Risolvere problemi relativi alla raccolta di metriche di Prometheus in Monitoraggio di Azure
Seguire la procedura descritta in questo articolo per determinare la causa della mancata raccolta delle metriche di Prometheus come previsto in Monitoraggio di Azure.
I pod di replica scorporano le metriche da kube-state-metrics, destinazioni di scorporo personalizzate nelle configmap ama-metrics-prometheus-config e destinazioni di scorporo personalizzate definite nelle risorse personalizzate. I pod DaemonSet scorporano le metriche dalle destinazioni seguenti nel rispettivo nodo: kubelet, cAdvisor, node-exporter e destinazioni di scorporo personalizzate nelle configmap ama-metrics-prometheus-config-node. Il pod di cui si vuole visualizzare i log e l’interfaccia utente di Prometheus per esso dipende da quale destinazione di scorporo si sta analizzando.
Risolvere problemi relativi all'uso dello script di PowerShell
Se si verifica un errore durante il tentativo di abilitare il monitoraggio per il cluster del servizio Azure Kubernetes, seguire queste istruzioni per eseguire lo script di risoluzione dei problemi. Questo script è progettato per eseguire una diagnosi di base di eventuali problemi di configurazione nel cluster ed è possibile inserire i file generati durante la creazione di una richiesta di supporto per una risoluzione più rapida del caso di supporto.
Limitazione delle metriche
Il servizio gestito per Prometheus di Monitoraggio di Azure ha limiti e quote predefiniti per l'inserimento. Quando si raggiungono i limiti di inserimento, la limitazione può verificarsi. È possibile richiedere un aumento di questi limiti. Per informazioni sui limiti delle metriche di Prometheus, vedere Limiti del servizio Monitoraggio di Azure.
Nel portale di Azure, passare all’area di lavoro di Monitoraggio di Azure. Passare a Metricse selezionare le metriche Active Time Series % Utilization e Events Per Minute Received % Utilization. Verificare che entrambi siano inferiori al 100%.
Per altre informazioni sul monitoraggio e l'invio di avvisi sulle metriche di inserimento, vedere Monitorare l'inserimento delle metriche dell'area di lavoro di Monitoraggio di Azure.
Gap intermittenti nella raccolta dei dati delle metriche
Durante gli aggiornamenti dei nodi, è possibile che venga visualizzato un gap da 1 a 2 minuti nei dati delle metriche raccolti dall'agente di raccolta a livello di cluster. Questo gap è dovuto al fatto che il nodo in cui viene eseguito viene aggiornato come parte di un normale processo di aggiornamento. Influisce sulle destinazioni a livello di cluster, ad esempio kube-state-metrics e destinazioni dell'applicazione personalizzate specificate. Si verifica quando il cluster viene aggiornato manualmente o tramite l'aggiornamento automatico. Questo comportamento è previsto e si verifica a causa del nodo in cui viene eseguito l'aggiornamento. Nessuna delle regole di avviso consigliate è interessata da questo comportamento.
Stato pod
Controllare lo stato del pod con il comando seguente:
kubectl get pods -n kube-system | grep ama-metrics
Quando il servizio è in esecuzione correttamente, viene restituito l'elenco seguente di pod nel formato ama-metrics-xxxxxxxxxx-xxxxx :
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*pod per ogni nodo nel cluster.
Ogni stato del pod deve essere Running e avere un numero uguale di riavvii al numero di modifiche configmap applicate. Il pod ama-metrics-operator-targets-* potrebbe riavviarsi ancora all’inizio e questo comportamento è previsto:

Se ogni stato del pod è Running ma uno o più pod si riavviano ancora, eseguire il comando seguente:
kubectl describe pod <ama-metrics pod name> -n kube-system
- Questo comando fornisce il motivo per i riavvii. I riavvii dei pod sono previsti se sono state apportate modifiche a configmap. Se il motivo del riavvio è
OOMKilled, il pod non può tenere il passo con il volume delle metriche. Vedere i consigli sulla scalabilità per il volume delle metriche.
Se i pod sono in esecuzione come previsto, la posizione successiva da controllare è quella dei log dei contenitori.
Verificare la presenza di configurazioni di rietichettatura
Se mancano le metriche, è possibile verificare se sono presenti anche configurazioni di rietichettatura. Con la rilabazione delle configurazioni, assicurarsi che la rilabazione non filtra le destinazioni e che le etichette configurate corrispondano correttamente alle destinazioni. Per altre informazioni, vedere la documentazione relativa alla configurazione di Prometheus relabel.
Log dei contenitori
Visualizzare i log dei contenitori con il comando seguente:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
All’avvio, tutti gli errori iniziali vengono stampati in rosso, mentre gli avvisi vengono stampati in giallo. La visualizzazione dei log colorati richiede almeno PowerShell versione 7 o una distribuzione linux.
- Verificare se si verifica un problema con il recupero del token di autenticazione:
- Il messaggio Nessuna configurazione presente per la risorsa del servizio Azure Kubernetes viene registrata ogni 5 minuti.
- Il pod viene riavviato ogni 15 minuti per riprovare con l’errore: Nessuna configurazione presente per la risorsa del servizio Azure Kubernetes.
- In tal caso, verificare che la regola di raccolta dati e l’endpoint di raccolta dati esistano nel gruppo di risorse.
- Verificare anche che l’area di lavoro di Monitoraggio di Azure esista.
- Verificare che non sia disponibile un cluster del servizio Azure Kubernetes privato e che non sia collegato a un ambito collegamento privato di Monitoraggio di Azure per qualsiasi altro servizio. Questo scenario non è attualmente supportato.
Elaborazione della configurazione
Visualizzare i log dei contenitori con il comando seguente:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Verificare che non siano presenti errori con l’analisi della configurazione di Prometheus, l’unione con destinazioni di scorporo predefinite abilitate e la convalida della configurazione completa.
- Se è stata inclusa una configurazione di Prometheus personalizzata, verificare che sia riconosciuta nei log. In caso contrario:
- Verificare che configmap abbia il nome corretto:
ama-metrics-prometheus-confignello spazio dei nomikube-system. - Verificare che in configmap, la configurazione di Prometheus si trovi in una sezione denominata
prometheus-configindatacome illustrato di seguito:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- Verificare che configmap abbia il nome corretto:
- Se sono state create risorse personalizzate, devono essere stati rilevati errori di convalida durante la creazione di monitoraggi di pod/servizi. Se le metriche delle destinazioni non vengono ancora visualizzate, assicurarsi che i log non visualizzino errori.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Verificare che non siano presenti errori da
MetricsExtensionrelativi all’autenticazione con l’area di lavoro di Monitoraggio di Azure. - Verificare che non siano presenti errori da
OpenTelemetry collectorsullo scorporo delle destinazioni.
Esegui questo comando:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- Questo comando mostra un errore se si verifica un problema con l’autenticazione con l’area di lavoro di Monitoraggio di Azure. L’esempio seguente mostra i log senza problemi:
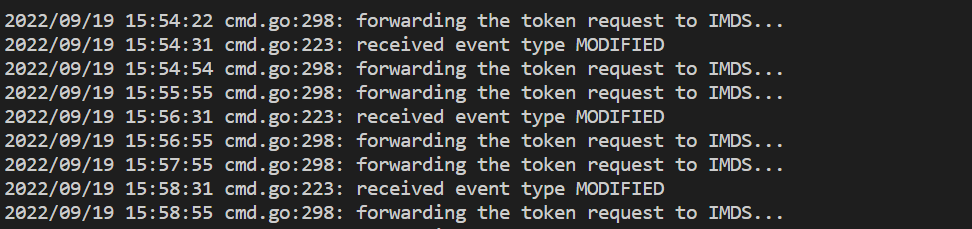

Se non sono presenti errori nei log, l’interfaccia di Prometheus può essere usata per il debug, per verificare la configurazione e le destinazioni previste da scorporare.
Interfaccia di Prometheus
Ogni pod ama-metrics-* ha l’interfaccia utente in modalità agente di Prometheus disponibile sulla porta 9090.
La configurazione personalizzata e le destinazioni delle risorse personalizzate vengono scorporate dal pod ama-metrics-* e dalle destinazioni del nodo dal pod ama-metrics-node-*.
Eseguire il port forward nel pod di replica o in uno dei pod del set di daemon per controllare la configurazione, l’individuazione dei servizi e gli endpoint di destinazione, come descritto qui per verificare che le configurazioni personalizzate siano corrette, le destinazioni previste sono state individuate per ogni processo e non sono presenti errori con lo scorporo delle destinazioni specifiche.
Eseguire il comando kubectl port-forward <ama-metrics pod> -n kube-system 9090.
Aprire un browser per l’indirizzo
127.0.0.1:9090/config. Questa interfaccia utente ha la configurazione completa di scorporo. Verificare che tutti i processi siano inclusi nella configurazione.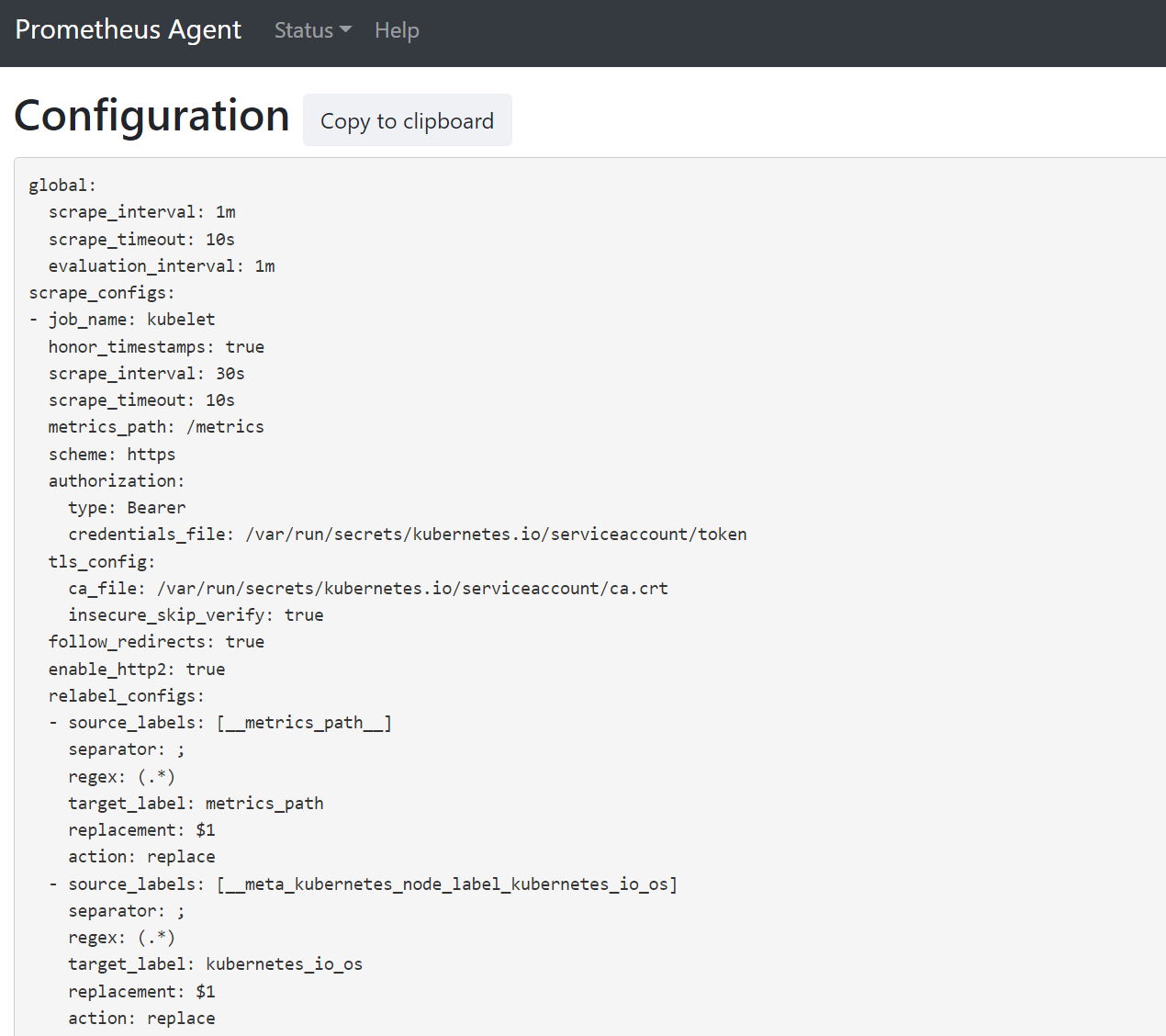
Passare a
127.0.0.1:9090/service-discoveryper visualizzare le destinazioni individuate dall’oggetto di individuazione del servizio specificato e cosa relabel_configs hanno filtrato le destinazioni per essere. Ad esempio, quando mancano metriche da un determinato pod, è possibile trovare se il pod è stato individuato e qual è l’URI. È quindi possibile usare questo URI quando si esaminano le destinazioni per verificare se sono presenti errori di scorporo.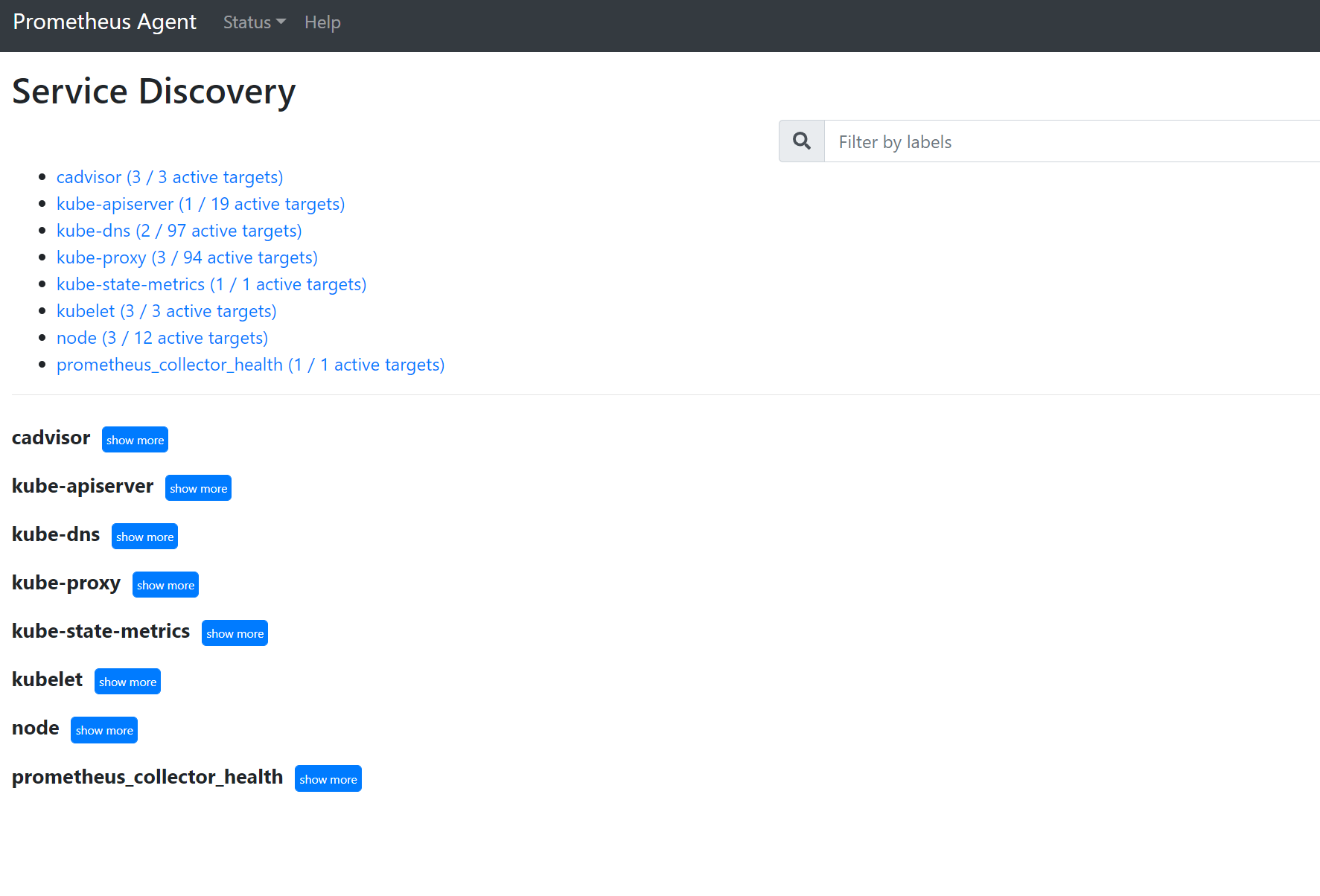
Passare a
127.0.0.1:9090/targetsper visualizzare tutti i processi, l’ultima volta che l’endpoint del processo è stato eliminato ed eventuali errori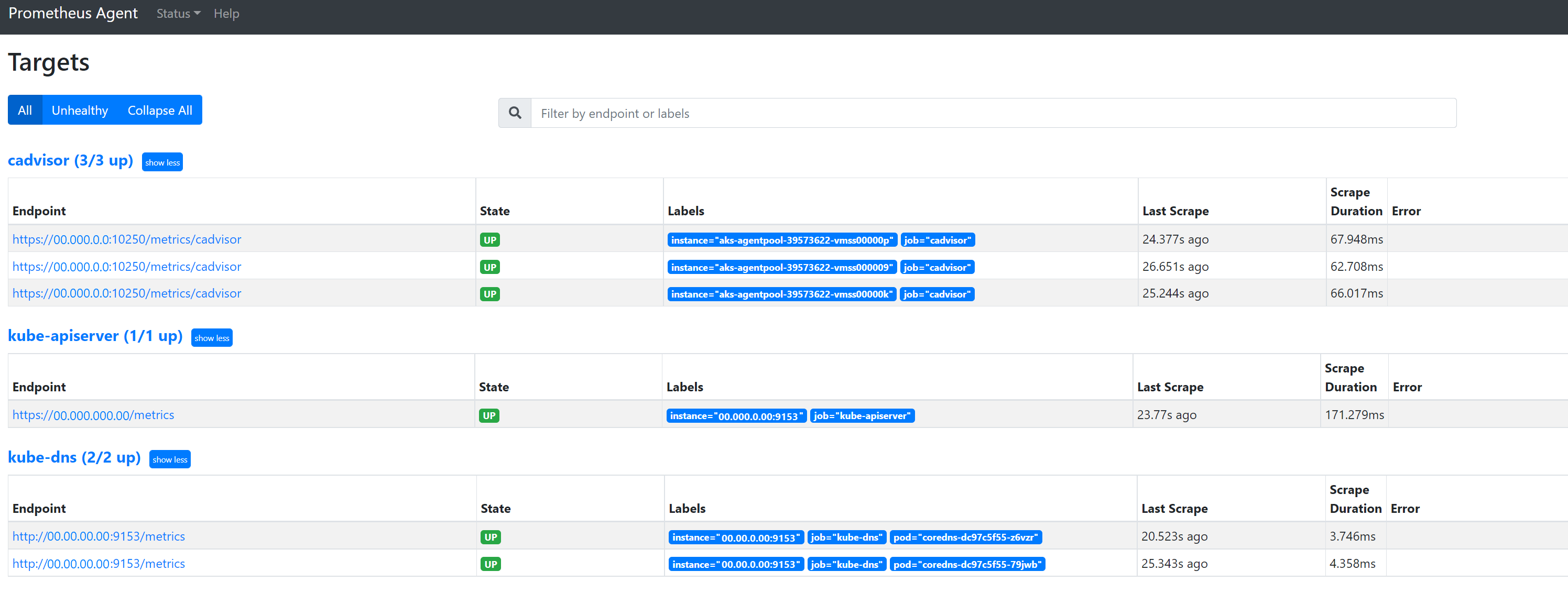



Risorse personalizzate
- Se sono state incluse risorse personalizzate, assicurarsi che vengano visualizzate nella configurazione, nell’individuazione dei servizi e nelle destinazioni.
Impostazione

Individuazione del servizio

Target

Se non sono presenti problemi e le destinazioni desiderate vengono scorporate, è possibile visualizzare le metriche esatte che vengono scorporate abilitando la modalità di debug.
Modalità di debug
Avviso
Questa modalità può influire sulle prestazioni e deve essere abilitata solo per un breve periodo di tempo a scopo di debug.
L’add-on per le metriche può essere configurato per l’esecuzione in modalità di debug modificando l’impostazione configmap enabled in debug-mode in true seguendo le istruzioni qui.
Se abilitato, tutte le metriche di Prometheus che vengono scorporate sono ospitate sulla porta 9091. Esegui questo comando:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
Passare a 127.0.0.1:9091/metrics in un browser per verificare se le metriche sono state scorporate dall’agente di raccolta OpenTelemetry. È possibile accedere a questa interfaccia utente per ogni pod ama-metrics-*. Se le metriche non sono presenti, potrebbe verificarsi un problema con le lunghezze della metrica o del nome dell’etichetta o il numero di etichette. Verificare anche il superamento della quota di inserimento per le metriche di Prometheus come specificato in questo articolo.
Nomi delle metriche, nomi di etichette e valori di etichetta
Lo scorporo delle metriche presenta attualmente limitazioni nella tabella seguente:
| Proprietà | Limite |
|---|---|
| Lunghezza nome etichetta | Minore o uguale a 511 caratteri. Quando questo limite viene superato per qualsiasi serie temporale in un processo, l’intero processo di scorporo ha esito negativo e le metriche vengono eliminate da tale processo prima dell’inserimento. È possibile visualizzare up=0 per il processo e anche l’esperienza utente di destinazione mostra il motivo per up=0. |
| Lunghezza valore etichetta | Minore o uguale a 1023 caratteri. Quando questo limite viene superato per qualsiasi serie temporale in un processo, l’intero scorporo ha esito negativo e le metriche vengono eliminate dal processo prima dell’inserimento. È possibile visualizzare up=0 per il processo e anche l’esperienza utente di destinazione mostra il motivo per up=0. |
| Numero di etichette per serie temporale | Minore o uguale a 63. Quando questo limite viene superato per qualsiasi serie temporale in un processo, l’intero processo di scorporo ha esito negativo e le metriche vengono eliminate da tale processo prima dell’inserimento. È possibile visualizzare up=0 per il processo e anche l’esperienza utente di destinazione mostra il motivo per up=0. |
| Lunghezza nome di metrica | Minore o uguale a 511 caratteri. Quando questo limite viene superato per qualsiasi serie temporale in un processo, viene eliminata solo la serie specifica. MetricextensionConsoleDebugLog contiene tracce per la metrica eliminata. |
| Nomi di etichette con maiuscole e minuscole diverse | Due etichette all’interno dello stesso esempio di metrica, con maiuscole e minuscole diverse vengono considerate come aventi etichette duplicate e vengono eliminate durante l’inserimento. Ad esempio, la serie temporale my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} viene eliminata a causa di etichette duplicate perché ExampleLabel e examplelabel vengono considerate come lo stesso nome di etichetta. |
Controllare la quota di inserimento nell’area di lavoro di Monitoraggio di Azure
Se mancano delle metriche, per prima cosa è possibile verificare se i limiti di inserimento vengono superati per l’area di lavoro di Monitoraggio di Azure. Nel portale di Azure è possibile controllare l’utilizzo corrente per qualsiasi area di lavoro di Monitoraggio di Azure. È possibile visualizzare le metriche di utilizzo correnti nel menu Metrics per l’area di lavoro di Monitoraggio di Azure. Le metriche di utilizzo seguenti sono disponibili come metriche standard per ogni area di lavoro di Monitoraggio di Azure.
- Serie temporali attive: numero di serie temporali univoche inserite di recente nell’area di lavoro nelle 12 ore precedenti
- Limite serie temporali attive: limite per il numero di serie temporali univoche che possono essere inserite attivamente nell’area di lavoro
- Utilizzo in % serie temporali attive: percentuale di serie temporali attive correnti in uso
- Eventi al minuto inseriti: numero di eventi (campioni) per minuto ricevuti di recente
- Limite di inserimento di eventi per minuto: numero massimo di eventi al minuto che possono essere inseriti prima di essere limitati
- Utilizzo in % di inserimento di eventi per minuto: percentuale del limite di frequenza di inserimento delle metriche corrente utilizzate
Per evitare la limitazione dell’inserimento di metriche, è possibile monitorare e configurare un avviso sui limiti di inserimento. Vedere Monitorare limiti di inserimento.
Fare riferimento a quote e limiti del servizio per le quote predefinite e anche per comprendere cosa può essere aumentato in base all’utilizzo. È possibile richiedere l’aumento delle quote per le aree di lavoro di Monitoraggio di Azure usando il menu Support Request per l’area di lavoro di Monitoraggio di Azure. Assicurarsi di includere l'ID, l'ID interno e la località/area per l'area di lavoro monitoraggio di Azure nella richiesta di supporto, disponibile nel menu "Proprietà" per l'area di lavoro monitoraggio di Azure nella portale di Azure.
La creazione dell’area di lavoro di Monitoraggio di Azure non è riuscita a causa della valutazione di Criteri di Azure
Se la creazione dell'area di lavoro di Monitoraggio di Azure ha esito negativo e viene visualizzato un errore che riporta "La risorsa 'resource-name-xyz' non è stata consentita dai criteri", potrebbe essere presenti Criteri di Azure che impediscono la creazione della risorsa. Se sono presenti criteri che applicano una convenzione di denominazione per le risorse o i gruppi di risorse di Azure, è necessario creare un'esenzione per la convenzione di denominazione per la creazione di un'area di lavoro di Monitoraggio di Azure.
Quando si crea un’area di lavoro di Monitoraggio di Azure, per impostazione predefinita, una regola di raccolta dati e un endpoint di raccolta dati nel formato “azure-monitor-workspace-name” verranno creati automaticamente in un gruppo di risorse nel formato “MA_azure-monitor-workspace-name_location_managed”. Attualmente non è possibile modificare i nomi di queste risorse e sarà necessario impostare un'esenzione per il Criteri di Azure per esentare le risorse precedenti dalla valutazione dei criteri. Vedere Struttura di esenzione di Criteri di Azure.