Automatizzare la replica delle modifiche dello schema nella sincronizzazione dati SQL di Azure
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
Importante
Sincronizzazione dati SQL verrà ritirato il 30 settembre 2027. Valutare la possibilità di eseguire la migrazione a soluzioni alternative per la replica/sincronizzazione dei dati.
Sincronizzazione dati SQL consente agli utenti di sincronizzare dati tra database SQL di Azure e istanze SQL Server locali in una direzione o in entrambe le direzioni. Una dei limiti correnti della sincronizzazione dati SQL è che non supporta la replica delle modifiche dello schema. Ogni volta che si modifica lo schema di tabella, è necessario applicare le modifiche manualmente in tutti gli endpoint, incluso l'hub e tutti i membri, quindi aggiornare lo schema di sincronizzazione.
In questo articolo viene presentata una soluzione per replicare automaticamente le modifiche dello schema in tutti gli endpoint di sincronizzazione dati SQL.
- Questa soluzione usa un trigger DDL per tenere traccia delle modifiche dello schema.
- Il trigger inserisce i comandi di modifica dello schema in una tabella di rilevamento.
- Questa tabella di rilevamento viene sincronizzata con tutti gli endpoint usando il servizio sincronizzazione dati.
- I trigger DML dopo l'inserimento vengono usati per applicare le modifiche dello schema negli altri endpoint.
In questo articolo si usa ALTER TABLE come esempio di modifica dello schema, ma la soluzione funziona anche per altri tipi di modifiche dello schema.
Prima di iniziare a implementare la replica automatizzata delle modifiche dello schema nell'ambiente di sincronizzazione, leggere questo articolo con attenzione, in particolare le sezioni Risoluzione dei problemi e Altre considerazioni. Alcune operazioni di database possono creare problemi nella soluzione descritta in questo articolo. È possibile che vengano richieste ulteriori informazioni di dominio su SQL Server e Transact-SQL per risolvere i problemi.
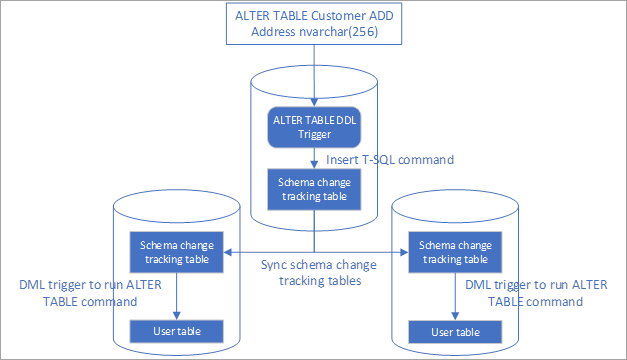
Configurare la replica automatizzata delle modifica dello schema
Creare una tabella per tenere traccia delle modifiche dello schema
Creare una tabella per tenere traccia delle modifiche dello schema in tutti i database nel gruppo di sincronizzazione:
CREATE TABLE SchemaChanges (
ID bigint IDENTITY(1,1) PRIMARY KEY,
SqlStmt nvarchar(max),
[Description] nvarchar(max)
)
In questa tabella è presente una colonna Identity per tenere traccia dell'ordine delle modifiche dello schema. Se necessario, è possibile aggiungere altri campi per registrare ulteriori informazioni.
Creare una tabella per tenere traccia della cronologia delle modifiche dello schema.
In tutti gli endpoint creare una tabella per tenere traccia dell'ID del comando di modifica dello schema applicato più di recente.
CREATE TABLE SchemaChangeHistory (
LastAppliedId bigint PRIMARY KEY
)
GO
INSERT INTO SchemaChangeHistory VALUES (0)
Creare un trigger DDL per ALTER TABLE nel database in cui sono state apportate modifiche dello schema.
Creare un trigger DDL per le operazioni ALTER TABLE. È necessario creare questo trigger solo nel database in cui vengono apportate modifiche dello schema. Per evitare conflitti, consentire solo le modifiche dello schema in un database in un gruppo di sincronizzazione.
CREATE TRIGGER AlterTableDDLTrigger
ON DATABASE
FOR ALTER_TABLE
AS
-- You can add your own logic to filter ALTER TABLE commands instead of replicating all of them.
IF NOT (EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)[1]', 'nvarchar(512)') like 'DataSync')
INSERT INTO SchemaChanges (SqlStmt, Description)
VALUES (EVENTDATA().value('(/EVENT_INSTANCE/TSQLCommand/CommandText)[1]', 'nvarchar(max)'), 'From DDL trigger')
Il trigger inserisce un record nella tabella di rilevamento delle modifiche dello schema per ogni comando ALTER TABLE. Questo esempio aggiunge un filtro per evitare di replicare le modifiche dello schema apportate nello schema DataSync, perché queste sono molto probabilmente effettuate dal servizio di sincronizzazione dati. Aggiungere altri filtri se si vuole replicare solo alcuni tipi di modifiche dello schema.
È possibile anche aggiungere altri trigger per replicare altri tipi di modifiche dello schema. Ad esempio, creare trigger CREATE_PROCEDURE, ALTER_PROCEDURE e DROP_PROCEDURE per replicare le modifiche alle stored procedure.
Creare un trigger in altri endpoint per applicare le modifiche dello schema durante l'inserimento
Questo trigger esegue il comando di modifica dello schema quando viene sincronizzato con altri endpoint. È necessario creare questo trigger in tutti gli endpoint, ad eccezione di quello in cui vengono apportate modifiche dello schema, ovvero nel database in cui è stato creato il trigger DDL AlterTableDDLTrigger nel passaggio precedente.
CREATE TRIGGER SchemaChangesTrigger
ON SchemaChanges
AFTER INSERT
AS
DECLARE @lastAppliedId bigint
DECLARE @id bigint
DECLARE @sqlStmt nvarchar(max)
SELECT TOP 1 @lastAppliedId=LastAppliedId FROM SchemaChangeHistory
SELECT TOP 1 @id = id, @SqlStmt = SqlStmt FROM SchemaChanges WHERE id > @lastAppliedId ORDER BY id
IF (@id = @lastAppliedId + 1)
BEGIN
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
WHILE (1 = 1)
BEGIN
SET @id = @id + 1
IF exists (SELECT id FROM SchemaChanges WHERE ID = @id)
BEGIN
SELECT @sqlStmt = SqlStmt FROM SchemaChanges WHERE ID = @id
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
END
ELSE
BREAK;
END
END
Questo trigger viene eseguito dopo l'inserimento e controlla se il comando corrente deve essere eseguito successivamente. La logica del codice garantisce che nessuna istruzione di modifica dello schema venga ignorata e che tutte le modifiche vengano applicate anche se l'inserimento non è in ordine.
Sincronizzare la tabella di rilevamento delle modifiche dello schema su tutti gli endpoint.
È possibile sincronizzare la tabella di rilevamento delle modifiche dello schema in tutti gli endpoint usando il gruppo di sincronizzazione esistente o un nuovo gruppo di sincronizzazione. Verificare che le modifiche nella tabella di rilevamento possano essere sincronizzate in tutti gli endpoint, in particolare quando si usa una sincronizzazione unidirezionale.
Non sincronizzare la tabella di cronologia delle modifiche dello schema, poiché tale tabella mantiene uno stato diverso in endpoint diversi.
Applicare le modifiche dello schema in un gruppo di sincronizzazione
Vengono replicate solo le modifiche dello schema apportate nel database in cui è stato creato il trigger DDL. Le modifiche dello schema apportate in altri database non vengono replicate.
Dopo che le modifiche dello schema sono state replicate in tutti gli endpoint, è necessario anche effettuare passaggi aggiuntivi per aggiornare lo schema di sincronizzazione per avviare o arrestare la sincronizzazione delle nuove colonne.
Aggiungere nuove colonne
Modificare lo schema.
Evitare qualsiasi modifica dei dati in cui sono interessate le nuove colonne fino al completamento del passaggio di creazione del trigger.
Attendere che le modifiche dello schema vengano applicate a tutti gli endpoint.
Aggiornare lo schema del database e aggiungere la nuova colonna allo schema di sincronizzazione.
I dati nella nuova colonna vengono sincronizzati durante la successiva operazione di sincronizzazione.
Rimuovere colonne
Rimuovere le colonne dallo schema di sincronizzazione. La sincronizzazione dati interrompe la sincronizzazione dei dati in queste colonne.
Modificare lo schema.
Aggiornare lo schema del database.
Aggiornare i tipi di dati.
Modificare lo schema.
Attendere che le modifiche dello schema vengano applicate a tutti gli endpoint.
Aggiornare lo schema del database.
Se i tipi di dati nuovi e precedenti non sono completamente compatibili, ad esempio, se si passa da
intabigint, la sincronizzazione potrebbe non riuscire prima del completamento delle operazioni di creazione dei trigger. La sincronizzazione ha esito positivo dopo un nuovo tentativo.
Rinominare le colonne o le tabelle
La rinomina di colonne o tabelle interrompe la sincronizzazione dei dati. Creare una nuova tabella o colonna, eseguire il backfill dei dati e quindi eliminare la vecchia tabella o colonna anziché assegnare un nuovo nome.
Altri tipi di modifiche dello schema
Per altri tipi di modifiche dello schema, ad esempio la creazione di stored procedure o l'eliminazione di un indice, non è necessario aggiornare lo schema di sincronizzazione.
Risoluzione dei problemi relativi alla replica automatica delle modifiche dello schema
La logica di replica descritta in questo articolo smette di funzionare in alcune situazioni, ad esempio se è stata apportata una modifica dello schema in un database locale non supportato nel database SQL di Azure. In tal caso, la sincronizzazione della tabella di rilevamento delle modifiche dello schema ha esito negativo. È necessario correggere il problema manualmente:
Disabilitare il trigger DDL ed evitare ulteriori modifiche dello schema fino alla risoluzione del problema.
Nel database di endpoint in cui si sta verificando il problema, disabilitare il trigger AFTER INSERT nell'endpoint in cui non è possibile eseguire la modifica dello schema. Questa azione consente di sincronizzare il comando di modifica dello schema.
Attivare la sincronizzazione del trigger per sincronizzare la tabella di tracciamento delle modifiche dello schema.
Nel database di endpoint in cui si sta verificando il problema, eseguire una query sulla tabella di cronologia delle modifiche dello schema per ottenere l'ID dell'ultimo comando di modifica dello schema applicato.
Eseguire una query sulla tabella di rilevamento delle modifiche dello schema per elencare tutti i comandi con un ID maggiore del valore ID recuperato nel passaggio precedente.
a. Ignorare i comandi che non possono essere eseguiti nel database di endpoint. È necessario gestire correttamente l'incoerenza dello schema. Ripristinare le modifiche dello schema originale se l'incoerenza influisce sull'applicazione.
b. Applicare manualmente i comandi che devono essere applicati.
Aggiornare la tabella della cronologia delle modifiche dello schema e impostare l'ultimo ID applicato sul valore corretto.
Verificare se lo schema viene aggiornato.
Abilitare nuovamente il trigger AFTER INSERT disattivato nel secondo passaggio.
Abilitare nuovamente il trigger DDL disattivato nel primo passaggio.
Se si vuole pulire i record nella tabella di rilevamento delle modifiche dello schema, usare DELETE anziché TRUNCATE. Non reinizializzare mai la colonna Identity nella tabella di rilevamento delle modifiche dello schema usando DBCC CHECKIDENT. È possibile creare nuove tabelle di rilevamento delle modifiche dello schema e aggiornare il nome della tabella nel trigger DDL se è necessario reinizializzare.
Altre considerazioni
Gli utenti del database che configurano l'hub e i database dei membri devono disporre di autorizzazioni sufficienti per eseguire i comandi di modifica dello schema.
È possibile aggiungere altri filtri nel trigger DDL per replicare solo la modifica dello schema nelle tabelle o nelle operazioni selezionate.
È possibile apportare modifiche allo schema solo nel database in cui è stato creato il trigger DDL.
Se si apporta una modifica in un database di SQL Server, assicurarsi che la modifica dello schema sia supportata nel database SQL di Azure.
Le modifiche dello schema apportate in database diversi dal database in cui viene creato il trigger DDL non vengono replicate. Per evitare questo problema, è possibile creare trigger DDL per bloccare le modifiche negli altri endpoint.
Se è necessario modificare lo schema della tabella di rilevamento delle modifiche dello schema, disabilitare il trigger DDL prima di apportare la modifica e quindi applicare manualmente la modifica in tutti gli endpoint. L'aggiornamento dello schema in un trigger AFTER INSERT sulla stessa tabella non funziona.
Non reinizializzare la colonna Identity usando DBCC CHECKIDENT.
Non usare TRUNCATE per pulire i dati nella tabella di rilevamento delle modifiche dello schema.
Contenuto correlato
- Che cos'è Sincronizzazione dati SQL per Azure?
- Esercitazione: Configurare la sincronizzazione dati SQL tra i database nel database SQL di Azure e in SQL Server
- Usare PowerShell per sincronizzare i dati tra più database nel database SQL di Azure
- Usare PowerShell per sincronizzare i dati tra database SQL e SQL Server
- Data Sync Agent per Sincronizzazione dati SQL
- Procedure consigliate per la sincronizzazione dati SQL di Azure
- Monitorare e ottimizzare le prestazioni in database SQL di Azure e Istanza gestita di SQL di Azure
- Risolvere i problemi con Sincronizzazione dati SQL
- Usare PowerShell per aggiornare lo schema di sincronizzazione in un gruppo di sincronizzazione esistente