La memorizzazione nella cache è una tecnica comune che ha l'obiettivo di migliorare le prestazioni e la scalabilità del sistema. Memorizza nella cache i dati copiando temporaneamente i dati a cui si accede di frequente in una risorsa di archiviazione veloce che si trova vicino all'applicazione. Se questa risorsa di archiviazione rapida dei dati si trova più vicina all'applicazione rispetto all'origine iniziale, la memorizzazione nella cache può migliorare significativamente i tempi di risposta per le applicazioni client fornendo i dati più rapidamente.
La memorizzazione nella cache è più efficace quando un'istanza di un client legge ripetutamente gli stessi dati, soprattutto se per l'archivio dati originale si verificano tutte le condizioni seguenti:
- Rimane relativamente statico.
- È lento rispetto alla velocità della cache.
- È soggetto a un elevato livello di contesa.
- Si trova lontano a tal punto che una latenza di rete potrebbe comportare lentezza nell'accesso.
Memorizzazione nella cache di applicazioni distribuite
Le applicazioni distribuite solitamente implementano una o entrambe le due strategie seguenti durante la memorizzazione nella cache dei dati:
- Usano una cache privata, in cui i dati vengono mantenuti localmente nel computer che esegue un'istanza di un'applicazione o di un servizio.
- Usano una cache condivisa, che funge da origine comune a cui è possibile accedere da più processi e computer.
In entrambi i casi, la memorizzazione nella cache può essere eseguita sul lato client e sul lato server. La memorizzazione nella cache sul lato client viene eseguita dal processo che fornisce l'interfaccia utente per un sistema, ad esempio un Web browser o un'applicazione desktop. La memorizzazione nella cache sul lato server viene eseguita dal processo che fornisce i servizi aziendali in esecuzione in remoto.
Memorizzazione nella cache privata
Il tipo più semplice di cache è un archivio in memoria. Questo è situato nello spazio di indirizzi di un singolo processo ed è accessibile direttamente da parte del codice in esecuzione nel processo. Questo tipo di cache è accessibile rapidamente Può anche offrire un mezzo efficace per archiviare quantità modeste di dati statici. Le dimensioni di una cache sono in genere vincolate dalla quantità di memoria disponibile nel computer che ospita il processo.
Se è necessario memorizzare nella cache un maggior numero di informazioni in memoria rispetto a quanto fisicamente possibile, sarà possibile scrivere i dati memorizzati nella cache nel file system locale. Questo processo sarà più lento rispetto all'accesso rispetto ai dati contenuti in memoria, ma dovrebbe essere ancora più veloce e affidabile rispetto al recupero dei dati in una rete.
Se si dispone di più istanze di un'applicazione che usa questo modello in esecuzione in modo simultaneo, ciascuna istanza dell'applicazione dispone della propria cache indipendente, contenente una copia distinta dei dati.
Si può pensare a una cache come a uno snapshot dei dati originali in un determinato momento nel passato. Se questi dati non sono statici, è probabile che diverse istanze dell'applicazione contengano versioni diverse dei dati nella cache. Pertanto, la stessa query eseguita da tali istanze può restituire risultati diversi, come mostrato nella Figura 1.
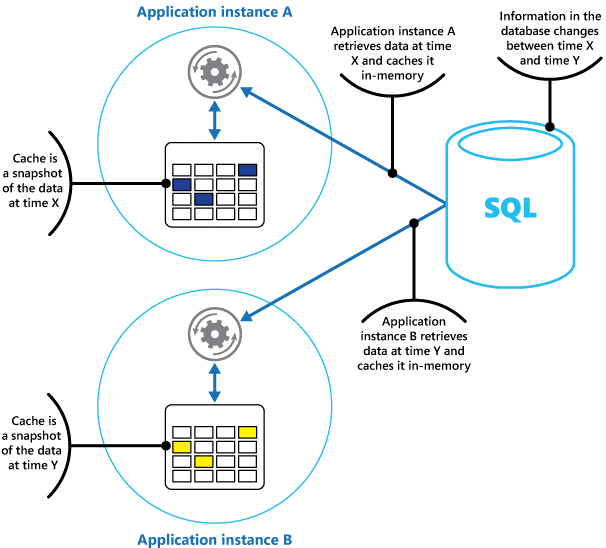
Figura 1: uso di una cache in memoria in diverse istanze di un'applicazione.
Memorizzazione nella cache condivisa
Se si usa una cache condivisa, può contribuire ad alleviare le preoccupazioni che i dati potrebbero differire in ogni cache, che possono verificarsi con la memorizzazione nella cache in memoria. La memorizzazione nella cache condivisa garantisce che istanze diverse di un'applicazione abbiano accesso alla stessa visualizzazione di dati memorizzati nella cache. Individua la cache in una posizione separata, in genere ospitata come parte di un servizio separato, come illustrato nella figura 2.
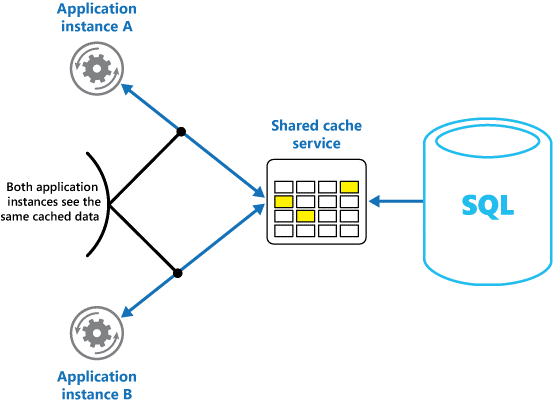
Figura 2: uso di una cache condivisa.
Un vantaggio importante dell'approccio basato sulla memorizzazione nella cache condivisa è rappresentato dalla scalabilità. Molti servizi di cache condivisa vengono implementati mediante l'uso di un cluster di server e usano il software per distribuire i dati nel cluster in modo trasparente. Un'istanza dell'applicazione invia semplicemente una richiesta al servizio cache. L'infrastruttura sottostante determina la posizione dei dati memorizzati nella cache nel cluster. È possibile aumentare la quantità di cache aggiungendo più server.
L'approccio basato sulla memorizzazione nella cache condivisa presenta due svantaggi principali:
- L'accesso alla cache è più lento perché non viene più mantenuto in locale in ogni istanza dell'applicazione.
- L'esigenza di implementare un servizio cache separato potrebbe comportare una maggiore complessità della soluzione.
Considerazioni sull'uso della memorizzazione della cache
Nelle sezioni seguenti vengono descritte considerazioni in modo più dettagliato per la progettazione e l'uso di una cache.
Decidere quando memorizzare i dati nella cache
La memorizzazione nella cache può migliorare significativamente le prestazioni, la scalabilità e la disponibilità. Maggiore la quantità di dati a disposizione e maggiore il numero di utenti che dovranno accedere a tali dati, maggiori saranno i vantaggi della memorizzazione nella cache. La memorizzazione nella cache riduce la latenza e la contesa associata alla gestione di grandi volumi di richieste simultanee nell'archivio dati originale.
Ad esempio, un database potrebbe supportare un numero limitato di connessioni simultanee, ma il recupero di dati da una cache condivisa, tuttavia, piuttosto che da un database sottostante consente a un'applicazione client di accedere ai dati anche se il numero di connessioni disponibili è esaurito. Inoltre, se il database non fosse disponibile, l'esecuzione delle applicazioni client potrebbe continuare grazie ai dati contenuti nella cache.
Si prenda in considerazione l'opportunità di memorizzare nella cache i dati letti di frequente, ma modificati raramente, ad esempio i dati che in proporzione subiscono più operazioni di lettura che di scrittura. Non è però consigliabile usare la cache come archivio autorevole di informazioni di rilevanza critica. Assicurarsi invece che tutte le modifiche che l'applicazione non possa permettersi di perdere vengono sempre salvate in un archivio dati permanente. Se la cache non è disponibile, l'applicazione può continuare a funzionare usando l'archivio dati e non si perderanno informazioni importanti.
Determinare come memorizzare dati nella cache in modo efficace
Il modo fondamentale in cui usare una cache in modo efficiente consiste nello stabilire i dati più importanti da memorizzare nella cache e l'orario più adatto. I dati possono essere aggiunti alla cache su richiesta la prima volta che vengono recuperati da un'applicazione. L'applicazione deve recuperare i dati una sola volta dall'archivio dati e che l'accesso successivo può essere soddisfatto usando la cache.
In alternativa, una cache può essere parzialmente o completamente popolata con i dati in anticipo, di solito all'avvio dell'applicazione (approccio noto come seeding). Tuttavia, potrebbe non essere consigliabile implementare il seeding per una cache di grosse dimensioni, poiché tale approccio potrebbe imporre un carico elevato e improvviso sull'archivio dati originale all'inizio dell'esecuzione dell'applicazione.
Spesso un'analisi dei modelli di uso consente di decidere se prepopolare completamente o parzialmente una cache e di scegliere i dati da memorizzare nella cache. Ad esempio, è possibile eseguire il seeding della cache con i dati del profilo utente statico per i clienti che usano regolarmente l'applicazione (ad esempio ogni giorno), ma non per i clienti che usano l'applicazione solo una volta alla settimana.
La memorizzazione nella cache solitamente funziona bene con i dati non modificabili o che non vengono modificati di frequente. Tra i possibili casi, informazioni di riferimento, ad esempio i dati dei prodotti e dei prezzi in un'applicazione di e-commerce, o risorse statiche condivise costose da costruire. A|cuni o tutti questi dati possono essere caricati nella cache all'avvio dell'applicazione per ridurre al minimo la richiesta di risorse e per migliorare le prestazioni. È anche possibile avere un processo in background che aggiorna periodicamente i dati di riferimento nella cache per assicurarsi che sia aggiornato. In alternativa, il processo in background può aggiornare la cache quando i dati di riferimento cambiano.
La memorizzazione nella cache è meno utile per i dati dinamici, anche se ci sono alcune eccezioni. Per altre informazioni, vedere la sezione Memorizzazione nella cache di dati altamente dinamici più avanti in questo articolo. Quando i dati originali cambiano regolarmente, le informazioni memorizzate nella cache diventano non aggiornate rapidamente o il sovraccarico della sincronizzazione della cache con l'archivio dati originale riduce l'efficacia della memorizzazione nella cache.
Una cache non deve includere i dati completi per un'entità. Ad esempio, se un elemento dati rappresenta un oggetto multivalore, ad esempio un cliente bancario con un nome, un indirizzo e un saldo del conto, alcuni di questi elementi potrebbero rimanere statici, ad esempio il nome e l'indirizzo. Altri elementi, ad esempio il saldo del conto, potrebbero essere più dinamici. In queste situazioni, può essere utile memorizzare nella cache le parti statiche dei dati e recuperare (o calcolare) solo le informazioni rimanenti quando sono necessarie.
È consigliabile effettuare il test delle prestazioni e l'analisi dell'utilizzo per stabilire se sia opportuno procedere al prepopolamento o al caricamento su richiesta della cache oppure una combinazione di entrambi. La decisione dovrebbe basarsi sulla volatilità e sul modello di uso dei dati. L'utilizzo della cache e l'analisi delle prestazioni sono importanti nelle applicazioni che riscontrano carichi elevati e devono essere altamente scalabili. Negli scenari altamente scalabili, ad esempio, è possibile eseguire il seeding della cache per ridurre il carico nell'archivio dati nei momenti di picco.
La memorizzazione nella cache può essere usata anche per evitare la ripetizione di calcoli durante l'esecuzione dell'applicazione. Se un'operazione trasforma i dati o esegue un calcolo complicato, potrebbe salvare i risultati dell'operazione nella cache. Se lo stesso calcolo è necessario successivamente, l'applicazione potrà semplicemente richiamare i risultati dalla cache.
Un'applicazione può modificare i dati conservati nella cache. È però consigliabile considerare la cache come un archivio dati temporaneo che potrebbe scomparire in qualsiasi momento. Non archiviare dati preziosi solo nella cache; assicurarsi di mantenere anche le informazioni nell'archivio dati originale. In questo modo, se la cache dovesse diventare non disponibile, la possibilità di perdere i dati sarebbe ridotta al minimo.
Memorizzazione nella cache di dati altamente dinamici
L'archiviazione di informazioni che cambiano rapidamente in un archivio dati permanente può comportare un sovraccarico del sistema. Ad esempio, si consideri un dispositivo che segnali continuamente uno stato o un altro tipo di misurazione. Se un'applicazione sceglie di non memorizzare nella cache i dati sulla base del fatto che le informazioni memorizzate nella cache saranno quasi sempre obsolete, le stesse considerazioni potrebbero valere anche durante l'archiviazione e il richiamo di tali informazioni dall'archivio dati. Nel tempo necessario a salvare e recuperare i dati, questi potrebbero essere stati modificati.
In una situazione simile, considerare i vantaggi di archiviare le informazioni dinamiche direttamente nella cache invece che nell'archivio dati permanente. Se i dati non sono critici e non richiedono il controllo, non è importante se la modifica occasionale viene persa.
Gestire la scadenza dei dati nella cache
Nella maggior parte dei casi, i dati conservati in una cache sono una copia dei dati conservati nell'archivio dati originale. I dati nell'archivio dati originale potrebbero cambiare dopo essere memorizzati nella cache, provocando l'obsolescenza dei dati memorizzati nella cache. Molti sistemi di memorizzazione nella cache consentono di configurare la cache per la scadenza dei dati e per la riduzione del periodo di tempo per cui i dati potrebbero risultare scaduti.
Quando i dati memorizzati nella cache scadono, vengono rimossi dalla cache e l'applicazione deve recuperare i dati dall'archivio dati originale, inserendo, se opportuno, le informazioni appena recuperate nella cache. Successivamente, sarà possibile impostare un criterio di scadenza predefinito durante la configurazione della cache. In molti servizi cache è anche possibile impostare il periodo di scadenza per i singoli oggetti al momento di archiviarli nella cache a livello di codice. Alcune cache consentono di specificare il periodo di scadenza come valore assoluto o come valore scorrevole che fa sì che l'elemento venga rimosso dalla cache se non è accessibile entro l'ora specificata. Questa impostazione esegue l'override di qualsiasi criterio di scadenza relativo alla cache, ma solo per gli oggetti specificati.
Nota
Si consideri attentamente il periodo di scadenza della cache e degli oggetti in essa contenuti. Se si imposta un periodo troppo ridotto, gli oggetti scadranno troppo rapidamente e si ridurranno i vantaggi dell'uso della cache. Se si imposta il periodo in modo troppo esteso, si rischi l'obsolescenza dei dati.
È inoltre possibile che la cache si riempia se ai dati è consentita una permanenza prolungata. In tal caso, qualsiasi richiesta di aggiungere nuovi elementi alla cache potrebbe comportare la rimozione forzata di alcuni elementi in un processo noto come rimozione. I servizi cache tipicamente rimuovono i dati usati meno di recente, ma è solitamente possibile eseguire l'override di questo criterio e impedire la rimozione di elementi. Tuttavia, se si adotta questo approccio, si rischia di superare la memoria disponibile nella cache. Un'applicazione che tenta di aggiungere un elemento alla cache non completerà l'operazione, generando un'eccezione.
Alcune implementazioni di memorizzazione nella cache possono specificare altri criteri di rimozione. Esistono diversi tipi di criteri di rimozione. tra cui:
- Un criterio usato più di recente (in attesa che i dati non vengano nuovamente richiesti).
- Criteri First-In-First-Out (i dati meno recenti vengono rimossi per primi).
- Criteri di rimozione esplicita in base all'attivazione di un evento (ad esempio la modifica dei dati).
Annullare i dati in una cache lato client
I dati contenuti in una cache lato client sono in genere considerati fuori dalla portata del servizio che fornisce i dati al client. Un servizio non può forzare direttamente un client ad aggiungere o rimuovere informazioni da una cache lato client.
Ciò significa che per un client che usa una cache configurata in modo non corretto è possibile continuare a usare informazioni non aggiornate. Ad esempio, se i criteri di scadenza della cache non sono implementati correttamente, un client potrebbe usare informazioni obsolete memorizzate in locale quando le informazioni nell'origine dati originale sono state modificate.
Se si compila un'applicazione Web che gestisce i dati tramite una connessione HTTP, è possibile forzare implicitamente un client Web (ad esempio un browser o un proxy Web) a recuperare le informazioni più recenti. Ciò è possibile se una risorsa viene aggiornata modificando l'URI della risorsa stessa. I client Web solitamente usano l'URI di una risorsa come chiave nella cache lato client, pertanto se l'URI cambia, il client Web ignora eventuali versioni di una risorsa memorizzate in precedenza nella cache e recupera la nuova versione.
Gestione della concorrenza in una cache
Le cache sono spesso progettate per essere condivise da più istanze di un'applicazione. Ciascuna istanza dell'applicazione può leggere e modificare i dati nella cache. Di conseguenza, gli stessi problemi di concorrenza che si verificano con qualsiasi archivio dati condiviso valgono anche per una cache. In una situazione in cui un'applicazione deve modificare i dati contenuti nella cache, potrebbe essere necessario assicurarsi che gli aggiornamenti eseguiti da un'istanza dell'applicazione non sovrascrivano le modifiche apportate da un'altra istanza.
A seconda della natura dei dati e della probabilità delle collisioni, è possibile uno dei due seguenti approcci alla concorrenza:
- Ottimistico. Subito prima di aggiornare i dati, l'applicazione controlla se i dati nella cache siano stati modificati dopo che sono stati recuperati. Se i dati sono ancora gli stessi, sarà possibile apportare la modifica. In caso contrario, l'applicazione deve decidere se aggiornarli La logica di business che guida questa decisione sarà specifica dell'applicazione. Questo approccio è adatto per situazioni in cui gli aggiornamenti sono poco frequenti o in cui è improbabile che si verifichino conflitti.
- Pessimistico. Quando recupera i dati, l'applicazione li blocca all'interno della cache, per evitarne la modifica da parte di un'altra istanza. Questo processo garantisce che i conflitti non possano verificarsi, ma possono anche bloccare altre istanze che devono elaborare gli stessi dati. La concorrenza pessimistica può influire sulla scalabilità di una soluzione ed è consigliabile solo per operazioni di breve durata. Questo approccio potrebbe essere appropriato per situazioni in cui sono più probabili conflitti, soprattutto se un'applicazione aggiorna più elementi nella cache e deve assicurarsi che queste modifiche vengano applicate in modo coerente.
Implementare disponibilità elevata e scalabilità e migliorare le prestazioni
Evitare di usare una cache come repository principale dei dati. Questo è il ruolo dell'archivio dati originale da cui la cache viene popolata. L'archivio dati originale è responsabile di garantire la persistenza dei dati.
Prestare attenzione a non introdurre dipendenze critiche per la disponibilità di un servizio di cache condivisa nelle soluzioni. Un'applicazione deve essere in grado di continuare a funzionare anche se il servizio che fornisce la cache condivisa non è disponibile. L'applicazione non deve rispondere o non rispondere durante l'attesa della ripresa del servizio cache.
Pertanto, l'applicazione deve essere preparata per rilevare la disponibilità del servizio cache e il fallback all'archivio dati originale se la cache non è accessibile. Il modello a interruttore è utile per la gestione di questo scenario. È possibile ripristinare il servizio che fornisce la cache. Non appena questo torna disponibile, la cache può essere ripopolata man mano che i dati vengono letti dall'archivio dati originale, seguendo una strategia come il modello cache-aside.
Tuttavia, se l'applicazione esegue il fallback all'archivio dati originale quando la cache è temporaneamente non disponibile, si potrebbe avere un impatto sulla scalabilità del sistema. Mentre viene recuperato l'archivio dati, l'archivio dati originale potrebbe essere sovraccaricato da richieste di dati, con conseguenti timeout ed errori di connessione.
Prendere in considerazione la possibilità di implementare una cache locale privata in ogni istanza di un'applicazione insieme alla cache condivisa a cui accedono tutte le istanze dell'applicazione. Quando l'applicazione deve recuperare un elemento, può cercarlo prima nella propria cache locale, quindi nella cache condivisa e infine nell'archivio dati originale. La cache locale può essere popolata con i dati nella cache condivisa o nel database, se la cache condivisa non è disponibile.
Questo approccio richiede una configurazione attenta per evitare che la cache locale diventi obsoleta rispetto alla cache condivisa. Tuttavia, la cache locale funge da buffer se la cache condivisa non è raggiungibile. Nella Figura 3 viene illustrata questa struttura.
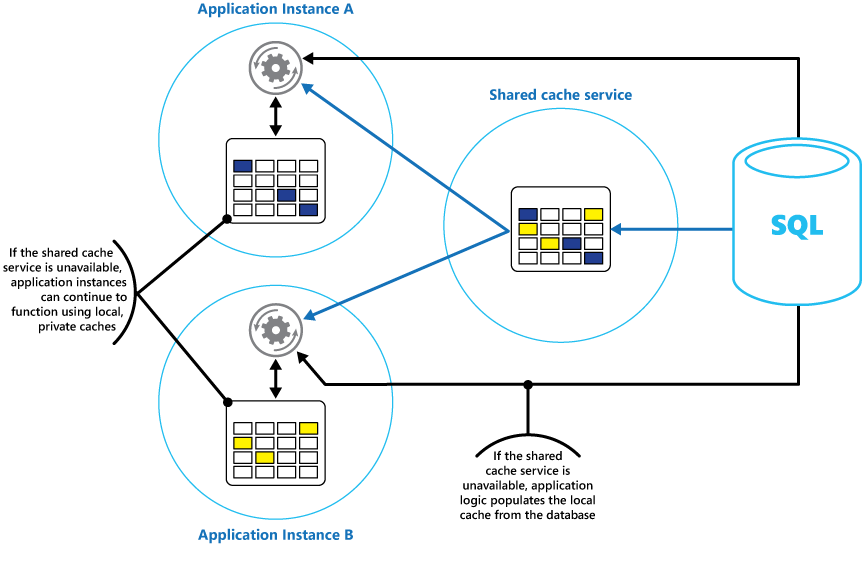
Figura 3: uso di una cache privata locale con una cache condivisa.
Per supportare la cache di grandi dimensioni che contengono dati di durata relativamente lunga, alcuni servizi cache forniscono un'opzione di disponibilità elevata che implementa il failover automatico, se la cache non è più disponibile. Questo approccio implica in genere la replica in un server di cache secondario dei dati memorizzati nella cache archiviati in un server di cache primario, implicando anche il passaggio al server secondario se il server primario non funziona o se la connessione viene persa.
Per ridurre la latenza associata a più destinazioni, la replica nel server secondario può verificarsi in modo asincrono quando i dati vengono scritti nella cache nel server primario. Questo approccio comporta la possibilità che alcune informazioni memorizzate nella cache vadano perse in caso di errore, ma la proporzione di questi dati deve essere ridotta rispetto alle dimensioni complessive della cache.
Se una cache condivisa è grande, potrebbe essere utile suddividere i dati memorizzati nella cache tra i nodi, per ridurre le probabilità di contesa e migliorare la scalabilità. Molte cache condivise supportano la possibilità di aggiungere in modo dinamico (e rimuovere) i nodi, ribilanciando i dati tra le partizioni. Questo approccio potrebbe richiedere il clustering, in cui la raccolta di nodi viene presentata alle applicazioni client come un'unica cache. Internamente, tuttavia, i dati sono suddivisi tra i nodi secondo una strategia di distribuzione predefinita che consente di bilanciare il carico in modo uniforme. Per altre informazioni sulle possibili strategie di partizionamento, vedere Linee guida di partizionamento di dati.
Il clustering può anche aumentare la disponibilità della cache. Se un nodo non funziona, il resto della cache è comunque disponibile. Il clustering viene spesso usato in combinazione con la replica e il failover. Ogni nodo può essere replicato e la replica può essere rapidamente portata online se il nodo non funziona.
È probabile che molte operazioni di lettura e di scrittura coinvolgano valori di dati o oggetti singoli. Tuttavia, talvolta potrebbe essere necessario archiviare o recuperare rapidamente elevati volumi di dati. Ad esempio, il seeding di una cache può comportare la scrittura di centinaia o di migliaia di elementi nella cache. Per un'applicazione potrebbe anche essere necessario recuperare dalla cache un numero elevato di elementi correlati con la stessa richiesta.
Molte cache su larga scala forniscono operazioni batch per tali scopi. Ciò consente a un'applicazione client di creare il pacchetto di un volume elevato di elementi in una singola richiesta e riduce il sovraccarico associato all'esecuzione di un numero elevato di richieste di ridotte dimensioni.
Memorizzazione nella cache e coerenza finale
Perché il modello cache-aside funzioni, l'istanza dell'applicazione che popola la cache deve accedere alla versione più recente e coerente dei dati. In un sistema che implementa la coerenza finale (ad esempio, un archivio di dati replicati), ciò potrebbe non verificarsi.
Un'istanza di un'applicazione può modificare un elemento di dati e invalidare la versione memorizzata nella cache dell'elemento. Un'altra istanza dell'applicazione potrebbe tentare di leggere l'elemento dalla cache provocando un mancato riscontro nella cache, in modo da leggere i dati dall'archivio dati e aggiungerli alla cache. Tuttavia, se l'archivio dati non è stato completamente sincronizzato con le altre repliche, l'istanza dell'applicazione potrebbe leggere e popolare la cache con il valore precedente.
Per altre informazioni sulla gestione della coerenza dei dati, vedere Data consistency primer (Primer della coerenza dei dati).
Proteggere i dati memorizzati nella cache
Qualunque sia il servizio cache in uso, è necessario considerare il modo in cui proteggere i dati contenuti nella cache da accessi non autorizzati. Esistono due problemi principali:
- La riservatezza dei dati nella cache.
- La riservatezza del flusso dei dati tra la cache e l'applicazione che usa la cache.
Per proteggere i dati nella cache, il servizio cache può implementare un meccanismo di autenticazione che richiede alle applicazioni di specificare quanto segue:
- Le identità che possono accedere ai dati nella cache.
- Le operazioni (in lettura e in scrittura) che queste identità sono autorizzate a eseguire.
Per ridurre il sovraccarico associato alla lettura e alla scrittura dei dati, dopo che a un'identità è stato concesso l'accesso in scrittura o in lettura alla cache, tale identità può usare tutti i dati nella cache.
Se è necessario limitare l'accesso a subset di dati memorizzati nella cache, è possibile eseguire una delle operazioni seguenti:
- Suddividere la cache in partizioni (usando diversi server di cache) e concedere l'accesso alle identità solo per le partizioni che possono usare.
- Crittografare i dati in ogni subset con chiavi diverse e fornire le chiavi di crittografia solo alle identità che devono disporre dell'accesso a ogni subset. Un'applicazione client potrebbe comunque essere in grado di recuperare tutti i dati nella cache, ma sarà in grado di decrittografare solo i dati per i quali dispone delle chiavi.
È inoltre necessario proteggere i dati durante la trasmissione dalla cache e nella cache. Il raggiungimento di questo scopo dipende dalle funzionalità di sicurezza fornite dall'infrastruttura di rete usata dalle applicazioni client per connettersi alla cache. Se la cache è implementata tramite un server locale all'interno della stessa organizzazione che ospita le applicazioni client, grazie all'isolamento della rete stessa potrebbe non essere necessario eseguire altri passaggi. Se la cache è remota e richiede una connessione TCP o HTTP attraverso una rete pubblica (ad esempio Internet), prendere in considerazione l'implementazione del protocollo SSL.
Considerazioni per l'implementazione della cache in Azure
Cache di Azure per Redis è un'implementazione della cache Redis open source che viene eseguita come servizio in un data center di Azure. Se l'applicazione viene implementata come un servizio cloud, un sito Web o all'interno di una macchina virtuale di Azure fornisce un servizio di caching a cui è possibile accedere da qualsiasi applicazione Azure. Le cache possono essere condivise da applicazioni client che dispongono della chiave di accesso appropriato.
Cache di Azure per Redis è una soluzione di memorizzazione nella cache a prestazioni elevate che fornisce disponibilità, scalabilità e sicurezza. In genere, viene eseguita come servizio distribuito in uno o più computer dedicati e tenta di archiviare quante più informazioni possibile in memoria per garantire un rapido accesso. Questa architettura è destinata a fornire bassa latenza e velocità effettiva elevata, riducendo la necessità di eseguire lente operazioni di I/O.
Cache di Azure per Redis è compatibile con molte delle numerose API usate dalle applicazioni client. Se sono presenti applicazioni esistenti che usano già la cache di Azure per Redis in esecuzione in locale, la cache di Azure per Redis fornisce un percorso di migrazione rapido per la memorizzazione nella cache nel cloud.
Funzionalità di Redis
Redis è più di un semplice server di cache. Fornisce un database in memoria distribuito con un set di comandi completo che supporta molti scenari comuni descritti più avanti in questo documento, nella sezione Uso della memorizzazione nella cache di Redis. In questa sezione vengono riepilogate alcune delle funzionalità chiave fornite da Redis.
Redis come un database in memoria
Redis supporta operazioni sia di lettura e che di scrittura. In Redis le operazioni di scrittura possono essere protette dagli errori di sistema mediante memorizzazione periodica in un file di snapshot locale o in un file di log di solo accodamento. Questa situazione non è il caso in molte cache, che devono essere considerate archivi dati transitori.
Tutte le scritture sono asincrone e non impediscono ai client di leggere e scrivere dati. Quando viene avviata l'esecuzione di Redis, verranno letti i dati dal file di snapshot o di log e verranno usati per costruire la cache in memoria. Per altre informazioni, vedere la sezione relativa alla persistenza di Redis nel sito Web Redis.
Nota
Redis non garantisce che tutte le scritture vengano salvate se si verifica un errore irreversibile, ma nel peggiore dei casi si potrebbero perdere solo pochi secondi di dati. Tenere presente che una cache non è progettata per fungere da origine dati autorevole ed è responsabilità delle applicazioni che usano la cache per garantire che i dati critici vengano salvati correttamente in un archivio dati appropriato. Per altre informazioni, vedere il modello cache-aside.
Tipi di dati Redis
Redis è un archivio chiave-valore, dove i valori possono contenere tipi semplici o complesse strutture di dati, ad esempio gli hash, gli elenchi e i set. Redis supporta una serie di operazioni atomiche su questi tipi di dati. Le chiavi possono essere permanenti o contrassegnate con un periodo di durata limitato, dopo il quale la chiave e il valore corrispondente vengono automaticamente rimossi dalla cache. Per altre informazioni sulle chiavi e sui valori di Redis, visitare la pagina di introduzione ai tipi di dati e alle astrazioni Redis nel sito Web Redis.
Replica e cluster di Redis
Redis supporta la replica primaria/subordinata per garantire la disponibilità e gestire la velocità effettiva. Le operazioni di scrittura in un nodo primario di Redis vengono replicate su uno o più nodi subordinati. Le operazioni di lettura possono essere gestite dal nodo primario o da uno dei nodi subordinati.
Se si dispone di una partizione di rete, i subordinati possono continuare a gestire i dati e quindi risincronizzare in modo trasparente con il database primario quando la connessione viene ristabilita. Per ulteriori informazioni, visitare la pagina relativa alla replica sul sito Web di Redis.
Redis fornisce inoltre il clustering, che consente di suddividere in modo trasparente i dati in partizioni tra server e distribuire il carico. Questa funzionalità migliora la scalabilità, poiché man mano che la dimensione della cache aumenta è possibile aggiungere nuovi server Redis e partizionare di nuovo i dati.
Inoltre, ogni server del cluster può essere replicato usando la replica primaria/subordinata. Ciò garantisce la disponibilità in ogni nodo del cluster. Per altre informazioni sul clustering e sul partizionamento orizzontale, visitare la pagina dell'esercitazione sui cluster Redis nel sito Web Redis.
uso della memoria di Redis
La cache Redis ha una dimensione limitata che dipende dalle risorse disponibili nel computer host. Quando si configura un server Redis, è possibile specificare la quantità massima di memoria usabile. È anche possibile configurare una chiave in una cache Redis per avere una scadenza, dopo la quale viene rimossa automaticamente dalla cache. Questa funzionalità consente di evitare il riempimento della cache in memoria con dati obsoleti o non aggiornati.
Come la memoria si riempie, Redis automaticamente provvedere alla rimozione di chiavi e dei relativi valori seguendo un determinato numero di criteri. L'impostazione predefinita è LRU (almeno usata di recente), ma è anche possibile selezionare altri criteri, ad esempio la rimozione casuale o la disattivazione del tutto della rimozione (in questo caso, i tentativi di aggiungere elementi alla cache hanno esito negativo se è pieno). Altre informazioni sono disponibili nella pagina relativa all'uso di Redis come cache LRU.
Transazioni e batch Redis
Redis consente a un'applicazione client di inviare una serie di operazioni che consentono di leggere e scrivere dati nella cache come una transazione atomica. L'esecuzione di tutti i comandi della transazione è garantita come sequenziale. Non verrà interposto alcun comando emesso da altri client simultanei.
Tuttavia, queste transazioni non sono vere perché un database relazionale le eseguirà. L'elaborazione delle transazioni è costituita da due fasi: la prima corrisponde all'inserimento dei comandi in coda e a seconda corrisponde all'esecuzione dei comandi stessi. Durante la fase di accodamento messaggi del comando, i comandi che costituiscono la transazione vengono inviati dal client. Se si verificano errori di qualsiasi tipo a questo punto (ad esempio un errore di sintassi o un numero errato di parametri), Redis rifiuta di elaborare l'intera transazione e annulla le modifiche.
Durante la fase di esecuzione, Redis esegue ogni comando in coda in sequenza. Se un comando non riesce durante questa fase, Redis continua con il comando in coda successivo e non esegue il rollback degli effetti di tutti i comandi già eseguiti. Questo tipo di transazione semplificata consente di mantenere le normali prestazioni e di evitare problemi di prestazioni causati da contese.
Redis implementa una forma di blocco ottimistico per facilitare la gestione della coerenza. Per informazioni dettagliate sulle transazioni e sul blocco di Redis, visitare la pagina relativa alle transazioni sul sito Web di Redis.
Redis supporta inoltre l'invio in batch non transazionale di richieste. Il protocollo di Redis usato dai client per inviare comandi a un server di Redis consente ai client di inviare una serie di operazioni come parte della richiesta stessa. Ciò può contribuire a ridurre la frammentazione del pacchetto in rete. Quando viene elaborato il batch, viene eseguito ogni comando. Se uno di questi comandi non è valido, questi verranno rifiutati (che non si verificano con una transazione), ma verranno eseguiti i comandi rimanenti. Non esiste anche alcuna garanzia sull'ordine in cui verranno elaborati i comandi nel batch.
Sicurezza di Redis
Redis è progettato esclusivamente per fornire accesso rapido ai dati e per l'esecuzione in un ambiente attendibile a cui possano accedere solo client attendibili. Redis supporta un modello di sicurezza limitato basato sull'autenticazione della password. È possibile rimuovere completamente l'autenticazione, anche se non è consigliabile.
Tutti i client autenticati condividono la stessa password globale e hanno accesso alle stesse risorse. Se è necessaria una sicurezza di accesso più completa, occorre implementare un livello di sicurezza personalizzato a protezione del server Redis e tutte le richieste dei client devono passare tramite questo livello aggiuntivo. Redis non deve essere esposto direttamente a client non attendibili o non autenticati.
È possibile limitare l'accesso ai comandi disabilitandoli o rinominandoli e fornendo i nuovi nomi solo ai client privilegiati.
Redis non supporta direttamente alcuna forma di crittografia dei dati, quindi tutte le codifiche devono essere eseguite dalle applicazioni client. Inoltre, Redis non fornisce alcuna forma di sicurezza del trasporto. Se è necessario proteggere i dati trasmessi attraverso la rete, è consigliabile implementare un proxy SSL.
Per altre informazioni, visitare la pagina relativa alla sicurezza di Redis nel sito Web di Redis.
Nota
Cache di Azure per Redis offre un proprio livello di sicurezza tramite il quale i client possono connettersi. I server Redis sottostanti non sono esposti alla rete pubblica.
Cache Redis di Azure
Cache di Azure per Redis fornisce l'accesso ai server Redis ospitati in un data center di Azure. Il suo ruolo è quello di un'interfaccia che garantisce controllo dell'accesso e sicurezza. È possibile eseguire il provisioning di una cache tramite il portale di Azure.
Il portale fornisce una serie di configurazioni predefinite. Si tratta di una cache da 53 GB in esecuzione come servizio dedicato che supporta le comunicazioni SSL (per la privacy) e la replica master/subordinata con un contratto di servizio (SLA) del 99,9% di disponibilità, fino a una cache di 250 MB senza replica (nessuna garanzia di disponibilità) in esecuzione su hardware condiviso.
Tramite il portale di Azure è possibile anche configurare il criterio di rimozione della cache e controllare l'accesso alla cache mediante l'aggiunta di utenti ai ruoli disponibili. Questi ruoli, che definiscono le operazioni che i membri possono eseguire, sono Proprietario, Collaboratore e Lettore. Ad esempio, i membri del ruolo Proprietario dispongono di controllo completo sulla cache (inclusa la sicurezza) e il relativo contenuto, i membri del ruolo Collaboratore sono in grado di leggere e scrivere informazioni nella cache e i membri del ruolo Lettore possono recuperare solo i dati dalla cache.
La maggior parte delle attività amministrative vengono eseguite tramite il portale di Azure. Per questo motivo, molti dei comandi amministrativi disponibili nella versione standard di Redis non sono disponibili, inclusa la possibilità di modificare la configurazione a livello di codice, arrestare il server Redis, configurare subordinati aggiuntivi o salvare forzatamente i dati su disco.
Il portale di Azure include una pratica visualizzazione grafica che consente di monitorare le prestazioni della cache. Ad esempio, è possibile visualizzare il numero di connessioni in corso, il numero di richieste eseguite, il volume di letture e scritture e il numero di riscontri nella cache rispetto ai mancati riscontri. Queste informazioni consentono di determinare l'efficacia della cache e, se necessario, di passare a una configurazione diversa o di modificare i criteri di rimozione.
Inoltre, è possibile creare avvisi che inviano messaggi di posta elettronica a un amministratore se uno o più metriche scende al di sotto di un intervallo previsto. Ad esempio, può essere necessario avvertire un amministratore se il numero di mancati riscontri nella cache durante l'ultima ora supera il valore specificato, perché la cache potrebbe essere troppo piccola o i dati potrebbero essere rimossi troppo rapidamente.
È inoltre possibile monitorare la CPU, la memoria e l'uso della rete per la cache.
Per altre informazioni ed esempi che illustrano come creare e configurare una cache di Azure per Redis, visitare la pagina relativa all'introduzione alla Cache di Azure per Redis sul blog di Azure.
Memorizzazione nella cache dello stato della sessione e dell'output HTML
Se si compilano ASP.NET applicazioni Web eseguite usando i ruoli Web di Azure, è possibile salvare le informazioni sullo stato della sessione e l'output HTML in un cache di Azure per Redis. Il provider di stato della sessione per cache di Azure per Redis consente di condividere informazioni sulla sessione tra istanze diverse di un'applicazione Web ASP.NET ed è molto utile nelle situazioni della Web farm in cui l'affinità client-server non è disponibile e la memorizzazione nella cache dei dati della sessione in memoria non sarebbe appropriata.
L'uso del provider di stato della sessione con cache di Azure per Redis offre diversi vantaggi, tra cui:
- Condivisione dello stato della sessione con un numero elevato di istanze di applicazioni Web ASP.NET.
- Maggiore scalabilità.
- Supporto dell'accesso controllato e simultaneo agli stessi dati di stato della sessione per più lettori e un unico scrittore.
- Uso della compressione per risparmiare memoria e migliorare le prestazioni della rete.
Per altre informazioni vedere Provider di stato della sessione ASP.NET per la cache di Azure per Redis.
Nota
Non usare il provider di stato della sessione per cache di Azure per Redis con ASP.NET applicazioni eseguite all'esterno dell'ambiente Azure. La latenza di accesso alla cache dall'esterno di Azure consente di eliminare le prestazioni di memorizzazione nella cache di dati.
Analogamente, il provider della cache di output per la cache di Azure per Redis consente di salvare le risposte HTTP generate da un'applicazione Web ASP.NET. L'uso del provider della cache di output con la cache di Azure per Redis può migliorare i tempi di risposta delle applicazioni che eseguono il rendering di output HTML complesso. Le istanze dell'applicazione che generano risposte simili possono usare frammenti di output condivisi nella cache anziché generare il modello di output HTML da zero. Per altre informazioni, vedere Provider della cache di output ASP.NET per la cache di Azure per Redis.
Creazione di una Cache Redis personalizzata
Cache di Azure per Redis funge da interfaccia per i server Redis sottostanti. Se è necessaria una configurazione avanzata non coperta dalla cache Redis di Azure (ad esempio una cache di dimensioni superiori a 53 GB), è possibile compilare e ospitare i propri server Redis usando Azure Macchine virtuali.
Si tratta di un processo potenzialmente complesso, poiché, se si desidera implementare la replica, potrebbe essere necessario creare più macchine virtuali con la funzione di nodi primari e subordinati. Inoltre, se si desidera creare un cluster, sono necessari più server primari e subordinati. Una topologia di replica in cluster minima che fornisce un elevato livello di disponibilità e scalabilità è costituita da almeno sei macchine virtuali organizzate come tre coppie di server primario/subordinato (un cluster deve contenere almeno tre nodi primari).
Ogni coppia primario/subordinato deve risiedere in una posizione vicina per ridurre al minimo la latenza. Tuttavia, ogni set di coppie può essere in esecuzione in data center di Azure diversi ubicati in aree diverse, se si desidera posizionare dati memorizzati nella cache vicino alle applicazioni che hanno maggiori probabilità di usarli. Per un esempio di creazione e configurazione di un nodo di Redis in esecuzione come una macchina virtuale di Azure, vedere Esecuzione Redis in una macchina virtuale Linux CentOS in Azure.
Nota
Se si implementa la cache Redis in questo modo, si è responsabili del monitoraggio, della gestione e della protezione del servizio.
Partizionamento di una cache Redis
Il partizionamento della cache comporta la suddivisione della cache tra più computer. Questa struttura offre diversi vantaggi rispetto all'uso di un singolo server di cache, tra cui:
- La creazione di una cache più grande di quanto non possa essere archiviata in un singolo server.
- Distribuzione dei dati tra server, migliorando la disponibilità. Se un server genera errori o non è accessibile, i dati che contiene non sono accessibili ma i dati negli altri server lo sono ancora. Per una cache, questo non è fondamentale perché i dati memorizzati nella cache sono solo una copia temporanea dei dati contenuti in un database. I dati memorizzati nella cache in un server non più accessibile possono essere memorizzati nella cache in un altro server.
- Estensione del carico tra server, con conseguente miglioramento delle prestazioni e della scalabilità.
- Attivazione della geolocalizzazione dei dati vicini agli utenti che vi accedono, riducendo la latenza.
Per una cache, la forma più comune di partizionamento è il partizionamento orizzontale. In questa strategia ogni partizione è una cache Redis in sé. I dati vengono indirizzati a una partizione specifica tramite la logica di partizionamento orizzontale, che consente di usare un'ampia gamma di approcci per distribuire i dati. Il modello di partizionamento orizzontale fornisce ulteriori informazioni sull'implementazione del partizionamento orizzontale.
Per implementare il partizionamento in una cache Redis, è possibile adottare uno degli approcci seguenti:
- Routing di query lato server. Con questa tecnica, un'applicazione client invia una richiesta a un qualsiasi server Redis che costituisca la cache (probabilmente il server più vicino). Ogni server Redis archivia i metadati che descrivono la partizione contenuta e contiene inoltre informazioni sulle partizioni che si trovano su altri server. Il server Redis esamina la richiesta del client. Se può risolverla in locale eseguirà l'operazione richiesta. In caso contrario inoltrerà la richiesta al server appropriato. Questo modello viene implementato dal clustering Redis e viene descritto più dettagliatamente nell'esercitazione relativa al cluster Redis sulla relativa pagina Web. Il clustering Redis è trasparente per le applicazioni client e i server Redis aggiuntivi possono essere aggiunti al cluster (e i dati ripartizionati) senza dover riconfigurare i client.
- Partizionamento lato client. In questo modello, l'applicazione client contiene la logica (possibilmente in forma di una libreria) le richieste vengono indirizzate al server Redis appropriato. Questo approccio può essere usato con la cache di Azure per Redis. È possibile creare più cache di Azure per Redis (una per ogni partizione di dati) e implementare la logica lato client che effettua il routing delle richieste verso la cache corretta. Se lo schema di partizionamento viene modificato, ad esempio se vengono create altre cache di Azure per Redis, potrebbe essere necessario riconfigurare le applicazioni client.
- Partizionamento assistito dal proxy. In questo schema, il client invia le applicazioni richieste al servizio proxy intermediario che comprende il modo in cui i dati sono partizionati e instrada la richiesta appropriata Redis server. Questo approccio può essere usato anche con la cache di Azure per Redis. Il servizio proxy è implementato come servizio cloud di Azure. Questo approccio richiede un ulteriore livello di complessità per implementare il servizio e le richieste potrebbero richiedere più tempo rispetto all'uso del partizionamento sul lato client.
La pagina Partizionamento: come suddividere i dati tra più istanze di Redis sul sito Web Redis fornisce ulteriori informazioni sull'implementazione del partizionamento con Redis.
Implementare applicazioni client della cache Redis
Redis supporta le applicazioni client scritte in numerosi linguaggi di programmazione. Se si compilano nuove applicazioni usando .NET Framework, è consigliabile usare la libreria client StackExchange.Redis. Questa libreria fornisce un modello a oggetti .NET Framework che astrae i dettagli per la connessione a un server di Redis, l'invio di comandi e la ricezione delle risposte. È disponibile in Visual Studio come pacchetto NuGet. Per connettersi alla cache di Azure per Redis o a una cache Redis personalizzata ospitata in una macchina virtuale è possibile usare la stessa libreria.
Per connettersi a un server Redis è possibile usare il metodo statico Connect della classe ConnectionMultiplexer. La connessione creata da questo metodo è progettata per essere usata per tutta la durata dell'applicazione client e la stessa connessione può essere usata da più thread simultanei. Non riconnettersi e disconnettersi ogni volta che si esegue un'operazione Redis perché ciò può compromettere le prestazioni.
È possibile specificare i parametri di connessione, ad esempio l'indirizzo dell'host Redis e la password. Se si usa cache di Azure per Redis, la password è la chiave primaria o secondaria generata per cache di Azure per Redis usando il portale di Azure.
Dopo aver eseguito la connessione al server Redis, è possibile ottenere un handle nel database Redis che funge da cache. La connessione Redis fornisce il metodo GetDatabase a tale scopo. È quindi possibile recuperare elementi dalla cache e archiviare i dati nella cache usando i metodi StringGet e StringSet. Questi metodi presuppongono una chiave come parametro e restituiscono l'elemento nella cache con un valore corrispondente (StringGet) o aggiungono l'elemento alla cache con questa chiave (StringSet).
A seconda della posizione del server Redis, molte operazioni potrebbero essere soggette a latenza mentre una richiesta viene trasmessa al server e la risposta viene restituita al client. La libreria StackExchange offre versioni asincrone di molti dei metodi esposti per consentire ai client di rimanere attivi. Questi metodi supportano il modello asincrono basato su attività in .NET Framework.
Il frammento di codice seguente mostra il metodo RetrieveItem. Il codice illustra un esempio di implementazione del modello cache-aside basato su Redis e sulla libreria StackExchange. Il metodo accetta un valore chiave stringa e tenta di recuperare l'elemento corrispondente dalla cache Redis chiamando il metodo StringGetAsync (la versione asincrona di StringGet).
Se l'elemento non viene trovato, viene recuperato dall'origine dati sottostante usando il GetItemFromDataSourceAsync metodo ( che è un metodo locale e non fa parte della libreria StackExchange). Viene quindi aggiunto alla cache tramite il metodo StringSetAsync , pertanto può essere recuperato più rapidamente in seguito.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
I StringGet metodi e StringSet non sono limitati al recupero o all'archiviazione di valori stringa. ma possono recuperare qualsiasi elemento serializzato come matrice di byte. Se è necessario salvare un oggetto .NET, è possibile serializzarlo come flusso di byte e usare il metodo StringSet per scriverlo nella cache.
Analogamente, è possibile leggere un oggetto dalla cache tramite il metodo StringGet e deserializzarlo come oggetto .NET. Il codice seguente illustra un set di metodi di estensione per l'interfaccia IDatabase (il metodo GetDatabase di una connessione Redis restituisce un oggetto IDatabase). È mostrato anche il codice di esempio che usa questi metodi per leggere e scrivere un oggetto BlogPost nella cache:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Nell'esempio di codice riportato di seguito viene illustrato un metodo denominato RetrieveBlogPost che usa questi metodi di estensione per leggere e scrivere un oggetto BlogPost serializzabile nella cache del modello cache-aside:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis supporta il pipelining di comandi se un'applicazione client invia più richieste asincrone. Redis consente di eseguire il metodo multiplex delle richieste usando la stessa connessione piuttosto che ricevere e rispondere ai comandi in una sequenza rigorosa.
Questo approccio consente di ridurre la latenza effettuando un uso più efficiente della rete. Nel frammento di codice riportato di seguito viene illustrato un esempio in cui vengono recuperati i dettagli di due clienti contemporaneamente. Il codice invia due richieste e quindi esegue altre attività di elaborazione (non mostrate) prima di attendere di ricevere i risultati. Il metodo Wait dell'oggetto nella cache è simile al metodo Task.Wait in .NET Framework:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Per altre informazioni sulla scrittura di applicazioni client che possono usare il cache di Azure per Redis, vedere la documentazione cache di Azure per Redis. Altre informazioni sono disponibili anche su StackExchange.Redis.
La pagina relativa a pipeline e multiplexer nello stesso sito Web offre altre informazioni sulle operazioni asincrone e sul pipelining con Redis e la libreria StackExchange.
Uso della memorizzazione nella cache di Redis
L'uso più semplice di Redis per risolvere i problemi di memorizzazione nella cache consiste in coppie chiave/valore in cui il valore è una stringa non interpretata di lunghezza arbitraria che può contenere qualsiasi dato binario. Si tratta essenzialmente di una matrice di byte che può essere considerata come stringa. Questo scenario è stato illustrato nella sezione Implementare applicazioni client della cache Redis più indietro in questo articolo.
Si noti che le chiavi contengono anche dati non interpretati, pertanto è possibile utilizzare qualsiasi informazione binaria come chiave. Più lunga la chiave, tuttavia, maggiore sarà lo spazio necessario per archiviarla e maggiore sarà il tempo impiegato per eseguire operazioni di ricerca. Per l'usabilità e la facilità di manutenzione, progettare con attenzione lo spazio delle chiavi e usare chiavi significative, ma non dettagliate.
Ad esempio, è possibile usare chiavi strutturate quali "customer:100" per rappresentare la chiave per il cliente con ID 100 anziché semplicemente "100". Questo schema consente di distinguere facilmente tra i valori che consentono di archiviare diversi tipi di dati. Ad esempio, è possibile usare anche la chiave "orders: 100" per rappresentare la chiave per l'ordine con ID 100.
Oltre alle stringhe binarie unidimensionali, un valore nella coppia chiave/valore Redis può contenere anche informazioni più strutturate: elenchi, set (ordinati e non ordinati) e hash. Redis fornisce un set di comandi completo che consente di modificare questi tipi. Molti di questi comandi sono disponibili per le applicazioni .NET Framework tramite una libreria client, ad esempio StackExchange. La pagina An introduction to Redis data types and abstractions sul sito Web di Redis fornisce una panoramica più dettagliata su questi tipi e sui comandi che è possibile usare per gestirli.
In questa sezione vengono riepilogati alcuni casi comuni di uso per questi tipi di dati e questi comandi.
Eseguire operazioni atomiche e batch
Redis supporta una serie di operazioni di lettura e scrittura atomiche su valori di stringa. Queste operazioni eliminano i rischi possibili di race condition che potrebbero verificarsi quando si usano i comandi GET e SET separati. Le operazioni disponibili sono:
INCR,INCRBY,DECReDECRBY, che eseguono operazioni di incremento e decremento atomiche su valori di dati numerici interi. La libreria StackExchange fornisce versioni di overload dei metodiIDatabase.StringIncrementAsynceIDatabase.StringDecrementAsyncper eseguire queste operazioni e restituire il valore risultante memorizzato nella cache. Il frammento di codice riportato di seguito illustra come usare i metodi seguenti:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET, che recupera il valore associato a una chiave e lo modifica in un nuovo valore. La libreria StackExchange rende disponibile questa operazione tramite il metodoIDatabase.StringGetSetAsync. Nel frammento di codice seguente viene illustrato un esempio di questo metodo. Questo codice restituisce il valore corrente associato alla chiave "data:counter" dell'esempio precedente. Quindi reimposta il valore di questa chiave su zero, il tutto all'interno della stessa operazione:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);I metodi
MGETeMSET, che possono restituire o modificare un set di valori stringa come un'unica operazione. I metodiIDatabase.StringGetAsynceIDatabase.StringSetAsyncdi sovraccarico per supportare questa funzionalità, come illustrato nell'esempio seguente:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
È anche possibile combinare più operazioni in una singola transazione Redis, come descritto nella sezione Transazioni e batch Redis in questo articolo. La libreria StackExchange fornisce supporto per le transazioni attraverso l'interfaccia ITransaction.
Per creare un oggetto ITransaction, usare il metodo IDatabase.CreateTransaction. Per richiamare i comandi per la transazione, usare i metodi forniti dall'oggetto ITransaction .
L'interfaccia ITransaction fornisce l'accesso a un set di metodi simile a quelli a cui si accede tramite l'interfaccia IDatabase, ad eccezione del fatto che tutti i metodi sono asincroni. Ciò significa che vengono eseguite solo quando viene richiamato il ITransaction.Execute metodo . Il valore restituito dal metodo ITransaction.Execute indica se la transazione è stata creata (true) o meno (false).
Nel frammento di codice riportato di seguito viene illustrato un esempio che incrementa e decrementa due contatori come parte della stessa transazione:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Tenere presente che le transazioni di Redis sono a differenza delle transazioni nei database relazionali. Il metodo Execute semplicemente accoda tutti i comandi che costituiscono la transazione da eseguire e se uno qualsiasi di questi non è valido la transazione viene interrotta. Se tutti i comandi sono stati inseriti in coda correttamente, ogni comando viene eseguito in modo asincrono.
Se un comando non riesce, l'elaborazione degli altri continua comunque. Se è necessario verificare che un comando sia stato completato correttamente, è necessario recuperare i risultati del comando stesso usando la proprietà Result dell'attività corrispondente, come illustrato nell'esempio precedente. La lettura della proprietà Result bloccherà il thread chiamante fino al completamento dell'attività.
Per altre informazioni, vedere Transazioni in Redis.
Quando si eseguono operazioni batch, è possibile usare l'interfaccia IBatch della libreria StackExchange. Questa interfaccia fornisce l'accesso a un set di metodi simile a quelli a cui si accede tramite l'interfaccia IDatabase , ad eccezione del fatto che tutti i metodi sono asincroni.
È possibile creare un oggetto IBatch tramite il metodo IDatabase.CreateBatch e quindi eseguire il batch tramite il metodo IBatch.Execute, come illustrato nell'esempio seguente. Questo codice semplicemente imposta un valore stringa, incrementa e decrementa gli stessi contatori usati nell'esempio precedente e visualizza i risultati:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
È importante comprendere che a differenza di una transazione, se un comando in un batch ha esito negativo perché è in formato non valido, gli altri comandi potrebbero comunque essere eseguiti. Il IBatch.Execute metodo non restituisce alcuna indicazione di esito positivo o negativo.
Eseguire operazioni della cache "Fire and Forget"
Redis supporta operazioni "Fire and Forget" tramite i flag di comando. In questo caso, il client avvia semplicemente un'operazione, ma non ha alcun interesse per il risultato e non attende il completamento del comando. Nell'esempio seguente viene illustrato come eseguire il comando INCR come operazione "Fire and Forget":
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Specificare chiavi a scadenza automatica
Quando si archivia un elemento in una cache Redis, è possibile specificare un timeout dopo il quale l'oggetto verrà automaticamente rimosso dalla cache. Per sapere quanto manca alla scadenza di una chiave è anche possibile eseguire una query usando il comando TTL . Questo comando è disponibile per le applicazioni StackExchange tramite il metodo IDatabase.KeyTimeToLive .
Il frammento di codice riportato di seguito mostra come impostare una durata pari a 20 secondi per una chiave e come eseguire una query per sapere la durata rimanente della chiave:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
È anche possibile impostare come scadenza un'ora e una data specifiche usando il comando EXPIRE, disponibile nella libreria StackExchange come metodo KeyExpireAsync :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Suggerimento
È possibile rimuovere un elemento dalla cache manualmente usando il comando DEL, disponibile tramite la libreria StackExchange come metodo IDatabase.KeyDeleteAsync.
Usare tag per intercorrelare elementi memorizzati nella cache
Un set di Redis è un insieme di più elementi che condividono una singola chiave. È possibile creare un insieme usando il comando SADD. È possibile recuperare gli elementi di un set usando il comando SMEMBERS. La libreria StackExchange implementa il comando SADD con il metodo IDatabase.SetAddAsync e il comando SMEMBERS con il metodo IDatabase.SetMembersAsync.
È inoltre possibile combinare set esistenti per creare nuovi set usando i comandi SDIFF (imposta differenzsa), SINTER (imposta intersezione) e SUNION (imposta unione). La libreria StackExchange unifica queste operazioni nel metodo IDatabase.SetCombineAsync . Il primo parametro da passare a questo metodo specifica l'operazione SetOperation da eseguire.
Nei frammenti di codice riportati di seguito viene illustrato come i set possono rivelarsi utili per l'archiviazione e il recupero di raccolte di elementi correlati rapidamente. Questo codice usa il tipo BlogPost descritto nella sezione Implementare applicazioni client della cache Redis più indietro in questo articolo.
Un oggetto BlogPost contiene quattro campi: un ID, un titolo, un punteggio di classificazione e una raccolta di tag. Il primo dei frammenti di codice che seguono mostra i dati di esempio usati per popolare un elenco C# di oggetti BlogPost :
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
È possibile archiviare i tag per ogni oggetto BlogPost come set in una cache Redis e associare ogni set all'ID dell'oggetto BlogPost. In questo modo un'applicazione può trovare rapidamente tutti i tag appartenenti a un post di blog specifico. Per attivare la ricerca nella direzione opposta e trovare tutti i post di blog che condividono un tag specifico, è possibile creare un altro set che contiene il post di blog del riferimento all'ID di tag nella chiave:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Queste strutture consentono di eseguire numerose query comuni in modo efficiente. Ad esempio, è possibile trovare e visualizzare tutti i tag per i post di blog 1 simile al seguente:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
È possibile trovare tutti i tag comuni al post di blog 1 e 2 eseguendo un'operazione di intersezione di set, come indicato di seguito:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
Ed è possibile trovare tutti i post di blog che contengono un tag specifico:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Trovare elementi utilizzati più di recente
Un'attività comunemente richiesta a molte applicazioni è di trovare gli elementi utilizzati più di recente. Per un sito blog, ad esempio, è possibile visualizzare informazioni sui post di blog letti più di recente.
È possibile implementare questa funzionalità usando un elenco di Redis. Un elenco di Redis contiene più elementi che condividono la stessa chiave. L'elenco funge da coda doppia. È possibile inserire gli elementi in una delle parti dell'elenco usando i comandi LPUSH (push a sinistra) e RPUSH (push a destra). È possibile recuperare gli elementi da delle estremità dell'elenco usando i comandi LPOP e RPOP. È inoltre possibile restituire un set di elementi usando i comandi LRANGE e RRANGE.
Nei frammenti di codice riportati di seguito viene illustrato come è possibile eseguire queste operazioni tramite la libreria StackExchange. Questo codice usa il tipo BlogPost degli esempi precedenti. Mentre un post di blog viene letto da un utente, il metodo IDatabase.ListLeftPushAsync inserisce il titolo del post di blog in un elenco associato alla chiave "blog:recent_posts" nella cache Redis.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Durante la lettura di ulteriori post di blog, i titoli vengono inseriti nello stesso elenco. L'elenco è ordinato in base alla sequenza in cui sono stati aggiunti i titoli. I post di blog letti più di recente si trovano verso l'estremità sinistra dell'elenco. Se lo stesso post di blog viene letto più di una volta, avrà più voci nell'elenco.
È possibile visualizzare i titoli dei post letti più di recente usando il metodo IDatabase.ListRange . Questo metodo accetta la chiave che contiene l'elenco, un punto di partenza e un punto finale. Il codice seguente recupera i titoli dei post di blog 10 (voci da 0 a 9) alla fine dell'elenco più a sinistra:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Si noti che il ListRangeAsync metodo non rimuove elementi dall'elenco. A tale scopo, è possibile usare i metodi IDatabase.ListLeftPopAsync e IDatabase.ListRightPopAsync.
Per impedire che l'elenco cresca indefinitamente, è possibile selezionare periodicamente elementi Trim nell'elenco. Il frammento di codice riportato di seguito mostra come rimuovere tutti gli elementi dall'elenco, tranne i cinque più a sinistra:
await cache.ListTrimAsync(redisKey, 0, 5);
Implementare una classifica
Per impostazione predefinita, gli elementi di un set non vengono mantenuti in un ordine specifico. È possibile creare un set ordinato usando il comando ZADD (il metodo IDatabase.SortedSetAdd nella libreria StackExchange). Gli elementi vengono ordinati tramite un valore numerico, detto punteggio, fornito come parametro al comando.
Nel frammento di codice seguente viene aggiunto il titolo del post del blog per un elenco ordinato. In questo esempio ogni post di blog dispone anche di un campo relativo al punteggio che contiene la classificazione del post di blog stesso.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
È possibile recuperare i titoli e i punteggi dei post di blog in ordine crescente di punteggio usando il metodo IDatabase.SortedSetRangeByRankWithScores:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Nota
La libreria StackExchange fornisce anche il IDatabase.SortedSetRangeByRankAsync metodo , che restituisce i dati in ordine di punteggio, ma non restituisce i punteggi.
È inoltre possibile recuperare gli elementi in ordine decrescente di punteggio e limitare il numero di elementi restituiti fornendo parametri aggiuntivi al metodo IDatabase.SortedSetRangeByRankWithScoresAsync. L'esempio seguente consente di visualizzare i titoli e i punteggi dei primi 10 post di blog pertinenti:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
Nell'esempio successivo viene usato il metodo IDatabase.SortedSetRangeByScoreWithScoresAsync , che è possibile usare per limitare gli elementi restituiti a quelli che rientrano in un determinato intervallo di punteggi:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Usare i canali di messaggistica
Oltre che funge da cache di dati, un server Redis fornisce funzionalità di messaggistica attraverso un meccanismo di pubblicazione/sottoscrizione ad alte prestazioni. Le applicazioni client possono sottoscrivere un canale, mentre altre applicazioni o servizi possono pubblicare messaggi nel canale. Applicazioni in sottoscrizione riceveranno i messaggi e ne consentiranno l'elaborazione.
Redis è dotato del comando SUBSCRIBE che le applicazioni client devono usare per la sottoscrizione ai canali. Questo comando è previsto il nome di uno o più canali su cui l'applicazione accetta i messaggi. La libreria StackExchange include l'interfaccia ISubscription che consente a un'applicazione .NET Framework di effettuare la sottoscrizione e pubblicare all'interno di canali.
È possibile creare un oggetto ISubscription tramite il metodo GetSubscriber della connessione al server Redis. Quindi, per rimanere in ascolto dei messaggi su un canale si usa il metodo SubscribeAsync di questo oggetto. Nell'esempio di codice seguente viene illustrato come sottoscrivere un canale denominato "messages:blogPosts":
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Il primo parametro del metodo Subscribe è il nome del canale. Questo nome segue le stesse convenzioni usate dalle chiavi nella cache. Il nome può contenere dati binari, ma è consigliabile usare stringhe relativamente brevi e significative per garantire prestazioni ottimali e gestibilità.
Si noti anche che lo spazio dei nomi usato dai canali è separato da quello usato dalle chiavi. Ciò significa che canali e chiavi possono avere lo stesso nome. Questo però può rendere il codice dell'applicazione più difficile da gestire.
Il secondo parametro è un delegato Action. Questo delegato viene eseguito in modo asincrono quando viene visualizzato un nuovo messaggio sul canale. Con questo esempio viene semplicemente visualizzato il messaggio sulla console (il messaggio conterrà il titolo di un post di blog).
Per pubblicare su un canale, un'applicazione può usare il comando PUBLISH di Redis. La libreria StackExchange fornisce il metodo IServer.PublishAsync per eseguire questa operazione. Nel frammento di codice seguente viene illustrato come pubblicare un messaggio per il canale "messages:blogPosts":
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Esistono diversi punti, che è necessario comprendere sul meccanismo di pubblicazione/sottoscrizione:
- Più sottoscrittori possono sottoscrivere lo stesso canale e riceveranno tutti i messaggi pubblicati in tale canale.
- I sottoscrittori ricevono solo messaggi pubblicati dopo la sottoscrizione. I canali non vengono memorizzati nel buffer e, dopo la pubblicazione di un messaggio, l'infrastruttura Redis esegue il push del messaggio a ogni sottoscrittore e quindi lo rimuove.
- Per impostazione predefinita, i messaggi vengono ricevuti dai sottoscrittori nell'ordine in cui vengono inviati. In un sistema molto attivo con un numero elevato di messaggi e molte sottoscrittori e server di pubblicazione, recapito messaggi garantito sequenza può rallentare le prestazioni del sistema. Se ogni messaggio è indipendente e l'ordine è irrilevante, è possibile abilitare per il sistema Redis l'elaborazione simultanea, che può contribuire a migliorare la velocità di risposta. Per ottenere questo risultato in un client StackExchange, impostare la proprietà PreserveAsyncOrder della connessione usata dal sottoscrittore su false:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Considerazioni sulla serializzazione
Quando si sceglie un formato di serializzazione, prendere in considerazione i compromessi tra prestazioni, interoperabilità, controllo delle versioni, compatibilità con i sistemi esistenti, compressione dei dati e memoria in generale. Quando si valutano le prestazioni, tenere presente che i benchmark dipendono in modo elevato dal contesto. Potrebbero non riflettere il carico di lavoro effettivo e non considerare le librerie o le versioni più recenti. Non esiste un singolo serializzatore "più veloce" per tutti gli scenari.
Alcune opzioni da considerare includono:
Buffer del protocollo, definiti anche protobuf, sono un formato di serializzazione sviluppato da Google per la serializzazione dei dati strutturati in modo efficiente. Usa file di definizione fortemente tipizzati per definire le strutture dei messaggi. Questi file di definizione vengono quindi compilati in un codice con linguaggio specifico per la serializzazione e deserializzazione dei messaggi. Protobuf può essere usato tramite meccanismi RPC esistenti o può generare un servizio RPC.
Thrift di Apache usa un approccio simile, con file con definizione fortemente tipizzata e un passaggio di compilazione per generare il codice di serializzazione e i servizi RPC.
Apache Avro offre funzionalità simili a Buffer protocollo e Thrift, ma non esiste alcun passaggio di compilazione. I dati serializzati invece includono sempre uno schema che descrive la struttura.
JSON è uno standard aperto che usa i campi di testo leggibili. È dotato di un ampio supporto multipiattaforma. JSON non usa schemi di messaggio. Essendo un formato basato su testo, non è molto efficiente in rete. In alcuni casi, tuttavia, è possibile restituire gli elementi memorizzati nella cache direttamente in un client tramite HTTP. In questo caso l'archiviazione JSON può risparmiare il costo della deserializzazione da un altro formato e quindi eseguire la serializzazione in JSON.
binary JSON (BSON) è un formato di serializzazione binaria che usa una struttura simile a JSON. BSON è stato progettato per essere semplice, facile da analizzare e per una serializazione e deserializzazione rapida, per quanto riguarda il JSON. I payload hanno dimensioni simili al JSON. A seconda dei dati, un payload BSON può essere più piccolo o più grande di un payload JSON. BSON include alcuni tipi di dati aggiuntivi che non sono disponibili in JSON, in particolare BinData (per matrici di byte) e Date.
MessagePack è un formato di serializzazione binaria progettato per essere compatto nella trasmissione in rete. Non sono presenti schemi di messaggio o controlli dei tipi di messaggio.
Bond è un framework multipiattaforma per l'uso di dati schematizzati. Supporta la serializzazione e la deserializzazione tra i linguaggi. Differenze rilevanti rispetto agli altri sistemi elencati di seguito riguardano il supporto per l'ereditarietà, gli alias del tipo e generics.
gRPC è un sistema RPC open source sviluppato da Google. Per impostazione predefinita, usa i buffer del protocollo come linguaggio di definizione e un formato di interscambio messaggi sottostante.
Passaggi successivi
- Documentazione di Cache di Azure per Redis
- Domande frequenti su cache di Azure per Redis
- Modello asincrono basato su attività
- Documentazione di Redis
- StackExchange.Redis
- Linee guida di partizionamento di dati
Risorse correlate
Anche i modelli seguenti potrebbero essere importanti per lo scenario quando si implementa la memorizzazione nella cache nelle applicazioni:
Modello cache-aside: questo modello descrive come caricare i dati su richiesta in una cache da un archivio dati. Questo modello consente anche di mantenere la coerenza tra i dati memorizzati nella cache e i dati nell'archivio dati originale.
Il modello di partizionamento orizzontale fornisce informazioni sull'implementazione del partizionamento orizzontale per migliorare la scalabilità in caso di archiviazione e accesso a grandi volumi di dati.