Gestire lo spazio dei file per i database in database SQL di Azure
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
Questo articolo descrive i diversi tipi di spazio di archiviazione per i database nel database SQL di Azure e le operazioni che è possibile eseguire quando lo spazio allocato per i file deve essere gestito esplicitamente.
Panoramica
Nel database SQL di Azure sono disponibili modelli di carico di lavoro in cui l'allocazione dei file di dati sottostanti per i database può superare il numero di pagine di dati usate. Questa condizione si può verificare quando lo spazio usato aumenta e i dati vengono poi eliminati. Ciò è dovuto al fatto che lo spazio file allocato non viene recuperato automaticamente quando i dati vengono eliminati.
Potrebbe essere necessario monitorare l'utilizzo dello spazio file e compattare i file di dati per:
- Consentire l'aumento delle dimensioni dei dati in un pool elastico quando lo spazio file allocato per i relativi database raggiunge le dimensioni massime del pool.
- Consentire la riduzione delle dimensioni massime di un database singolo o di un pool elastico.
- Consentire il passaggio di un database singolo o di un pool elastico a un livello di servizio o a un livello di prestazioni diverso con dimensioni massime inferiori.
Nota
Le operazioni di compattazione non devono essere considerate un'operazione di ordinaria manutenzione. I file di dati e i file di resoconto che aumentano a causa di operazioni aziendali regolari e ricorrenti non richiedono operazioni di compattazione.
Monitoraggio dell'utilizzo dello spazio dei file
La maggior parte delle metriche per lo spazio di archiviazione visualizzate nel portale di Azure e delle API seguenti misura solo le dimensioni delle pagine di dati usate:
- API per le metriche basate su Azure Resource Manager tra cui get-metrics di PowerShell
Le API seguenti misurano invece anche le dimensioni dello spazio allocato per i database e i pool elastici:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
Informazioni sui tipi di spazio di archiviazione per un database
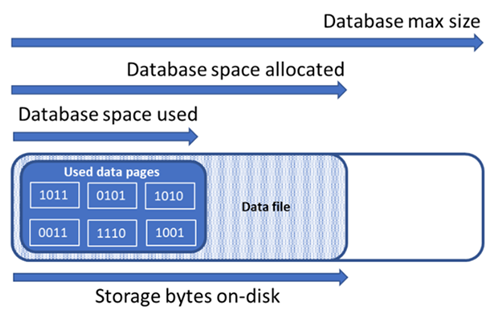
La comprensione delle quantità di spazio di archiviazione seguenti è importante per la gestione dello spazio file di un database.
| Quantità di database | Definizione | Commenti |
|---|---|---|
| Spazio dati usato | La quantità di spazio usato per archiviare i dati del database. | In genere, lo spazio usato aumenta quando vengono inseriti i dati e diminuisce quando vengono eliminati. In alcuni casi, lo spazio usato non cambia in caso di inserimenti o eliminazioni, a seconda della quantità e del modello di dati coinvolti nell'operazione e dell'eventuale frammentazione. Ad esempio, se si elimina una riga da ogni pagina di dati, non si riduce necessariamente lo spazio usato. |
| Spazio dati allocato | Quantità di spazio file formattato messo a disposizione per l'archiviazione dei dati del database. | La quantità di spazio allocato aumenta automaticamente, ma non diminuisce mai dopo le eliminazioni. Questo comportamento assicura che gli inserimenti futuri avvengano più velocemente, perché non è necessario riformattare lo spazio. |
| Spazio dati allocato ma non usato | Differenza tra la quantità di spazio dati allocato e lo spazio dati usato. | Questa quantità rappresenta la quantità massima di spazio libero che può essere recuperata compattando i file di dati del database. |
| Dimensioni massime dei dati | Quantità massima di spazio che può essere usata per l'archiviazione dei dati del database. | La quantità di spazio dati allocato non può superare le dimensioni massime dei dati. |
Il diagramma seguente illustra la relazione tra i diversi tipi di spazio di archiviazione per un database.
Eseguire una query su un database singolo per ottenere informazioni sullo spazio dei file
Usare la query seguente su sys.database_files per restituire la quantità di spazio per i dati del database allocato e la quantità di spazio inutilizzato allocato. L'unità di misura dei risultati di query è costituita da MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Informazioni sui tipi di spazio di archiviazione per un pool elastico
La comprensione delle quantità di spazio di archiviazione seguenti è importante per la gestione dello spazio file di un pool elastico.
| Quantità di pool elastico | Definizione | Commenti |
|---|---|---|
| Spazio dati usato | Somma dello spazio dati usato da tutti i database nel pool elastico. | |
| Spazio dati allocato | Somma dello spazio dati allocato da tutti i database nel pool elastico. | |
| Spazio dati allocato ma non usato | Differenza tra la quantità di spazio dati allocato e lo spazio dati usato da tutti i database nel pool elastico. | Questa quantità rappresenta la quantità massima di spazio allocato per il pool elastico che può essere recuperata compattando i file di dati del database. |
| Dimensioni massime dei dati | Quantità massima di spazio dati che può essere usata dal pool elastico per tutti i rispettivi database. | Lo spazio allocato per il pool elastico non deve superare le dimensioni massime del pool elastico. Se si verifica questa condizione, lo spazio allocato e non usato può essere recuperato compattando i file di dati del database. |
Nota
Il messaggio di errore "Il pool elastico ha raggiunto il limite di archiviazione" indica che gli oggetti di database sono stati allocati abbastanza spazio per soddisfare il limite di archiviazione del pool elastico, ma potrebbe esserci spazio inutilizzato nell'allocazione dello spazio dati. Prendere in considerazione l'aumento del limite di spazio di archiviazione del pool elastico o come soluzione a breve termine, liberando spazio dati usando gli esempi in Recuperare lo spazio allocato inutilizzato. È anche consigliabile considerare il potenziale impatto negativo della compattazione dei file di database, vedere in Manutenzione dell'indice dopo la compattazione.
Eseguire una query su un pool elastico per ottenere informazioni sullo spazio di archiviazione
Le query seguenti possono essere usate per determinare le quantità di spazio di archiviazione per un pool elastico.
Spazio dati del pool elastico usato
Modificare la query seguente per restituire la quantità di spazio dati del pool elastico usato. L'unità di misura dei risultati di query è costituita da MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Spazio di dati del pool elastico allocato e spazio allocato non usato
Modificare gli esempi seguenti per restituire una tabella che elenca lo spazio allocato e lo spazio allocato non usato per ogni database in un pool elastico. La tabella dispone i database in ordine decrescente in base alla quantità di spazio allocato non usato. L'unità di misura dei risultati di query è costituita da MB.
I risultati delle query per determinare lo spazio allocato per ogni database nel pool possono essere sommati per determinare lo spazio totale allocato per il pool elastico. Lo spazio allocato del pool elastico non deve superare le dimensioni massime del pool elastico.
Importante
Il modulo Azure Resource Manager di PowerShell è ancora supportato da Database SQL di Azure, ma tutte le attività di sviluppo future sono incentrate sul modulo Az.Sql. Il modulo AzureRM continuerà a ricevere correzioni di bug almeno fino a dicembre 2020. Gli argomenti per i comandi nei moduli Az e AzureRm sono sostanzialmente identici. Per altre informazioni sulla compatibilità, vedere Introduzione del nuovo modulo Az di Azure PowerShell.
Lo script di PowerShell richiede il modulo SQL Server PowerShell. Vedere Scaricare il modulo PowerShell per l'installazione.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
Lo screenshot seguente mostra un esempio di output dello script:

Dimensioni massime dei dati del pool elastico
Modificare la query T-SQL seguente per restituire le dimensioni massime dei dati del pool elastico. L'unità di misura dei risultati di query è costituita da MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Recuperare lo spazio allocato non usato
Importante
I comandi di compattazione influiscono sulle prestazioni del database mentre è in esecuzione e, se possibile, dovrebbero essere eseguiti in periodi di utilizzo ridotto.
Compattare i file di dati
A causa di un potenziale impatto sulle prestazioni del database, database SQL di Azure non compatta automaticamente i file di dati. I clienti possono tuttavia compattare i file di dati autonomamente quando preferiscono. Non si tratta di un'operazione pianificata regolarmente, ma piuttosto di un evento singolo in risposta a una riduzione significativa del consumo di spazio usato dai file di dati.
Suggerimento
Non è consigliabile compattare i file di dati se il normale carico di lavoro dell'applicazione causa l'aumento delle dimensioni dei file fino a raggiungere le stesse dimensioni allocate.
In database SQL di Azure, per compattare i file è possibile usare uno dei comandi DBCC SHRINKDATABASE o DBCC SHRINKFILE:
DBCC SHRINKDATABASEcompatta tutti i file di dati e di resoconto in un database usando un singolo comando. Il comando compatta un file di dati alla volta e può richiedere molto tempo per i database di dimensioni maggiori. Compatta anche il file di resoconto, che in genere non è necessario perché database SQL di Azure compatta automaticamente i file di log in base alle esigenze.- Il comando
DBCC SHRINKFILEsupporta scenari più avanzati:- Può scegliere come destinazione singoli file in base alle esigenze, invece di compattare tutti i file nel database.
- Ogni comando
DBCC SHRINKFILEpuò essere eseguito in parallelo con altri comandiDBCC SHRINKFILEper compattare più file contemporaneamente e ridurre il tempo totale di compattazione, a scapito di un utilizzo più elevato delle risorse e una maggiore probabilità di bloccare le query utente, se vengono eseguite durante la compattazione.- La compattazione di più file di dati contemporaneamente consente di completare l'operazione di compattazione più velocemente. Se si usa la compattazione del file di dati simultaneo, è possibile osservare il blocco temporaneo di una richiesta di compattazione da un'altra.
- Se la parte finale del file non contiene dati, può ridurre le dimensioni del file allocate molto più velocemente specificando l'argomento
TRUNCATEONLY. Questo non richiede lo spostamento dei dati all'interno del file.
- Per ulteriori informazioni su questi comandi di compattazione, vedere DBCC SHRINKDATABA edizione Standard e DBCC SHRINKFILE.
- Le operazioni di compattazione di database e file sono supportati in anteprima per database SQL di Azure Hyperscale. Per altre informazioni, vedere Compattazione per il database SQL di Azure Hyperscale.
Gli esempi seguenti devono essere eseguiti durante la connessione al database utente di destinazione, non al database master.
Per usare DBCC SHRINKDATABASE per compattare tutti i file di dati e di resoconto in un determinato database:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
In database SQL di Azure un database può avere uno o più file di dati, creati automaticamente man mano che aumentano i dati. Per determinare il layout del file del database, incluse le dimensioni usate e allocate di ogni file, eseguire una query sulla vista del catalogo di sys.database_files usando lo script di esempio seguente:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
È possibile eseguire una compattazione su un solo file tramite il comando DBCC SHRINKFILE, ad esempio:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
È anche consigliabile tenere presente il potenziale impatto negativo sulle prestazioni della compattazione dei file di database, come descritto in Manutenzione dell'indice dopo la compattazione.
Compattare il file registro transazioni
A differenza dei file di dati, database SQL di Azure compatta automaticamente i file registro transazioni per evitare un utilizzo eccessivo dello spazio che può causare errori di spazio insufficiente. In genere non è necessario che i clienti compattino il file registro transazioni.
Nei livelli di servizio Premium e Business Critical, se il log delle transazioni diventa di grandi dimensioni, può contribuire in modo significativo al consumo di archiviazione locale verso il limite massimo di archiviazione locale. Se il consumo di archiviazione locale è vicino al limite, i clienti possono scegliere di compattare il log delle transazioni usando il comando DBCC SHRINKFILE , come illustrato nell'esempio seguente. Questa operazione rilascia l'archiviazione locale non appena il comando viene completato, senza attendere l'operazione di compattazione automatica periodica.
L'esempio seguente deve essere eseguito durante la connessione al database utente di destinazione, non al database master.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Compattazione automatica
In alternativa alla compattazione manuale dei file di dati, è possibile abilitare la compattazione automatica per un database. Può essere però meno efficace nel recupero dello spazio file rispetto a DBCC SHRINKDATABASE e DBCC SHRINKFILE.
Per impostazione predefinita, e come consigliato per la maggior parte dei database, auto_shrink è disabilitato. Se si rende necessario abilitare la compattazione automatica, è consigliabile disabilitarla dopo aver raggiunto gli obiettivi di gestione dello spazio, invece di mantenerla abilitata in modo permanente. Per altre informazioni, vedere Considerazioni per AUTO_SHRINK.
Ad esempio, la riduzione automatica può essere utile nello scenario specifico in cui un pool elastico contiene molti database che riscontrano una crescita significativa e una riduzione significativa dello spazio dei file di dati usato, causando l'avvicinamento del limite massimo di dimensioni del pool. Non si tratta di uno scenario comune.
Per abilitare auto_shrink, eseguire il comando seguente una volta connessi al database (non nel database master).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Per altre informazioni su questo comando, vedere Opzioni ALTER DATABASE SET.
Manutenzione dell'indice dopo la compattazione
Al termine di un'operazione di compattazione rispetto ai file di dati, gli indici potrebbero essere frammentati. In questo modo si riduce l'efficacia dell'ottimizzazione delle prestazioni per determinati carichi di lavoro, ad esempio le query che usano analisi di grandi dimensioni. Se si verifica una riduzione del livello delle prestazioni dopo il completamento dell'operazione di compattazione, prendere in considerazione la possibilità di eseguire la manutenzione degli indici ricostruendoli. Tenere presente che le ricompilazioni dell'indice richiedono spazio disponibile nel database e pertanto lo spazio allocato può aumentare, contrastando l'effetto della compattazione.
Per altre informazioni sulla manutenzione degli indici, vedere Ottimizzare la manutenzione degli indici per migliorare le prestazioni delle query e ridurre il consumo di risorse.
Compattare database di grandi dimensioni
Quando lo spazio allocato del database è in centinaia di gigabyte o superiore, la compattazione potrebbe richiedere un tempo significativo per il completamento, spesso misurato in ore o giorni per i database da più terabyte. Esistono tuttavia ottimizzazioni dei processi e procedure consigliate per rendere questa operazione più efficiente e con un impatto minore sui carichi di lavoro delle applicazioni.
Previsione di utilizzo dello spazio di acquisizione
Prima di iniziare la compattazione, acquisire lo spazio corrente utilizzato e allocato in ogni file di database eseguendo la query di utilizzo dello spazio seguente:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Al termine della compattazione, è possibile eseguire di nuovo questa query e confrontare il risultato con la previsione iniziale.
Troncare file di dati
È consigliabile eseguire prima la compattazione per ogni file di dati con il parametro TRUNCATEONLY. In questo modo, se uno spazio allocato ma non usato si trova alla fine del file, viene rimosso rapidamente senza spostare dati. Il comando di esempio seguente tronca il file di dati con file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Dopo aver eseguito questo comando per ogni file di dati, è possibile eseguire nuovamente la query sull'utilizzo dello spazio per visualizzare la riduzione dello spazio allocato, se presente. È anche possibile visualizzare lo spazio allocato per il database nel portale di Azure.
Valutare la densità della pagina dell'indice
Se il troncamento dei file di dati non ha generato una riduzione sufficiente dello spazio allocato, sarà necessario compattare i file di dati. Tuttavia, come passaggio facoltativo ma consigliato, è necessario prima determinare la densità media delle pagine per gli indici all'interno del database. Per la stessa quantità di dati, la compattazione verrà completata più velocemente se la densità di pagina è elevata, perché dovrà spostare meno pagine. Se la densità di pagina è bassa per alcuni indici, si consiglia di eseguire operazioni di manutenzione su questi indici per aumentare la densità di pagina prima di compattare i file di dati. In questo modo si otterrà anche una compattazione più profonda dello spazio di archiviazione allocato.
Per determinare la densità di pagina per tutti gli indici nel database, usare la query seguente. La densità di pagina viene segnalata nella colonna avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Se sono presenti indici con un numero elevato di pagine con densità di pagina inferiore al 60-70%, valutare la possibilità di ricompilare o riorganizzare questi indici prima di compattare i file di dati.
Nota
Per i database più grandi, la query per determinare la densità delle pagine potrebbe richiedere molto tempo (ore) per il completamento. Inoltre, la ricompilazione o la riorganizzazione di indici di grandi dimensioni richiede tempi e utilizzi sostanziali delle risorse. C'è un compromesso tra la spesa aggiuntiva per aumentare la densità di pagina da una parte e ridurre la durata della compattazione e ottenere un risparmio di spazio più elevato su un altro.
Se sono presenti più indici con densità di pagina bassa, è possibile ricompilarli in parallelo in più sessioni di database per velocizzare il processo. Tuttavia, assicurarsi di non avvicinarsi ai limiti delle risorse del database in questo modo e di lasciare sufficiente capacità aggiuntiva delle risorse per i carichi di lavoro delle applicazioni che potrebbero essere in esecuzione. Monitorare l'utilizzo delle risorse (CPU, I/O dei dati, I/O dei log) nel portale di Azure o usando la vista sys.dm_db_resource_stats e avviare ricompilazione parallele aggiuntive solo se l'utilizzo delle risorse in ognuna di queste dimensioni rimane sostanzialmente inferiore al 100%. Se l'utilizzo di CPU, l'I/O dei dati o l'I/O dei log è pari al 100%, è possibile aumentare le prestazioni del database per avere più core CPU e aumentare la velocità effettiva di I/O. Questo potrebbe consentire la ricompilazione parallela aggiuntiva per completare il processo più velocemente.
Comando di ricompilazione dell'indice di esempio
Di seguito è riportato un comando di esempio per ricompilare un indice e aumentarne la densità di pagina usando l'istruzione ALTER INDEX:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Questo comando avvia una ricompilazione dell'indice online e ripristinabile. Ciò consente ai carichi di lavoro simultanei di continuare a usare la tabella mentre la ricompilazione è in corso e consente di riprendere la ricompilazione se viene interrotta per qualsiasi motivo. Tuttavia, questo tipo di ricompilazione è più lento rispetto a una ricompilazione offline, che blocca l'accesso alla tabella. Se nessun altro carico di lavoro deve accedere alla tabella durante la ricompilazione, impostare le opzioni ONLINE e RESUMABLE su OFF e rimuovere la clausola WAIT_AT_LOW_PRIORITY.
Per maggiori informazioni sulla manutenzione degli indici, vedere Ottimizzare la manutenzione degli indici per migliorare le prestazioni delle query e ridurre il consumo di risorse.
Compattare più file di dati
Come indicato in precedenza, la compattazione con lo spostamento dei dati è un processo a esecuzione prolungata. Se nel database sono presenti più file di dati, è possibile velocizzare il processo compattando più file di dati in parallelo. Per farlo, aprire più sessioni di database e usare DBCC SHRINKFILE in ogni sessione con un valore di file_id diverso. Analogamente alla ricompilazione degli indici in precedenza, assicurarsi di disporre di sufficienti capacità aggiuntive per le risorse (CPU, I/O dati, I/O log) prima di avviare ogni nuovo comando di compattazione parallela.
Il comando di esempio seguente riduce il file di dati con file_id 4, spostando le pagine all'interno del file nel tentativo di ridurre le dimensioni allocate a 52.000 MB:
DBCC SHRINKFILE (4, 52000);
Per ridurre lo spazio allocato per il file al minimo possibile, eseguire l'istruzione senza specificare le dimensioni di destinazione:
DBCC SHRINKFILE (4);
Se un carico di lavoro è in esecuzione simultaneamente alla compattazione, può iniziare a usare lo spazio di archiviazione liberato dalla compattazione prima del completamento della stessa e troncare il file. In questo caso, la compattazione non sarà in grado di ridurre lo spazio allocato alla destinazione specificata.
È possibile attenuare questo problema compattando ogni file in passaggi più piccoli. Ciò significa che nel comando DBCC SHRINKFILE si imposta la destinazione leggermente inferiore rispetto allo spazio allocato corrente per il file come appare nei risultati della query per l'utilizzo dello spazio previsto. Ad esempio, se lo spazio allocato per il file con file_id 4 è 200.000 MB e si vuole ridurlo a 100.000 MB, è possibile impostare prima la destinazione su 170.000 MB:
DBCC SHRINKFILE (4, 170000);
Una volta che il comando è stato eseguito, il file verrà troncato e le dimensioni allocate saranno ridotte a 170.000 MB. È quindi possibile ripetere questo comando, impostando la destinazione prima su 140.000 MB, quindi su 110.000 MB e così via, fino a quando il file non viene ridotto alle dimensioni desiderate. Se il comando viene completato ma il file non viene troncato, usare passaggi più piccoli, ad esempio 15.000 MB anziché 30.000 MB.
Per monitorare lo stato di compattazione per tutte le sessioni di compattazione in esecuzione simultanea, è possibile usare la query seguente:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Nota
Lo stato di avanzamento della compattazione può essere non lineare e il valore nella colonna percent_complete può rimanere praticamente invariato per lunghi periodi di tempo, anche se la compattazione è ancora in corso.
Una volta completata la compattazione per tutti i file di dati, eseguire di nuovo la query sull'utilizzo dello spazio (o verificare nel portale di Azure) per determinare la riduzione risultante delle dimensioni di archiviazione allocate. Se esiste ancora una grande differenza tra lo spazio usato e lo spazio allocato, è possibile ricompilare gli indici come indicato in precedenza. Questo può aumentare temporaneamente lo spazio allocato, ma la compattazione dei file di dati dopo la ricompilazione degli indici dovrebbe comportare una riduzione ulteriore dello spazio allocato.
Errori temporanei durante la compattazione
In alcuni casi, un comando di compattazione potrebbe non riuscire a causa di diversi errori, ad esempio timeout e deadlock. In generale, questi errori sono temporanei e non si verificano di nuovo se si ripete lo stesso comando. Se la compattazione ha esito negativo con un errore, lo stato di avanzamento apportato finora nelle pagine di dati in movimento viene mantenuto e lo stesso comando di compattazione può essere eseguito di nuovo per continuare a compattare il file.
Lo script di esempio seguente illustra come eseguire la compattazione in un ciclo di ripetizione dei tentativi per riprovare automaticamente fino a un numero configurabile di volte in cui si verifica un errore di timeout o un errore di deadlock. Questo approccio di ripetizione dei tentativi è applicabile a molti altri errori che potrebbero verificarsi durante la compattazione.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Oltre agli errori di timeout e di deadlock, la compattazione può riscontrare errori a causa di determinati problemi noti.
I passaggi restituiti e di mitigazione degli errori sono i seguenti:
- Numero errore: 49503, messaggio di errore: %.*ls: Impossibile spostare la pagina %d:%d perché si tratta di una pagina dell'archivio versioni persistente fuori riga. Motivo di blocco della pagina: %ls. Timestamp di blocco della pagina: %I64d.
Questo errore si verifica quando sono presenti transazioni attive a esecuzione prolungata che hanno generato versioni di riga nell'archivio versioni persistenti (PVS). Le pagine contenenti queste versioni di riga non possono essere spostate tramite compattazione, pertanto non è possibile eseguire lo stato di avanzamento e non riesce con questo errore.
Per attenuare il problema, è necessario attendere il completamento di queste transazioni a esecuzione prolungata. In alternativa, è possibile identificare e terminare queste transazioni a esecuzione prolungata, ma ciò può influire sull'applicazione se non gestisce correttamente gli errori delle transazioni. Un modo per trovare transazioni a esecuzione prolungata consiste nell'eseguire la query seguente nel database in cui è stato eseguito il comando compattare:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
È possibile terminare una transazione usando il comando KILL e specificando il valore session_id associato dal risultato della query:
KILL 4242; -- replace 4242 with the session_id value from query results
Attenzione
La terminazione di una transazione può influire negativamente sui carichi di lavoro.
Una volta terminate o completate le transazioni a esecuzione prolungata, un'attività in background interna eseguirà la pulizia delle versioni di riga non necessarie dopo un certo periodo di tempo. È possibile monitorare le dimensioni PVS per misurare lo stato di avanzamento della pulizia usando la query seguente. Eseguire la query nel database in cui è stato eseguito il comando compattare:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Una volta che le dimensioni PVS segnalate nella colonna persistent_version_store_size_gb sono notevolmente ridotte rispetto alle dimensioni originali, la ripetizione della compattazione dovrebbe avere esito positivo.
- Numero errore: 5223, messaggio di errore: %.*ls: Impossibile deallocare la pagina vuota %d:%d.
Questo errore può verificarsi se sono in corso operazioni di manutenzione dell'indice, ad esempio ALTER INDEX. Ripetere il comando compattare dopo il completamento di queste operazioni.
Se questo errore persiste, potrebbe essere necessario ricompilare l'indice associato. Per trovare l'indice da ricompilare, eseguire la query seguente nello stesso database in cui è stato eseguito il comando compattare:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Prima di eseguire questa query, sostituire i segnaposto <file_id> e <page_id> con i valori effettivi del messaggio di errore ricevuto. Ad esempio, se il messaggio è Non è stato possibile deallocare la pagina vuota 1:62669, quindi <file_id> è 1 e <page_id> è 62669.
Ricompilare l'indice identificato dalla query e ripetere il comando compattare.
- Numero errore: 5201, messaggio di errore: DBCC SHRINKDATABASE: il file con ID %d del database con ID %d è stato ignorato perché lo spazio disponibile non è sufficiente per il recupero.
Questo errore indica che il file di dati non può essere compattato ulteriormente. È possibile passare al file di dati successivo.
Contenuto correlato
Per informazioni sulle dimensioni massime dei database, vedere:
- Limiti del modello di acquisto basato su vCore per il database SQL di Azure per un database singolo
- Limiti di risorse per i database singoli usando il modello di acquisto basato su DTU
- Limiti del modello di acquisto basato su vCore per il database SQL di Azure per i pool elastici
- Limiti di risorse per i pool elastici usando il modello di acquisto basato su DTU