Linee guida per il monitoraggio e la diagnostica
Le applicazioni distribuite e i servizi in esecuzione nel cloud sono, per loro natura, componenti complessi di software che comprendono molte parti in movimento. In un ambiente di produzione, è importante essere in grado di tenere traccia del modo in cui gli utenti usano il sistema, tracciano l'utilizzo delle risorse e in genere monitorano l'integrità e le prestazioni del sistema. Queste informazioni possono essere usate come strumento diagnostico per rilevare e correggere i problemi, nonché per individuare potenziali problemi e impedire che si verifichino.
Scenari di monitoraggio e diagnostica
È possibile usare il monitoraggio per ottenere informazioni dettagliate sul funzionamento di un sistema. Il monitoraggio è una parte fondamentale della gestione degli obiettivi di qualità del servizio. Gli scenari comuni per la raccolta dei dati di monitoraggio includono:
- Garantire che il sistema rimanga integro.
- Rilevamento della disponibilità del sistema e dei relativi elementi componenti.
- Mantenere le prestazioni per garantire che la velocità effettiva del sistema non si degradi in modo imprevisto man mano che aumenta il volume di lavoro.
- Garanzia che il sistema soddisfi tutti i contratti di servizio stabiliti con i clienti.
- Protezione della privacy e della sicurezza del sistema, degli utenti e dei relativi dati.
- Tenere traccia delle operazioni eseguite per scopi di controllo o normativi.
- Monitoraggio dell'utilizzo quotidiano del sistema e dell'analisi delle tendenze che potrebbero causare problemi se non vengono risolti.
- Rilevamento dei problemi che si verificano, dal report iniziale all'analisi di possibili cause, rettifica, conseguente aggiornamenti software e distribuzione.
- Operazioni di traccia e debug delle versioni software.
Annotazioni
Questo elenco non è destinato a essere completo. Questo documento è incentrato su questi scenari come le situazioni più comuni per l'esecuzione del monitoraggio. Potrebbero esserci altri che sono meno comuni o sono specifici dell'ambiente.
Le sezioni seguenti descrivono questi scenari in modo più dettagliato. Le informazioni per ogni scenario vengono illustrate nel formato seguente:
- Breve panoramica dello scenario.
- Requisiti tipici di questo scenario.
- Dati di strumentazione non elaborati necessari per supportare lo scenario e le possibili origini di queste informazioni.
- Come è possibile analizzare e combinare questi dati non elaborati per generare informazioni di diagnostica significative.
Monitoraggio dello stato
Un sistema è integro se è in esecuzione e in grado di elaborare le richieste. Lo scopo del monitoraggio dell'integrità è generare uno snapshot dell'integrità corrente del sistema in modo da poter verificare che tutti i componenti del sistema funzionino come previsto.
Requisiti per il monitoraggio dell'integrità
Un operatore deve essere avvisato rapidamente (entro pochi secondi) se una parte del sistema viene considerata non integra. L'operatore deve essere in grado di verificare quali parti del sistema funzionano normalmente e quali parti riscontrano problemi. L'integrità del sistema può essere evidenziata tramite un sistema di illuminazione del traffico:
- Rosso per la mancata integrità (il sistema è stato arrestato)
- Giallo per parzialmente integro (il sistema è in esecuzione con funzionalità ridotte)
- Verde per completamente sano
Un sistema di monitoraggio dell'integrità completo consente a un operatore di eseguire il drill-down del sistema per visualizzare lo stato di integrità dei sottosistemi e dei componenti. Ad esempio, se il sistema complessivo è rappresentato come parzialmente integro, l'operatore deve essere in grado di eseguire lo zoom avanti e determinare quale funzionalità non è attualmente disponibile.
Requisiti relativi a origini dati, strumentazione e raccolta dati
I dati non elaborati necessari per supportare il monitoraggio dell'integrità possono essere generati in seguito a:
- Traccia dell'esecuzione delle richieste utente. Queste informazioni possono essere usate per determinare quali richieste hanno avuto esito positivo, quali hanno avuto esito negativo e per quanto tempo ogni richiesta richiede.
- Monitoraggio utenti sintetici. Questo processo simula i passaggi eseguiti da un utente e segue una serie predefinita di passaggi. I risultati di ogni passaggio devono essere acquisiti.
- Registrazione di eccezioni, errori e avvisi. Queste informazioni possono essere acquisite come risultato di istruzioni di traccia incorporate nel codice dell'applicazione, nonché il recupero di informazioni dai registri eventi di tutti i servizi a cui fa riferimento il sistema.
- Monitoraggio dell'integrità di tutti i servizi di terze parti usati dal sistema. Questo monitoraggio potrebbe richiedere il recupero e l'analisi dei dati di integrità forniti da questi servizi. Queste informazioni potrebbero richiedere diversi formati.
- Monitoraggio degli endpoint. Questo meccanismo è descritto in modo più dettagliato nella sezione "Monitoraggio della disponibilità".
- Raccolta di informazioni sulle prestazioni di ambiente, ad esempio l'utilizzo della CPU in background o l'attività di I/O (inclusa la rete).
Analisi dei dati di integrità
L'obiettivo principale del monitoraggio dell'integrità è indicare rapidamente se il sistema è in esecuzione. L'analisi ad accesso frequente dei dati immediati può attivare un avviso se viene rilevato un componente critico come non integro. Ad esempio, non risponde a una serie consecutiva di ping. L'operatore può quindi eseguire l'azione correttiva appropriata.
Un sistema più avanzato può includere un elemento predittivo che esegue un'analisi a freddo sui carichi di lavoro recenti e correnti. Un'analisi a freddo può individuare le tendenze e determinare se è probabile che il sistema rimanga integro o se il sistema necessita di risorse aggiuntive. Questo elemento predittivo deve essere basato su metriche di prestazioni critiche, ad esempio:
- Frequenza delle richieste indirizzate a ogni servizio o sottosistema.
- Tempi di risposta di queste richieste.
- Volume di dati in ingresso e in uscita da ogni servizio.
Se il valore di una metrica supera una soglia definita, il sistema può generare un avviso per abilitare un operatore o la scalabilità automatica (se disponibile) per eseguire le azioni preventive necessarie per mantenere l'integrità del sistema. Queste azioni possono comportare l'aggiunta di risorse, il riavvio di uno o più servizi che hanno esito negativo o l'applicazione della limitazione alle richieste con priorità inferiore.
Monitoraggio della disponibilità
Un sistema veramente integro richiede che i componenti e i sottosistemi che compongono il sistema siano disponibili. Il monitoraggio della disponibilità è strettamente correlato al monitoraggio dell'integrità. Tuttavia, mentre il monitoraggio dell'integrità fornisce una visione immediata dell'integrità corrente del sistema, il monitoraggio della disponibilità è preoccupato per tenere traccia della disponibilità del sistema e dei relativi componenti per generare statistiche sul tempo di attività del sistema.
In molti sistemi alcuni componenti, ad esempio un database, sono configurati con ridondanza predefinita per consentire un failover rapido in caso di grave errore o perdita di connettività. Idealmente, gli utenti non devono essere consapevoli che si è verificato un errore di questo tipo. Tuttavia, dal punto di vista del monitoraggio della disponibilità, è necessario raccogliere il maggior numero possibile di informazioni su tali errori per determinare la causa e intraprendere azioni correttive per impedire che vengano ricorrenti.
I dati necessari per tenere traccia della disponibilità possono dipendere da diversi fattori di livello inferiore. Molti di questi fattori possono essere specifici per l'applicazione, il sistema e l'ambiente. Un sistema di monitoraggio efficace acquisisce i dati di disponibilità che corrispondono a questi fattori di basso livello e li aggrega per dare un quadro generale del sistema. Ad esempio, in un sistema di e-commerce, la funzionalità aziendale che consente a un cliente di effettuare ordini può dipendere dal repository in cui sono archiviati i dettagli dell'ordine e dal sistema di pagamento che gestisce le transazioni monetarie per il pagamento di questi ordini. La disponibilità della parte di posizionamento degli ordini del sistema è quindi una funzione della disponibilità del repository e del sottosistema di pagamento.
Requisiti per il monitoraggio della disponibilità
Un operatore deve anche essere in grado di visualizzare la disponibilità cronologica di ogni sistema e sottosistema e di usare queste informazioni per individuare eventuali tendenze che potrebbero causare l'esito negativo periodico di uno o più sottosistemi. I servizi iniziano a non riuscire in un determinato orario del giorno che corrisponde alle ore di elaborazione di picco?
Una soluzione di monitoraggio deve fornire una visualizzazione immediata e cronologica della disponibilità o dell'indisponibilità di ogni sottosistema. Deve anche essere in grado di avvisare rapidamente un operatore quando uno o più servizi hanno esito negativo o quando gli utenti non possono connettersi ai servizi. Questo non è solo il monitoraggio di ogni servizio, ma anche l'analisi delle azioni eseguite da ogni utente se queste azioni hanno esito negativo quando tentano di comunicare con un servizio. In alcuni casi, un grado di errore di connettività è normale e potrebbe essere dovuto a errori temporanei. Può tuttavia essere utile consentire al sistema di generare un avviso per il numero di errori di connettività a un sottosistema specificato che si verifica durante un periodo specifico.
Requisiti relativi a origini dati, strumentazione e raccolta dati
Come per il monitoraggio dell'integrità, i dati non elaborati necessari per supportare il monitoraggio della disponibilità possono essere generati in seguito al monitoraggio sintetico degli utenti e alla registrazione di eventuali eccezioni, errori e avvisi che potrebbero verificarsi. È anche possibile ottenere i dati di disponibilità dall'esecuzione del monitoraggio degli endpoint. L'applicazione può esporre uno o più endpoint di integrità, ognuno dei quali testa l'accesso a un'area funzionale all'interno del sistema. Il sistema di monitoraggio può effettuare il ping di ogni endpoint seguendo una pianificazione definita e raccogliere i risultati (esito positivo o negativo).
Tutti i timeout, gli errori di connettività di rete e i tentativi di connessione devono essere registrati. Tutti i dati devono essere timestamp.
Analisi dei dati di disponibilità
I dati di strumentazione devono essere aggregati e correlati per supportare i tipi di analisi seguenti:
- Disponibilità immediata del sistema e dei sottosistemi.
- Frequenza degli errori di disponibilità del sistema e dei sottosistemi. Idealmente, un operatore dovrebbe essere in grado di correlare gli errori con attività specifiche: cosa accadeva quando il sistema non è riuscito?
- Visualizzazione cronologica dei tassi di errore del sistema o di qualsiasi sottosistema in qualsiasi periodo specificato e carico nel sistema (numero di richieste utente, ad esempio) quando si è verificato un errore.
- Motivi di indisponibilità del sistema o di qualsiasi sottosistema. Ad esempio, i motivi potrebbero essere l'esecuzione del servizio, la connettività persa, la connessione, il timeout e il timeout e la connessione ma la restituzione di errori.
È possibile calcolare la disponibilità percentuale di un servizio in un periodo di tempo usando la formula seguente:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Questa operazione è utile a scopo di contratto di servizio. Il monitoraggio del contratto di servizio è descritto in modo più dettagliato più avanti in questa guida. La definizione del tempo di inattività dipende dal servizio. Ad esempio, visual Studio Team Services Build Service definisce il tempo di inattività come periodo (totale di minuti accumulati) durante il quale il servizio di compilazione non è disponibile. Un minuto viene considerato non disponibile se tutte le richieste HTTP continue al servizio di compilazione per eseguire operazioni avviate dal cliente durante il minuto generano un codice di errore o non restituiscono una risposta.
Monitoraggio delle prestazioni
Man mano che il sistema viene messo sotto maggiore stress (aumentando il volume degli utenti), le dimensioni dei set di dati a cui questi utenti accedono aumentano e la possibilità di errori di uno o più componenti diventano più probabili. Spesso, l'errore del componente è preceduto da una riduzione delle prestazioni. Se si è in grado di rilevare una riduzione di questo tipo, è possibile adottare misure proattive per risolvere la situazione.
Le prestazioni del sistema dipendono da diversi fattori. Ogni fattore viene in genere misurato tramite indicatori di prestazioni chiave (KPI), ad esempio il numero di transazioni di database al secondo o il volume di richieste di rete gestite correttamente in un intervallo di tempo specificato. Alcuni di questi indicatori KPI potrebbero essere disponibili come misure di prestazioni specifiche, mentre altre potrebbero essere derivate da una combinazione di metriche.
Annotazioni
Per determinare prestazioni scarse o buone è necessario comprendere il livello di prestazioni in cui il sistema deve essere in grado di eseguire. Ciò richiede l'osservazione del sistema durante il funzionamento in un carico tipico e l'acquisizione dei dati per ogni indicatore KPI in un periodo di tempo. Ciò potrebbe comportare l'esecuzione del sistema in un carico simulato in un ambiente di test e la raccolta dei dati appropriati prima di distribuire il sistema in un ambiente di produzione.
È inoltre necessario assicurarsi che il monitoraggio a scopo di prestazioni non diventi un onere per il sistema. È possibile modificare in modo dinamico il livello di dettaglio per i dati raccolti dal processo di monitoraggio delle prestazioni.
Requisiti per il monitoraggio delle prestazioni
Per esaminare le prestazioni del sistema, un operatore in genere deve visualizzare informazioni che includono:
- Velocità di risposta per le richieste utente.
- Numero di richieste utente simultanee.
- Volume del traffico di rete.
- Tassi di completamento delle transazioni aziendali.
- Tempo medio di elaborazione per le richieste.
Può anche essere utile fornire strumenti che consentono a un operatore di individuare le correlazioni, ad esempio:
- Numero di utenti simultanei rispetto ai tempi di latenza delle richieste (tempo necessario per avviare l'elaborazione di una richiesta dopo l'invio dell'utente).
- Numero di utenti simultanei rispetto al tempo medio di risposta (tempo necessario per completare una richiesta dopo l'avvio dell'elaborazione).
- Volume di richieste rispetto al numero di errori di elaborazione.
Oltre a queste informazioni funzionali di alto livello, un operatore deve essere in grado di ottenere una visualizzazione dettagliata delle prestazioni per ogni componente del sistema. Questi dati vengono in genere forniti tramite contatori delle prestazioni di basso livello che tengono traccia delle informazioni, ad esempio:
- Utilizzo della memoria.
- Numero di thread.
- Tempo di elaborazione della CPU.
- Lunghezza della coda delle richieste.
- Velocità e errori di I/O su disco o di rete.
- Numero di byte scritti o letti.
- Indicatori middleware, ad esempio la lunghezza della coda.
Tutte le visualizzazioni devono consentire a un operatore di specificare un periodo di tempo. I dati visualizzati potrebbero essere uno snapshot della situazione corrente o una visualizzazione cronologica delle prestazioni.
Un operatore deve essere in grado di generare un avviso in base a qualsiasi misura di prestazioni per qualsiasi valore specificato durante qualsiasi intervallo di tempo specificato.
Requisiti relativi a origini dati, strumentazione e raccolta dati
È possibile raccogliere dati sulle prestazioni di alto livello (velocità effettiva, numero di utenti simultanei, numero di transazioni aziendali, percentuali di errore e così via) monitorando lo stato di avanzamento delle richieste degli utenti man mano che arrivano e passano attraverso il sistema. Ciò comporta l'incorporamento di istruzioni di traccia nei punti chiave nel codice dell'applicazione, insieme alle informazioni sulla tempistica. Tutti gli errori, le eccezioni e gli avvisi devono essere acquisiti con dati sufficienti per correlarli con le richieste che li hanno generati. Il log di Internet Information Services (IIS) è un'altra origine utile.
Se possibile, è consigliabile acquisire anche i dati sulle prestazioni per tutti i sistemi esterni usati dall'applicazione. Questi sistemi esterni possono fornire contatori delle prestazioni personalizzati o altre funzionalità per richiedere dati sulle prestazioni. Se non è possibile, registrare informazioni quali l'ora di inizio e l'ora di fine di ogni richiesta effettuata a un sistema esterno, insieme allo stato (esito positivo, negativo o avviso) dell'operazione. Ad esempio, è possibile usare un approccio di controllo di arresto alle richieste temporali: avviare un timer all'avvio della richiesta e quindi arrestare il timer al termine della richiesta.
I dati sulle prestazioni di basso livello per i singoli componenti in un sistema potrebbero essere disponibili tramite funzionalità e servizi, ad esempio contatori delle prestazioni di Windows e Diagnostica di Azure.
Analisi dei dati relativi alle prestazioni
Gran parte del lavoro di analisi consiste nell'aggregare i dati sulle prestazioni in base al tipo di richiesta utente o al sottosistema o al servizio a cui viene inviata ogni richiesta. Un esempio di richiesta utente è l'aggiunta di un articolo a un carrello acquisti o l'esecuzione del processo di checkout in un sistema di e-commerce.
Un altro requisito comune consiste nel riepilogare i dati sulle prestazioni nei percentili selezionati. Ad esempio, un operatore potrebbe determinare i tempi di risposta per il 99% delle richieste, il 95% delle richieste e il 70% delle richieste. Potrebbero esserci obiettivi del contratto di servizio o altri obiettivi impostati per ogni percentile. I risultati in corso devono essere segnalati quasi in tempo reale per rilevare problemi immediati. I risultati devono essere aggregati anche nel tempo più lungo a scopo statistico.
Nel caso di problemi di latenza che influiscono sulle prestazioni, un operatore deve essere in grado di identificare rapidamente la causa del collo di bottiglia esaminando la latenza di ogni passaggio eseguito da ogni richiesta. I dati sulle prestazioni devono quindi fornire un mezzo per correlare le misure di prestazioni per ogni passaggio per collegarle a una richiesta specifica.
A seconda dei requisiti di visualizzazione, potrebbe essere utile generare e archiviare un cubo di dati che contiene visualizzazioni dei dati non elaborati. Questo cubo di dati può consentire query e analisi ad hoc complesse delle informazioni sulle prestazioni.
Monitoraggio della sicurezza
Tutti i sistemi commerciali che includono dati sensibili devono implementare una struttura di sicurezza. La complessità del meccanismo di sicurezza è in genere una funzione della riservatezza dei dati. In un sistema che richiede l'autenticazione degli utenti, è necessario registrare:
- Tutti i tentativi di accesso, indipendentemente dal fatto che abbiano esito negativo o esito positivo.
- Tutte le operazioni eseguite da e i dettagli di tutte le risorse a cui si accede, un utente autenticato.
- Quando un utente termina una sessione e si disconnette.
Il monitoraggio potrebbe essere in grado di aiutare a rilevare gli attacchi nel sistema. Ad esempio, un numero elevato di tentativi di accesso non riusciti potrebbe indicare un attacco di forza bruta. Un aumento imprevisto delle richieste potrebbe essere il risultato di un attacco DDoS (Distributed Denial of Service). È necessario essere pronti a monitorare tutte le richieste a tutte le risorse indipendentemente dall'origine di queste richieste. Un sistema che presenta una vulnerabilità di accesso potrebbe esporre accidentalmente risorse all'esterno senza richiedere a un utente di eseguire effettivamente l'accesso.
Requisiti per il monitoraggio della sicurezza
Gli aspetti più critici del monitoraggio della sicurezza devono consentire a un operatore di:
- Rilevare le intrusioni tentate da un'entità non autenticata.
- Identificare i tentativi da parte delle entità di eseguire operazioni sui dati per i quali non è stato concesso l'accesso.
- Determinare se il sistema, o parte del sistema, è sotto attacco dall'esterno o dall'interno. Ad esempio, un utente malintenzionato autenticato potrebbe tentare di arrestare il sistema.
Per supportare questi requisiti, un operatore deve ricevere una notifica se:
- Un account esegue tentativi di accesso ripetuti non riusciti entro un periodo specificato.
- Un account autenticato tenta ripetutamente di accedere a una risorsa non consentita durante un periodo specificato.
- Un numero elevato di richieste non autenticate o non autorizzate si verifica durante un periodo specificato.
Le informazioni fornite a un operatore devono includere l'indirizzo host dell'origine per ogni richiesta. Se le violazioni di sicurezza si verificano regolarmente da un determinato intervallo di indirizzi, questi host potrebbero essere bloccati.
Una parte fondamentale nella gestione della sicurezza di un sistema è in grado di rilevare rapidamente le azioni che deviano dal modello consueto. Le informazioni, ad esempio il numero di richieste di accesso non riuscite o riuscite, possono essere visualizzate visivamente per rilevare se si verifica un picco di attività in un momento insolito. Un esempio di questa attività è rappresentato dagli utenti che eseguono l'accesso alle 3:00 ed eseguono un numero elevato di operazioni quando il giorno lavorativo inizia alle 9:00. Queste informazioni possono essere usate anche per configurare la scalabilità automatica basata sul tempo. Ad esempio, se un operatore osserva che un numero elevato di utenti accede regolarmente a un determinato orario del giorno, l'operatore può organizzare l'avvio di servizi di autenticazione aggiuntivi per gestire il volume di lavoro e quindi arrestare questi servizi aggiuntivi quando il picco è trascorso.
Requisiti relativi a origini dati, strumentazione e raccolta dati
La sicurezza è un aspetto incomprensivo della maggior parte dei sistemi distribuiti. È probabile che i dati pertinenti vengano generati in più punti in un sistema. È consigliabile adottare un approccio SIEM (Security Information and Event Management) per raccogliere le informazioni relative alla sicurezza risultanti da eventi generati dall'applicazione, apparecchiature di rete, server, firewall, software antivirus e altri elementi di prevenzione delle intrusioni.
Il monitoraggio della sicurezza può incorporare dati da strumenti che non fanno parte dell'applicazione. Questi strumenti possono includere utilità che identificano le attività di analisi delle porte da parte di agenzie esterne o filtri di rete che rilevano i tentativi di ottenere l'accesso non autenticato all'applicazione e ai dati.
In tutti i casi, i dati raccolti devono consentire a un amministratore di determinare la natura di qualsiasi attacco e adottare le contromisure appropriate.
Analisi dei dati di sicurezza
Una funzionalità di monitoraggio della sicurezza è la varietà di origini da cui derivano i dati. I diversi formati e il livello di dettaglio spesso richiedono un'analisi complessa dei dati acquisiti per collegarli in un thread coerente di informazioni. Oltre ai casi più semplici ,ad esempio il rilevamento di un numero elevato di accessi non riusciti o tentativi ripetuti di ottenere l'accesso non autorizzato alle risorse critiche, potrebbe non essere possibile eseguire alcuna complessa elaborazione automatizzata dei dati di sicurezza. Potrebbe invece essere preferibile scrivere questi dati, timestamp, ma in caso contrario nel formato originale, in un repository sicuro per consentire l'analisi manuale di esperti.
Monitoraggio del contratto di servizio
Molti sistemi commerciali che supportano i pagamenti dei clienti garantiscono le prestazioni del sistema sotto forma di contratti di servizio. Essenzialmente, i contratti di servizio dichiarano che il sistema può gestire un volume definito di lavoro entro un intervallo di tempo concordato e senza perdere informazioni critiche. Il monitoraggio del contratto di servizio è preoccupato per garantire che il sistema possa soddisfare contratti di servizio misurabili.
Annotazioni
Il monitoraggio del contratto di servizio è strettamente correlato al monitoraggio delle prestazioni. Tuttavia, mentre il monitoraggio delle prestazioni è preoccupato per garantire che il sistema funzioni in modo ottimale, il monitoraggio del contratto di servizio è disciplinato da un obbligo contrattuale che definisce ciò che in realtà significa in modo ottimale .
I contratti di servizio vengono spesso definiti in termini di:
- Disponibilità complessiva del sistema. Ad esempio, un'organizzazione potrebbe garantire che il sistema sarà disponibile per il 99,9% del tempo. Ciò equivale a non più di 9 ore di inattività all'anno o circa 10 minuti alla settimana.
- Velocità effettiva operativa. Questo aspetto viene spesso espresso come uno o più segni di acqua elevati, ad esempio garantendo che il sistema possa supportare fino a 100.000 richieste utente simultanee o gestire 10.000 transazioni aziendali simultanee.
- Tempo di risposta operativo. Il sistema potrebbe anche garantire la frequenza con cui vengono elaborate le richieste. Un esempio è che il 99% di tutte le transazioni aziendali terminerà entro 2 secondi e che nessuna transazione richiederà più di 10 secondi.
Annotazioni
Alcuni contratti per i sistemi commerciali possono includere anche contratti di servizio per il supporto clienti. Un esempio è che tutte le richieste di help desk genereranno una risposta entro cinque minuti e che il 99% di tutti i problemi verrà completamente risolto entro 1 giorno lavorativo. Il rilevamento effettivo dei problemi (descritto più avanti in questa sezione) è fondamentale per soddisfare contratti di servizio come questi.
Requisiti per il monitoraggio del contratto di servizio
Al livello più alto, un operatore deve essere in grado di determinare a colpo d'occhio se il sistema soddisfa o meno i contratti di servizio concordati. In caso contrario, l'operatore deve essere in grado di eseguire il drill-down ed esaminare i fattori sottostanti per determinare i motivi delle prestazioni standard.
Gli indicatori di alto livello tipici che possono essere rappresentati visivamente includono:
- Percentuale di tempo di attività del servizio.
- Velocità effettiva dell'applicazione (misurata in termini di transazioni o operazioni riuscite al secondo).
- Numero di richieste dell'applicazione con esito positivo o negativo.
- Numero di errori di applicazione e di sistema, eccezioni e avvisi.
Tutti questi indicatori devono essere in grado di essere filtrati in base a un periodo di tempo specificato.
Un'applicazione cloud comprenderà probabilmente diversi sottosistemi e componenti. Un operatore deve essere in grado di selezionare un indicatore di alto livello e vedere come è composto dall'integrità degli elementi sottostanti. Ad esempio, se il tempo di attività del sistema complessivo scende al di sotto di un valore accettabile, un operatore deve essere in grado di eseguire lo zoom avanti e determinare quali elementi contribuiscono a questo errore.
Annotazioni
Il tempo di attività del sistema deve essere definito con attenzione. In un sistema che usa la ridondanza per garantire la massima disponibilità, le singole istanze di elementi potrebbero non riuscire, ma il sistema può rimanere funzionante. Il tempo di attività del sistema presentato dal monitoraggio dell'integrità deve indicare il tempo di attività aggregato di ogni elemento e non necessariamente se il sistema si è effettivamente arrestato. Inoltre, gli errori potrebbero essere isolati. Pertanto, anche se un sistema specifico non è disponibile, il resto del sistema potrebbe rimanere disponibile, anche se con funzionalità ridotte. In un sistema di e-commerce, un errore nel sistema potrebbe impedire a un cliente di effettuare ordini, ma il cliente potrebbe comunque essere in grado di esplorare il catalogo dei prodotti.
Ai fini degli avvisi, il sistema deve essere in grado di generare un evento se uno degli indicatori di alto livello supera una soglia specificata. I dettagli di livello inferiore dei vari fattori che compongono l'indicatore generale devono essere disponibili come dati contestuali al sistema di avvisi.
Requisiti relativi a origini dati, strumentazione e raccolta dati
I dati non elaborati necessari per supportare il monitoraggio del contratto di servizio sono simili ai dati non elaborati necessari per il monitoraggio delle prestazioni, insieme ad alcuni aspetti del monitoraggio dell'integrità e della disponibilità. Per altri dettagli, vedere tali sezioni. È possibile acquisire questi dati in base a:
- Esecuzione del monitoraggio degli endpoint.
- Registrazione di eccezioni, errori e avvisi.
- Traccia dell'esecuzione delle richieste utente.
- Monitoraggio della disponibilità di tutti i servizi di terze parti usati dal sistema.
- Uso di metriche e contatori delle prestazioni.
Tutti i dati devono essere timed e timestamp.
Analisi dei dati del contratto di servizio
I dati di strumentazione devono essere aggregati per generare un'immagine delle prestazioni complessive del sistema. I dati aggregati devono inoltre supportare il drill-down per consentire l'esame delle prestazioni dei sottosistemi sottostanti. Ad esempio, dovrebbe essere possibile:
- Calcolare il numero totale di richieste utente durante un periodo specificato e determinare il tasso di esito positivo e negativo di queste richieste.
- Combinare i tempi di risposta delle richieste degli utenti per generare una visualizzazione complessiva dei tempi di risposta del sistema.
- Analizzare lo stato di avanzamento delle richieste dell'utente per suddividere il tempo di risposta complessivo di una richiesta nei tempi di risposta dei singoli elementi di lavoro in tale richiesta.
- Determinare la disponibilità complessiva del sistema come percentuale di tempo di attività per qualsiasi periodo specifico.
- Analizzare la disponibilità percentuale del tempo dei singoli componenti e servizi nel sistema. Ciò potrebbe comportare l'analisi dei log generati da servizi di terze parti.
Molti sistemi commerciali sono tenuti a segnalare dati reali sulle prestazioni rispetto ai contratti di servizio concordati per un periodo specificato, in genere un mese. Queste informazioni possono essere utilizzate per calcolare crediti o altre forme di rimborso per i clienti se i contratti di servizio non vengono soddisfatti durante tale periodo. È possibile calcolare la disponibilità per un servizio usando la tecnica descritta nella sezione Analisi dei dati di disponibilità.
Per scopi interni, un'organizzazione potrebbe anche tenere traccia del numero e della natura degli eventi imprevisti che hanno causato l'esito negativo dei servizi. Imparare a risolvere questi problemi rapidamente, o eliminarli completamente, consentirà di ridurre i tempi di inattività e soddisfare i contratti di servizio.
Revisione contabile
A seconda della natura dell'applicazione, potrebbero esserci normative legali o di altro tipo che specificano i requisiti per il controllo delle operazioni degli utenti e la registrazione di tutti gli accessi ai dati. Il controllo può fornire prove che consentono di collegare i clienti a richieste specifiche. La mancata valutazione è un fattore importante in molti sistemi di e-business per mantenere la fiducia tra un cliente e l'organizzazione responsabile dell'applicazione o del servizio.
Requisiti per il controllo
Un analista deve essere in grado di tracciare la sequenza di operazioni aziendali eseguite dagli utenti in modo da poter ricostruire le azioni degli utenti. Questo potrebbe essere necessario semplicemente come record, o come parte di un'indagine forense.
Le informazioni di controllo sono estremamente sensibili. È probabile che includa i dati che identificano gli utenti del sistema, insieme alle attività eseguite. Per questo motivo, le informazioni di controllo avranno probabilmente la forma di report disponibili solo per analisti attendibili anziché come sistema interattivo che supporta il drill-down delle operazioni grafiche. Un analista deve essere in grado di generare un intervallo di report. Ad esempio, i report possono elencare tutte le attività degli utenti che si verificano durante un intervallo di tempo specificato, in dettaglio la cronologia dell'attività per un singolo utente o elencare la sequenza di operazioni eseguite su una o più risorse.
Requisiti relativi a origini dati, strumentazione e raccolta dati
Le fonti principali di informazioni per il controllo possono includere:
- Sistema di sicurezza che gestisce l'autenticazione utente.
- Log di traccia che registrano l'attività dell'utente.
- Log di sicurezza che tengono traccia di tutte le richieste di rete identificabili e non identificabili.
Il formato dei dati di controllo e il modo in cui vengono archiviati potrebbe essere determinato dai requisiti normativi. Ad esempio, potrebbe non essere possibile pulire i dati in alcun modo. Deve essere registrato nel formato originale. L'accesso al repository in cui è conservato deve essere protetto per evitare manomissioni.
Analisi dei dati di controllo
Un analista deve essere in grado di accedere ai dati non elaborati nella sua interezza, nel suo formato originale. A parte il requisito di generare report di controllo comuni, è probabile che gli strumenti per l'analisi di questi dati siano specializzati e mantenuti esterni al sistema.
Monitoraggio dell'utilizzo
Il monitoraggio dell'utilizzo tiene traccia del modo in cui vengono usate le funzionalità e i componenti di un'applicazione. Un operatore può usare i dati raccolti per:
Determinare quali funzionalità vengono usate pesantemente e determinare eventuali potenziali hotspot nel sistema. Gli elementi a traffico elevato possono trarre vantaggio dal partizionamento funzionale o anche dalla replica per distribuire il carico in modo più uniforme. Un operatore può anche utilizzare queste informazioni per verificare quali funzionalità vengono usate raramente e sono possibili candidati per il ritiro o la sostituzione in una versione futura del sistema.
Ottenere informazioni sugli eventi operativi del sistema in uso normale. Ad esempio, in un sito di e-commerce è possibile registrare le informazioni statistiche sul numero di transazioni e sul volume di clienti responsabili. Queste informazioni possono essere usate per la pianificazione della capacità man mano che aumenta il numero di clienti.
Rilevare (possibilmente indirettamente) la soddisfazione dell'utente con le prestazioni o le funzionalità del sistema. Ad esempio, se un numero elevato di clienti in un sistema di e-commerce abbandona regolarmente i carrello acquisti, questo potrebbe essere dovuto a un problema con la funzionalità di checkout.
Generare informazioni di fatturazione. Un'applicazione commerciale o un servizio multi-tenant potrebbe addebitare ai clienti le risorse usate.
Applicare le quote. Se un utente in un sistema multi-tenant supera la quota a pagamento del tempo di elaborazione o dell'utilizzo delle risorse durante un periodo specificato, l'accesso può essere limitato o l'elaborazione può essere limitata.
Requisiti per il monitoraggio dell'utilizzo
Per esaminare l'utilizzo del sistema, un operatore in genere deve visualizzare le informazioni che includono:
- Numero di richieste elaborate da ogni sottosistema e indirizzate a ogni risorsa.
- Il lavoro eseguito da ogni utente.
- Volume di archiviazione dei dati occupato da ogni utente.
- Risorse a cui accede ogni utente.
Un operatore deve anche essere in grado di generare grafici. Ad esempio, un grafico potrebbe visualizzare gli utenti più affamati di risorse o le risorse o le funzionalità di sistema a cui si accede più di frequente.
Requisiti relativi a origini dati, strumentazione e raccolta dati
Il rilevamento dell'utilizzo può essere eseguito a un livello relativamente elevato. Può notare l'ora di inizio e di fine di ogni richiesta e la natura della richiesta (lettura, scrittura e così via, a seconda della risorsa in questione). Per ottenere queste informazioni, è possibile:
- Traccia dell'attività dell'utente.
- Acquisizione di contatori delle prestazioni che misurano l'utilizzo per ogni risorsa.
- Monitoraggio dell'utilizzo delle risorse da parte di ogni utente.
A scopo di misurazione, è anche necessario essere in grado di identificare quali utenti sono responsabili dell'esecuzione delle operazioni e delle risorse usate da queste operazioni. Le informazioni raccolte devono essere sufficientemente dettagliate per consentire una fatturazione accurata.
Rilevamento dei problemi
I clienti e altri utenti potrebbero segnalare problemi se si verificano eventi o comportamenti imprevisti nel sistema. Il rilevamento dei problemi riguarda la gestione di questi problemi, l'associazione con gli sforzi per risolvere eventuali problemi sottostanti nel sistema e informare i clienti delle possibili soluzioni.
Requisiti per il rilevamento dei problemi
Gli operatori spesso eseguono il rilevamento dei problemi usando un sistema separato che consente loro di registrare e segnalare i dettagli dei problemi che gli utenti segnalano. Questi dettagli possono includere le attività che l'utente stava tentando di eseguire, i sintomi del problema, la sequenza di eventi e tutti i messaggi di errore o di avviso emessi.
Requisiti relativi a origini dati, strumentazione e raccolta dati
L'origine dati iniziale per i dati di rilevamento dei problemi è l'utente che ha segnalato il problema al primo posto. L'utente potrebbe essere in grado di fornire dati aggiuntivi, ad esempio:
- Un dump di arresto anomalo (se l'applicazione include un componente eseguito sul desktop dell'utente).
- Snapshot dello schermo.
- Data e ora in cui si è verificato l'errore, insieme ad altre informazioni ambientali, ad esempio la posizione dell'utente.
Queste informazioni possono essere usate per facilitare il debug e creare un backlog per le versioni future del software.
Analisi dei dati di rilevamento dei problemi
Utenti diversi potrebbero segnalare lo stesso problema. Il sistema di rilevamento dei problemi deve associare report comuni.
Lo stato di avanzamento dello sforzo di debug deve essere registrato in base a ogni report del problema. Quando il problema viene risolto, il cliente può essere informato della soluzione.
Se un utente segnala un problema con una soluzione nota nel sistema di rilevamento dei problemi, l'operatore deve essere in grado di informare immediatamente l'utente della soluzione.
Operazioni di traccia e debug delle versioni software
Quando un utente segnala un problema, l'utente è spesso a conoscenza solo dell'effetto immediato che ha sulle operazioni. L'utente può solo segnalare i risultati della propria esperienza a un operatore responsabile della gestione del sistema. Queste esperienze sono in genere solo un sintomo visibile di uno o più problemi fondamentali. In molti casi, un analista dovrà esaminare la cronologia delle operazioni sottostanti per stabilire la causa radice del problema. Questo processo è denominato analisi della causa radice.
Annotazioni
L'analisi della causa radice potrebbe rivelare inefficienze nella progettazione di un'applicazione. In queste situazioni, potrebbe essere possibile rielaborare gli elementi interessati e distribuirli come parte di una versione successiva. Questo processo richiede un controllo accurato e i componenti aggiornati devono essere monitorati attentamente.
Requisiti per la traccia e il debug
Per tracciare eventi imprevisti e altri problemi, è fondamentale che i dati di monitoraggio forniscano informazioni sufficienti per consentire a un analista di risalire alle origini di questi problemi e ricostruire la sequenza di eventi che si sono verificati. Queste informazioni devono essere sufficienti per consentire a un analista di diagnosticare la causa radice di eventuali problemi. Uno sviluppatore può quindi apportare le modifiche necessarie per impedire che vengano ricorrenti.
Requisiti relativi a origini dati, strumentazione e raccolta dati
La risoluzione dei problemi può comportare la traccia di tutti i metodi (e i relativi parametri) richiamati come parte di un'operazione per creare un albero che illustra il flusso logico attraverso il sistema quando un cliente effettua una richiesta specifica. Eccezioni e avvisi generati dal sistema in seguito a questo flusso devono essere acquisiti e registrati.
Per supportare il debug, il sistema può fornire hook che consentono a un operatore di acquisire informazioni sullo stato in punti cruciali del sistema. In alternativa, il sistema può fornire informazioni dettagliate dettagliate come avanzamento delle operazioni selezionate. L'acquisizione di dati a questo livello di dettaglio può imporre un carico aggiuntivo nel sistema e deve essere un processo temporaneo. Un operatore usa questo processo principalmente quando si verifica una serie molto insolita di eventi ed è difficile da replicare o quando una nuova versione di uno o più elementi in un sistema richiede un attento monitoraggio per garantire che gli elementi funzionino come previsto.
Pipeline di monitoraggio e diagnostica
Il monitoraggio di un sistema distribuito su vasta scala costituisce una sfida significativa. Ognuno degli scenari descritti nella sezione precedente non deve necessariamente essere considerato in isolamento. È probabile che si verifichi una sovrapposizione significativa nei dati di monitoraggio e diagnostica necessari per ogni situazione, anche se questi dati potrebbero essere necessari per essere elaborati e presentati in modi diversi. Per questi motivi, è consigliabile adottare una visione olistica del monitoraggio e della diagnostica.
È possibile prevedere l'intero processo di monitoraggio e diagnostica come pipeline che comprende le fasi illustrate nella figura 1.
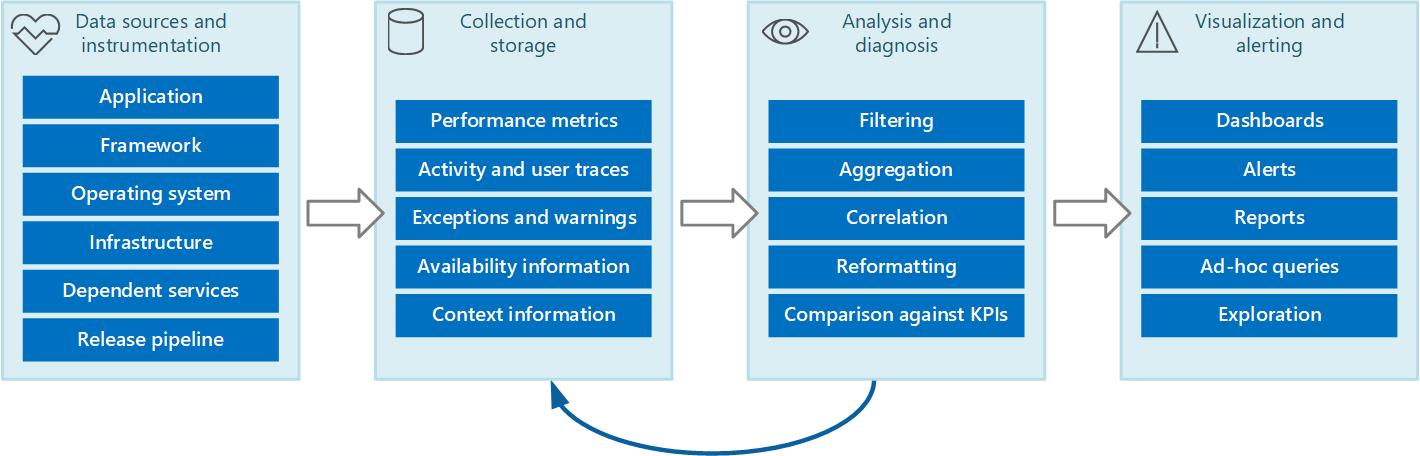
Figura 1 : fasi della pipeline di monitoraggio e diagnostica.
La figura 1 evidenzia il modo in cui i dati per il monitoraggio e la diagnostica possono provenire da un'ampia gamma di origini dati. Le fasi di strumentazione e raccolta riguardano l'identificazione delle origini da cui devono essere acquisiti i dati, la determinazione dei dati da acquisire, la modalità di acquisizione e la formattazione dei dati in modo da poterli esaminare facilmente. La fase di analisi/diagnosi accetta i dati non elaborati e la usa per generare informazioni significative che un operatore può usare per determinare lo stato del sistema. L'operatore può usare queste informazioni per prendere decisioni sulle possibili azioni da intraprendere e quindi inserire i risultati nelle fasi di strumentazione e raccolta. La fase di visualizzazione/avviso presenta una visualizzazione di consumo dello stato del sistema. Può visualizzare informazioni quasi in tempo reale usando una serie di dashboard. E può generare report, grafici e grafici per fornire una visualizzazione cronologica dei dati che consentono di identificare le tendenze a lungo termine. Se le informazioni indicano che è probabile che un indicatore KPI superi limiti accettabili, questa fase può anche attivare un avviso a un operatore. In alcuni casi, è anche possibile usare un avviso per attivare un processo automatizzato che tenta di eseguire azioni correttive, ad esempio la scalabilità automatica.
Si noti che questi passaggi costituiscono un processo di flusso continuo in cui le fasi si verificano in parallelo. Idealmente, tutte le fasi devono essere configurabili in modo dinamico. In alcuni casi, in particolare quando un sistema è stato appena distribuito o riscontra problemi, potrebbe essere necessario raccogliere dati estesi su base più frequente. In altri casi, dovrebbe essere possibile ripristinare l'acquisizione di un livello di base di informazioni essenziali per verificare che il sistema funzioni correttamente.
Inoltre, l'intero processo di monitoraggio deve essere considerato una soluzione in tempo reale e continuativa soggetta a ottimizzazione e miglioramenti a seguito del feedback. Ad esempio, è possibile iniziare a misurare molti fattori per determinare l'integrità del sistema. L'analisi nel tempo può portare a un perfezionamento man mano che si eliminano misure non pertinenti, consentendo di concentrarsi più precisamente sui dati necessari riducendo al minimo il rumore di fondo.
Origini dei dati di monitoraggio e diagnostica
Le informazioni usate dal processo di monitoraggio possono provenire da diverse origini, come illustrato nella figura 1. A livello di applicazione, le informazioni provengono dai log di traccia incorporati nel codice del sistema. Gli sviluppatori devono seguire un approccio standard per tenere traccia del flusso di controllo tramite il codice. Ad esempio, una voce di un metodo può generare un messaggio di traccia che specifica il nome del metodo, l'ora corrente, il valore di ogni parametro e qualsiasi altra informazione pertinente. Anche la registrazione dei tempi di ingresso e uscita può rivelarsi utile.
È consigliabile registrare tutte le eccezioni e gli avvisi e assicurarsi di conservare una traccia completa di eventuali eccezioni e avvisi annidati. Idealmente, è consigliabile acquisire anche informazioni che identificano l'utente che esegue il codice, insieme alle informazioni di correlazione dell'attività (per tenere traccia delle richieste mentre passano attraverso il sistema). È inoltre consigliabile registrare i tentativi di accesso a tutte le risorse, ad esempio code di messaggi, database, file e altri servizi dipendenti. Queste informazioni possono essere usate a scopo di misurazione e controllo.
Molte applicazioni usano librerie e framework per eseguire attività comuni, ad esempio l'accesso a un archivio dati o la comunicazione tramite una rete. Questi framework potrebbero essere configurabili per fornire i propri messaggi di traccia e informazioni di diagnostica non elaborate, ad esempio velocità delle transazioni e errori di trasmissione dei dati.
Annotazioni
Molti framework moderni pubblicano automaticamente eventi di prestazioni e traccia. L'acquisizione di queste informazioni è semplicemente una questione di fornire un mezzo per recuperarlo e archiviarlo dove può essere elaborato e analizzato.
Il sistema operativo in cui l'applicazione è in esecuzione può essere un'origine di informazioni a livello di sistema di basso livello, ad esempio i contatori delle prestazioni che indicano le frequenze di I/O, l'utilizzo della memoria e l'utilizzo della CPU. Potrebbero essere segnalati anche errori del sistema operativo, ad esempio l'errore di apertura corretta di un file.
È anche consigliabile considerare l'infrastruttura e i componenti sottostanti in cui viene eseguito il sistema. Le macchine virtuali, le reti virtuali e i servizi di archiviazione possono essere tutte origini di importanti contatori delle prestazioni a livello di infrastruttura e altri dati di diagnostica.
Se l'applicazione usa altri servizi esterni, ad esempio un server Web o un sistema di gestione di database, questi servizi potrebbero pubblicare le proprie informazioni di traccia, log e contatori delle prestazioni. Ad esempio, le viste a gestione dinamica di SQL Server per il rilevamento delle operazioni eseguite su un database di SQL Server e i log di traccia IIS per la registrazione delle richieste effettuate a un server Web.
Man mano che i componenti di un sistema vengono modificati e vengono distribuite nuove versioni, è importante essere in grado di attribuire problemi, eventi e metriche a ogni versione. Queste informazioni devono essere collegate alla pipeline di versione in modo che i problemi con una versione specifica di un componente possano essere rilevati rapidamente e rettificati.
I problemi di sicurezza possono verificarsi in qualsiasi punto del sistema. Ad esempio, un utente potrebbe tentare di accedere con un ID utente o una password non validi. Un utente autenticato potrebbe provare a ottenere l'accesso non autorizzato a una risorsa. In alternativa, un utente potrebbe fornire una chiave non valida o obsoleta per accedere alle informazioni crittografate. Le informazioni relative alla sicurezza per le richieste riuscite e non riuscite devono essere sempre registrate.
La sezione Instrumenting an application (Strumentazione di un'applicazione ) contiene altre indicazioni sulle informazioni da acquisire. Tuttavia, è possibile usare un'ampia gamma di strategie per raccogliere queste informazioni:
Monitoraggio dell'applicazione/del sistema. Questa strategia usa origini interne all'interno dell'applicazione, dei framework applicazione, del sistema operativo e dell'infrastruttura. Il codice dell'applicazione può generare i propri dati di monitoraggio in punti rilevanti durante il ciclo di vita di una richiesta client. L'applicazione può includere istruzioni di traccia che potrebbero essere abilitate o disabilitate in modo selettivo in base alle circostanze. Potrebbe anche essere possibile inserire la diagnostica in modo dinamico usando un framework di diagnostica. Questi framework in genere forniscono plug-in che possono essere collegati a vari punti di strumentazione nel codice e acquisire i dati di traccia in questi punti.
Inoltre, il codice o l'infrastruttura sottostante potrebbero generare eventi in punti critici. Gli agenti di monitoraggio configurati per l'ascolto di questi eventi possono registrare le informazioni sull'evento.
Monitoraggio utenti reali. Questo approccio registra le interazioni tra un utente e l'applicazione e osserva il flusso di ogni richiesta e risposta. Queste informazioni possono avere uno scopo doppio: può essere usato per la misurazione dell'utilizzo da parte di ogni utente e può essere usato per determinare se gli utenti ricevono una qualità di servizio appropriata (ad esempio, tempi di risposta rapidi, bassa latenza e errori minimi). È possibile usare i dati acquisiti per identificare le aree in cui si verificano gli errori più spesso. È anche possibile usare i dati per identificare gli elementi in cui il sistema rallenta, probabilmente a causa di hotspot nell'applicazione o di un altro tipo di collo di bottiglia. Se si implementa con attenzione questo approccio, potrebbe essere possibile ricostruire i flussi degli utenti attraverso l'applicazione a scopo di debug e test.
Importante
È consigliabile considerare i dati acquisiti monitorando gli utenti reali in modo che siano altamente sensibili perché potrebbero includere materiale riservato. Se si salvano i dati acquisiti, archiviarlo in modo sicuro. Se si vogliono usare i dati per scopi di monitoraggio delle prestazioni o debug, rimuovere prima tutti i dati personali.
Monitoraggio utenti sintetici. In questo approccio si scrive un client di test personalizzato che simula un utente ed esegue una serie di operazioni configurabili ma tipiche. È possibile tenere traccia delle prestazioni del client di test per determinare lo stato del sistema. È anche possibile usare più istanze del client di test come parte di un'operazione di test di carico per stabilire come il sistema risponde sotto stress e quale tipo di output di monitoraggio viene generato in queste condizioni.
Annotazioni
È possibile implementare il monitoraggio utente reale e sintetico includendo codice che esegue tracce e volte l'esecuzione di chiamate al metodo e altre parti critiche di un'applicazione.
Profilatura. Questo approccio è destinato principalmente al monitoraggio e al miglioramento delle prestazioni dell'applicazione. Anziché operare a livello funzionale di monitoraggio utente reale e sintetico, acquisisce informazioni di livello inferiore durante l'esecuzione dell'applicazione. È possibile implementare la profilatura usando il campionamento periodico dello stato di esecuzione di un'applicazione (determinando quale parte di codice è in esecuzione in un determinato momento). È anche possibile usare la strumentazione che inserisce probe nel codice in momenti importanti (ad esempio l'inizio e la fine di una chiamata a un metodo) e registra i metodi richiamati, in quale momento e per quanto tempo ogni chiamata ha impiegato. È quindi possibile analizzare questi dati per determinare quali parti dell'applicazione potrebbero causare problemi di prestazioni.
Monitoraggio degli endpoint. Questa tecnica usa uno o più endpoint di diagnostica esposti dall'applicazione in modo specifico per abilitare il monitoraggio. Un endpoint fornisce un percorso nel codice dell'applicazione e può restituire informazioni sull'integrità del sistema. Endpoint diversi possono concentrarsi su vari aspetti della funzionalità. È possibile scrivere un client di diagnostica personalizzato che invia richieste periodiche a questi endpoint e assimilare le risposte. Per altre informazioni, vedere Modello di monitoraggio degli endpoint di integrità.
Per la copertura massima, è consigliabile usare una combinazione di queste tecniche.
Strumentazione di un'applicazione
La strumentazione è una parte fondamentale del processo di monitoraggio. È possibile prendere decisioni significative sulle prestazioni e sull'integrità di un sistema solo se si acquisiscono prima i dati che consentono di prendere queste decisioni. Le informazioni raccolte tramite strumentazione devono essere sufficienti per consentire di valutare le prestazioni, diagnosticare i problemi e prendere decisioni senza richiedere l'accesso a un server di produzione remoto per eseguire manualmente la traccia (e il debug). I dati di strumentazione in genere comprendono metriche e informazioni scritte nei log di traccia.
Il contenuto di un log di traccia può essere il risultato di dati testuali scritti dall'applicazione o dai dati binari creati come risultato di un evento di traccia, se l'applicazione usa Event Tracing for Windows (ETW). Possono anche essere generati dai log di sistema che registrano eventi derivanti da parti dell'infrastruttura, ad esempio un server Web. I messaggi di log testuali sono spesso progettati per essere leggibili dall'utente, ma devono anche essere scritti in un formato che consente a un sistema automatizzato di analizzarli facilmente.
È anche consigliabile classificare i log. Non scrivere tutti i dati di traccia in un singolo log, ma usare log separati per registrare l'output della traccia da diversi aspetti operativi del sistema. È quindi possibile filtrare rapidamente i messaggi di log leggendo dal log appropriato anziché dover elaborare un singolo file di lunghezza. Non scrivere mai informazioni con requisiti di sicurezza diversi, ad esempio le informazioni di controllo e i dati di debug, nello stesso log.
Annotazioni
Un log può essere implementato come file nel file system oppure può essere mantenuto in un altro formato, ad esempio un BLOB nell'archivio BLOB. Le informazioni sui log possono essere contenute anche in una risorsa di archiviazione più strutturata, ad esempio le righe di una tabella.
Le metriche in genere saranno una misura o un conteggio di alcuni aspetti o risorse nel sistema in un momento specifico, con uno o più tag o dimensioni associati (talvolta denominati campione). Una singola istanza di una metrica in genere non è utile in isolamento. Al contrario, le metriche devono essere acquisite nel tempo. Il problema principale da considerare è quali metriche è necessario registrare e con quale frequenza. La generazione di dati per le metriche troppo spesso può imporre un carico aggiuntivo significativo nel sistema, mentre l'acquisizione di metriche raramente può causare la mancata esecuzione delle circostanze che causano un evento significativo. Le considerazioni variano da metrica a metrica. Ad esempio, l'utilizzo della CPU in un server può variare significativamente da secondo a secondo, ma un utilizzo elevato diventa un problema solo se è di lunga durata in un numero di minuti.
Informazioni per la correlazione dei dati
È possibile monitorare facilmente singoli contatori delle prestazioni a livello di sistema, acquisire le metriche per le risorse e ottenere informazioni di traccia dell'applicazione da vari file di log. Tuttavia, alcune forme di monitoraggio richiedono la fase di analisi e diagnostica nella pipeline di monitoraggio per correlare i dati recuperati da diverse origini. Questi dati possono assumere diverse forme nei dati non elaborati e il processo di analisi deve essere fornito con dati di strumentazione sufficienti per poter eseguire il mapping di queste diverse forme. Ad esempio, a livello di framework applicazione, un'attività potrebbe essere identificata da un ID thread. All'interno di un'applicazione, lo stesso lavoro potrebbe essere associato all'ID utente per l'utente che esegue tale attività.
Inoltre, è improbabile che si verifichi un mapping 1:1 tra thread e richieste utente, perché le operazioni asincrone potrebbero riutilizzare gli stessi thread per eseguire operazioni per conto di più utenti. Per complicare ulteriormente le cose, una singola richiesta potrebbe essere gestita da più thread mentre l'esecuzione scorre attraverso il sistema. Se possibile, associare ogni richiesta a un ID attività univoco propagato nel sistema come parte del contesto della richiesta. La tecnica per la generazione e l'inclusione degli ID attività nelle informazioni di traccia dipende dalla tecnologia usata per acquisire i dati di traccia.
Tutti i dati di monitoraggio devono essere timestamp nello stesso modo. Per coerenza, registrare tutte le date e le ore usando Coordinated Universal Time. Ciò consentirà di tracciare più facilmente sequenze di eventi.
Annotazioni
I computer che operano in fusi orari e reti diversi potrebbero non essere sincronizzati. Non dipendere dall'uso solo di timestamp per correlare i dati di strumentazione che si estendono su più computer.
Informazioni da includere nei dati di strumentazione
Quando si decide quali dati di strumentazione è necessario raccogliere, tenere presente quanto segue:
Assicurarsi che le informazioni acquisite dagli eventi di traccia siano leggibili dal computer. Adottare schemi ben definiti per queste informazioni per facilitare l'elaborazione automatizzata dei dati di log tra sistemi e per garantire coerenza alle operazioni e al personale tecnico che leggono i log. Includere informazioni ambientali, ad esempio l'ambiente di distribuzione, il computer in cui è in esecuzione il processo, i dettagli del processo e lo stack di chiamate.
Abilitare la profilatura solo quando necessario perché può comportare un sovraccarico significativo nel sistema. La profilatura tramite strumentazione registra un evento ,ad esempio una chiamata al metodo, ogni volta che si verifica, mentre il campionamento registra solo gli eventi selezionati. La selezione può essere basata sul tempo (una volta ogni n secondi) o basata sulla frequenza (una volta ogni n richieste). Se gli eventi si verificano molto frequentemente, la profilatura tramite strumentazione potrebbe causare una quantità eccessiva di carico e influire negativamente sulle prestazioni complessive. In questo caso, l'approccio di campionamento potrebbe essere preferibile. Tuttavia, se la frequenza degli eventi è bassa, il campionamento potrebbe perdere. In questo caso, la strumentazione potrebbe essere l'approccio migliore.
Fornire contesto sufficiente per consentire a uno sviluppatore o a un amministratore di determinare l'origine di ogni richiesta. Ciò può includere una forma di ID attività che identifica un'istanza specifica di una richiesta. Può includere anche informazioni che possono essere usate per correlare questa attività con il lavoro di calcolo eseguito e le risorse usate. Si noti che questo lavoro potrebbe attraversare i limiti del processo e del computer. Per la misurazione, il contesto deve includere (direttamente o indirettamente tramite altre informazioni correlate) un riferimento al cliente che ha causato la richiesta. Questo contesto fornisce informazioni utili sullo stato dell'applicazione al momento dell'acquisizione dei dati di monitoraggio.
Registrare tutte le richieste e le località o le aree da cui vengono effettuate queste richieste. Queste informazioni possono essere utili per determinare se sono presenti hotspot specifici della posizione. Queste informazioni possono essere utili anche per determinare se ripartizionare un'applicazione o i dati usati.
Registrare e acquisire attentamente i dettagli delle eccezioni. Spesso, le informazioni di debug critiche vengono perse a causa di una gestione delle eccezioni insufficiente. Acquisire i dettagli completi delle eccezioni generate dall'applicazione, incluse eventuali eccezioni interne e altre informazioni sul contesto. Se possibile, includere lo stack di chiamate.
Essere coerenti nei dati acquisiti dai diversi elementi dell'applicazione, perché ciò può facilitare l'analisi degli eventi e la correlazione con le richieste utente. Prendere in considerazione l'uso di un pacchetto di registrazione completo e configurabile per raccogliere informazioni, anziché in base agli sviluppatori per adottare lo stesso approccio implementato da parti diverse del sistema. Raccogliere dati dai contatori delle prestazioni chiave, ad esempio il volume di operazioni di I/O eseguite, l'utilizzo della rete, il numero di richieste, l'uso della memoria e l'utilizzo della CPU. Alcuni servizi di infrastruttura possono fornire contatori delle prestazioni specifici, ad esempio il numero di connessioni a un database, la frequenza con cui vengono eseguite le transazioni e il numero di transazioni che hanno esito positivo o negativo. Le applicazioni possono anche definire contatori delle prestazioni specifici.
Registra tutte le chiamate effettuate a servizi esterni, ad esempio sistemi di database, servizi Web o altri servizi a livello di sistema che fanno parte dell'infrastruttura. Registrare informazioni sul tempo impiegato per eseguire ogni chiamata e sull'esito positivo o negativo della chiamata. Se possibile, acquisire informazioni su tutti i tentativi e sugli errori per eventuali errori temporanei che si verificano.
Garantire la compatibilità con i sistemi di telemetria
In molti casi, le informazioni generate dalla strumentazione vengono generate come una serie di eventi e passate a un sistema di telemetria separato per l'elaborazione e l'analisi. Un sistema di telemetria è in genere indipendente da qualsiasi applicazione o tecnologia specifica, ma prevede che le informazioni seguano un formato specifico definito in genere da uno schema. Lo schema specifica in modo efficace un contratto che definisce i campi dati e i tipi che il sistema di telemetria può inserire. Lo schema deve essere generalizzato per consentire l'arrivo dei dati da un'ampia gamma di piattaforme e dispositivi.
Uno schema comune deve includere campi comuni a tutti gli eventi di strumentazione, ad esempio il nome dell'evento, l'ora dell'evento, l'indirizzo IP del mittente e i dettagli necessari per correlare con altri eventi, ad esempio un ID utente, un ID dispositivo e un ID applicazione. Tenere presente che un numero qualsiasi di dispositivi potrebbe generare eventi, quindi lo schema non deve dipendere dal tipo di dispositivo. Inoltre, vari dispositivi potrebbero generare eventi per la stessa applicazione; l'applicazione potrebbe supportare il roaming o un'altra forma di distribuzione tra dispositivi.
Lo schema può includere anche campi di dominio rilevanti per uno scenario specifico comune in diverse applicazioni. Potrebbero trattarsi di informazioni sulle eccezioni, sugli eventi di avvio e di fine dell'applicazione e sull'esito positivo o negativo delle chiamate API del servizio Web. Tutte le applicazioni che usano lo stesso set di campi di dominio devono generare lo stesso set di eventi, consentendo la compilazione di un set di report e analisi comuni.
Infine, uno schema può contenere campi personalizzati per acquisire i dettagli degli eventi specifici dell'applicazione.
Procedure consigliate per la strumentazione delle applicazioni
L'elenco seguente riepiloga le procedure consigliate per instrumentare un'applicazione distribuita in esecuzione nel cloud.
Semplifica la lettura e la facilità di analisi dei log. Usare la registrazione strutturata laddove possibile. Essere concisi e descrittivi nei messaggi di log.
In tutti i log identificare l'origine e fornire informazioni di contesto e temporizzazione durante la scrittura di ogni record di log.
Usare lo stesso fuso orario e il formato per tutti i timestamp. Ciò consentirà di correlare gli eventi per le operazioni che si estendono su hardware e servizi in esecuzione in aree geografiche diverse.
Classificare i log e scrivere messaggi nel file di log appropriato.
Non divulgare informazioni riservate sul sistema o informazioni personali sugli utenti. Eseguire lo scrub di queste informazioni prima della registrazione, ma assicurarsi che i dettagli pertinenti vengano conservati. Ad esempio, rimuovere l'ID e la password da qualsiasi stringa di connessione del database, ma scrivere le informazioni rimanenti nel log in modo che un analista possa determinare che il sistema accede al database corretto. Registrare tutte le eccezioni critiche, ma consentire all'amministratore di attivare e disattivare la registrazione per livelli inferiori di eccezioni e avvisi. Acquisire e registrare anche tutte le informazioni sulla logica di ripetizione dei tentativi. Questi dati possono essere utili per monitorare l'integrità temporanea del sistema.
Tracciare le chiamate di processo, ad esempio le richieste a servizi Web esterni o database.
Non combinare messaggi di log con requisiti di sicurezza diversi nello stesso file di log. Ad esempio, non scrivere informazioni di debug e controllo nello stesso log.
Ad eccezione degli eventi di controllo, assicurarsi che tutte le chiamate di registrazione siano operazioni di tipo fire-and-forget che non bloccano lo stato di avanzamento delle operazioni aziendali. Gli eventi di controllo sono eccezionali perché sono fondamentali per l'azienda e possono essere classificati come parte fondamentale delle operazioni aziendali.
Assicurarsi che la registrazione sia estendibile e non abbia dipendenze dirette da una destinazione concreta. Ad esempio, anziché scrivere informazioni usando System.Diagnostics.Trace, definire un'interfaccia astratta ,ad esempio ILogger, che espone i metodi di registrazione e che può essere implementata tramite qualsiasi mezzo appropriato.
Assicurarsi che tutte le registrazioni siano sicure per gli errori e che non attivino mai errori a catena. La registrazione non deve generare eccezioni.
Considerare la strumentazione come processo iterativo in corso ed esaminare regolarmente i log, non solo quando si verifica un problema.
Raccolta e archiviazione dei dati
La fase di raccolta del processo di monitoraggio riguarda il recupero delle informazioni generate dalla strumentazione, la formattazione di questi dati per semplificare l'utilizzo della fase di analisi/diagnosi e il salvataggio dei dati trasformati in un archivio affidabile. I dati di strumentazione raccolti da diverse parti di un sistema distribuito possono essere mantenuti in diverse posizioni e con formati diversi. Ad esempio, il codice dell'applicazione potrebbe generare file di log di traccia e generare dati del log eventi dell'applicazione, mentre i contatori delle prestazioni che monitorano gli aspetti chiave dell'infrastruttura usata dall'applicazione possono essere acquisiti tramite altre tecnologie. Tutti i componenti e i servizi di terze parti usati dall'applicazione possono fornire informazioni di strumentazione in formati diversi, usando file di traccia separati, archiviazione BLOB o anche un archivio dati personalizzato.
La raccolta dei dati viene spesso eseguita tramite un servizio di raccolta che può essere eseguito in modo autonomo dall'applicazione che genera i dati di strumentazione. La figura 2 illustra un esempio di questa architettura, evidenziando il sottosistema di raccolta dati di strumentazione.
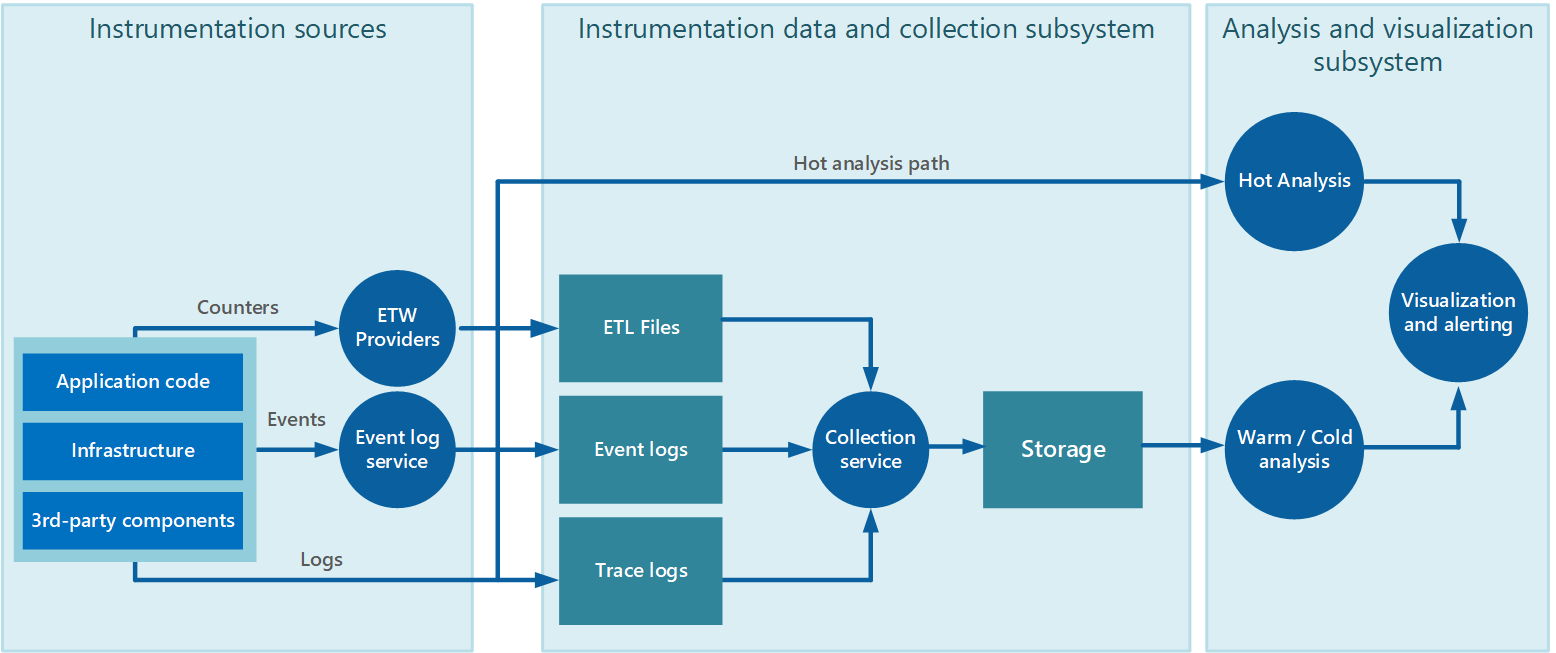
Figura 2 - Raccolta dei dati di strumentazione.
Si noti che si tratta di una visualizzazione semplificata. Il servizio di raccolta non è necessariamente un singolo processo e può includere molte parti costitutive in esecuzione in computer diversi, come descritto nelle sezioni seguenti. Inoltre, se l'analisi di alcuni dati di telemetria deve essere eseguita rapidamente (analisi ad accesso frequente, come descritto nella sezione Supporto di analisi ad accesso frequente, frequente e ad accesso sporadico più avanti in questo documento), i componenti locali che operano all'esterno del servizio di raccolta potrebbero eseguire immediatamente le attività di analisi. La figura 2 illustra questa situazione per gli eventi selezionati. Dopo l'elaborazione analitica, i risultati possono essere inviati direttamente al sottosistema di visualizzazione e avviso. I dati sottoposti ad analisi ad accesso frequente o sporadico vengono mantenuti nell'archiviazione mentre sono in attesa dell'elaborazione.
Per le applicazioni e i servizi di Azure, Diagnostica di Azure offre una possibile soluzione per l'acquisizione dei dati. Diagnostica di Azure raccoglie i dati dalle origini seguenti per ogni nodo di calcolo, lo aggrega e quindi lo carica in Archiviazione di Azure:
- Log iis
- Log delle richieste non riuscite di IIS
- Registri eventi di Windows
- Contatori delle prestazioni
- Dump di arresto anomalo del sistema
- Log dell'infrastruttura Diagnostica di Azure
- Registri degli errori personalizzati
- EventSource .NET
- ETW basato su manifesto
Per altre informazioni, vedere l'articolo Azure: Nozioni di base sulla telemetria e risoluzione dei problemi.
Strategie per la raccolta dei dati di strumentazione
Considerando la natura elastica del cloud e per evitare la necessità di recuperare manualmente i dati di telemetria da ogni nodo del sistema, è necessario disporre che i dati vengano trasferiti in una posizione centrale e consolidati. In un sistema che si estende su più data center, potrebbe essere utile raccogliere, consolidare e archiviare i dati in base all'area per area e quindi aggregare i dati a livello di area in un unico sistema centrale.
Per ottimizzare l'uso della larghezza di banda, è possibile scegliere di trasferire dati meno urgenti in blocchi, come batch. Tuttavia, i dati non devono essere ritardati per un periodo illimitato, soprattutto se contengono informazioni sensibili al tempo.
Pull e push dei dati di strumentazione
Il sottosistema di raccolta dati di strumentazione può recuperare attivamente i dati di strumentazione dai vari log e altre origini per ogni istanza dell'applicazione (modello di pull). In alternativa, può fungere da ricevitore passivo che attende l'invio dei dati dai componenti che costituiscono ogni istanza dell'applicazione (modello push).
Un approccio all'implementazione del modello pull consiste nell'usare gli agenti di monitoraggio eseguiti localmente con ogni istanza dell'applicazione. Un agente di monitoraggio è un processo separato che recupera periodicamente i dati di telemetria (pull) raccolti nel nodo locale e scrive queste informazioni direttamente nella risorsa di archiviazione centralizzata condivisa da tutte le istanze dell'applicazione. Si tratta del meccanismo implementato da Diagnostica di Azure. Ogni istanza di un ruolo Web o di lavoro di Azure può essere configurata per acquisire informazioni di diagnostica e di traccia archiviate in locale. L'agente di monitoraggio eseguito insieme a ogni istanza copia i dati specificati in Archiviazione di Azure. L'articolo Abilitazione della diagnostica nei servizi cloud di Azure e nelle macchine virtuali fornisce altri dettagli su questo processo. Alcuni elementi, ad esempio i log IIS, i dump di arresto anomalo del sistema e i log degli errori personalizzati, vengono scritti nell'archivio BLOB. I dati del registro eventi di Windows, degli eventi ETW e dei contatori delle prestazioni vengono registrati nell'archiviazione tabelle. La figura 3 illustra questo meccanismo.
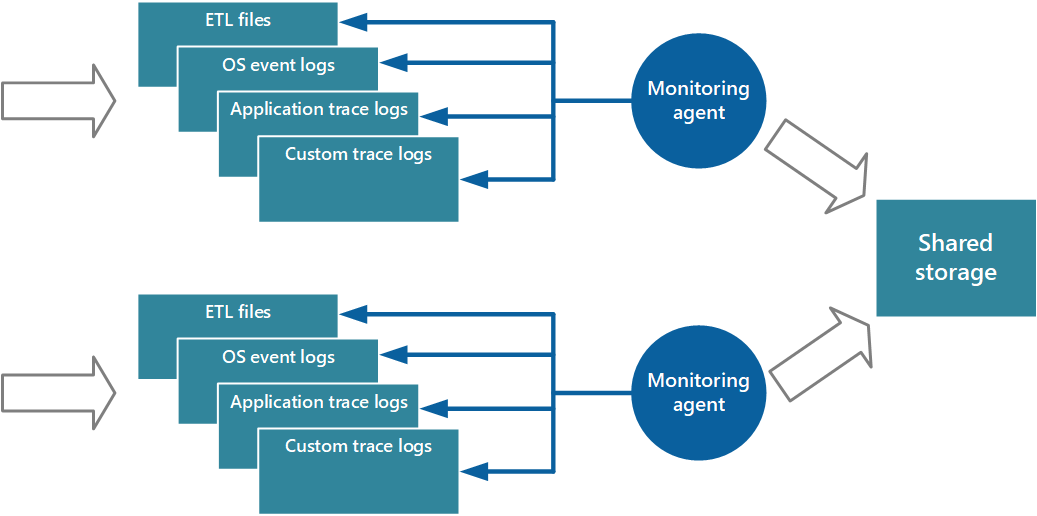
Figura 3 - Uso di un agente di monitoraggio per eseguire il pull delle informazioni e scrivere nella risorsa di archiviazione condivisa.
Annotazioni
L'uso di un agente di monitoraggio è particolarmente indicato per l'acquisizione dei dati di strumentazione estratti in modo naturale da un'origine dati. Un esempio è rappresentato dalle viste a gestione dinamica di SQL Server o dalla lunghezza di una coda del bus di servizio di Azure.
È possibile usare l'approccio appena descritto per archiviare i dati di telemetria per un'applicazione su scala ridotta in esecuzione in un numero limitato di nodi in un'unica posizione. Tuttavia, un'applicazione cloud globale complessa e altamente scalabile può generare enormi volumi di dati da centinaia di ruoli Web e di lavoro, partizioni di database e altri servizi. Questa alluvione di dati può facilmente sovraccaricare la larghezza di banda di I/O disponibile con una singola posizione centrale. Pertanto, la soluzione di telemetria deve essere scalabile per impedire che agisca come collo di bottiglia man mano che il sistema si espande. Idealmente, la soluzione deve incorporare un grado di ridondanza per ridurre i rischi di perdita di informazioni di monitoraggio importanti (ad esempio il controllo o i dati di fatturazione) se una parte del sistema non riesce.
Per risolvere questi problemi, è possibile implementare l'accodamento, come illustrato nella figura 4. In questa architettura, l'agente di monitoraggio locale (se può essere configurato in modo appropriato) o il servizio di raccolta dati personalizzato (se non lo è) inserisce i dati in una coda. Un processo separato in esecuzione in modo asincrono (il servizio di scrittura di archiviazione nella figura 4) accetta i dati in questa coda e lo scrive nell'archiviazione condivisa. Una coda di messaggi è adatta a questo scenario perché fornisce semantiche "almeno una volta" che consentono di garantire che i dati in coda non andranno persi dopo la pubblicazione. È possibile implementare il servizio di scrittura dell'archiviazione usando un ruolo di lavoro separato.
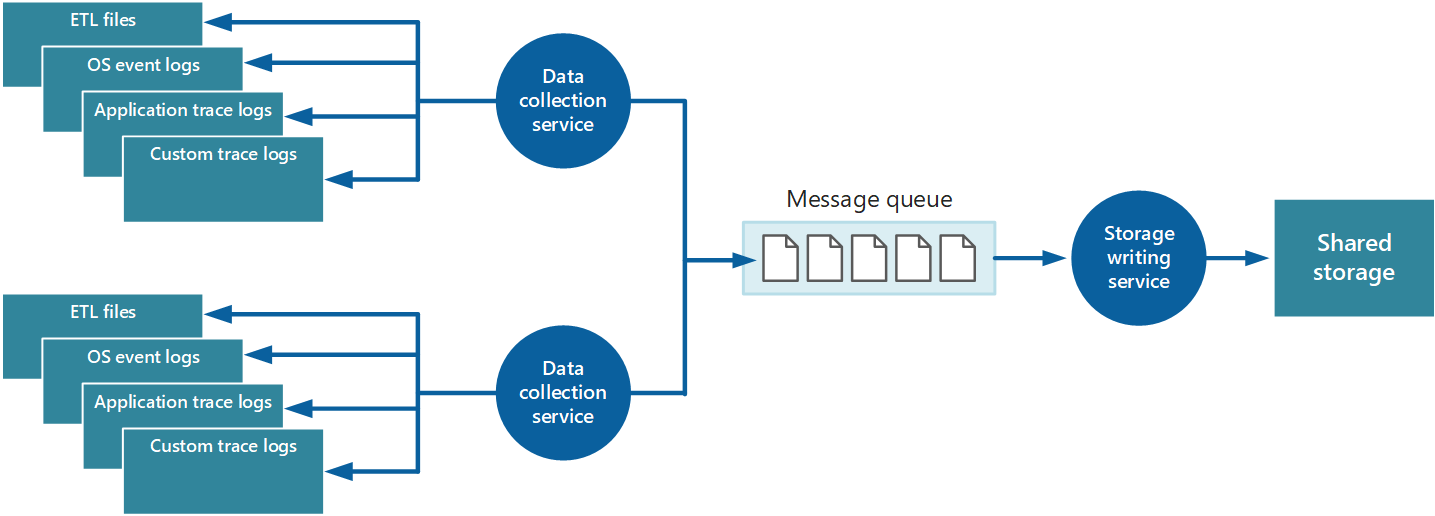
Figura 4 - Uso di una coda per memorizzare nel buffer i dati di strumentazione.
Il servizio di raccolta dati locale può aggiungere dati a una coda immediatamente dopo la ricezione. La coda funge da buffer e il servizio di scrittura dell'archiviazione può recuperare e scrivere i dati al proprio ritmo. Per impostazione predefinita, una coda opera in base al primo istanza. Tuttavia, è possibile classificare in ordine di priorità i messaggi per accelerarli attraverso la coda se contengono dati che devono essere gestiti più rapidamente. Per altre informazioni, vedere Modello di coda priorità. In alternativa, è possibile usare canali diversi,ad esempio gli argomenti del bus di servizio, per indirizzare i dati a destinazioni diverse a seconda della forma di elaborazione analitica necessaria.
Per la scalabilità, è possibile eseguire più istanze del servizio di scrittura dell'archiviazione. Se è presente un volume elevato di eventi, è possibile usare un hub eventi per inviare i dati a risorse di calcolo diverse per l'elaborazione e l'archiviazione.
Consolidamento dei dati di strumentazione
I dati di strumentazione recuperati dal servizio di raccolta dati da una singola istanza di un'applicazione offrono una visualizzazione localizzata dell'integrità e delle prestazioni di tale istanza. Per valutare l'integrità complessiva del sistema, è necessario consolidare alcuni aspetti dei dati nelle visualizzazioni locali. È possibile eseguire questa operazione dopo l'archiviazione dei dati, ma in alcuni casi è anche possibile ottenerli durante la raccolta dei dati. Anziché essere scritti direttamente nell'archiviazione condivisa, i dati di strumentazione possono passare attraverso un servizio di consolidamento dei dati separato che combina i dati e funge da processo di filtro e pulizia. Ad esempio, i dati di strumentazione che includono le stesse informazioni di correlazione, ad esempio un ID attività, possono essere amalgamati. È possibile che un utente inizi a eseguire un'operazione aziendale su un nodo e quindi venga trasferito a un altro nodo in caso di errore del nodo o a seconda della configurazione del bilanciamento del carico. Questo processo può anche rilevare e rimuovere tutti i dati duplicati (sempre una possibilità se il servizio di telemetria usa code di messaggi per eseguire il push dei dati di strumentazione nell'archiviazione). La figura 5 illustra un esempio di questa struttura.
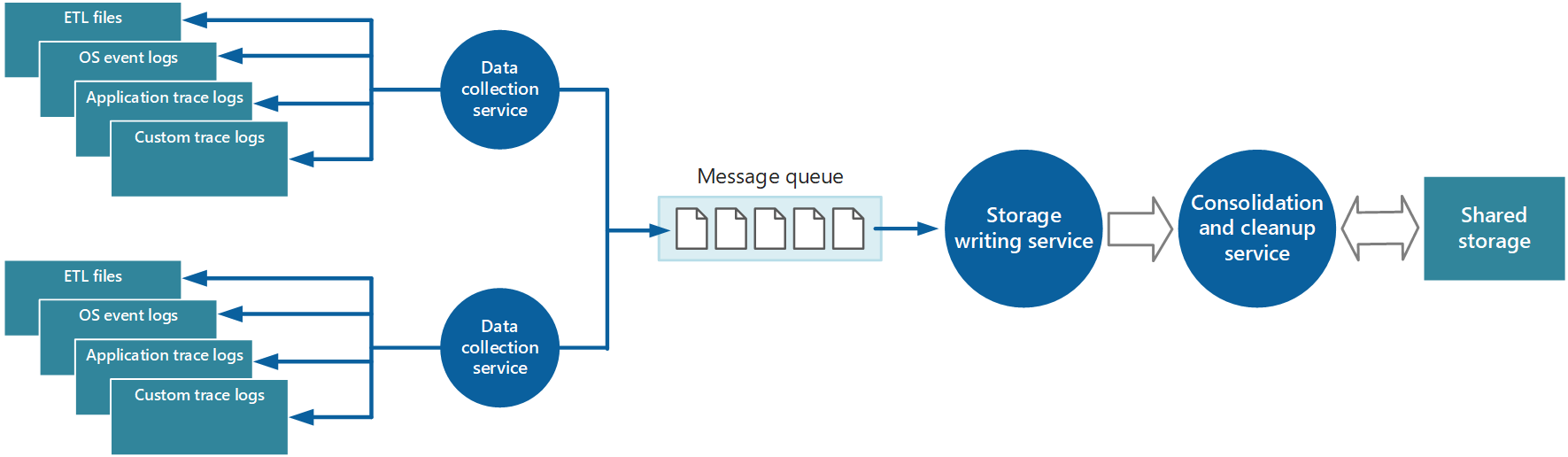
Figura 5 - Uso di un servizio separato per consolidare e pulire i dati di strumentazione.
Archiviazione dei dati di strumentazione
Le discussioni precedenti hanno illustrato una visione piuttosto semplicistica del modo in cui vengono archiviati i dati di strumentazione. In realtà, può essere utile archiviare i diversi tipi di informazioni usando tecnologie più appropriate per il modo in cui è probabile che ogni tipo venga usato.
Ad esempio, l'archiviazione BLOB e tabelle di Azure presenta alcune analogie nel modo in cui si accede. Tuttavia, presentano limitazioni nelle operazioni che è possibile eseguire usando tali operazioni e la granularità dei dati contenuti è piuttosto diversa. Se è necessario eseguire altre operazioni di analisi o servono funzionalità di ricerca full-text sui dati, è preferibile usare l'archiviazione dei dati che fornisce funzionalità ottimizzate per specifici tipi di query e accesso ai dati. Per esempio:
- I dati dei contatori delle prestazioni possono essere archiviati in un database SQL per abilitare l'analisi ad hoc.
- I log di traccia potrebbero essere meglio archiviati in Azure Cosmos DB.
- Le informazioni di sicurezza possono essere scritte in HDFS.
- Le informazioni che richiedono la ricerca full-text possono essere archiviate tramite Elasticsearch (che può anche velocizzare le ricerche tramite indicizzazione avanzata).
È possibile implementare un servizio aggiuntivo che recupera periodicamente i dati dall'archiviazione condivisa, dalle partizioni e filtra i dati in base allo scopo e quindi li scrive in un set appropriato di archivi dati, come illustrato nella figura 6. Un approccio alternativo consiste nell'includere questa funzionalità nel processo di consolidamento e pulizia e nello scrivere i dati direttamente in questi archivi man mano che vengono recuperati, piuttosto che salvarli in un'area di archiviazione intermedia condivisa. Ogni approccio presenta vantaggi e svantaggi. L'implementazione di un servizio di partizionamento separato riduce il carico sul servizio di consolidamento e pulizia e consente di rigenerare almeno alcuni dei dati partizionati, se necessario (a seconda della quantità di dati conservati nell'archiviazione condivisa). Tuttavia, utilizza risorse aggiuntive. Potrebbe anche verificarsi un ritardo tra la ricezione dei dati di strumentazione da ogni istanza dell'applicazione e la conversione dei dati in informazioni di utilità operativa.
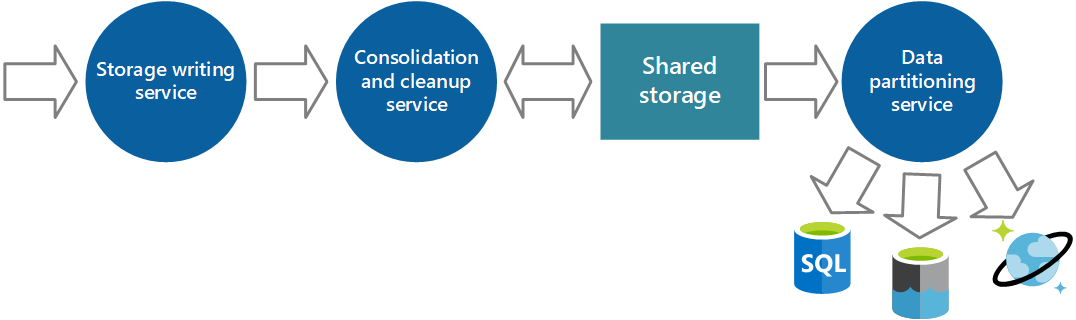
Figura 6 - Partizionamento dei dati in base ai requisiti analitici e di archiviazione.
Gli stessi dati di strumentazione potrebbero essere necessari per più scopi. Ad esempio, i contatori delle prestazioni possono essere usati per fornire una visualizzazione cronologica delle prestazioni del sistema nel tempo. Queste informazioni potrebbero essere combinate con altri dati sull'utilizzo per generare informazioni di fatturazione clienti. In queste situazioni, gli stessi dati possono essere inviati a più di una destinazione, ad esempio un database di documenti che può fungere da archivio a lungo termine per la conservazione delle informazioni di fatturazione e un archivio multidimensionale per la gestione di analisi delle prestazioni complesse.
È anche necessario considerare quanto urgentemente sono necessari i dati. I dati che forniscono informazioni per l'invio di avvisi devono essere accessibili rapidamente, pertanto devono essere mantenuti nell'archiviazione dei dati veloce e indicizzati o strutturati per ottimizzare le query eseguite dal sistema di avvisi. In alcuni casi, potrebbe essere necessario per il servizio di telemetria che raccoglie i dati in ogni nodo per formattare e salvare i dati in locale, in modo che un'istanza locale del sistema di avvisi possa notificare rapidamente eventuali problemi. Gli stessi dati possono essere inviati al servizio di scrittura nell'archivio visualizzato nei diagrammi precedenti e archiviati in modo centralizzato, se necessari anche per altri scopi.
Le informazioni usate per un'analisi più considerata, per la creazione di report e per individuare tendenze cronologiche sono meno urgenti e possono essere archiviate in modo da supportare il data mining e le query ad hoc. Per altre informazioni, vedere la sezione Supporto di analisi ad accesso frequente, frequente e sporadico più avanti in questo documento.
Rotazione dei log e conservazione dei dati
La strumentazione può generare volumi notevoli di dati. Questi dati possono essere conservati in diverse posizioni, a partire dai file di log non elaborati, dai file di traccia e da altre informazioni acquisite in ogni nodo alla visualizzazione consolidata, pulita e partizionata di questi dati contenuti nell'archiviazione condivisa. In alcuni casi, dopo l'elaborazione e il trasferimento dei dati, i dati di origine non elaborati originali possono essere rimossi da ogni nodo. In altri casi, potrebbe essere necessario o semplicemente utile salvare le informazioni non elaborate. Ad esempio, i dati generati per scopi di debug potrebbero essere più disponibili nel formato non elaborato, ma possono essere eliminati rapidamente dopo la correzione di eventuali bug.
I dati sulle prestazioni hanno spesso una durata più lunga, in modo che possa essere usata per individuare le tendenze delle prestazioni e per la pianificazione della capacità. La visualizzazione consolidata di questi dati viene generalmente mantenuta online per un periodo limitato, per consentirne l'accesso rapido. In seguito, questi dati possono essere archiviati o eliminati. I dati raccolti per la misurazione e la fatturazione ai clienti potrebbero dover essere salvati a tempo indeterminato. Inoltre, i requisiti normativi potrebbero determinare che anche le informazioni raccolte per scopi di controllo e sicurezza devono essere archiviate e salvate. Anche questi dati sono sensibili e potrebbe essere necessario crittografarli o proteggerli in altro modo per evitare manomissioni. È consigliabile non registrare mai le password degli utenti o altre informazioni che potrebbero essere usate per commettere frodi di identità. Tali dettagli devono essere eliminati dai dati prima che vengano archiviati.
Campionamento inattivo
Archiviare dati cronologici è utile per individuare le tendenze a lungo termine. Invece di salvare i dati obsoleti nel suo insieme, potrebbe essere possibile eseguire il down-sample dei dati per ridurre la risoluzione e risparmiare sui costi di archiviazione. Ad esempio, invece di risparmiare indicatori di prestazioni minuto per minuto, è possibile consolidare i dati più vecchi di un mese per formare una visualizzazione oraria per ora.
Procedure consigliate per la raccolta e l'archiviazione delle informazioni di registrazione
L'elenco seguente riepiloga le procedure consigliate per l'acquisizione e l'archiviazione delle informazioni di registrazione:
L'agente di monitoraggio o il servizio di raccolta dati deve essere eseguito come servizio out-of-process e deve essere semplice da distribuire.
Tutto l'output dell'agente di monitoraggio o del servizio di raccolta dati deve essere un formato indipendente dal computer, dal sistema operativo o dal protocollo di rete. Ad esempio, generare informazioni in un formato autodescrittivo, ad esempio JSON, MessagePack o Protobuf anziché ETL/ETW. L'uso di un formato standard consente al sistema di costruire pipeline di elaborazione; i componenti che leggono, trasformano e inviano dati nel formato concordato possono essere facilmente integrati.
Il processo di monitoraggio e raccolta dati deve essere sicuro e non deve attivare condizioni di errore a catena.
In caso di errore temporaneo nell'invio di informazioni a un sink di dati, l'agente di monitoraggio o il servizio di raccolta dati deve essere preparato per riordinare i dati di telemetria in modo che le informazioni più recenti vengano inviate per prime. L'agente di monitoraggio/il servizio di raccolta dati potrebbe scegliere di eliminare i dati meno recenti o salvarli in locale e trasmetterli in un secondo momento per recuperarli, a propria discrezione.
Analisi dei dati e diagnosi dei problemi
Una parte importante del processo di monitoraggio e diagnostica consiste nell'analizzare i dati raccolti per ottenere un quadro del benessere generale del sistema. È necessario definire indicatori KPI e metriche delle prestazioni personalizzati ed è importante comprendere come strutturare i dati raccolti per soddisfare i requisiti di analisi. È anche importante comprendere come sono correlati i dati acquisiti in metriche e file di log diversi, perché queste informazioni possono essere fondamentali per tenere traccia di una sequenza di eventi e diagnosticare i problemi che si verificano.
Come descritto nella sezione Consolidamento dei dati di strumentazione, i dati per ogni parte del sistema vengono in genere acquisiti localmente, ma in genere devono essere combinati con i dati generati in altri siti che partecipano al sistema. Queste informazioni richiedono un'attenta correlazione per garantire che i dati vengano combinati in modo accurato. Ad esempio, i dati di utilizzo per un'operazione potrebbero estendersi su un nodo che ospita un sito Web a cui si connette un utente, un nodo che esegue un servizio separato a cui si accede come parte di questa operazione e l'archiviazione dei dati contenuta in un altro nodo. Queste informazioni devono essere collegate insieme per fornire una visualizzazione complessiva dell'utilizzo delle risorse e dell'elaborazione per l'operazione. Alcune operazioni di pre-elaborazione e filtro dei dati possono verificarsi nel nodo in cui vengono acquisiti i dati, mentre è più probabile che l'aggregazione e la formattazione si verifichino in un nodo centrale.
Supporto di analisi ad accesso frequente, frequente e sporadico
L'analisi e la riformattazione dei dati per scopi di visualizzazione, creazione di report e avvisi possono essere un processo complesso che utilizza il proprio set di risorse. Alcune forme di monitoraggio sono cruciali per il tempo e richiedono un'analisi immediata dei dati per essere efficaci. Questa operazione è nota come analisi ad accesso frequente. Gli esempi includono le analisi necessarie per l'invio di avvisi e alcuni aspetti del monitoraggio della sicurezza ,ad esempio il rilevamento di un attacco al sistema. I dati necessari per questi scopi devono essere rapidamente disponibili e strutturati per un'elaborazione efficiente. In alcuni casi, potrebbe essere necessario spostare l'elaborazione dell'analisi nei singoli nodi in cui sono contenuti i dati.
Altre forme di analisi sono meno critiche per il tempo e potrebbero richiedere calcoli e aggregazioni dopo la ricezione dei dati non elaborati. Questa operazione è detta analisi ad accesso frequente. L'analisi delle prestazioni rientra spesso in questa categoria. In questo caso, è improbabile che un singolo evento di prestazioni isolato sia statisticamente significativo. Potrebbe essere causato da un picco improvviso o da un problema. I dati di una serie di eventi devono fornire un quadro più affidabile delle prestazioni del sistema.
L'analisi ad accesso frequente può essere usata anche per diagnosticare i problemi di integrità. Un evento di integrità viene in genere elaborato tramite l'analisi ad accesso frequente e può generare immediatamente un avviso. Un operatore deve essere in grado di esaminare i motivi dell'evento di integrità esaminando i dati dal percorso ad accesso frequente. Questi dati devono contenere informazioni sugli eventi che causano l'evento di integrità.
Alcuni tipi di monitoraggio generano dati a lungo termine. Questa analisi può essere eseguita in un secondo momento, possibilmente in base a una pianificazione predefinita. In alcuni casi, l'analisi potrebbe dover eseguire un filtro complesso di grandi volumi di dati acquisiti in un periodo di tempo. Questa operazione è detta analisi a freddo. Il requisito chiave è che i dati vengono archiviati in modo sicuro dopo l'acquisizione. Ad esempio, il monitoraggio e il controllo dell'utilizzo richiedono un'immagine accurata dello stato del sistema in momenti regolari, ma queste informazioni sullo stato non devono essere disponibili per l'elaborazione immediatamente dopo la raccolta.
Un operatore può anche usare l'analisi a freddo per fornire i dati per l'analisi predittiva dell'integrità. L'operatore può raccogliere informazioni cronologiche in un periodo specificato e usarle insieme ai dati di integrità correnti (recuperati dal percorso critico) per individuare le tendenze che potrebbero causare presto problemi di integrità. In questi casi, potrebbe essere necessario generare un avviso in modo che possa essere eseguita un'azione correttiva.
Correlazione dei dati
I dati acquisiti dalla strumentazione possono fornire uno snapshot dello stato del sistema, ma lo scopo dell'analisi è rendere questi dati interattivi. Per esempio:
- Cosa ha causato un intenso caricamento di I/O a livello di sistema in un momento specifico?
- È il risultato di un numero elevato di operazioni di database?
- Ciò si riflette nei tempi di risposta del database, nel numero di transazioni al secondo e nei tempi di risposta dell'applicazione nello stesso momento?
In tal caso, un'azione correttiva che potrebbe ridurre il carico potrebbe essere quella di partizionare i dati su più server. Inoltre, le eccezioni possono verificarsi a causa di un errore in qualsiasi livello del sistema. Un'eccezione in un livello spesso attiva un altro errore nel livello precedente.
Per questi motivi, è necessario essere in grado di correlare i diversi tipi di dati di monitoraggio a ogni livello per produrre una visualizzazione generale dello stato del sistema e delle applicazioni in esecuzione su di esso. È quindi possibile utilizzare queste informazioni per prendere decisioni su se il sistema funziona in modo accettabile o meno e determinare cosa può essere fatto per migliorare la qualità del sistema.
Come descritto nella sezione Informazioni per correlare i dati, è necessario assicurarsi che i dati di strumentazione non elaborati includano informazioni di contesto e ID attività sufficienti per supportare le aggregazioni necessarie per correlare gli eventi. Inoltre, questi dati potrebbero essere conservati in formati diversi e potrebbe essere necessario analizzare queste informazioni per convertirle in un formato standardizzato per l'analisi.
Diagnosi e risoluzione dei problemi
La diagnosi richiede la possibilità di determinare la causa di errori o comportamenti imprevisti, inclusa l'esecuzione dell'analisi della causa radice. Le informazioni necessarie in genere includono:
- Informazioni dettagliate dai registri eventi e dalle tracce, per l'intero sistema o per un sottosistema specificato durante un intervallo di tempo specificato.
- Analisi dello stack complete risultanti da eccezioni e errori di qualsiasi livello specificato che si verifica all'interno del sistema o di un sottosistema specificato durante un periodo specificato.
- Dump di arresto anomalo per qualsiasi processo non riuscito in qualsiasi punto del sistema o per un sottosistema specificato durante un intervallo di tempo specificato.
- Log attività che registrano le operazioni eseguite da tutti gli utenti o per gli utenti selezionati durante un periodo specificato.
L'analisi dei dati a scopo di risoluzione dei problemi richiede spesso una conoscenza tecnica approfondita dell'architettura di sistema e dei vari componenti che compongono la soluzione. Di conseguenza, è spesso necessario un elevato grado di intervento manuale per interpretare i dati, stabilire la causa dei problemi e consigliare una strategia appropriata per correggerli. Potrebbe essere opportuno archiviare una copia di queste informazioni nel formato originale e renderla disponibile per l'analisi a freddo da parte di un esperto.
Visualizzazione dei dati e generazione di avvisi
Un aspetto importante di qualsiasi sistema di monitoraggio è la possibilità di presentare i dati in modo che un operatore possa individuare rapidamente eventuali tendenze o problemi. È importante anche la possibilità di informare rapidamente un operatore se si è verificato un evento significativo che potrebbe richiedere attenzione.
La presentazione dei dati può assumere diverse forme, tra cui la visualizzazione usando dashboard, avvisi e report.
Visualizzazione tramite dashboard
Il modo più comune per visualizzare i dati consiste nell'usare i dashboard che possono visualizzare informazioni come una serie di grafici, grafici o altre illustrazioni. Questi elementi possono essere parametrizzati e un analista deve essere in grado di selezionare i parametri importanti (ad esempio il periodo di tempo) per qualsiasi situazione specifica.
I dashboard possono essere organizzati gerarchicamente. I dashboard di primo livello possono offrire una visualizzazione complessiva di ogni aspetto del sistema, ma consentono a un operatore di eseguire il drill-down dei dettagli. Ad esempio, un dashboard che illustra l'I/O complessivo del disco per il sistema deve consentire a un analista di visualizzare le tariffe di I/O per ogni singolo disco per verificare se uno o più dispositivi specifici rappresentano un volume sproporzionato di traffico. Idealmente, il dashboard dovrebbe anche visualizzare informazioni correlate, ad esempio l'origine di ogni richiesta (l'utente o l'attività) che genera questo I/O. Queste informazioni possono quindi essere usate per determinare se (e come) distribuire il carico in modo più uniforme tra i dispositivi e se il sistema avrebbe prestazioni migliori se sono stati aggiunti più dispositivi.
Un dashboard può anche usare la codifica a colori o altri segnali visivi per indicare i valori che appaiono anomali o che non rientrano in un intervallo previsto. Uso dell'esempio precedente:
- Un disco con una velocità di I/O che sta raggiungendo la capacità massima in un periodo prolungato (un disco critico) può essere evidenziato in rosso.
- Un disco con una velocità di I/O che viene eseguita periodicamente al limite massimo per brevi periodi (un disco caldo) può essere evidenziato in giallo.
- Un disco che presenta un utilizzo normale può essere visualizzato in verde.
Si noti che per il funzionamento efficace di un sistema di dashboard, è necessario che i dati non elaborati funzionino con . Se si sta creando un sistema dashboard personalizzato o usando un dashboard sviluppato da un'altra organizzazione, è necessario comprendere quali dati di strumentazione è necessario raccogliere, a quali livelli di granularità e come deve essere formattato per l'utilizzo del dashboard.
Un dashboard valido non visualizza solo le informazioni, ma consente anche a un analista di porre domande ad hoc su tali informazioni. Alcuni sistemi forniscono strumenti di gestione che un operatore può usare per eseguire queste attività ed esplorare i dati sottostanti. In alternativa, a seconda del repository usato per contenere queste informazioni, potrebbe essere possibile eseguire query direttamente su questi dati o importarli in strumenti come Microsoft Excel per ulteriori analisi e report.
Annotazioni
È consigliabile limitare l'accesso ai dashboard al personale autorizzato, perché queste informazioni potrebbero essere sensibili a livello commerciale. È anche consigliabile proteggere i dati sottostanti per i dashboard per impedire agli utenti di modificarli.
Generazione di avvisi
L'invio di avvisi è il processo di analisi dei dati di monitoraggio e strumentazione e della generazione di una notifica se viene rilevato un evento significativo.
L'invio di avvisi garantisce che il sistema rimanga integro, reattivo e sicuro. È una parte importante di qualsiasi sistema che garantisce prestazioni, disponibilità e privacy agli utenti in cui i dati potrebbero dover agire immediatamente. Un operatore potrebbe dover ricevere una notifica dell'evento che ha attivato l'avviso. Gli avvisi possono essere usati anche per richiamare funzioni di sistema, ad esempio la scalabilità automatica.
Gli avvisi dipendono in genere dai dati di strumentazione seguenti:
- Eventi di sicurezza. Se i registri eventi indicano che si verificano errori ripetuti di autenticazione o autorizzazione, il sistema potrebbe essere sotto attacco e un operatore deve essere informato.
- Metriche delle prestazioni. Il sistema deve rispondere rapidamente se una determinata metrica delle prestazioni supera una soglia specificata.
- Informazioni sulla disponibilità. Se viene rilevato un errore, potrebbe essere necessario riavviare rapidamente uno o più sottosistemi o eseguire il failover in una risorsa di backup. Gli errori ripetuti in un sottosistema potrebbero indicare problemi più gravi.
Gli operatori potrebbero ricevere informazioni sugli avvisi usando molti canali di recapito, ad esempio posta elettronica, un dispositivo cercapersone o sms. Un avviso può includere anche un'indicazione del livello di criticità di una situazione. Molti sistemi di avviso supportano i gruppi di sottoscrittori e tutti gli operatori membri dello stesso gruppo possono ricevere lo stesso set di avvisi.
Un sistema di avvisi deve essere personalizzabile e i valori appropriati dei dati di strumentazione sottostanti possono essere forniti come parametri. Questo approccio consente a un operatore di filtrare i dati e concentrarsi su tali soglie o combinazioni di valori di interesse. Si noti che in alcuni casi, i dati di strumentazione non elaborati possono essere forniti al sistema di avviso. In altre situazioni, potrebbe essere più appropriato fornire dati aggregati. Ad esempio, un avviso può essere attivato se l'utilizzo della CPU per un nodo ha superato il 90% negli ultimi 10 minuti. I dettagli forniti al sistema di avviso devono includere anche eventuali informazioni di riepilogo e contesto appropriate. Questi dati possono contribuire a ridurre la possibilità che gli eventi falsi positivi vengano inviati a un avviso.
Rendicontazione
Il reporting viene utilizzato per generare una visione complessiva del sistema. Può incorporare dati cronologici oltre alle informazioni correnti. I requisiti di creazione di report rientrano in due categorie generali: creazione di report operativi e report sulla sicurezza.
La creazione di report operativi include in genere gli aspetti seguenti:
- Statistiche di aggregazione utilizzabili per comprendere l'utilizzo delle risorse del sistema complessivo o di sottosistemi specificati durante un intervallo di tempo specificato.
- Identificazione delle tendenze nell'utilizzo delle risorse per l'intero sistema o per sottosistemi specifici durante un periodo specificato.
- Monitoraggio delle eccezioni che si sono verificate in tutto il sistema o nei sottosistemi specificati durante un periodo specificato.
- Determinare l'efficienza dell'applicazione in termini di risorse distribuite e capire se il volume di risorse (e il relativo costo associato) può essere ridotto senza influire inutilmente sulle prestazioni.
La creazione di report sulla sicurezza riguarda il monitoraggio dell'uso del sistema da parte dei clienti. Può includere:
- Controllo delle operazioni utente. Ciò richiede la registrazione delle singole richieste eseguite da ogni utente, insieme a date e ore. I dati devono essere strutturati per consentire a un amministratore di ricostruire rapidamente la sequenza di operazioni eseguite da un utente in un periodo specificato.
- Rilevamento dell'uso delle risorse da parte dell'utente. Ciò richiede la registrazione del modo in cui ogni richiesta per un utente accede alle varie risorse che compongono il sistema e per quanto tempo. Un amministratore deve essere in grado di usare questi dati per generare un report di utilizzo da parte dell'utente in un periodo specificato, possibilmente a scopo di fatturazione.
In molti casi, i processi batch possono generare report in base a una pianificazione definita. La latenza non è in genere un problema. Ma dovrebbero anche essere disponibili per la generazione su base ad hoc, se necessario. Ad esempio, se si archiviano dati in un database relazionale, ad esempio un database SQL di Azure, è possibile usare uno strumento come SQL Server Reporting Services per estrarre e formattare i dati e presentarli come set di report.
Passaggi successivi
- Panoramica di Monitoraggio di Azure
- Monitoraggio, diagnosi e risoluzione dei problemi del servizio di archiviazione di Microsoft Azure
- Panoramica degli avvisi in Microsoft Azure
- Visualizzare le notifiche sull'integrità del servizio tramite il portale di Azure
- Che cos'è Application Insights?
- Diagnostica delle prestazioni per le macchine virtuali di Azure
- Scaricare e installare SQL Server Data Tools (SSDT) per Visual Studio
" output is necessary.)
- Le linee guida per la scalabilità automatica descrivono come ridurre il sovraccarico di gestione riducendo la necessità di un operatore di monitorare continuamente le prestazioni di un sistema e prendere decisioni sull'aggiunta o la rimozione di risorse.
- Il modello di monitoraggio degli endpoint di integrità descrive come implementare controlli funzionali all'interno di un'applicazione a cui gli strumenti esterni possono accedere tramite endpoint esposti a intervalli regolari.
- Modello di coda con priorità mostra come classificare in ordine di priorità i messaggi in coda in modo che le richieste urgenti vengano ricevute e possano essere elaborate prima di messaggi meno urgenti.