcolo del WER dai risultati del riconoscimento automatico per valutare la qualità del modello in uso con la propria app, strumento o prodotto. Un WER del 5-10% è considerato di buona qualità e pronto all'uso. Un WER del 20% è accettabile, ma è consigliabile prendere in considerazione un training aggiuntivo. Un WER pari o superiore al 30% segnala una scarsa qualità e richiede una personalizzazione e un training.
La modalità di distribuzione degli errori è importante. Quando si verificano molti errori di eliminazione, in genere è a causa della debolezza del segnale audio. Per risolvere il problema, è necessario raccogliere i dati audio più vicino all'origine. Gli errori di inserimento indicano che l'audio è stato registrato in un ambiente rumoroso e che potrebbe essere presente una diafonia che causa problemi di riconoscimento. Gli errori di sostituzione si verificano spesso quando un campione insufficiente di termini specifici del dominio viene fornito come trascrizioni con etichetta umana o come testo correlato.
Analizzando i singoli file, è possibile determinare il tipo di errori esistenti e quali errori sono univoci per un file specifico. La comprensione dei problemi a livello di file consente di ottenere miglioramenti mirati.
Valutare il TER (tasso errori token)
Oltre al tasso di errore delle parole, è anche possibile usare la misurazione estesa del TER (tasso di errore token) per valutare la qualità nel formato di visualizzazione end-to-end finale. Oltre al formato lessicale (That will cost $900. invece di that will cost nine hundred dollars), TER tiene conto degli aspetti del formato di visualizzazione, ad esempio punteggiatura, maiuscole e ITN. Altre informazioni su come Visualizzare la formattazione dell'output con il riconoscimento vocale.
Il TER conta il numero di token errati identificati durante il riconoscimento e divide la somma per il numero totale di token forniti nella trascrizione con etichetta umana (N).
$$ TER = {{I+D+S}\over N} \times 100 $$
Anche la formula del calcolo TER è simile a WER. L'unica differenza è che il TER viene calcolato in base al livello del token anziché al livello di parole.
- Inserimento (I): token aggiunti erroneamente nella trascrizione dell'ipotesi
- Eliminazione (D): token non rilevati nella trascrizione dell'ipotesi
- Sostituzione (S): token sostituiti tra il riferimento e l'ipotesi
In un caso reale, è possibile analizzare sia i risultati di WER che quelli di TER per ottenere i miglioramenti desiderati.
Nota
Per misurare il TER, è necessario assicurarsi che i dati di test audio e trascrizioni includano trascrizioni con formattazione di visualizzazione, ad esempio punteggiatura, maiuscole e ITN.
Risultati dello scenario di esempio
Gli scenari di riconoscimento vocale variano in base alla qualità dell'audio e alla lingua (vocabolario e stile del parlato). La tabella seguente esamina quattro scenari comuni:
| Sceneggiatura | Qualità audio | Vocabolario | Modo di parlare |
|---|---|---|---|
| centro di contatto | Bassa, 8 kHz, potrebbero esserci due persone su un canale audio, potrebbe essere compresso | Ristretta, unico per dominio e prodotti | Conversazione, struttura libera |
| Assistente vocale, ad esempio Cortana, o una finestra drive-through | Alta, 16 kHz | Entità pesanti (titoli di canzoni, prodotti, luoghi) | Parole e frasi chiaramente espresse |
| Dettatura (messaggio istantaneo, note, ricerca) | Alta, 16 kHz | Varia | Prendere appunti |
| Sottotitoli video | Varia, incluso l'uso di diversi microfoni, aggiunta di musica | Varia, da riunioni, discorsi recitati, testi musicali | Lettura, preparazione o strutturazione libera |
Scenari diversi producono risultati di qualità diversi. La tabella seguente esamina la valutazione dei contenuti di questi quattro scenari di WER. La tabella mostra quali tipi di errore sono più comuni in ogni scenario. Le percentuali di errore di inserimento, sostituzione ed eliminazione consentono di determinare il tipo di dati da aggiungere per migliorare il modello.
| Sceneggiatura | Qualità del riconoscimento vocale | Errori di inserimento | Errori di eliminazione | Errori di sostituzione |
|---|---|---|---|---|
| centro di contatto | Medio (< 30% di WER) |
Bassa, tranne quando altre persone parlano in background | Può essere alta. I call center possono essere rumorosi e gli altoparlanti che si sovrappongono possono confondere il modello | Medio. I prodotti e i nomi delle persone possono causare questi errori |
| Assistente vocale | Alta (può essere< 10% di WER) |
Basso | Basso | Media, a causa dei titoli delle canzoni, dei nomi dei prodotti o delle località |
| Dettatura | Alta (può essere< 10% di WER) |
Basso | Basso | Alta |
| Sottotitoli video | Dipende dal tipo di video (può essere < 50% di WER) | Basso | Può essere alta a causa della musica, dei rumori, della qualità del microfono | Il gergo può causare questi errori |