Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Azure
È possibile abilitare un'applicazione per gestire gli errori temporanei durante il tentativo di connessione a un servizio o a una risorsa di rete ritentando in modo trasparente un'operazione non riuscita. Ciò può migliorare la stabilità dell'applicazione.
Contesto e problema
Un'applicazione che comunica con gli elementi in esecuzione nel cloud deve essere sensibile agli errori temporanei che possono verificarsi in questo ambiente. Gli errori includono la perdita momentanea della connettività di rete a componenti e servizi, l'indisponibilità temporanea di un servizio o i timeout che si verificano quando un servizio è occupato.
Questi errori si risolvono di solito automaticamente e, se l'azione che ha generato l'errore viene ripetuta dopo un intervallo di tempo appropriato, è probabile che abbia esito positivo. Ad esempio, un servizio di database che elabora un numero elevato di richieste simultanee può implementare una strategia di limitazione che rifiuta temporaneamente eventuali altre richieste fino a quando il carico di lavoro non è stato facilitato. Un'applicazione che tenta di accedere al database in questa situazione potrebbe non riuscire a connettersi, ma un tentativo successivo potrebbe invece avere esito positivo.
Soluzione
Nel cloud è necessario prevedere errori temporanei e un'applicazione deve essere progettata per gestirli in modo elegante e trasparente. In questo modo si riducono al minimo gli errori che possono verificarsi nelle attività aziendali eseguite dall'applicazione. Il modello di progettazione più comune da affrontare consiste nell'introdurre un meccanismo di ripetizione dei tentativi.
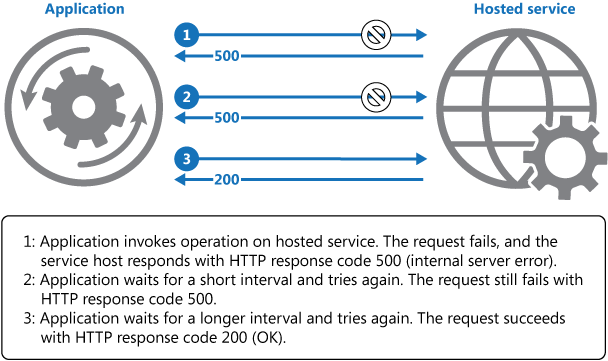
Il diagramma precedente illustra la chiamata di un'operazione in un servizio ospitato usando un meccanismo di ripetizione dei tentativi. Se la richiesta ha esito negativo dopo un numero predefinito di tentativi, l'applicazione deve considerare l'errore come un'eccezione e gestirlo di conseguenza.
Nota
A causa della natura comune degli errori temporanei, i meccanismi di ripetizione dei tentativi predefiniti sono ora disponibili in molte librerie client e servizi cloud, con un certo grado di configurabilità per il numero massimo di tentativi, il ritardo tra i tentativi e altri parametri. Ad esempio, Entity Framework Core offre funzionalità per riprovare operazioni di database fallite.
Strategie di ripetizione dei tentativi
Se un'applicazione rileva un errore durante il tentativo di inviare una richiesta a un servizio remoto, può adottare le strategie seguenti per gestire l'errore:
Annullare. Se l'errore indica che non si tratta di un problema temporaneo o che è improbabile che l'operazione abbia esito positivo se ripetuta, l'applicazione deve annullare l'operazione e segnalare un'eccezione.
Riprovare immediatamente. Se l'errore specifico segnalato è insolito o raro, ad esempio un pacchetto di rete danneggiato durante la trasmissione, il miglior corso di azione potrebbe essere quello di ritentare immediatamente la richiesta.
Riprovare dopo un certo intervallo di tempo. Se l'errore è causato da uno dei più comuni problemi di connettività o congestione, la rete o il servizio potrebbe richiedere un breve lasso di tempo per correggere i problemi di connettività o smaltire l'arretrato di lavoro. Pertanto, ritardare il tentativo in modo programmato è una buona strategia. In molti casi, il periodo tra i tentativi deve essere scelto per distribuire le richieste da più istanze dell'applicazione il più uniformemente possibile per ridurre la probabilità che un servizio occupato continui a essere sovraccaricato.
Se la richiesta continua a non riuscire, l'applicazione può attendere ed eseguire un altro tentativo. Se necessario, questo processo può essere ripetuto con ritardi crescenti tra i tentativi, fino a quando non viene tentato un numero massimo di richieste. Il ritardo può essere aumentato in modo incrementale o esponenziale, a seconda del tipo di errore e delle probabilità che venga risolto durante questo periodo.
L'applicazione deve eseguire il wrapping di tutti i tentativi di accesso a un servizio remoto nel codice che implementa un criterio di ripetizione corrispondente a una delle strategie elencate sopra. Le richieste inviate a servizi diversi possono essere soggette a criteri diversi.
Un'applicazione deve registrare i dettagli degli errori e delle operazioni non riuscite. Queste informazioni sono utili per gli operatori. Detto questo, per evitare l'inondazione degli operatori con avvisi sulle operazioni in cui i tentativi successivi hanno avuto esito positivo, è consigliabile registrare errori iniziali come voci informative e solo l'errore dell'ultimo tentativo di ripetizione come errore effettivo. Ecco un esempio di come potrebbe apparire questo modello di registrazione.
Se un servizio è spesso non disponibile o occupato, spesso è perché il servizio ha esaurito le risorse. È possibile ridurre la frequenza di questi errori ridimensionando il servizio. Ad esempio, se un servizio di database è continuamente sovraccarico, potrebbe essere utile partizionare il database e distribuire il carico tra più server.
Considerazioni e problemi
Prima di decidere come implementare questo modello, è opportuno considerare quanto segue.
Impatto sulle prestazioni
I criteri di ripetizione dei tentativi devono essere adattati ai requisiti aziendali dell'applicazione e alla natura dell'errore. Per alcune operazioni non critiche, è preferibile eseguire un errore rapido anziché riprovare più volte e influire sulla velocità effettiva dell'applicazione. Ad esempio, in un'applicazione Web interattiva che accede a un servizio remoto, è preferibile non riuscire dopo un numero minore di tentativi con un breve ritardo tra i tentativi e visualizzare un messaggio appropriato all'utente, ad esempio "riprova più tardi". Per un'applicazione che esegue operazioni in batch, potrebbe essere invece più appropriato aumentare il numero di tentativi con un ritardo esponenzialmente maggiore tra i vari tentativi.
Una politica di ripetizione aggressiva con un ritardo minimo tra i tentativi e un numero elevato di tentativi potrebbe ulteriormente degradare un servizio che è già vicino o al massimo della capacità. Questo tipo di criteri di ripetizione possono influire anche sulla velocità di risposta dell'applicazione, se tenta continuamente di eseguire un'operazione che non riesce.
Se una richiesta ha ancora esito negativo dopo un numero significativo di tentativi, è preferibile che l'applicazione eviti ulteriori richieste verso la stessa risorsa e segnali immediatamente un errore. Al termine del periodo, l'applicazione può consentire provvisoriamente a una o più richieste di passare per vedere se hanno successo. Per ulteriori informazioni su questa strategia, vedere il pattern Circuit Breaker.
Idempotenza
Valutare se l'operazione è idempotente. In caso affermativo, la ripetizione dei tentativi è intrinsecamente sicura. Altrimenti, i tentativi di ritentare potrebbero far eseguire l'operazione più di una volta, con effetti collaterali imprevisti. Ad esempio, un servizio potrebbe ricevere la richiesta ed elaborarla correttamente, ma non riuscire invece a inviare una risposta. A questo punto, la logica di ripetizione dei tentativi potrebbe inviare nuovamente la richiesta, partendo dal presupposto che la prima richiesta non sia stata ricevuta.
Tipo di eccezione
Una richiesta a un servizio può non riuscire per diversi motivi che generano eccezioni diverse a seconda della natura dell'errore. Alcune eccezioni indicano un errore che può essere risolto rapidamente, mentre altre indicano errori di più lunga durata. È utile che i criteri per la ripetizione dei tentativi adattino l'intervallo di tempo tra i tentativi in base al tipo dell'eccezione.
Coerenza delle transazioni
Valutare gli effetti della ripetizione di un'operazione che fa parte di una transazione sulla coerenza complessiva delle transazioni. Mettere a punto i criteri di ripetizione dei tentativi per le operazioni transazionali per ottenere la massima probabilità di successo e ridurre la necessità di annullare tutti i passaggi della transazione.
Indicazioni generali
Assicurarsi che tutto il codice di ripetizione dei tentativi venga testato completamente in base a varie condizioni di errore. Verificare che non influisca gravemente sulle prestazioni o affidabilità dell'applicazione, causi un carico eccessivo su servizi e risorse, o generi condizioni di gara o bottleneck.
Implementare la logica di ripetizione dei tentativi solo nei casi in cui è noto il contesto completo di un'operazione con esito negativo. Ad esempio, se un'attività che contiene criteri di ripetizione richiama un'altra attività che contiene a sua volta criteri di ripetizione, questo livello aggiuntivo di tentativi può introdurre lunghi ritardi per l'elaborazione. Potrebbe essere più appropriato configurare l'attività di livello più basso in modo che fallisca rapidamente e segnali il motivo del fallimento all'attività che l'ha richiamata. Questa attività di livello superiore può quindi gestire l'errore in base ai propri criteri.
Registrare tutti gli errori di connettività che causano un nuovo tentativo in modo che sia possibile identificare i problemi sottostanti con l'applicazione, i servizi o le risorse.
Esaminare gli errori che è più probabile che si verifichino per un servizio o una risorsa per stabilire se è probabile che siano durevoli o terminali. In questo caso, è preferibile gestire l'errore come un'eccezione. L'applicazione può segnalare o registrare l'eccezione e quindi tentare di continuare richiamando un servizio alternativo (se disponibile) o offrendo funzionalità ridotte. Per altre informazioni su come rilevare e gestire gli errori di lunga durata, vedere il Circuit Breaker pattern.
Quando usare questo modello
Usare questo modello quando un'applicazione può subire errori temporanei quando interagisce con un servizio remoto o accede a una risorsa remota. Questi errori sono prevedibilmente di breve durata e la ripetizione di una richiesta non riuscita in precedenza potrebbe avere esito positivo durante un tentativo successivo.
Questo modello potrebbe non essere utile:
- Quando è probabile che un errore sia di lunga durata, in quanto questo può influire sulla velocità di risposta di un'applicazione. L'applicazione potrebbe sprecare tempo e risorse nel tentativo di ripetere una richiesta che probabilmente non riuscirà.
- Per la gestione degli errori che non sono dovuti a problematiche temporanee, ad esempio le eccezioni interne causate da errori nella logica di business di un'applicazione.
- Come alternativa alla risoluzione dei problemi di scalabilità in un sistema. Se un'applicazione riscontra errori frequenti per condizioni di occupato, questo spesso è segno della necessità di potenziare il servizio o la risorsa a cui si accede.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello di ripetizione dei tentativi può essere usato nella progettazione del carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Ad esempio:
| Pilastro | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| Le decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resilienti a malfunzionamenti e di assicurarsi che venga ripristinato in uno stato completamente funzionante dopo che si verifica un errore. | La mitigazione degli errori temporanei in un sistema distribuito è una tecnica di base per migliorare la resilienza di un carico di lavoro. - RE:07 Autoconservazione - RE:07 Errori temporanei |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Esempio
Per un esempio dettagliato dell'uso di Azure SDK con il meccanismo di ripetizione dei tentativi predefinito, vedere la guida Implementare un criterio di ripetizione dei tentativi con .NET .
Passaggi successivi
Prima di scrivere logica di ripetizione dei tentativi personalizzata, provare a usare un framework generale, ad esempio Polly per .NET o Resilience4j per Java.
Quando si elaborano comandi che modificano i dati aziendali, è importante considerare che i tentativi di ripetizione possono portare all'esecuzione dell'azione due volte, il che potrebbe risultare problematico se tale azione comporta l'addebito sulla carta di credito di un cliente. L'uso del modello di Idempotenza descritto in questo post di blog può aiutare a gestire queste situazioni.
Risorse correlate
Per la maggior parte dei servizi di Azure, gli SDK client includono la logica di ripetizione dei tentativi predefinita.
Schema Circuit Breaker. Se si prevede che un errore sia più duraturo, potrebbe risultare più appropriato implementare il pattern Circuit Breaker. La combinazione dei modelli Retry e Circuit Breaker rappresenta un metodo completo per la gestione degli errori.