Configurare il gruppo di failover - Interfaccia della riga di comando
Questo articolo illustra come configurare il ripristino di emergenza per Istanza gestita di SQL abilitato da Azure Arc con l'interfaccia della riga di comando. Prima di procedere, esaminare le informazioni e i prerequisiti in Istanza gestita di SQL abilitati da Azure Arc - Ripristino di emergenza.
Prerequisiti
Prima di configurare i gruppi di failover tra due istanze di Istanza gestita di SQL abilitati da Azure Arc, è necessario soddisfare i prerequisiti seguenti:
- Un controller dati di Azure Arc e un'istanza gestita di SQL abilitata per Arc di cui è stato effettuato il provisioning nel sito primario con
--license-typecome uno diBasePriceoLicenseIncluded. - Un controller dati di Azure Arc e un'istanza gestita di SQL abilitata per Arc di cui è stato effettuato il provisioning nel sito secondario con una configurazione identica a quella primaria in termini di:
- CPU
- Memoria
- Storage
- Livello di servizio
- Regole di confronto
- Altre impostazioni dell'istanza
- L'istanza nel sito secondario richiede
--license-typecomeDisasterRecovery. Questa istanza deve essere nuova, senza oggetti utente.
Nota
- È importante specificare durante la creazione dell'istanza
--license-typegestita. Ciò consentirà di eseguire il seeding dell'istanza di ripristino di emergenza dall'istanza primaria nel data center primario. L'aggiornamento di questa proprietà dopo la distribuzione non avrà lo stesso effetto.
Processo di distribuzione
Per configurare un gruppo di failover di Azure tra due istanze, seguire questa procedura:
- Creare una risorsa personalizzata per il gruppo di disponibilità distribuito nel sito primario
- Creare una risorsa personalizzata per il gruppo di disponibilità distribuito nel sito secondario
- Copiare i dati binari dai certificati di mirroring
- Configurare il gruppo di disponibilità distribuito tra i siti primari e secondari in
syncmodalità oasync
L'immagine seguente mostra un gruppo di disponibilità distribuito configurato correttamente:
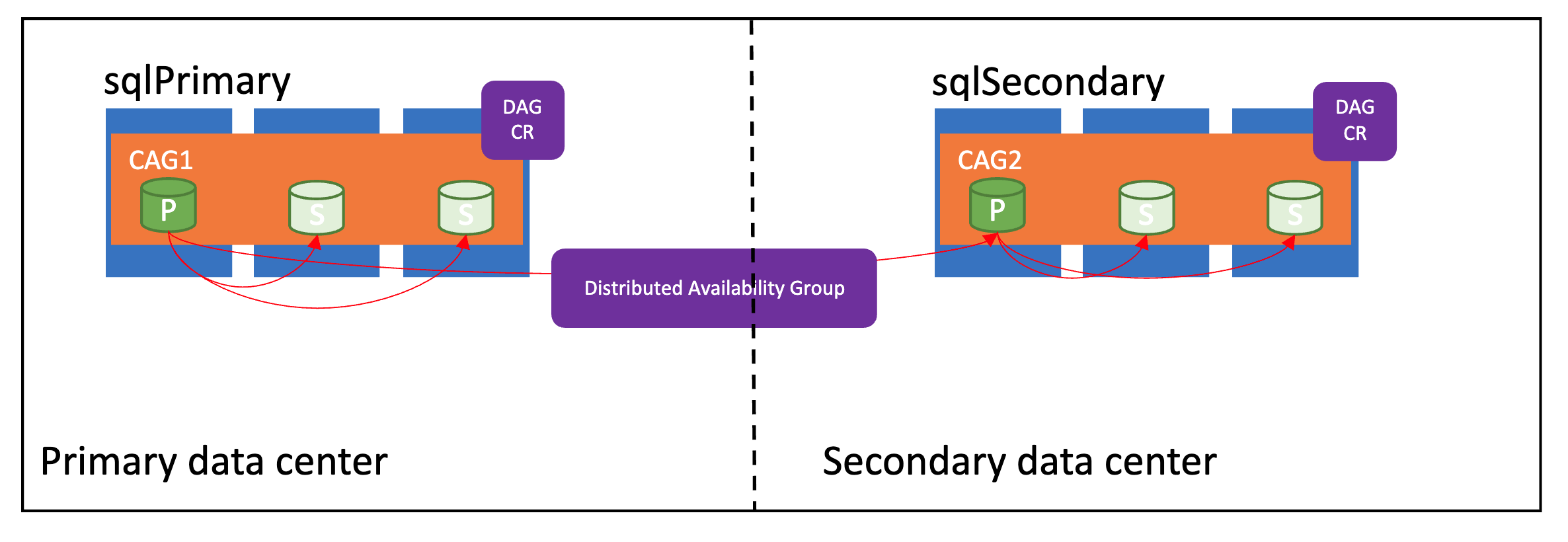
Modalità di sincronizzazione
I gruppi di failover nei servizi dati di Azure Arc supportano due modalità di sincronizzazione: sync e async. La modalità di sincronizzazione influisce direttamente sul modo in cui i dati vengono sincronizzati tra le istanze e potenzialmente sulle prestazioni nell'istanza gestita primaria.
Se i siti primari e secondari si trovano a pochi chilometri l'uno dall'altro, usare la sync modalità. In caso contrario, usare la async modalità per evitare eventuali effetti sulle prestazioni nel sito primario.
Configurare il gruppo di failover di Azure - modalità diretta
Seguire questa procedura se i servizi dati di Azure Arc vengono distribuiti in directly modalità connessa.
Dopo aver soddisfatto i prerequisiti, eseguire il comando seguente per configurare il gruppo di failover di Azure tra le due istanze:
az sql instance-failover-group-arc create --name <name of failover group> --mi <primary SQL MI> --partner-mi <Partner MI> --resource-group <name of RG> --partner-resource-group <name of partner MI RG>
Esempio:
az sql instance-failover-group-arc create --name sql-fog --mi sql1 --partner-mi sql2 --resource-group rg-name --partner-resource-group rg-name
Il comando precedente:
- Crea le risorse personalizzate necessarie nei siti primari e secondari
- Copia i certificati di mirroring e configura il gruppo di failover tra le istanze
Configurare il gruppo di failover di Azure - modalità indiretta
Seguire questa procedura se i servizi dati di Azure Arc vengono distribuiti in indirectly modalità connessa.
Effettuare il provisioning dell'istanza gestita nel sito primario.
az sql mi-arc create --name <primaryinstance> --tier bc --replicas 3 --k8s-namespace <namespace> --use-k8sPassare al contesto del cluster secondario eseguendo ed effettuando
kubectl config use-context <secondarycluster>il provisioning dell'istanza gestita nel sito secondario che sarà l'istanza di ripristino di emergenza. A questo punto, i database di sistema non fanno parte del gruppo di disponibilità indipendente.Nota
È importante specificare
--license-type DisasterRecoverydurante l'istanza gestita. Ciò consentirà di eseguire il seeding dell'istanza di ripristino di emergenza dall'istanza primaria nel data center primario. L'aggiornamento di questa proprietà dopo la distribuzione non avrà lo stesso effetto.az sql mi-arc create --name <secondaryinstance> --tier bc --replicas 3 --license-type DisasterRecovery --k8s-namespace <namespace> --use-k8sCertificati di mirroring: i dati binari all'interno della proprietà Certificato mirroring dell'istanza gestita sono necessari per la creazione del gruppo di failover dell'istanza CR (risorsa personalizzata).
Questa operazione può essere ottenuta in alcuni modi:
(a) Se si usa l'interfaccia
azdella riga di comando, generare prima il file del certificato di mirroring e quindi puntare a tale file durante la configurazione del gruppo di failover dell'istanza in modo che i dati binari vengano letti dal file e copiati nel cr. I file di certificato non sono necessari dopo la creazione del gruppo di failover.(b) Se si usa
kubectl, copiare e incollare direttamente i dati binari dall'istanza gestita CR nel file yaml che verrà usato per creare il gruppo di failover dell'istanza.Uso di (a) precedente:
Creare il file del certificato di mirroring per l'istanza primaria:
az sql mi-arc get-mirroring-cert --name <primaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sEsempio:
az sql mi-arc get-mirroring-cert --name sqlprimary --cert-file $HOME/sqlcerts/sqlprimary.pem --k8s-namespace my-namespace --use-k8sConnessione al cluster secondario e creare il file del certificato di mirroring per l'istanza secondaria:
az sql mi-arc get-mirroring-cert --name <secondaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sEsempio:
az sql mi-arc get-mirroring-cert --name sqlsecondary --cert-file $HOME/sqlcerts/sqlsecondary.pem --k8s-namespace my-namespace --use-k8sDopo aver creato i file del certificato di mirroring, copiare il certificato dall'istanza secondaria in un percorso condiviso/locale nel cluster dell'istanza primaria e viceversa.
Creare la risorsa del gruppo di failover in entrambi i siti.
Nota
Verificare che le istanze DI SQL abbiano nomi diversi sia per i siti primari che per i siti secondari e il
shared-namevalore deve essere identico in entrambi i siti.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for primary failover group resource> --mi <local SQL managed instance name> --role primary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<secondary IP> --partner-mirroring-cert-file <secondary.pem> --k8s-namespace <namespace> --use-k8sEsempio:
az sql instance-failover-group-arc create --shared-name myfog --name primarycr --mi sqlinstance1 --role primary --partner-mi sqlinstance2 --partner-mirroring-url tcp://10.20.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance2.pem --k8s-namespace my-namespace --use-k8sNell'istanza secondaria eseguire il comando seguente per configurare la risorsa personalizzata del gruppo di failover. In
--partner-mirroring-cert-filequesto caso deve puntare a un percorso con il file del certificato di mirroring generato dall'istanza primaria, come descritto in 3(a) sopra.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for secondary failover group resource> --mi <local SQL managed instance name> --role secondary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<primary IP> --partner-mirroring-cert-file <primary.pem> --k8s-namespace <namespace> --use-k8sEsempio:
az sql instance-failover-group-arc create --shared-name myfog --name secondarycr --mi sqlinstance2 --role secondary --partner-mi sqlinstance1 --partner-mirroring-url tcp://10.10.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance1.pem --k8s-namespace my-namespace --use-k8s
Recuperare lo stato di integrità del gruppo di failover di Azure
Le informazioni sul gruppo di failover, ad esempio il ruolo primario, il ruolo secondario e lo stato di integrità corrente, possono essere visualizzate nella risorsa personalizzata nel sito primario o secondario.
Eseguire il comando seguente nel sito primario e/o secondario per elencare la risorsa personalizzata dei gruppi di failover:
kubectl get fog -n <namespace>
Descrivere la risorsa personalizzata per recuperare lo stato del gruppo di failover, come indicato di seguito:
kubectl describe fog <failover group cr name> -n <namespace>
Failover group operations (Operazioni dei gruppi di failover)
Dopo aver configurato il gruppo di failover tra le istanze gestite, è possibile eseguire diverse operazioni di failover a seconda delle circostanze.
I possibili scenari di failover sono:
Le istanze di entrambi i siti sono in stato integro e deve essere eseguito un failover:
- eseguire un failover manuale da primario a secondario senza perdita di dati impostando
role=secondaryl'istanza gestita di SQL primaria.
- eseguire un failover manuale da primario a secondario senza perdita di dati impostando
Il sito primario non è integro/non raggiungibile e deve essere eseguito un failover:
- il Istanza gestita di SQL primario abilitato da Azure Arc è inattivo/non integro/non raggiungibile
- il Istanza gestita di SQL secondario abilitato da Azure Arc deve essere promosso forzatamente al database primario con potenziale perdita di dati
- quando il Istanza gestita di SQL primario originale abilitato da Azure Arc torna online, segnala come
Primarystato ruolo e non integro e deve essere forzato in unsecondaryruolo in modo che possa aggiungere il gruppo di failover e i dati possono essere sincronizzati.
Failover manuale (senza perdita di dati)
Usare az sql instance-failover-group-arc update ... il gruppo di comandi per avviare un failover da primario a secondario. Tutte le transazioni in sospeso nell'istanza geografica primaria vengono replicate nell'istanza geografica secondaria prima del failover.
Modalità di connessione diretta
Eseguire il comando seguente per avviare un failover manuale, in direct modalità connessa usando le API ARM:
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <primary instance> --role secondary --resource-group <resource group>
Esempio:
az sql instance-failover-group-arc update --name myfog --mi sqlmi1 --role secondary --resource-group myresourcegroup
Modalità di connessione indiretta
Eseguire il comando seguente per avviare un failover manuale, in indirect modalità connessa usando le API kubernetes:
az sql instance-failover-group-arc update --name <name of failover group resource> --role secondary --k8s-namespace <namespace> --use-k8s
Esempio:
az sql instance-failover-group-arc update --name myfog --role secondary --k8s-namespace my-namespace --use-k8s
Failover forzato con perdita di dati
Nella circostanza in cui l'istanza geografica primaria non è più disponibile, è possibile eseguire i comandi seguenti nell'istanza di ripristino di emergenza geografica secondaria per alzare di livello a primario con un failover forzato che causa una potenziale perdita di dati.
Nell'istanza di ripristino di emergenza geografica secondaria eseguire il comando seguente per alzarlo di livello al ruolo primario, con perdita di dati.
Nota
Se è --partner-sync-mode stato configurato come sync, deve essere reimpostato su async quando il database secondario viene alzato di livello primario.
Modalità di connessione diretta
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <instance> --role force-primary-allow-data-loss --resource-group <resource group> --partner-sync-mode async
Esempio:
az sql instance-failover-group-arc update --name myfog --mi sqlmi2 --role force-primary-allow-data-loss --resource-group myresourcegroup --partner-sync-mode async
Modalità di connessione indiretta
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-primary-allow-data-loss --partner-sync-mode async
Quando l'istanza geografica primaria diventa disponibile, eseguire il comando seguente per inserirla nel gruppo di failover e sincronizzare i dati:
Modalità di connessione diretta
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <old primary instance> --role force-secondary --resource-group <resource group>
Modalità di connessione indiretta
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-secondary
Facoltativamente, --partner-sync-mode può essere configurato di nuovo in sync modalità, se necessario.
Operazioni successive al failover
Dopo aver eseguito un failover dal sito primario al sito secondario, con o senza perdita di dati, potrebbe essere necessario eseguire le operazioni seguenti:
- Aggiornare il stringa di connessione per le applicazioni per connettersi all'istanza gestita di Arc SQL appena promossa
- Se si prevede di continuare a eseguire il carico di lavoro di produzione all'esterno del sito secondario, aggiornare in
--license-typeBasePriceoLicenseIncludedper avviare la fatturazione per i vCore utilizzati.