Antipattern di recupero estraneo
Gli antipattern sono difetti di progettazione comuni che possono rompere il software o le applicazioni in situazioni di stress e non devono essere trascurati. In un antipattern di recupero estraneo vengono recuperati più dati del necessario per un'operazione aziendale, causando spesso un sovraccarico di I/O non necessario e una velocità di risposta ridotta.
Esempi di antipattern di recupero estraneo
Questo antipattern può verificarsi se l'applicazione prova a ridurre al minimo le richieste I/O recuperando tutti i dati che potrebbero essere necessari. Spesso si tratta di un risultato della sovracompensazione per l'antipattern I/O "frammentato". Ad esempio, un'applicazione può recuperare i dettagli per ogni prodotto in un database. Ma l'utente potrebbe aver bisogno solamente di un subset dei dettagli (alcuni potrebbero non essere rilevanti per i clienti) e probabilmente non aver bisogno di vedere tutti i prodotti in una sola volta. Anche se l'utente sfoglia l'intero catalogo, potrebbe essere più utile impaginare i risultati, mostrandone ad esempio 20 alla volta.
Un'altra origine di questo problema è quella di seguire delle programmazioni o delle procedure consigliate di progettazione non ottimali. Ad esempio, il codice seguente usa Entity Framework per recuperare i dettagli completi per ogni prodotto. Poi filtra i risultati per restituire solo un subset dei campi, ignorando il resto. L'esempio completo è disponibile qui.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
Nell'esempio successivo l'applicazione recupera i dati per eseguire un'aggregazione che poteva essere invece eseguita dal database. L'applicazione calcola le vendite totali raccogliendo ogni record per tutti gli ordini venduti e poi calcolando la somma su tali record. L'esempio completo è disponibile qui.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
L'esempio successivo mostra un problema complesso causato dal modo in cui Entity Framework usa LINQ to Entities.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
L'applicazione cerca di trovare i prodotti con un SellStartDate in più rispetto alla settimana precedente. Nella maggior parte dei casi, LINQ to Entities converte una clausola where in un'istruzione SQL che viene eseguita dal database. In questo caso, tuttavia, LINQ to Entities non può eseguire il mapping del metodo AddDays in SQL. Al contrario, vengono restituite tutte le righe dalla tabella Product e i risultati vengono filtrati in memoria.
La chiamata a AsEnumerable è un suggerimento che indica un problema. Questo metodo converte i risultati in un'interfaccia IEnumerable. Sebbene IEnumerable supporti il filtro, il filtro viene applicato sul lato client, non sul database. Per impostazione predefinita, LINQ to Entities usa IQueryable, che passa la responsabilità per il filtro all'origine dati.
Come correggere l'antipattern di recupero estraneo
Evitare il recupero di grandi volumi di dati che potrebbero presto risultare obsoleti o potrebbero essere scartati e recuperare solo i dati necessari per l'esecuzione dell'operazione.
Invece di ottenere ogni colonna da una tabella e filtrarla successivamente, selezionare le colonne necessarie dal database.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
Analogamente, eseguire l'aggregazione nel database e non nella memoria dell'applicazione.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Quando si usa Entity Framework, verificare che le query LINQ vengano risolte usando l'interfaccia IQueryable e non IEnumerable. Potrebbe essere necessario modificare la query per usare solo le funzioni che possono essere mappate nell'origine dati. L'esempio precedente può essere sottoposto a refactoring per rimuovere il metodo AddDays dalla query, consentendo di applicare un filtro dal database.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Considerazioni
In alcuni casi è possibile migliorare le prestazioni tramite il partizionamento orizzontale dei dati. Se diverse operazioni hanno accesso a diversi attributi dei dati, il partizionamento orizzontale può ridurre le contese. Spesso, la maggior parte delle operazioni vengono eseguite su un piccolo subset dei dati, pertanto se si estende il carico le prestazioni possono migliorare. Vedere Partizionamento dei dati.
Per le operazioni che devono supportare query unbounded, implementare l'impaginazione e recuperare solo un numero limitato di entità alla volta. Ad esempio, se un cliente sta sfogliando un catalogo dei prodotti, è possibile visualizzare una pagina di risultati alla volta.
Dove possibile, sfruttare i vantaggi delle funzionalità compilate nell'archivio dati. Ad esempio, i database SQL in genere forniscono funzioni di aggregazione.
Se si usa un archivio dati che non supporta una determinata funzione, ad esempio l'aggregazione, è possibile archiviare il risultato calcolato altrove, aggiornando il valore a seconda dei record che vengono aggiunti o aggiornati. In questo modo, l'applicazione non deve ricalcolare il valore ogni volta che viene richiesto.
Se si nota che le richieste stanno recuperando un numero elevato di campi, esaminare il codice sorgente per determinare se tutti questi campi sono necessari. A volte queste richieste sono il risultato di una query
SELECT *progettata in modo non adeguato.Analogamente, le richieste che recuperano un numero elevato di entità potrebbero indicare che l'applicazione non filtra i dati correttamente. Verificare che tutte queste entità siano necessarie. Usare il filtro dal lato del database se possibile, ad esempio, usando le clausole
WHEREin SQL.Eseguire il processo di offload nel database non è sempre la scelta migliore. Usare questa strategia solo quando il database è progettato o ottimizzato per eseguire questa operazione. La maggior parte dei sistemi di database è altamente ottimizzata per determinate funzioni, ma non è progettata per fungere da motori di applicazione generici. Per altre informazioni, vedere Antipattern del database occupato.
Come rilevare un antipattern di recupero estraneo
I sintomi del recupero di estranei includono una latenza elevata e una bassa velocità effettiva. Se i dati vengono recuperati da un archivio dati, è probabile anche un aumento della contesa. È probabile che gli utenti finali segnalano tempi di risposta estesi o errori causati dal timeout dei servizi. Questi errori potrebbero restituire errori HTTP 500 (server interno) o errori HTTP 503 (servizio non disponibile). Esaminare i log di eventi per il server Web che possono contenere informazioni più dettagliate sulle cause e le circostanze degli errori.
I sintomi di questo antipattern e alcuni dei dati di telemetria ottenuti potrebbero essere molto simili a quelli dell'antipattern di Persistenza monolitica.
È possibile eseguire la procedura seguente per identificare la causa:
- Identificare i carichi di lavoro o le transazioni lenti tramite l'esecuzione di test di carico, il monitoraggio del processo o altri metodi di acquisizione dei dati di strumentazione.
- Osservare gli eventuali modelli di comportamento mostrati dal sistema. Esistono limiti particolari in termini di transazioni al secondo o di volume degli utenti?
- Correlare le istanze dei carichi di lavoro lenti con i modelli di comportamento.
- Identificare gli archivi dati in uso. Per ogni origine dati, eseguire la telemetria di livello inferiore per osservare il comportamento delle operazioni.
- Identificare le query a esecuzione lenta che fanno riferimento a queste origini dati.
- Eseguire un'analisi delle risorse specifiche delle query a esecuzione lenta e verificare come vengono usati e consumati i dati.
Cercare uno qualsiasi dei seguenti sintomi:
- Richieste frequenti, elevate I/O presentate allo stesso archivio dati o risorsa.
- Contesa in un archivio dati o di risorse condivise.
- Un'operazione che riceve spesso grandi volumi di dati nella rete.
- Applicazioni e servizi che impiegano un lasso di tempo consistente in attesa del completamento di I/O.
Diagnosi di esempio
Nelle sezioni seguenti si applica questa procedura agli esempi precedenti.
Identificare i carichi di lavoro lenti
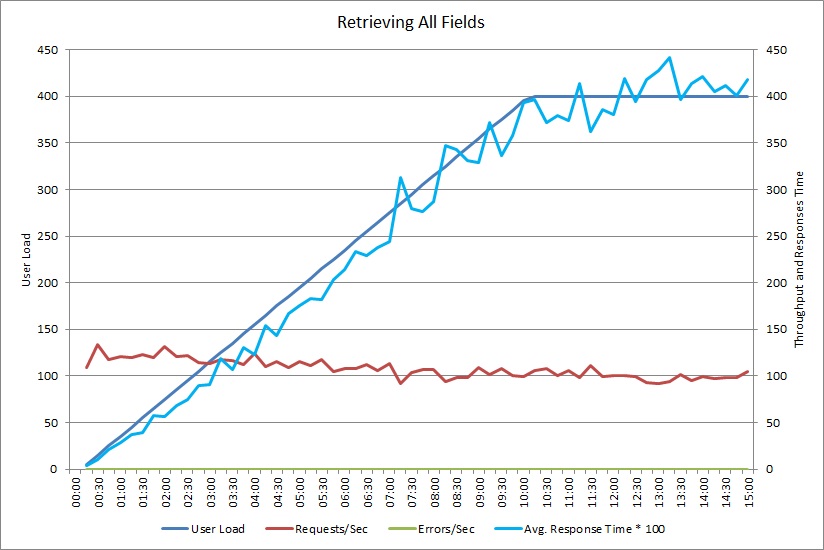
Questo grafico mostra i risultati delle prestazioni da un test di carico che ha simulato fino a 400 utenti concorrenti che eseguono il metodo GetAllFieldsAsync illustrato in precedenza. La velocità effettiva diminuisce lentamente man mano che aumenta il carico. Il tempo medio di risposta aumenta man mano che aumenta il carico di lavoro.
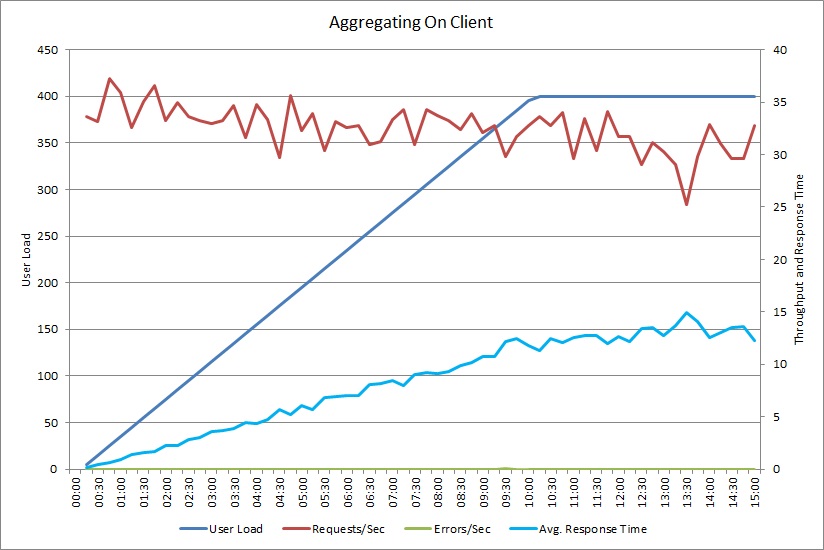
Un test di carico per l'operazione AggregateOnClientAsync mostra un modello simile. Il volume delle richieste è abbastanza stabile. Il tempo medio di risposta aumenta con il carico di lavoro, anche se più lentamente rispetto al grafico precedente.
Correlare i carichi di lavoro lenti con i modelli di comportamento
Eventuali correlazioni tra i normali periodi di utilizzo elevato e il rallentamento delle prestazioni possono indicare aree problematiche. Esaminare attentamente il profilo delle prestazioni della funzionalità di cui si sospetta l'esecuzione lenta per determinare se corrisponde con il test di carico eseguito in precedenza.
Eseguire il test di carico sulla stessa funzionalità usando carichi utente basati sul passaggio per trovare il punto in cui le prestazioni scendono in modo significativo o non riescono affatto. Se tale punto è compreso entro i limiti dell'uso reale previsto, esaminare in che modo è implementata la funzionalità.
Un'operazione lenta non è necessariamente un problema, se non viene eseguita quando il sistema è in condizioni di stress, non ha una situazione problematica a livello di tempo e non influisce negativamente sulle prestazioni di altre operazioni importanti. Ad esempio, la generazione di statistiche operative mensili potrebbe essere un'operazione con esecuzione prolungata, ma probabilmente può essere eseguita come processo batch e come processo con bassa priorità. D'altra parte, l'esecuzione di query del catalogo dei prodotti da parte dei clienti è un'operazione aziendale critica. Concentrarsi sui dati di telemetria generati da queste operazioni critiche per osservare come variano le prestazioni durante i periodi di utilizzo elevato.
Identificare le origini dati nei carichi di lavoro lenti
Se si ritiene che un servizio viene eseguito in modo inadeguato a causa del modo in cui avviene il recupero dei dati, esaminare come l'applicazione interagisce con il repository che usa. Monitorare il sistema in tempo reale per vedere a quali origini si ha accesso durante i periodi di riduzione delle prestazioni.
Per ogni origine dati, instrumentare il sistema per acquisire gli elementi seguenti:
- La frequenza con cui si ha accesso a ogni archivio dati.
- Il volume dei dati che entrano ed escono dall'archivio dati.
- I tempi di queste operazioni, in particolare la latenza delle richieste.
- La natura e la frequenza degli errori che si verificano durante l'accesso a ogni archivio dati con un carico tipico.
Confrontare queste informazioni sul volume dei dati restituiti dall'applicazione al client. Tenere traccia del rapporto del volume dei dati restituiti dall'archivio dati rispetto al volume dei dati restituiti al client. Se non vi è alcuna disparità di grandi dimensioni, indagare per determinare se l'applicazione recupera dati di cui non ha bisogno.
Potrebbe essere possibile acquisire questi dati osservando il sistema in tempo reale e tenendo traccia del ciclo di vita di ogni richiesta dell'utente oppure è possibile modellare una serie di carichi di lavoro sintetici ed eseguirli in relazione a un sistema di test.
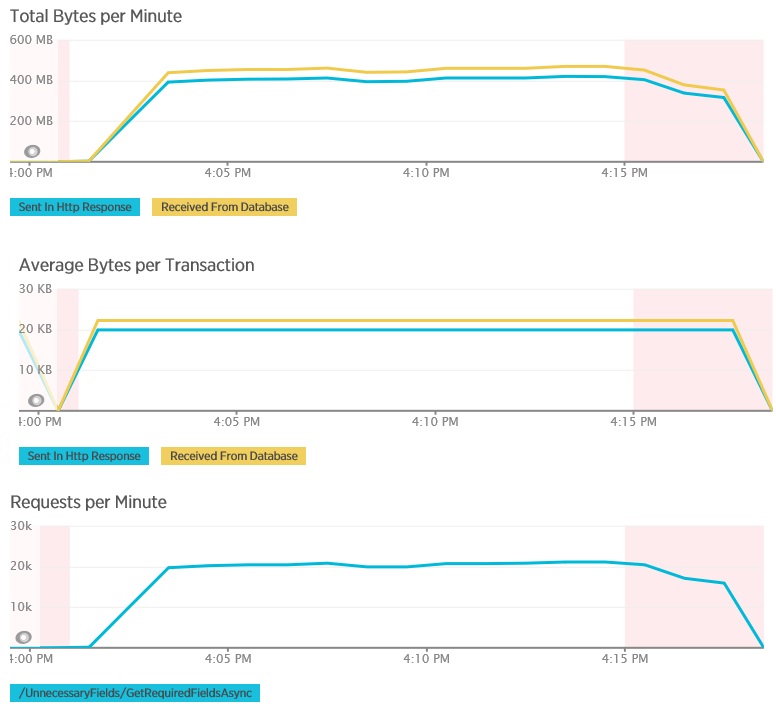
I grafici seguenti mostrano la telemetria acquisita tramite New Relic APM durante un test di carico del metodo GetAllFieldsAsync. Si noti la differenza tra i volumi di dati ricevuti dal database e le risposte HTTP corrispondenti.
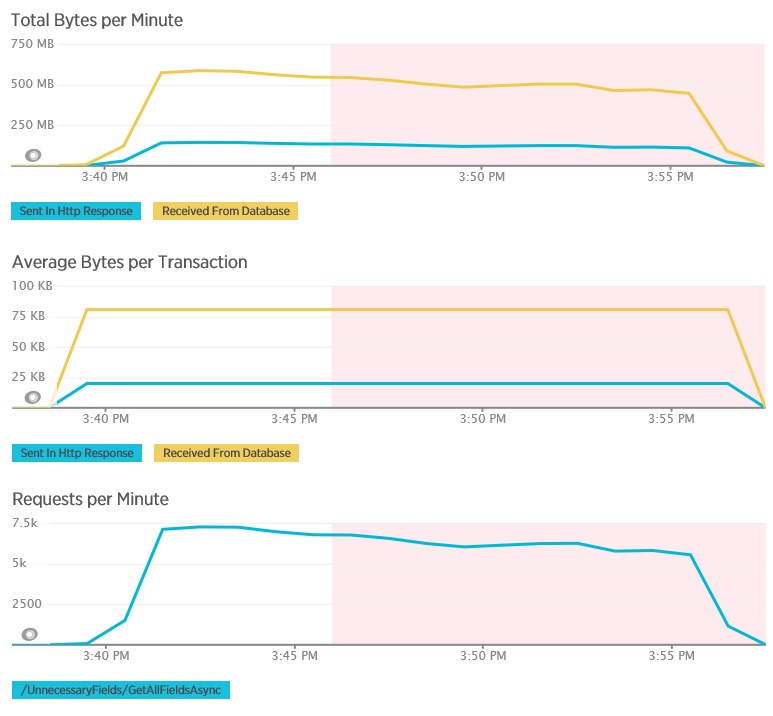
Per ogni richiesta, il database ha restituito 80.503 byte, ma la risposta al client conteneva solo 19.855 byte, circa il 25% delle dimensioni della risposta del database. Le dimensioni dei dati restituiti al client possono variare a seconda del formato. Per questo test di carico, il client ha richiesto i dati JSON. L'esecuzione di test separati usando XML (non illustrato) ha avuto una dimensione della risposta di 35.655 byte, o del 44% delle dimensioni della risposta del database.
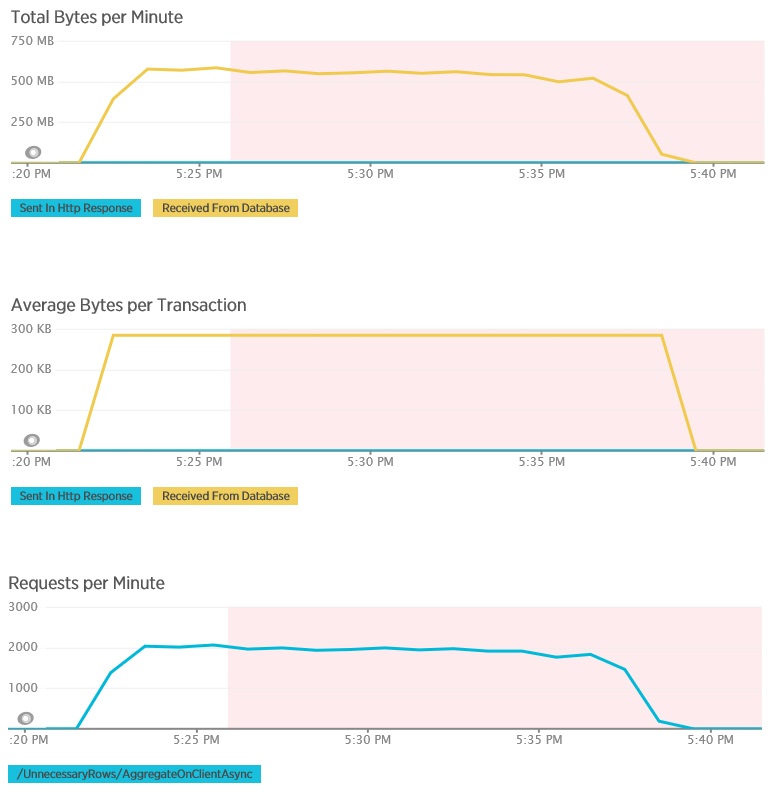
Il test di carico per il metodo AggregateOnClientAsync mostra più risultati estremi. In questo caso, ogni test ha eseguito una query che ha recuperato più di 280 KB di dati dal database, ma la risposta JSON era di soli 14 byte. L'ampia disparità è dovuta al fatto che il metodo calcola un risultato aggregato da un grande volume di dati.
Identificare e analizzare le query lente
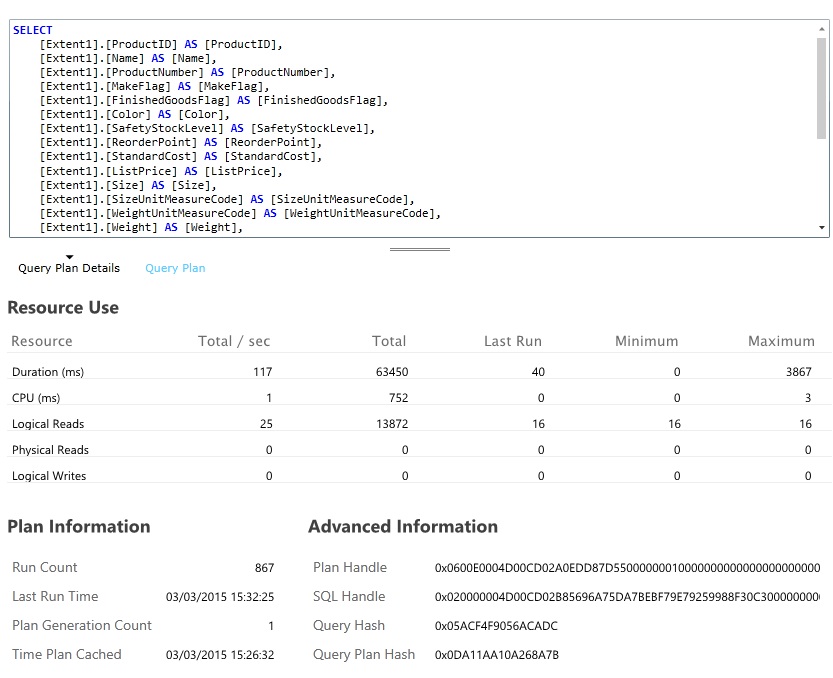
Cercare le query del database che usano la maggior parte delle risorse e richiedono più tempo per l'esecuzione. È possibile aggiungere altri strumenti per trovare le ore di inizio e di completamento per molte operazioni del database. Inoltre, molti archivi dati forniscono informazioni dettagliate su come vengono eseguite e ottimizzate le query. Ad esempio, il riquadro delle Prestazioni delle query nel portale di gestione di Database SQL di Azure consente di selezionare una query e di visualizzare le informazioni dettagliate sulle prestazioni di runtime. Ecco la query generata per l'operazione GetAllFieldsAsync:
Implementare la soluzione e verificare il risultato
Dopo aver modificato il metodo GetRequiredFieldsAsync per usare un'istruzione SELECT sul lato database, il test di carico ha mostrato i risultati seguenti.
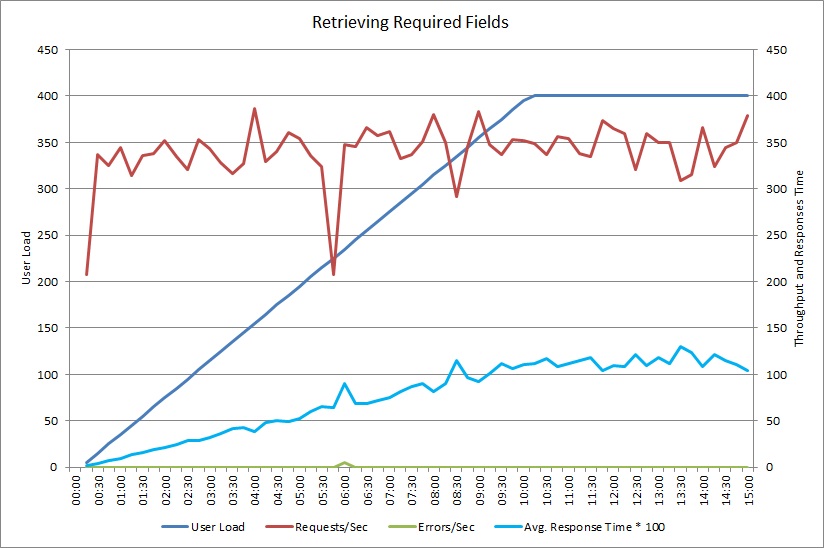
Questo test di carico ha usato la stessa distribuzione e lo stesso carico di lavoro simulato di 400 utenti concorrenti usato in precedenza. Il grafico mostra una latenza di molto inferiore. Il tempo di risposta aumenta con il carico a circa 1,3 secondi, rispetto ai 4 secondi nel caso precedente. Anche la velocità effettiva è superiore, con 350 richieste per secondo rispetto alle 100 precedenti. Il volume dei dati recuperati dal database ora corrispondono alle dimensioni dei messaggi di risposta HTTP.
L'esecuzione del test di carico tramite il metodo AggregateOnDatabaseAsync genera i risultati seguenti:
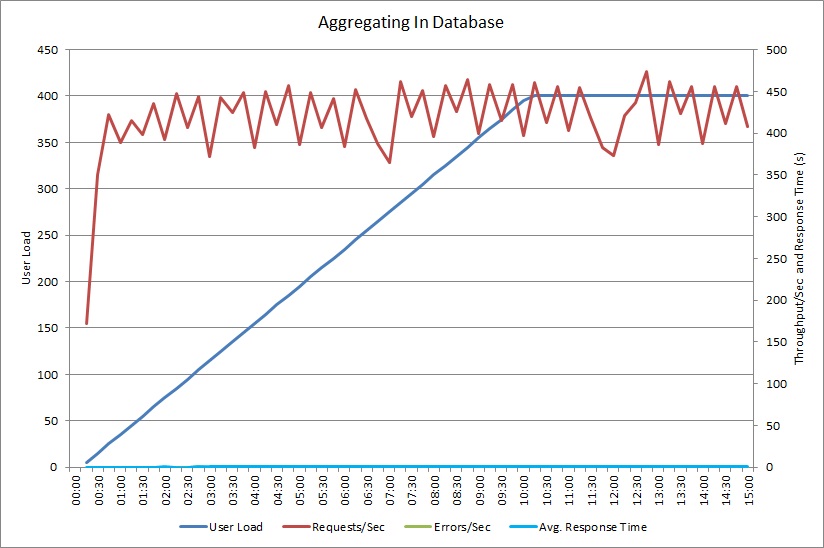
Il tempo di risposta medio è ora minimo. Si tratta di un ordine di miglioramento della grandezza delle prestazioni, dovuto principalmente alla riduzione delle grandi dimensioni in I/O dal database.
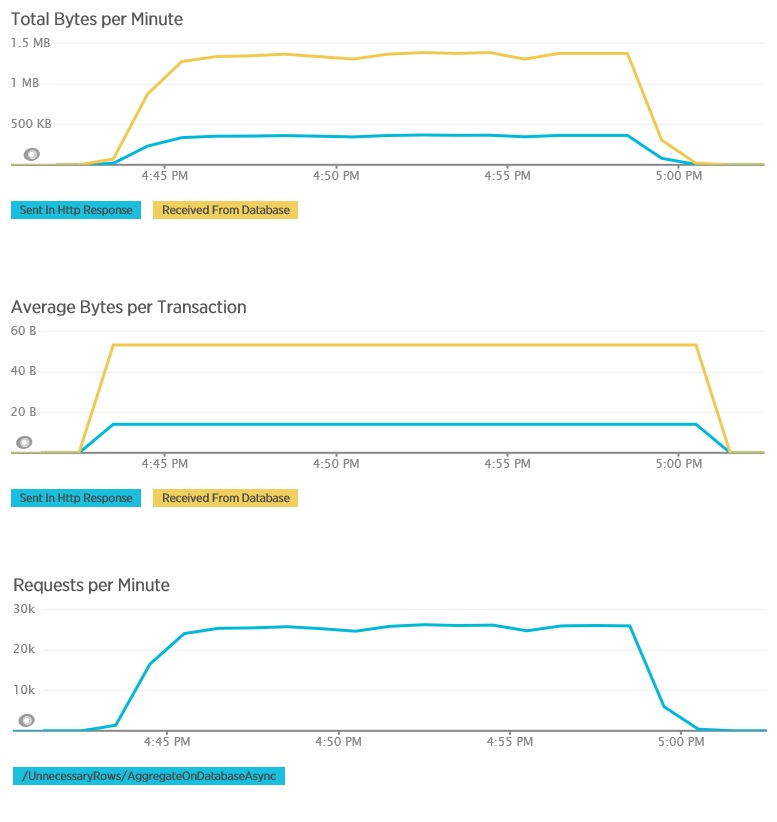
Ecco i dati di telemetria corrispondenti per il metodo AggregateOnDatabaseAsync. La quantità di dati recuperati dal database è stata notevolmente ridotta, da oltre 280 KB per transazione a 53 byte. Di conseguenza, il numero massimo sostenuto di richieste al minuto è stato aumentato da circa 2.000 a più di 25.000.
Risorse correlate
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per