Collegamento di failover - Istanza gestita di SQL di Azure
Si applica a: ![]() Istanza gestita di SQL di Azure SQL
Istanza gestita di SQL di Azure SQL
Questo articolo illustra come eseguire il failover di un database collegato tra SQL Server e Istanza gestita di SQL di Azure usando SQL Server Management Studio (SSMS) o PowerShell per il ripristino di emergenza o la migrazione.
Prerequisiti
Per eseguire il failover dei database nella replica secondaria tramite il collegamento sono necessari i prerequisiti seguenti:
- Una sottoscrizione di Azure attiva. Se non se ne ha una, creare un account gratuito.
- Versione supportata di SQL Server con l’aggiornamento del servizio richiesto installato.
- Collegamento configurato tra la replica primaria e quella secondaria.
- È possibile eseguire il failover del collegamento usando Transact-SQL (attualmente in anteprima) a partire da SQL Server 2022 CU13 (KB5036432).
Interrompere il carico di lavoro
Se si è pronti per eseguire il failover del database nella replica secondaria, interrompere prima qualsiasi carico di lavoro dell’applicazione nella replica primaria durante le ore di manutenzione. Ciò consente alla replica di database di recuperare il database secondario per effettuare il failover del database secondario senza perdita di dati. Assicurarsi che le applicazioni non eseguano il commit delle transazioni nella replica primaria prima del failover.
Eseguire il failover di un database
È possibile eseguire il failover di un database collegato utilizzando Transact-SQL (T-SQL), SQL Server Management Studio o PowerShell.
È possibile eseguire il failover del collegamento usando Transact-SQL (attualmente in anteprima) a partire da SQL Server 2022 CU13 (KB5036432).
Per eseguire un failover pianificato per un collegamento, usare il comando T-SQL seguente nella replica primaria:
ALTER AVAILABILITY GROUP [<DAGname>] FAILOVER
Per eseguire un failover forzato, usare il comando T-SQL seguente nella replica secondaria:
ALTER AVAILABILITY GROUP [<DAGname>] FORCE_FAILOVER_ALLOW_DATA_LOSS
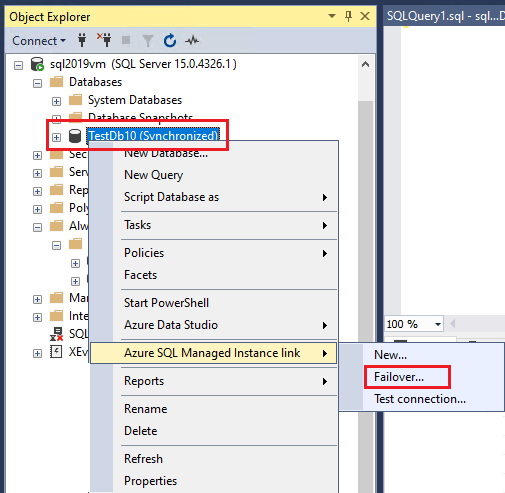
Visualizzare il database dopo il failover
Per SQL Server 2022, se si sceglie di mantenere il collegamento, è possibile verificare che il gruppo di disponibilità distribuito esista in Gruppi di disponibilità in Esplora oggetti in SQL Server Management Studio.
Se il collegamento è stato eliminato durante il failover, è possibile usare Esplora oggetti per confermare che il gruppo di disponibilità distribuito non esiste più. Se si sceglie di mantenere il gruppo di disponibilità, il database verrà comunque sincronizzato.
Eseguire la pulizia dopo il failover
Se non si seleziona Rimuovi collegamento dopo il failover riuscito, il failover con SQL Server 2022 non interrompe il collegamento. È possibile mantenere il collegamento dopo il failover, lasciando attivo il gruppo di disponibilità e il gruppo di disponibilità distribuito. Non sono necessarie ulteriori azioni.
L'eliminazione del collegamento elimina solo il gruppo di disponibilità distribuito e lascia attivo il gruppo di disponibilità. È possibile decidere di mantenere il gruppo di disponibilità o eliminarlo.
Se si decide di eliminare il gruppo di disponibilità, sostituire il seguente valore e poi eseguire il codice T-SQL di esempio:
<AGName>con il nome del gruppo di disponibilità in SQL Server (usato per creare il collegamento).
-- Run on SQL Server
USE MASTER
GO
DROP AVAILABILITY GROUP <AGName>
GO
Stato incoerente a seguito di failover forzato
Dopo un failover forzato, è possibile che si verifichi uno scenario split-brain in cui entrambe le repliche si trovano nel ruolo primario, lasciando il collegamento in uno stato incoerente. Ciò può verificarsi se si effettua il failover nella replica secondaria durante un'emergenza e quindi la replica primaria torna online.
Prima di tutto, verificare di essere in uno scenario split-brain. A tale scopo, è possibile usare Transact-SQL (T-SQL) o SQL Server Management Studio (SSMS).
Connettersi sia a SQL Server che a Istanza gestita di SQL in SSMS e quindi, in Esplora oggetti, espandere Repliche di disponibilità nel nodo Gruppo di disponibilità in Disponibilità elevata sempre attiva. Se due repliche diverse sono elencate come (primaria), ci si trova in uno scenario split-brain.
In alternativa, è possibile eseguire lo script T-SQL seguente sia in SQL Server che in Istanza gestita di SQL per controllare il ruolo delle repliche:
-- Execute on SQL Server and SQL Managed Instance
declare @link_name varchar(max) = '<DAGName>'
USE MASTER
GO
SELECT
ag.name [Link name],
rs.role_desc [Link role]
FROM
sys.availability_groups ag
join sys.dm_hadr_availability_replica_states rs
on ag.group_id = rs.group_id
WHERE
rs.is_local = 1 and ag.name = @link_name
GO
Se entrambe le istanze elencano un elemento Primario diverso nella colonna del ruolo Collegamento, si è in uno scenario split-brain.
Per risolvere lo stato split-brain, eseguire prima un backup sulla replica primaria originale. Se il database primario originale era SQL Server, eseguire un backup della parte finale del log. Se il database primario originale è stato Istanza gestita di SQL, eseguire un backup completo di sola copia. Al termine del backup, impostare il gruppo di disponibilità distribuito sul ruolo secondario per la replica che usava come replica primaria originale, ma sarà ora il nuovo database secondario.
Ad esempio, in caso di vera emergenza, presupponendo che sia stato forzato un failover del carico di lavoro di SQL Server a Istanza gestita di SQL di Azure e si intende continuare a eseguire il carico di lavoro in Istanza gestita di SQL, eseguire un backup della parte finale del log in SQL Server e quindi impostare il gruppo di disponibilità distribuito sul ruolo secondario in SQL Server, ad esempio:
--Execute on SQL Server
USE MASTER
ALTER availability group [<DAGName>]
SET (role = secondary)
GO
Quindi, eseguire un failover manuale pianificato da Istanza gestita di SQL a SQL Server usando il collegamento, ad esempio l'esempio seguente:
--Execute on SQL Managed Instance
USE MASTER
ALTER availability group [<DAGName>] FAILOVER
GO
Contenuto correlato
Per altre informazioni sul collegamento, vedere le risorse seguenti:
- Panoramica del collegamento a Istanza gestita
- Preparare l'ambiente per il collegamento di un'istanza gestita
- Configurare il collegamento tra SQL Server e istanza gestita di SQL con script
- Ripristino di emergenza con il collegamento all'istanza gestita
- Procedure consigliate per la gestione del collegamento