Testare la qualità del riconoscimento di un modello di riconoscimento vocale personalizzato
È possibile controllare la qualità del riconoscimento di un modello di riconoscimento vocale personalizzato in Speech Studio. È possibile riprodurre l'audio caricato e determinare se il risultato del riconoscimento fornito è corretto. Dopo aver creato correttamente un test, è possibile vedere in che modo un modello ha trascritto il set di dati audio oppure confrontare i risultati di due modelli affiancati.
Il test di modelli affiancati è utile per individuare il modello di riconoscimento vocale ottimale per un'applicazione. Per una misura obiettiva dell'accuratezza, che richiede l'input dei set di dati di trascrizione, vedere Testare il modello in modo quantitativo.
Importante
Durante il test, il sistema esegue una trascrizione. Questo aspetto è importante da tenere presente, in quanto i prezzi variano in base all'offerta di servizio e al livello della sottoscrizione. Fare sempre riferimento ai prezzi ufficiali di Servizi di Azure AI per i dettagli più recenti.
Creazione di un test
Seguire queste istruzioni per creare un test:
Accedere a Speech Studio.
Passare a Speech Studio>Riconoscimento vocale personalizzato e selezionare il nome del progetto dall'elenco.
Selezionare Modelli di test>Crea nuovo test.
Selezionare Controlla qualità (dati solo audio)>Avanti.
Scegliere un set di dati audio da usare per il test e quindi selezionare Avanti. Se non sono disponibili set di dati, annullare la configurazione, quindi passare al menu set di dati Voce per caricare set di dati.
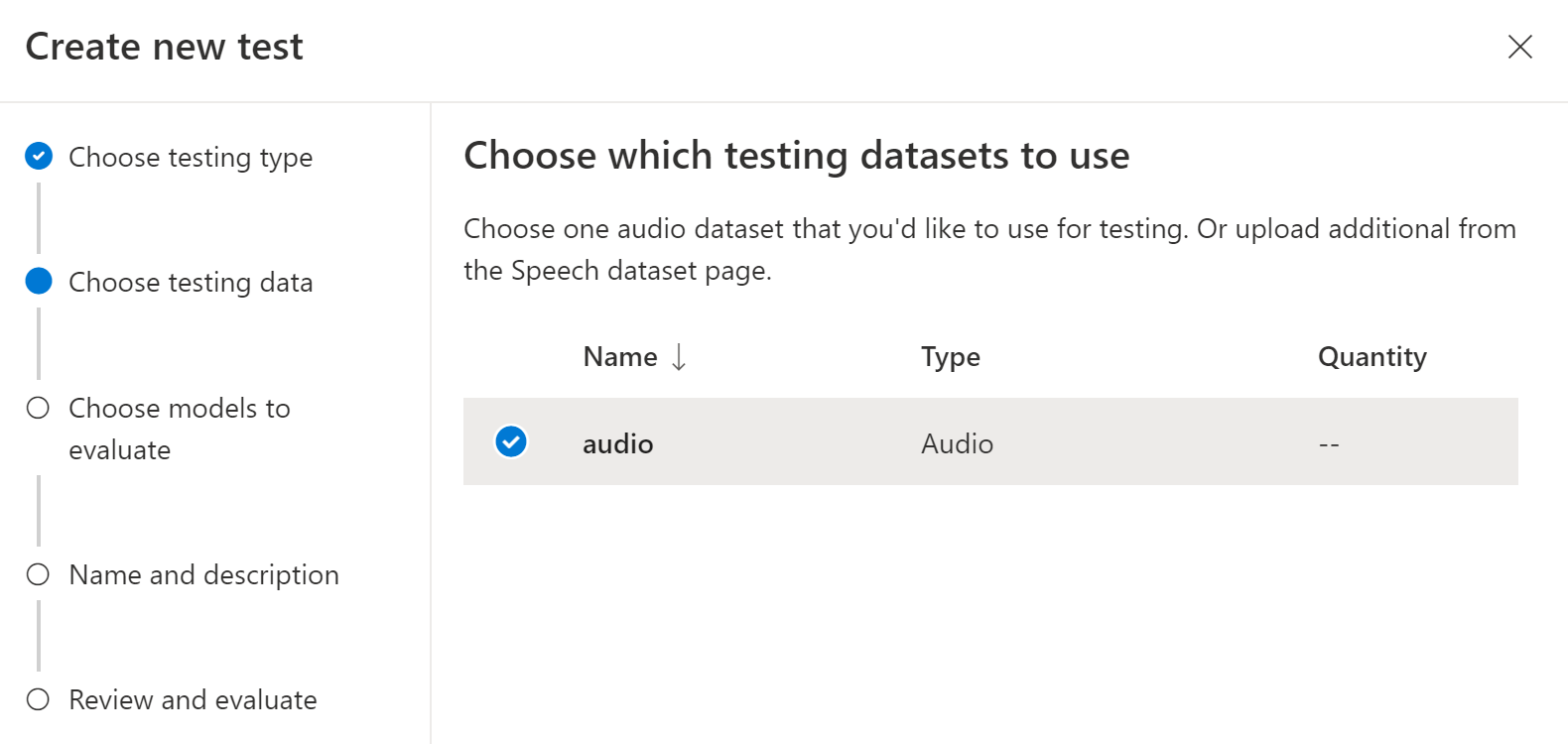
Selezionare uno o due modelli da valutare e di cui confrontare l'accuratezza.
Immettere il nome e la descrizione del test, quindi selezionare Avanti.
Rivedere le impostazioni, quindi selezionare Salva e chiudi.
Per creare un test, usare il comando spx csr evaluation create. Creare i parametri della richiesta in base alle istruzioni seguenti:
- Impostare il parametro
projectsull'ID di un progetto esistente. Questo parametro è consigliato per poter visualizzare il test anche in Speech Studio. È possibile eseguire il comandospx csr project listper ottenere i progetti disponibili. - Impostare il parametro
model1obbligatorio sull'ID di un modello da testare. - Impostare il parametro
model2obbligatorio sull'ID di un altro modello da testare. Se non si vogliono confrontare due modelli, usare lo stesso modello permodel1e permodel2. - Impostare il parametro
datasetobbligatorio sull'ID di un set di dati da usare per il test. - Impostare il parametro
language; in caso contrario, l'interfaccia della riga di comando di Voce usa "en-US" per impostazione predefinita. Usare le impostazioni locali del contenuto del set di dati per il parametro. Le impostazioni locali non possono essere modificate in un secondo momento. Il parametrolanguagedell'interfaccia della riga di comando di Voce corrisponde alla proprietàlocalenella richiesta e nella risposta JSON. - Impostare il parametro
nameobbligatorio. Questo parametro indica il nome visualizzato in Speech Studio. Il parametronamedell'interfaccia della riga di comando di Voce corrisponde alla proprietàdisplayNamenella richiesta e nella risposta JSON.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce che crea un test:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
La proprietà self di primo livello nel corpo della risposta è l'URI della valutazione. Usare questo URI per ottenere informazioni dettagliate sul progetto e sui risultati del test. È anche possibile usare questo URI per aggiornare o eliminare la valutazione.
Per ottenere la guida dell'interfaccia della riga di comando di Voce per le valutazioni, eseguire il comando seguente:
spx help csr evaluation
Per creare un test, usare l'operazione Evaluations_Create dell'API REST Riconoscimento vocale. Creare il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà
projectsull'URI di un progetto esistente. Questa proprietà è consigliata per poter visualizzare il test anche in Speech Studio. È possibile effettuare una richiesta Projects_List per ottenere i progetti disponibili. - Impostare la proprietà
model1obbligatoria sull'URI di un modello da testare. - Impostare la proprietà
model2obbligatoria sull'URI di un altro modello da testare. Se non si vogliono confrontare due modelli, usare lo stesso modello permodel1e permodel2. - Impostare la proprietà
datasetobbligatoria sull'URI di un set di dati da usare per il test. - Impostare la proprietà
localeobbligatoria. Usare le impostazioni locali del contenuto del set di dati per la proprietà. Le impostazioni locali non possono essere modificate in un secondo momento. - Impostare la proprietà
displayNameobbligatoria. Questa proprietà indica il nome visualizzato in Speech Studio.
Eseguire una richiesta HTTP POST usando l'URI, come illustrato nell'esempio seguente. Sostituire YourSubscriptionKey con la chiave della risorsa Voce e YourServiceRegion con l'area della risorsa Voce, quindi impostare le proprietà del corpo della richiesta come descritto in precedenza.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
La proprietà self di primo livello nel corpo della risposta è l'URI della valutazione. Usare questo URI per ottenere dettagli sul progetto di valutazione e sui risultati del test. È anche possibile usare questo URI per aggiornare o eliminare la valutazione.
Ottenere i risultati del test
È necessario ottenere i risultati del test e controllare i set di dati audio rispetto ai risultati della trascrizione per ogni modello.
Per ottenere i risultati del test, seguire questa procedura:
- Accedere a Speech Studio.
- Selezionare Riconoscimento vocale personalizzato> Nome del progetto >Modelli di test.
- Selezionare il collegamento in base al nome del test.
- Al termine del test, come indicato dallo stato impostato su Operazione completata, verranno visualizzati i risultati che includono il numero di WER per ogni modello testato.
Questa pagina elenca tutte le espressioni del set di dati e i risultati del riconoscimento, insieme alla trascrizione del set di dati inviato. È possibile attivare o disattivare vari tipi di errore, tra cui inserimento, eliminazione e sostituzione. Ascoltando l'audio e confrontando i risultati del riconoscimento in ogni colonna, è possibile decidere quale modello soddisfa le proprie esigenze e determinare dove sono necessari ulteriori training e miglioramenti.
Per ottenere i risultati del test, usare il comando spx csr evaluation status. Creare i parametri della richiesta in base alle istruzioni seguenti:
- Impostare il parametro
evaluationobbligatorio sull'ID della valutazione di cui si vogliono ottenere i risultati del test.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce che ottiene i risultati del test:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
Nel corpo della risposta vengono restituiti i modelli, il set di dati audio, le trascrizioni e altri dettagli.
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Per ottenere la guida dell'interfaccia della riga di comando di Voce per le valutazioni, eseguire il comando seguente:
spx help csr evaluation
Per ottenere i risultati del test, iniziare usando l'operazione Evaluations_Get dell'API REST di riconoscimento vocale.
Effettuare una richiesta HTTP GET usando l'URI come illustrato nell'esempio seguente. Sostituire YourEvaluationId con l'ID di valutazione, sostituire YourSubscriptionKey con la chiave della risorsa Voce e sostituire YourServiceRegion con l'area della risorsa Voce.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
Nel corpo della risposta vengono restituiti i modelli, il set di dati audio, le trascrizioni e altri dettagli.
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Confrontare la trascrizione con l'audio
È possibile controllare l'output della trascrizione di ogni modello testato rispetto al set di dati di input audio. Se nel test sono stati inclusi due modelli, è possibile confrontare la qualità della trascrizione in modalità affiancata.
Per esaminare la qualità delle trascrizioni:
- Accedere a Speech Studio.
- Selezionare Riconoscimento vocale personalizzato> Nome del progetto >Modelli di test.
- Selezionare il collegamento in base al nome del test.
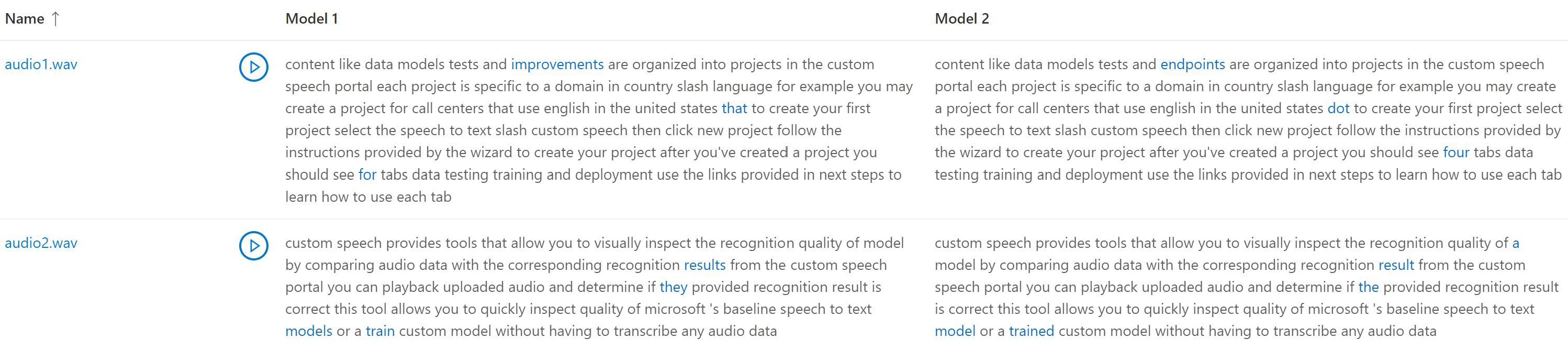
- Riprodurre un file audio durante la lettura della trascrizione corrispondente da un modello.
Se il set di dati di test include più file audio, nella tabella verranno visualizzate più righe. Se nel test sono stati inclusi due modelli, le trascrizioni vengono visualizzate in colonne affiancate. Le differenze di trascrizione tra i modelli vengono visualizzate con il tipo di carattere per il testo di colore blu.
Nei risultati del test vengono restituiti iI set di dati di test audio, le trascrizioni e i modelli testati. Se è stato testato un solo modello, il valore model1 corrisponde a model2 e il valore transcription1 corrisponde a transcription2.
Per esaminare la qualità delle trascrizioni:
- Scaricare il set di dati di test audio, a meno che non sia già disponibile una copia.
- Scaricare le trascrizioni di output.
- Riprodurre un file audio durante la lettura della trascrizione corrispondente da un modello.
Se si confronta la qualità tra due modelli, prestare particolare attenzione alle differenze tra le trascrizioni di ogni modello.
Nei risultati del test vengono restituiti iI set di dati di test audio, le trascrizioni e i modelli testati. Se è stato testato un solo modello, il valore model1 corrisponde a model2 e il valore transcription1 corrisponde a transcription2.
Per esaminare la qualità delle trascrizioni:
- Scaricare il set di dati di test audio, a meno che non sia già disponibile una copia.
- Scaricare le trascrizioni di output.
- Riprodurre un file audio durante la lettura della trascrizione corrispondente da un modello.
Se si confronta la qualità tra due modelli, prestare particolare attenzione alle differenze tra le trascrizioni di ogni modello.