Panoramica della scalabilità automatica del cluster nel servizio Azure Kubernetes (AKS)
Per tenere il passo delle richieste delle applicazioni nel servizio Azure Kubernetes (AKS), potresti aver bisogno di regolare il numero di nodi che eseguono i carichi di lavoro. Il componente di scalabilità automatica del cluster può cercare i pod del cluster che non possono essere pianificati a causa di vincoli delle risorse. Quando la scalabilità automatica del cluster rileva pod non pianificati, aumenta il numero di nodi nel pool di nodi per soddisfare la richiesta dell'applicazione. Controlla regolarmente anche i nodi che non hanno pod pianificati e riduce il numero di nodi in base alle esigenze.
Questo articolo ti aiuta a comprendere come funziona il ridimensionamento automatico del cluster in AKS. Fornisce anche indicazioni, procedure consigliate e considerazioni per la configurazione del ridimensionamento automatico del cluster per i carichi di lavoro in AKS. Se vuoi abilitare, disabilitare o aggiornare il ridimensionamento automatico del cluster per i tuoi carichi di lavoro AKS, vedi Usare il ridimensionamento automatico del cluster in AKS.
Informazioni sul componente di scalabilità automatica
Per adattarsi alle variazioni delle richieste delle applicazioni, ad esempio tra l’orario lavorativo diurno e serale o del fine settimana, è spesso necessario trovare il modo di adattare automaticamente i cluster. I cluster AKS possono essere ridimensionati nei modi seguenti:
- Il componente di scalabilità automatica controlla periodicamente i pod che non possono essere pianificati nei nodi a causa di vincoli delle risorse. Il cluster aumenta quindi automaticamente il numero di nodi. Il ridimensionamento manuale è disabilitato quando si usa il componente di scalabilità automatica del cluster. Per ulteriori informazioni, vedi Come funziona la scalabilità verso l’alto (scale up)?.
- L’utilità di scalabilità automatica orizzontale dei pod usa il server delle metriche in un cluster Kubernetes per monitorare la richiesta di risorse dei pod. Se un'applicazione richiede più risorse, il numero di pod viene aumentato automaticamente per soddisfare la domanda.
- L’utilità di scalabilità automatica orizzontale dei pod imposta automaticamente le richieste di risorse e limiti per i contenitori per carico di lavoro in base all'utilizzo passato per garantire che i pod siano pianificati in nodi che hanno le risorse di CPU e memoria necessarie.
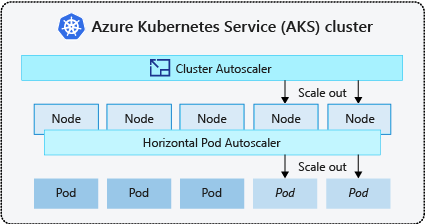
È pratica comune abilitare l’utilità di scalabilità automatica del cluster per i nodi e l’utilità di scalabilità automatica verticale dei pod o l’utilità di scalabilità automatica orizzontale dei pod per i pod. Quando abiliti la scalabilità automatica del cluster, questa applica le regole di ridimensionamento specificate quando le dimensioni del pool di nodi sono inferiori al conteggio minimo dei nodi, fino al conteggio massimo. L’utilità di scalabilità automatica del cluster aspetta di avere effetto finché non è necessario un nuovo nodo nel pool di nodi o finché un nodo non può essere eliminato in modo sicuro dal pool di nodi corrente. Per ulteriori informazioni, vedi Come funziona la scalabilità verso il basso (scale down)?
Procedure consigliate e considerazioni
- Quando si implementano zone di disponibilità con l’utilità di scalabilità automatica del cluster, è consigliabile usare un singolo pool di nodi per ogni zona. Puoi impostare il parametro
--balance-similar-node-groupssuTrueper mantenere una distribuzione bilanciata di nodi tra zone per i tuoi carichi di lavoro durante le operazioni di scale up. Quando questo approccio non viene implementato, le operazioni di scale down possono compromettere il bilanciamento dei nodi tra le zone. - Per i cluster con più di 400 nodi, è consigliabile usare Azure CNI o Azure CNI Overlay.
- Per eseguire in modo efficace i carichi di lavoro simultaneamente nei pool di nodi sia spot che fissi, è consigliabile usare espansori con priorità. Questo approccio ti consente di pianificare i pod in base alla priorità del pool di nodi.
- Presta attenzione quando assegni richieste di CPU/memoria nei pod. L'utilità di scalabilità automatica del cluster aumenta in base ai pod in sospeso anziché alla pressione della CPU/memoria sui nodi.
- Per i cluster che ospitano simultaneamente carichi di lavoro a esecuzione prolungata, ad esempio app Web e carichi di lavoro di processi brevi/burst, è consigliabile separarli in pool di nodi distinti con Affinity Rules/expanders (espansori di regole di affinità) o usare PriorityClass (classe di priorità) per evitare operazioni di svuotamento o scale down dei nodi non necessarie.
- In un pool di nodi abilitato per la scalabilità automatica, ridurre i nodi rimuovendo i carichi di lavoro, invece di ridurre manualmente il numero di nodi. Ciò può rappresentare un problema se il pool di nodi è già alla capacità massima o se sono presenti carichi di lavoro attivi in esecuzione nei nodi, causando potenzialmente un comportamento imprevisto da parte della scalabilità automatica del cluster.
- I nodi non aumentano se i pod hanno un valore PriorityClass inferiore a -10. La priorità -10 è riservata ai pod di provisioning eccessivo. Per ulteriori informazioni, vedi Uso del ridimensionamento automatico del cluster con priorità e prelazione pod.
- Non combinare altri meccanismi di scalabilità automatica dei nodi, ad esempio utilità di scalabilità automatica del set di scalabilità di macchine virtuali con l’utilità di scalabilità automatica del cluster.
- L’utilità di scalabilità automatica del cluster potrebbe non essere in grado di effettuare la riduzione qualora non fosse possibile spostare i pod, ad esempio nelle situazioni seguenti:
- Un pod creato direttamente non supportato da un oggetto controller, come un set di distribuzioni o di repliche (Deployment o ReplicaSet).
- Un budget di interruzione dei pod (PDB) troppo restrittivo e che non permette la riduzione del numero di pod sotto una determinata soglia.
- Un pod che utilizza selettori di nodo o anti-affinità impossibili da rispettare se pianificati in un nodo diverso. Per ulteriori informazioni, vedi Quali tipi di pod possono impedire all’unità di scalabilità automatica del cluster di rimuovere un nodo?.
Importante
Non apportare modifiche ai singoli nodi all'interno dei pool di nodi con scalabilità automatica. Tutti i nodi nello stesso gruppo di nodi devono avere capacità, etichette, taint e pod di sistema uniformi in esecuzione su di essi.
- La scalabilità automatica del cluster non è responsabile dell'applicazione di un "numero massimo di nodi" in un pool di nodi del cluster indipendentemente dalle considerazioni sulla pianificazione dei pod. Se un attore di scalabilità automatica non cluster imposta il conteggio dei pool di nodi su un numero superiore al massimo configurato dal ridimensionamento automatico del cluster, il ridimensionamento automatico del cluster non rimuove automaticamente i nodi. I comportamenti di riduzione delle prestazioni della scalabilità automatica del cluster rimangono limitati alla rimozione solo dei nodi che non dispongono di pod pianificati. L'unico scopo della configurazione del conteggio massimo di nodi della scalabilità automatica del cluster è applicare un limite superiore per le operazioni di aumento delle prestazioni. Non ha alcun effetto sulle considerazioni sulla riduzione delle prestazioni.
Profilo dell'utilità di scalabilità automatica del cluster
Il profilo dell'utilità di scalabilità automatica del cluster è un set di parametri che controllano il comportamento dell'utilità di scalabilità automatica del cluster. Puoi configurare il profilo dell'utilità di scalabilità automatica del cluster quando crei un cluster o aggiorni un cluster esistente.
Ottimizzazione del profilo dell'utilità di scalabilità automatica del cluster
Dovresti ottimizzare le impostazioni del profilo dell'utilità di scalabilità automatica del cluster in base agli scenari di carico di lavoro specifici, considerando anche i compromessi tra prestazioni e costi. In questa sezione vengono forniti esempi che illustrano tali compromessi.
È importante notare che le impostazioni del profilo dell'utilità di scalabilità automatica del cluster sono a livello di cluster e applicate a tutti i pool di nodi abilitati per la scalabilità automatica. Tutte le azioni di ridimensionamento eseguite in un pool di nodi possono influire sul comportamento di scalabilità automatica di altri pool di nodi, causando risultati imprevisti. Assicurati di applicare configurazioni del profilo coerenti e sincronizzate in tutti i pool di nodi pertinenti per avere la certezza di ottenere i risultati desiderati.
Esempio 1: Ottimizzazione delle prestazioni
Per i cluster che gestiscono carichi di lavoro sostanziali e burst con particolare attenzione alle prestazioni, è consigliabile aumentare il scan-interval e ridurre il scale-down-utilization-threshold. Queste impostazioni consentono di eseguire il batch di più operazioni di dimensionamento in una singola chiamata, ottimizzando il tempo di dimensionamento e l'utilizzo delle quote di lettura/scrittura di calcolo. Consentono anche di ridurre il rischio di operazioni rapide di scale down nei nodi sottoutilizzati, migliorando l'efficienza di pianificazione dei pod. Aumentare anche ok-total-unready-count e max-total-unready-percentage.
Per i cluster con pod daemonset, è consigliabile impostare ignore-daemonset-utilization su true, in modo da far ignorare in modo efficace l'utilizzo dei nodi dai pod daemonset e ridurre al minimo le operazioni di scale down non necessarie. Vedere il profilo per carichi di lavoro bursty
Esempio 2: Ottimizzazione dei costi
Se si vuole un profilo ottimizzato per i costi, è consigliabile impostare le configurazioni dei parametri seguenti:
- Ridurre
scale-down-unneeded-time, ovvero la quantità di tempo per cui un nodo non deve essere necessario prima che sia idoneo per eseguire lo scale down. - Ridurre
scale-down-delay-after-add, ovvero la quantità di tempo di attesa dopo l'aggiunta di un nodo prima di considerarlo per eseguire lo scale down. - Aumentare
scale-down-utilization-threshold, ovvero la soglia di utilizzo per la rimozione dei nodi. - Aumentare
max-empty-bulk-delete, ovvero il numero massimo di nodi che possono essere eliminati in una singola chiamata. - Impostare
skip-nodes-with-local-storagesu False. - Aumentare
ok-total-unready-countemax-total-unready-percentage.
Problemi comuni e raccomandazioni per la mitigazione
Visualizzare gli errori di scalabilità e aumentare le prestazioni degli eventi non attivati tramite l'interfaccia della riga di comando o il portale.
Mancata attivazione di operazioni di scale up
| Cause comuni | Raccomandazioni per la mitigazione |
|---|---|
| Conflitti di affinità dei nodi PersistentVolume, che possono verificarsi quando si usa l’unità di scalabilità automatica del cluster con più zone di disponibilità o quando la zona del volume permanente o di un pod differisce dalla zona del nodo. | Usare un pool di nodi per zona di disponibilità e abilitare --balance-similar-node-groups. Puoi anche impostare il campo volumeBindingMode su WaitForFirstConsumer nella specifica del pod per impedire che il volume venga associato a un nodo fino a quando non viene creato un pod usando il volume. |
| Conflitti di affinità Taints and Tolerations/Node (Nodo/Contaminazioni e tolleranze) | Valutare le contaminazioni assegnate ai nodi ed esaminare le tolleranze definite nei pod. Se necessario, apporta modifiche a contaminazioni e tolleranze per assicurarti che i pod possano essere pianificati in modo efficiente nei nodi. |
Errori nelle operazioni di scale up
| Cause comuni | Raccomandazioni per la mitigazione |
|---|---|
| Esaurimento degli indirizzi IP nella subnet | Aggiungi un'altra subnet nella stessa rete virtuale e aggiungi un altro pool di nodi nella nuova subnet. |
| Esaurimento della quota di core | La quota di core approvata è stata esaurita. Richiedi un aumento della quota. L’entità di scalabilità automatica del cluster entra in uno stato di backoff esponenziale all'interno del gruppo di nodi specifico quando si verificano più tentativi di scale up non riusciti. |
| Dimensioni massime del pool di nodi | Aumenta il numero massimo di nodi nel pool di nodi o crea un nuovo pool di nodi. |
| Richieste/chiamate che superano il limite di velocità | Vedi Errori 429 Troppe richieste. |
Errori delle operazioni di scale down
| Cause comuni | Raccomandazioni per la mitigazione |
|---|---|
| Pod che impedisce lo svuotamento del nodo/Non in grado di rimuovere il pod | • Visualizza quali tipi di pod possono impedire lo scale down. • Per i pod che usano l'archiviazione locale, ad esempio hostPath e emptyDir, imposta il flag del profilo dell’entità di scalabilità automatica del cluster skip-nodes-with-local-storage su false. • Nella specifica del pod, imposta l'annotazione cluster-autoscaler.kubernetes.io/safe-to-evict su true. • Controlla il tuo PDB, in quanto potrebbe essere restrittivo. |
| Dimensioni minime del pool di nodi | Riduci le dimensioni minime del pool di nodi. |
| Richieste/chiamate che superano il limite di velocità | Vedi Errori 429 Troppe richieste. |
| Operazioni di scrittura bloccate | Non apportare modifiche al gruppo di risorse AKS completamente gestito (vedi Criteri di supporto AKS). Rimuovi o reimposta i blocchi delle risorse applicati in precedenza al gruppo di risorse. |
Altri problemi
| Cause comuni | Raccomandazioni per la mitigazione |
|---|---|
| PriorityConfigMapNotMatchedGroup | Assicurati di aggiungere tutti i gruppi di nodi che richiedono la scalabilità automatica al file di configurazione dell'espansore. |
Pool di nodi nel backoff
Il pool di nodi nel backoff è stato introdotto nella versione 0.6.2 e fa sì che l'utilità di scalabilità automatica del cluster esegua il dimensionamento di un pool di nodi dopo un errore.
A seconda della durata degli errori riscontrati dalle operazioni di ridimensionamento, potrebbero essere necessari fino a 30 minuti prima di eseguire un altro tentativo. È possibile reimpostare lo stato di backoff del pool di nodi disabilitando e poi riabilitando la scalabilità automatica.

Azure Kubernetes Service