Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() Istanza gestita di SQL di Azure SQL
Istanza gestita di SQL di Azure SQL
Questo articolo illustra come monitorare e gestire i file nei database in Istanza gestita di SQL di Azure. Illustra come monitorare le dimensioni del file di database, compattare il log delle transazioni, ingrandire un file di log delle transazioni e controllare l'aumento di un file di log delle transazioni.
Questo articolo si applica a Istanza gestita di SQL di Azure. Per informazioni sulla gestione delle dimensioni dei file di log delle transazioni in SQL Server, vedere Gestire le dimensioni del file di log delle transazioni.
Informazioni sui tipi di spazio di archiviazione per un database
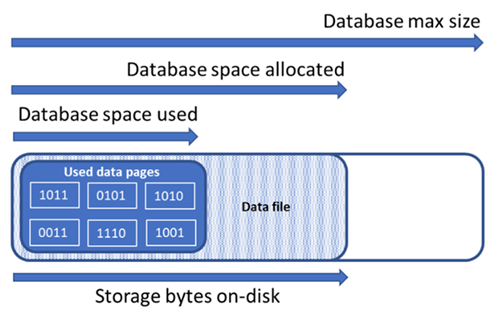
Comprendere le quantità di spazio di archiviazione seguenti è importante per gestire lo spazio file di un database.
| Quantità di database | Definizione | Commenti |
|---|---|---|
| Spazio dati usato | La quantità di spazio usato per archiviare i dati del database. | In generale, lo spazio usato aumenta (diminuisce) durante gli inserimenti (eliminazioni). In alcuni casi, lo spazio usato non cambia in caso di inserimenti o eliminazioni a seconda della quantità e del modello di dati coinvolti nell'operazione e in qualsiasi frammentazione. Ad esempio, se si elimina una riga da ogni pagina di dati, non si riduce necessariamente lo spazio usato. |
| Spazio dati allocato | Quantità di spazio file formattato messo a disposizione per l'archiviazione dei dati del database. | La quantità di spazio allocato aumenta automaticamente, ma non diminuisce mai dopo le eliminazioni. Questo comportamento garantisce che gli inserimenti futuri siano più veloci perché non è necessario riformattare lo spazio. |
| Spazio dati allocato ma non usato | Differenza tra la quantità di spazio dati allocato e lo spazio dati usato. | Questa quantità rappresenta la quantità massima di spazio libero che può essere recuperata compattando i file di dati del database. |
| Dimensioni massime dei dati | Quantità massima di spazio che può essere usata per l'archiviazione dei dati del database. | La quantità di spazio dati allocato non può superare le dimensioni massime dei dati. |
Il diagramma seguente illustra la relazione tra i diversi tipi di spazio di archiviazione per un database.
Eseguire una query su un database singolo per ottenere informazioni sullo spazio dei file
Usare la query seguente su sys.database_files per restituire la quantità di spazio per i dati del database allocato e la quantità di spazio inutilizzato allocato. L'unità di misura dei risultati di query è costituita da MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Monitorare l'uso dello spazio del log
Monitorare l'uso dello spazio del log tramite sys.dm_db_log_space_usage. Questo DMV restituisce informazioni sulla quantità di spazio del log attualmente usata e indica quando il log delle transazioni deve essere troncato.
Per informazioni sulle dimensioni correnti del file di log, sulle dimensioni massime e sull'opzione di aumento automatico per il file, usare le sizecolonne , max_sizee growth per tale file di log in sys.database_files.
Metriche dello spazio di archiviazione visualizzate nelle API delle metriche basate su Azure Resource Manager misurano solo le dimensioni delle pagine di dati usate. Per esempi, vedere PowerShell Get-AZMetric.
Ridurre la dimensione del file di log
Per ridurre la dimensione fisica di un file di log fisico rimuovendo lo spazio non utilizzato, è necessario compattare il file di resoconto. Una compattazione fa la differenza solo quando un file di log delle transazioni contiene spazio inutilizzato. Se il file di log è pieno, probabilmente a causa di transazioni aperte, esaminare cosa impedisce il troncamento del log delle transazioni.
Attenzione
Le operazioni di compattazione non devono essere considerate un'operazione di manutenzione regolare. I file di dati e di log che aumentano a causa di operazioni aziendali regolari e ricorrenti non richiedono operazioni di compattazione. I comandi di compattazione influiscono sulle prestazioni del database mentre è in esecuzione e, se possibile, dovrebbero essere eseguiti in periodi di utilizzo ridotto. La compattazione dei file di dati non è consigliata se il carico di lavoro normale dell'applicazione fa aumentare nuovamente le dimensioni dei file allocati.
Tenere presente il potenziale impatto negativo sulle prestazioni della compattazione dei file di database. Per altre informazioni, vedere Manutenzione dell'indice dopo la compattazione. In rari casi, i backup automatici del database possono influire sulle operazioni di compattazione. Se necessario, ripetere l'operazione di compattazione.
Prima di compattare il log delle transazioni, tenere presente i fattori che possono ritardare il troncamento del log. Se lo spazio di archiviazione è necessario di nuovo dopo la compattazione di un log, il log delle transazioni aumenta di nuovo e, in questo modo, comporta un sovraccarico delle prestazioni durante le operazioni di crescita del log. Per altre informazioni, vedere la sezione raccomandazioni .
È possibile compattare un file di log solo mentre il database è online ed è disponibile almeno un file di log virtuale (VLF). In alcuni casi, la riduzione del log potrebbe non essere possibile fino al prossimo troncamento del log.
Fattori come una transazione con esecuzione prolungata, che possono mantenere i VLF attivi per un lungo periodo di tempo, possono limitare la compattazione del log, o addirittura impedirne del tutto la riduzione. Per informazioni, vedere Fattori che possono posticipare il troncamento del log.
Il processo di compattazione di un file di log comporta la rimozione di uno o più VLF che non contengono alcuna parte del log logico, ovvero dei VLF inattivi. Quando si compatta un file di registro delle transazioni, i VLF inattivi vengono rimossi dalla fine del file di registro per ridurre il log approssimativamente alla dimensione obiettivo.
Per altre informazioni sulle operazioni di compattazione, vedere la documentazione seguente:
Compattare un file di log senza compattare i file di database
Monitorare gli eventi di compattazione dei file di log
Monitorare lo spazio del log
sys.database_files (Transact-SQL) (vedere le colonne
size,max_sizeegrowthper i file o i file di log).
Manutenzione dell'indice dopo la compattazione
Al termine di un'operazione di compattazione rispetto ai file di dati, gli indici possono essere frammentati. La frammentazione riduce l'efficacia dell'ottimizzazione delle prestazioni di un indice per determinati carichi di lavoro, ad esempio le query che usano analisi di grandi dimensioni. Se si verifica una riduzione del livello delle prestazioni dopo il completamento dell'operazione di compattazione, prendere in considerazione la possibilità di eseguire la manutenzione degli indici ricostruendoli. Tenere presente che le ricompilazioni dell'indice richiedono spazio disponibile nel database e pertanto lo spazio allocato può aumentare, contrastando l'effetto della compattazione.
Per altre informazioni sulla manutenzione degli indici, vedere Ottimizzare la manutenzione degli indici per migliorare le prestazioni delle query e ridurre il consumo di risorse.
Valutare la densità della pagina dell'indice
Se il troncamento dei file di dati non comporta una riduzione sufficiente dello spazio allocato, è possibile decidere di compattare i file di dati del database per recuperare lo spazio inutilizzato da tali file. Tuttavia, come passaggio facoltativo ma consigliato, è necessario prima determinare la densità media delle pagine per gli indici all'interno del database. Per la stessa quantità di dati, la compattazione viene completata più velocemente se la densità di pagina è elevata, perché sposta meno pagine. Se la densità di pagina è bassa per alcuni indici, si consiglia di eseguire operazioni di manutenzione su questi indici per aumentare la densità di pagina prima di compattare i file di dati. Questo passaggio consente di ridurre in modo più profondo lo spazio di archiviazione allocato.
Per determinare la densità di pagina per tutti gli indici nel database, usare la query seguente. La densità di pagina viene segnalata nella colonna avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Se sono presenti indici con un numero elevato di pagine con densità di pagina inferiore al 60-70%, valutare la possibilità di ricompilare o riorganizzare questi indici prima di compattare i file di dati.
Nota
Per i database più grandi, la query per determinare la densità delle pagine può richiedere molto tempo (ore) per il completamento. Inoltre, la ricompilazione o la riorganizzazione di indici di grandi dimensioni richiede tempi e utilizzi sostanziali delle risorse. C'è un compromesso tra la spesa aggiuntiva per aumentare la densità di pagina da una parte e ridurre la durata della riduzione e ottenere risparmi di spazio più elevati su un altro.
Se sono presenti più indici con densità di pagina bassa, è possibile ricompilarli in parallelo in più sessioni di database per velocizzare il processo. Tuttavia, assicurarsi di non avvicinarsi ai limiti delle risorse del database in questo modo e lasciare sufficiente il headroom delle risorse per i carichi di lavoro delle applicazioni. Monitorare l'utilizzo delle risorse (CPU, I/O dati, I/O log) nel portale di Azure o usando la visualizzazione sys.dm_db_resource_stats . Avviare ulteriori ricompilazione parallele solo se l'utilizzo delle risorse in ognuna di queste dimensioni rimane sostanzialmente inferiore a 100%. Se l'utilizzo di CPU, I/O dei dati o I/O dei log è pari a 100%, è possibile aumentare le prestazioni del database in modo da avere più core CPU e aumentare la velocità effettiva di I/O, consentendo di completare più rapidamente il processo.
Comando di ricompilazione dell'indice di esempio
Di seguito è riportato un comando di esempio per ricompilare un indice e aumentarne la densità di pagina usando l'istruzione ALTER INDEX:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Questo comando avvia una ricompilazione dell'indice online e ripristinabile. Questo tipo di ricompilazione consente ai carichi di lavoro simultanei di continuare a usare la tabella mentre la ricompilazione è in corso e consente di riprendere la ricompilazione se viene interrotta per qualsiasi motivo. Tuttavia, questo tipo di ricompilazione è più lento rispetto a una ricompilazione offline, che blocca l'accesso alla tabella. Se nessun altro carico di lavoro deve accedere alla tabella durante la ricompilazione, impostare le opzioni ONLINE e RESUMABLE su OFF e rimuovere la clausola WAIT_AT_LOW_PRIORITY.
Per maggiori informazioni sulla manutenzione degli indici, vedere Ottimizzare la manutenzione degli indici per migliorare le prestazioni delle query e ridurre il consumo di risorse.
Compattare più file di dati
Come indicato in precedenza, la riduzione con lo spostamento dei dati è un processo che richiede molto tempo. Se nel database sono presenti più file di dati, è possibile velocizzare il processo compattando più file di dati in parallelo. Questa operazione viene eseguita aprendo più sessioni di database e usando DBCC SHRINKFILE in ogni sessione con un valore diverso file_id . Analogamente alla ricostruzione degli indici in precedenza, assicurarsi di avere un margine di risorse sufficiente (CPU, I/O dati, I/O log) prima di avviare ogni nuovo comando di compattazione parallela.
Il comando di esempio seguente riduce il file di dati con file_id 4, spostando le pagine all'interno del file nel tentativo di ridurre le dimensioni allocate a 52.000 MB :
DBCC SHRINKFILE (4, 52000);
Se si vuole ridurre lo spazio allocato per il file al minimo possibile, eseguire l'istruzione senza specificare le dimensioni di destinazione:
DBCC SHRINKFILE (4);
Se un carico di lavoro è in esecuzione simultaneamente alla compattazione, può iniziare a usare lo spazio di archiviazione liberato dalla compattazione prima del completamento della stessa e troncare il file. In questo caso, la compattazione non può ridurre lo spazio allocato alla destinazione specificata.
È possibile attenuare questo problema compattando ogni file in passaggi più piccoli. Ciò significa che nel comando DBCC SHRINKFILE si imposta la destinazione leggermente inferiore rispetto allo spazio allocato corrente per il file. Ad esempio, se lo spazio allocato per il file con file_id 4 è 200.000 MB e si vuole ridurlo a 100.000 MB, è possibile impostare prima la destinazione su 170.000 MB:
DBCC SHRINKFILE (4, 170000);
Al termine di questo comando, tronca il file e riduce le dimensioni allocate a 170.000 MB. È quindi possibile ripetere questo comando, impostando la destinazione prima su 140.000 MB, quindi su 110.000 MB e così via, fino a quando il file non viene ridotto alle dimensioni desiderate. Se il comando viene completato ma il file non viene troncato, usare passaggi più piccoli, ad esempio 15.000 MB anziché 30.000 MB.
Per monitorare lo stato di compattazione per tutte le sessioni di compattazione in esecuzione simultanea, è possibile usare la query seguente:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Nota
Lo stato di avanzamento della compattazione può essere non lineare e il valore nella percent_complete colonna potrebbe rimanere invariato per lunghi periodi di tempo, anche se la compattazione è ancora in corso.
Al termine della compattazione per tutti i file di dati, usare la query sull'utilizzo dello spazio per determinare la riduzione risultante delle dimensioni di archiviazione allocate. Se esiste ancora una grande differenza tra lo spazio usato e lo spazio allocato, è possibile ricompilare gli indici. La ricompilazione può aumentare temporaneamente lo spazio allocato, ma la compattazione dei file di dati dopo la ricompilazione degli indici dovrebbe comportare una riduzione più profonda dello spazio allocato.
Ingrandire un file di log
In Istanza gestita di SQL di Azure è possibile aggiungere spazio a un file di log ampliando il file di log esistente, se lo spazio su disco è consentito. L'aggiunta di un file di log al database non è supportata. Un file di log delle transazioni è sufficiente a meno che lo spazio del log non esaurisca e che lo spazio su disco si esaurisca anche nel volume che contiene il file di log.
Per ingrandire il file di log, usare la MODIFY FILE clausola dell'istruzione ALTER DATABASE e specificare la SIZE sintassi e MAXSIZE . Per ulteriori informazioni, vedere ALTER DATABASE (Transact-SQL) opzioni di file e filegroup.
Per ulteriori informazioni, consultare Suggerimenti.
Controllare l'aumento delle dimensioni di un file di log delle transazioni
Per gestire l'aumento dell'aumento di un file di log delle transazioni, usare l'istruzione di opzioni alter DATABASE (Transact-SQL) file e filegroup . Si notino le opzioni seguenti:
- Usare l'opzione
SIZEper modificare le dimensioni correnti del file in UNITÀ KB, MB, GB e TB. - Usare l'opzione
FILEGROWTHper modificare l'incremento della crescita. Il valore 0 indica che l'aumento automatico delle dimensioni è disattivato e non è consentita l'allocazione di spazio aggiuntivo. - Usare l'opzione
MAXSIZEper controllare le dimensioni massime di un file di log in UNITÀ KB, MB, GB e TB o per impostare la crescita suUNLIMITED.
Consigli
Quando si lavora con i file di log delle transazioni, prendere in considerazione le raccomandazioni seguenti:
Impostare l'incremento automatico (aumento automatico) del log delle transazioni, come configurato dall'opzione
FILEGROWTH, in modo che sia sufficientemente grande per soddisfare le esigenze delle transazioni del carico di lavoro. Aumentare la crescita dei file in un file di log sufficientemente grande per evitare un'espansione frequente. È possibile ridimensionare correttamente un log delle transazioni monitorando la quantità di log occupata durante:- Tempo necessario per eseguire un backup completo, perché i backup del log non possono verificarsi fino al termine.
- Il tempo necessario per le operazioni di manutenzione dell'indice più grande.
- Il tempo necessario per eseguire il batch più grande in un database.
Impostare l'aumento automatico dei file di dati e di log usando l'opzione
FILEGROWTHanzichésizepercentage, per consentire un maggiore controllo sul rapporto di crescita, perché la percentuale è una quantità in continua crescita.- Nell'Istanza gestita di Azure SQL, l'inizializzazione immediata dei file può offrire vantaggi agli eventi di crescita del log delle transazioni fino a 64 MB. L'incremento predefinito delle dimensioni di aumento automatico per i nuovi database è 64 MB. Gli eventi di aumento automatico dei file registro transazioni di dimensioni superiori a 64 MB non possono trarre vantaggio dall'inizializzazione immediata dei file.
- Come procedura consigliata, non impostare il valore dell'opzione
FILEGROWTHsuperiore a 1.024 MB per i log delle transazioni.
Evitare di impostare un piccolo incremento automatico perché può generare troppi file VVL di piccole dimensioni e ridurre le prestazioni. Per determinare la distribuzione ottimale degli VLF per la dimensione corrente del log delle transazioni di tutti i database in una determinata istanza, e gli incrementi necessari per raggiungere la dimensione desiderata, vedere questo script per analizzare e correggere gli VLF, fornito dal SQL Tiger Team.
Evitare di impostare un incremento automatico di grandi dimensioni perché può causare due problemi:
- Il database può essere sospeso durante l'allocazione del nuovo spazio, causando potenzialmente timeout delle query.
- Può generare VLF troppo pochi e grandi e può influire anche sulle prestazioni. Per determinare la distribuzione ottimale degli VLF per la dimensione corrente del log delle transazioni di tutti i database in una determinata istanza, e gli incrementi necessari per raggiungere la dimensione desiderata, vedere questo script per analizzare e correggere gli VLF, fornito dal SQL Tiger Team.
Anche con l'aumento automatico abilitato, è possibile ricevere un messaggio che indica che il log delle transazioni è pieno se non può crescere abbastanza velocemente per soddisfare le esigenze della query. Per altre informazioni su come modificare l'incremento della crescita, vedere Opzioni per file e filegroup ALTER DATABASE (Transact-SQL).
È possibile impostare i file di log per la compattazione automatica. Questa procedura non è tuttavia consigliata e la proprietà del database auto_shrink è impostata su FALSE per impostazione predefinita. Se si imposta auto_shrink su TRUE, la compattazione automatica riduce le dimensioni di un file solo quando più del 25% dello spazio è inutilizzato.
- Il file viene ridotto alle dimensioni in base alle quali solo il 25% del file è spazio inutilizzato o viene ridotto alle dimensioni originali del file, a qualsiasi livello di dimensioni maggiori.
- Per informazioni sulla modifica dell'impostazione della proprietà auto_shrink, vedere Visualizzare o modificare le proprietà di un database e Opzioni ALTER DATABASE SET (Transact-SQL).