Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Per esaminare le impostazioni locali supportate per l'ID visema e le forme di fusione, vedere l'elenco di tutte le impostazioni locali supportate. Il formato SVG (Scalable Vector Graphics) è supportato solo per le impostazioni locali en-US.
Un visema è la descrizione visiva di un fonema nella lingua parlata. Definisce la posizione del viso e della bocca mentre una persona sta parlando. Ogni visema illustra le pose chiave del viso per un set specifico di fonemi.
È possibile usare i visemi per controllare il movimento dei modelli di avatar 2D e 3D, in modo che le posizioni del viso siano il più possibile allineate alla sintesi vocale. È ad esempio possibile:
- Creare un assistente vocale virtuale animato per chioschi multimediali intelligenti, creando servizi integrati disponibili in più modalità per i clienti.
- Creare notiziari coinvolgenti e migliorare l'esperienza del pubblico con movimenti naturali del viso e della bocca.
- Generare avatar di gioco più interattivi e personaggi dei cartoni animati in grado di parlare con contenuti dinamici.
- Realizzare video didattici più efficaci che aiutino gli studenti a comprendere i movimenti della bocca per ogni parola e fonema.
- Le persone con problemi di udito possono anche percepire visivamente i suoni e "leggere le labbra" su un volto animato il contenuto del discorso raffigurato tramite visemi.
Per altre informazioni sui visema, vedere questo video introduttivo.
Flusso di lavoro generale sulla produzione di visemi con il parlato
La sintesi vocale neurale (Neural Text to speech, TTS) trasforma il testo in ingresso o il linguaggio SSML (Speech Synthesis Markup Language) in parlato sintetizzato realistico. L'output audio del parlato può essere accompagnato da ID visema, SVG (Scalable Vector Graphics) o forme di fusione. Con un motore di rendering 2D o 3D è possibile usare questi eventi visema per animare l'avatar.
Il flusso di lavoro generale del visema è illustrato nel diagramma di flusso seguente:
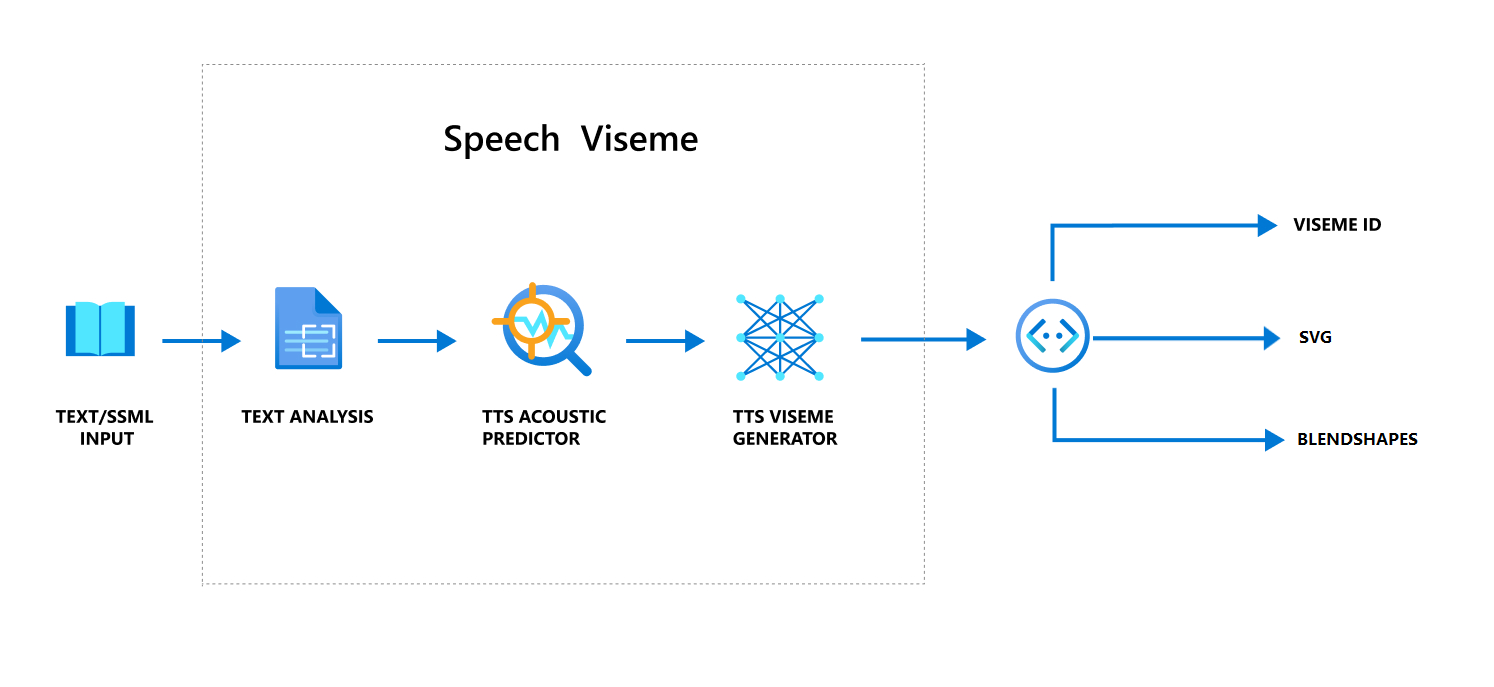
ID Viseme
L'ID visema fa riferimento a un numero intero che specifica un visema. Sono disponibili 22 visemi diversi. Ognuno rappresenta la posizione della bocca per un set specifico di fonemi. Non esiste una corrispondenza uno-a-uno tra visemi e fonemi. Spesso, diversi fonemi corrispondono a un unico visema, perché sembrano identici sul viso del parlante quando vengono prodotti, ad esempio s e z. Per informazioni più specifiche, vedere la tabella del mapping tra fonemi e ID visema.
L'output audio del parlato può essere accompagnato da ID visema e Audio offset. Audio offset indica il timestamp di offset che rappresenta l'ora di inizio di ogni visema, in tick (100 nanosecondi).
Eseguire il mapping di fonemi ai visemi
I visemi variano in base alla lingua e alle impostazioni locali. Per ogni impostazione locale è disponibile un set di visemi che corrispondono ai relativi fonemi specifici. Nella documentazione degli alfabeti fonetici SSML è riportato il mapping degli ID visema ai fonemi dell'Alfabeto fonetico internazionale corrispondente. La tabella di questa sezione mostra la relazione di mapping tra ID visema e posizioni della bocca, elencando i fonemi standard dell'Alfabeto fonetico internazionale per ogni ID visema.
| ID Viseme | Alfabeto fonetico internazionale | Posizione della bocca |
|---|---|---|
| 0 | Silenzio |  |
| 1 | æ, ə, ʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, i, ɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, tʃ, dʒ, ʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, t, n, θ |
 |
| 20 | k, g, ŋ |
 |
| 21 | p, b, m |
 |
Animazione SVG in 2D
Per personaggi 2D è possibile progettare un personaggio adatto allo scenario e usare il formato SVG (Scalable Vector Graphics) per ogni ID visema per ottenere una posizione del viso in funzione del tempo.
Con i tag temporali forniti in un evento visema, questi file SVG correttamente progettati vengono elaborati con modifiche di smoothing e forniscono agli utenti animazioni affidabili. Ad esempio, la figura seguente mostra un personaggio con le labbra rosse progettato per l'apprendimento delle lingue.

Animazione delle forme di fusione 3D
È possibile usare le forme di fusione per controllare i movimenti del viso di un personaggio 3D progettato.
La stringa JSON delle forme di fusione è rappresentata come una matrice bidimensionale. Ogni riga rappresenta un fotogramma. Ogni fotogramma (in 60 FPS) contiene una matrice di 55 posizioni del viso.
Ottenere eventi visema con Speech SDK
Per ottenere il visema con il parlato sintetizzato, sottoscrivere l'evento VisemeReceived in Speech SDK.
Nota
Per richiedere l'output SVG o delle forme di fusione, è necessario usare l'elemento mstts:viseme in SSML. Per informazioni dettagliate, vedere l'articolo su come usare l'elemento visema in SSML.
Il frammento di codice seguente illustra come sottoscrivere l'evento visema:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Ecco un esempio dell'output del visema.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Dopo aver ottenuto l'output del visema, è possibile usare questi eventi per controllare l'animazione dei personaggi. È possibile creare personaggi e animarli automaticamente.