Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() Database SQL di Azure
Database SQL di Azure
Importante
La funzione SQL Data Sync verrà ritirata il 30 settembre 2027. Valutare la possibilità di eseguire la migrazione a soluzioni alternative per la replica/sincronizzazione dei dati.
In questa esercitazione si imparerà a configurare la sincronizzazione dati SQL creando un gruppo di sincronizzazione che contiene sia istanze del database SQL di Azure che istanze di SQL Server. Il gruppo di sincronizzazione ha una configurazione personalizzata ed esegue la sincronizzazione in base alla pianificazione impostata dall'utente.
Questa esercitazione presuppone che tu abbia almeno un po' di esperienza con i Database SQL e SQL Server.
Per una panoramica di Sincronizzazione dati SQL, vedere Che cos’è Sincronizzazione dati SQL per Azure?
Per esempi di PowerShell su come configurare Sincronizzazione dati SQL, vedere Usare PowerShell per eseguire la sincronizzazione tra più database nel database SQL di Azure o tra database nel database SQL di Azure e in SQL Server.
Il database hub è un endpoint centrale della topologia di sincronizzazione, in cui per un gruppo di sincronizzazione sono presenti più endpoint del database. Tutti gli altri database membri con endpoint nel gruppo di sincronizzazione eseguono la sincronizzazione con il database hub. La sincronizzazione dati SQL è supportata solo nel database SQL di Azure. Il database hub deve essere un database SQL di Azure.
Hyperscale del database SQL di Azure è supportato solo come database membro, non come database hub.
Creare un gruppo di sincronizzazione
Vai al portale di Azure. Cercare e selezionare Database SQL per trovare un database SQL di Azure esistente.
Selezionare il database esistente che si vuole usare come database hub per la sincronizzazione dei dati.
Dal menu risorse di Database SQL per il database selezionato, in Gestione dei dati scegliere Sincronizza con altri database.
Nella pagina Sincronizza con altri database selezionare Nuovo gruppo di sincronizzazione. Viene aperta la pagina Crea gruppo di sincronizzazione dati.
Nella pagina Crea gruppo di sincronizzazione dati cambiare le impostazioni seguenti:
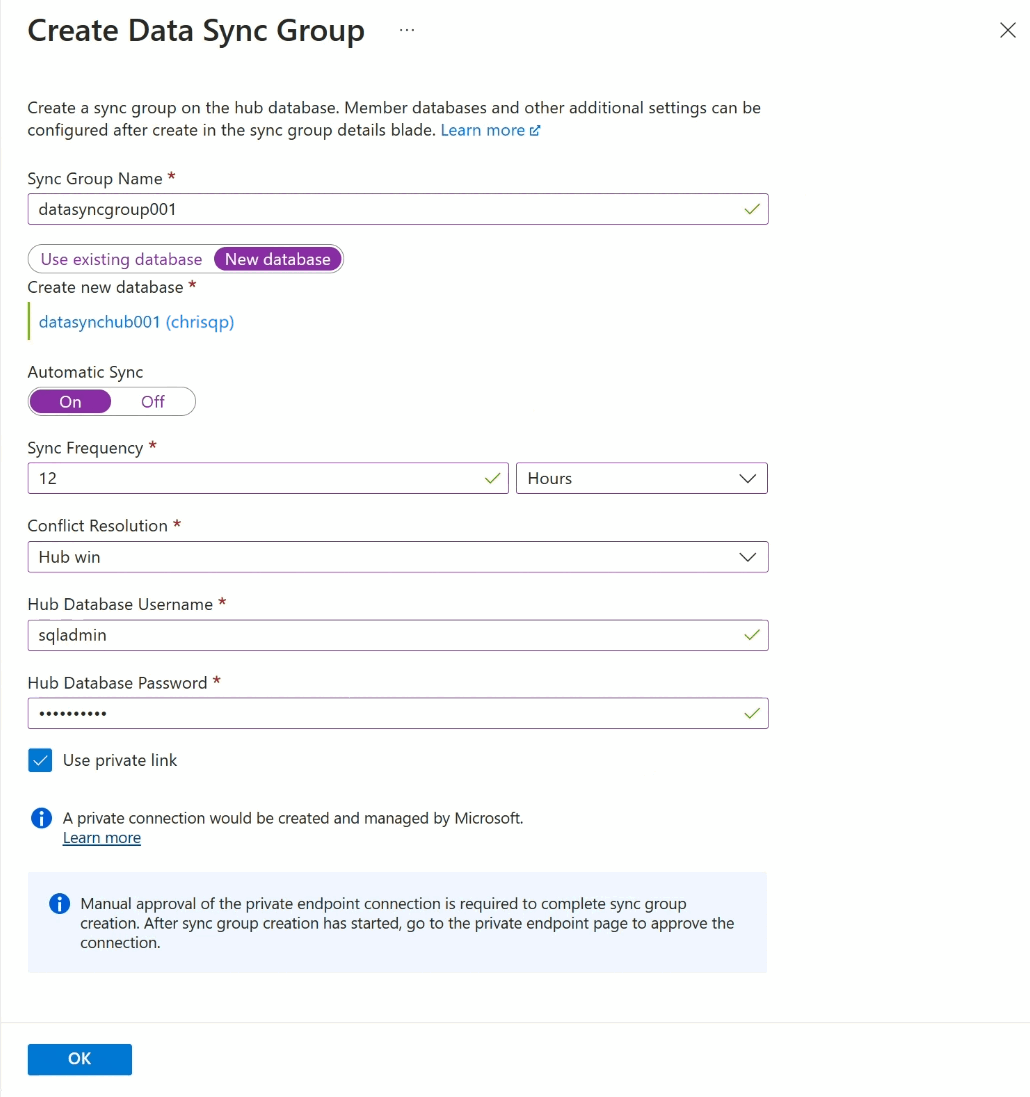
Impostazione Descrizione Nome gruppo di sincronizzazione Immettere un nome per il nuovo gruppo di sincronizzazione. Questo nome è distinto dal nome del database stesso. Database dei metadati di sincronizzazione Scegliere se creare un nuovo database (scelta consigliata) o usare un database esistente da utilizzare come Database dei metadati di sincronizzazione.
Microsoft consiglia di creare un nuovo database vuoto da usare come Database dei metadati di sincronizzazione. La sincronizzazione dati crea tabelle in questo database ed esegue un carico di lavoro frequente. Questo database viene condiviso come database dei metadati di sincronizzazione per tutti i gruppi di sincronizzazione in un'area e in una sottoscrizione selezionate. Non è possibile modificare il database o il nome di questo senza rimuovere tutti i gruppi e gli agenti di sincronizzazione nell'area.
Se si sceglie di creare un nuovo database, selezionare Nuovo database. Selezionare Configurare le impostazioni del database. Nella pagina Database SQL, specificare un nome per il nuovo database SQL di Azure, configurarlo e selezionare OK.
Se si sceglie Usa database esistente, selezionare il database dall'elenco a discesa Database dei metadati di sincronizzazione.Sincronizzazione automatica Selezionare Sì o No.
Se si sceglie Sì, immettere un numero e selezionare Secondi, Minuti, Ore o Giorni nella sezione Frequenza sincronizzazione.
La prima sincronizzazione inizia al termine dell'intervallo di tempo selezionato dopo il salvataggio della configurazione.Risoluzione dei conflitti Selezionare Hub vince o Membro vince.
Vittoria dell'hub significa che, quando si verifica un conflitto, i dati nel database hub sovrascrivono i dati conflittuali nel database membro.
Vittoria del membro significa che, quando si verifica un conflitto, i dati nel database del membro sovrascrivono i dati in conflitto nel database hub.Nome utente del database hub e password del database hub Specificare il nome utente e la password per l'account di accesso autenticato SQL dell'amministratore del server per il database Hub. Si tratta del nome utente e della password dell'amministratore del server per lo stesso server logico SQL di Azure su cui hai iniziato. L'autenticazione Microsoft Entra (in precedenza Azure Active Directory) non è supportata. Usare il collegamento privato Scegliere un endpoint privato gestito dal servizio per stabilire una connessione sicura tra il servizio di sincronizzazione e il database hub. Selezionare OK e attendere che il gruppo di sincronizzazione venga creato e distribuito.
Nella pagina Nuovo gruppo di sincronizzazione, se è stata selezionata l'opzione Usa collegamento privato, sarà necessario approvare la connessione all'endpoint privato. Il collegamento nel messaggio di informazioni consente di passare all'esperienza di connessione all'endpoint privato in cui è possibile approvare la connessione.
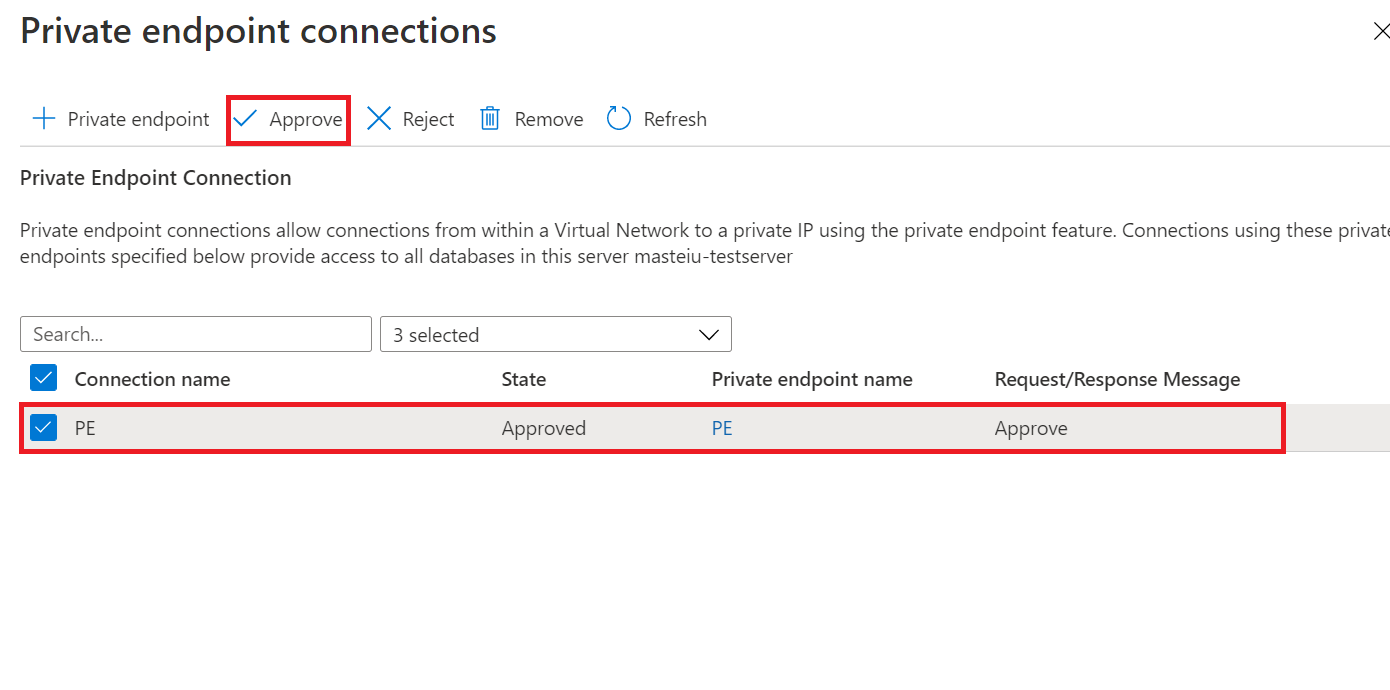
Nota
I collegamenti privati per il gruppo di sincronizzazione e i membri di sincronizzazione devono essere creati, approvati e disabilitati separatamente.


Aggiungere membri di sincronizzazione
Dopo aver creato e distribuito il nuovo gruppo di sincronizzazione, aprire il gruppo di sincronizzazione e accedere alla pagina Database , in cui verranno selezionati i membri di sincronizzazione.
Nota
Per aggiornare o inserire il nome utente e la password nel database hub, passare alla sezione Database hub nella pagina Seleziona membri di sincronizzazione.
Aggiungere un database in database SQL di Azure come membro a un gruppo di sincronizzazione
Nella sezione Seleziona membro sincronizzazione, aggiungere facoltativamente un database nel database SQL di Azure al gruppo di sincronizzazione selezionando Aggiungi un database di Azure. Verrà aperta la pagina Configura database di Azure.
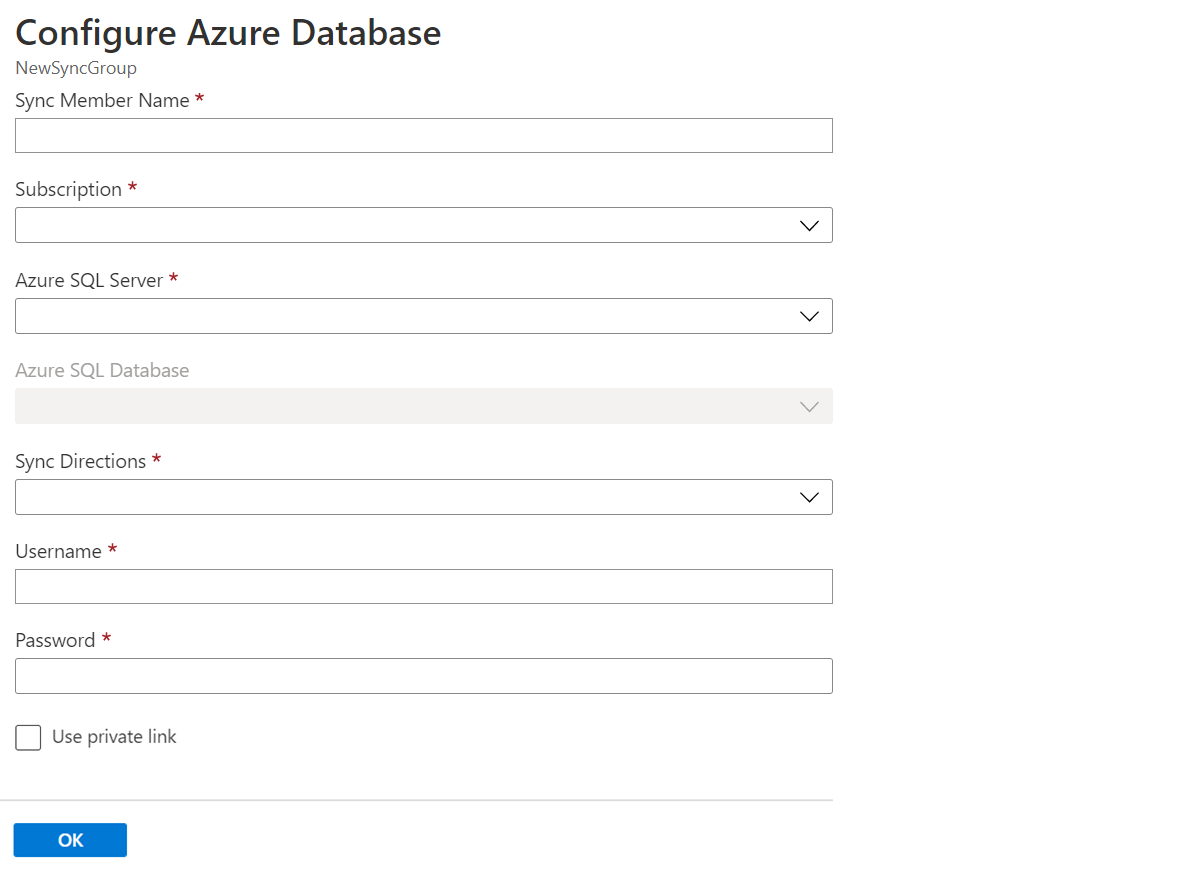
Nella pagina Configura database SQL di Azure cambiare le impostazioni seguenti:
Impostazione Descrizione Nome membro di sincronizzazione Specificare un nome per il nuovo membro di sincronizzazione. Questo nome è distinto dal nome del database. Abbonamento Selezionare la sottoscrizione di Azure associata ai fini della fatturazione. Azure SQL Server Selezionare il server esistente. Database SQL di Azure Selezionare il database esistente nel database SQL. Direzioni sincronizzazione La direzione di sincronizzazione può essere dall'hub al membro o dal membro all'hub o entrambe. Selezionare Dall'hub, All'hub o Sincronizzazione bidirezionale. Per altre informazioni, vedere Funzionamento. Nome utente e Password Immettere le credenziali esistenti per il server in cui si trova il database membro. Non immettere nuove credenziali in questa sezione. Usare il collegamento privato Scegliere un endpoint privato gestito dal servizio per stabilire una connessione sicura tra il servizio di sincronizzazione e il database membro. Selezionare OK e attendere che il nuovo membro di sincronizzazione venga creato e distribuito.

Aggiungere un database in un'istanza di SQL Server come membro di un gruppo di sincronizzazione
Nella sezione Database membro aggiungere facoltativamente un’istanza di SQL Server al gruppo di sincronizzazione selezionando Aggiungi un database locale.
Verrà visualizzata la pagina Configura in sede, in cui è possibile eseguire le operazioni seguenti:
Selezionare Scegliere il gateway dell'agente di sincronizzazione. Verrà aperta la pagina Seleziona agente di sincronizzazione.
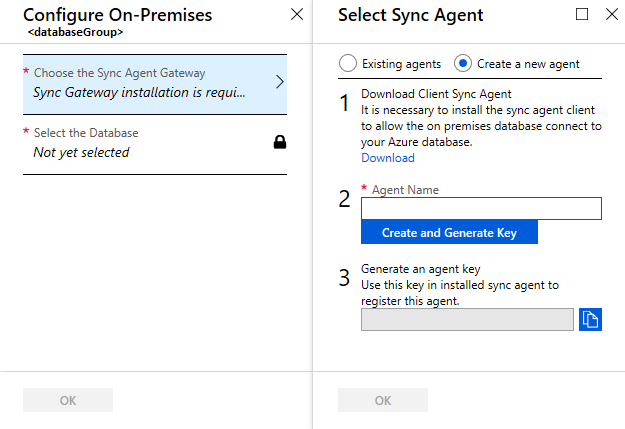
Nella pagina Seleziona agente di sincronizzazione scegliere se usare un agente esistente o crearne uno.
Se si sceglie Agenti esistenti, selezionare l'agente esistente dall'elenco.
Se si sceglie Crea un nuovo agente, eseguire le operazioni seguenti:
Scaricare l'agente di sincronizzazione dati dal collegamento disponibile e installarlo in un server diverso da quello in cui si trova SQL Server. È anche possibile scaricare l'agente direttamente da SQL Azure Data Sync Agent. Per le procedure consigliate sull'agente client di sincronizzazione, vedere Procedure consigliate per sincronizzazione dati SQL di Azure.
Importante
È necessario aprire la porta TCP 1433 in uscita nel firewall per consentire all'agente client di comunicare con il server.
Immetti un Nome agente.
Seleziona Crea e Genera Chiave e copia la chiave dell'agente negli Appunti.
Selezionare OK per chiudere la pagina Seleziona agente di sincronizzazione.
Sul server dove è installato l'agente client di sincronizzazione, individuare ed eseguire l'app Agente di sincronizzazione client.
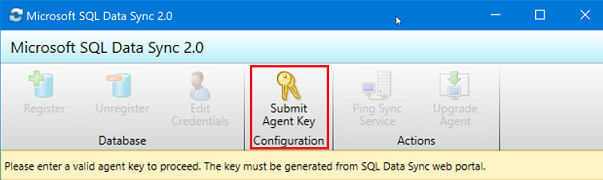
Nell'app dell'agente di sincronizzazione selezionare Submit Agent Key (Invia chiave agente). Verrà aperta la finestra di dialogo Sync Metadata Database Configuration (Configurazione del database dei metadati di sincronizzazione).
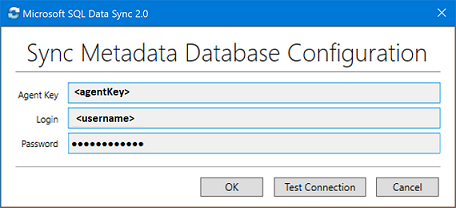
Nella finestra di dialogo Sync Metadata Database Configuration (Configurazione del database dei metadati di sincronizzazione) incollare la chiave dell'agente copiata dal portale di Azure. Specificare anche le credenziali esistenti per il server in cui si trova il database dei metadati di sincronizzazione. Selezionare OK e attendere che la configurazione venga completata.
Nota
Se viene visualizzato un errore del firewall, creare una regola del firewall in Azure per consentire il traffico in ingresso dal computer SQL Server. È possibile creare manualmente la regola nel portale o in SQL Server Management Studio (SSMS). In SSMS connettersi al database hub in Azure immettendone il nome nel formato
<hub_database_name>.database.windows.net.Selezionare Registra per registrare un database SQL Server con l'agente. Verrà aperta la finestra di dialogo Configurazione di SQL Server.
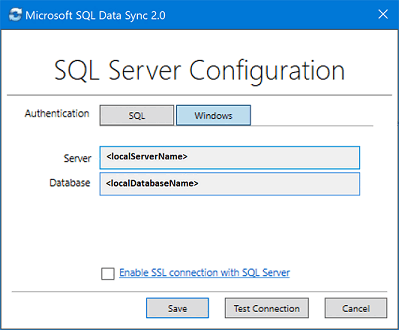
Nella finestra di dialogo Configurazione di SQL Server scegliere di effettuare la connessione tramite l'autenticazione di SQL Server o l'autenticazione di Windows. Se si sceglie l'autenticazione di SQL Server, immettere le credenziali esistenti. Specificare il nome dell'istanza di SQL Server e il nome del database che si vuole sincronizzare e selezionare Test connessione per testare le impostazioni. Selezionare quindi Salva. Il database registrato verrà visualizzato nell'elenco.
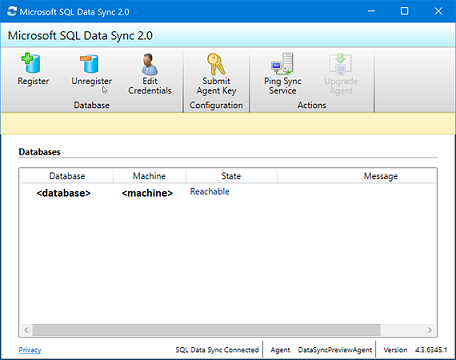
Chiudere l'app dell'agente di sincronizzazione client.
Nel portale di Azure, nella pagina Configura On-Premises, selezionare Seleziona il database.
Nella pagina Seleziona database, nel campo Nome membro di sincronizzazione, specificare un nome per il nuovo membro di sincronizzazione. Questo nome è distinto dal nome del database stesso. Selezionare il database nell'elenco. Nel campo Direzioni sincronizzazione selezionare Sincronizzazione bidirezionale, Verso l'hub o Dall'hub.
Selezionare OK per chiudere la finestra Seleziona database. Selezionare quindi OK per chiudere la pagina Configura database locale e attendere che il nuovo membro di sincronizzazione venga creato e distribuito. Selezionare infine OK per chiudere la pagina Selezionare i membri di sincronizzazione.
Nota
Per connettersi alla sincronizzazione dati SQL e all'agente locale, aggiungere il proprio nome utente al ruolo DataSync_Executor. La Sincronizzazione dei dati crea questo ruolo sull'istanza di SQL Server.
Configurare il gruppo di sincronizzazione
Dopo aver creato e distribuito i nuovi membri del gruppo di sincronizzazione, passare alla sezione Tabelle nella pagina Gruppo di sincronizzazione database.

Nella pagina Tabelle selezionare un database dall'elenco dei membri del gruppo di sincronizzazione e selezionare Aggiorna schema. Attendere alcuni minuti di ritardo nello schema di aggiornamento, il ritardo potrebbe essere di alcuni minuti più lungo se si usa il collegamento privato.
Nell'elenco selezionare le tabelle da sincronizzare. Per impostazione predefinita, vengono selezionate tutte le colonne, quindi disabilitare la casella di controllo per le colonne che non si desidera sincronizzare. Assicurarsi di lasciare selezionata la colonna chiave primaria.
Seleziona Salva.
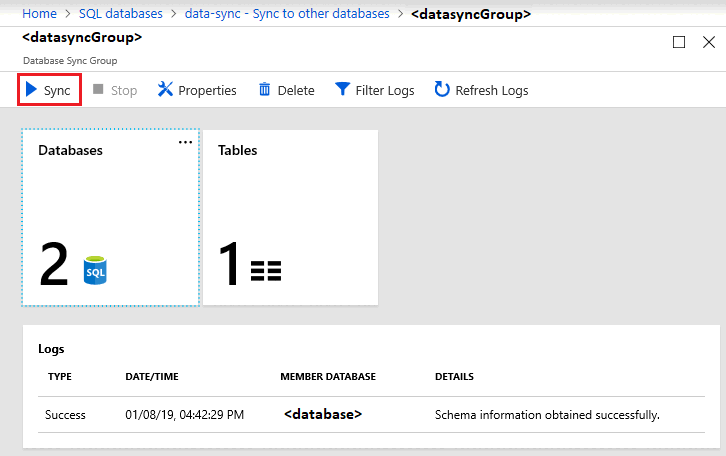
Per impostazione predefinita, i database vengono sincronizzati solo manualmente o tramite pianificazione. Per eseguire una sincronizzazione manuale, passare al database nel database SQL nel portale di Azure, selezionare Sincronizza con altri database e selezionare il gruppo di sincronizzazione. Verrà aperta la pagina Sincronizzazione dati. Seleziona Sincronizza.
Domande frequenti
Questa sezione risponde alle domande frequenti sul servizio sincronizzazione dati SQL di Azure.
La sincronizzazione dati SQL crea tabelle complete?
Se le tabelle dello schema di sincronizzazione non sono presenti nel database di destinazione, la sincronizzazione dati SQL le crea usando le colonne selezionate dall'utente. Questa operazione tuttavia non ha come risultato uno schema pienamente fedele per i motivi seguenti:
- Nella tabella di destinazione vengono create solo le colonne selezionate dall'utente. Le colonne non selezionate vengono ignorate.
- Nella tabella di destinazione vengono creati solo gli indici di colonna selezionati. Per le colonne non selezionate, tali indici vengono ignorati.
- Gli indici nelle colonne di tipo XML non vengono creati.
- I vincoli CHECK non vengono creati.
- I trigger esistenti nelle tabelle di origine non vengono creati.
- Le viste e le procedure memorizzate non vengono create.
A causa di questi limiti, è consigliabile eseguire le operazioni seguenti:
- Per gli ambienti di produzione, crea autonomamente uno schema pienamente fedele.
- Quando si eseguono esperimenti con il servizio, usare la funzionalità di provisioning automatico.
Perché sono visualizzate tabelle non create dall'utente?
La sincronizzazione dati crea tabelle aggiuntive nel database utente per il rilevamento delle modifiche. Non eliminarle o la sincronizzazione dati cesserà di funzionare.
I dati risultano convergenti dopo una sincronizzazione?
Non necessariamente. Si supponga che in un gruppo di sincronizzazione con un hub e tre spoke (A, B e C), le sincronizzazioni siano da hub ad A, da hub a B e da hub a C. Se si apporta una modifica al database A dopo la sincronizzazione da hub ad A, tale modifica viene scritta nei database B e C solo dopo l'attività di sincronizzazione successiva.
Come si applicano a un gruppo di sincronizzazione le modifiche apportate allo schema?
Apportare e propagare tutte le modifiche allo schema manualmente.
- Replicare manualmente le modifiche dello schema all'hub e a tutti i membri di sincronizzazione.
- Aggiornare lo schema di sincronizzazione.
Per aggiungere nuove tabelle e colonne:
Nuove tabelle e colonne non influiscono sulla sincronizzazione corrente e la sincronizzazione dati le ignora fino a quando non vengono aggiunte allo schema di sincronizzazione. Quando si aggiungono nuovi oggetti di database, rispettare questa sequenza:
- Aggiungi nuove tabelle o colonne all'hub e a tutti i membri di sincronizzazione.
- Aggiungere le nuove tabelle o colonne allo schema di sincronizzazione.
- Iniziare a inserire valori nelle nuove tabelle e colonne.
Per cambiare il tipo di dati di una colonna:
Quando si modifica il tipo di dati di una colonna esistente, la sincronizzazione dei dati continua a funzionare, fino a quando i nuovi valori sono conformi al tipo di dati originale definito nello schema di sincronizzazione. Se ad esempio si modifica il tipo nel database di origine da int a bigint, la sincronizzazione dati continua a funzionare fino a quando non si inserisce un valore troppo grande per il tipo di dati int. Per completare la modifica, replicare manualmente la modifica dello schema nell'hub e in tutti i membri di sincronizzazione e quindi aggiornare lo schema di sincronizzazione.
Come si esporta e importa un database con la sincronizzazione dati?
Dopo aver esportato un database come file con estensione .bacpac e dopo aver importato quest'ultimo per creare un database, eseguire le operazioni seguenti per usare la sincronizzazione dati nel nuovo database:
- Pulire gli oggetti di sincronizzazione dati e le tabelle aggiuntive nel nuovo database usando Data Sync complete cleanup.sql. Lo script elimina dal database tutti gli oggetti di sincronizzazione dati richiesti.
- Creare di nuovo il gruppo di sincronizzazione con il nuovo database. Se il gruppo di sincronizzazione precedente non è più necessario, eliminarlo.
Dove è possibile trovare informazioni sull'agente client?
Per le domande frequenti sull'agente client, vedere Domande frequenti sull'agente.
È necessario approvare manualmente il collegamento prima di iniziare a usarlo?
Sì. È necessario approvare manualmente l'endpoint privato gestito dal servizio, nella pagina Connessioni a endpoint privato del portale di Azure durante la distribuzione del gruppo di sincronizzazione o usando PowerShell.
Perché viene visualizzato un errore del firewall quando il processo di sincronizzazione esegue il provisioning del database di Azure?
Questo problema può verificarsi perché le risorse di Azure non sono autorizzate ad accedere al server. Sono disponibili due soluzioni:
Assicurarsi che il firewall nel database di Azure abbia impostato Consenti ai servizi e alle risorse di Azure di accedere a questo server su Sì. Per altre informazioni, vedere Controllo di accesso alla rete del database SQL di Azure.
Configurare un collegamento privato per sincronizzazione dati, diverso da un collegamento privato di Azure. collegamento privato è il modo per creare gruppi di sincronizzazione usando una connessione sicura con i database che si trovino dietro un firewall. Il Collegamento Privato di Sincronizzazione Dati SQL è un endpoint gestito da Microsoft che crea internamente una subnet all'interno della rete virtuale esistente, quindi non è necessario creare un'altra rete virtuale o subnet.
Quali versioni di SQL Server in locale possono far parte di un gruppo di sincronizzazione?
Solo le versioni seguenti di SQL Server in locale possono far parte di un gruppo di sincronizzazione:
- SQL Server 2008
- SQL Server 2008 R2
- SQL Server 2012
- SQL Server 2016
- SQL Server 2017 in Windows
- SQL Server 2019 in Windows
- SQL Server 2022 in Windows
Contenuto correlato
- Che cos'è Sincronizzazione dati SQL per Azure?
- Data Sync Agent per Sincronizzazione dati SQL
- Procedure consigliate per la sincronizzazione dati SQL di Azure
- Risolvere i problemi con Sincronizzazione dati SQL
- Monitorare e ottimizzare le prestazioni in database SQL di Azure e Istanza gestita di SQL di Azure
- Informazioni sul database SQL di Azure
- Gestione del ciclo di vita del database