Questa architettura di riferimento illustra un'architettura senza server e basata su eventi, che inserisce un flusso di dati, li elabora e scrive i risultati in un database back-end.
Architettura
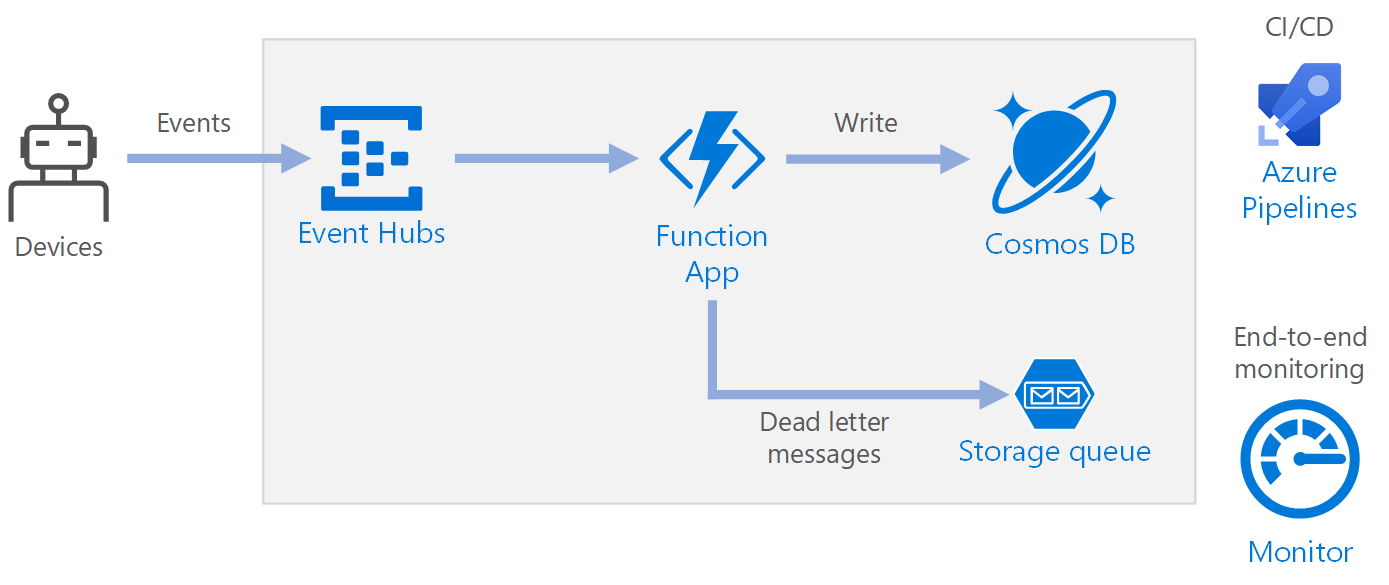
Workflow
- Gli eventi arrivano alle Hub eventi di Azure.
- Un'app per le funzioni viene attivata per gestire l'evento.
- L'evento viene archiviato in un database di Azure Cosmos DB.
- Se l'app per le funzioni non archivia correttamente l'evento, l'evento viene salvato in una coda di archiviazione da elaborare in un secondo momento.
Componenti
Hub eventi inserisce il flusso di dati. Hub eventi è progettato per scenari di flusso di dati con velocità effettiva elevata.
Nota
Per gli scenari IoT (Internet delle cose), è consigliabile hub IoT di Azure. hub IoT ha un endpoint predefinito compatibile con l'API Hub eventi di Azure, quindi è possibile usare entrambi i servizi in questa architettura senza modifiche importanti nell'elaborazione back-end. Per informazioni, vedere Connessione di dispositivi IoT ad Azure: hub IoT e hub eventi.
App per le funzioni. Funzioni di Azure è un'opzione di calcolo senza server. Usa un modello basato su eventi, in cui una parte di codice (una funzione) viene richiamata da un trigger. In questa architettura, quando gli eventi arrivano a Hub eventi, attivano una funzione che elabora gli eventi e scrive i risultati nell'archiviazione.
Le app per le funzioni sono adatte per l'elaborazione di singoli record da Hub eventi. Per scenari di elaborazione di flussi più complessi, prendere in considerazione Apache Spark usando Azure Databricks o Analisi di flusso di Azure.
Azure Cosmos DB. Azure Cosmos DB è un servizio di database multimodelli disponibile in modalità serverless basata sul consumo. Per questo scenario, la funzione di elaborazione eventi archivia i record JSON usando Azure Cosmos DB per NoSQL.
Archiviazione code. L'archiviazione code viene usata per i messaggi non recapitabili. Se si verifica un errore durante l'elaborazione di un evento, la funzione archivia i dati dell'evento in una coda di messaggi non recapitabili per un'elaborazione successiva. Per altre informazioni, vedere la sezione Resilienza più avanti in questo articolo.
Monitoraggio di Azure. Monitoraggio raccoglie le metriche relative alle prestazioni dei servizi di Azure distribuiti nella soluzione. La visualizzazione delle metriche in una dashboard consente di ottenere visibilità sull'integrità della soluzione.
Azure Pipelines. Pipelines è un servizio di integrazione continua, ovvero CI, e recapito continuo, ovvero CD, che compila, verifica e distribuisce l'applicazione.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Disponibilità
La distribuzione illustrata di seguito si trova in una sola area di Azure. Per un approccio più resiliente al ripristino di emergenza, sfruttare le funzionalità di distribuzione a livello geografico nei vari servizi:
- Hub eventi. Creare due spazi dei nomi di Hub eventi, uno spazio dei nomi primario (attivo) e un spazio dei nomi secondario (passivo). I messaggi vengono indirizzati automaticamente allo spazio dei nomi attivo a meno che non si esegua il failover nello spazio dei nomi secondario. Per altre informazioni, vedere Ripristino di emergenza geografico nel servizio Hub eventi di Azure.
- App per le funzioni. Distribuire una seconda app per le funzioni che è in attesa di leggere lo spazio dei nomi secondario di Hub eventi. Questa funzione scrive in un account di archiviazione secondario per una coda di messaggi non recapitabili.
- Azure Cosmos DB. Azure Cosmos DB supporta più aree di scrittura, che consentono di scrivere in qualsiasi area aggiunta all'account Azure Cosmos DB. Se non si abilita la scrittura multipla, è comunque possibile eseguire il failover dell'area di scrittura primaria. Gli SDK client di Azure Cosmos DB e le associazioni di funzioni di Azure gestiscono automaticamente il failover, quindi non è necessario aggiornare le impostazioni di configurazione dell'applicazione.
- Archiviazione di Azure. Usare l'archiviazione con ridondanza geografica e accesso in lettura per la coda di messaggi non recapitabili. Verrà creata una replica di sola lettura in un'altra area. Se l'area primaria diventa non disponibile, è possibile leggere gli elementi attualmente presenti nella coda. In aggiunta eseguire il provisioning di un altro account di archiviazione nella regione secondaria in cui la funzione può scrivere dopo un failover.
Scalabilità
Hub eventi
La capacità di elaborazione di Hub eventi viene misurata in unità elaborate. È possibile ridimensionare automaticamente un hub eventi abilitando l'aumento automatico, che ridimensiona automaticamente le unità elaborate in base al traffico, fino a un limite massimo configurato.
Il trigger di Hub eventi nell'app per le funzioni viene ridimensionato in base al numero di partizioni nell'hub eventi. A ogni partizione viene assegnata un'istanza di funzione alla volta. Per ottimizzare la velocità effettiva, ricevere gli eventi in batch, anziché uno alla volta.
Azure Cosmos DB
Azure Cosmos DB è disponibile in due diverse modalità di capacità:
- Serverless, per i carichi di lavoro con traffico intermittente o imprevedibile e un basso rapporto di traffico medio-picco.
- Velocità effettiva con provisioning, per carichi di lavoro con traffico prolungato che richiede prestazioni prevedibili.
Per assicurarsi che il carico di lavoro sia scalabile, è importante scegliere una chiave di partizione appropriata quando si creano i contenitori di Azure Cosmos DB. Ecco alcune caratteristiche di una chiave di partizione efficace:
- Lo spazio dei valori della chiave è grande.
- Si verificherà una distribuzione uniforme delle operazioni di lettura/scrittura per ogni valore della chiave, evitando le chiavi usate di frequente.
- I dati massimi archiviati per qualsiasi valore di chiave singola non supereranno le dimensioni massime della partizione fisica (20 GB).
- La chiave di partizione per un documento non cambierà. Non è possibile aggiornare la chiave di partizione su un documento esistente.
Nello scenario per questa architettura di riferimento la funzione archivia esattamente un documento per ogni dispositivo che invia dati. La funzione aggiorna continuamente i documenti con lo stato più recente del dispositivo usando un'operazione upsert. L'ID dispositivo è una chiave di partizione valida per questo scenario perché le scritture verranno distribuite uniformemente tra le chiavi e le dimensioni di ogni partizione verranno vincolate rigorosamente perché è presente un singolo documento per ogni valore della chiave. Per altre informazioni sulle chiavi di partizione, vedere Partizionamento e ridimensionamento in Azure Cosmos DB.
Resilienza
Quando si usa il trigger di Hub eventi con Funzioni, intercettare le eccezioni all'interno del ciclo di elaborazione. Se si verifica un'eccezione non gestita, il runtime di Funzioni non ritenta i messaggi. Se non è possibile elaborare un messaggio, inserire il messaggio in una coda di messaggi non recapitabili. Usare un processo fuori banda per esaminare i messaggi e determinare l'azione correttiva.
Il codice seguente illustra come la funzione di inserimento intercetta le eccezioni e inserisce messaggi non elaborati in una coda di messaggi non recapitabili.
[Function(nameof(RawTelemetryFunction))]
public async Task RunAsync([EventHubTrigger("%EventHubName%", Connection = "EventHubConnection")] EventData[] messages,
FunctionContext context)
{
_telemetryClient.GetMetric("EventHubMessageBatchSize").TrackValue(messages.Length);
DeviceState? deviceState = null;
// Create a new CosmosClient
var cosmosClient = new CosmosClient(Environment.GetEnvironmentVariable("COSMOSDB_CONNECTION_STRING"));
// Get a reference to the database and the container
var database = cosmosClient.GetDatabase(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_NAME"));
var container = database.GetContainer(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_COL"));
// Create a new QueueClient
var queueClient = new QueueClient(Environment.GetEnvironmentVariable("DeadLetterStorage"), "deadletterqueue");
await queueClient.CreateIfNotExistsAsync();
foreach (var message in messages)
{
try
{
deviceState = _telemetryProcessor.Deserialize(message.Body.ToArray(), _logger);
try
{
// Add the device state to Cosmos DB
await container.UpsertItemAsync(deviceState, new PartitionKey(deviceState.DeviceId));
}
catch (Exception ex)
{
_logger.LogError(ex, "Error saving on database", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error deserializing message", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
}
Il codice illustrato registra anche le eccezioni ad Application Insights. È possibile usare la chiave di partizione e il numero di sequenza per correlare i messaggi non recapitabili con le eccezioni nei log.
I messaggi nella coda dei messaggi non recapitabili devono avere informazioni sufficienti per comprendere il contesto dell'errore. In questo esempio la DeadLetterMessage classe contiene il messaggio di eccezione, i dati del corpo dell'evento originale e il messaggio di evento deserializzato (se disponibile).
public class DeadLetterMessage
{
public string? Issue { get; set; }
public byte[]? MessageBody { get; set; }
public DeviceState? DeviceState { get; set; }
}
Usare Monitoraggio di Azure per monitorare l'hub eventi. Se viene visualizzato un input ma nessun output, significa che i messaggi non vengono elaborati. In tal caso, passare a Log Analytics e cercare le eccezioni o altri errori.
DevOps
Usare l'infrastruttura come codice (IaC) quando possibile. IaC gestisce l'infrastruttura, l'applicazione e le risorse di archiviazione con un approccio dichiarativo come Azure Resource Manager. Ciò consentirà di automatizzare la distribuzione usando DevOps come soluzione di integrazione continua e recapito continuo (CI/CD). I modelli devono essere con versione e inclusi come parte della pipeline di versione.
Quando si creano modelli, raggruppare le risorse come modo per organizzarle e isolarle per ogni carico di lavoro. Un modo comune per considerare il carico di lavoro è una singola applicazione serverless o una rete virtuale. L'obiettivo dell'isolamento del carico di lavoro è associare le risorse a un team, in modo che il team DevOps possa gestire in modo indipendente tutti gli aspetti di tali risorse ed eseguire CI/CD.
Quando si distribuiscono i servizi, sarà necessario monitorarli. Prendere in considerazione l'uso di Application Insights per consentire agli sviluppatori di monitorare le prestazioni e rilevare i problemi.
Ripristino di emergenza
La distribuzione illustrata di seguito si trova in una sola area di Azure. Per un approccio più resiliente al ripristino di emergenza, sfruttare le funzionalità di distribuzione a livello geografico nei vari servizi:
Hub eventi. Creare due spazi dei nomi di Hub eventi, uno spazio dei nomi primario (attivo) e un spazio dei nomi secondario (passivo). I messaggi vengono indirizzati automaticamente allo spazio dei nomi attivo a meno che non si esegua il failover nello spazio dei nomi secondario. Per altre informazioni, vedere Ripristino di emergenza geografico nel servizio Hub eventi di Azure.
App per le funzioni. Distribuire una seconda app per le funzioni che è in attesa di leggere lo spazio dei nomi secondario di Hub eventi. Questa funzione scrive in un account di archiviazione secondario per la coda di messaggi non recapitabili.
Azure Cosmos DB. Azure Cosmos DB supporta più aree di scrittura, che consentono di scrivere in qualsiasi area aggiunta all'account Azure Cosmos DB. Se non si abilita la scrittura multipla, è comunque possibile eseguire il failover dell'area di scrittura primaria. Gli SDK client di Azure Cosmos DB e le associazioni di funzioni di Azure gestiscono automaticamente il failover, quindi non è necessario aggiornare le impostazioni di configurazione dell'applicazione.
Archiviazione di Azure. Usare l'archiviazione con ridondanza geografica e accesso in lettura per la coda di messaggi non recapitabili. Verrà creata una replica di sola lettura in un'altra area. Se l'area primaria diventa non disponibile, è possibile leggere gli elementi attualmente presenti nella coda. In aggiunta eseguire il provisioning di un altro account di archiviazione nella regione secondaria in cui la funzione può scrivere dopo un failover.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
Usare il calcolatore prezzi di Azure per stimare i costi. Ecco alcune altre considerazioni per Funzioni di Azure e Azure Cosmos DB.
Funzioni di Azure
Funzioni di Azure supporta due modelli di hosting:
- Piano a consumo. La potenza di calcolo viene allocata automaticamente quando il codice è in esecuzione.
- Piano di servizio app. Un set di macchine virtuali (VM) viene allocato per il codice. Definisce anche il numero di macchine virtuali e le relative dimensioni.
In questa architettura, ogni evento che arriva in Hub eventi attiva una funzione che elabora tale evento. Dal punto di vista dei costi, è consigliabile usare il piano a consumo perché si paga solo per le risorse di calcolo usate.
Azure Cosmos DB
Con Azure Cosmos DB, si paga per le operazioni eseguite sul database e per l'archiviazione utilizzata dai dati.
- Operazioni di database. Il modo in cui vengono addebitati i costi per le operazioni del database dipende dal tipo di account Azure Cosmos DB in uso.
- In modalità serverless non è necessario effettuare il provisioning di alcuna velocità effettiva durante la creazione di risorse nell'account Azure Cosmos DB. Al termine del periodo di fatturazione, viene fatturato l'importo delle unità richiesta utilizzate dalle operazioni del database.
- Nella modalità velocità effettiva con provisioning si specifica la velocità effettiva necessaria in Unità richiesta al secondo (UR/sec) e viene fatturata ogni ora per la velocità effettiva massima con provisioning per un'ora specifica. Nota: poiché il modello di velocità effettiva con provisioning dedica le risorse al contenitore o al database, verrà addebitato il costo della velocità effettiva di cui è stato effettuato il provisioning anche se non si eseguono carichi di lavoro.
- Archiviazione. Viene addebitata una tariffa fissa per la quantità totale di spazio di archiviazione (in GB) utilizzata dai dati e dagli indici per un'ora specifica.
In questa architettura di riferimento, la funzione archivia esattamente un documento per dispositivo che invia dati. La funzione aggiorna continuamente i documenti con lo stato più recente del dispositivo, usando un'operazione upsert, che è conveniente in termini di archiviazione utilizzata. Per altre informazioni, vedere Modello di prezzi di Azure Cosmos DB.
Usare il calcolatore della capacità di Azure Cosmos DB per ottenere una stima rapida del costo del carico di lavoro.
Distribuire lo scenario
 Un'implementazione di riferimento per questa architettura è disponibile in GitHub.
Un'implementazione di riferimento per questa architettura è disponibile in GitHub.
Passaggi successivi
- Introduzione a Funzioni di Azure
- Introduzione ad Azure Cosmos DB
- Che cos'è Archiviazione code di Azure?
- Panoramica di Monitoraggio di Azure
- Documentazione di Azure Pipelines