Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come ripristinare i database SAP HANA in esecuzione su macchine virtuali Azure utilizzando il portale Azure e che il servizio Backup di Azure ha eseguito il backup in una cassette di sicurezza di Servizi di ripristino. Backup di Azure consente di usare i dati ripristinati per creare copie per scenari di sviluppo e test o per tornare a uno stato precedente. È anche possibile ripristinare il database usando l'interfaccia della riga di comando di Azure.
Backup di Azure supporta ora il backup e il ripristino dell'istanza di replica di sistema SAP HANA usando il portale di Azure. È anche possibile eseguire l'operazione di ripristino usando l'interfaccia della riga di comando di Azure.
Nota
- Il processo di ripristino per i database HANA con HSR equivale al processo di ripristino per i database HANA senza HSR. In base agli avvisi SAP, è possibile ripristinare i database con la modalità HSR come database autonomi . Se nel sistema di destinazione è abilitata la modalità HSR, disabilitare prima la modalità e quindi ripristinare il database. Tuttavia, se si esegue il ripristino come file, la disabilitazione della modalità HSR (che causa l'interruzione dell'HSR) non è necessaria.
- Il ripristino della posizione originale (OLR) non è attualmente supportato per HSR. In alternativa, selezionare Ripristino percorso alternativo e quindi selezionare la macchina virtuale di origine come host dall'elenco.
- Il ripristino nell'istanza HSR non è supportato. Tuttavia, è supportato solo il ripristino nell'istanza di HANA.
Per informazioni sulle configurazioni e gli scenari supportati, vedere la matrice di supporto per il backup di SAP HANA.
Eseguire il ripristino in un punto nel tempo o in un punto di ripristino
Backup di Azure ripristina i database SAP HANA in esecuzione in macchine virtuali di Azure. Il Centro sicurezza di Azure può:
Ripristinarli in una data o un'ora specifica (al secondo) usando i backup del log. Backup di Azure determina automaticamente i backup completi, i backup differenziali e la catena di backup del log necessari per il ripristino in base all'ora selezionata. Ulteriori informazioni.
Ripristinarli in un backup completo o differenziale specifico per ripristinarli in un punto di ripristino specifico. Ulteriori informazioni.
Prerequisiti
Prima di iniziare a ripristinare un database, tenere presente quanto segue:
È possibile ripristinare il database solo in un'istanza di SAP HANA che risiede nella stessa area.
L'istanza di destinazione deve essere registrata con lo stesso insieme di credenziali dell'origine. Altre informazioni sul backup dei database SAP HANA.
Backup di Azure non può identificare due istanze di SAP HANA diverse nella stessa macchina virtuale. Il ripristino dei dati da un'istanza a un'altra nella stessa macchina virtuale non è quindi possibile.
Per assicurarsi che l'istanza di SAP HANA di destinazione sia pronta per il ripristino, controllare lo stato di conformità del backup:
Nella portale di Azure passare al Centro backup e quindi selezionare Backup.
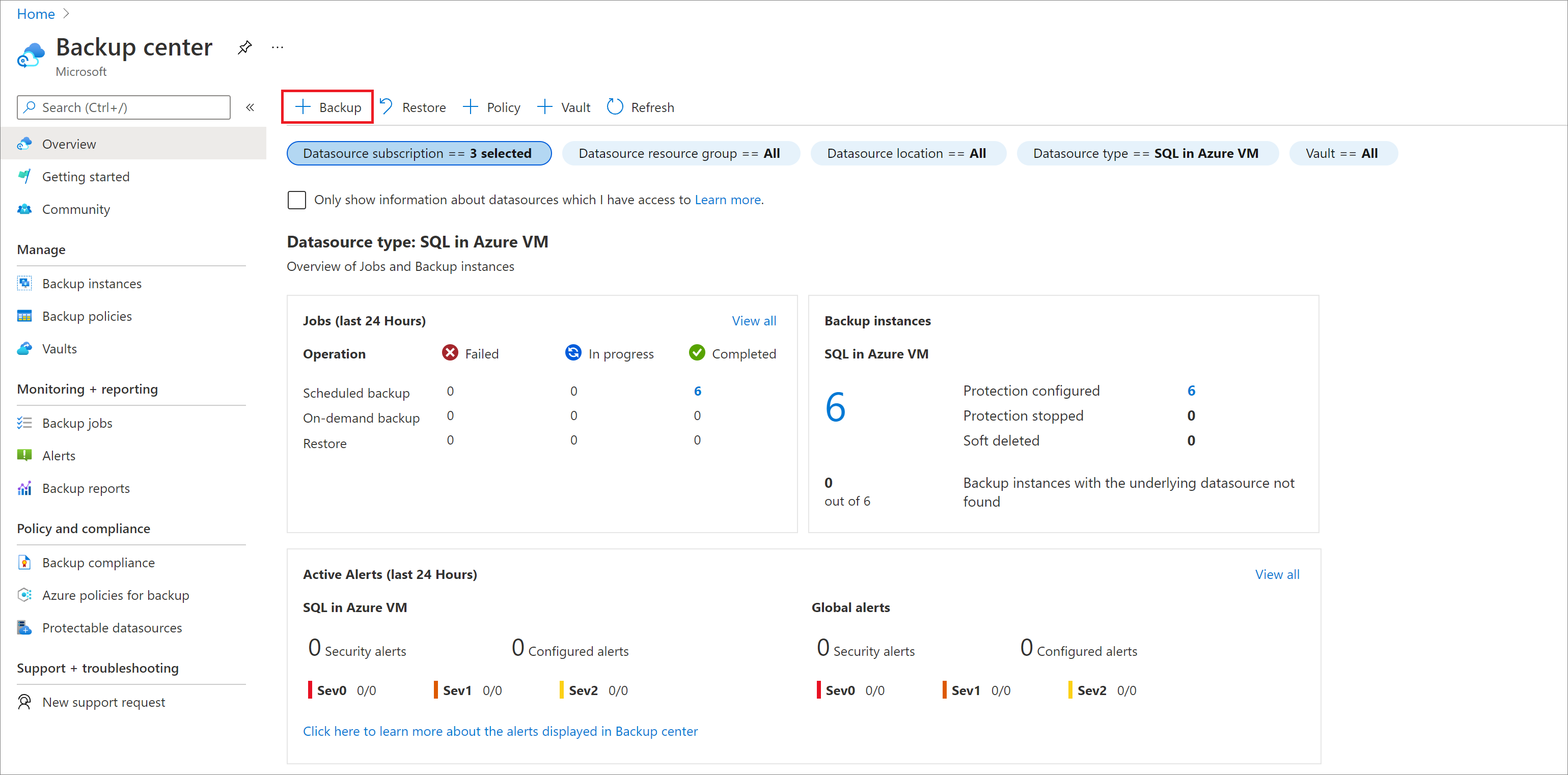
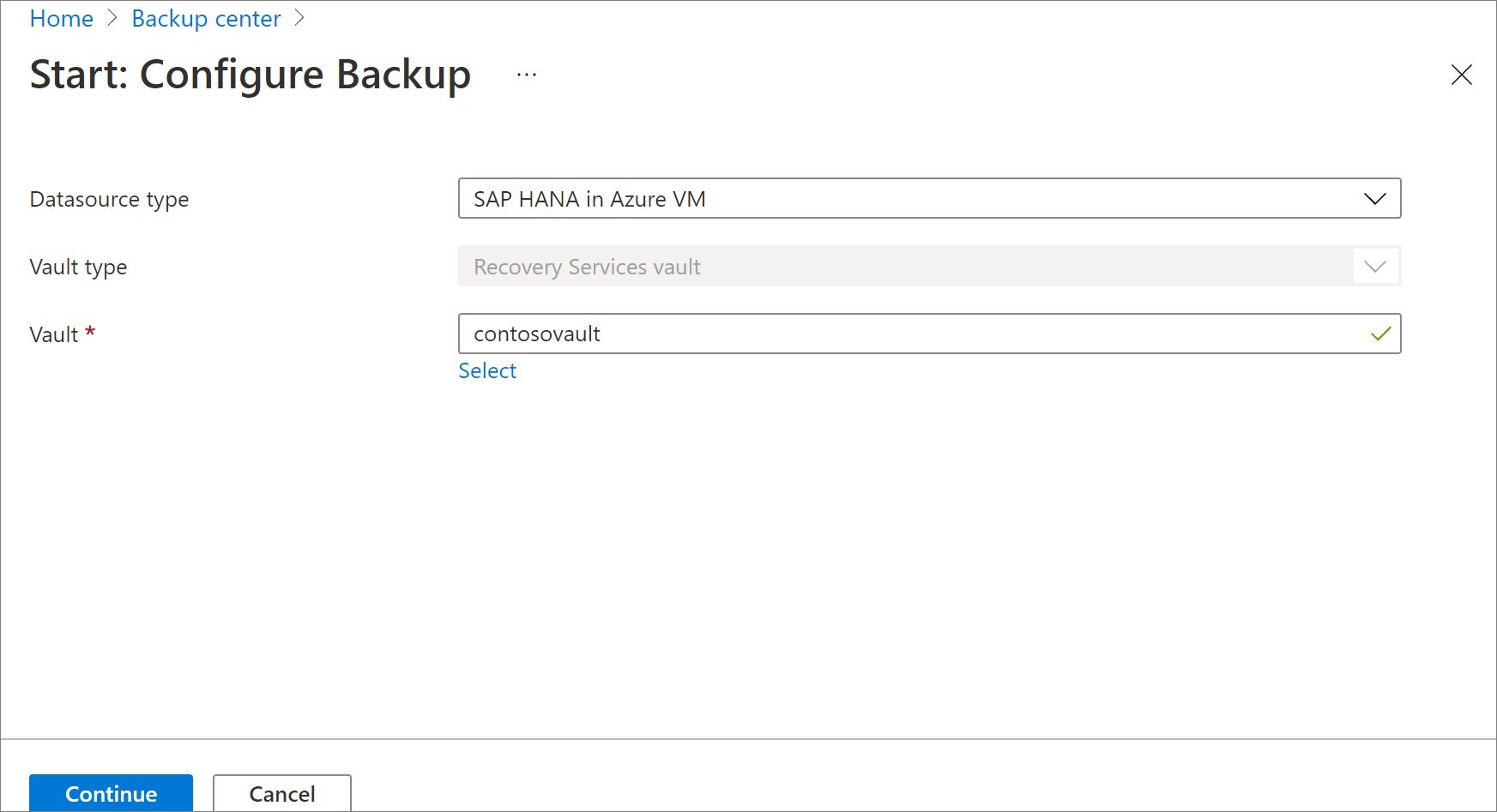
Nel riquadro Start: Configure Backup (Avvia: Configura backup) per Tipo di origine dati selezionare SAP HANA nella macchina virtuale di Azure, selezionare l'insieme di credenziali in cui è registrata l'istanza di SAP HANA e quindi selezionare Continua.
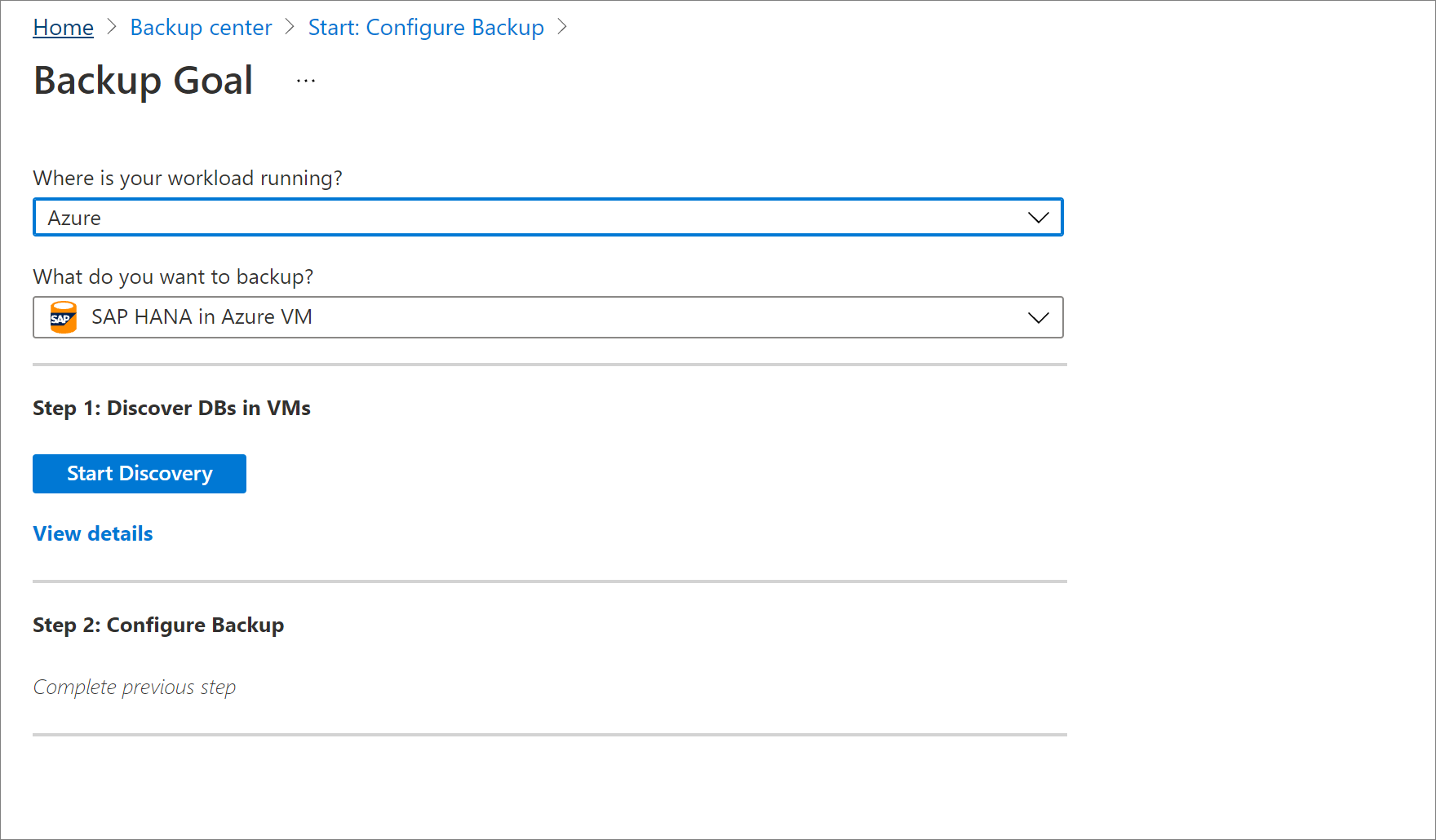
In Individua database nelle macchine virtuali selezionare Visualizza dettagli.
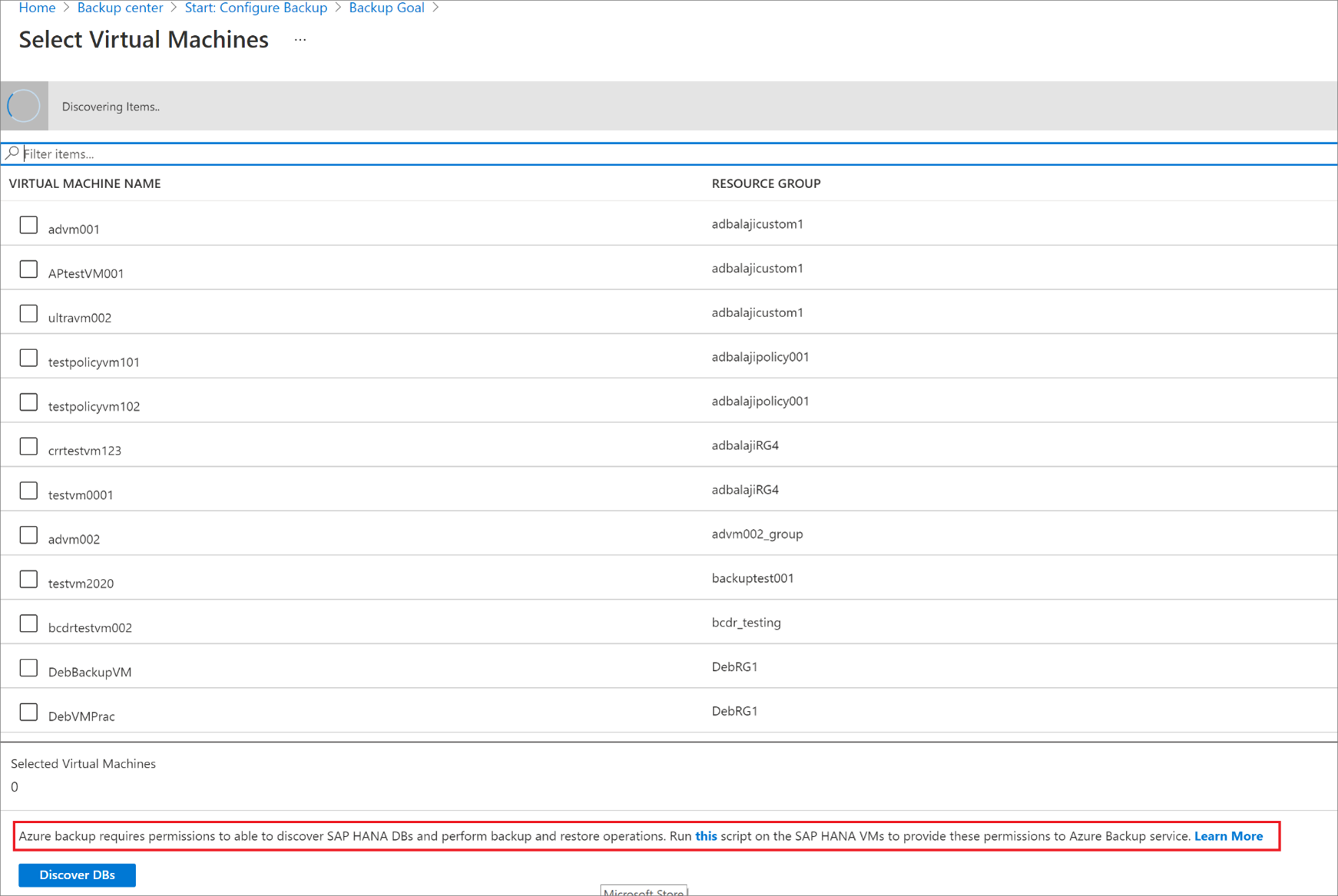
Esaminare l'idoneità per il backup della macchina virtuale di destinazione.
Per altre informazioni sui tipi di ripristino supportati da SAP HANA, vedere La nota di SAP HANA 1642148.


Ripristinare un database
Per ripristinare un database, sono necessarie le seguenti autorizzazioni:
- Operatore di backup: fornisce le autorizzazioni nell'insieme di credenziali in cui si esegue il ripristino.
- Collaboratore (scrittura): consente di accedere alla macchina virtuale di origine di cui è stato eseguito il backup.
-
Collaboratore (scrittura): fornisce l'accesso alla macchina virtuale di destinazione.
- Se si esegue il ripristino nella stessa macchina virtuale, questa è la macchina virtuale di origine.
- Se si esegue il ripristino in un percorso alternativo, questa è la nuova macchina virtuale di destinazione.
Nel portale di Azure passare al Centro backup e quindi selezionare Ripristina.
Selezionare SAP HANA nella macchina virtuale di Azure come tipo di origine dati, selezionare il database da ripristinare e quindi selezionare Continua.
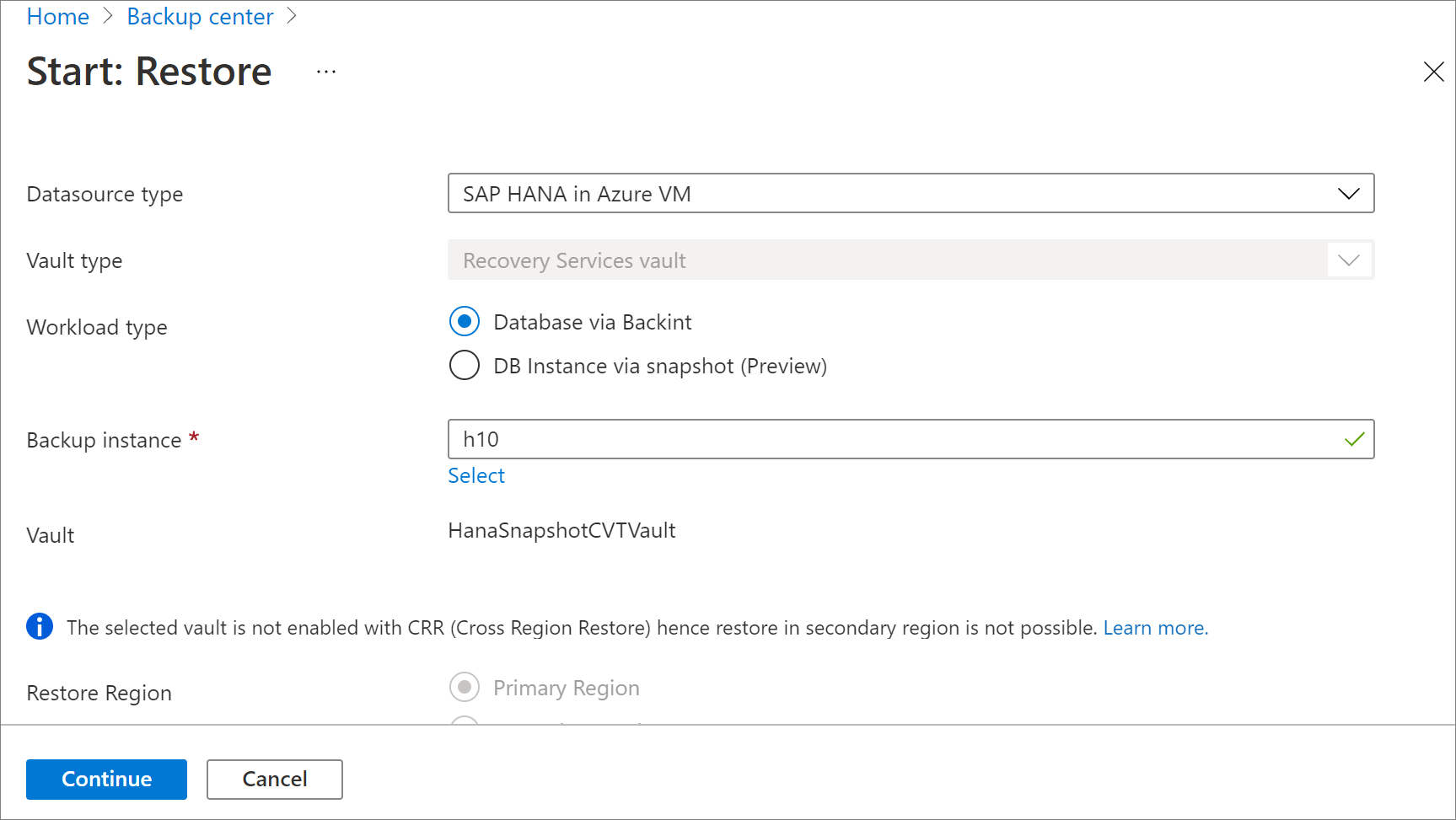
In Configurazione ripristino specificare dove o come ripristinare i dati:
- Percorso alternativo: consente di ripristinare il database in un percorso diverso mantenendo il database di origine.
- Sovrascrivi database: consente di ripristinare i dati nella stessa istanza di SAP HANA dell'origine. Questa opzione sovrascrive il database originale.

Nota
Durante il ripristino (applicabile solo allo scenario IP front-end ip front-end ip/bilanciamento del carico virtuale), se si tenta di ripristinare un backup nel nodo di destinazione dopo aver modificato la modalità HSR come HSR autonomo o di interruzione prima del ripristino come consigliato da SAP e assicurarsi che load Balancer punti al nodo di destinazione.
Scenari di esempio:
- Se si usa hdbuserstore set SYSTEMKEY localhost nello script di preregistrazione, non ci saranno problemi durante il ripristino.
- Se il set
SYSTEMKEY <load balancer host/ip>*hdbuserstore nello script di preregistrazione e si sta tentando di ripristinare il backup nel nodo di destinazione, assicurarsi che il servizio di bilanciamento del carico punti al nodo di destinazione che deve essere ripristinato.
Ripristinare in un percorso alternativo
Nel riquadro Ripristina, in Dove e come eseguire il ripristino, selezionare Percorso alternativo.
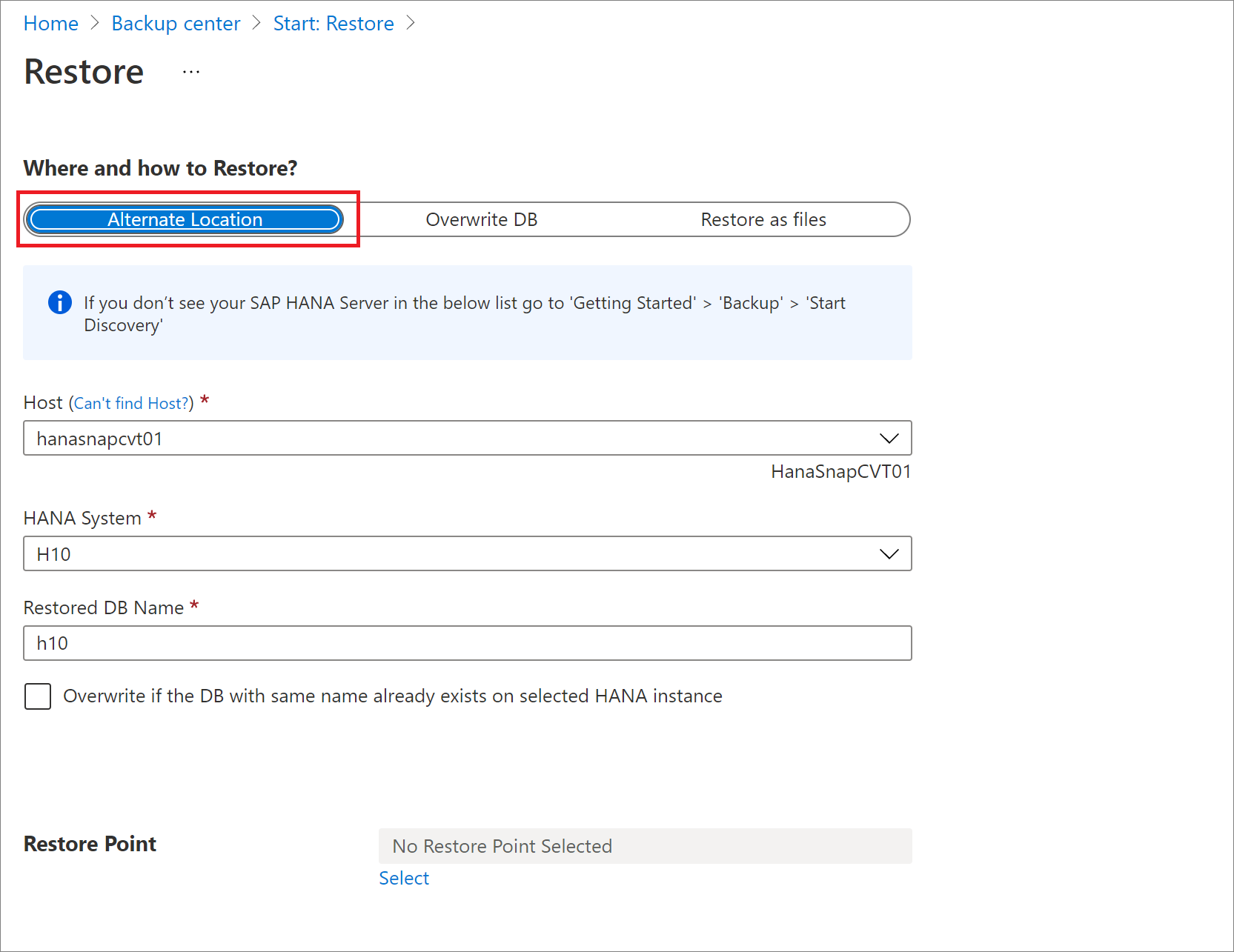
Selezionare il nome host e il nome dell'istanza di SAP HANA in cui si vuole ripristinare il database.
Verificare se l'istanza di SAP HANA di destinazione è pronta per essere ripristinata assicurandone l'idoneità per il backup. Per altre informazioni, consulta Prerequisiti.
Nella finestra di dialogo Nome del database ripristinato inserire il nome del database di destinazione.
Nota
I ripristini del contenitore di database singolo (SDC) devono seguire questi controlli.
Se applicabile, selezionare la casella di controllo Sovrascrivi se il database con lo stesso nome esiste già nell'istanza di HANA selezionata.
In Seleziona punto di ripristino selezionare Log (temporizzato) per eseguire il ripristino a un punto specifico temporizzato. In alternativa, selezionare Completo e differenziale per eseguire il ripristino a un punto di ripristino specifico.
Ripristinare come file
Nota
Il ripristino come file non funziona nelle condivisioni CIFS (Common Internet File System), ma funziona per Network File System (NFS).
Per ripristinare i dati di backup come file anziché come database, selezionare Ripristina come file. Dopo aver eseguito il dump dei file in un percorso specificato, è possibile portarli in qualsiasi computer SAP HANA in cui si desidera ripristinarli come database. Poiché è possibile spostare i file in qualsiasi computer, è ora possibile ripristinare i dati tra sottoscrizioni e aree.
Nel riquadro Ripristina, in Dove e come eseguire il ripristino, selezionare Ripristina come file.
Selezionare il nome del server host o HANA in cui si desidera ripristinare i file di backup.
Nella casella Percorso di destinazione del server immettere il percorso della cartella nel server selezionato nel passaggio precedente. Si tratta del percorso in cui il servizio eseguirà il dump di tutti i file di backup necessari.
I file di cui viene eseguito il dump sono:
- File di backup del database
- File di metadati JSON (per ogni file di backup interessato)
In genere, un percorso di condivisione di rete o il percorso di una condivisione file di Azure montata specificata come percorso di destinazione, consente di accedere più facilmente a questi file da altri computer nella stessa rete o con la stessa condivisione file di Azure montata su di essi.
Nota
Per ripristinare i file di backup del database in una condivisione file di Azure montata nella macchina virtuale registrata di destinazione, assicurarsi che l'account radice disponga delle autorizzazioni di lettura/scrittura per la condivisione.
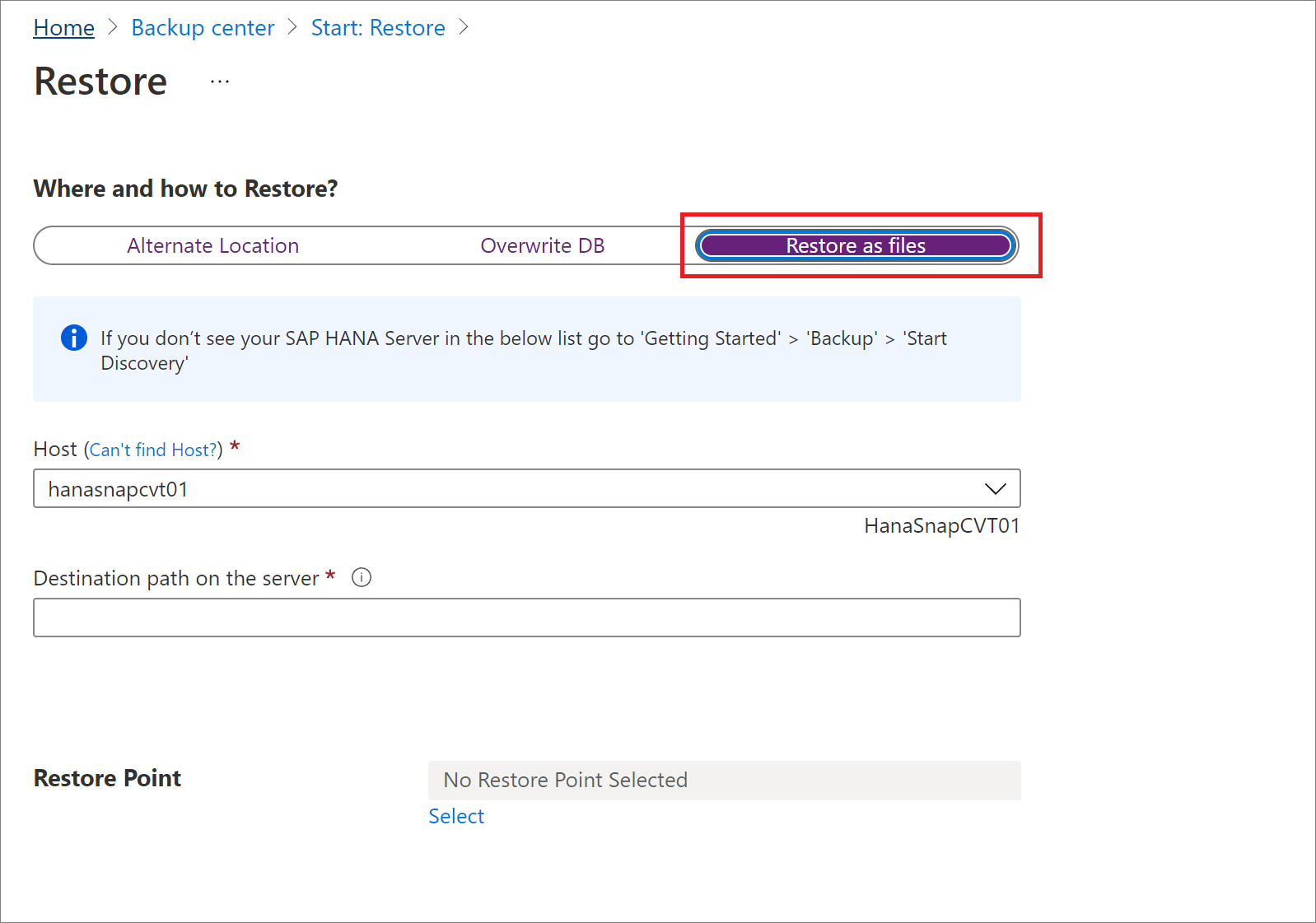
Selezionare il punto di ripristino in cui verranno ripristinati tutti i file e le cartelle di backup.
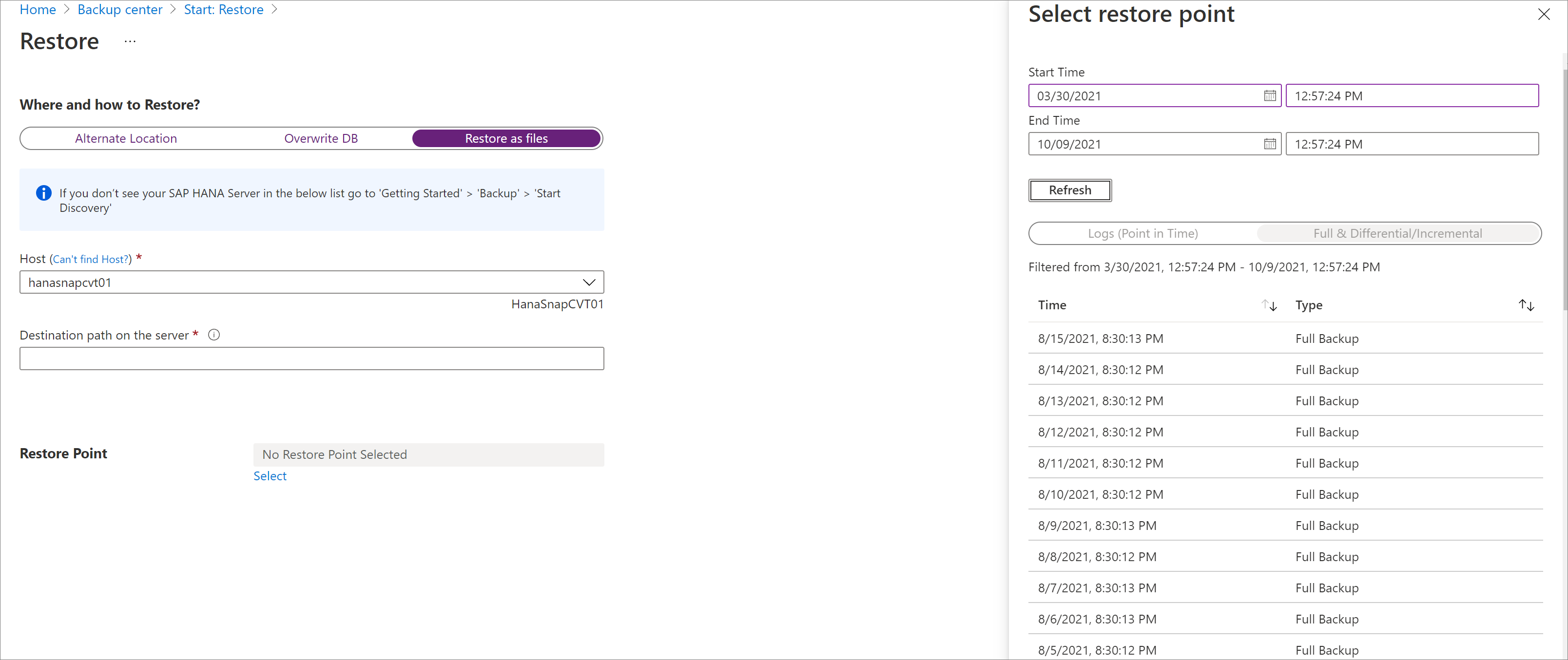
Tutti i file di backup associati al punto di ripristino selezionato vengono scaricati nel percorso di destinazione.
A seconda del tipo di punto di ripristino scelto (temporizzato o completo e differenziale), nel percorso di destinazione verranno visualizzate una o più cartelle create. Una delle cartelle, <> contiene i backup completi e l'altra cartella, Log contiene i backup del log e altri backup (ad esempio differenziale e incrementale).
Nota
Se è stato selezionato Ripristina in un momento specifico, i file di log, di cui è stato eseguito il dump nella macchina virtuale di destinazione, possono talvolta contenere log oltre il punto nel tempo scelto per il ripristino. Backup di Azure esegue questa operazione per assicurarsi che i backup del log per tutti i servizi HANA siano disponibili per il ripristino coerente e riuscito al momento scelto.
Spostare i file ripristinati nel server SAP HANA in cui si desidera ripristinarli come database e quindi eseguire le operazioni seguenti:
a) Impostare le autorizzazioni per la cartella o la directory in cui vengono archiviati i file di backup eseguendo il comando seguente:
chown -R <SID>adm:sapsys <directory>b. Eseguire il set successivo di comandi come
<SID>adm:su: <sid>admc. Generare il file di catalogo per il ripristino. Estrarre BackupId dal file di metadati JSON per il backup completo, che verrà usato più avanti nell'operazione di ripristino. Assicurarsi che i backup completi e del log (non presenti per il ripristino completo del backup) si trovino in cartelle diverse ed eliminare i file di metadati JSON in queste cartelle. Terza fase
hdbbackupdiag --generate --dataDir <DataFileDir> --logDirs <LogFilesDir> -d <PathToPlaceCatalogFile>-
<DataFileDir>: cartella contenente i backup completi. -
<LogFilesDir>: cartella che contiene i backup del log, i backup differenziali e i backup incrementali. Per Ripristino backup completo, perché la cartella di log non viene creata, aggiungere una directory vuota. -
<PathToPlaceCatalogFile>: cartella in cui deve essere inserito il file di catalogo generato.
d. È possibile eseguire il ripristino usando il file di catalogo appena generato tramite HANA Studio oppure eseguire la query di ripristino dello strumento HDBSQL di SAP HANA con questo catalogo appena generato. Le query HDBSQL sono elencate di seguito:
Per aprire il prompt di HDBSQL, eseguire il comando seguente:
hdbsql -U AZUREWLBACKUPHANAUSER -d systemDBPer eseguire il ripristino temporizzato:
Se si sta creando un nuovo database ripristinato, eseguire il comando HDBSQL per creare un nuovo database
<DatabaseName>e quindi arrestare il database per il ripristino usando il comandoALTER SYSTEM STOP DATABASE <db> IMMEDIATE. Tuttavia, se si ripristina solo un database esistente, eseguire il comando HDBSQL per arrestare il database.Eseguire quindi il comando seguente per ripristinare il database:
RECOVER DATABASE FOR <db> UNTIL TIMESTAMP <t1> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> USING BACKUP_ID <bkId> CHECK ACCESS USING FILE-
<DatabaseName>: nome del nuovo database o del database esistente da ripristinare. -
<Timestamp>: timestamp esatto del ripristino temporizzato. -
<DatabaseName@HostName>: nome del database il cui backup viene usato per il ripristino e il nome del server host o SAP HANA in cui risiede il database. L'opzioneUSING SOURCE <DatabaseName@HostName>specifica che il backup dei dati (usato per il ripristino) è di un database con un SID o un nome diverso rispetto al computer SAP HANA di destinazione. Non è necessario specificare per i ripristini eseguiti nello stesso server HANA da cui viene eseguito il backup. -
<PathToGeneratedCatalogInStep3>: percorso del file di catalogo generato nel "passaggio c". -
<DataFileDir>: cartella contenente i backup completi. -
<LogFilesDir>: cartella che contiene i backup del log, i backup differenziali e i backup incrementali (se presenti). -
<BackupIdFromJsonFile>: BackupId estratto nel "passaggio c".
-
Per eseguire il ripristino in un backup completo o differenziale specifico:
Se si sta creando un nuovo database ripristinato, eseguire il comando HDBSQL per creare un nuovo database
<DatabaseName>e quindi arrestare il database per il ripristino usando il comandoALTER SYSTEM STOP DATABASE <db> IMMEDIATE. Tuttavia, se si ripristina solo un database esistente, eseguire il comando HDBSQL per arrestare il database:RECOVER DATA FOR <DatabaseName> USING BACKUP_ID <BackupIdFromJsonFile> USING SOURCE '<DatabaseName@HostName>' USING CATALOG PATH ('<PathToGeneratedCatalogInStep3>') USING DATA PATH ('<DataFileDir>') CLEAR LOG-
<DatabaseName>: nome del nuovo database o del database esistente da ripristinare. -
<Timestamp>: timestamp esatto del ripristino temporizzato. -
<DatabaseName@HostName>: nome del database il cui backup viene usato per il ripristino e il nome del server host o SAP HANA in cui risiede il database. L'opzioneUSING SOURCE <DatabaseName@HostName>specifica che il backup dei dati (usato per il ripristino) è di un database con un SID o un nome diverso rispetto al computer SAP HANA di destinazione. Non è quindi necessario specificare per i ripristini eseguiti nello stesso server HANA da cui viene eseguito il backup. -
<PathToGeneratedCatalogInStep3>: percorso del file di catalogo generato nel "passaggio c". -
<DataFileDir>: cartella contenente i backup completi. -
<LogFilesDir>: cartella che contiene i backup del log, i backup differenziali e i backup incrementali (se presenti). -
<BackupIdFromJsonFile>: BackupId estratto nel "passaggio c".
-
Per eseguire il ripristino usando un ID di backup:
RECOVER DATA FOR <db> USING BACKUP_ID <bkId> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> CHECK ACCESS USING FILEEsempi:
Ripristino del sistema SAP HANA nello stesso server:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERipristino del tenant SAP HANA nello stesso server:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERipristino del sistema SAP HANA in un server diverso:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERipristino del tenant SAP HANA in un server diverso:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE
-

Ripristino parziale come file
Il servizio Backup di Azure decide la catena di file da scaricare durante il ripristino come file. Tuttavia, esistono scenari in cui potrebbe non essere necessario scaricare nuovamente l'intero contenuto.
Ad esempio, potrebbe essere disponibile un criterio di backup di completi settimanali, differenziali giornalieri e log e i file già scaricati per un particolare differenziale. Si è scoperto che questo non è il punto di ripristino corretto e si è deciso di scaricare il differenziale del giorno successivo. A questo punto è sufficiente il file differenziale, perché è già disponibile il backup completo iniziale. Con la possibilità di eseguire il ripristino parziale come file, fornito da Backup di Azure, è ora possibile escludere il backup completo dalla catena di download e scaricare solo il backup differenziale.
Esclusione dei tipi di file di backup
ExtensionSettingOverrides.json è un file JSON (JavaScript Object Notation) che contiene override per più impostazioni del servizio Backup di Azure per SQL. Per un ripristino parziale come operazione di file , è necessario aggiungere un nuovo campo JSON, RecoveryPointsToBeExcludedForRestoreAsFiles. Questo campo contiene un valore stringa che indica quali tipi di punti di ripristino devono essere esclusi nell'operazione di ripristino successiva come file .
Nel computer di destinazione in cui scaricare i file passare alla cartella opt/msawb/bin .
Creare un nuovo file JSON denominato ExtensionSettingOverrides.JSON, se non esiste già.
Aggiungere la coppia di valori di chiave JSON seguente:
{ "RecoveryPointsToBeExcludedForRestoreAsFiles": "ExcludeFull" }Modificare le autorizzazioni e la proprietà del file:
chmod 750 ExtensionSettingsOverrides.json chown root:msawb ExtensionSettingsOverrides.jsonNon è necessario riavviare alcun servizio. Il servizio Backup di Azure tenterà di escludere i tipi di backup nella catena di ripristino, come indicato in questo file.
RecoveryPointsToBeExcludedForRestoreAsFiles accetta solo valori specifici, che indicano i punti di ripristino da escludere durante il ripristino. Per SAP HANA, questi valori sono:
-
ExcludeFull. Verranno scaricati altri tipi di backup, ad esempio differenziali, incrementali e log, se presenti nella catena di punti di ripristino. -
ExcludeFullAndDifferential. Verranno scaricati altri tipi di backup, ad esempio incrementali e log, se presenti nella catena di punti di ripristino. -
ExcludeFullAndIncremental. Verranno scaricati altri tipi di backup, ad esempio differenziali e log, se presenti nella catena di punti di ripristino. -
ExcludeFullAndDifferentialAndIncremental. Altri tipi di backup, ad esempio i log, verranno scaricati, se presenti nella catena di punti di ripristino.
Ripristinare un punto temporizzato specifico
Se si è scelto log (punto temporizzato) come tipo di ripristino, eseguire le operazioni seguenti:
Selezionare un punto di ripristino dal grafico dei log e quindi selezionare OK per scegliere il punto di ripristino.
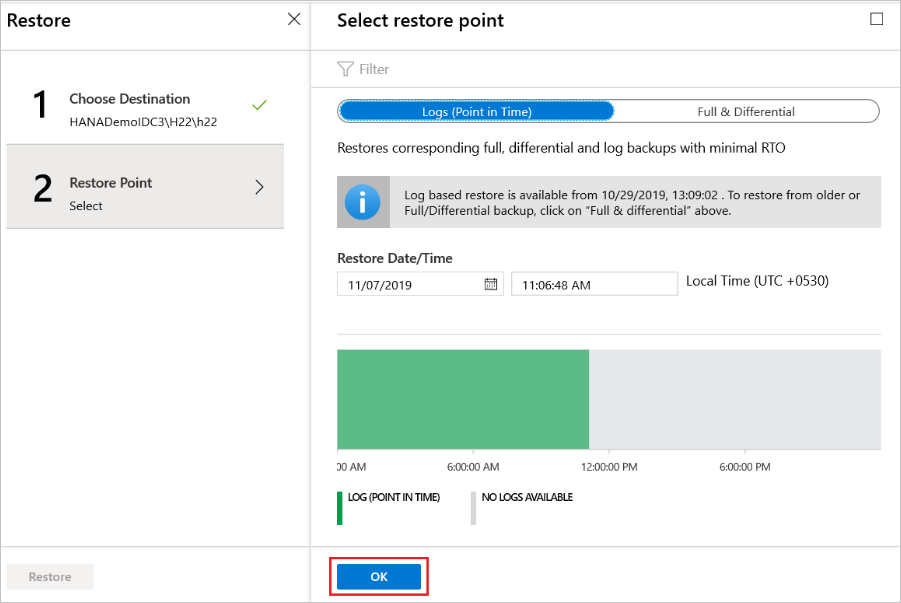
Nel menu Ripristina selezionare Ripristina per avviare il processo di ripristino.
Tenere traccia dello stato di avanzamento del ripristino nell'area Notifiche oppure tenere traccia del processo selezionando Ripristina processi nel menu del database.

Eseguire il ripristino in un punto di ripristino specifico
Se si è scelto Completo e differenziale come tipo di ripristino, eseguire le operazioni seguenti:
Selezionare un punto di ripristino dall'elenco e quindi selezionare OK per scegliere il punto di ripristino.
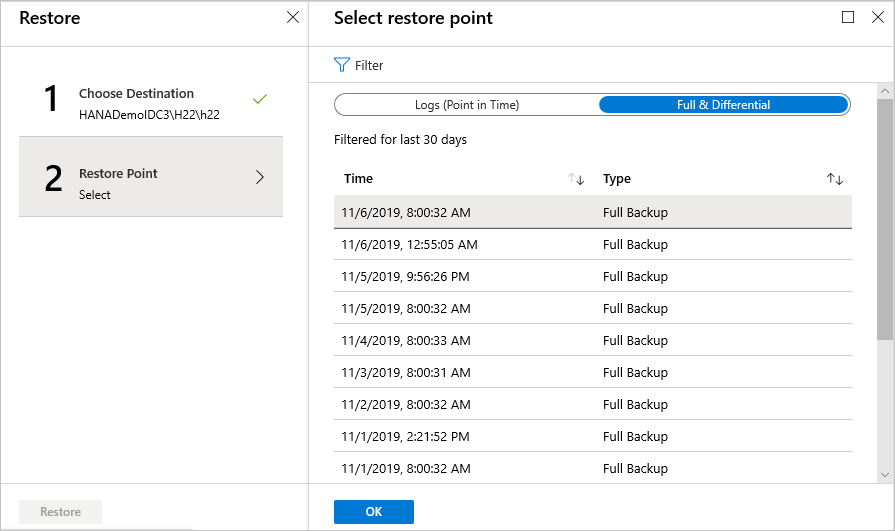
Nel menu Ripristina selezionare Ripristina per avviare il processo di ripristino.
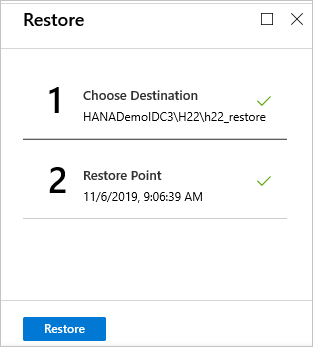
Tenere traccia dello stato di avanzamento del ripristino nell'area Notifiche oppure tenere traccia del processo selezionando Ripristina processi nel menu del database.

Nota
In Multiple Database Container (MDC) restores, after the system database is restore to a target instance, you need to run the preregistration script again. I ripristini del database tenant successivi avranno esito positivo. Per altre informazioni, vedere Risolvere i problemi relativi al ripristino di più database contenitore.
Ripristino tra aree
Come una delle opzioni di ripristino, il ripristino tra aree consente di ripristinare i database SAP HANA ospitati in macchine virtuali di Azure in un'area secondaria, ovvero un'area abbinata di Azure.
Per iniziare a usare la funzionalità, vedere Impostare il ripristino tra aree.
Visualizzare gli elementi di backup nell'area secondaria
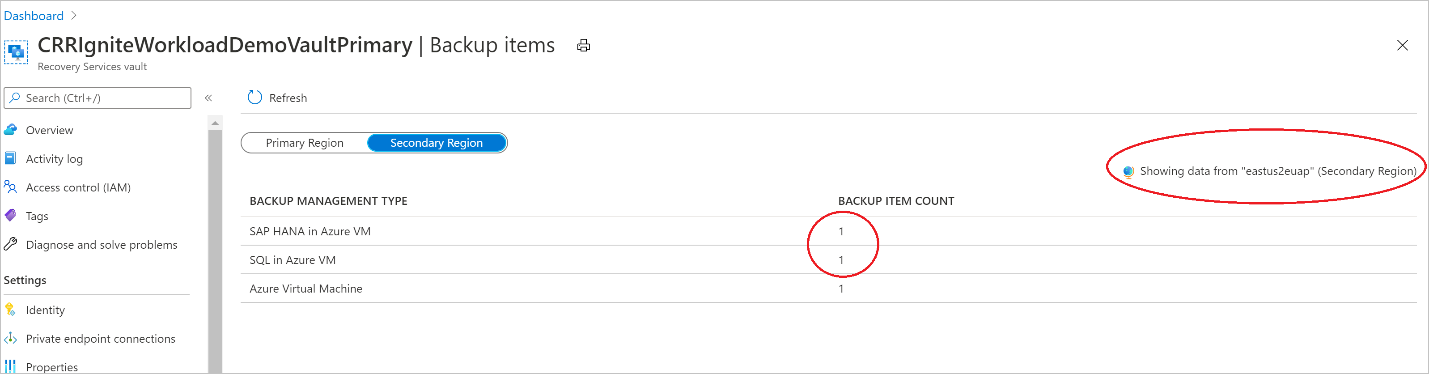
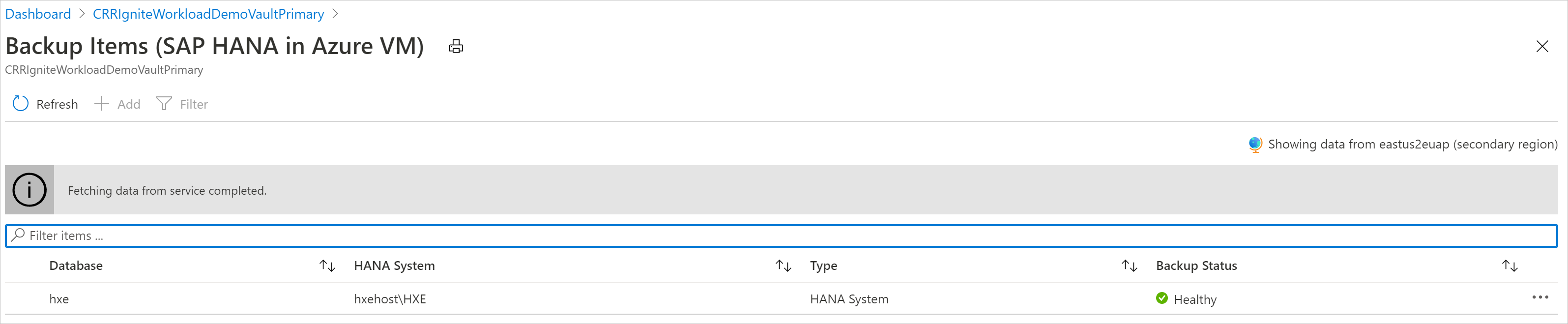
Se CRR è abilitato, è possibile visualizzare gli elementi di backup nell'area secondaria.
- Nella portale di Azure passare all'insieme di credenziali di Servizi di ripristino e quindi selezionare Elementi di backup.
- Selezionare Area secondaria per visualizzare gli elementi nell'area secondaria.
Nota
Nell'elenco vengono visualizzati solo i tipi di gestione dei backup che supportano la funzionalità CRR. Attualmente è consentito solo il supporto per il ripristino dei dati dell'area secondaria in un'area secondaria.
Ripristino nell'area secondaria
L'esperienza utente per il ripristino dell'area secondaria è simile all'esperienza utente per il ripristino dell'area primaria. Quando si configurano i dettagli nel riquadro Configurazione ripristino, viene richiesto di specificare solo i parametri dell'area secondaria. Un insieme di credenziali deve essere presente nell'area secondaria e il server SAP HANA deve essere registrato nell'insieme di credenziali nell'area secondaria.
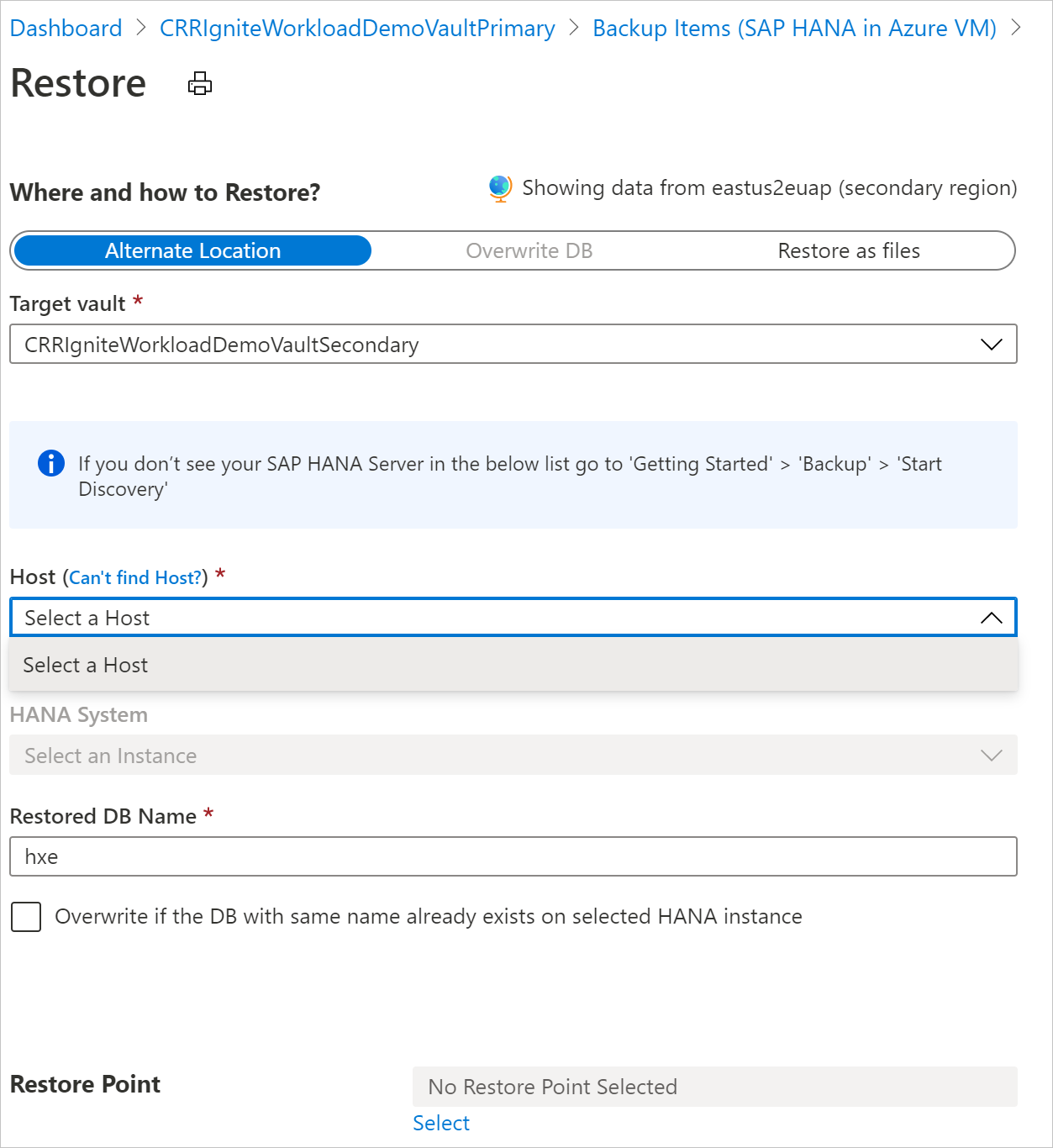
Nota
- Dopo l'attivazione del ripristino e nella fase di trasferimento dei dati, il processo di ripristino non può essere annullato.
- Il ruolo e il livello di accesso necessari per eseguire un'operazione di ripristino tra aree sono il ruolo Operatore di backup nella sottoscrizione e nell'accesso collaboratore (scrittura) nelle macchine virtuali di origine e di destinazione. Per visualizzare i processi di backup, il lettore di backup è l'autorizzazione minima necessaria nella sottoscrizione.
- L'obiettivo del punto di ripristino (RPO) per i dati di backup disponibili nell'area secondaria è di 12 ore. Pertanto, quando si attiva CRR, l'RPO per l'area secondaria è di 12 ore e la durata della frequenza del log (che può essere impostata su un minimo di 15 minuti).
Informazioni sui requisiti minimi di ruolo per il ripristino tra aree.
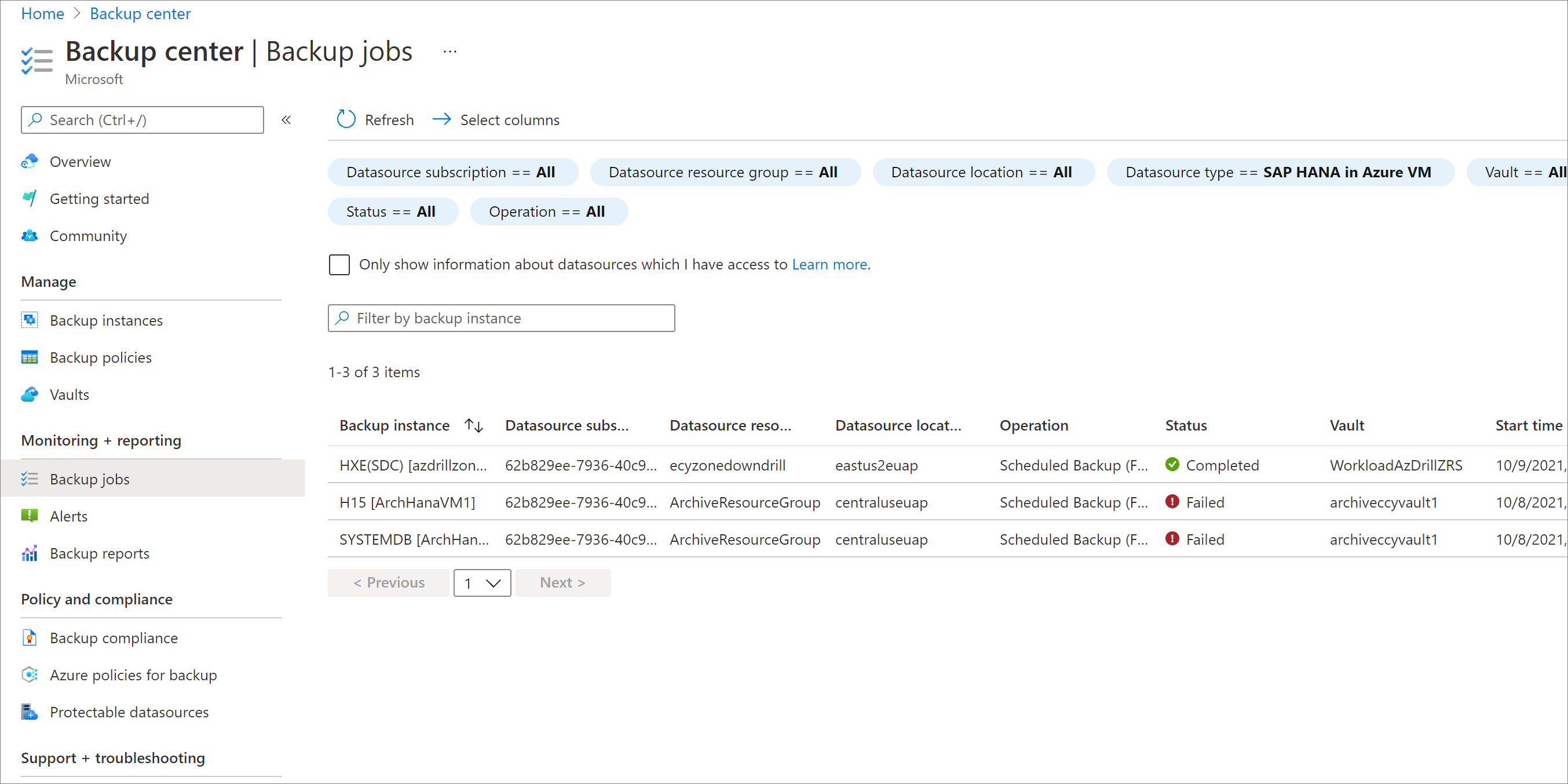
Monitorare i processi di ripristino dell'area secondaria
Nella portale di Azure passare al Centro backup e quindi selezionare Processi di backup.
Per visualizzare i processi nell'area secondaria, filtrare l'operazione per CrossRegionRestore.

Ripristino tra sottoscrizioni
Backup di Azure ora consente di ripristinare il database SAP HANA in qualsiasi sottoscrizione (in base ai requisiti di Controllo degli accessi in base al ruolo di Azure seguenti) dal punto di ripristino. Per impostazione predefinita, Backup di Azure esegue il ripristino nella stessa sottoscrizione in cui sono disponibili i punti di ripristino.
Con il ripristino tra sottoscrizioni è possibile eseguire il ripristino in qualsiasi sottoscrizione e in qualsiasi insieme di credenziali nel tenant, se sono disponibili le autorizzazioni di ripristino. Per impostazione predefinita, il ripristino tra sottoscrizioni è abilitato in tutti gli insiemi di credenziali di Servizi di ripristino (insiemi di credenziali esistenti e appena creati).
Nota
- È possibile attivare il ripristino tra sottoscrizioni dall'insieme di credenziali di Servizi di ripristino.
- Il ripristino tra sottoscrizioni è supportato solo per i backup basati su streaming/Backint e non è supportato per i backup basati su snapshot.
- Il ripristino tra aree combinato con il ripristino tra sottoscrizioni non è supportato.
Ripristino tra sottoscrizioni in un insieme di credenziali abilitato per l'endpoint privato
Per eseguire il ripristino tra sottoscrizioni in un insieme di credenziali abilitato per l'endpoint privato:
- In Insieme di credenziali di Servizi di ripristino di origine, passare alla scheda Rete.
- Passare alla sezione Accesso privato e creare Endpoint privati.
- Selezionare la sottoscrizione dell'insieme di credenziali di destinazione in cui si vuole eseguire il ripristino.
- Nella sezione Rete virtuale, selezionare la VNet della macchina virtuale di destinazione da ripristinare tra le sottoscrizioni.
- Creare l'endpoint privato e attivare il processo di ripristino.
Requisiti di Controllo degli accessi in base al ruolo di Azure
| Tipo di operazione | Backup Operators | Insieme di credenziali di Servizi di ripristino | Operatore alternativo |
|---|---|---|---|
| Eseguire il ripristino del database o come file | Virtual Machine Contributor |
Macchina virtuale di origine di cui è stato eseguito il backup | Anziché un ruolo predefinito, è possibile considerare un ruolo personalizzato con le autorizzazioni seguenti: - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
Virtual Machine Contributor |
Macchina virtuale di destinazione in cui verrà ripristinato il database o verranno creati i file. | Anziché un ruolo predefinito, è possibile considerare un ruolo personalizzato con le autorizzazioni seguenti: - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
|
Backup Operator |
Insieme di credenziali di Servizi di ripristino di destinazione |
Per impostazione predefinita, CSR è abilitato nell'insieme di credenziali di Servizi di ripristino. Per aggiornare le impostazioni di ripristino dell'insieme di credenziali di Servizi di ripristino, passare a Proprietà>Ripristino tra sottoscrizioni e apportare le modifiche necessarie.

Ripristino tra sottoscrizioni con l'interfaccia della riga di comando di Azure
az backup vault create
Aggiungere il parametro cross-subscription-restore-state che consente di impostare lo stato del ripristino tra sottoscrizioni dell'insieme di credenziali durante la creazione e l'aggiornamento dell'insieme di credenziali.
az backup recoveryconfig show
Aggiungere il parametro --target-subscription-id che consente di specificare la sottoscrizione di destinazione come input durante l'attivazione del ripristino tra sottoscrizioni per le origini dati SQL o HANA.
Esempio:
az backup vault create -g {rg_name} -n {vault_name} -l {location} --cross-subscription-restore-state Disable
az backup recoveryconfig show --restore-mode alternateworkloadrestore --backup-management-type azureworkload -r {rp} --target-container-name {target_container} --target-item-name {target_item} --target-resource-group {target_rg} --target-server-name {target_server} --target-server-type SQLInstance --target-subscription-id {target_subscription} --target-vault-name {target_vault} --workload-type SQLDataBase --ids {source_item_id}