Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Microsoft Fabric
Azure Data Factory
Le organizzazioni in genere devono raccogliere dati da più origini in diversi formati e spostarli in uno o più archivi dati. La destinazione potrebbe non essere lo stesso tipo di archivio dati dell'origine e spesso i dati devono essere modellati, puliti o trasformati prima del caricamento.
Vari strumenti, servizi e processi aiutano a risolvere queste sfide. Indipendentemente dall'approccio, è necessario coordinare il lavoro e applicare trasformazioni dei dati all'interno della pipeline di dati. Le sezioni seguenti illustrano i metodi e le procedure comuni per queste attività.
Processo di estrazione, trasformazione, caricamento (ETL)
Estrazione, trasformazione, caricamento (ETL) è un processo di integrazione dei dati che consolida i dati da origini diverse in un archivio dati unificato. Durante la fase di trasformazione, i dati sono modificati in base alle regole business usando un motore specializzato. Questo comporta spesso tabelle di staging che contengono temporaneamente i dati durante l'elaborazione e infine caricati nella destinazione.
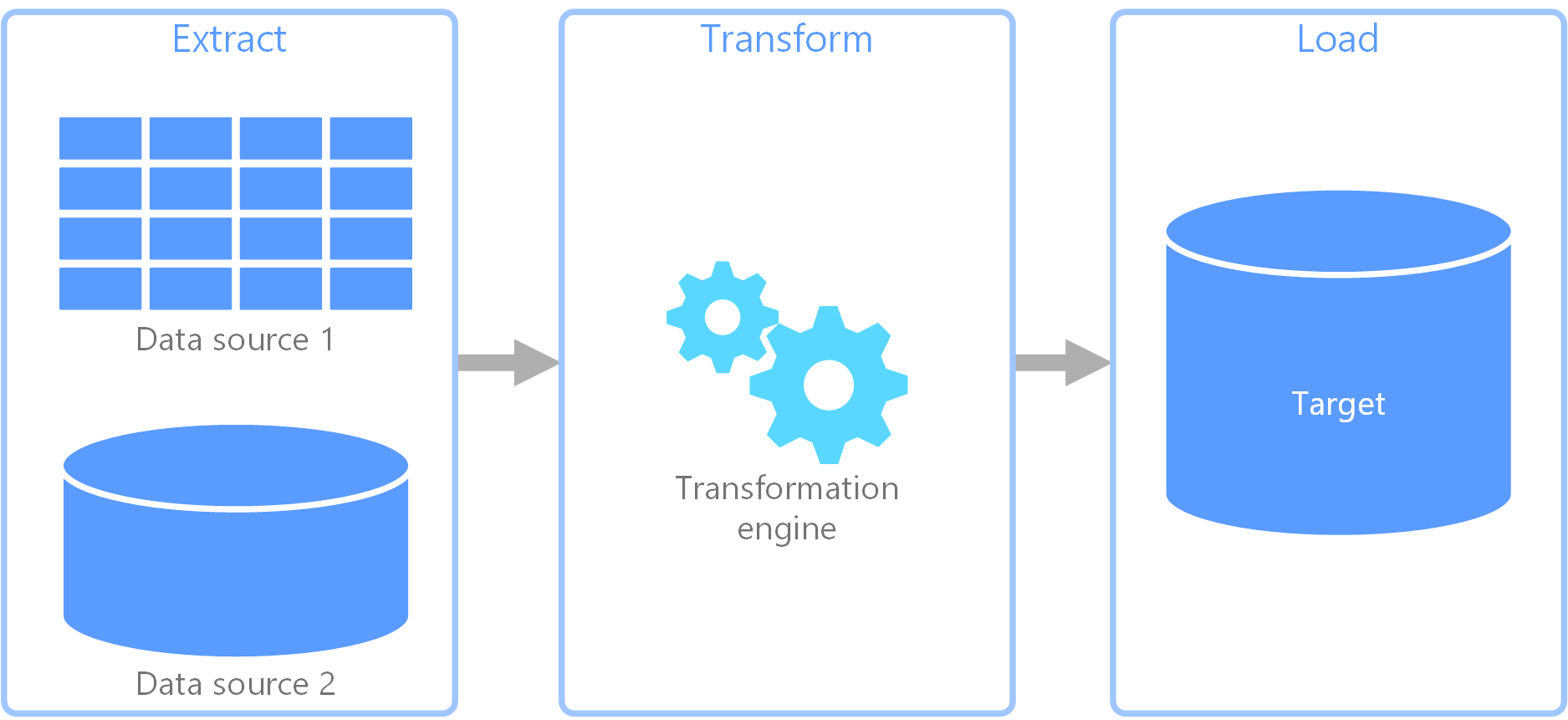
La trasformazione dei dati che solitamente si verifica include diverse operazioni, ad esempio il filtro, l'ordinamento, l'aggregazione, il join dei dati, la pulizia dei dati, la deduplicazione e la convalida dei dati.
Spesso, le tre fasi ETL vengono eseguite in parallelo per risparmiare tempo. Ad esempio, mentre i dati vengono estratti, un processo di trasformazione può funzionare sui dati già ricevuti e prepararli per il caricamento e un processo di caricamento può iniziare a lavorare sui dati preparati, anziché attendere il completamento dell'intero processo di estrazione. In genere si progetta la parallelizzazione intorno ai limiti della partizione dati (data, tenant, chiave di partizione) per evitare conflitti di scrittura e abilitare idempotenti tentativi.
Servizio pertinente:
Altri strumenti:
Estrazione, caricamento, trasformazione (ELT)
Estrazione, caricamento, trasformazione (ELT) differisce esclusivamente da ETL in cui viene eseguita la trasformazione. Nella pipeline ELT la trasformazione si verifica nell'archivio dati di destinazione. Per trasformare i dati, anziché usare un motore di trasformazione separato, vengono usate le funzionalità di elaborazione dell'archivio dati di destinazione. Rimuovendo il motore di trasformazione dalla pipeline, l'architettura risulta estremamente semplificata. Un altro vantaggio offerto da questo approccio è il ridimensionamento dell'archivio dati di destinazione, che determina anche un miglioramento delle prestazioni della pipeline ELT. Tuttavia, ELT funziona in modo ottimale solo quando il sistema di destinazione è abbastanza potente da trasformare i dati in modo efficiente.
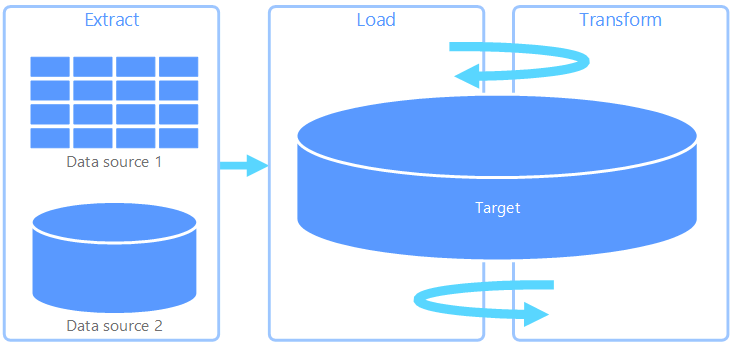
Casi d'uso tipici di ELT sono quelli che rientrano nell'ambito dei Big Data. Ad esempio, è possibile iniziare estraendo i dati di origine in file flat nell'archiviazione scalabile, ad esempio un file system hadoop distribuito (HDFS), un archivio BLOB di Azure o Azure Data Lake Storage Gen2. È quindi possibile usare tecnologie come Spark, Hive o PolyBase per eseguire query sui dati di origine. Il punto chiave di ELT è che l'archivio dati usato per eseguire la trasformazione è lo stesso in cui i dati vengono alla fine utilizzati. Questo archivio dati legge direttamente dalla risorsa di archiviazione scalabile, invece di caricare i dati in una risorsa di archiviazione separata. Questo approccio ignora i passaggi di copia dei dati presenti in ETL, che spesso possono richiedere molto tempo per set di dati di grandi dimensioni. Alcuni carichi di lavoro materializzano tabelle o viste trasformate per migliorare le prestazioni delle query o applicare regole di governance; ELT non implica sempre trasformazioni puramente virtualizzate.
La fase finale della pipeline ELT trasforma in genere i dati di origine in un formato più efficiente per i tipi di query che devono essere supportati. Ad esempio, i dati potrebbero essere partizionati da chiavi comunemente filtrate. ELT può anche usare formati di archiviazione ottimizzati come Parquet, che è un formato di archiviazione a colonne che organizza i dati per colonna per abilitare la compressione, il pushdown predicato e analisi analitiche efficienti.
Servizio Microsoft pertinente:
Scelta di ETL o ELT
La scelta tra questi approcci dipende dai requisiti.
Scegliere ETL quando:
- È necessario eseguire l'offload di trasformazioni pesanti da un sistema di destinazione vincolato
- Regole business complesse richiedono motori di trasformazione specializzati
- I requisiti normativi o di conformità impongono controlli di gestione temporanea curati prima del caricamento
Scegliere ELT quando:
- Il sistema di destinazione è un data warehouse moderno o lakehouse con scalabilità di calcolo elastico
- È necessario conservare i dati non elaborati per l'analisi esplorativa o l'evoluzione futura dello schema
- La logica di trasformazione trae vantaggio dalle funzionalità native del sistema di destinazione
Flusso di dati e flusso di controllo
Nell'ambito delle pipeline di dati, il flusso di controllo assicura l'elaborazione ordinata di un set di attività. Per applicare il corretto ordine di elaborazione di queste attività, vengono usati i vincoli di precedenza. È possibile considerare questi vincoli come connettori in un diagramma del flusso di lavoro, come illustrato nell'immagine seguente. Ogni attività fornisce un risultato, ad esempio operazione riuscita, operazione non riuscita o completamento. Qualsiasi attività successiva non avvia l'elaborazione fino al completamento del predecessore con uno di questi risultati.
I flussi di controllo eseguono i flussi di dati come un'attività. In un'attività Flusso di dati i dati vengono estratti da un'origine, trasformati o caricati in un archivio dati. L'output di un'attività Flusso di dati può costituire l'input per l'attività Flusso di dati successiva e i flussi di dati possono essere eseguiti in parallelo. A differenza dei flussi di controllo, non è possibile aggiungere vincoli tra le attività in un flusso di dati. Tuttavia, è possibile aggiungere un visualizzatore per osservare i dati che vengono elaborati da ogni attività.
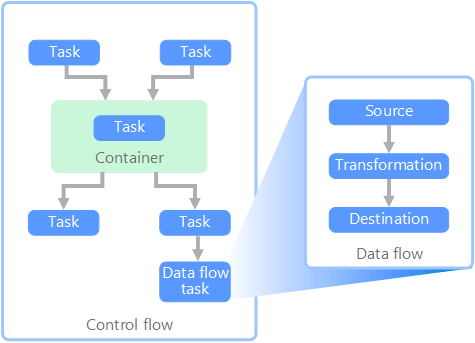
Nel diagramma sono presenti diverse attività all'interno del flusso di controllo, una delle quali è un'attività flusso di dati. Una delle attività è nidificata all'interno di un contenitore. È possibile usare i contenitori per fornire alle attività una struttura o un'unità di lavoro. Un esempio di questo tipo è costituito dagli elementi ripetitivi all'interno di una raccolta, ad esempio i file di una cartella o le istruzioni di un database.
Servizio pertinente:
ETL inverso
L'ETL inverso è il processo di spostamento di dati trasformati e modellati dai sistemi analitici in strumenti operativi e applicazioni. A differenza di ETL tradizionale, che scorre i dati dai sistemi operativi all'analisi, ETL inversa attiva informazioni dettagliate eseguendo il push dei dati curati in cui gli utenti aziendali possono agire su di esso. In una pipeline ETL inversa, i dati passano da data warehouse, lakehouse o altri archivi analitici a sistemi operativi, ad esempio:
- Piattaforme CRM (Customer Relationship Management)
- Strumenti di automazione del marketing
- Sistemi di supporto clienti
- Database del carico di lavoro
L'approccio segue comunque un processo di estrazione, trasformazione e caricamento. Il passaggio di trasformazione è il punto in cui si esegue la conversione dal formato specifico usato dal data warehouse o da un altro sistema di analisi per allinearsi al sistema di destinazione.
Per un esempio , vedere Estrazione inversa, trasformazione e caricamento (ETL) con Azure Cosmos DB per NoSQL .
Architetture dei dati di streaming e dei percorsi ad accesso frequente
Quando sono necessarie architetture Lambda hot path o Kappa, è possibile sottoscrivere le origini dati man mano che vengono generati i dati. A differenza di ETL o ELT, che opera su set di dati in batch pianificati, lo streaming in tempo reale elabora i dati man mano che arriva, abilitando informazioni dettagliate e azioni immediate.
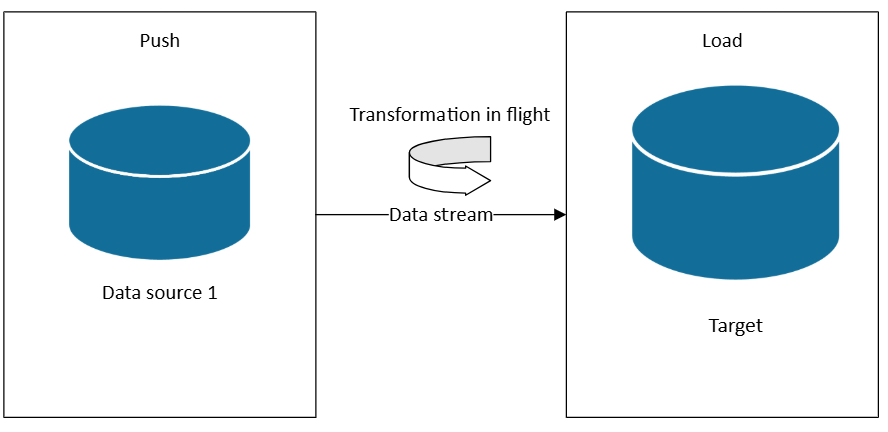
In un'architettura di streaming, i dati vengono inseriti da origini eventi in un broker di messaggi o in un hub eventi (ad esempio Hub eventi di Azure o Kafka), quindi elaborati da un processore di flusso (ad esempio Fabric Real-Time Intelligence, Analisi di flusso di Azure o Apache Flink). Il processore applica trasformazioni come il filtro, l'aggregazione, l'arricchimento o l'unione con i dati di riferimento, tutti in movimento, prima di instradare i risultati a sistemi downstream come dashboard, avvisi o database.
Questo approccio è ideale per scenari in cui la bassa latenza e aggiornamenti continui sono critici, ad esempio:
- Monitoraggio delle apparecchiature di produzione per le anomalie
- Rilevamento di frodi nelle transazioni finanziarie
- Potenza dei dashboard in tempo reale per la logistica o le operazioni
- Attivazione di avvisi in base alle soglie del sensore
Considerazioni sull'affidabilità per lo streaming
- Usare il checkpoint per garantire l'elaborazione at-least-once e il ripristino da errori
- Progettare trasformazioni da idempotente per gestire potenziali elaborazioni duplicate
- Implementare la filigrana per gli eventi in arrivo in ritardo e l'elaborazione out-of-order
- Usare code di messaggi non recapitabili per i messaggi che non possono essere elaborati
Scelte di tecnologia
Archivi dati:
Pipeline e orchestrazione:
- Orchestrazione di pipeline
- Microsoft Fabric Data Factory (orchestrazione moderna)
- Azure Data Factory (scenari ibridi e non di infrastruttura)
Lakehouse e analisi moderna: