Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
Questo articolo illustra come configurare la replica geografica attiva e avviare il failover per il Database SQL di Azure nel portale di Azure, in PoweShell o nell’interfaccia della riga di comando di Azure.
La georeplicazione attiva è configurata per ogni database. Per eseguire il failover di un gruppo di database o se l'applicazione richiede un endpoint di connessione stabile, prendere in considerazione i gruppi di failover .
Prerequisiti
Per completare questa esercitazione, è necessario un singolo database SQL di Azure. Per informazioni su come creare un database singolo con portale di Azure, interfaccia della riga di comando di Azure o PowerShell, vedere Guida rapida: creare un database singolo - database SQL di Azure.
È possibile usare il portale di Azure per configurare la replica geografica attiva tra sottoscrizioni, purché entrambe le sottoscrizioni si trovino nello stesso tenant di Microsoft Entra ID.
- Per creare una replica geografica secondaria in una sottoscrizione diversa dalla sottoscrizione del database primario in un tenant diverso da Microsoft Entra ID, usare la replica geografica secondaria tra le sottoscrizioni e l'esercitazione T-SQL tenant di Microsoft Entra ID.
- Le operazioni di replica geografica tra sottoscrizioni, inclusa la configurazione e il failover geografico, sono supportate usando le API REST per la creazione e l’aggiornamento dei database.
Aggiungere un database secondario
La procedura seguente crea un nuovo database secondario in una relazione di replica geografica.
Per aggiungere un database secondario, è necessario essere il proprietario o un comproprietario della sottoscrizione.
Il database secondario ha lo stesso nome del database primario e, per impostazione predefinita, ha lo stesso livello di servizio e le stesse dimensioni di calcolo. Il database secondario può essere un database singolo o un database in pool. Per altre informazioni, vedere Panoramica del modello di acquisto basato su DTU e modello di acquisto basato su vCore. Dopo aver creato ed eseguito il seeding del database secondario, inizia la replica dei dati dal database primario al nuovo database secondario.
Se la replica secondaria viene usata solo per il ripristino di emergenza e non dispone di carichi di lavoro di lettura o scrittura, è possibile risparmiare sui costi di licenza designando il database per standby quando si configura una nuova relazione di replica geografica attiva. Per altre informazioni, vedere Replica standby senza licenza.
Nota
Se il database partner esiste già, ad esempio come risultato della terminazione di una precedente relazione di replica geografica, il comando non riesce.
Nel portale di Azure passare al database per cui si vuole installare la replica geografica.
Nella pagina database SQL selezionare il database, scorrere fino a Gestione dati, selezionare Repliche, quindi selezionare Crea replica.
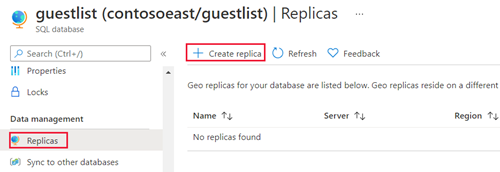
Selezionare la Sottoscrizione e il Gruppo di risorse del database secondario dell’area geografica.
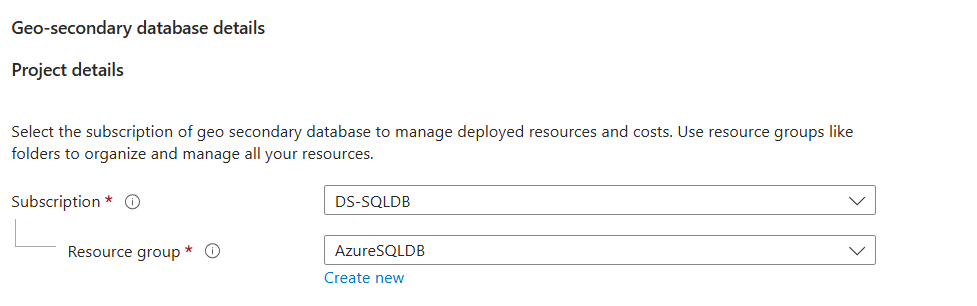
Selezionare o creare il server per il database secondario e configurare le opzioni Calcolo e archiviazione, se necessario. È possibile selezionare qualsiasi area per il server secondario, ma è consigliabile usare l’area abbinata.
Facoltativamente, è possibile aggiungere un database secondario a un pool elastico. Per creare il database secondario in un pool, selezionare Sì accanto a Usare il pool elastico SQL?, quindi selezionare un pool sul server di destinazione. Un pool deve esistere già nel server di destinazione. Questo flusso di lavoro non crea un pool.
Seleziona Rivedi e crea, esamina le informazioni e quindi seleziona Crea.
Viene avvitato il database secondario e avviato il processo di distribuzione.
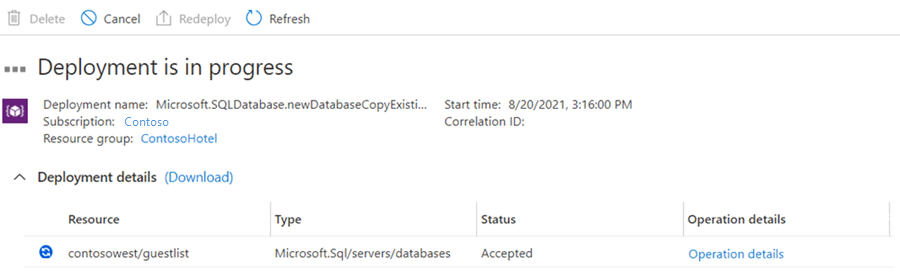
Una volta completato il processo di distribuzione, il database secondario mostra il relativo stato.

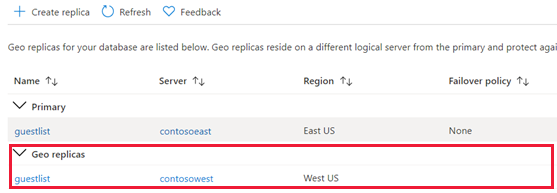
Tornare alla pagina del database primario e selezionare Repliche. Il database secondario figura nell’elenco delle Repliche geografiche.



Avviare un failover
Il database secondario può diventare il database primario.
Nel portale di Azure passare al database primario nella relazione di replica geografica.
Scorrere fino a Gestione dei dati, quindi selezionare Repliche.
Nell’elenco Repliche geografiche selezionare il database che dovrà diventare il nuovo database primario, selezionare i puntini di sospensione, quindi scegliere Failover forzato.
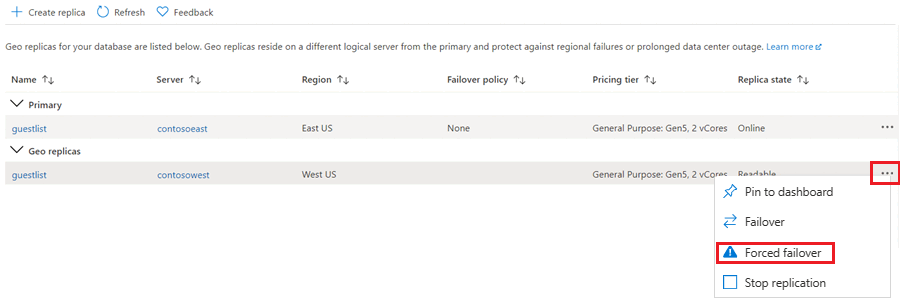
Selezionare Sì per avviare il failover.

Il comando passa immediatamente il database secondario al ruolo di database primario. Questo processo normalmente viene completato entro 30 secondi o meno.
Entrambi i database non sono disponibili, per un massimo di 25 secondi, mentre i ruoli vengono cambiati. Se il database primario ha più database secondari, il comando riconfigura automaticamente gli altri database secondari per la connessione al nuovo database primario. In circostanze normali il completamento dell’intera operazione dovrebbe richiedere meno di un minuto.
Rimuovere il database secondario
Questa operazione arresta in modo permanente la replica al database secondario e modifica il ruolo del database secondario in un database di lettura/scrittura normale. Se la connettività al database secondario viene interrotta il comando ha esito positivo ma il database secondario non diventa un database di lettura-scrittura fino a quando la connettività non verrà ripristinata.
- Nel portale di Azure passare al database primario nella relazione di replica geografica.
- Selezionare Repliche.
- Nell’elenco Repliche geografiche selezionare il database da rimuovere dalla relazione di replica geografica, selezionare i puntini di sospensione e quindi selezionare Arresta replica.
- Verrà visualizzata una finestra di conferma. Fare clic su Sì per rimuovere il database dalla relazione di replica geografica. Impostarlo su un database di lettura/scrittura che non fa parte di alcuna replica.
Replica geografica tra sottoscrizioni
- Per creare una replica geografica secondaria in una sottoscrizione diversa dalla sottoscrizione del database primario nello stesso tenant di Microsoft Entra, è possibile usare il portale di Azure o i passaggi descritti in questa sezione.
- Per creare una replica geografica secondaria in una sottoscrizione diversa dalla sottoscrizione del database primario in un tenant Microsoft Entra diverso, è necessario usare l’autenticazione SQL e T-SQL come descritto nei passaggi descritti in questa sezione. L'autenticazione di Microsoft Entra per Azure SQL per la replica geografica tra sottoscrizioni non è supportata quando un server logico si trova in un tenant di Azure diverso
Aggiungere l’indirizzo IP del computer client che esegue i comandi T-SQL in questo esempio, ai firewall del server di entrambi i server primario e secondario. È possibile confermare l’indirizzo IP eseguendo la query seguente durante la connessione al server primario dallo stesso computer client.
SELECT client_net_address FROM sys.dm_exec_connections WHERE session_id = @@SPID;Per ulteriori informazioni, vedere Regole del firewall di Database SQL di Azure e dell'IP di Azure Synapse.
Nel database
masternel server primario creare un account di accesso per l’autenticazione SQL dedicato alla configurazione attiva della replica geografica. Modificare il nome e la password di accesso come necessario.CREATE LOGIN geodrsetup WITH PASSWORD = 'ComplexPassword01';Nello stesso database creare un utente per l’account di accesso e aggiungerlo al ruolo
dbmanager:CREATE USER geodrsetup FOR LOGIN geodrsetup; ALTER ROLE dbmanager ADD MEMBER geodrsetup;Prendere nota del valore SID indicato in nell’accesso. Ottenere il valore SID con la query seguente.
SELECT sid FROM sys.sql_logins WHERE name = 'geodrsetup';Connessione al database primario (non al database
master) e creare un utente per lo stesso account di accesso.CREATE USER geodrsetup FOR LOGIN geodrsetup;Nello stesso database aggiungere l’utente al ruolo
db_owner.ALTER ROLE db_owner ADD MEMBER geodrsetup;Nel database
masternel server secondario creare lo stesso account di accesso del server primario, usando lo stesso nome, password e SID. Sostituire il valore SID esadecimale nel comando di esempio seguente con il valore ottenuto nel passaggio 4.CREATE LOGIN geodrsetup WITH PASSWORD = 'ComplexPassword01', SID = 0x010600000000006400000000000000001C98F52B95D9C84BBBA8578FACE37C3E;Nello stesso database creare un utente per l’account di accesso e aggiungerlo al ruolo
dbmanager.CREATE USER geodrsetup FOR LOGIN geodrsetup; ALTER ROLE dbmanager ADD MEMBER geodrsetup;Connettersi al database
masternel server primario usando il nuovo accessogeodrsetupe avviare la creazione della replica geografica secondaria nel server secondario. Modificare il nome del database e il nome del server secondario come necessario. Dopo aver eseguito il comando, è possibile monitorare la creazione geografica secondaria eseguendo una query sulla vista sys.dm_geo_replication_link_status nel database primario e sulla vista sys.dm_operation_status nel databasemasternel server primario. Il tempo necessario per creare un database geografico secondario dipende dalle dimensioni del database primario.alter database [dbrep] add secondary on server [servername];Dopo la creazione della replica geografica secondaria, è possibile rimuovere gli utenti, gli account di accesso e le regole del firewall creati dalla procedura.