Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra la distribuzione di un'applicazione chatbot basata su Express.jsintegrata con l'estensione sidecar Phi-4 nel servizio app di Azure. Seguendo i passaggi, si apprenderà come configurare un'app Web scalabile, aggiungere un sidecar basato su intelligenza artificiale per funzionalità di conversazione avanzate e testare le funzionalità del chatbot.
L'hosting di un modello linguistico di piccole dimensioni (SLM) offre diversi vantaggi:
- Controllo completo sui dati. Le informazioni riservate non vengono esposte a servizi esterni, che è fondamentale per i settori con requisiti di conformità rigorosi.
- I modelli self-hosted possono essere ottimizzati per soddisfare casi d'uso specifici o requisiti specifici del dominio.
- Latenza di rete ridotta e tempi di risposta più rapidi per un'esperienza utente migliore.
- Controllo completo sull'allocazione delle risorse, garantendo prestazioni ottimali per l'applicazione.
Prerequisiti
- Un account Azure con una sottoscrizione attiva.
- Un account GitHub.
Distribuire l'applicazione di esempio
Nel browser, passare al repository dell'applicazione di esempio.
Avviare un nuovo codespace dal repository.
Accedere con l'account Azure:
az loginAprire il terminale in Codespace ed eseguire i comandi seguenti:
cd use_sidecar_extension/expressapp az webapp up --sku P3MV3
Questo comando di avvio è una configurazione comune per la distribuzione di applicazioni Express.js nel servizio app di Azure. Per altre informazioni, vedere Distribuire un'app Web Node.js in Azure.
Aggiungere l'estensione sidecar Phi-4
In questa sezione si aggiunge l'estensione sidecar Phi-4 all'applicazione ASP.NET Core ospitata nel servizio app di Azure.
- Passare al portale di Azure e passare alla pagina di gestione dell'app.
- Nel menu a sinistra selezionare Distribuzione>Centro di distribuzione.
- Nella scheda Contenitori selezionare Aggiungi>estensione Sidecar.
- Nelle opzioni dell'estensione sidecar, selezionare AI: phi-4-q4-gguf (Sperimentale).
- Specificare un nome per l'estensione sidecar.
- Selezionare Salva per applicare le modifiche.
- Attendere alcuni minuti perché la distribuzione dell'estensione sidecar venga completata. Continuare a selezionare Aggiorna fino a quando la colonna Stato non mostra In esecuzione.
Questa estensione sidecar Phi-4 utilizza un'API di completamento della chat come OpenAI che può rispondere alla risposta di completamento della chat in http://localhost:11434/v1/chat/completions. Per altre informazioni su come interagire con l'API, vedere:
Testare il chatbot
Nella pagina di gestione dell'app selezionare Panoramica nel menu a sinistra.
In Dominio predefinito selezionare l'URL per aprire l'app Web in un browser.
Verificare che l'applicazione chatbot sia in esecuzione e risponda agli input dell'utente.
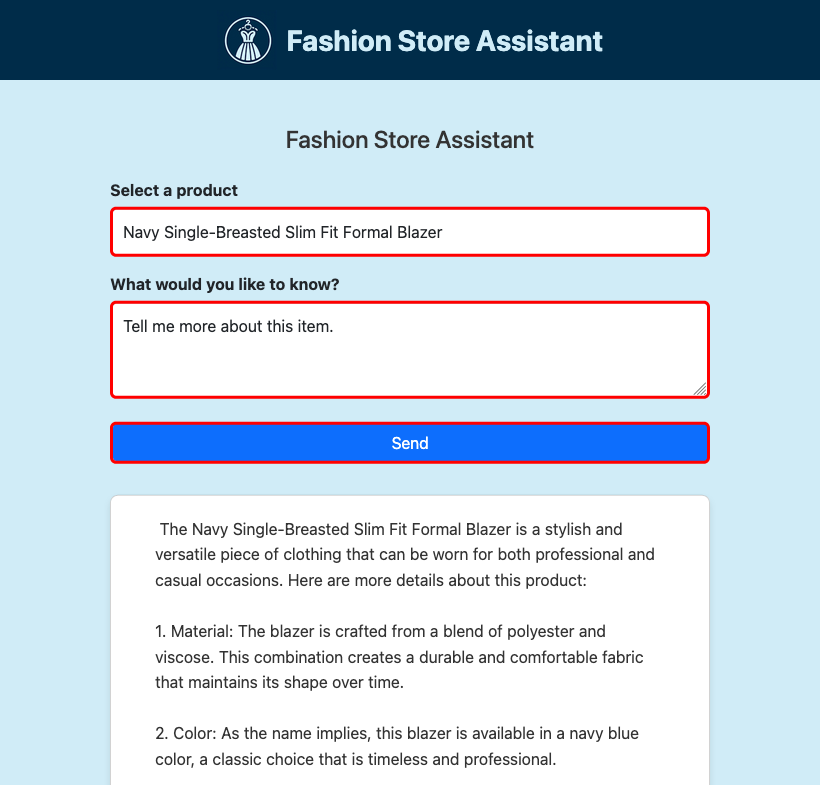
Funzionamento dell'applicazione di esempio
L'applicazione di esempio illustra come integrare un servizio basato su Express.jscon l'estensione sidecar SLM. La SLMService classe incapsula la logica per l'invio di richieste all'API SLM e l'elaborazione delle risposte trasmessi. Questa integrazione consente all'applicazione di generare risposte conversazionali in modo dinamico.
Esaminando use_sidecar_extension/expressapp/src/services/slm_service.js, si noterà che:
Il servizio invia una richiesta POST all'endpoint
http://127.0.0.1:11434/v1/chat/completionsSLM.this.apiUrl = 'http://127.0.0.1:11434/v1/chat/completions';Il payload POST include il messaggio di sistema e la richiesta costruita dal prodotto selezionato e dalla query dell'utente.
const requestPayload = { messages: [ { role: 'system', content: 'You are a helpful assistant.' }, { role: 'user', content: prompt } ], stream: true, cache_prompt: false, n_predict: 2048 // Increased token limit to allow longer responses };La richiesta POST trasmette la riga di risposta per riga. Ogni riga viene analizzata per estrarre il contenuto generato (o il token).
// Set up Server-Sent Events headers res.setHeader('Content-Type', 'text/event-stream'); res.setHeader('Cache-Control', 'no-cache'); res.setHeader('Connection', 'keep-alive'); res.flushHeaders(); const response = await axios.post(this.apiUrl, requestPayload, { headers: { 'Content-Type': 'application/json' }, responseType: 'stream' }); response.data.on('data', (chunk) => { const lines = chunk.toString().split('\n').filter(line => line.trim() !== ''); for (const line of lines) { let parsedLine = line; if (line.startsWith('data: ')) { parsedLine = line.replace('data: ', '').trim(); } if (parsedLine === '[DONE]') { return; } try { const jsonObj = JSON.parse(parsedLine); if (jsonObj.choices && jsonObj.choices.length > 0) { const delta = jsonObj.choices[0].delta || {}; const content = delta.content; if (content) { // Use non-breaking space to preserve formatting const formattedToken = content.replace(/ /g, '\u00A0'); res.write(`data: ${formattedToken}\n\n`); } } } catch (parseError) { console.warn(`Failed to parse JSON from line: ${parsedLine}`); } } });
Domande frequenti
- In che modo il piano tariffario influisce sulle prestazioni del sidecar SLM?
- Come usare il mio sidecar SLM?
In che modo il piano tariffario influisce sulle prestazioni del sidecar SLM?
Poiché i modelli di intelligenza artificiale utilizzano risorse considerevoli, scegliere il piano tariffario che offre vCPU e memoria sufficienti per eseguire il modello specifico. Per questo motivo, le estensioni sidecar IA predefinite sono disponibili solo quando l'app è inclusa in un piano tariffario appropriato. Se si crea un contenitore sidecar SLM, è consigliabile utilizzare anche un modello ottimizzato per la CPU, poiché i piani tariffari del servizio app sono a livello di sola CPU.
Ad esempio, il modello mini Phi-3 con una lunghezza di contesto 4K da Hugging Face è progettato per essere eseguito con risorse limitate e fornisce calcoli matematici e logici forti per molti scenari comuni. Includere anche una versione ottimizzata per la CPU. Nell'App Service, abbiamo testato il modello in tutti i livelli Premium e abbiamo scoperto che offre buone prestazioni nel livello P2mv3 o superiore. Se i requisiti lo consentono, è possibile eseguirla a un livello inferiore.
Come usare il mio sidecar SLM?
Il repository di esempio contiene un contenitore SLM di esempio che è possibile utilizzare come sidecar. Esegue un'applicazione FastAPI in ascolto sulla porta 8000, come specificato nel Dockerfile. L'applicazione utilizza ONNX Runtime per caricare il modello Phi-3, quindi inoltra i dati HTTP POST al modello e trasmette la risposta dal modello al client. Per altre informazioni, vedere model_api.py.
Per compilare manualmente l'immagine sidecar, è necessario installare Docker Desktop in locale nel computer.
Clonare il repository in locale.
git clone https://github.com/Azure-Samples/ai-slm-in-app-service-sidecar cd ai-slm-in-app-service-sidecarAccedi alla directory di origine dell'immagine Phi-3 e scarica localmente il modello usando il Huggingface CLI.
cd bring_your_own_slm/src/phi-3-sidecar huggingface-cli download microsoft/Phi-3-mini-4k-instruct-onnx --local-dir ./Phi-3-mini-4k-instruct-onnxDockerfile è configurato per copiare il modello da ./Phi-3-mini-4k-instruct-onnx.
Compilare l'immagine Docker. Per esempio:
docker build --tag phi-3 .Caricare l'immagine compilata in Registro Azure Container con Eseguire il push della prima immagine nel registro Azure Container usando l'interfaccia della riga di comando di Docker.
Nella scheda Centro di distribuzione>Contenitori (nuovo), selezionare Aggiungi>Contenitore Personalizzato e configurare il nuovo contenitore come indicato di seguito:
- Nome: phi-3
- Origine immagine: Registro Azure Container
- Registro di sistema: il tuo registro
- Immagine: immagine caricata
- Tag: tag immagine desiderato
- Porta: 8000
Selezionare Applica.
Vedere bring_your_own_slm/src/webapp per un'applicazione di esempio che interagisce con questo contenitore sidecar personalizzato.
Passaggi successivi
Esercitazione: Configurare un contenitore sidecar per un'app Linux nel servizio app di Azure