Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Azure Chaos Studio è un servizio gestito che usa l'ingegneria chaos per aiutare a misurare, comprendere e migliorare la resilienza dell'applicazione cloud e del servizio. La progettazione di Chaos è una metodologia in base alla quale inserire errori reali nell'applicazione per eseguire esperimenti di inserimento degli errori controllati.
La resilienza è la capacità di un sistema di gestire e ripristinare le interruzioni. Le interruzioni dell'applicazione possono causare errori e guasti che possono influire negativamente sull'azienda o sulla missione. Per lo sviluppo, la migrazione o il funzionamento delle applicazioni Azure, è importante convalidare e migliorare la resilienza dell'applicazione.
Chaos Studio consente di evitare conseguenze negative verificando se l'applicazione risponde in modo efficace alle interruzioni e agli errori. È possibile usare Chaos Studio per testare la resilienza in caso di incidenti reali, ad esempio interruzioni o un utilizzo elevato della CPU nelle macchine virtuali.
Il video seguente fornisce altre informazioni generali su Chaos Studio:
Scenari di Chaos Studio
È possibile usare la progettazione di Chaos per vari scenari di convalida della resilienza che riguardano il ciclo di vita delle operazioni e lo sviluppo del servizio. Esistono due tipi di scenari:
- Sposta a destra: questi scenari usano un ambiente di produzione o di preproduzione. In genere, si eseguono scenari di spostamento a destra con traffico reale dei clienti o un carico simulato.
- Sposta a sinistra: questi scenari possono usare un ambiente di sviluppo o di test condiviso. È possibile eseguire scenari di spostamento a sinistra senza traffico reale dei clienti.
È possibile usare Chaos Studio per gli scenari comuni di progettazione di Chaos seguenti:
- Riprodurre un evento imprevisto che ha interessato l'applicazione per comprendere meglio l'errore. Assicurarsi che le riparazioni post-evento imprevisto impediscano che l'evento imprevisto si verifichi nuovamente.
- Prepararsi per un evento o una stagione importante con la convalida della resilienza, delle prestazioni, della scalabilità e del carico del "grande giorno".
- Eseguire drill sulla continuità aziendale e sul ripristino di emergenza per garantire che l'applicazione sia in grado di ripristinare rapidamente e conservare i dati critici in caso di emergenza.
- Eseguire drill sulla disponibilità elevata per testare la resilienza dell'applicazione in caso di interruzioni dell'area, errori di configurazione della rete, eventi di stress elevato o problemi che influiscono negativamente.
- Sviluppare benchmark delle prestazioni dell'applicazione.
- Pianificare le esigenze di capacità per gli ambienti di produzione.
- Eseguire test di stress o test di carico.
- Assicurarsi che i servizi migrati da un ambiente locale o un altro ambiente cloud rimangano resilienti agli errori noti.
- Creare fiducia nei servizi basati su architetture native del cloud.
- Verificare che gli strumenti del sito live, i dati di osservabilità e i processi a chiamata funzionino anche in condizioni impreviste.
Per molti di questi scenari, è prima necessario creare la resilienza usando esperimenti di Chaos ad hoc. Quindi, si verifica continuamente che le nuove distribuzioni non regrediscano la resilienza. Per effettuare tale verifica, eseguire esperimenti di Chaos come attività di controllo di distribuzione nelle pipeline di integrazione continua/distribuzione continua.
Funzionamento di Chaos Studio
Con Chaos Studio è possibile orchestrare le attività di fault injection in modo sicuro e controllato nelle risorse di Azure. Gli esperimenti di Chaos sono il cuore di Chaos Studio. Un esperimento di Chaos descrive gli errori da eseguire e le risorse da verificare. È possibile organizzare gli errori da eseguire in parallelo o in sequenza, a seconda delle esigenze.
Chaos Studio supporta due tipi di errori:
- Service-direct: questi errori vengono eseguiti direttamente su una risorsa di Azure, senza alcuna installazione o strumentazione. Alcuni esempi includono il riavvio di un cluster di cache di Azure per Redis o l'aggiunta della latenza di rete ai pod del servizio Azure Kubernetes.
- Basato su agente: questi errori vengono eseguiti in macchine virtuali o set di scalabilità di macchine virtuali per eseguire errori nel guest. Ad esempio, l'applicazione di un utilizzo elevato della memoria virtuale o l'eliminazione di un processo.
Ogni errore include parametri specifici che è possibile configurare, ad esempio il processo da terminare o l'utilizzo elevato di memoria da generare.
Quando si compila un esperimento chaos, si definiscono uno o più passaggi che vengono eseguiti in sequenza. Ogni passaggio contiene uno o più rami eseguiti in parallelo all'interno del passaggio. Ogni ramo contiene una o più azioni, ad esempio l'inserimento di un errore o l'attesa di una data durata.
Puoi organizzare le risorse destinate alla gestione di malfunzionamenti in gruppi chiamati selettori, per fare facilmente riferimento a un gruppo di risorse in ogni azione.
Il diagramma seguente illustra il layout di un esperimento di Chaos in Chaos Studio:
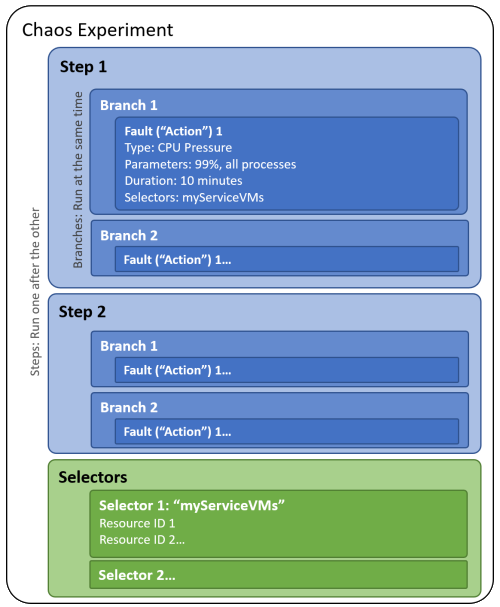
Un esperimento di Chaos è una risorsa di Azure in una sottoscrizione e in un gruppo di risorse. È possibile usare il portale di Azure o l'API REST di Chaos Studio per creare, aggiornare, avviare, annullare e visualizzare lo stato degli esperimenti.
Passaggi successivi
Ora che si è appreso come usare la progettazione di Caos, si è pronti per: