Procedura: Eseguire l'onboarding dei dati delle metriche in Advisor metriche
Importante
A partire dal 20 settembre 2023 non sarà possibile creare nuove risorse di Advisor metriche. Il servizio Advisor metriche viene ritirato il 1° ottobre 2026.
Usare questo articolo per informazioni sull'onboarding dei dati in Advisor metriche.
Requisiti e configurazione dello schema di dati
Advisor metriche di Intelligenza artificiale di Azure è un servizio per il rilevamento, la diagnostica e l'analisi delle anomalie delle serie temporali. Come servizio basato su intelligenza artificiale, usa i dati per eseguire il training del modello usato. Il servizio accetta tabelle di dati aggregati con le colonne seguenti:
- Misura (obbligatorio): una misura è un termine fondamentale o specifico dell'unità e un valore quantificabile della metrica. Significa che una o più colonne contenenti valori numerici.
- Timestamp (facoltativo): zero o una colonna, con tipo o
StringDateTime. Quando questa colonna non è impostata, il timestamp viene impostato come ora di inizio di ogni periodo di inserimento. Formattare il timestamp come indicato di seguito:yyyy-MM-ddTHH:mm:ssZ. - Dimensione (facoltativa): una dimensione è uno o più valori categorici. La combinazione di questi valori identifica una particolare serie temporale univariata , ad esempio paese/area geografica, lingua e tenant. Le colonne della dimensione possono essere di qualsiasi tipo di dati. Prestare attenzione quando si lavora con grandi volumi di colonne e valori, per evitare l'elaborazione di un numero eccessivo di dimensioni.
Se si usano origini dati come Azure Data Lake Archiviazione o Archiviazione BLOB di Azure, è possibile aggregare i dati per allinearli allo schema delle metriche previsto. Ciò è dovuto al fatto che queste origini dati usano un file come input delle metriche.
Se si usano origini dati come Azure SQL o Azure Esplora dati, è possibile usare funzioni di aggregazione per aggregare i dati nel proprio schema previsto. Ciò è dovuto al fatto che queste origini dati supportano l'esecuzione di una query per ottenere i dati delle metriche dalle origini.
Se non si è certi di alcuni termini, vedere Glossario.
Evitare di caricare dati parziali
I dati parziali sono causati da incoerenze tra i dati archiviati in Advisor metriche e l'origine dati. Questo problema può verificarsi quando l'origine dati viene aggiornata dopo che Advisor metriche ha terminato il pull dei dati. Advisor metriche esegue il pull dei dati solo da una determinata origine dati una sola volta.
Ad esempio, se è stata eseguito l'onboarding di una metrica in Advisor metriche per il monitoraggio. Advisor metriche recupera correttamente i dati delle metriche al timestamp A ed esegue il rilevamento anomalie su di esso. Tuttavia, se i dati delle metriche di quel particolare timestamp A sono stati aggiornati dopo l'inserimento dei dati. Il nuovo valore dei dati non verrà recuperato.
È possibile provare a eseguire il backfill dei dati cronologici (descritti più avanti) per attenuare le incoerenze, ma questo non attiverà nuovi avvisi di anomalia, se gli avvisi per tali punti temporali sono già stati attivati. Questo processo può aggiungere un carico di lavoro aggiuntivo al sistema e non è automatico.
Per evitare il caricamento di dati parziali, è consigliabile adottare due approcci:
Generare dati in una transazione:
Verificare che i valori delle metriche per tutte le combinazioni di dimensioni contemporaneamente vengano archiviati nell'origine dati in una transazione. Nell'esempio precedente attendere che i dati di tutte le origini dati non sono pronti e quindi caricarli in Advisor metriche in una transazione. Advisor metriche può eseguire regolarmente il polling del feed di dati fino a quando i dati non vengono recuperati correttamente (o parzialmente).
Ritardare l'inserimento dei dati impostando un valore appropriato per il parametro di offset del tempo di inserimento:
Impostare il parametro di offset dell'ora di inserimento per il feed di dati per ritardare l'inserimento fino a quando i dati non vengono preparati completamente. Ciò può essere utile per alcune origini dati che non supportano transazioni come l'Archiviazione tabelle di Azure. Per informazioni dettagliate, vedere Impostazioni avanzate.
Per iniziare, aggiungere un feed di dati
Dopo aver eseguito l'accesso al portale di Advisor metriche e aver scelto l'area di lavoro, fare clic su Inizia. Nella pagina principale dell'area di lavoro fare quindi clic su Aggiungi feed di dati dal menu a sinistra.
Aggiungere le impostazioni di connessione
1. Impostazioni di base
Verrà quindi immesso un set di parametri per connettere l'origine dati time series.
- Tipo di origine: tipo di origine dati in cui sono archiviati i dati delle serie temporali.
- Granularità: intervallo tra punti dati consecutivi nei dati delle serie temporali. Attualmente Advisor metriche supporta: Annually, Monthly, Weekly, Daily, Hourly, al minuto e Custom. L'intervallo più basso supportato dall'opzione di personalizzazione è di 60 secondi.
- Secondi: numero di secondi in cui granularityName è impostato su Personalizza.
- Inserire dati dall'ora UTC: ora di inizio prevista per l'inserimento dati.
startOffsetInSecondsviene spesso usato per aggiungere un offset per facilitare la coerenza dei dati.
2. Specificare stringa di connessione
Sarà quindi necessario specificare le informazioni di connessione per l'origine dati. Per informazioni dettagliate sugli altri campi e sulla connessione di diversi tipi di origini dati, vedere Procedura: Connessione origini dati diverse.
3. Specificare una query per un singolo timestamp
Per informazioni dettagliate sui diversi tipi di origini dati, vedere Procedura: Connessione origini dati diverse.
Caricare i dati
Dopo aver immesso il stringa di connessione e la stringa di query, selezionare Carica dati. In questa operazione, Advisor metriche verificherà la connessione e l'autorizzazione per caricare i dati, controllare i parametri necessari (@IntervalStart e @IntervalEnd) che devono essere usati nella query e controllare il nome della colonna dall'origine dati.
Se si verifica un errore in questo passaggio:
- Controllare prima di tutto se il stringa di connessione è valido.
- Controllare quindi se sono presenti autorizzazioni sufficienti e che all'indirizzo IP del ruolo di lavoro di inserimento venga concesso l'accesso.
- Controllare quindi se i parametri obbligatori (@IntervalStart e @IntervalEnd) vengono usati nella query.
Configurazione dello schema
Dopo aver caricato lo schema dei dati, selezionare i campi appropriati.
Se il timestamp di un punto dati viene omesso, Advisor metriche userà il timestamp quando il punto dati viene inserito. Per ogni feed di dati, è possibile specificare al massimo una colonna come timestamp. Se viene visualizzato un messaggio che indica che una colonna non può essere specificata come timestamp, controllare la query o l'origine dati e se sono presenti più timestamp nel risultato della query, non solo nei dati di anteprima. Quando si esegue l'inserimento dati, Advisor metriche può usare un solo blocco (ad esempio un giorno, un'ora, in base alla granularità) dei dati delle serie temporali dall'origine specificata ogni volta.
| Selezione | Descrizione | Note |
|---|---|---|
| Nome visualizzato | Nome da visualizzare nell'area di lavoro anziché il nome della colonna originale. | (Facoltativo). |
| Timestamp: | Timestamp di un punto dati. Se omesso, Advisor metriche userà il timestamp quando il punto dati viene inserito. Per ogni feed di dati, è possibile specificare al massimo una colonna come timestamp. | (Facoltativo). Deve essere specificato con al massimo una colonna. Se non è possibile specificare una colonna come errore timestamp , controllare la query o l'origine dati per i timestamp duplicati. |
| Misura | Valori numerici nel feed di dati. Per ogni feed di dati, è possibile specificare più misure, ma almeno una colonna deve essere selezionata come misura. | Deve essere specificato con almeno una colonna. |
| Dimensione | Valori di categoria. Una combinazione di valori diversi identifica una particolare serie temporale a dimensione singola, ad esempio paese/area geografica, lingua, tenant. È possibile selezionare zero o più colonne come dimensioni. Nota: prestare attenzione quando si seleziona una colonna non stringa come dimensione. | (Facoltativo). |
| Ignora | Ignora la colonna selezionata. | (Facoltativo). Per il supporto delle origini dati tramite una query per ottenere i dati, non è disponibile alcuna opzione "Ignora". |
Per ignorare le colonne, è consigliabile aggiornare la query o l'origine dati per escludere tali colonne. È anche possibile ignorare le colonne usando Ignora colonne e quindi Ignora nelle colonne specifiche. Se una colonna deve essere una dimensione e viene erroneamente impostata come Ignorata, Advisor metriche potrebbe terminare l'inserimento di dati parziali. Si supponga, ad esempio, che i dati della query siano i seguenti:
| ID riga | Timestamp: | Paese/area geografica | Lingua | Reddito |
|---|---|---|---|---|
| 1 | 2019/11/10 | Cina | ZH-CN | 10000 |
| 2 | 2019/11/10 | Cina | EN-US | 1000 |
| 3 | 2019/11/10 | Stati Uniti | ZH-CN | 12000 |
| 4 | 2019/11/11 | Stati Uniti | EN-US | 23000 |
| ... | ... | ... | ... | ... |
Se Country è una dimensione e Language è impostato su Ignorato, le prime e le seconde righe avranno le stesse dimensioni per un timestamp. Advisor metriche userà arbitrariamente un valore delle due righe. Advisor metriche non aggrega le righe in questo caso.
Dopo aver configurato lo schema, selezionare Verify schema (Verifica schema). All'interno di questa operazione, Advisor metriche eseguirà i controlli seguenti:
- Indica se il timestamp dei dati sottoposti a query rientra in un singolo intervallo.
- Indica se sono presenti valori duplicati restituiti per la stessa combinazione di dimensioni entro un intervallo di metriche.
Impostazioni di rollup automatico
Importante
Se si vuole abilitare l'analisi della causa radice e altre funzionalità di diagnostica, è necessario configurare le impostazioni di rollup automatico. Dopo l'abilitazione, non è possibile modificare le impostazioni di rollup automatico.
Advisor metriche può eseguire automaticamente aggregazioni(ad esempio SUM, MAX, MIN) in ogni dimensione durante l'inserimento, quindi crea una gerarchia che verrà usata nell'analisi dei casi radice e in altre funzionalità di diagnostica.
Si considerino gli scenari seguenti:
"Non è necessario includere l'analisi di rollup per i dati."
Non è necessario usare il rollup di Advisor metriche.
"I miei dati sono già stati distribuiti e il valore della dimensione è rappresentato da: NULL o Empty (Default), NULL only, Others".
Questa opzione indica che Advisor metriche non deve eseguire il rollup dei dati perché le righe sono già sommate. Ad esempio, se si seleziona solo NULL, la seconda riga di dati nell'esempio seguente verrà considerata come un'aggregazione di tutti i paesi e della lingua EN-US. La quarta riga di dati con un valore vuoto per Country verrà tuttavia considerata come una riga normale che potrebbe indicare dati incompleti.
Paese/area geografica Lingua Reddito Cina ZH-CN 10000 (NULL) EN-US 999999 Stati Uniti EN-US 12000 EN-US 5000 "Ho bisogno di Advisor metriche per eseguire il rollup dei dati calcolando Sum/Max/Min/Avg/Count e rappresentarlo da {una stringa}".
Alcune origini dati, ad esempio Azure Cosmos DB o Archiviazione BLOB di Azure non supportano determinati calcoli, ad esempio raggruppa per cubo o . Advisor metriche offre l'opzione di rollup per generare automaticamente un cubo di dati durante l'inserimento. Questa opzione significa che è necessario Advisor metriche per calcolare il rollup usando l'algoritmo selezionato e usare la stringa specificata per rappresentare il rollup in Advisor metriche. Questo non modificherà alcun dato nell'origine dati. Si supponga, ad esempio, di avere un set di serie temporali che corrisponde alle metriche Sales con la dimensione (Country, Region). Per un determinato timestamp, potrebbe essere simile al seguente:
Paese Area Sales Canada Alberta 100 Canada British Columbia 500 Stati Uniti Montana 100 Dopo aver abilitato il rollup automatico con Sum, Advisor metriche calcolerà le combinazioni di dimensioni e somma le metriche durante l'inserimento dati. Il risultato potrebbe essere:
Paese Area Sales Canada Alberta 100 NULL Alberta 100 Canada British Columbia 500 NULL British Columbia 500 Stati Uniti Montana 100 NULL Montana 100 NULL NULL 700 Canada NULL 600 Stati Uniti NULL 100 (Country=Canada, Region=NULL, Sales=600)indica che la somma delle vendite in Canada (tutte le aree) è 600.Di seguito è riportata la trasformazione nel linguaggio SQL.
SELECT dimension_1, dimension_2, ... dimension_n, sum (metrics_1) AS metrics_1, sum (metrics_2) AS metrics_2, ... sum (metrics_n) AS metrics_n FROM each_timestamp_data GROUP BY CUBE (dimension_1, dimension_2, ..., dimension_n);Prima di usare la funzionalità di rollup automatico, tenere presente quanto segue:
- Se si vuole usare SUM per aggregare i dati, assicurarsi che le metriche siano aggiuntive in ogni dimensione. Ecco alcuni esempi di metriche non additivi :
- Metriche basate su frazione. Sono inclusi rapporto, percentuale e così via. Ad esempio, non si dovrebbe aggiungere il tasso di disoccupazione di ogni stato per calcolare il tasso di disoccupazione dell'intero paese/area geografica.
- Sovrapposizione nella dimensione. Ad esempio, non si dovrebbe aggiungere il numero di persone in ogni sport per calcolare il numero di persone che amano lo sport, perché c'è una sovrapposizione tra loro, una persona può come più sport.
- Per garantire l'integrità dell'intero sistema, le dimensioni del cubo sono limitate. Attualmente, il limite è 100.000. Se i dati superano tale limite, l'inserimento avrà esito negativo per tale timestamp.
- Se si vuole usare SUM per aggregare i dati, assicurarsi che le metriche siano aggiuntive in ogni dimensione. Ecco alcuni esempi di metriche non additivi :
Impostazioni avanzate
Esistono diverse impostazioni avanzate per abilitare i dati inseriti in modo personalizzato, ad esempio specificando l'offset di inserimento o la concorrenza. Per altre informazioni, vedere la sezione Impostazioni avanzate nell'articolo sulla gestione dei feed di dati.
Specificare un nome per il feed di dati e controllare lo stato di avanzamento dell'inserimento
Assegnare al feed di dati un nome personalizzato, che verrà visualizzato nell'area di lavoro. Selezionare quindi Invia. Nella pagina dei dettagli del feed di dati è possibile usare la barra di stato di inserimento per visualizzare le informazioni sullo stato.

Per controllare i dettagli dell'errore di inserimento:
- Selezionare Mostra dettagli.
- Selezionare Stato e quindi scegliere Non riuscito o Errore.
- Passare il puntatore del mouse su un inserimento non riuscito e visualizzare il messaggio dei dettagli visualizzato.
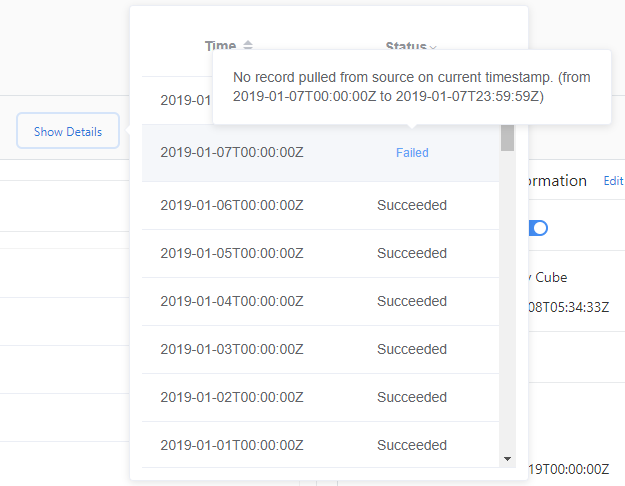
Uno stato non riuscito indica che l'inserimento per questa origine dati verrà ritentato in un secondo momento. Uno stato errore indica che Advisor metriche non riprova per l'origine dati. Per ricaricare i dati, è necessario attivare manualmente un backfill/ricaricamento.
È anche possibile ricaricare lo stato di avanzamento di un inserimento facendo clic su Aggiorna stato. Al termine dell'inserimento dati, è possibile fare clic sulle metriche e controllare i risultati del rilevamento anomalie.