Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa esercitazione si creerà un'applicazione Java Retrieval Augmented Generation (RAG) usando Spring Boot, Azure OpenAI e Azure AI Search e distribuirla in Azure App Service. Questa applicazione illustra come implementare un'interfaccia di chat che recupera informazioni dai propri documenti e sfrutta i servizi di intelligenza artificiale in Azure per fornire risposte accurate e con riconoscimento contestuale con citazioni appropriate. La soluzione usa le identità gestite per l'autenticazione senza password tra i servizi.
Suggerimento
Anche se questa esercitazione usa Spring Boot, i concetti di base per la creazione di un'applicazione RAG con Azure OpenAI e Azure AI Search si applicano a qualsiasi applicazione Web Java. Se si usa un'opzione di hosting diversa nel servizio app, ad esempio Tomcat o JBoss EAP, è possibile adattare i modelli di autenticazione e l'utilizzo Azure SDK mostrati qui nel framework preferito.
In questa esercitazione si apprenderà come:
- Distribuire un'applicazione Spring Boot che usa il modello RAG con i servizi di intelligenza artificiale in Azure.
- Configurare Azure OpenAI e Azure AI Search per la ricerca ibrida.
- Caricare e indicizzare documenti da usare nell'applicazione basata su intelligenza artificiale.
- Usare le identità gestite per la comunicazione sicura da servizio a servizio.
- Testare l'implementazione rag in locale con i servizi di produzione.
Panoramica dell'architettura
Prima di iniziare la distribuzione, è utile comprendere l'architettura dell'applicazione che verrà compilata. Il diagramma seguente proviene dal modello RAG Custom per Azure AI Search:
diagramma di architettura che mostra un'applicazione web che si connette ad Azure OpenAI e Azure AI Search, con memoria come origine dati
In questa esercitazione l'applicazione Blazer nel servizio app si occupa sia dell'esperienza utente dell'app che del server app. Tuttavia, non esegue un'interrogazione di conoscenza separata per Azure AI Search. In alternativa, indica Azure OpenAI di eseguire le query sulle informazioni specificando Azure AI Search come origine dati. Questa architettura offre diversi vantaggi principali:
- Integrated Vectorization: le funzionalità di vettorializzazione integrata di Azure AI Search rendono facile e veloce l'acquisizione per la ricerca di tutti i documenti, senza richiedere più codice per la generazione degli embedding.
- Accesso API Semplificato: Usando il modello Azure OpenAI sui Tuoi Dati con Azure AI Search come origine dati per i completamenti di Azure OpenAI, non è necessario implementare la ricerca o la generazione di embedding complessi. Si tratta di una sola chiamata API e Azure OpenAI gestisce tutti gli elementi, inclusa la progettazione dei prompt e l'ottimizzazione delle query.
- Funzionalità di ricerca avanzate: la vettorizzazione integrata fornisce tutto ciò che serve per la ricerca ibrida avanzata con reranking semantico, che combina i punti di forza della corrispondenza delle parole chiave, la somiglianza vettoriale e la classificazione basata sull'intelligenza artificiale.
- Supporto completo per la citazione: le risposte includono automaticamente citazioni nei documenti di origine, rendendo le informazioni verificabili e tracciabili.
Prerequisiti
- Un account Azure con una sottoscrizione attiva- Creare un account gratuitamente.
- Un account GitHub per utilizzare GitHub Codespaces: Altre informazioni su GitHub Codespaces.
1. Aprire l'esempio con Codespaces
Il modo più semplice per iniziare consiste nell'usare GitHub Codespaces, che offre un ambiente di sviluppo completo con tutti gli strumenti necessari preinstallati.
Passare al repository GitHub su https://github.com/Azure-Samples/app-service-rag-openai-ai-search-java.
Selezionare il pulsante Codice , selezionare la scheda Codespaces e fare clic su Crea spazio di codice nel main.
Attendere alcuni istanti per inizializzare Codespace. Quando si è pronti, nel browser verrà visualizzato un ambiente VS Code completamente configurato.
2. Distribuire l'architettura di esempio
Nel terminale accedere a Azure usando l'interfaccia della riga di comando per sviluppatori di Azure:
azd auth loginSeguire le istruzioni per completare il processo di autenticazione.
Effettuare il provisioning delle risorse Azure con il modello AZD:
azd provisionQuando richiesto, fornire le risposte seguenti:
Domanda Risposta Immettere un nuovo nome di ambiente: Digitare un nome univoco. Selezionare una sottoscrizione Azure da usare: Selezionare la sottoscrizione. Selezionare un gruppo di risorse da usare: Selezionare Crea un nuovo gruppo di risorse. Selezionare un percorso in cui creare il gruppo di risorse: Selezionare un'area qualsiasi. Le risorse verranno effettivamente create negli Stati Uniti orientali 2. Immettere un nome per il nuovo gruppo di risorse: Digitare INVIO. Attendere il completamento della distribuzione. Questo processo:
- Creare tutte le risorse necessarie Azure.
- Distribuire l'applicazione in Azure App Service.
- Configurare l'autenticazione sicura tra servizi utilizzando identità gestite.
- Configurare le assegnazioni di ruolo necessarie per l'accesso sicuro tra i servizi.
Annotazioni
Per altre informazioni sul funzionamento delle identità gestite, vedere Che sono identità gestite per le risorse Azure? e Come usare le identità gestite con il servizio app.
Dopo aver completato la distribuzione, verrà visualizzato un URL per l'applicazione distribuita. Prendere nota di questo URL, ma non accedervi perché è comunque necessario configurare l'indice di ricerca.
3. Caricare documenti e creare un indice di ricerca
Dopo aver distribuito l'infrastruttura, è necessario caricare i documenti e creare un indice di ricerca che verrà usato dall'applicazione:
Nel portale di Azure passare all'account di archiviazione creato dalla distribuzione. Il nome inizierà con il nome dell'ambiente specificato in precedenza.
SelezionareContenitori> dal menu di spostamento a sinistra e aprire il contenitore documenti.
Caricare documenti di esempio facendo clic su Carica. È possibile usare i documenti di esempio della cartella
sample-docsnel repository oppure i propri file PDF, Word o di testo.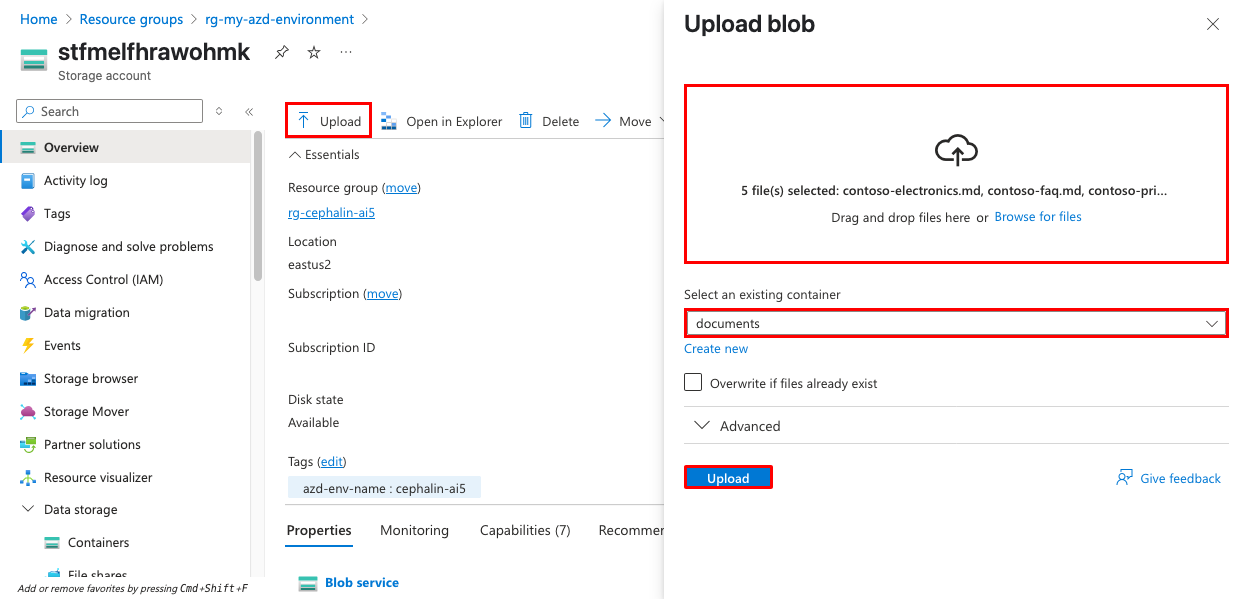
Accedere al servizio di ricerca Azure AI nel portale di Azure.
Selezionare Importa dati (nuovo) per avviare il processo di creazione di un indice di ricerca.
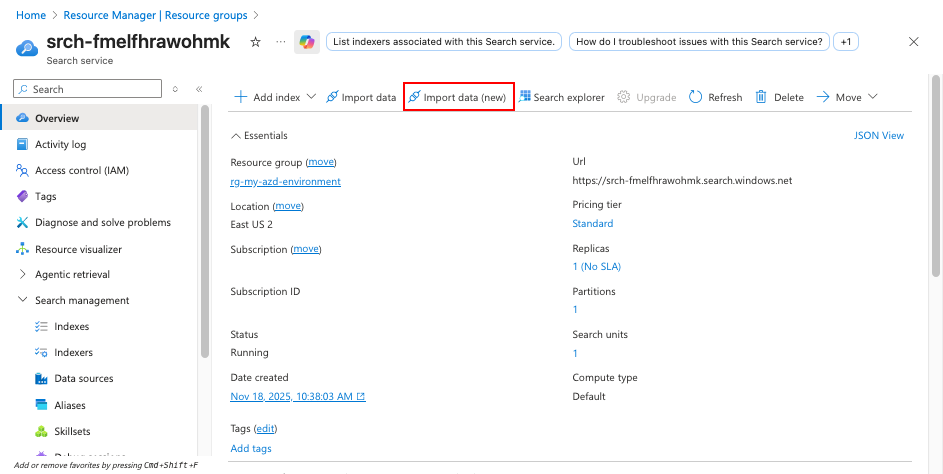
Nel passaggio Connetti ai dati :
- Selezionare Azure Blob Storage come origine dati.
- Selezionare RAG.
- Scegli l'account di archiviazione e il contenitore di documenti.
- Selezionare Autenticati con l'identità gestita.
- Seleziona Avanti.
Nel passaggio Vettorializza il testo :
- Seleziona il servizio Azure OpenAI.
- Scegliere text-embedding-ada-002 come modello di incorporamento. Il template AZD ha già distribuito questo modello per te.
- Selezionare Identità assegnata dal sistema per l'autenticazione.
- Selezionare la casella di controllo per l'accettazione dei costi aggiuntivi.
- Seleziona Avanti.
Suggerimento
Ulteriori informazioni sulla ricerca vettoriale in Azure AI Search e sugli incorporamenti di testo in Azure OpenAI.
Nel passaggio Vectorize and enrich your images (Vettorializzare e arricchire le immagini):
- Mantenere le impostazioni predefinite.
- Seleziona Avanti.
Nel passaggio Impostazioni avanzate :
- Verificare che l'opzione Abilita classificazione semantica sia selezionata.
- (Facoltativo) Selezionare una pianificazione di indicizzazione. Ciò è utile se si desidera aggiornare regolarmente l'indice con le modifiche più recenti del file.
- Seleziona Avanti.
Nel passaggio Rivedi e crea :
- Copiare il valore del prefisso dei nomi degli oggetti. Si tratta del nome dell'indice di ricerca.
- Selezionare Crea per avviare il processo di indicizzazione.
Attendere il completamento del processo di indicizzazione. L'operazione potrebbe richiedere alcuni minuti a seconda delle dimensioni e del numero dei documenti.
Per testare l'importazione dei dati, selezionare Avvia la ricerca e provare una query di ricerca come "Informazioni sull'azienda".
Tornare al terminale Codespace, impostare il nome dell'indice di ricerca come variabile di ambiente AZD:
azd env set SEARCH_INDEX_NAME <your-search-index-name>Sostituire
<your-search-index-name>con il nome dell'indice copiato in precedenza. AZD usa questa variabile nelle distribuzioni successive per impostare l'impostazione dell'app del servizio app.
4. Testare l'applicazione e distribuire
Se si preferisce testare l'applicazione in locale prima o dopo la distribuzione, è possibile eseguirla direttamente da Codespace:
Nel terminale Codespace ottenere i valori dell'ambiente AZD:
azd env get-valuesAprire src/main/resources/application.properties. Usando l'output del terminale, aggiornare i valori seguenti nei rispettivi segnaposto
<input-manually-for-local-testing>:azure.openai.endpointazure.search.urlazure.search.index.name
Accedere a Azure con il Azure CLI:
az loginIn questo modo la libreria client Azure Identity nel codice di esempio riceve un token di autenticazione per l'utente connesso.
Eseguire l'applicazione in locale:
mvn spring-boot:runQuando viene visualizzato L'applicazione in esecuzione sulla porta 8080 è disponibile, selezionare Apri nel browser.
Provare a porre alcune domande nell'interfaccia della chat. Se si riceve una risposta, l'applicazione si connette correttamente alla risorsa OpenAI Azure.
Arrestare il server di sviluppo con CTRL+C.
Applicare la nuova configurazione
SEARCH_INDEX_NAMEin Azure e distribuire il codice dell'applicazione di esempio:azd up
5. Testare l'applicazione RAG distribuita
Con l'applicazione completamente distribuita e configurata, è ora possibile testare la funzionalità RAG:
Aprire l'URL dell'applicazione fornito alla fine della distribuzione.
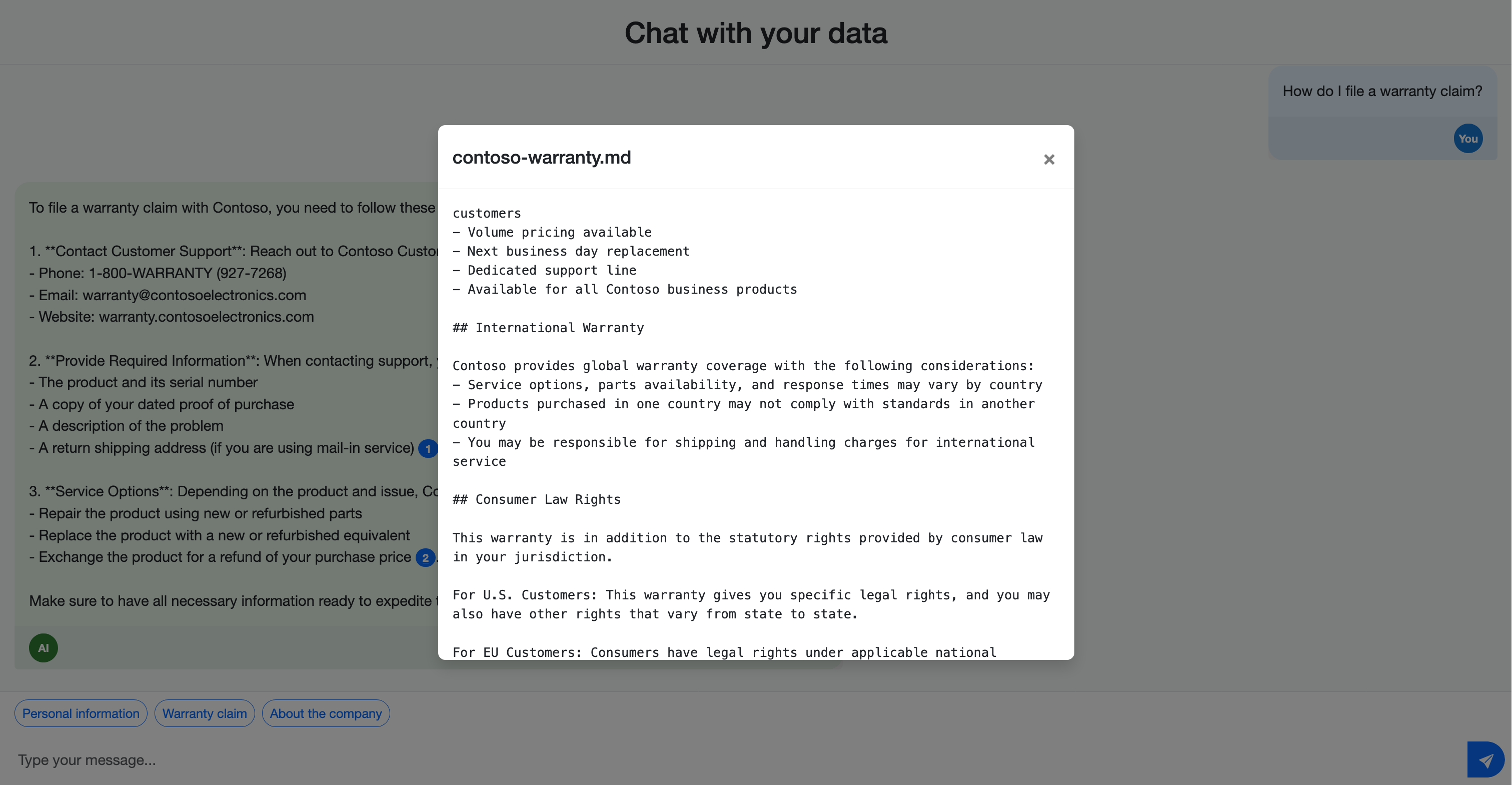
Viene visualizzata un'interfaccia di chat in cui è possibile immettere domande sul contenuto dei documenti caricati.
Provare a porre domande specifiche per il contenuto dei documenti. Ad esempio, se i documenti sono stati caricati nella cartella sample-docs , è possibile provare queste domande:
- In che modo Contoso usa i dati personali?
- Come si effettua la richiesta di garanzia?
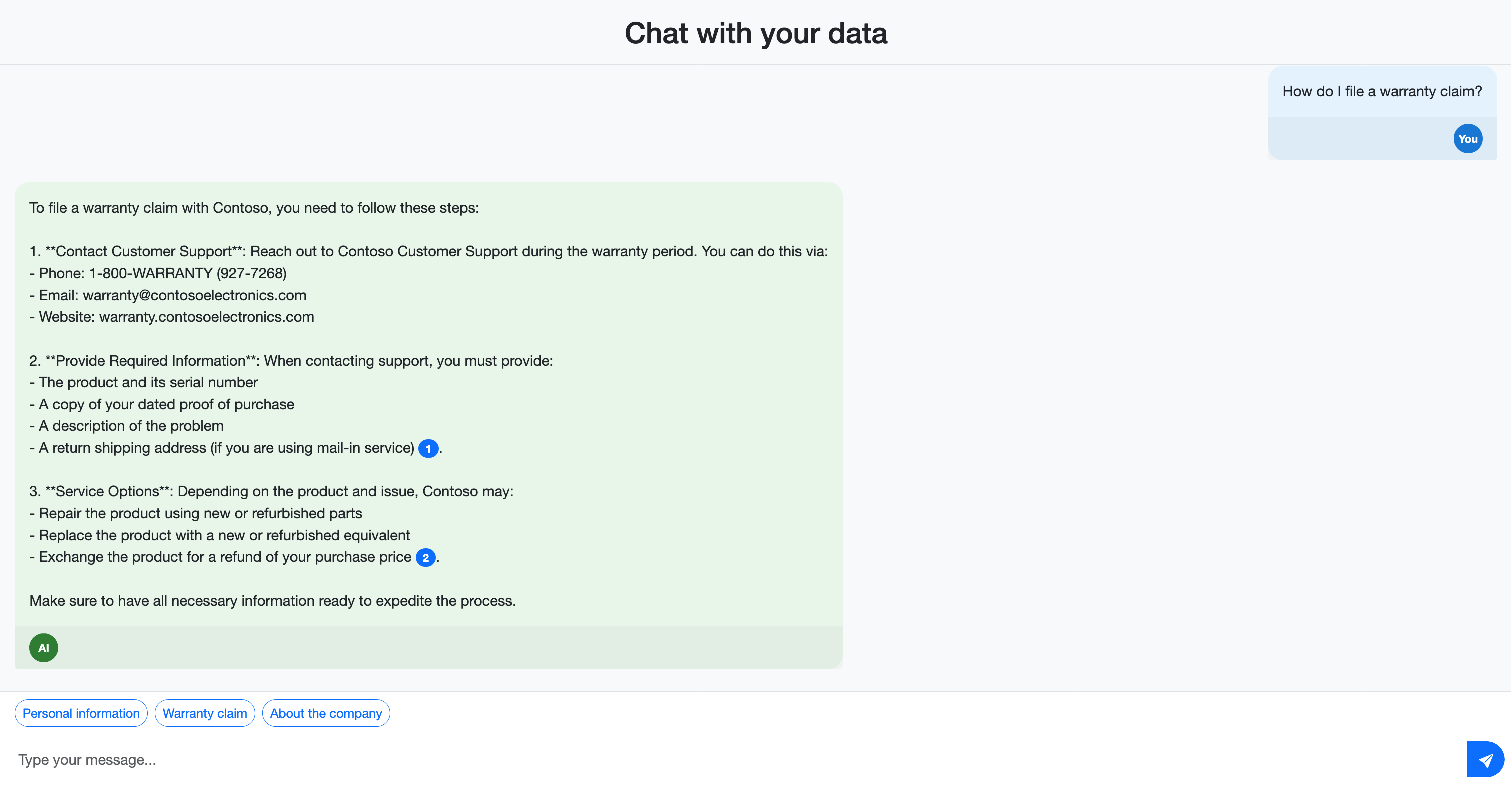
Si noti che le risposte includono citazioni che fanno riferimento ai documenti di origine. Queste citazioni aiutano gli utenti a verificare l'accuratezza delle informazioni e trovare altri dettagli nel materiale di origine.
Testare le funzionalità di ricerca ibrida ponendo domande che potrebbero trarre vantaggio da approcci di ricerca diversi:
- Domande con terminologia specifica (valida per la ricerca di parole chiave).
- Domande sui concetti che potrebbero essere descritti usando termini diversi (validi per la ricerca vettoriale).
- Domande complesse che richiedono un contesto di comprensione (valido per la classificazione semantica).
Pulire le risorse
Al termine dell'applicazione, è possibile eliminare tutte le risorse per evitare di sostenere ulteriori costi:
azd down --purge
Questo comando elimina tutte le risorse associate all'applicazione.
Domande frequenti
- Come fa il codice di esempio a recuperare le citazioni dai completamenti della chat di Azure OpenAI?
- Qual è il vantaggio dell'uso delle identità gestite in questa soluzione?
- Come viene usata l'identità gestita assegnata dal sistema in questa architettura e nell'applicazione di esempio?
- Come viene implementata la ricerca ibrida con il ranker semantico nell'applicazione di esempio?
- Perché tutte le risorse vengono create negli Stati Uniti orientali 2?
- È possibile usare modelli OpenAI personalizzati anziché quelli forniti da Azure?
- Come posso migliorare la qualità delle risposte?
In che modo il codice di esempio recupera le citazioni dai completamenti della chat di Azure OpenAI?
L'esempio recupera le citazioni usando AzureSearchChatExtensionConfiguration come origine dati per il client di chat. Quando viene richiesto un completamento della chat, la risposta include un Citations oggetto all'interno del contesto del messaggio. Il codice estrae queste citazioni come segue:
public static ChatResponse fromChatCompletions(ChatCompletions completions) {
ChatResponse response = new ChatResponse();
if (completions.getChoices() != null && !completions.getChoices().isEmpty()) {
var message = completions.getChoices().get(0).getMessage();
if (message != null) {
response.setContent(message.getContent());
if (message.getContext() != null && message.getContext().getCitations() != null) {
var azureCitations = message.getContext().getCitations();
for (int i = 0; i < azureCitations.size(); i++) {
var azureCitation = azureCitations.get(i);
Citation citation = new Citation();
citation.setIndex(i + 1);
citation.setTitle(azureCitation.getTitle());
citation.setContent(azureCitation.getContent());
citation.setFilePath(azureCitation.getFilepath());
citation.setUrl(azureCitation.getUrl());
response.getCitations().add(citation);
}
}
}
}
return response;
}
Nella risposta di chat, il contenuto usa [doc#] la notazione per fare riferimento alla citazione corrispondente nell'elenco, consentendo agli utenti di tracciare le informazioni nei documenti di origine originali. Per altre informazioni, vedere:
Qual è il vantaggio dell'uso delle identità gestite in questa soluzione?
Le identità gestite eliminano la necessità di archiviare le credenziali nel codice o nella configurazione. Usando le identità gestite, l'applicazione può accedere in modo sicuro ai servizi Azure come Azure OpenAI e Azure AI Search senza gestire i segreti. Questo approccio segue i principi di sicurezza Zero Trust e riduce il rischio di esposizione delle credenziali.
Come viene usata l'identità gestita assegnata dal sistema in questa architettura e nell'applicazione di esempio?
La distribuzione AZD crea identità gestite assegnate dal sistema per Azure App Service, Azure OpenAI e Azure AI Search. Esegue anche le rispettive assegnazioni di ruolo per ognuna di esse (vedere il file main.bicep ). Per informazioni sulle assegnazioni di ruolo necessarie, vedere Configurazione di rete e accesso per Azure OpenAI sui tuoi dati.
Nell'applicazione di esempio Java, l'Azure SDKs usare questa identità gestita per l'autenticazione sicura, quindi non è necessario archiviare credenziali o segreti in qualsiasi posizione. Ad esempio, l'OpenAIAsyncClient viene inizializzato con DefaultAzureCredential, che usa automaticamente l'identità gestita durante l'esecuzione in Azure:
@Bean
public TokenCredential tokenCredential() {
return new DefaultAzureCredentialBuilder().build();
}
@Bean
public OpenAIAsyncClient openAIClient(TokenCredential tokenCredential) {
return new OpenAIClientBuilder()
.endpoint(openAiEndpoint)
.credential(tokenCredential)
.buildAsyncClient();
}
Analogamente, quando si configura l'origine dati per Azure AI Search, l'identità gestita viene specificata per l'autenticazione:
AzureSearchChatExtensionConfiguration searchConfiguration =
new AzureSearchChatExtensionConfiguration(
new AzureSearchChatExtensionParameters(appSettings.getSearch().getUrl(), appSettings.getSearch().getIndex().getName())
.setAuthentication(new OnYourDataSystemAssignedManagedIdentityAuthenticationOptions())
// ...
);
Questa configurazione consente la comunicazione sicura senza password tra l'app Spring Boot e i servizi di Azure, seguendo le procedure consigliate per la sicurezza Zero Trust. Altre informazioni su DefaultAzureCredential e sulla libreria client Azure Identity per Java.
Come viene implementata la ricerca ibrida con il ranker semantico nell'applicazione di esempio?
L'applicazione di esempio configura la ricerca ibrida con classificazione semantica usando gli SDK Azure OpenAI e Azure AI Search Java. Nel back-end l'origine dati viene configurata nel modo seguente:
AzureSearchChatExtensionParameters parameters = new AzureSearchChatExtensionParameters(
appSettings.getSearch().getUrl(),
appSettings.getSearch().getIndex().getName())
// ...
.setQueryType(AzureSearchQueryType.VECTOR_SEMANTIC_HYBRID)
.setEmbeddingDependency(new OnYourDataDeploymentNameVectorizationSource(appSettings.getOpenai().getEmbedding().getDeployment()))
.setSemanticConfiguration(appSettings.getSearch().getIndex().getName() + "-semantic-configuration");
Questa configurazione consente all'applicazione di combinare la ricerca vettoriale (somiglianza semantica), la corrispondenza delle parole chiave e la classificazione semantica in una singola query. Il ranker semantico riordina i risultati per restituire le risposte più pertinenti e contestualmente appropriate, che vengono quindi usate da Azure OpenAI per generare risposte.
Il nome della configurazione semantica viene definito automaticamente dal processo di vettorizzazione integrata. Usa il nome dell'indice di ricerca come prefisso e aggiunge come suffisso -semantic-configuration . Ciò garantisce che la configurazione semantica sia associata in modo univoco all'indice corrispondente e segua una convenzione di denominazione coerente.
Perché tutte le risorse vengono create negli Stati Uniti orientali 2?
L'esempio usa i modelli gpt-4o-mini e text-embedding-ada-002 , entrambi disponibili con il tipo di distribuzione Standard negli Stati Uniti orientali 2. Questi modelli vengono scelti anche perché non sono pianificati presto per il ritiro, fornendo stabilità per la distribuzione di esempio. La disponibilità del modello e i tipi di distribuzione possono variare in base all'area, quindi è selezionata l'opzione Stati Uniti orientali 2 per assicurarsi che l'esempio funzioni correttamente. Se si vuole usare un'area o modelli diversi, assicurarsi di selezionare i modelli disponibili per lo stesso tipo di distribuzione nella stessa area. Quando si scelgono modelli personalizzati, controllare le date di disponibilità e ritiro per evitare interruzioni.
- Disponibilità del modello: modelli del servizio Azure OpenAI
- Date di ritiro dei modelli: deprecazioni e ritiri dei modelli del servizio Azure OpenAI.
È possibile usare modelli OpenAI personalizzati anziché quelli forniti da Azure?
Questa soluzione è progettata per funzionare con Azure OpenAI Service. Anche se è possibile modificare il codice per usare altri modelli OpenAI, si perderebbero le funzionalità di sicurezza integrate, il supporto delle identità gestite e l'integrazione senza problemi con Azure AI Search fornita da questa soluzione.
Come posso migliorare la qualità delle risposte?
È possibile migliorare la qualità della risposta:
- Caricamento di documenti più rilevanti e di qualità superiore.
- Modifica delle strategie di suddivisione in blocchi nella pipeline di indicizzazione Azure AI Search. Tuttavia, non è possibile personalizzare la suddivisione in blocchi con la vettorizzazione integrata illustrata in questa esercitazione.
- Sperimentare modelli di prompt diversi nel codice dell'applicazione.
- Ottimizzare la ricerca con altre proprietà nella classe AzureSearchChatExtensionParameters.
- Uso di modelli OpenAI più specializzati Azure per il dominio specifico.