Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Archiviazione BLOB di Azure
Coordinare le azioni eseguite da una raccolta di istanze di collaborazione in un'applicazione distribuita scegliendo un'istanza come leader che assume la responsabilità di gestire gli altri. Ciò può contribuire a garantire che le istanze non siano in conflitto tra loro, causare conflitti per le risorse condivise o interferire inavvertitamente con il lavoro eseguito da altre istanze.
Contesto e problema
Un'applicazione cloud tipica ha molte attività che agiscono in modo coordinato. Queste attività possono essere tutte istanze che eseguono lo stesso codice e richiedono l'accesso alle stesse risorse oppure potrebbero collaborare in parallelo per eseguire le singole parti di un calcolo complesso.
Le istanze dell'attività possono essere eseguite separatamente per gran parte del tempo, ma potrebbe anche essere necessario coordinare le azioni di ogni istanza per assicurarsi che non siano in conflitto, causare conflitti per le risorse condivise o interferire accidentalmente con il lavoro eseguito da altre istanze di attività.
Per esempio:
- In un sistema basato sul cloud che implementa il ridimensionamento orizzontale, più istanze della stessa attività potrebbero essere in esecuzione contemporaneamente con ogni istanza che serve un utente diverso. Se queste istanze scrivono in una risorsa condivisa, è necessario coordinare le azioni per impedire a ogni istanza di sovrascrivere le modifiche apportate dagli altri.
- Se le attività eseguono singoli elementi di un calcolo complesso in parallelo, i risultati devono essere aggregati al termine di tutte le attività.
Le istanze del compito sono tutte pari, quindi non esiste un leader naturale che possa fungere da coordinatore o aggregatore.
Soluzione
Una singola istanza di attività deve essere selezionata per fungere da leader e questa istanza deve coordinare le azioni delle altre istanze di attività subordinate. Se tutte le istanze dell'attività eseguono lo stesso codice, ognuna può fungere da leader. Pertanto, il processo elettorale deve essere gestito attentamente per evitare che due o più istanze assumessero la posizione di leader contemporaneamente.
Il sistema deve fornire un meccanismo affidabile per la selezione del leader. Questo metodo deve gestire eventi come interruzioni di rete o errori di processo. In molte soluzioni, le istanze di attività subordinate monitorano il leader tramite un tipo di metodo di heartbeat o attraverso il polling. Se il leader designato termina in modo imprevisto o un errore di rete rende il leader non disponibile per le istanze di attività subordinate, è necessario che elezionino un nuovo leader.
Esistono più strategie per scegliere un leader tra un set di attività in un ambiente distribuito, tra cui:
- Corsa per acquisire un mutex distribuito e condiviso. La prima istanza dell'attività che acquisisce il mutex è il leader. Tuttavia, il sistema deve assicurarsi che, se il leader termina o viene disconnesso dal resto del sistema, il mutex viene rilasciato per consentire a un'altra istanza dell'attività di diventare leader. Questa strategia è illustrata nell'esempio seguente.
- Implementazione di uno degli algoritmi di elezione leader comuni, ad esempio l'algoritmo Bully, l'algoritmo Raft Consensus o Chang e Roberts. Questi algoritmi presuppongono che ogni candidato nelle elezioni abbia un ID univoco e che possa comunicare con gli altri candidati in modo affidabile.
Problemi e considerazioni
Quando si decide come implementare questo modello, tenere presente quanto segue:
- Il processo di selezione di un leader deve essere resiliente agli errori temporanei e persistenti.
- Deve essere possibile rilevare quando il leader non è riuscito o non è più disponibile, ad esempio a causa di un errore di comunicazione. La velocità di rilevamento necessaria dipende dal sistema. Alcuni sistemi potrebbero essere in grado di funzionare per un breve periodo di tempo senza un leader, durante il quale potrebbe essere corretto un errore temporaneo. In altri casi, potrebbe essere necessario rilevare immediatamente il fallimento del leader e attivare una nuova elezione.
- In un sistema che implementa la scalabilità automatica orizzontale, il leader potrebbe essere terminato se il sistema ridimensiona e arresta alcune delle risorse di calcolo.
- L'uso di un mutex distribuito condiviso introduce una dipendenza dal servizio esterno che fornisce il mutex. Il servizio costituisce un punto singolo di guasto. Se non è più disponibile per qualsiasi motivo, il sistema non sarà in grado di eleggere un leader.
- Utilizzare un singolo processo dedicato come leader è un approccio semplice. Tuttavia, se il processo non riesce potrebbe verificarsi un ritardo significativo durante il riavvio. La latenza risultante può influire sulle prestazioni e sui tempi di risposta di altri processi se sono in attesa del leader per coordinare un'operazione.
- L'implementazione manuale di uno degli algoritmi di elezione leader offre la massima flessibilità per la sintonizzazione e l'ottimizzazione del codice.
- Evitate di trasformare il leader in un collo di bottiglia nel sistema. Lo scopo del leader è coordinare il lavoro delle attività subordinate e non è necessariamente tenuto a prendere parte a questo lavoro, anche se dovrebbe essere in grado di farlo se il compito non viene scelto come leader.
Quando usare questo modello
Usare questo modello quando le attività in un'applicazione distribuita, ad esempio una soluzione ospitata nel cloud, richiedono un'attenta coordinamento e non esiste un leader naturale.
Questo modello potrebbe non essere utile se:
- C'è un leader naturale o un processo dedicato che può sempre fungere da leader. Ad esempio, potrebbe essere possibile implementare un processo singleton che coordina le istanze dell'attività. Se questo processo ha esito negativo o diventa non integro, il sistema può arrestarlo e riavviarlo.
- Il coordinamento tra le attività può essere ottenuto usando un metodo più leggero. Ad esempio, se più istanze di attività richiedono semplicemente l'accesso coordinato a una risorsa condivisa, una soluzione migliore consiste nell'usare il blocco ottimistico o pessimistico per controllare l'accesso.
- Una soluzione di terze parti, ad esempio Apache Zookeeper , potrebbe essere una soluzione più efficiente.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello di Elezione del Leader può essere usato nella progettazione del workload per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Per esempio:
| Pilastro | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| Le decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resilienti a malfunzionamenti e di assicurarsi che venga ripristinato in uno stato completamente funzionante dopo che si verifica un errore. | Questo modello riduce l'effetto di malfunzionamenti del nodo reindirizzando in modo affidabile il lavoro. Implementa anche il failover tramite algoritmi di consenso quando un leader non funziona correttamente. - Ridondanza RE:05 - RE:07 Autoriparazione |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Esempio
L'esempio relativo alle elezioni leader in GitHub illustra come usare un lease in un BLOB di Archiviazione di Azure per fornire un meccanismo per implementare un mutex condiviso e distribuito. Questo mutex può essere usato per scegliere un leader tra un gruppo di istanze di lavoro disponibili. La prima istanza che acquisisce il lease viene eletta leader e rimane leader fino a quando non rilascia il lease o non è in grado di rinnovare il lease. Altre istanze del ruolo di lavoro possono continuare a monitorare il lease del blob qualora il leader non sia più disponibile.
Un lease di blob è un blocco di scrittura esclusivo su un blob. Un singolo BLOB può essere oggetto di un solo lease in qualsiasi momento. Un'istanza del ruolo di lavoro può richiedere un lease su un BLOB specificato e verrà concesso il lease se nessun'altra istanza del ruolo di lavoro contiene un lease sullo stesso BLOB. In caso contrario, la richiesta genererà un'eccezione.
Per evitare che un'istanza leader guasta mantenga la concessione per un periodo illimitato, specificare una durata per la concessione. Alla scadenza, il lease diventa disponibile. Tuttavia, mentre un'istanza detiene il contratto di locazione, può richiedere che il contratto di locazione venga rinnovato, e che venga concesso per un ulteriore periodo di tempo. L'istanza leader può ripetere continuamente questo processo se vuole conservare il lease. Per altre informazioni su come eseguire il lease di un BLOB, vedere Lease Blob (API REST).
La classe BlobDistributedMutex nell'esempio C# seguente contiene il metodo RunTaskWhenMutexAcquired che consente a un'istanza di worker di tentare di ottenere un lease su un blob specificato. I dettagli del BLOB (il nome, il contenitore e l'account di archiviazione) vengono passati al costruttore in un BlobSettings oggetto quando viene creato l'oggetto BlobDistributedMutex (questo oggetto è uno struct semplice incluso nel codice di esempio). Il costruttore accetta anche un Task che fa riferimento al codice che l'istanza del worker deve eseguire se acquisisce correttamente il lease sul blob e viene eletta leader. Il codice che gestisce i dettagli di basso livello dell'acquisizione del lease viene implementato in una classe helper separata denominata BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
Il RunTaskWhenMutexAcquired metodo nell'esempio di codice precedente richiama il RunTaskWhenBlobLeaseAcquired metodo illustrato nell'esempio di codice seguente per acquisire effettivamente il lease. Il RunTaskWhenBlobLeaseAcquired metodo viene eseguito in modo asincrono. Se il lease viene acquisito correttamente, l'istanza di lavoro è stata eletta leader. Lo scopo del taskToRunWhenLeaseAcquired delegato è eseguire il lavoro che coordina le altre istanze di lavoro. Se la locazione non viene acquisita, un'altra istanza di lavoro è stata selezionata come leader e quindi l'istanza di lavoro corrente rimane subordinata. Si noti che il metodo TryAcquireLeaseOrWait è un metodo di supporto che utilizza l'oggetto BlobLeaseManager per acquisire la locazione.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
Anche l'attività avviata dal leader viene eseguita in modo asincrono. Durante l'esecuzione di questa attività, il RunTaskWhenBlobLeaseAcquired metodo illustrato nell'esempio di codice seguente tenta periodicamente di rinnovare il lease. Ciò consente di garantire che l'istanza del lavoratore rimanga il leader. Nella soluzione di esempio, il ritardo tra le richieste di rinnovo è inferiore al tempo specificato per la durata del lease, in modo da impedire che un'altra istanza di lavoro venga selezionata come leader. Se il rinnovo non riesce per qualsiasi motivo, l'attività specifica del leader viene annullata.
Se il lease non viene rinnovato o l'attività viene annullata (probabilmente a causa dell'arresto dell'istanza del ruolo di lavoro), il lease viene rilasciato. A questo punto, questa o un'altra istanza di lavoro può essere eletta come leader. L'estratto di codice seguente illustra questa parte del processo.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
Il KeepRenewingLease metodo è un altro metodo helper che usa l'oggetto BlobLeaseManager per rinnovare il lease. Il CancelAllWhenAnyCompletes metodo annulla le attività specificate come primi due parametri. Il diagramma seguente illustra l'uso della BlobDistributedMutex classe per scegliere un leader ed eseguire un'attività che coordina le operazioni.
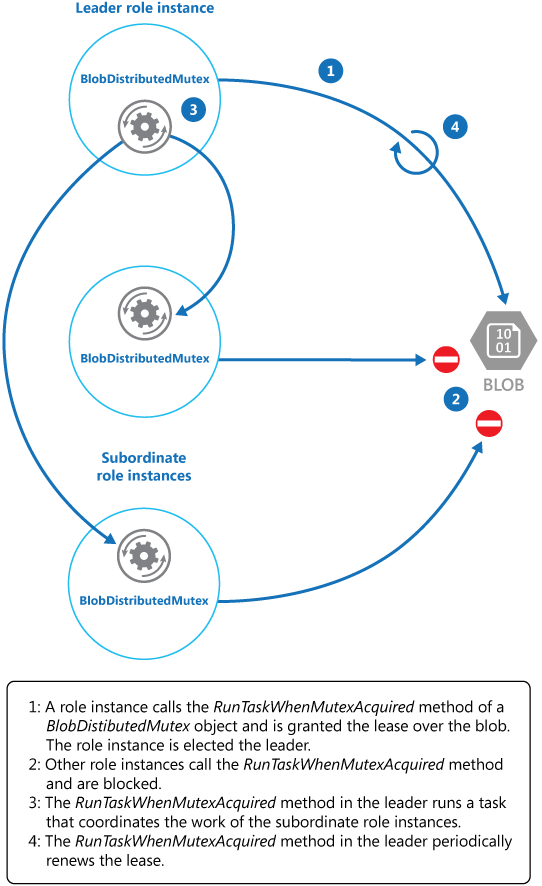
Nell'esempio di codice seguente viene illustrato come usare la classe BlobDistributedMutex all'interno di un'istanza di un worker. Questo codice acquisisce un lease su un blob denominato MyLeaderCoordinatorTask nel contenitore del lease in Azure Blob Storage e specifica che il codice definito nel metodo MyLeaderCoordinatorTask deve essere eseguito se l'istanza del worker è selezionata come leader.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Si notino i punti seguenti relativi alla soluzione di esempio:
- Il blob è un potenziale punto singolo di guasto. Se il servizio BLOB non è più disponibile o non è accessibile, il responsabile non sarà in grado di rinnovare il lease e nessun'altra istanza del ruolo di lavoro sarà in grado di acquisire il lease. In questo caso, nessuna istanza del ruolo di lavoro sarà in grado di fungere da leader. Tuttavia, il servizio BLOB è progettato per essere resiliente, quindi l'errore completo del servizio BLOB è considerato estremamente improbabile.
- Se l'attività eseguita dal leader si blocca, il leader potrebbe continuare a rinnovare il leasing, impedendo a qualsiasi altra istanza di lavoro di acquisire il leasing e assumere la posizione di leader per coordinare le attività. Nel mondo reale, la salute del leader deve essere controllata a intervalli frequenti.
- Il processo elettorale non è deterministico. Non è possibile fare ipotesi su quale istanza di lavoratore acquisirà un lease del blob e diventerà leader.
- Il BLOB destinato al contratto di lease di BLOB non deve essere utilizzato per altri scopi. Se un'istanza del ruolo di lavoro tenta di archiviare i dati in questo blob, questi dati non saranno accessibili a meno che l'istanza del ruolo di lavoro non sia leader e possieda il lease del blob.
Passaggi successivi
Quando si implementa questo modello, possono essere rilevanti anche le indicazioni seguenti:
- Questo modello include un'applicazione di esempio scaricabile.
- Linee guida per la scalabilità automatica. È possibile avviare e arrestare le istanze degli host di attività al variare del carico dell'applicazione. La scalabilità automatica consente di mantenere la velocità effettiva e le prestazioni durante i periodi di picco di elaborazione.
- Modello asincrono basato su attività.
- Apache Curatore una libreria client per Apache ZooKeeper.
- L'articolo Lease BLOB (API REST) su MSDN.