Obiettivi del livello di servizio di monitoraggio cloud
Questo articolo fa parte di una serie della guida al monitoraggio del cloud.
Nelle sezioni seguenti vengono illustrati i principi fondamentali degli obiettivi del livello di servizio e come implementarli e applicarli.
Panoramica
Gli obiettivi del livello di servizio (SLO) sono obiettivi misurabili per gli indicatori di livello di servizio incentrati sui clienti. Misurano l'esperienza del cliente di un carico di lavoro aziendale o dell'infrastruttura e determinano se il provider di servizi aziendale soddisfa le promesse effettuate in un contratto di servizio negoziato formalmente o un contratto informale tra tutte le parti.
In qualità di Service Broker, ci si basa sull'impegno di Microsoft sull'affidabilità dei servizi, come definito nei contratti di servizio Microsoft per i servizi di Azure. In questo modo è possibile concentrarsi sulle responsabilità della catena di servizi, ad esempio il monitoraggio sintetico, la connettività di rete e la sicurezza e la conformità.
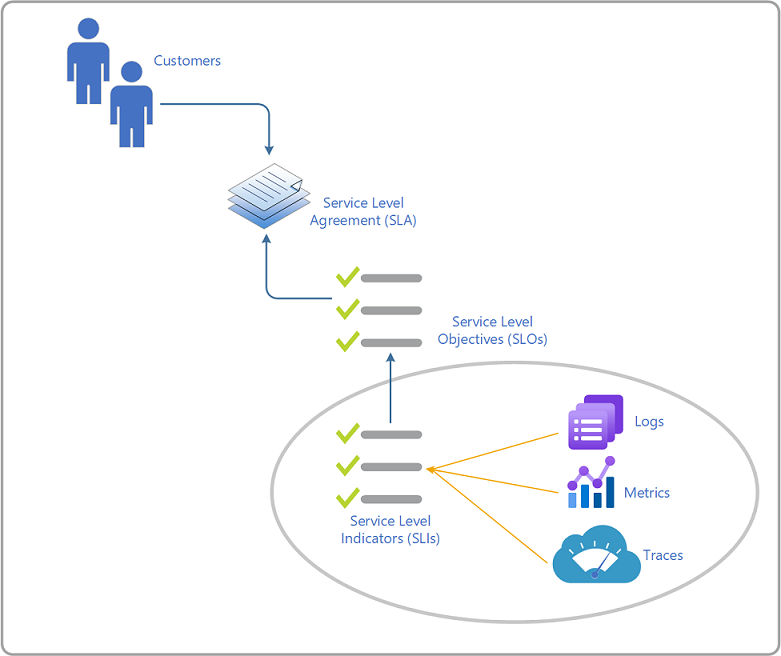
Terminologia
Di seguito sono riportate le definizioni per ognuno di questi termini e una breve descrizione. Queste definizioni sono tratte dal manuale di Google SRE.
| Termine | Descrizione |
|---|---|
| Contratto di servizio | In genere un impegno vincolante tra un provider di servizi e un cliente. Un accordo include in genere le conseguenze della mancanza degli obiettivi SLO . Aspetti specifici del servizio sono qualità, disponibilità e responsabilità concordate tra il provider di servizi e l'utente del servizio. |
| Monitoraggio | La pratica di raccogliere dati quantitativi in tempo reale su servizi e sistemi. |
| Metriche | Misura il comportamento del servizio pertinente e può essere aggregato in indicatori del livello di servizio (SLI), elaborati e aggregati per misurare lo stato operativo corrente di un servizio e quantificarne il comportamento. I contratti di servizio sono gli indicatori principali e in tempo reale dell'integrità corrente di un servizio. |
| Registri | Inizia con il codice e segnala informazioni su una singola esecuzione di un percorso di codice o un evento discreto. Usare queste informazioni per risolvere i problemi e lavorare per identificare i problemi della causa radice che influiscono sull'esperienza del cliente e sull'affidabilità del servizio misurata dai contratti di servizio/contratti di servizio. |
| Obiettivo del livello di servizio (SLO) | Valore di destinazione per il livello di servizio, come misurato dagli indicatori del livello di servizio, che imposta le aspettative sul livello di prestazioni di un servizio. I contratti di servizio tengono traccia specificamente dell'esperienza dei clienti end-to-end. Per stabilire buoni contratti di servizio, in genere si inizia definendo l'esperienza desiderata e quindi instrumentando il codice del servizio per misurare tale esperienza (raccogliere i contratti di servizio pertinenti) e impostare la destinazione del modo in cui si soddisfano o meno le aspettative dei clienti. |
| Indicatore del livello di servizio (SLI) | Metrica che quantifica la qualità o l'affidabilità del servizio. Come minimo, vengono valutati quattro contratti di servizio comuni: disponibilità, latenza, velocità effettiva e frequenza di errore. |
| Disponibilità | In genere si riferisce alla percentuale misurabile o osservabile di tempo in cui un sistema è operativo e funzionale. È possibile misurare la disponibilità come destinazione rivolta ai clienti per garantire la continuità dell'esperienza, che è influenzata da uno o più problemi di affidabilità (e altre modalità di errore correlate alle modifiche di configurazione, agli aggiornamenti applicati e altro ancora). |
| Budget degli errori | Percentuale del buffer rimanente relativo all'SLO. I budget degli errori sono lo strumento DevOps e l'IT usa per bilanciare l'affidabilità del servizio con il ritmo dell'innovazione. |
Scopo dei contratti di servizio
I contratti di servizio servono molti scopi essenziali per lo sviluppo e le operazioni dei carichi di lavoro cloud, tra cui:
- Quasi in tempo reale (NRT): per offrire una visualizzazione NRT dell'integrità di un servizio come sperimentato da un cliente.
- Riduzione del tempo per la notifica (TTN): guidare la notifica automatizzata dei problemi di servizio ai clienti, riducendo significativamente il tempo necessario per la notifica (TTN).
- Segnale principale per i clienti: fungere da segnale principale per le operazioni di distribuzione, guidando il rollback automatizzato in caso di problemi, esponendo così un minor numero di clienti a potenziali problemi.
- Verifica delle modifiche: fornire la convalida delle modifiche apportate al miglioramento previsto dell'esperienza del cliente.
- Determinare le priorità: aiutare i team a capire se creare funzionalità o lavorare sull'affidabilità.
- Integrità dei servizi informazioni dettagliate: abilitare discussioni incentrate sul cliente sull'integrità dei servizi.
- Ridurre il tempo necessario per l'analisi: velocizzare la mitigazione e l'analisi della causa radice dei problemi dei clienti indirizzando l'attenzione al servizio responsabile.
- Dipendenze dell'architettura: fungere da input essenziale nelle decisioni architetturali quando i servizi prendono dipendenze.
- Crea attendibilità: fornire una comprensione condivisa delle misure di integrità, che crea attendibilità tra i team.
- Portare la trasparenza: esporre gli stessi contratti di servizio usati per gestire la nostra attività ai clienti in modo che possano gestire i propri servizi.
- Singolo riquadro di vetro: abilitare un singolo riquadro orizzontale di vetro per i servizi e le relative dipendenze e silo di scomposizione.
Usando i contratti di servizio per guidare il processo di progettazione, DevOps e l'IT possono comprendere in anticipo l'integrità dell'applicazione o del servizio di infrastruttura che compilano o e migrate in Azure. Questo può quindi essere usato per guidare sia l'uomo che le decisioni automatizzate che devono essere prese sull'affidabilità di questi servizi. Questa trasformazione nella pratica di progettazione influirà significativamente sull'affidabilità di tali servizi a breve termine.
Come definire i contratti di servizio?
L'obiettivo di un SLO è ottenere segnali chiari che misurano accuratamente la qualità dal punto di vista del cliente. Ogni team di servizio crea un piccolo set di obiettivi del livello di servizio (SLO) che definiscono l'intervallo consentito per le metriche misurabili più importanti del servizio, come sperimentato dal consumer del servizio. Uno SLO è un obiettivo numerico definito per una metrica generata da un servizio. Le metriche associate a questo obiettivo possono essere monitorate per determinare se il servizio è integro.
Ecco, ad esempio, un esempio semplificato di SLO per un'applicazione basata sul Web di rilevamento tempo interno: le richieste negli ultimi 5 minuti vengono servite in meno di 1000 millisecondi al 99° percentile.
Le metriche sono aggregazioni di dati delle serie temporali denominati indicatori del livello di servizio. Dove vengono raccolti i contratti di servizio è importante molto. Nell'esempio precedente, se il cliente interagisce con il servizio usando un'API, misurare la latenza del sistema e il tempo per elaborare le richieste sono contratti di servizio accurati. Tuttavia, se il cliente interagisce con il servizio usando un portale Web, il tempo totale per gestire la richiesta deve includere anche le prestazioni JavaScript della pagina Web.
L'attenzione per i proprietari del servizio consiste nel determinare quanto segue:
- Quali scenari sono indicatori critici dell'integrità dei servizi dal punto di vista del cliente,
- Dove raccogliere i contratti di servizio in modo che siano il più vicini possibile all'esperienza del cliente e
- Quali devono essere i contratti di servizio per questi contratti di servizio?
I contratti di servizio possono essere definiti con un approccio graduale per favorire il raggiungimento o sono prescritti direttamente dall'azienda. Si usano i contratti di servizio definiti da un servizio per prendere decisioni sull'architettura relative alla modalità di compilazione. È quindi essenziale scegliere con attenzione gli scenari da misurare e l'intervallo di tempo per misurarli. Per riepilogare, un SLO è costituito dai valori seguenti:
- Un SLI. Ad esempio, la percentuale di richieste sufficientemente veloci, misurate dal servizio di bilanciamento del carico, è inferiore a 400 ms.
- Durata. Periodo di tempo in cui viene misurata una metrica.
- Destinazione. Ad esempio, una percentuale di destinazione di richieste veloci alle richieste totali (ad esempio il 90%) che si prevede di soddisfare per una determinata durata.
Tipi di contratti di servizio
Se si esamina il settore, esistono due tipi di contratti di servizio:
Contratti di servizio incentrati sui servizi: questi contratti di servizio sono obiettivi tattici che i team definiscono per migliorare la qualità del servizio nel tempo gradualmente. Sono progettati per essere obiettivi pragmatici raggiungibili in un'attività cardine dell'ingegneria. Ad esempio, se un servizio raggiunge attualmente il 99,7% di disponibilità, il team potrebbe impostare un obiettivo per raggiungere la disponibilità del 99,9% nel trimestre successivo.
Contratti di servizio incentrati sul cliente: questi contratti di servizio definiscono lo stato o l'obiettivo ideale per il futuro. A questo punto, ulteriori investimenti in qualità sarebbero ritenuti inutili perché si soddisfano pienamente le aspettative dei clienti.
Ad esempio, se il cliente prevede che un servizio aziendale o di infrastruttura gestito fornisca una disponibilità del 99,99% e il servizio attualmente raggiunge solo la disponibilità del 99,8%, l'SLO incentrato sul cliente è ancora del 99,99%.
La definizione di contratti di servizio appropriati richiede tempo. Il primo passaggio consiste nel comunicare con i clienti e capire cosa vogliono gli utenti dal servizio per derivare una piccola selezione di indicatori e documentarlo. Informazioni sugli scenari e le tolleranze per il modo in cui usano il servizio e le esigenze del servizio per gestire correttamente l'azienda. Si tratta in genere di un'esperienza iterativa, con le loro aspettative che vanno dalla disponibilità del 100% in tutte le condizioni, senza alcun impatto sul flusso di ricavi, attraverso la gestione delle aspettative di varianti selvaggie tra segmenti di clienti.
Gli approcci di monitoraggio che esaminano solo l'integrità del servizio (o dell'istanza del servizio) sono vulnerabili ai problemi di esperienza dei clienti mancanti a entrambe le estremità dello spettro; l'integrità dei servizi non è sempre correlata alla qualità dell'esperienza del cliente. Ciò è dovuto al fatto che esistono caratteristiche di comportamento diverse tra un servizio PaaS di Azure e saaS, la configurazione di tali servizi di Azure, la modalità e la posizione (ovvero l'area in cui vengono distribuite) le risorse e l'aggiunta del codice o della logica personalizzata, che aggiunge ulteriore complessità.
Quando si definisce un SLO, è importante ricordare che i provider di servizi cloud sono una dipendenza dal contratto di servizio. Tenere conto dei contratti di servizio specificati per ognuno dei servizi. Per Azure, vedere Contratti di servizio (SLA) per i servizi online
Come si definiscono i contratti di servizio?
Una specifica SLI è una dichiarazione formale delle aspettative degli utenti su una particolare dimensione di affidabilità per il servizio, ad esempio la latenza o la disponibilità.
Iniziare con semplicità selezionando le metriche corrette per misurare e raccogliere e non sovraplicarlo raccogliendo troppe metriche che non sono significative. Assicurarsi che i contratti di servizio definiti abbiano una relazione diretta con l'esperienza del cliente. Questo è il motivo per cui è essenziale comprendere la prospettiva degli utenti per iniziare con solo pochi indicatori.
Se il servizio è vincolato in qualche modo, ad esempio memoria o CPU, la saturazione può anche essere un'eccellente SLI. Tuttavia, la saturazione non deve essere usata come SLO perché non corrisponde direttamente a un'esperienza utente scarsa (un servizio può avere un utilizzo elevato della memoria, ma gli utenti non sono interessati).
È consigliabile creare fino a tre indicatori. Più di tre indicatori aggiungono raramente un valore significativo. Spesso, un numero eccessivo di indicatori potrebbe significare che si includono sintomi di indicatori primari. Il traffico e la saturazione devono essere aggiuntivi a questi tre indicatori principali, in quanto descrivono il carico del servizio e il supporto sull'interpretazione di altri indicatori di servizio.
Come si implementano i contratti di servizio?
I contratti di servizio più importanti sono quelli che rappresentano più chiaramente un impatto sul servizio dal punto di vista del cliente. Per molti servizi, ciò include latenza, velocità effettiva, frequenza degli errori e disponibilità. Se il servizio ha considerazioni speciali che influisce sull'esperienza del cliente, è necessario misurare anche i contratti di servizio per tali aree. Ad esempio, la latenza di elaborazione end-to-end per un servizio di messaggistica è un indicatore diretto dell'esperienza del cliente e deve essere coperta da un SLI.
Esempi di SLO
Le risorse umane sono interessate a modernizzare l'applicazione interna basata sul web e a ospitarla nel cloud di Azure con l'aiuto dell'IT aziendale. Vogliono che il servizio continui a raggiungere tutti gli utenti dell'organizzazione, pertanto sono interessati ai seguenti elementi:
- Report sull'utilizzo e numero di utenti che usano il servizio nel tempo.
- Monitoraggio regolare dell'integrità, ad esempio disponibilità, prestazioni, sicurezza e conformità (garanzia del servizio).
- Costo, ad esempio il costo mensile di un servizio.
- Cybersecurity, in termini di controllo dell'accesso alle risorse e ai dati seguendo una strategia di sicurezza Zero Trust.
Come illustrato in precedenza, le categorie SLO/SLI e gli esempi sono necessari per definire nelle fasi iniziali della progettazione del servizio. Questo non è affatto diverso dai servizi locali che si sta creando.
Categorie SLO Tables/SLI
Gli esempi seguenti non sono un elenco completo. Sebbene i contratti di servizio di affidabilità e manutenibilità siano caratteristiche distintive dei sistemi per decenni, è possibile definire contratti di servizio che includono misure per la sicurezza informatica, la qualità e l'esperienza utente e i costi.
Servizi
Le tipiche misure generali di un servizio o di un sistema sono in genere codificate nei contratti di servizio. La maggior parte dei contratti moderni misura la disponibilità come SLO chiave e usa semplici misure di tempo di inattività basate su elementi chiave del carico di lavoro o unità di produzione, ad esempio token di autenticazione, cassette postali o account di archiviazione.
| Categoria | Descrizione | Esempio |
|---|---|---|
| Disponibilità | Tempo di inattività semplice o tempo medio tra manutenzione o disponibilità operativa (MOUNTAINM/(MTBM+MDT)) | 99,99% in un periodo mensile |
| Capacità | Garantire prestazioni aziendali e di servizio adeguate, massime o ottimali, velocità effettiva, archiviazione, persone, larghezza di banda, domanda, risorse e funzioni del servizio. Include limiti di manodopera e tempo da usare come trigger. | % utilizzo (CPU, archiviazione, memoria, latenza, velocità effettiva, ridimensionamento) |
| Sicurezza | Minacce e vulnerabilità attive (interne ed esterne) che potrebbero o causano danni all'azienda, agli asset e ai dati. | Rilevamento delle minacce HAFNIUM |
| Conformità | Aggiornamenti, livelli di manutenzione, conformità alla protezione avanzata, deviazione della configurazione desiderata | Aggiornamenti gestiti del 99,5% su tutti gli asset |
| Continuità | Capacità di sopravvivere e recuperare da grandi emergenze ed eventi esterni. | Tempo (ricostituzione) |
| Quality of Service (QoS) | Caratteristiche dell'esperienza effettiva degli utenti nel tempo. | Qualità delle chiamate di Teams - Perdita < di pacchetti ricevuta 2% |
Affidabilità
L'affidabilità, l'SLO classico, implica il grado di affidabilità, durabilità e qualità nel tempo, di sistemi, servizi, risorse o componenti per errori e failover, con il lavoro di gestione applicato per risolvere gli errori (ad esempio la compilazione in una rete di distribuzione di contenuti o l'aggiunta di una rete per la distribuzione di contenuti) per aumentare il tempo operativo o la disponibilità. Può anche significare l'accuratezza, la fedeltà, l'integrità e l'attendibilità dei dati usati per misurare i contratti di servizio. Può significare la probabilità classica che un sistema eseguirà la sua funzione prevista in condizioni specificate, ad esempio lo stress della temperatura. La resilienza include anche fattori di progettazione predefiniti o funzionalità che forniscono flessibilità, ad esempio scalabilità, raffreddamento, bilanciamento del carico, ripristino, domanda imprevedibile, prestazioni ridotte sotto stress grave e progettazione per la continuità in situazioni di emergenza più grandi (in genere uno SLO separato).
| Categoria | Descrizione | Esempio |
|---|---|---|
| Frequenza errori | Numero di errori nelle ore operative totali | 5 errori in 973 ore il nostro .00514 |
| Tempo medio tra errore (MTBF) | MOUNTAINF è l'inversa della frequenza di guasto | 194,6 ore |
Manutenibilità
Combinare i contratti di servizio di supporto per i processi di gestione dei servizi IT, ad esempio eventi imprevisti e gestione dei problemi, insieme ai contratti di servizio di affidabilità, in modo che sia possibile ottenere la misurazione della disponibilità.
| Categoria | Descrizione | Esempio |
|---|---|---|
| Prestazioni degli eventi imprevisti del servizio | Per categoria, prodotto o priorità. | Misure relative al tempo e ai costi per ogni fase del ciclo di vita degli eventi imprevisti. |
| Prestazioni degli eventi imprevisti di sicurezza | Per categoria, prodotto o priorità. | Misure relative al tempo e ai costi per ogni fase del ciclo di vita degli eventi imprevisti. |
| Tempo medio componente per il ripristino (MTTR) | Dal rilevamento degli eventi tramite il ripristino o la correzione. | |
| Tempo medio tra manutenzione (MOUNTAINM) | Tempo medio o medio tra tutte le azioni di manutenzione, incluse le azioni preventive in cui si verifica il normale lavoro di produzione. | Vedere Tempo ritardo manutenzione |
| Tempo ritardo manutenzione (MDT) | Tempo totale dal rilevamento al ripristino, tra cui logistica e ritardo amministrativo. | Tempo necessario per sostituire l'hardware per includere l'ordine, la spedizione e l'installazione. |
Esperienza cliente
| Categoria | Descrizione | Esempio |
|---|---|---|
| Velocità effettiva. | Quantità, velocità o velocità del carico di lavoro o carico produttivo posizionato su un sistema nel tempo. | Transazioni per unità di tempo. |
| Percentuale di errore | Numero di errori totali come percentuale. | % Eventi di sicurezza |
| Latenza | Misura del tempo o del ritardo dall'input all'output, dallo spostamento del lavoro attraverso un processo o dall'applicazione all'utente. | Secondi medi. |
Altri
| Categoria | Descrizione | Esempio |
|---|---|---|
| Costo | Misurare le spese, la fatturazione e le fatture in base al servizio, al componente o al tempo. | Spese in conto capitale o spese operative |
| Copertura | Percentuale di componenti, sistemi e servizi in gestione (conformità) | Conformità |
| Affidabilità dei feed | Errori di heartbeat, connettori, modifiche e altro ancora. | Rilevamento delle modifiche nei dati aziendali cruciali. |
| Produttività | Efficacia per eseguire attività in modo produttivo | Lavoro, tempo per dipendente, produttività analista. |
Considerazioni
Verificare l'accesso. Assicurarsi che ai manager e ad altri utenti dell'organizzazione venga concesso l'accesso alle visualizzazioni disponibili in Monitoraggio di Azure o da altri servizi di Azure, in particolare SaaS e PaaS di Azure, per evitare di duplicarli.
Assicurarsi di monitorare la copertura o la visibilità totale degli asset. Assicurarsi che gli agenti, i log, le tabelle e le query generati per tutti gli asset che devono essere gestiti e protetti e identificare "punti ciechi" o lacune nella copertura per garantire il realismo nei contratti di servizio.
Ottenere i dati corretti davanti ai consumer corretti. Assicurarsi che i consumer di contratti di servizio e contratti di servizio possano interpretare i dati sottostanti per creare decisioni di attendibilità e guida usando le informazioni acquisite dai dati.
Fare promesse ragionevoli. Quando si impostano i contratti di servizio come destinazioni in particolare quando la gestione dei costi è essenziale, assicurarsi che le prestazioni effettive del sistema non vengano eseguite eccessivamente né sotto-recapito o regolano la destinazione per gestire le aspettative dei clienti.
Tenere conto di eventi esterni imprevisti. Sviluppare piani di continuità e valutazioni dei rischi per tenere conto degli eventi non sotto il controllo, ad esempio meteo, interruzioni dell'alimentazione o emergenze.
Account per modifica. Assicurarsi che i contratti di servizio tengano conto delle modifiche apportate al servizio o alle modifiche apportate all'affidabilità tecnica, alla velocità effettiva, alla qualità e alla manutenibilità, ad esempio riduzioni del personale di supporto.
Fornire un set bilanciato di contratti di servizio. Assicurarsi che una gamma di contratti di servizio che forniscano una prospettiva bilanciata o di 360 gradi sul servizio o sul sistema e un focus sull'affidabilità.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per