Intelligenza artificiale responsabile e attendibile
Microsoft illustra i sei principi guida per l'intelligenza artificiale responsabile: responsabilità, inclusività, affidabilità e sicurezza, equità, trasparenza, privacy e sicurezza. Questi principi sono essenziali per creare l'IA responsabile e affidabile man mano che passa a prodotti e servizi mainstream. Sono guidati da due prospettive: etica e spiegabile.
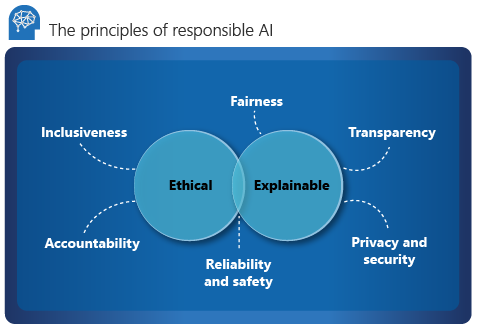
Etica
Dal punto di vista etico, l'IA dovrebbe:
- Essere equi e inclusivi nelle sue asserzioni.
- Essere responsabili delle sue decisioni.
- Non discriminare o ostacolare razze, disabilità o sfondi diversi.
Nel 2017 Microsoft ha istituito un comitato consultivo per l'IA, l'etica e gli effetti in ingegneria e ricerca (Aether). La responsabilità principale del comitato è consigliare questioni, tecnologie, processi e procedure consigliate per l'IA responsabile. Per altre informazioni, vedere Informazioni sul modello di governance Microsoft - Aether + Office of Responsible AI.
Responsabilità
La responsabilità è un elemento fondamentale dell'intelligenza artificiale responsabile. Le persone che progettano e distribuiscono un sistema di intelligenza artificiale devono essere responsabili delle azioni e delle decisioni, soprattutto quando progrediamo verso sistemi più autonomi.
Le organizzazioni devono valutare la possibilità di creare un organismo di revisione interno che fornisce supervisione, informazioni dettagliate e linee guida sullo sviluppo e la distribuzione di sistemi di intelligenza artificiale. Queste linee guida possono variare a seconda dell'azienda e dell'area geografica e devono riflettere il percorso di IA di un'organizzazione.
Inclusività
L'inclusione impone che l'IA consideri tutte le razze e le esperienze umane. Le procedure di progettazione inclusiva possono aiutare gli sviluppatori a comprendere e risolvere potenziali barriere che potrebbero escludere involontariamente le persone. Dove possibile, le organizzazioni devono usare la tecnologia di riconoscimento vocale, sintesi vocale e riconoscimento visivo per consentire alle persone con problemi di udito, visivo e altro.
Affidabilità e sicurezza
Affinché i sistemi di intelligenza artificiale siano attendibili, devono essere affidabili e sicuri. È importante che un sistema esegua come originariamente progettato e risponda in modo sicuro a nuove situazioni. La sua resilienza intrinseca deve opporsi a modifiche previste o non intenzionali.
Un'organizzazione deve stabilire test rigorosi e convalida per le condizioni operative per garantire che il sistema risponda in modo sicuro ai casi perimetrali. Deve integrare i metodi test A/B e champion/challenger nel processo di valutazione.
Le prestazioni di un sistema di intelligenza artificiale possono peggiorare nel tempo. Un'organizzazione deve stabilire un solido processo di monitoraggio e rilevamento dei modelli per misurare in modo reattivo e proattivo le prestazioni del modello e ripetere il training per la modernizzazione, se necessario.
Spiegabile
La spiegazione aiuta i data scientist, i revisori e i decision maker aziendali a garantire che i sistemi di IA possano giustificare le proprie decisioni e come raggiungono le loro conclusioni. La spiegazione consente anche di garantire la conformità ai criteri aziendali, agli standard del settore e alle normative governative.
Un data scientist deve essere in grado di spiegare a uno stakeholder come hanno ottenuto determinati livelli di accuratezza e cosa ha influenzato il risultato. Allo stesso modo, per rispettare i criteri aziendali, un revisore necessita di uno strumento che convalida il modello. Un decision maker aziendale deve ottenere fiducia fornendo un modello trasparente.
Strumenti di spiegabilità
Microsoft ha sviluppato InterpretML, un toolkit open source che consente alle organizzazioni di ottenere la spiegazione del modello. Supporta modelli glass-box e black-box:
La struttura dei modelli glass-box ne garantisce l'interpretabilità. Per questi modelli, Explainable Boosting Machine (EBM) fornisce lo stato dell'algoritmo in base a un albero delle decisioni o a modelli lineari. EBM fornisce spiegazioni senza perdita ed è modificabile da esperti di dominio.
I modelli black-box sono più complessi da interpretare a causa di una struttura interna complessa, la rete neurale. Gli strumenti di spiegazione come spiegazioni indipendenti dai modelli interpretabili locali (LIME) o SHapley Additive exPlanations (SHAP) interpretano questi modelli analizzando la relazione tra l'input e l'output.
Fairlearn è un'integrazione di Azure Machine Learning e un toolkit open source per l'SDK e l'interfaccia utente grafica AutoML. Usa gli strumenti di spiegazione per comprendere cosa influisce principalmente sul modello e usa esperti di dominio per convalidare queste influenze.
Per altre informazioni sulla spiegazione, esplorare l'interpretazione dei modelli in Azure Machine Learning.
Equità
L'equità è un principio etico fondamentale che tutti gli esseri umani mirano a comprendere e applicare. Questo principio è ancora più importante quando si sviluppano sistemi di intelligenza artificiale. I controlli chiave e i saldi devono assicurarsi che le decisioni del sistema non discriminano o esprimono un pregiudizio verso, un gruppo o un individuo basato su sesso, razza, orientamento sessuale o religione.
Microsoft fornisce un elenco di controllo per l'equità dell'intelligenza artificiale che offre indicazioni e soluzioni per i sistemi di intelligenza artificiale. Queste soluzioni sono suddivise in cinque fasi: progettazione, prototipo, compilazione, lancio ed evoluzione. Ogni fase elenca le attività consigliate di due diligence che consentono di ridurre al minimo l'impatto dell'iniquità nel sistema.
Fairlearn si integra con Azure Machine Learning e supporta data scientist e sviluppatori per valutare e migliorare l'equità dei sistemi di intelligenza artificiale. Fornisce algoritmi di mitigazione dell'iniquità e un dashboard interattivo che visualizza l'equità del modello. Un'organizzazione deve usare il toolkit e valutare attentamente l'equità del modello durante la creazione. Questa attività deve essere parte integrante del processo di data science.
Informazioni su come attenuare l'iniquità nei modelli di Machine Learning.
Trasparenza
Il raggiungimento della trasparenza aiuta il team a comprendere:
- Dati e algoritmi usati per eseguire il training del modello.
- Logica di trasformazione applicata ai dati.
- Modello finale generato.
- Asset associati del modello.
Queste informazioni offrono informazioni dettagliate sulla modalità di creazione del modello, in modo che il team possa riprodurlo in modo trasparente. Gli snapshot all'interno delle aree di lavoro di Azure Machine Learning supportano la trasparenza tramite la registrazione o un nuovo training tutte le metriche e gli asset correlati al training coinvolti nell'esperimento.
Privacy e sicurezza
Un titolare dei dati è obbligato a proteggere i dati in un sistema di intelligenza artificiale. La privacy e la sicurezza sono parte integrante di questo sistema.
I dati personali devono essere protetti e l'accesso a tali dati non dovrebbe compromettere la privacy di un individuo. La privacy differenziale di Azure consente di proteggere e preservare la privacy tramite la casualità dei dati e l'aggiunta di disturbo per nascondere le informazioni personali agli scienziati dei dati.
Linee guida sull'intelligenza artificiale incentrata sull'uomo
Le linee guida per la progettazione dell'intelligenza artificiale incentrata sull'uomo sono costituite da 18 principi che si verificano in quattro periodi: fase iniziale, durante l'interazione, in caso di errore e nel tempo. Questi principi aiutano un'organizzazione a produrre un sistema di intelligenza artificiale più inclusivo e incentrato sull'uomo.
Iniziale
Chiarire cosa può fare il sistema. Se il sistema di intelligenza artificiale usa o genera metriche, è importante mostrarle tutte e illustrare come vengono rilevate.
Chiarire il modo in cui il sistema può fare ciò che fa. Aiutare gli utenti a comprendere che l'intelligenza artificiale non è completamente accurata. Impostare le aspettative per quando il sistema di intelligenza artificiale potrebbe commettere errori.
Durante l'interazione
Mostra informazioni contestualmente rilevanti. Fornire informazioni visive relative al contesto e all'ambiente correnti dell'utente, ad esempio gli hotel nelle vicinanze. Restituisce i dettagli vicini alla destinazione e alla data.
Attenuare i pregiudizi sociali. Assicurarsi che il linguaggio e il comportamento non introduca stereotipi o pregiudizi imprevisti. Ad esempio, una funzionalità di completamento automatico deve essere inclusiva dell'identità di genere.
In caso di errore
- Supportare una chiusura efficiente. Fornire un meccanismo semplice per ignorare o ignorare funzionalità o servizi indesiderati.
- Supportare una correzione efficiente. Offrire un modo intuitivo per semplificare la modifica, il perfezionamento o il ripristino.
- Chiarire perché il sistema ha fatto quello che ha fatto. Ottimizzare l'intelligenza artificiale spiegabile per offrire informazioni dettagliate sulle asserzioni del sistema di intelligenza artificiale.
Nel tempo
- Ricorda le interazioni recenti. Conservare una cronologia delle interazioni per riferimento futuro.
- Imparare dal comportamento dell'utente. Personalizzare l'interazione in base al comportamento degli utenti.
- Aggiornare e adattarsi con cautela. Limitare le modifiche che possono causare interruzioni ed eseguire gli aggiornamenti in base al profilo dell'utente.
- Incoraggiare un feedback granulare. Raccogliere i feedback degli utenti dalle interazioni con il sistema di intelligenza artificiale.
Framework di intelligenza artificiale attendibile
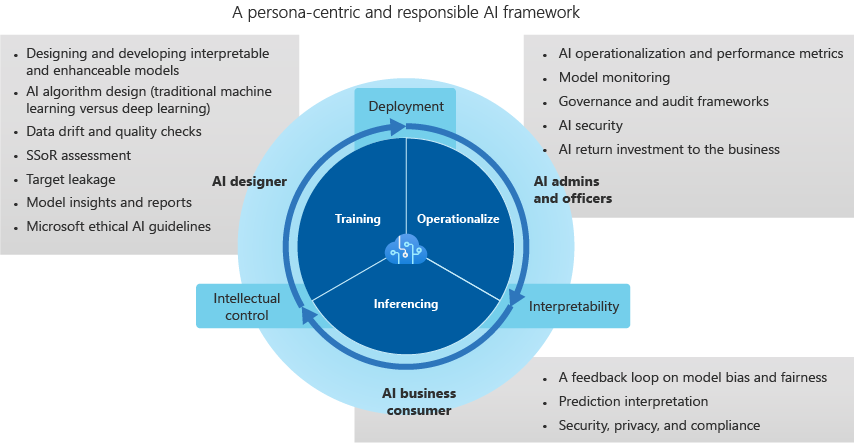
Progettista di intelligenza artificiale
Il progettista di intelligenza artificiale crea il modello ed è responsabile di quanto segue:
Deriva dei dati e controlli di qualità. La finestra di progettazione rileva gli outlier ed esegue controlli di qualità dei dati per identificare i valori mancanti. La finestra di progettazione standardizza anche la distribuzione, esamina i dati e produce report sui casi d'uso e sui progetti.
Valutazione dei dati nell'origine del sistema per identificare potenziali distorsioni.
Progettazione di algoritmi di intelligenza artificiale per ridurre al minimo le distorsioni dei dati. Questi sforzi includono l'individuazione di come binning, raggruppamento e normalizzazione (soprattutto nei modelli di Machine Learning tradizionali come quelli basati su albero) può eliminare i gruppi di minoranza dai dati. La progettazione di intelligenza artificiale categorica ripete i pregiudizi dei dati raggruppando classi sociali, razziali e di genere in verticali del settore che si basano su informazioni sanitarie protette (PHI) e dati personali.
Ottimizzazione del monitoraggio e degli avvisi per identificare possibili perdite e rafforzare lo sviluppo del modello.
Definizione delle procedure consigliate per la creazione di report e informazioni dettagliate che offrono una comprensione granulare del modello. La finestra di progettazione evita approcci black box che usano la caratteristica o l'importanza del vettore, il clustering UMAP (Uniform Manifold Approssimazione e proiezione), la statistica H-H di Friedman, gli effetti delle funzionalità e le tecniche correlate. Le metriche di identificazione consentono di definire l'influenza predittiva, le relazioni e le dipendenze tra correlazioni in set di dati complessi e moderni.
Amministratore e responsabili dell'intelligenza artificiale
L'amministratore e i responsabili dell'intelligenza artificiale supervisionano le operazioni, la governance e le metriche del framework di controllo e delle prestazioni. Supervisionano anche il modo in cui viene implementata la sicurezza dell'IA e il ritorno dell'azienda sugli investimenti. Le attività includono:
Monitoraggio di un dashboard di rilevamento che semplifica il monitoraggio del modello e combina le metriche del modello per i modelli di produzione. Il dashboard è incentrato sull'accuratezza, la riduzione del modello, la deviazione dei dati, la deviazione e le modifiche nella velocità/errore dell'inferenza.
Implementazione di distribuzione flessibile e ridistribuzione (preferibilmente tramite un'API REST) che consente l'implementazione dei modelli in un'architettura aperta e indipendente. L'architettura integra il modello con i processi aziendali e genera valore per i cicli di feedback.
Lavorare per creare la governance del modello e l'accesso per impostare i limiti e ridurre l'impatto operativo e aziendale negativi. Gli standard di controllo degli accessi in base al ruolo determinano i controlli di sicurezza, che mantengono gli ambienti di produzione con restrizioni e l'INDIRIZZO IP.
Utilizzo dei framework di controllo e conformità dell'intelligenza artificiale per tenere traccia dello sviluppo e della modifica dei modelli per rispettare gli standard specifici del settore. L'intelligenza artificiale interpretabile e responsabile è basata su misure di spiegabilità, caratteristiche concise, visualizzazioni dei modelli e linguaggio verticale del settore.
Consumer aziendali di intelligenza artificiale
I consumer aziendali di intelligenza artificiale (esperti aziendali) chiudono il ciclo di feedback e forniscono input per il progettista di intelligenza artificiale. Il processo decisionale predittivo e le potenziali implicazioni di pregiudizio come l'equità e le misure etiche, la privacy e la conformità e l'efficienza aziendale aiutano a valutare i sistemi di intelligenza artificiale. Ecco alcune considerazioni per i consumatori aziendali:
I cicli di feedback appartengono all'ecosistema di un'azienda. I dati che mostrano la distorsione, gli errori, la velocità di stima e l'equità di un modello stabiliscono attendibilità e equilibrio tra progettazione di intelligenza artificiale, amministratore e funzionari. La valutazione basata sull'uomo dovrebbe migliorare gradualmente l'IA nel tempo.
Ridurre al minimo l'apprendimento dell'intelligenza artificiale da dati complessi multidimensionali può impedire l'apprendimento distorto. Questa tecnica è chiamata apprendimento less-than-one-shot (LO-shot).
L'uso della progettazione dell'interpretabilità e degli strumenti include sistemi di intelligenza artificiale responsabili di potenziali distorsioni. I problemi di distorsione ed equità dei modelli devono essere contrassegnati e inseriti in un sistema di rilevamento di avvisi e anomalie che apprende da questo comportamento e risolve automaticamente le distorsioni.
Ogni valore predittivo deve essere suddiviso in singole caratteristiche o vettori in base all'importanza o all'impatto. Deve fornire spiegazioni complete di stima che possono essere esportate in un report aziendale per revisioni di controllo e conformità, trasparenza dei clienti e conformità aziendale.
A causa di un aumento dei rischi globali per la sicurezza e la privacy, le procedure consigliate per la risoluzione delle violazioni dei dati durante l'inferenza richiedono la conformità alle normative nei singoli settori verticali. Gli esempi includono avvisi sulla non conformità con PHI e dati personali o avvisi relativi alla violazione delle leggi nazionali/regionali sulla sicurezza.
Passaggi successivi
Esplorare le linee guida per l'intelligenza artificiale incentrata sull'uomo per altre informazioni sull'intelligenza artificiale responsabile.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per