Questo progetto clienti ha aiutato un'azienda alimentare Fortune 500 a migliorare la previsione della domanda. L'azienda spedisce i prodotti direttamente a più punti vendita al dettaglio. Il miglioramento ha aiutato a ottimizzare l'stocking dei loro prodotti in negozi diversi in diverse aree del Stati Uniti. A tale scopo, il team CSE (Commercial Software Engineering) di Microsoft ha lavorato con i data scientist del client in uno studio pilota per sviluppare modelli di Machine Learning personalizzati per le aree selezionate. I modelli prendono in considerazione:
- Dati demografici degli acquirenti
- Condizioni meteorologiche pregresse e previste
- Spedizioni passate
- Resi di prodotti
- Eventi speciali
L'obiettivo di ottimizzare l'stocking rappresentava una componente principale del progetto e il cliente ha realizzato un significativo aumento delle vendite nelle prime prove sul campo. Inoltre, il team ha visto una riduzione del 40% nella previsione dell'errore di percentuale assoluta (MAPE) rispetto a un modello di base medio cronologico.
Una parte fondamentale del progetto è stata capire come aumentare il flusso di lavoro di data science dallo studio pilota a un livello di produzione. Nell'ambito di questo flusso di lavoro a livello di produzione, il team CSE ha dovuto:
- Sviluppare modelli per molte aree geografiche.
- Aggiornare e monitorare continuamente le prestazioni dei modelli.
- Facilitare la collaborazione tra i team di progettazione e dati.
Il tipico flusso di lavoro di data science oggi è più vicino a un ambiente lab uno-off rispetto a un flusso di lavoro di produzione. Un ambiente per i data scientist deve essere adatto per:
- Preparare i dati.
- Eseguire esperimenti con modelli diversi.
- Ottimizzare gli iperparametri.
- Creare un ciclo build-test-evaluate-refine.
La maggior parte degli strumenti usati per queste attività ha scopi specifici e non è adatta all'automazione. In un'operazione di Machine Learning a livello di produzione, è necessario tenere in considerazione la gestione del ciclo di vita delle applicazioni e DevOps.
Il team CSE ha aiutato il cliente a aumentare le prestazioni dell'operazione ai livelli di produzione. Sono stati implementati vari aspetti delle funzionalità di integrazione continua e recapito continuo (CI/CD) e hanno risolto problemi come l'osservabilità e l'integrazione con le funzionalità di Azure. Durante l'implementazione, il team ha scoperto lacune nelle linee guida MLOps esistenti. Tali lacune dovevano essere riempite in modo che MLOps fosse meglio compreso e applicato su larga scala.
Comprendere le procedure MLOps aiuta le organizzazioni a garantire che i modelli di Machine Learning prodotti dal sistema siano modelli di qualità di produzione che migliorano le prestazioni aziendali. Quando viene implementato MLOps, l'organizzazione non deve più dedicare gran parte del tempo ai dettagli di basso livello relativi all'infrastruttura e al lavoro di progettazione necessari per sviluppare ed eseguire modelli di Machine Learning per le operazioni a livello di produzione. L'implementazione di MLOps consente anche alle community di data science e ingegneria del software di imparare a collaborare per distribuire un sistema pronto per la produzione.
Il team CSE ha usato questo progetto per soddisfare le esigenze della community di Machine Learning risolvendo problemi come lo sviluppo di un modello di maturità MLOps. Questi sforzi miravano a migliorare l'adozione di MLOps comprendendo le tipiche sfide dei principali attori del processo MLOps.
Scenari tecnici e di engagement
Lo scenario di engagement illustra le sfide reali che il team cse ha dovuto risolvere. Lo scenario tecnico definisce i requisiti per creare un ciclo di vita MLOps affidabile come il ciclo di vita devOps stabilito.
Scenario di engagement
Il cliente consegna i prodotti direttamente ai punti vendita al dettaglio in base a una pianificazione regolare. Ogni punto vendita varia in base ai modelli di utilizzo dei prodotti, quindi l'inventario dei prodotti deve variare in ogni consegna settimanale. Ottimizzare le vendite e ridurre al minimo i rendimenti dei prodotti e le opportunità di vendita perse sono gli obiettivi delle metodologie di previsione della domanda usate dal cliente. Questo progetto è incentrato sull'uso di Machine Learning per migliorare le previsioni.
Il team CSE ha diviso il progetto in due fasi. Fase 1 incentrata sullo sviluppo di modelli di Machine Learning per supportare uno studio pilota basato sul campo sull'efficacia delle previsioni di Machine Learning per un'area di vendita selezionata. Il successo della fase 1 ha portato alla fase 2, in cui il team ha ridimensionato lo studio pilota iniziale da un gruppo minimo di modelli che supportavano una singola area geografica a un set di modelli a livello di produzione sostenibile per tutte le aree di vendita del cliente. Una considerazione principale per la soluzione con scalabilità orizzontale è stata la necessità di gestire il numero elevato di aree geografiche e i punti vendita locali. Il team ha dedicato i modelli di Machine Learning ai punti vendita di grandi e di piccole dimensioni in ogni area geografica.
Lo studio pilota della fase 1 ha determinato che un modello dedicato ai punti vendita di una regione potrebbe usare la cronologia delle vendite locali, i dati demografici locali, il meteo e gli eventi speciali per ottimizzare la previsione della domanda per i punti vendita nella regione. Quattro modelli di previsione di Machine Learning di insieme hanno servito punti di vendita di mercato in una singola area. elaborando i dati in batch settimanali. Il team ha inoltre sviluppato due modelli di base usando dati cronologici per il confronto.
Per la prima versione della soluzione di fase 2 con scalabilità orizzontale, il team CSE ha selezionato 14 aree geografiche a cui partecipare, inclusi i punti vendita di mercato di piccole e grandi dimensioni. A questo scopo sono stati usati più di 50 modelli di previsione di Machine Learning. Il team si aspettava un'ulteriore crescita del sistema e un continuo perfezionamento dei modelli di Machine Learning. È diventato rapidamente chiaro che questa soluzione di Machine Learning su larga scala è sostenibile solo se si basa sui principi di procedura consigliata di DevOps per l'ambiente di Machine Learning.
| Ambiente | Area di mercato | Formato | Modelli | Suddivisione modello | Descrizione modello |
|---|---|---|---|---|---|
| Ambiente di sviluppo | Ogni area di mercato/area geografica (ad esempio Texas settentrionale) | Grandi negozi di formato (supermercati, grandi negozi di box e così via) | Due modelli di ensemble | Prodotti a lenta rotazione | La regressione lineare LASSO (Slow and Fast) include un insieme di un modello di regressione lineare meno assoluto e di una rete neurale con incorporamenti categorici |
| Prodotti a rotazione rapida | Sia lento che veloce hanno un insieme di un modello di regressione lineare LASSO e una rete neurale con incorporamenti categorici | ||||
| Un modello di ensemble | N/D | Media storica | |||
| Piccoli negozi di formato (farmacie, negozi di comodità e così via) | Due modelli di ensemble | Prodotti a lenta rotazione | Sia lento che veloce hanno un insieme di un modello di regressione lineare LASSO e una rete neurale con incorporamenti categorici | ||
| Prodotti a rotazione rapida | Lento ed entrambi hanno un insieme di un modello di regressione lineare LASSO e una rete neurale con incorporamenti categorici | ||||
| Un modello di ensemble | N/D | Media storica | |||
| Uguale a quello precedente per altre 13 aree geografiche | |||||
| Uguale a quello precedente per l'ambiente di produzione |
Il processo MLOps ha fornito un framework per il sistema con scalabilità orizzontale che ha risolto il ciclo di vita completo dei modelli di Machine Learning. Il framework include sviluppo, test, distribuzione, operazione e monitoraggio. Soddisfa le esigenze di un processo CI/CD classico. Tuttavia, la sua relativa immaturità rispetto a DevOps ha messo in evidenza le lacune esistenti nelle linee guida di MLOps. Il team del progetto ha lavorato per colmare alcune di queste lacune. Volevano fornire un modello di processo funzionale che garantisce la redditività della soluzione di Machine Learning con scalabilità orizzontale.
Il processo MLOps sviluppato da questo progetto ha fatto un passo significativo nel mondo reale per spostare MLOps a un livello superiore di maturità e redditività. Il nuovo processo è direttamente applicabile ad altri progetti di Machine Learning. Il team CSE ha usato ciò che hanno imparato a creare una bozza di un modello di maturità MLOps che chiunque può applicare ad altri progetti di Machine Learning.
Scenario tecnico
MLOps, noto anche come DevOps per l'apprendimento automatico, è un termine generico che comprende filosofie, procedure e tecnologie correlate all'implementazione di cicli di vita di Machine Learning in un ambiente di produzione. È un concetto ancora relativamente nuovo, Sono stati numerosi i tentativi di definire le operazioni MLOps e molte persone hanno interrogato se MLOps può riprendere tutto dal modo in cui i data scientist preparano i dati a come forniscono, monitorano e valutano i risultati di Machine Learning. Anche se DevOps ha avuto anni per sviluppare una serie di procedure fondamentali, MLOps è ancora all'inizio dello sviluppo. Man mano che si evolve, scopriamo le sfide di riunire due discipline che spesso operano con set di competenze e priorità diversi: progettazione software/operazioni e data science.
L'implementazione di MLOps in ambienti di produzione reali ha le sue problematiche uniche che devono essere risolte. Teams può usare Azure per supportare i modelli MLOps. Azure può anche offrire ai client servizi di gestione degli asset e orchestrazione per gestire in modo efficace il ciclo di vita di Machine Learning. I servizi di Azure sono la base per la soluzione MLOps descritta in questo articolo.
Requisiti del modello di Machine Learning
Gran parte del lavoro svolto durante lo studio sul campo pilota della fase 1 stava creando i modelli di Machine Learning applicati dal team CSE ai grandi e piccoli punti vendita in una singola area. Requisiti rilevanti per i modelli inclusi:
Uso del servizio Azure Machine Learning.
Modelli sperimentali iniziali sviluppati in notebook jupyter e implementati in Python.
Nota
Teams ha usato lo stesso approccio di Machine Learning per archivi di grandi dimensioni e di piccole dimensioni, ma i dati di training e assegnazione dei punteggi dipendono dalle dimensioni dell'archivio.
Dati che richiedono la preparazione per l'utilizzo del modello.
Dati elaborati in batch anziché in tempo reale.
Ripetizione del training del modello ogni volta che il codice o i dati cambiano o il modello diventa obsoleto.
Visualizzazione delle prestazioni del modello nei dashboard di Power BI.
Prestazioni del modello nell'assegnazione dei punteggi considerate significative quando MAPE <= 45% rispetto a un modello di base medio cronologico.
Requisiti di MLOps
Il team ha dovuto soddisfare diversi requisiti chiave per aumentare le prestazioni della soluzione dallo studio sul campo della fase 1, in cui sono stati sviluppati solo alcuni modelli per una singola area di vendita. La fase 2 ha implementato modelli di Machine Learning personalizzati per più aree. L'implementazione include:
Elaborazione batch settimanale per archivi di grandi dimensioni e piccole in ogni area per ripetere il training dei modelli con nuovi set di dati.
Perfezionamento continuo dei modelli di Machine Learning.
Integrazione del processo di sviluppo/test/creazione pacchetto/test/distribuzione comune a CI/CD in un ambiente di elaborazione simile a DevOps per MLOps.
Nota
Questo approccio rappresenta un cambiamento nel modo di lavorare dei data scientist e degli ingegneri dei dati.
Modello univoco che rappresenta ogni area per archivi di grandi dimensioni e piccole in base alla cronologia dell'archivio, ai dati demografici e ad altre variabili chiave. Il modello doveva elaborare l'intero set di dati per ridurre al minimo il rischio di errore di elaborazione.
Possibilità di aumentare inizialmente le prestazioni per supportare 14 aree di vendita con piani per aumentare ulteriormente le prestazioni.
Piani di sviluppo di modelli aggiuntivi per la previsione a lungo termine per le aree di vendita e altri gruppi di negozi.
Soluzione del modello di Machine Learning
Il ciclo di vita di Machine Learning, noto anche come ciclo di vita di data science, rientra approssimativamente nel flusso di processo generale seguente:
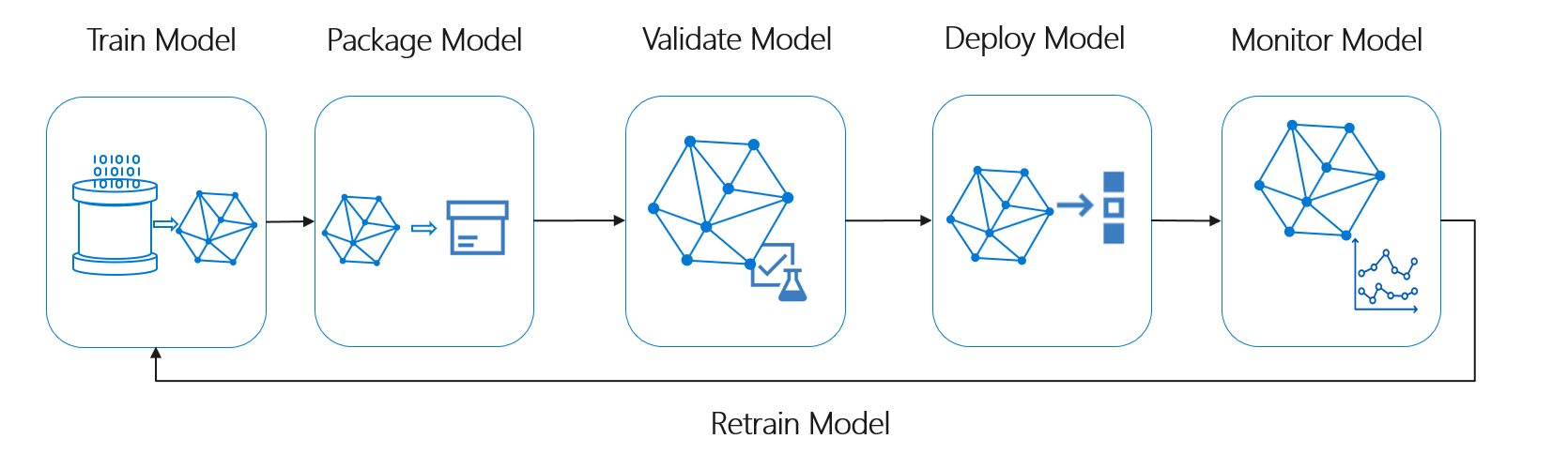
Distribuzione modello in questo flusso può rappresentare qualsiasi uso operativo del modello di Machine Learning convalidato. Rispetto a DevOps, MLOps presenta la sfida aggiuntiva dell'integrazione del ciclo di vita di Machine Learning nel tipico processo CI/CD.
Il ciclo di vita di data science non segue il tipico ciclo di vita dello sviluppo software. Include l'uso di Azure Machine Learning per eseguire il training e assegnare punteggi ai modelli, quindi questi passaggi devono essere inclusi nell'automazione CI/CD.
L'elaborazione batch dei dati è la base dell'architettura. Componenti centrali del processo sono due pipeline di Azure Machine Learning, una per il training e l'altra per l'assegnazione del punteggio. Questo diagramma illustra la metodologia di data science usata per la fase iniziale del progetto client:
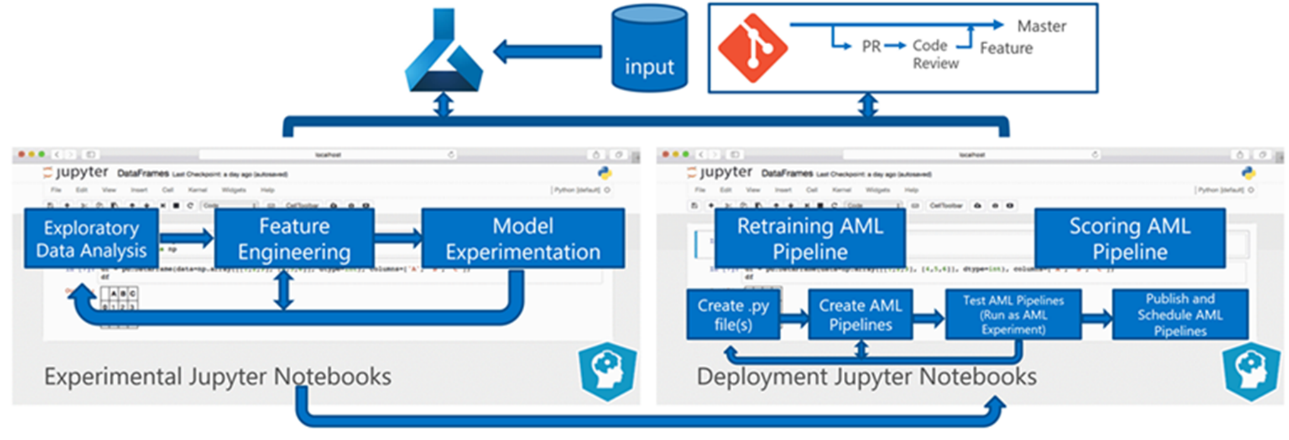
Il team ha testato diversi algoritmi, In definitiva, hanno scelto una progettazione completa di un modello di regressione lineare LASSO e una rete neurale con incorporamenti categorici. Il team ha usato lo stesso modello, definito dal livello di prodotto che il cliente poteva immagazzinare in loco, sia per i grandi che per i piccoli negozi. Ha quindi ulteriormente suddiviso il modello in prodotti a rotazione rapida e lenta.
I data scientist eseguono il training dei modelli di Machine Learning quando il team rilascia nuovo codice e quando sono disponibili nuovi dati. Il training viene in genere eseguito settimanalmente. Di conseguenza, ogni elaborazione coinvolge una grande quantità di dati. Poiché il team raccoglie i dati da molte origini in formati diversi, richiede l'inserimento dei dati in un formato di consumo prima che i data scientist possano elaborarli. Il condizionamento dei dati richiede un impegno manuale significativo e il team CSE lo ha identificato come candidato principale per l'automazione.
Come accennato, i data scientist hanno sviluppato e applicato i modelli sperimentali di Azure Machine Learning a una singola area di vendita nello studio sul campo della fase 1 pilota per valutare l'utilità di questo approccio di previsione. Il team CSE ha ritenuto che l'ascensore delle vendite per i negozi nello studio pilota fosse significativo. Questo successo giustificato applicando la soluzione ai livelli di produzione completi nella fase 2, a partire da 14 aree geografiche e migliaia di negozi. Il team ha quindi potuto usare lo stesso modello per aggiungere altre aree.
Il modello pilota funge da base per la soluzione con scalabilità orizzontale, ma il team CSE sapeva che il modello aveva bisogno di un ulteriore perfezionamento per migliorare le prestazioni.
Soluzione MLOps
Man mano che i concetti mlops maturano, i team spesso individuano sfide per riunire le discipline di data science e DevOps. Il motivo è che i principali attori delle discipline, degli ingegneri software e dei data scientist, operano con set di competenze e priorità diversi.
Ma ci sono analogie tra loro. MLOps, come DevOps, è un processo di sviluppo implementato da una toolchain. La toolchain MLOps include elementi come:
- Controllo della versione
- Analisi codice
- Automazione della compilazione
- Integrazione continua
- Framework di test e automazione
- Criteri di conformità integrati nelle pipeline CI/CD
- Automazione della distribuzione
- Monitoraggio
- Ripristino di emergenza e disponibilità elevata
- Gestione di pacchetti e contenitori
Come indicato in precedenza, la soluzione sfrutta le linee guida DevOps esistenti, ma è aumentata per creare un'implementazione MLOps più matura che soddisfi le esigenze del client e della community di data science. MLOps si basa sulle linee guida di DevOps a cui aggiunge questi requisiti:
- Il controllo delle versioni dei dati e del modello non è identico al controllo delle versioni del codice: è necessario disporre del controllo delle versioni dei set di dati come cambiano i dati dello schema e dell'origine.
- Requisiti di audit trail digitale: occorre tenere traccia di tutti i cambiamenti quando si gestiscono dati del cliente e codice.
- Generalizzazione: i modelli sono diversi dal codice per il riutilizzo, poiché i data scientist devono ottimizzare i modelli in base ai dati di input e agli scenari. Per riutilizzare un modello per un nuovo scenario, potrebbe essere necessario ottimizzare/trasferire/ottenere informazioni su di esso. È necessaria la pipeline di training.
- Modelli obsoleti: i modelli tendono al decadimento nel tempo ed è necessario poterli sottoporre nuovamente al training su richiesta per assicurarsi che rimangano pertinenti nell'ambiente di produzione.
Problematiche di MLOps
Standard MLOps immaturo
Il modello standard per MLOps è ancora in evoluzione. Una soluzione viene in genere creata da zero e creata per soddisfare le esigenze di un determinato client o utente. Il team CSE ha riconosciuto questa lacuna e ha cercato di usare le procedure consigliate di DevOps in questo progetto, potenziandole per soddisfare i requisiti aggiuntivi di MLOps. Il processo sviluppato dal team è un valido esempio di come dovrebbe essere un modello standard MLOps.
Differenze nei set di competenze
I tecnici software e i data scientist portano set di competenze unici al team. Questi set di competenze diversi possono rendere difficile trovare una soluzione adatta alle esigenze di tutti. La creazione di un flusso di lavoro chiaro per la distribuzione di un modello dall'ambiente di test a quello di produzione è importante. I membri del team devono condividere una conoscenza del modo in cui possono integrare le modifiche nel sistema senza interrompere il processo MLOps.
Gestione di più modelli
Spesso sono necessari più modelli per risolvere scenari difficili di Machine Learning. Una delle sfide poste da MLOps è la gestione di questi modelli, che implica tra le altre cose:
- Avere uno schema di controllo delle versioni coerente.
- Valutazione e monitoraggio continui di tutti i modelli.
È necessaria anche una derivazione tracciabile di codice e dati per diagnosticare i problemi del modello e creare modelli riproducibili. I dashboard personalizzati possono avere un senso delle prestazioni dei modelli distribuiti e indicare quando intervenire. Il team ha quindi creato dashboard di questo tipo per questo progetto.
Necessità di condizionamento dei dati
I dati usati con questi modelli provengono da diverse fonti private e pubbliche. Poiché i dati originali sono disorganizzati, è impossibile che il modello di Machine Learning lo consumi nello stato non elaborato. I data scientist devono impostare i dati in un formato standard per l'utilizzo del modello di Machine Learning.
Buona parte del test pilota sul campo è stata incentrata sul condizionamento dei dati non elaborati ai fini dell'elaborazione tramite il modello di Machine Learning. In un sistema MLOps il team dovrebbe automatizzare questo processo e tenere traccia degli output.
Modello di maturità di MLOps
Lo scopo del modello di maturità MLOps è chiarire i principi e le procedure e identificare le lacune in un'implementazione mlops. È anche un modo per mostrare a un client come aumentare in modo incrementale la funzionalità MLOps invece di tentare di eseguire tutte le operazioni contemporaneamente. Il cliente dovrebbe usare questo modello come guida per:
- Stimare l'ambito del lavoro per il progetto.
- Stabilire i criteri per il successo.
- Identificare i risultati finali.
Il modello di maturità MLOps definisce cinque livelli di funzionalità tecniche:
| Livello | Descrizione |
|---|---|
| 0 | Nessuna operazione |
| 1 | DevOps ma non MLOps |
| 2 | Training automatizzato |
| 3 | Distribuzione automatica dei modelli |
| 4 | Operazioni automatizzate (MLOps complete) |
Per la versione corrente del modello di maturità MLOps, vedere Modello di maturità delle operazioni di Machine Learning.
Definizione del processo MLOps
MLOps include tutte le attività dall'acquisizione di dati non elaborati al recapito dell'output del modello, noto anche come assegnazione dei punteggi:
- Condizionamento dei dati
- Training del modello
- Test e valutazione del modello
- Definizione di compilazione e pipeline
- Pipeline di versione
- Distribuzione
- Punteggio
Processo di Machine Learning di base
Il processo di Machine Learning di base è simile allo sviluppo di software tradizionale, ma esistono differenze significative. Questo diagramma illustra le fasi principali del processo di Machine Learning:
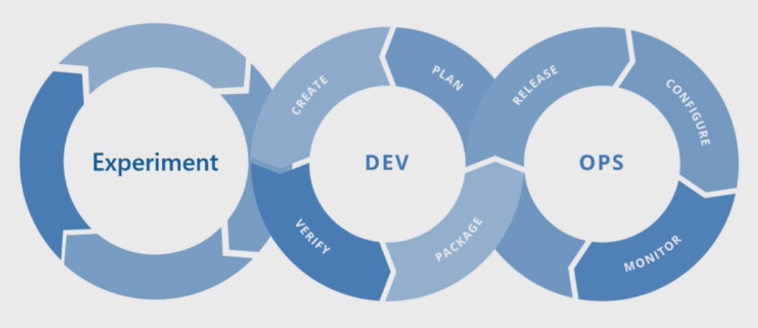
La fase Experiment è unica per il ciclo di vita della data science, che riflette il modo in cui i data scientist svolgono tradizionalmente il loro lavoro. Differisce dal modo in cui gli sviluppatori di codice svolgono il proprio lavoro. Il diagramma seguente illustra questo ciclo di vita in maggiore dettaglio.
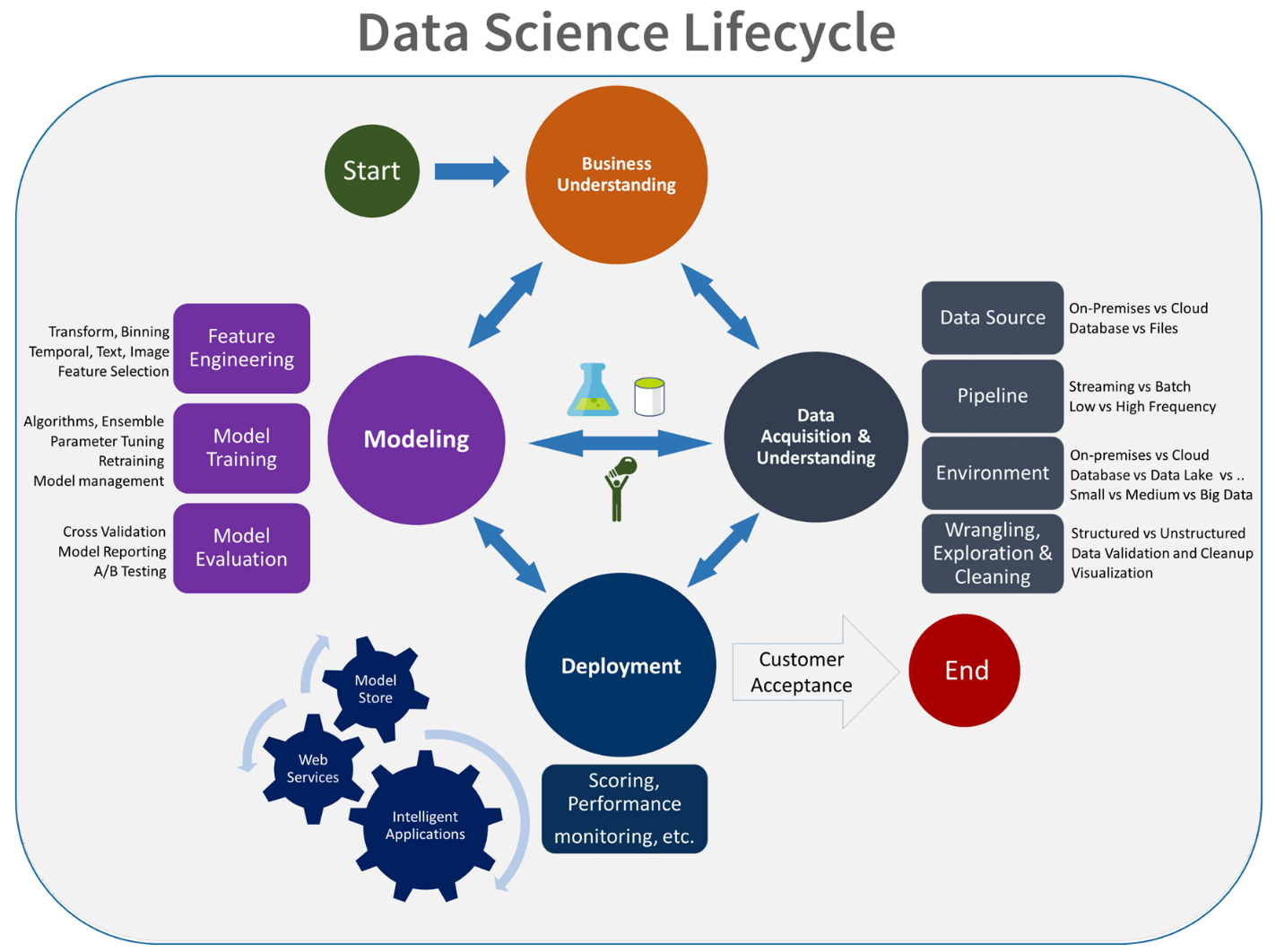
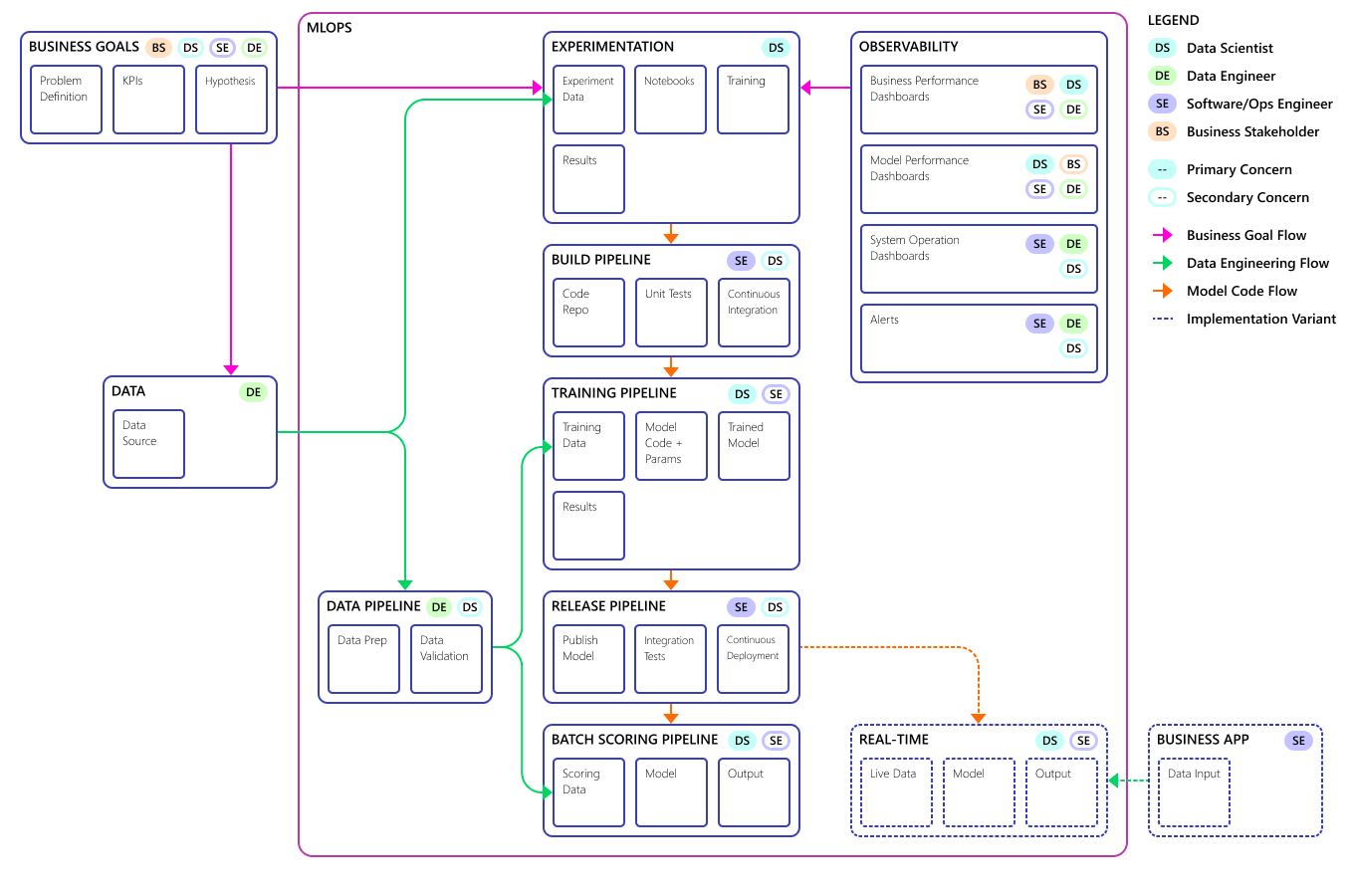
L'integrazione di questo processo di sviluppo dei dati in MLOps non è un'attività semplice. Di seguito viene illustrato il modello usato dal team per integrare il processo in un modulo che MLOps può supportare:
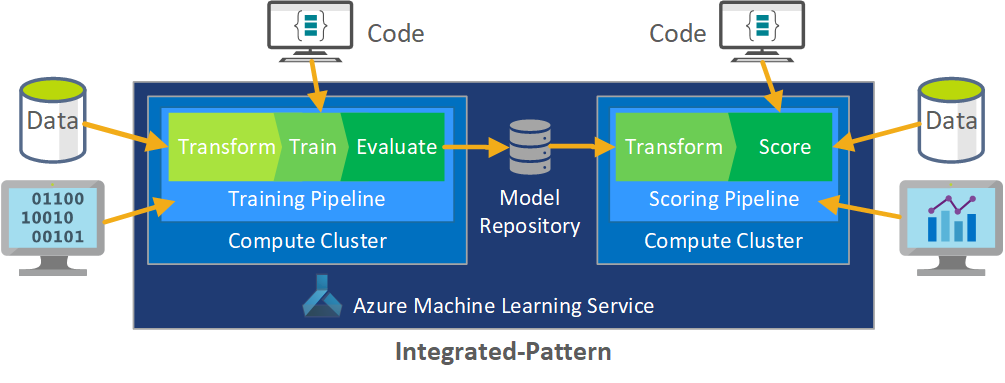
Il ruolo di MLOps consiste nel creare un processo coordinato in grado di supportare in modo efficiente gli ambienti CI/CD su larga scala comuni nei sistemi a livello di produzione. Concettualmente, il modello MLOps deve includere tutti i requisiti del processo, dalla sperimentazione all'assegnazione dei punteggi.
Il team CSE ha perfezionato il processo MLOps in base alle esigenze specifiche del client. La necessità più importante era l'elaborazione batch anziché l'elaborazione in tempo reale. Man mano che il team ha sviluppato il sistema di aumento delle prestazioni, ha identificato e risolto alcune carenze. La più significativa di queste carenze ha portato allo sviluppo di un ponte tra Azure Data Factory e Azure Machine Learning, implementato dal team usando un connettore predefinito in Azure Data Factory. Questo set di componenti è stato creato per facilitare l'attivazione e il monitoraggio dello stato necessari per il funzionamento dell'automazione del processo.
Un'altra modifica fondamentale era che i data scientist avevano bisogno della capacità di esportare il codice sperimentale dai notebook di Jupyter nel processo di distribuzione MLOps anziché attivare direttamente il training e l'assegnazione dei punteggi.
Il diagramma seguente illustra il modello di processo MLOps finale:
Importante
L'assegnazione dei punteggi è la fase finale. Il processo esegue il modello di Machine Learning per eseguire stime. Questo risponde al requisito di base del caso d'uso aziendale per la previsione della domanda. Il team valuta la qualità delle stime usando mape, che è una misura dell'accuratezza della stima dei metodi di previsione statistica e una funzione di perdita per i problemi di regressione in Machine Learning. In questo progetto, il team ha considerato significativo un MAPE <= 45%.
Flusso del processo MLOps
Il diagramma seguente illustra come applicare i flussi di lavoro di sviluppo CI/CD e rilascio al ciclo di vita di Machine Learning:
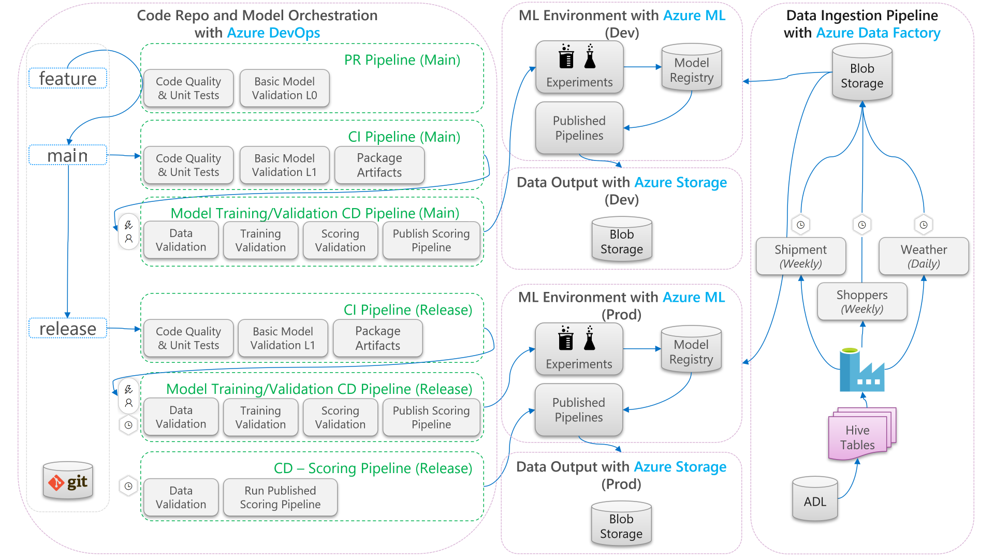
- Quando viene creata una richiesta pull da un ramo di funzionalità, la pipeline esegue test di convalida del codice per convalidare la qualità del codice tramite unit test e test di qualità del codice. Per convalidare la qualità upstream, la pipeline esegue anche test di convalida del modello di base per convalidare le fasi end-to-end di training e assegnazione dei punteggi con un set di dati fittizi di esempio.
- Quando la richiesta pull viene unita al ramo principale, la pipeline CI esegue gli stessi test di convalida del codice e i test di convalida del modello di base con un periodo più lungo. La pipeline crea quindi un pacchetto degli artefatti, che includono il codice e i file binari, da eseguire nell'ambiente di Machine Learning.
- Dopo aver reso disponibili gli artefatti, viene attivata una pipeline cd di convalida del modello. che esegue la convalida end-to-end nell'ambiente di Machine Learning di sviluppo. Viene pubblicato un meccanismo di assegnazione dei punteggi. Per uno scenario di assegnazione dei punteggi in batch, nell'ambiente di Machine Learning viene pubblicata una pipeline di assegnazione dei punteggi, che viene attivata per produrre risultati. Se si vuole usare uno scenario di assegnazione dei punteggi in tempo reale, è possibile pubblicare un'app Web o distribuire un contenitore.
- Dopo aver creato e unito un'attività cardine nel ramo di rilascio, vengono attivate la stessa pipeline CI e la pipeline cd di convalida del modello. Questa volta, vengono eseguiti sul codice dal ramo di rilascio.
È possibile considerare il flusso di dati del processo MLOps illustrato in precedenza come framework archetipo per i progetti che effettuano scelte architetturali simili.
Test di convalida del codice
I test di convalida del codice per Machine Learning sono incentrati sulla convalida della qualità della codebase. Si tratta dello stesso concetto di qualsiasi progetto di progettazione con test di qualità del codice (linting), unit test e misurazioni di code coverage.
Test di convalida del modello di base
La convalida del modello consiste in genere nella convalida delle fasi del processo end-to-end necessarie per produrre un modello di Machine Learning valido, Include passaggi come:
- Convalida dei dati: garantisce la validità dei dati di input.
- Convalida del training: garantisce che il training del modello possa essere eseguito correttamente.
- Convalida dell'assegnazione dei punteggi: garantisce che il team possa usare correttamente il modello sottoposto a training per l'assegnazione dei punteggi con i dati di input.
L'esecuzione di questo set completo di fasi nell'ambiente di Machine Learning è dispendiosa in termini di tempo e denaro. Di conseguenza, il team ha eseguito test di convalida del modello di base in locale in un computer di sviluppo. Sono stati eseguiti i passaggi precedenti e sono stati usati gli elementi seguenti:
- Set di dati di test locale: un set di dati di piccole dimensioni, spesso offuscato, archiviato nel repository e usato come origine dati di input.
- Flag locale: flag o argomento nel codice del modello che indica che il codice prevede l'esecuzione del set di dati in locale. Il flag indica al codice di ignorare qualsiasi chiamata all'ambiente di Machine Learning.
L'obiettivo di questi test di convalida non è valutare le prestazioni del modello sottoposto a training, È invece necessario verificare che il codice per il processo end-to-end sia di buona qualità. Garantisce la qualità del codice sottoposto a push upstream, come l'incorporazione di test di convalida del modello nella compilazione pull e CI. Consente inoltre ai tecnici e ai data scientist di inserire punti di interruzione nel codice a scopo di debug.
Pipeline CD di convalida del modello
L'obiettivo della pipeline di convalida del modello è convalidare le fasi end-to-end di training del modello e assegnazione dei punteggi nell'ambiente di Machine Learning con dati reali. Tutti i modelli sottoposti a training prodotti verranno aggiunti al Registro di sistema del modello e contrassegnati per attendere l'innalzamento di livello al termine della convalida. Per la stima batch, la promozione può essere la pubblicazione di una pipeline di assegnazione dei punteggi che usa questa versione del modello. Per il punteggio in tempo reale, è possibile contrassegnare il modello per indicare che è stato promosso.
Pipeline CD di assegnazione dei punteggi
La pipeline cd di assegnazione dei punteggi è applicabile per lo scenario di inferenza batch, in cui lo stesso agente di orchestrazione del modello usato per la convalida del modello attiva la pipeline di assegnazione dei punteggi pubblicata.
Ambienti di sviluppo e produzione
È consigliabile separare l'ambiente di sviluppo (sviluppo) dall'ambiente di produzione (prod). La separazione consente al sistema di attivare la pipeline cd di convalida del modello e la pipeline cd di assegnazione dei punteggi in pianificazioni diverse. Per il flusso MLOps descritto, le pipeline destinate all'esecuzione del ramo principale nell'ambiente di sviluppo e la pipeline destinata all'esecuzione del ramo di rilascio nell'ambiente di produzione.
Modifiche al codice e variazioni dei dati
Le sezioni precedenti riguardano principalmente come gestire le modifiche del codice dallo sviluppo al rilascio. Tuttavia, le modifiche ai dati devono seguire lo stesso rigore delle modifiche al codice per garantire la stessa qualità di convalida e coerenza nell'ambiente di produzione. Con un trigger di modifica dei dati o un trigger timer, il sistema può attivare la pipeline cd di convalida del modello e la pipeline cd di assegnazione dei punteggi dall'agente di orchestrazione del modello per eseguire lo stesso processo eseguito per le modifiche al codice nell'ambiente di produzione del ramo di rilascio.
Utenti tipo e ruoli MLOps
Un requisito fondamentale per qualsiasi processo MLOps è che soddisfa le esigenze dei molti utenti del processo. Ai fini della progettazione, considerare questi utenti come singoli utenti. Per questo progetto, il team ha identificato questi utenti:
- Data scientist: crea il modello di Machine Learning e i relativi algoritmi.
- Tecnico
- Ingegnere dei dati: gestisce il condizionamento dei dati.
- Software engineer: gestisce l'integrazione del modello nel pacchetto di asset e nel flusso di lavoro CI/CD.
- Operazioni o IT: supervisiona le operazioni di sistema.
- Stakeholder aziendali: riguarda le stime effettuate dal modello di Machine Learning e il modo in cui aiutano l'azienda.
- Utente finale dei dati: utilizza l'output del modello in un modo che aiuti a prendere decisioni aziendali.
Dallo studio degli utenti tipo e dei ruoli il team ha rilevato tre problematiche principali:
- Il modo di lavorare e le competenze di data scientist e tecnici non corrispondono. Semplificando la collaborazione con il data scientist e il tecnico è una considerazione importante per la progettazione del flusso del processo MLOps. Richiede nuove acquisizioni di competenze da parte di tutti i membri del team.
- C'è bisogno di unificare tutti i personaggi principali senza alienare nessuno. Un modo per eseguire questa operazione consiste nel:
- Assicurarsi di comprendere il modello concettuale per MLOps.
- Concordare i membri del team che lavoreranno insieme.
- Stabilire linee guida di lavoro per raggiungere obiettivi comuni.
- Se gli stakeholder aziendali e l'utente finale dei dati hanno bisogno di un modo per interagire con l'output dei dati dei modelli, un'interfaccia utente intuitiva è la soluzione standard.
Altri team incontreranno sicuramente problemi simili in altri progetti di Machine Learning da scalare in ambiente di produzione.
Architettura della soluzione MLOps
Architettura logica
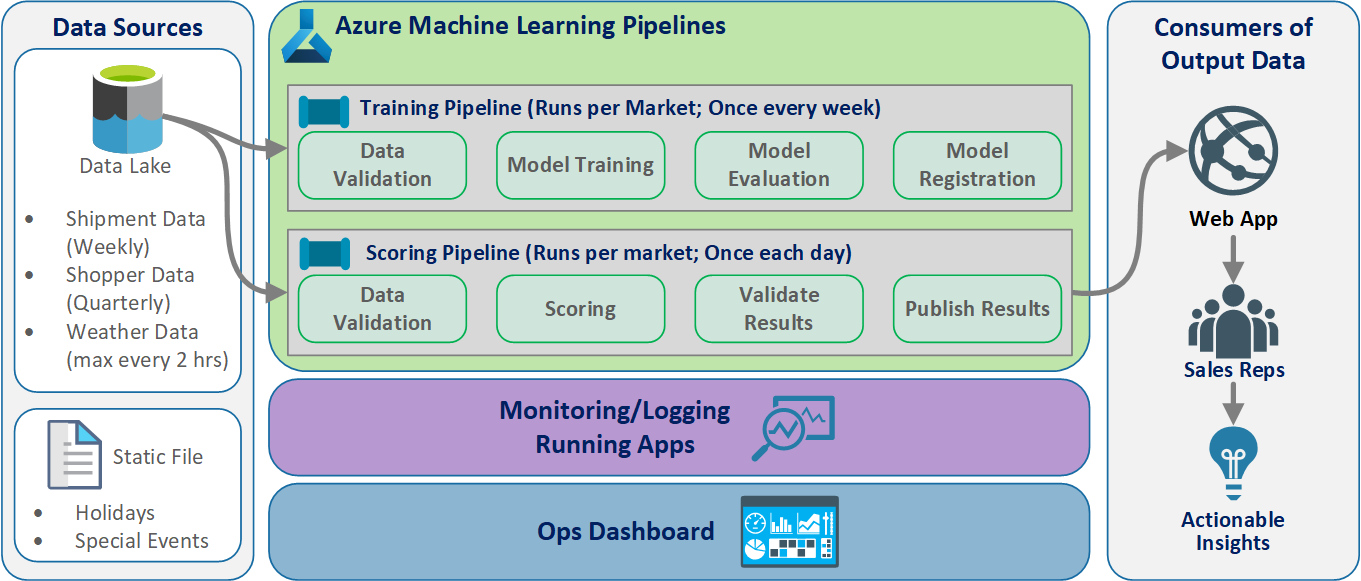
I dati provengono da molte origini in molti formati diversi, quindi vengono condizionali prima che vengano inseriti nel data lake. Il condizionamento viene eseguito usando microservizi che funzionano come Funzioni di Azure. I client personalizzano i microservizi per adattarli alle origini dati e trasformarli in un formato CSV standardizzato usato dalle pipeline di training e assegnazione dei punteggi.
Architettura del sistema
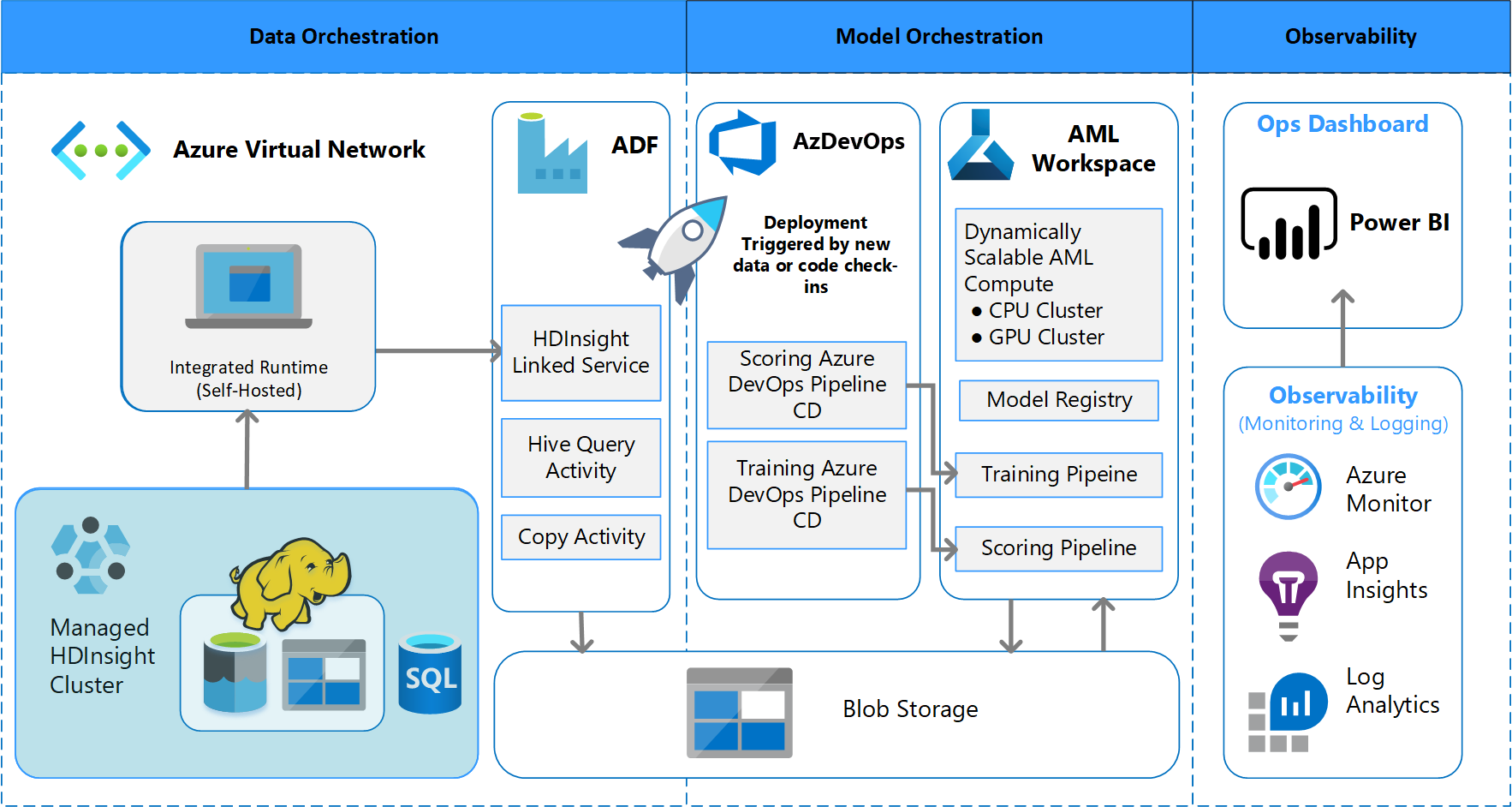
Architettura di elaborazione batch
Il team ha ideato la progettazione dell'architettura per supportare uno schema di elaborazione batch dei dati. Esistono alternative, ma qualsiasi elemento usato deve supportare i processi MLOps. Il pieno utilizzo dei servizi di Azure disponibili era un requisito della progettazione. Il diagramma seguente illustra l'architettura:
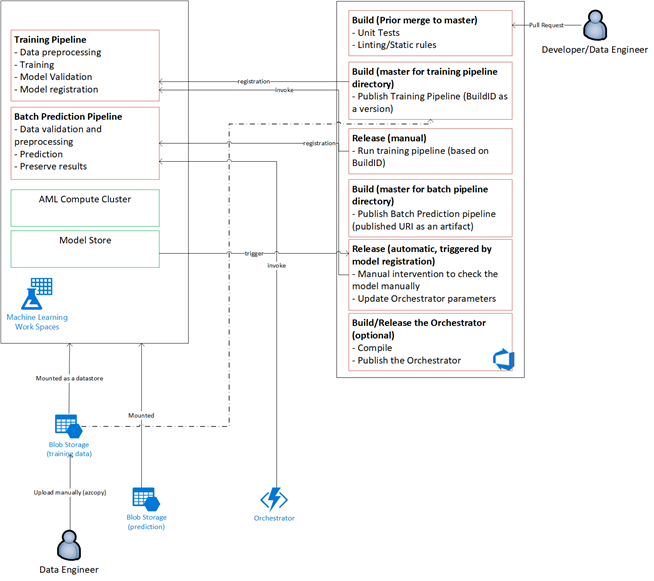
Panoramica della soluzione
Azure Data Factory esegue le operazioni seguenti:
- Attiva una funzione di Azure per avviare l'inserimento dati e un'esecuzione della pipeline di Azure Machine Learning.
- Avvia una funzione durevole per eseguire il polling della pipeline di Azure Machine Learning per il completamento.
I dashboard personalizzati di Power BI visualizzano i risultati. Altri dashboard di Azure connessi ad Azure SQL, Monitoraggio di Azure e App Insights tramite OpenCensus Python SDK, tenere traccia delle risorse di Azure. Questi dashboard forniscono informazioni sull'integrità del sistema di Machine Learning, Producono anche dati usati dal client per la previsione degli ordini di prodotto.
Orchestrazione del modello
L'orchestrazione del modello si articola nelle fasi seguenti:
- Quando viene inviata una richiesta pull, DevOps attiva una pipeline di convalida del codice.
- La pipeline esegue unit test, test di qualità del codice e test di convalida del modello.
- Quando viene unito al ramo principale, vengono eseguiti gli stessi test di convalida del codice e DevOps crea un pacchetto degli artefatti.
- La raccolta di elementi DevOps attiva Azure Machine Learning per eseguire le operazioni seguenti:
- Convalida dei dati.
- Convalida del training.
- Convalida dell'assegnazione dei punteggi.
- Al termine della convalida, viene eseguita la pipeline di assegnazione dei punteggi finale.
- La modifica dei dati e l'invio di una nuova richiesta pull attiva nuovamente la pipeline di convalida, seguita dalla pipeline di assegnazione dei punteggi finale.
Abilitare la sperimentazione
Come già accennato, il ciclo di vita di Machine Learning per il data science tradizionale non supporta il processo MLOps senza necessità di modifiche. Usa diversi tipi di strumenti manuali e sperimentazione, convalida, creazione di pacchetti e handoff del modello che non possono essere facilmente ridimensionati per un processo CI/CD efficace. MLOps richiede un livello elevato di automazione dei processi. Se si sta sviluppando un nuovo modello di Machine Learning o ne viene modificato uno precedente, è necessario automatizzare il ciclo di vita del modello di Machine Learning. Nel progetto fase 2 il team ha usato Azure DevOps per orchestrare e ripubblicare le pipeline di Azure Machine Learning per le attività di training. Il ramo principale a esecuzione prolungata esegue test di base dei modelli ed esegue il push di versioni stabili tramite il ramo di rilascio a esecuzione prolungata.
Il controllo del codice sorgente diventa una parte importante di questo processo. Git è il sistema di controllo della versione usato per tenere traccia del notebook e del codice del modello. Supporta anche l'automazione dei processi. Il flusso di lavoro di base implementato per il controllo del codice sorgente applica i principi seguenti:
- Usare il controllo delle versioni formale per il codice e i set di dati.
- Usare un ramo per lo sviluppo di nuovo codice fino a quando il codice non viene completamente sviluppato e convalidato.
- Dopo la convalida del nuovo codice, è possibile eseguire il merge nel ramo principale.
- Per una versione, viene creato un ramo con versione permanente separato dal ramo principale.
- Usare le versioni e il controllo del codice sorgente per i set di dati con condizioni per il training o l'utilizzo, in modo che sia possibile mantenere l'integrità di ogni set di dati.
- Usare il controllo del codice sorgente per tenere traccia degli esperimenti di Jupyter Notebook.
Integrazione con le origini dati
I data scientist usano un gran numero di origini dati non elaborate e set di dati elaborati per sperimentare modelli di Machine Learning diversi. Il volume dei dati in un ambiente di produzione può diventare così eccessivo. Per consentire ai data scientist di sperimentare modelli diversi, è necessario usare strumenti di gestione come Azure Data Lake. Il requisito per l'identificazione formale e il controllo della versione si applica a tutti i dati non elaborati, ai set di dati preparati e ai modelli di Machine Learning.
Nel progetto i data scientist hanno condizionato i dati seguenti per l'input nel modello:
- Dati cronologici relativi alla spedizione settimanale a partire da gennaio 2017
- Dati meteo giornalieri cronologici e previsti per ogni codice postale
- Dati degli acquirenti per ogni ID negozio
Integrazione con il controllo del codice sorgente
Per consentire ai data scientist di applicare le procedure consigliate di progettazione, è necessario integrare facilmente gli strumenti usati con sistemi di controllo del codice sorgente come GitHub. Questa procedura consente il controllo delle versioni dei modelli di Machine Learning, la collaborazione tra i membri del team e il ripristino di emergenza se i team riscontrano una perdita di dati o un'interruzione del sistema.
Supporto dei modelli ensemble
La progettazione del modello in questo progetto è un modello ensemble. In altre parole, i data scientist hanno usato molti algoritmi nella progettazione del modello finale. In questo caso, i modelli hanno usato la stessa progettazione degli algoritmi di base, con l'unica differenza che sono stati usati dati di training e di punteggio diversi. Per i modelli è stata usata una combinazione di algoritmo di regressione lineare LASSO e rete neurale.
Il team ha esplorato, ma non implementato, un'opzione per inoltrare il processo fino al punto in cui supportava l'esecuzione di molti modelli in tempo reale nell'ambiente di produzione per gestire una determinata richiesta. Questa opzione può supportare l'uso di modelli di insieme nei test A/B e negli esperimenti interleaved.
Interfacce utente per gli utenti finali
Il team ha sviluppato le interfacce utente per gli utenti finali per l'osservabilità, il monitoraggio e la strumentazione. Come già accennato, i dashboard mostrano visivamente i dati del modello di Machine Learning. Questi dashboard mostrano i dati seguenti in un formato facilmente comprensibile:
- Passaggi della pipeline, inclusa la pre-elaborazione dei dati di input.
- Per monitorare l'integrità dell'elaborazione del modello di Machine Learning:
- Quali metriche vengono raccolte dal modello distribuito?
- MAPE: errore percentuale assoluta media, metrica chiave da tenere traccia delle prestazioni complessive. (Specificare come destinazione un valore MAPE pari <a = 0,45 per ogni modello).
- RMSE 0: errore quadratico medio radice (RMSE) quando il valore di destinazione effettivo = 0.
- RMSE All: RMSE nell'intero set di dati.
- Come si valuta se il modello viene eseguito come previsto nell'ambiente di produzione?
- Esiste un modo per determinare se i dati di produzione si discostano troppo dai valori previsti?
- Le prestazioni del modello in ambiente di produzione sono scarse?
- È presente uno stato di failover?
- Quali metriche vengono raccolte dal modello distribuito?
- Tengono traccia della qualità dei dati elaborati.
- Visualizzano i punteggi e le stime prodotti dal modello di Machine Learning.
L'applicazione popola i dashboard in base alla natura dei dati e al modo in cui elabora e analizza tali dati. Di conseguenza, il team deve progettare il layout esatto dei dashboard per ogni caso d'uso. Di seguito sono riportati due dashboard di esempio:
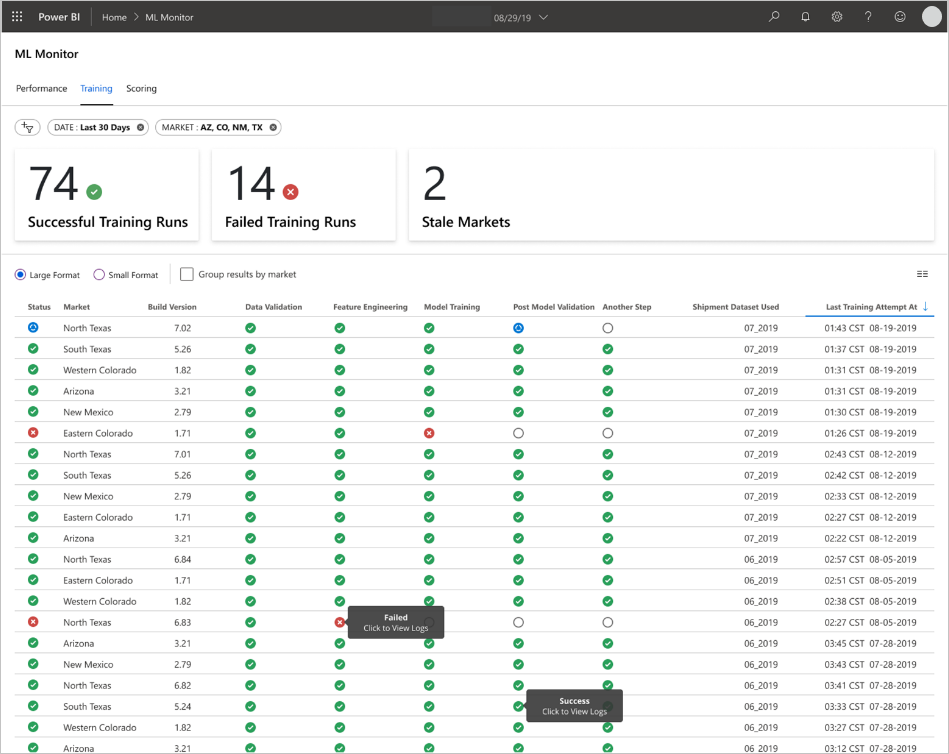
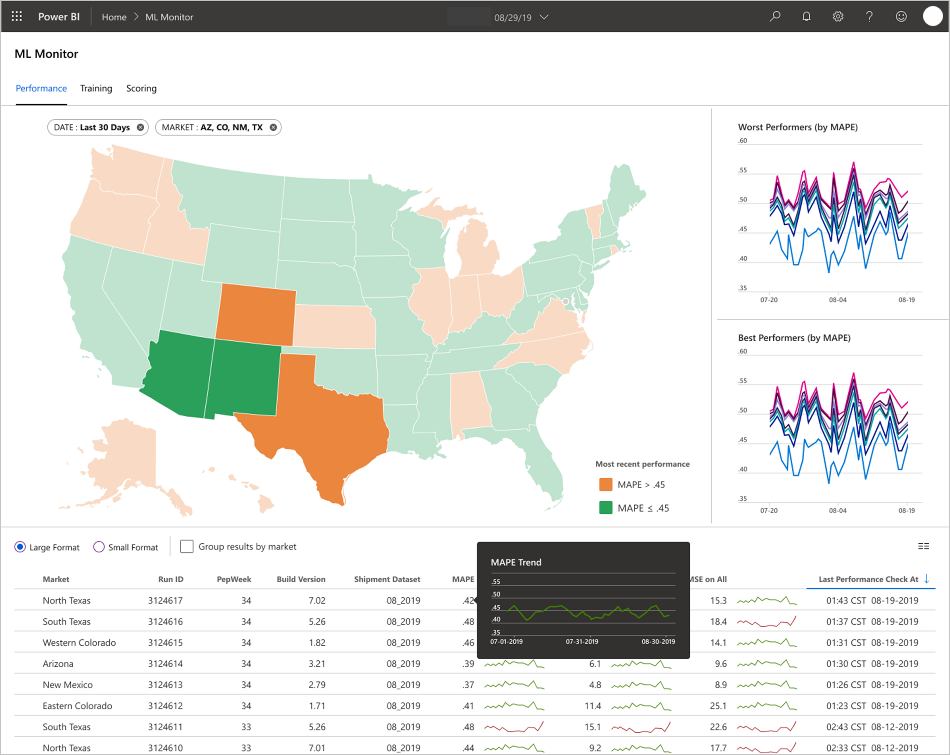
I dashboard sono stati progettati per fornire informazioni facilmente utilizzabili per l'utilizzo da parte dell'utente finale delle stime del modello di Machine Learning.
Nota
I modelli non aggiornati vengono eseguiti con punteggi in cui i data scientist hanno eseguito il training del modello usato per l'assegnazione dei punteggi a più di 60 giorni da quando si è verificato l'assegnazione dei punteggi. Nella pagina Scoring del dashboard ML Monitor viene visualizzata questa metrica di integrità.
Componenti
- Azure Machine Learning
- Archiviazione BLOB di Azure
- Archiviazione di Azure Data Lake
- Azure Pipelines
- Azure Data Factory
- Funzioni di Azure per Python
- Monitoraggio di Azure
- Database SQL di Azure
- Dashboard di Azure
- Power BI
Considerazioni
Di seguito è riportato un elenco di considerazioni basate sulle lezioni apprese dal team CSE durante il progetto.
Considerazioni sull'ambiente
- I data scientist sviluppano la maggior parte dei modelli di Machine Learning usando Python, spesso a partire dai notebook di Jupyter. Implementare questi notebook come codice di produzione può essere un'attività complessa. I notebook di Jupyter sono più che altro uno strumento sperimentale, mentre gli script di Python sono più appropriati per la produzione. I team devono spesso dedicare del tempo al refactoring del codice di creazione del modello in script di Python.
- Rendere i clienti che non hanno familiarità con DevOps e Machine Learning sanno che la sperimentazione e la produzione richiedono rigore diverso, quindi è consigliabile separare i due.
- Gli strumenti come Progettazione visiva di Azure Machine Learning o AutoML possono essere efficaci per ottenere modelli di base mentre il client si adatta alle procedure DevOps standard da applicare al resto della soluzione.
- Azure DevOps include plug-in che possono essere integrati con Azure Machine Learning per attivare i passaggi della pipeline. Il repository MLOpsPython contiene alcuni esempi di queste pipeline.
- Machine Learning richiede spesso potenti computer GPU (Graphics Processing Unit) per il training. Se il client non dispone già di tale hardware disponibile, i cluster di calcolo di Azure Machine Learning possono fornire un percorso efficace per effettuare rapidamente il provisioning di hardware potente e conveniente che viene ridimensionato automaticamente. Se un client ha esigenze di sicurezza o monitoraggio avanzate, sono disponibili altre opzioni, ad esempio macchine virtuali standard, Databricks o calcolo locale.
- Per garantire il successo del cliente, i team di creazione del modello (data scientist) e i team di distribuzione (tecnici DevOps) devono avere un canale di comunicazione efficace. Possono farlo con riunioni stand-up quotidiane o un servizio di chat online formale. Entrambi gli approcci consentono di integrare le attività di sviluppo in un framework MLOps.
Considerazioni sulla preparazione dei dati
La soluzione più semplice per l'uso di Azure Machine Learning consiste nell'archiviare i dati in una soluzione di archiviazione dati supportata. Strumenti come Azure Data Factory sono efficaci per l'invio dei dati tramite pipe da e in tali posizioni in base a una pianificazione.
È importante per i client acquisire spesso dati aggiuntivi di ripetizione del training per mantenere aggiornati i modelli. Se non hanno già una pipeline di dati, la sua creazione sarà un passaggio importante della soluzione complessiva. L'uso di una soluzione come i set di dati in Azure Machine Learning può essere utile per il controllo delle versioni dei dati per facilitare la tracciabilità dei modelli.
Considerazioni su training e valutazione del modello
È travolgente per un client che è appena iniziato nel percorso di Machine Learning per provare a implementare una pipeline MLOps completa. Se necessario, possono semplificarlo usando Azure Machine Learning per tenere traccia delle esecuzioni degli esperimenti e usando l'ambiente di calcolo di Azure Machine Learning come destinazione di training. Queste opzioni potrebbero creare una soluzione con un livello di complessità inferiore per iniziare a integrare i servizi Azure.
Passare da un esperimento di notebook a script ripetibili è una transizione approssimativa per molti data scientist. Prima di poter scrivere il codice di training negli script Python, sarà più semplice iniziare il controllo delle versioni del codice di training e abilitare la ripetizione del training.
Questo non è l'unico metodo possibile. Databricks supporta la pianificazione dei notebook come processi Tuttavia, in base all'esperienza client corrente, questo approccio è difficile da instrumentare con le procedure DevOps complete a causa delle limitazioni dei test.
È importante anche comprendere quali metriche vengono usate per considerare riuscito un modello. L'accuratezza da sola spesso non basta per determinare le prestazioni complessive di un modello rispetto a un altro.
Considerazioni sulle risorse di calcolo
- L'uso dei contenitori per standardizzare gli ambienti di calcolo è una soluzione che i clienti dovrebbero prendere in considerazione. Quasi tutte le destinazioni di calcolo di Azure Machine Learning supportano l'uso di Docker. La gestione delle dipendenze da parte di un contenitore può ridurre notevolmente l'attrito, soprattutto se il team usa molte destinazioni di calcolo.
Considerazioni sulla gestione dei modelli
- Azure Machine Learning SDK offre un'opzione per la distribuzione direttamente in servizio Azure Kubernetes (AKS) da un modello registrato, creando limiti per la sicurezza o le metriche applicate. È possibile provare a trovare una soluzione più semplice per i client per testare il modello, ma è consigliabile sviluppare una distribuzione più affidabile nel servizio Azure Kubernetes per i carichi di lavoro di produzione.
Passaggi successivi
- Altre informazioni su MLOps
- MLOps in Azure
- Visualizzazioni di Monitoraggio di Azure
- Ciclo di vita di Machine Learning
- Estensione Azure DevOps per Machine Learning
- Interfaccia della riga di comando di Azure Machine Learning
- Attivare applicazioni, processi o flussi di lavoro CI/CD basati su eventi di Azure Machine Learning
- Configurare il training e la distribuzione dei modelli con Azure DevOps
Risorse correlate
- Modello di maturità MLOps
- Orchestrare MLOps in Azure Databricks usando Databricks Notebook
- MLOps per i modelli Python con Azure Machine Learning
- Data science e Machine Learning con Azure Databricks
- Intelligenza artificiale per i cittadini con Power Platform
- Distribuire l'intelligenza artificiale e l'elaborazione di Machine Learning in locale e nel perimetro