Esercitazione: Configurare un batch di prodotti dati
Questa esercitazione illustra come configurare i servizi di prodotto dati già distribuiti. Usare Azure Data Factory per integrare e orchestrare i dati e usare Microsoft Purview per individuare, gestire e gestire gli asset di dati.
Scopri come:
- Creare e distribuire le risorse necessarie
- Assegnare ruoli e autorizzazioni di accesso
- Connessione risorse per l'integrazione dei dati
Questa esercitazione consente di acquisire familiarità con i servizi distribuiti nel <DMLZ-prefix>-dev-dp001 gruppo di risorse prodotto dati di esempio. Sperimentare l'interfaccia dei servizi di Azure tra loro e quali misure di sicurezza sono disponibili.
Quando si distribuiscono i nuovi componenti, si avrà la possibilità di esaminare il modo in cui Purview connette la governance dei servizi per creare una mappa olistica e aggiornata del panorama dei dati. Il risultato è l'individuazione automatica dei dati, la classificazione dei dati sensibili e la derivazione dei dati end-to-end.
Prerequisiti
Prima di iniziare a configurare il batch di prodotti dati, assicurarsi di soddisfare questi prerequisiti:
Abbonamento di Azure. Se non si ha una sottoscrizione di Azure, creare subito l'account Azure gratuito.
Autorizzazioni per la sottoscrizione di Azure. Per configurare Purview e Azure Synapse Analytics per la distribuzione, è necessario avere il ruolo Accesso utenti Amministrazione istrator o il ruolo Proprietario nella sottoscrizione di Azure. Nell'esercitazione verranno impostate più assegnazioni di ruolo per i servizi e le entità servizio.
Risorse distribuite. Per completare l'esercitazione, queste risorse devono essere già distribuite nella sottoscrizione di Azure:
- Zona di destinazione per la gestione dei dati. Per altre informazioni, vedere il repository GitHub della zona di destinazione della gestione dei dati.
- Zona di destinazione dei dati. Per altre informazioni, vedere il repository GitHub della zona di destinazione dei dati.
- Batch di prodotti dati. Per altre informazioni, vedere il repository GitHub del batch di prodotti dati.
Account Microsoft Purview. L'account viene creato come parte della distribuzione della zona di destinazione della gestione dei dati.
Runtime di integrazione self-hosted. Il runtime viene creato come parte della distribuzione della zona di destinazione dei dati.
Nota
In questa esercitazione i segnaposto fanno riferimento alle risorse prerequisite distribuite prima di iniziare l'esercitazione:
<DMLZ-prefix>fa riferimento al prefisso immesso al momento della creazione della distribuzione della zona di destinazione della gestione dei dati.<DLZ-prefix>fa riferimento al prefisso immesso al momento della creazione della distribuzione della zona di destinazione dei dati.<DP-prefix>fa riferimento al prefisso immesso al momento della creazione della distribuzione batch del prodotto dati.
Creare istanze di database SQL di Azure
Per iniziare questa esercitazione, creare due istanze di esempio database SQL. I database verranno usati per simulare origini dati CRM e ERP nelle sezioni successive.
Nel portale di Azure, nei controlli globali del portale selezionare l'icona di Cloud Shell per aprire un terminale di Azure Cloud Shell. Selezionare Bash per il tipo di terminale.

In Cloud Shell eseguire lo script seguente. Lo script trova il
<DLZ-prefix>-dev-dp001gruppo di risorse e il<DP-prefix>-dev-sqlserver001server SQL di Azure nel gruppo di risorse. Lo script crea quindi le due istanze di database SQL nel<DP-prefix>-dev-sqlserver001server. I database vengono prepopolati con i dati di esempio AdventureWorks. I dati includono le tabelle usate in questa esercitazione.Assicurarsi di sostituire il valore segnaposto del
subscriptionparametro con il proprio ID sottoscrizione di Azure.# Azure SQL Database instances setup # Create the AdatumCRM and AdatumERP databases to simulate customer and sales data. # Use the ID for the Azure subscription you used to deployed the data product. az account set --subscription "<your-subscription-ID>" # Get the resource group for the data product. resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dp001')==\`true\`].name") # Get the existing Azure SQL Database server name. sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") # Create the first SQL Database instance, AdatumCRM, to create the customer's data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumCRM --service-objective Basic --sample-name AdventureWorksLT # Create the second SQL Database instance, AdatumERP, to create the sales data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumERP --service-objective Basic --sample-name AdventureWorksLT
Al termine dell'esecuzione dello script, nel <DP-prefix>-dev-sqlserver001 server SQL di Azure sono disponibili due nuove istanze AdatumCRM di database SQL e AdatumERP. Entrambi i database si trovano nel livello di calcolo Basic. I database si trovano nello stesso <DLZ-prefix>-dev-dp001 gruppo di risorse usato per distribuire il batch di prodotti dati.
Configurare Purview per catalogare il batch di prodotti dati
Completare quindi i passaggi per configurare Purview per catalogare il batch di prodotti dati. Per iniziare, creare un'entità servizio. Quindi, si configurano le risorse necessarie e si assegnano ruoli e autorizzazioni di accesso.
Creare un'entità servizio
Nel portale di Azure, nei controlli globali del portale selezionare l'icona di Cloud Shell per aprire un terminale di Azure Cloud Shell. Selezionare Bash per il tipo di terminale.
Rivedere lo script seguente:
- Sostituire il valore segnaposto del
subscriptionIdparametro con il proprio ID sottoscrizione di Azure. - Sostituire il valore segnaposto del
spnameparametro con il nome da usare per l'entità servizio. Il nome dell'entità servizio deve essere univoco nella sottoscrizione.
Dopo aver aggiornato i valori dei parametri, eseguire lo script in Cloud Shell.
# Replace the parameter values with the name you want to use for your service principal name and your Azure subscription ID. spname="<your-service-principal-name>" subscriptionId="<your-subscription-id>" # Set the scope to the subscription. scope="/subscriptions/$subscriptionId" # Create the service principal. az ad sp create-for-rbac \ --name $spname \ --role "Contributor" \ --scope $scope- Sostituire il valore segnaposto del
Controllare l'output JSON per ottenere un risultato simile all'esempio seguente. Prendere nota o copiare i valori nell'output da usare nei passaggi successivi.
{ "appId": "<your-app-id>", "displayName": "<service-principal-display-name>", "name": "<your-service-principal-name>", "password": "<your-service-principal-password>", "tenant": "<your-tenant>" }
Configurare l'accesso e le autorizzazioni dell'entità servizio
Dall'output JSON generato nel passaggio precedente, ottenere i valori restituiti seguenti:
- ID entità servizio (
appId) - chiave dell'entità servizio (
password)
L'entità servizio deve avere le autorizzazioni seguenti:
- Archiviazione ruolo Lettore dati BLOB negli account di archiviazione.
- Autorizzazioni di lettura dati per le istanze di database SQL.
Per configurare l'entità servizio con il ruolo e le autorizzazioni necessarie, completare i passaggi seguenti.
Archiviazione di Azure autorizzazioni dell'account
Nel portale di Azure passare all'account
<DLZ-prefix>devrawArchiviazione di Azure. Nel menu delle risorse selezionare Controllo di accesso (IAM).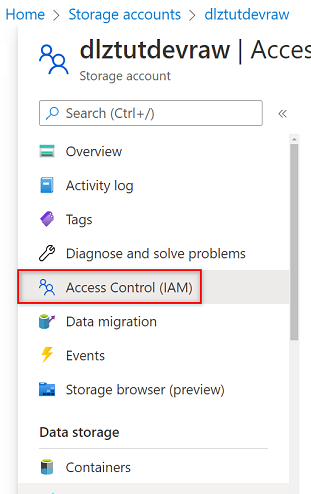
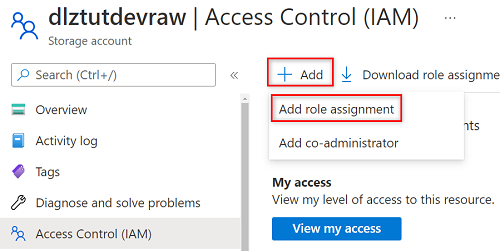
Seleziona Aggiungi>Aggiungi assegnazione ruolo.
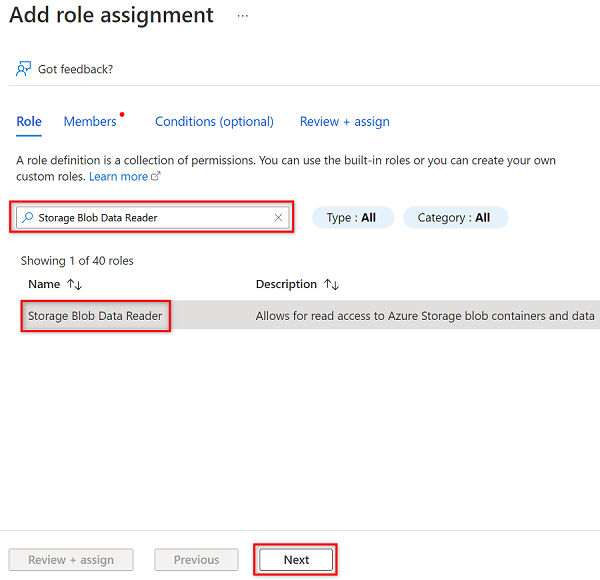
Nella scheda Ruolo della scheda Aggiungi assegnazione di ruolo cercare e selezionare Archiviazione Lettore dati BLOB. Quindi, seleziona Avanti.
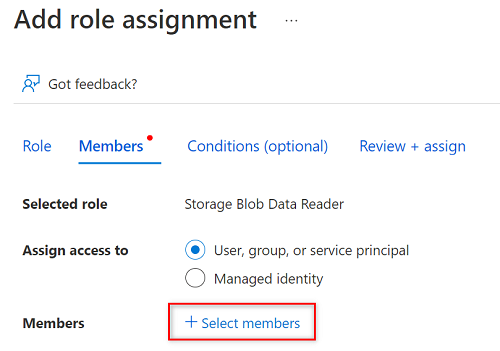
In Membri scegliere Seleziona membri.
In Seleziona membri cercare il nome dell'entità servizio creata.

Nei risultati della ricerca selezionare l'entità servizio e quindi scegliere Seleziona.
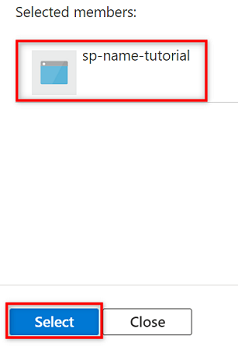
Per completare l'assegnazione di ruolo, selezionare Rivedi e assegna due volte.
Ripetere i passaggi descritti in questa sezione per gli account di archiviazione rimanenti:
<DLZ-prefix>devencur<DLZ-prefix>devwork
autorizzazioni database SQL
Per impostare le autorizzazioni di database SQL, connettersi alla macchina virtuale SQL di Azure usando l'editor di query. Poiché tutte le risorse si trovano dietro un endpoint privato, è prima necessario accedere al portale di Azure usando una macchina virtuale host di Azure Bastion.
Nella portale di Azure connettersi alla macchina virtuale distribuita nel <DMLZ-prefix>-dev-bastion gruppo di risorse. Se non si è certi di come connettersi alla macchina virtuale usando il servizio host Bastion, vedere Connessione a una macchina virtuale.
Per aggiungere l'entità servizio come utente nel database, potrebbe essere necessario aggiungere se stessi come amministratore di Microsoft Entra. Nei passaggi 1 e 2 si aggiunge se stessi come amministratore di Microsoft Entra. Nei passaggi da 3 a 5 si assegnano le autorizzazioni dell'entità servizio a un database. Dopo aver eseguito l'accesso al portale dalla macchina virtuale host Bastion, cercare macchine virtuali SQL di Azure nella portale di Azure.
Passare alla
<DP-prefix>-dev-sqlserver001macchina virtuale SQL di Azure. Nel menu delle risorse in Impostazioni selezionare Microsoft Entra ID.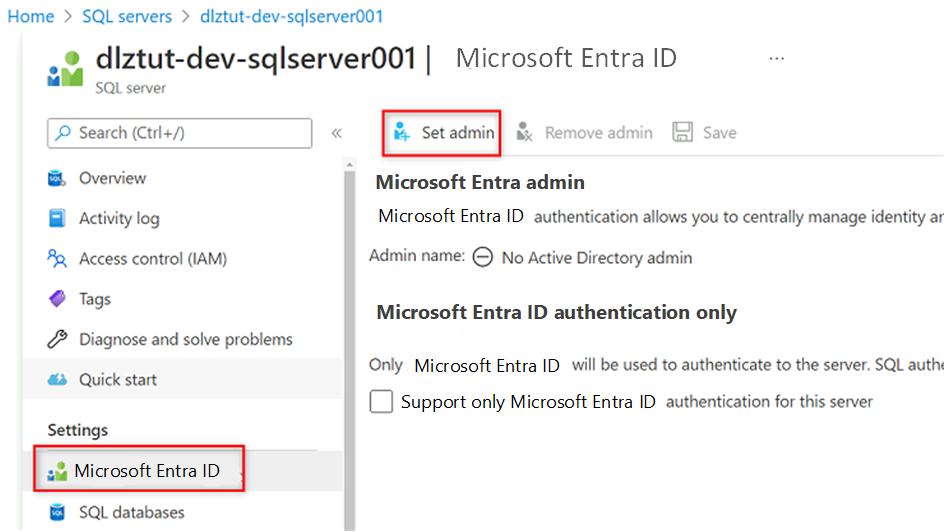
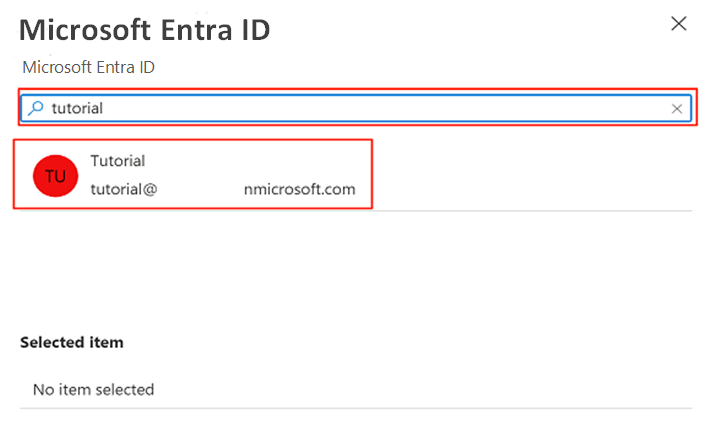
Nella barra dei comandi selezionare Imposta amministratore. Cercare e selezionare il proprio account. Scegli Seleziona.
Nel menu delle risorse selezionare Database SQL e quindi selezionare il
AdatumCRMdatabase.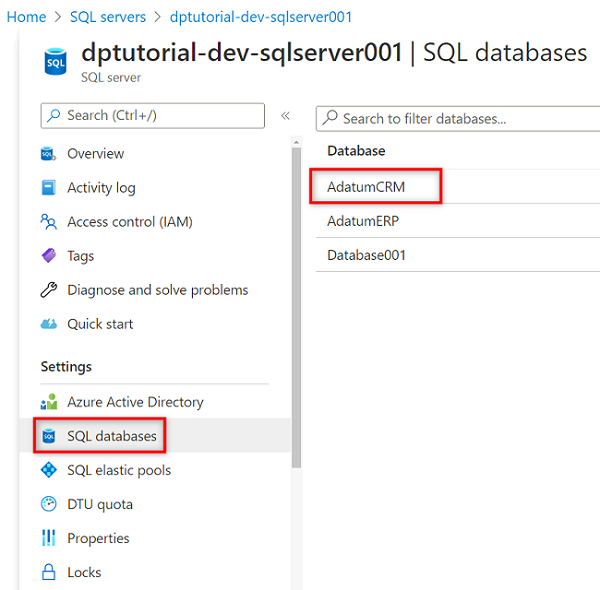
Nel menu della risorsa AdatumCRM selezionare Editor di query (anteprima). In Autenticazione di Active Directory selezionare il pulsante Continua come per accedere.
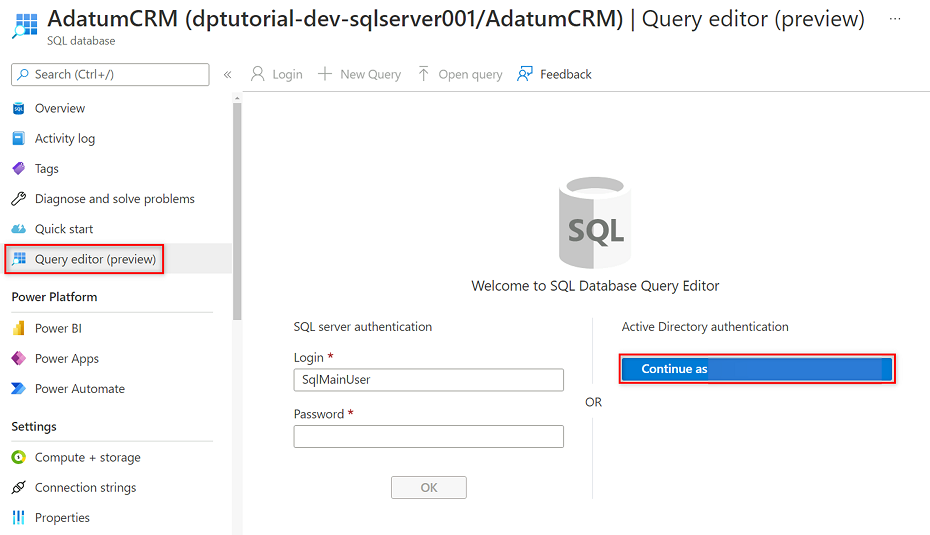
Nell'editor di query rivedere le istruzioni seguenti per sostituire
<service principal name>con il nome dell'entità servizio creata, ad esempiopurview-service-principal. Eseguire quindi le istruzioni .CREATE USER [<service principal name>] FROM EXTERNAL PROVIDER GO EXEC sp_addrolemember 'db_datareader', [<service principal name>] GO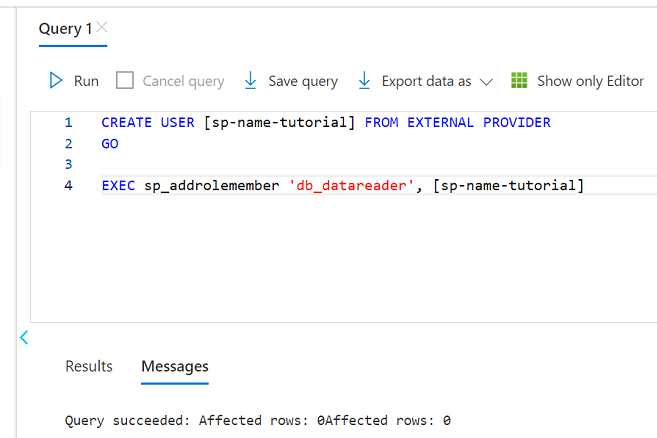
Ripetere i passaggi da 3 a 5 per il AdatumERP database.
Configurare l'insieme di credenziali delle chiavi
Purview legge la chiave dell'entità servizio da un'istanza di Azure Key Vault. L'insieme di credenziali delle chiavi viene creato nella distribuzione della zona di destinazione della gestione dei dati. Per configurare l'insieme di credenziali delle chiavi sono necessari i passaggi seguenti:
Aggiungere la chiave dell'entità servizio all'insieme di credenziali delle chiavi come segreto.
Concedere all'agente di lettura segreti MSI purview nell'insieme di credenziali delle chiavi.
Aggiungere l'insieme di credenziali delle chiavi a Purview come connessione all'insieme di credenziali delle chiavi.
Creare una credenziale in Purview che punti al segreto dell'insieme di credenziali delle chiavi.
Aggiungere autorizzazioni per aggiungere un segreto all'insieme di credenziali delle chiavi
Nel portale di Azure passare al servizio Azure Key Vault. Cercare l'insieme di credenziali delle
<DMLZ-prefix>-dev-vault001chiavi.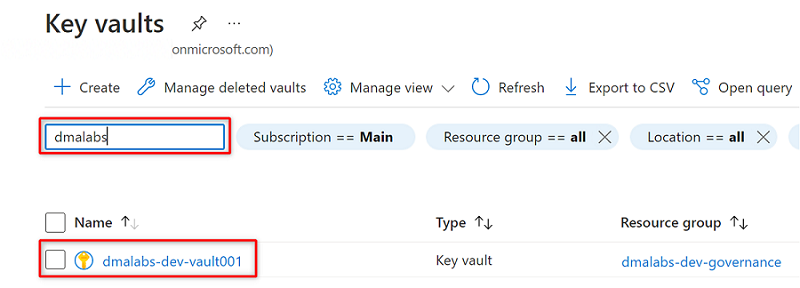
Nel menu della risorsa selezionare Controllo di accesso (IAM). Nella barra dei comandi selezionare Aggiungi e quindi Aggiungi assegnazione di ruolo.
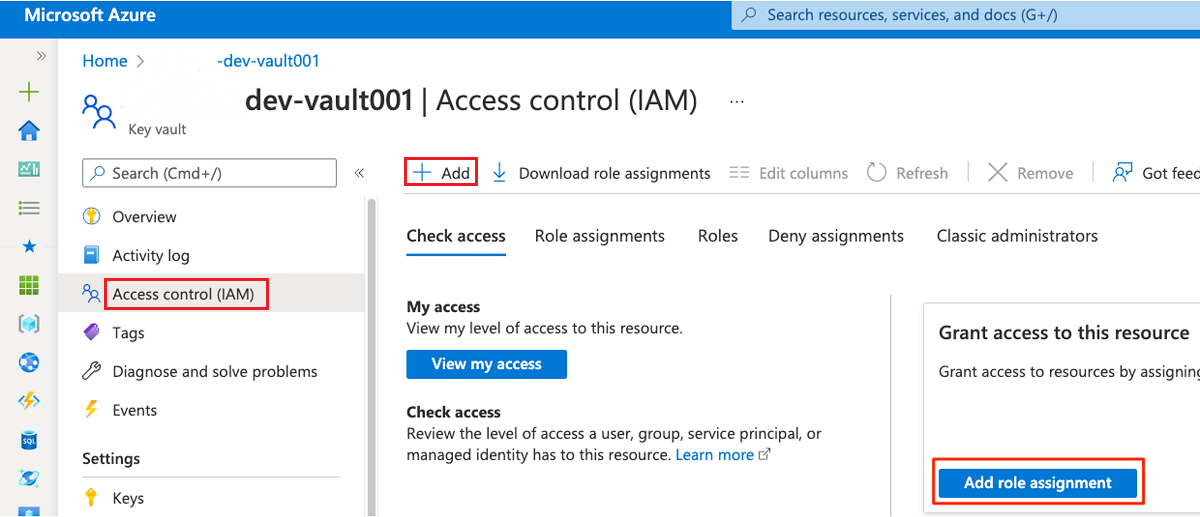
Nella scheda Ruolo cercare e quindi selezionare Key Vault Amministrazione istrator. Selezionare Avanti.
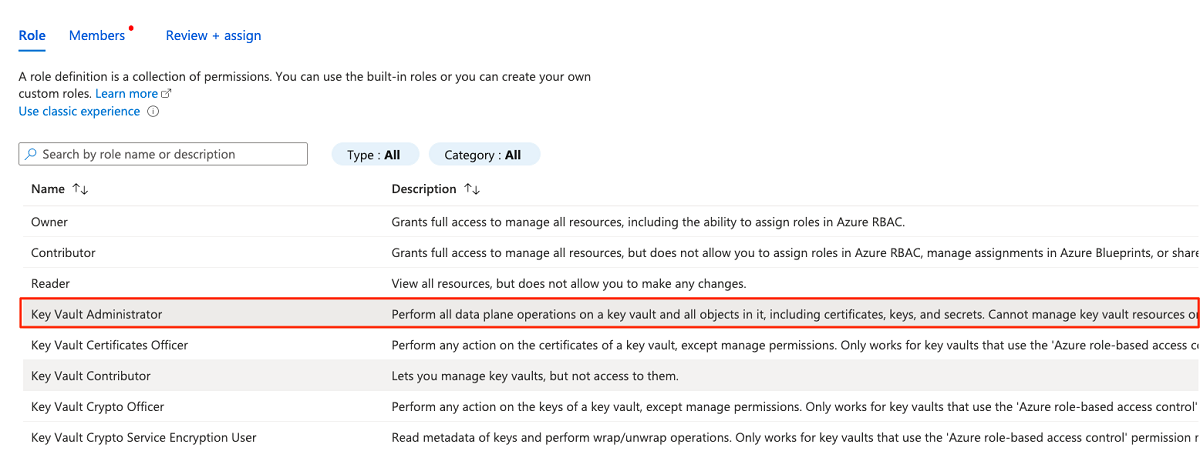
In Membri scegliere Seleziona membri per aggiungere l'account attualmente connesso.
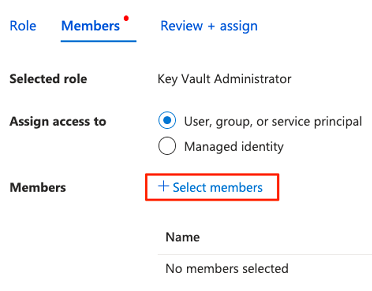
In Seleziona membri cercare l'account attualmente connesso. Selezionare l'account e quindi selezionare Seleziona.
Per completare il processo di assegnazione dei ruoli, selezionare Rivedi e assegna due volte.
Aggiungere un segreto all'insieme di credenziali delle chiavi
Completare i passaggi seguenti per accedere al portale di Azure dalla macchina virtuale host Bastion.
Nel menu delle risorse dell'insieme
<DMLZ-prefix>-dev-vault001di credenziali delle chiavi selezionare Segreti. Nella barra dei comandi selezionare Genera/Importa per creare un nuovo segreto.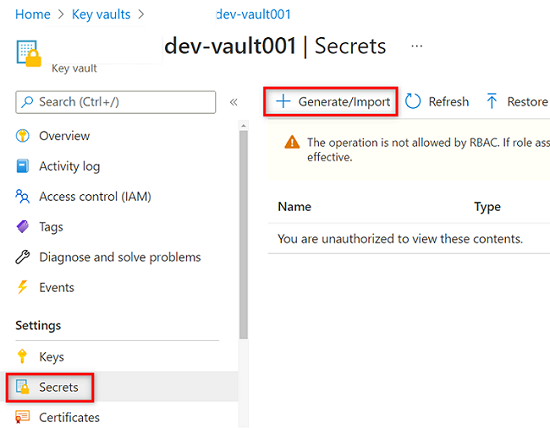
In Crea un segreto selezionare o immettere i valori seguenti:
Impostazione Azione Opzioni di caricamento Selezionare Manuale. Nome Immettere service-principal-secret. valore Immettere la password dell'entità servizio creata in precedenza. 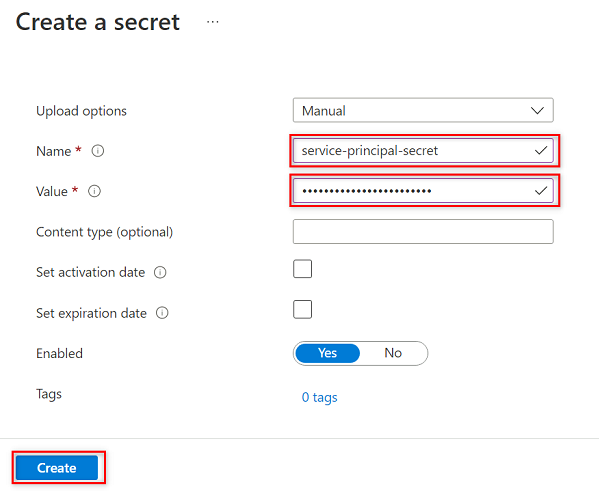
Nota
Questo passaggio crea un segreto denominato
service-principal-secretnell'insieme di credenziali delle chiavi usando la chiave della password dell'entità servizio. Purview usa il segreto per connettersi e analizzare le origini dati. Se si immette una password non corretta, non sarà possibile completare le sezioni seguenti.Seleziona Crea.
Configurare le autorizzazioni purview nell'insieme di credenziali delle chiavi
Per consentire all'istanza di Purview di leggere i segreti archiviati nell'insieme di credenziali delle chiavi, è necessario assegnare a Purview le autorizzazioni pertinenti nell'insieme di credenziali delle chiavi. Per impostare le autorizzazioni, aggiungere l'identità gestita purview al ruolo lettore segreti dell'insieme di credenziali delle chiavi.
Nel menu delle risorse dell'insieme
<DMLZ-prefix>-dev-vault001di credenziali delle chiavi selezionare Controllo di accesso (IAM).Nella barra dei comandi selezionare Aggiungi e quindi Aggiungi assegnazione di ruolo.
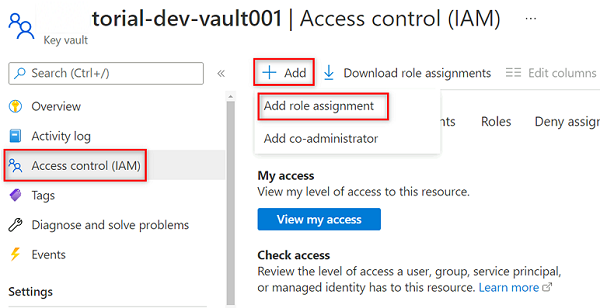
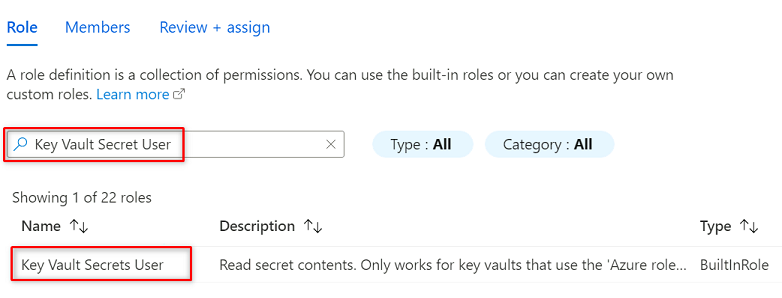
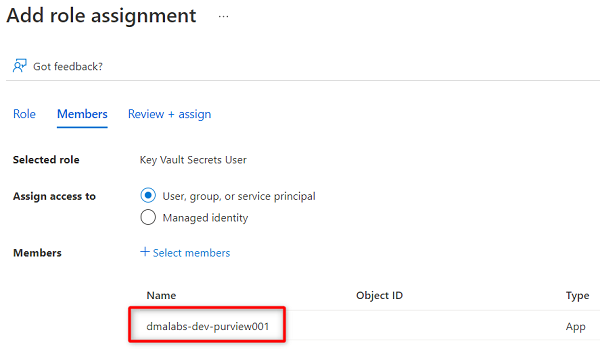
In Ruolo cercare e selezionare Key Vault Secrets User (Utente dei segreti dell'insieme di credenziali delle chiavi). Selezionare Avanti.
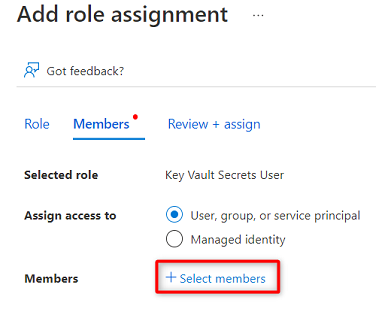
In Membri scegliere Seleziona membri.
Cercare l'istanza
<DMLZ-prefix>-dev-purview001di Purview. Selezionare l'istanza per aggiungere l'account pertinente. Scegliere, quindi, Seleziona.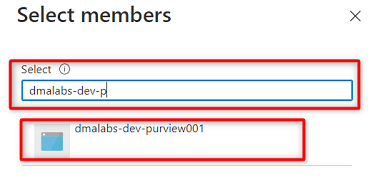
Per completare il processo di assegnazione dei ruoli, selezionare Rivedi e assegna due volte.
Configurare una connessione all'insieme di credenziali delle chiavi in Purview
Per configurare una connessione dell'insieme di credenziali delle chiavi a Purview, è necessario accedere al portale di Azure usando una macchina virtuale host di Azure Bastion.
Nel portale di Azure passare all'account
<DMLZ-prefix>-dev-purview001Purview. In Getting started (Introduzione) in Open Microsoft Purview Governance Portal (Apri portale di governance di Microsoft Purview) selezionare Apri.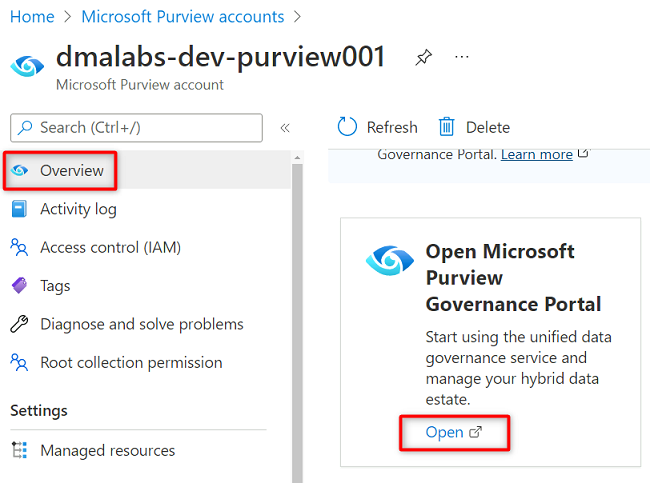
In Purview Studio selezionare Credenziali di gestione>. Nella barra dei comandi Credenziali selezionare Gestisci connessioni di Key Vault e quindi selezionare Nuovo.
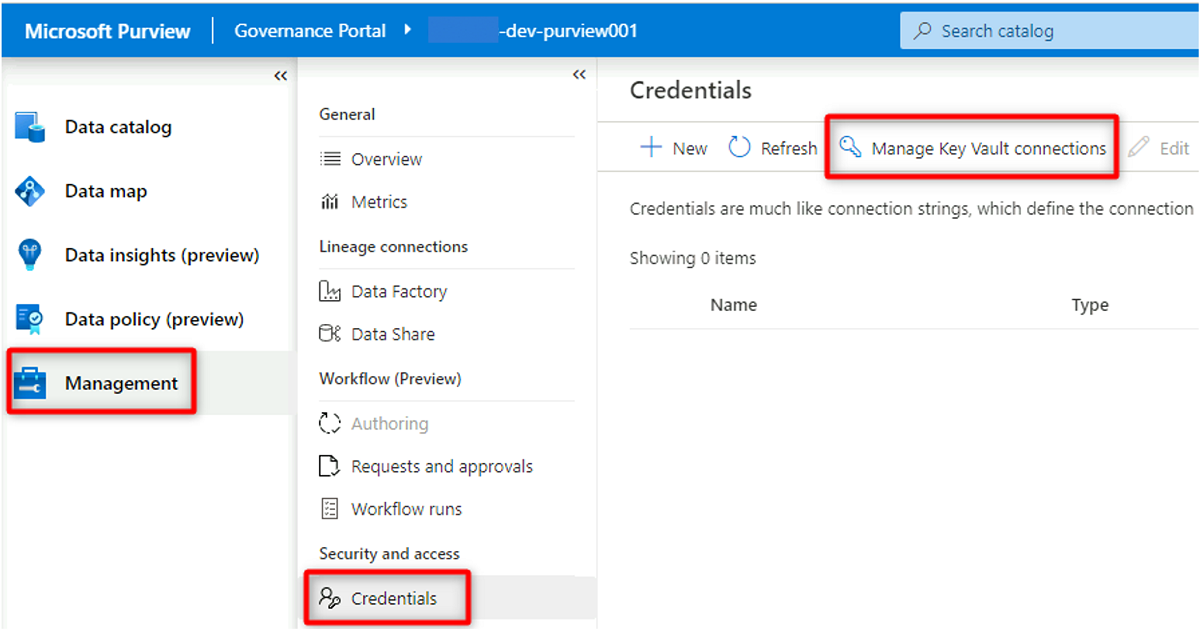
In Nuova connessione dell'insieme di credenziali delle chiavi selezionare o immettere le informazioni seguenti:
Impostazione Azione Nome Immettere <DMLZ-prefix-dev-vault001>. Sottoscrizione di Azure Selezionare la sottoscrizione che ospita l'insieme di credenziali delle chiavi. Nome dell'insieme di credenziali delle chiavi Selezionare l'insieme <di credenziali delle chiavi DMLZ-prefix-dev-vault001>. 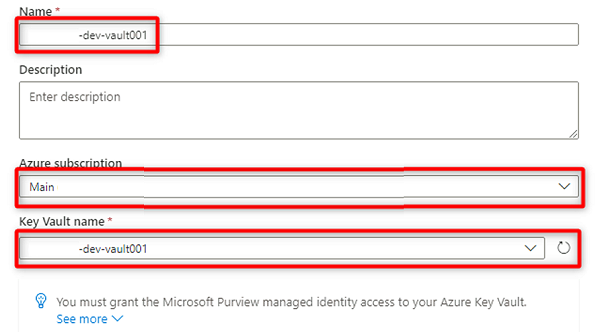
Seleziona Crea.
In Confermare la concessione dell'accesso selezionare Conferma.
Creare credenziali in Purview
Il passaggio finale per configurare l'insieme di credenziali delle chiavi consiste nel creare una credenziale in Purview che punti al segreto creato nell'insieme di credenziali delle chiavi per l'entità servizio.
In Purview Studio selezionare Credenziali di gestione>. Nella barra dei comandi Credenziali selezionare Nuovo.
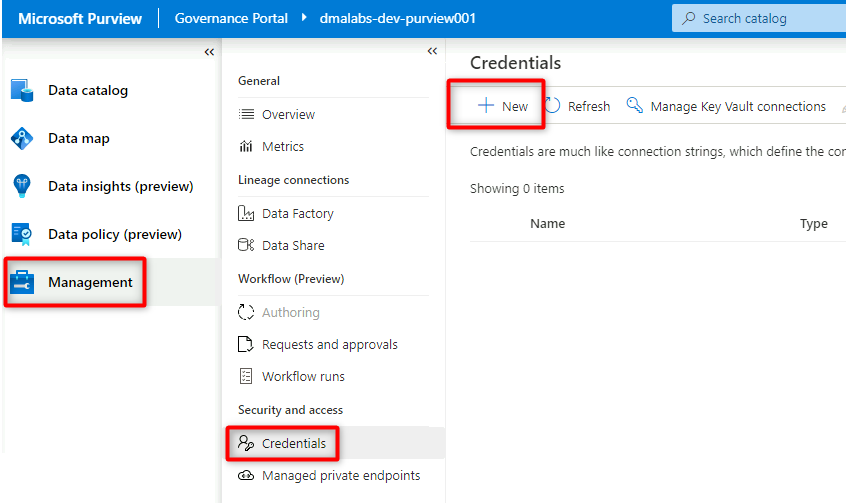
In Nuova credenziale selezionare o immettere le informazioni seguenti:
Impostazione Azione Nome Immettere purviewServicePrincipal. Metodo di autenticazione Selezionare Entità servizio. ID tenant Il valore viene popolato automaticamente. ID entità servizio Immettere l'ID applicazione o l'ID client dell'entità servizio. Connessione di Key Vault Selezionare la connessione all'insieme di credenziali delle chiavi creata nella sezione precedente. Nome segreto Immettere il nome del segreto nell'insieme di credenziali delle chiavi (service-principal-secret). 
Seleziona Crea.
Registrare le origini dati
A questo punto, Purview può connettersi all'entità servizio. È ora possibile registrare e configurare le origini dati.
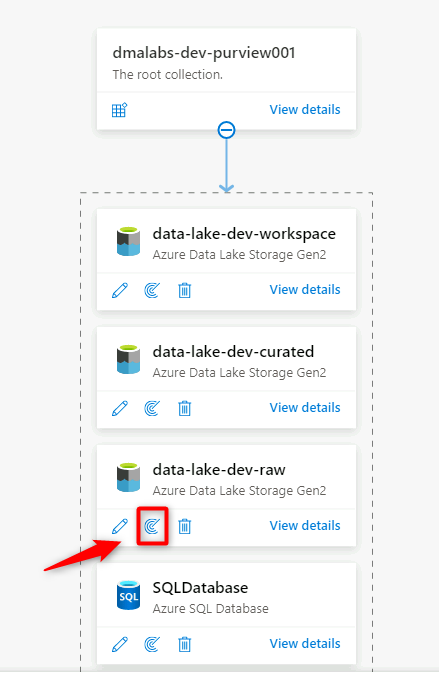
Registrare gli account azure Data Lake Archiviazione Gen2
I passaggi seguenti illustrano il processo per registrare un account di archiviazione di Azure Data Lake Archiviazione Gen2.
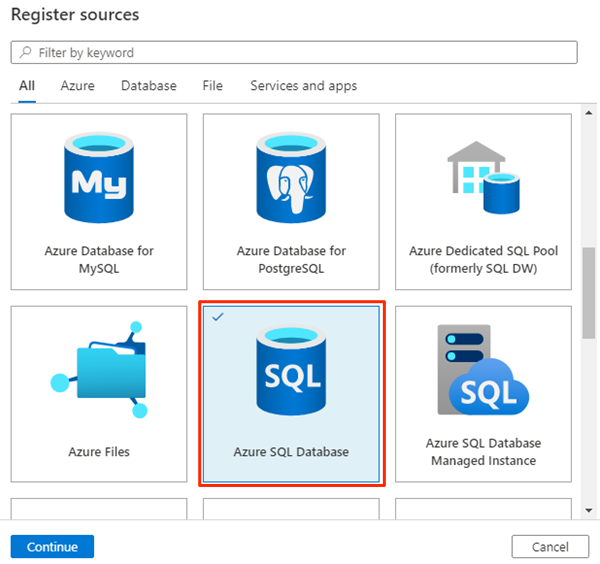
In Purview Studio selezionare l'icona della mappa dati, selezionare Origini e quindi selezionare Registra.
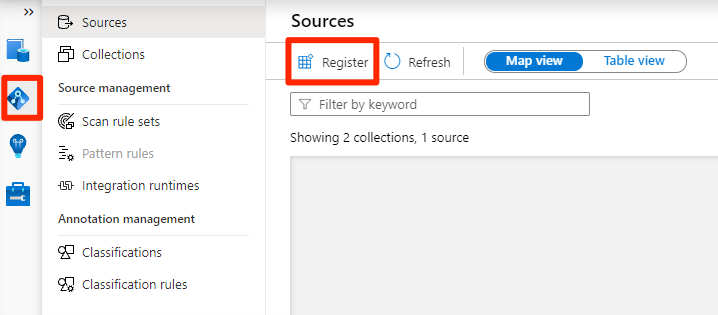
In Registra origini selezionare Azure Data Lake Archiviazione Gen2 e quindi selezionare Continua.

In Registra origini (Azure Data Lake Archiviazione Gen2) selezionare o immettere le informazioni seguenti:
Impostazione Azione Nome Immettere <DLZ-prefix>dldevraw. Sottoscrizione di Azure Selezionare la sottoscrizione che ospita l'account di archiviazione. Nome account di archiviazione Selezionare l'account di archiviazione pertinente. Endpoint Il valore viene popolato automaticamente in base all'account di archiviazione selezionato. Selezionare una raccolta Selezionare la raccolta radice. 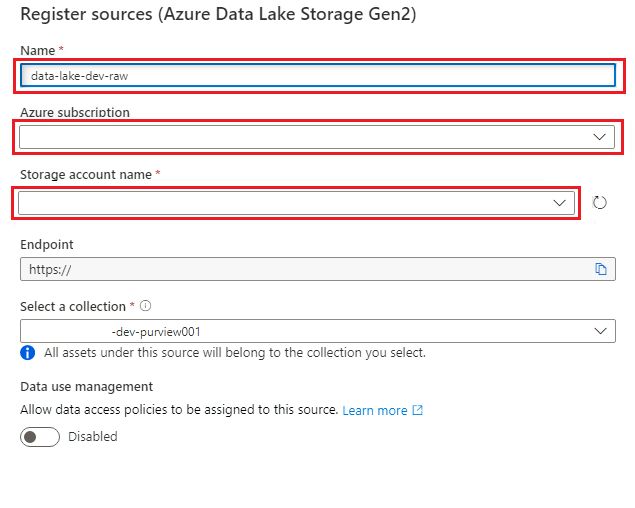
Selezionare Registra per creare l'origine dati.
Ripetere questi passaggi per gli account di archiviazione seguenti:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Registrare l'istanza di database SQL come origine dati
In Purview Studio selezionare l'icona Mappa dati, selezionare Origini e quindi selezionare Registra.
In Registra origini selezionare database SQL di Azure e quindi selezionare Continua.
In Registra origini (database SQL di Azure)selezionare o immettere le informazioni seguenti:
Impostazione Azione Nome Immettere SQLDatabase (nome del database creato in Creare istanze di database SQL di Azure). Abbonamento Selezionare la sottoscrizione che ospita il database. Nome server Immettere <DP-prefix-dev-sqlserver001>. 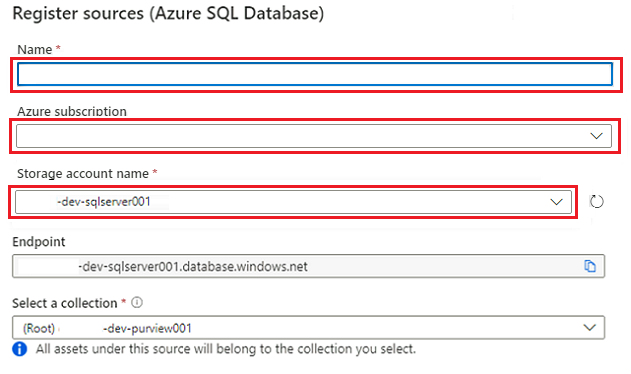
Selezionare Registrazione.
Configurare le analisi
Configurare quindi le analisi per le origini dati.
Analizzare l'origine dati data Lake Archiviazione Gen2
In Purview Studio passare alla mappa dei dati. Nell'origine dati selezionare l'icona Nuova analisi .
Nel nuovo riquadro di analisi selezionare o immettere le informazioni seguenti:
Impostazione Azione Nome Immettere Scan_<DLZ-prefix>devraw. Connessione tramite il runtime di integrazione Selezionare il runtime di integrazione self-hosted distribuito con la zona di destinazione dei dati. Credenziali Selezionare l'entità servizio configurata per Purview. 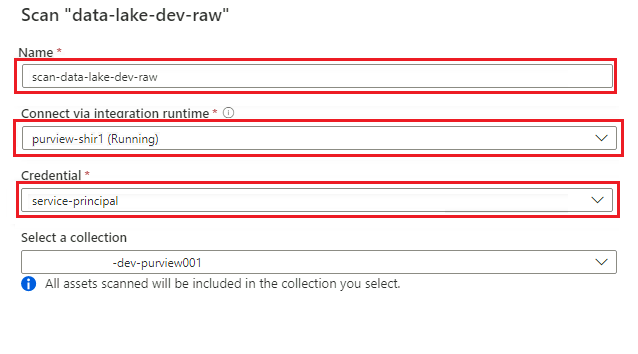
Selezionare Test connessione per verificare la connettività e che siano state applicate le autorizzazioni. Seleziona Continua.
In Ambito analisi selezionare l'intero account di archiviazione come ambito per l'analisi e quindi selezionare Continua.
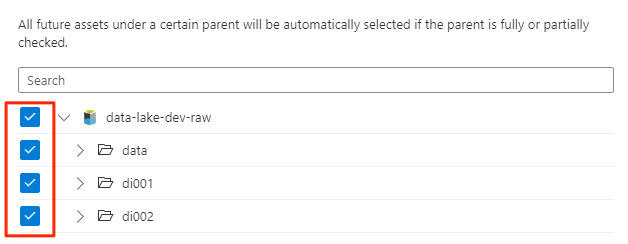
In Selezionare un set di regole di analisi selezionare AdlsGen2 e quindi selezionare Continua.
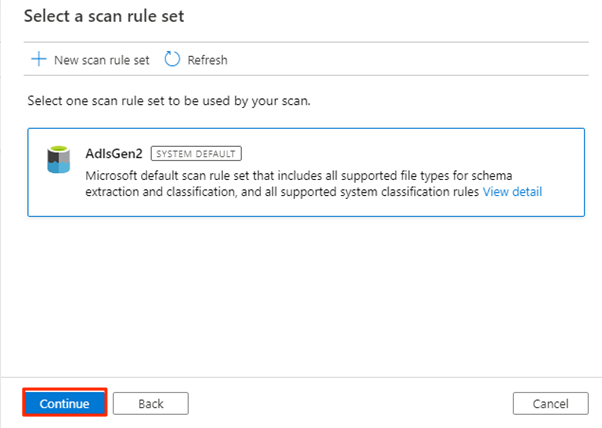
In Imposta un trigger di analisi selezionare Una sola volta e quindi selezionare Continua.
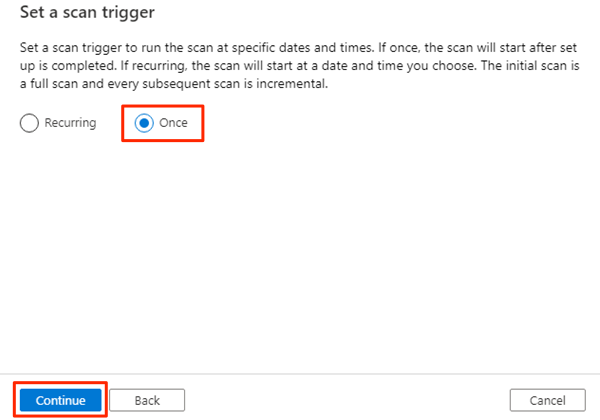
In Esaminare l'analisi esaminare le impostazioni di analisi. Selezionare Salva ed Esegui per avviare l'analisi.
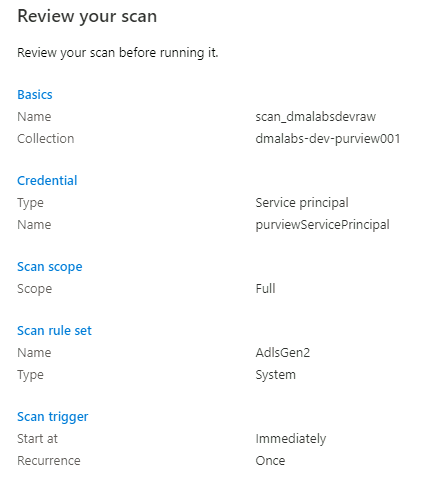
Ripetere questi passaggi per gli account di archiviazione seguenti:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Analizzare l'origine dati database SQL
Nell'origine dati database SQL di Azure selezionare Nuova analisi.
Nel nuovo riquadro di analisi selezionare o immettere le informazioni seguenti:
Impostazione Azione Nome Immettere Scan_Database001. Connessione tramite il runtime di integrazione Selezionare Purview-SHIR. Nome database Selezionare il nome del database. Credenziali Selezionare le credenziali dell'insieme di credenziali delle chiavi create in Purview. Estrazione derivazione (anteprima) selezionare No. 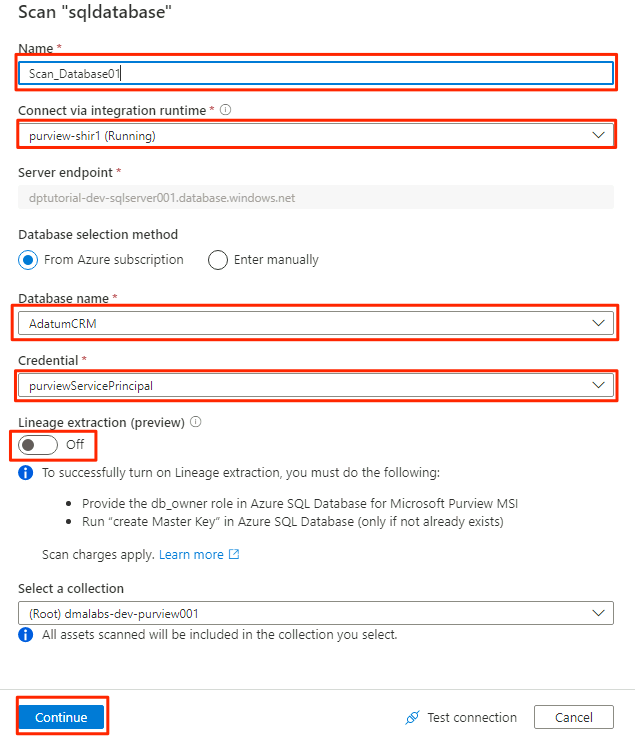
Selezionare Test connessione per verificare la connettività e che siano state applicate le autorizzazioni. Seleziona Continua.
Selezionare l'ambito per l'analisi. Per analizzare l'intero database, usare il valore predefinito.
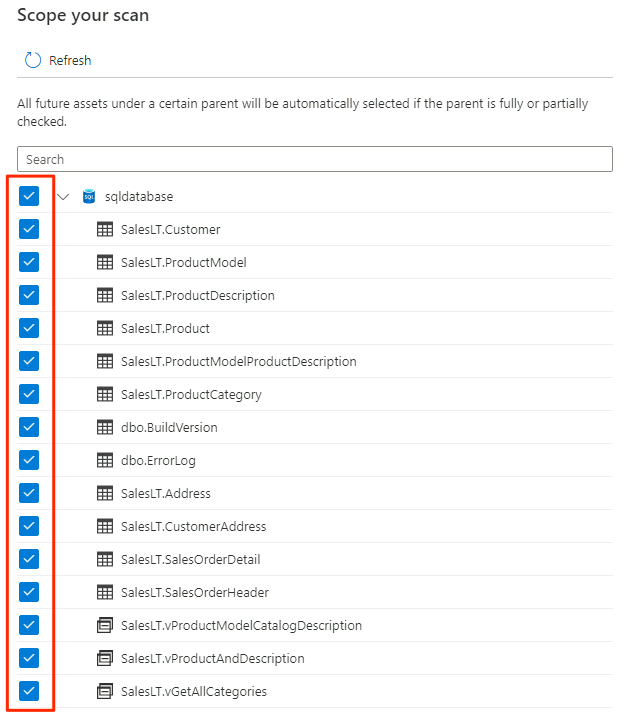
In Selezionare un set di regole di analisi selezionare AzureSqlDatabase e quindi selezionare Continua.
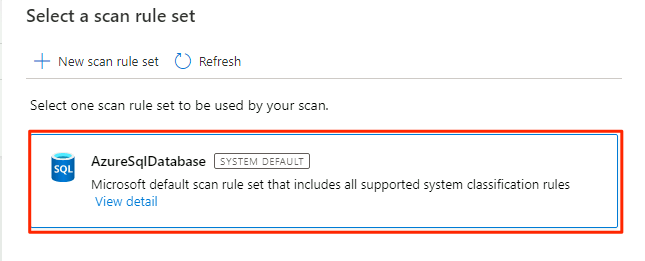
In Imposta un trigger di analisi selezionare Una sola volta e quindi selezionare Continua.
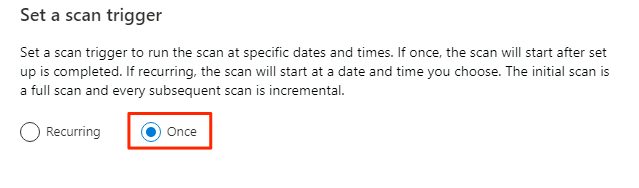
In Esaminare l'analisi esaminare le impostazioni di analisi. Selezionare Salva ed Esegui per avviare l'analisi.
Ripetere questi passaggi per il AdatumERP database.
Purview è ora configurato per la governance dei dati per le origini dati registrate.
Copiare database SQL dati in Data Lake Archiviazione Gen2
Nei passaggi seguenti si usa lo strumento Copia dati in Data Factory per creare una pipeline per copiare le tabelle dalle istanze AdatumCRM di database SQL e AdatumERP nei file CSV nell'account <DLZ-prefix>devraw Data Lake Archiviazione Gen2.
L'ambiente è bloccato per l'accesso pubblico, quindi è prima necessario configurare gli endpoint privati. Per usare gli endpoint privati, accedere al portale di Azure nel browser locale e quindi connettersi alla macchina virtuale host Bastion per accedere ai servizi di Azure necessari.
Creare endpoint privati
Per configurare gli endpoint privati per le risorse necessarie:
<DMLZ-prefix>-dev-bastionNel gruppo di risorse selezionare<DMLZ-prefix>-dev-vm001.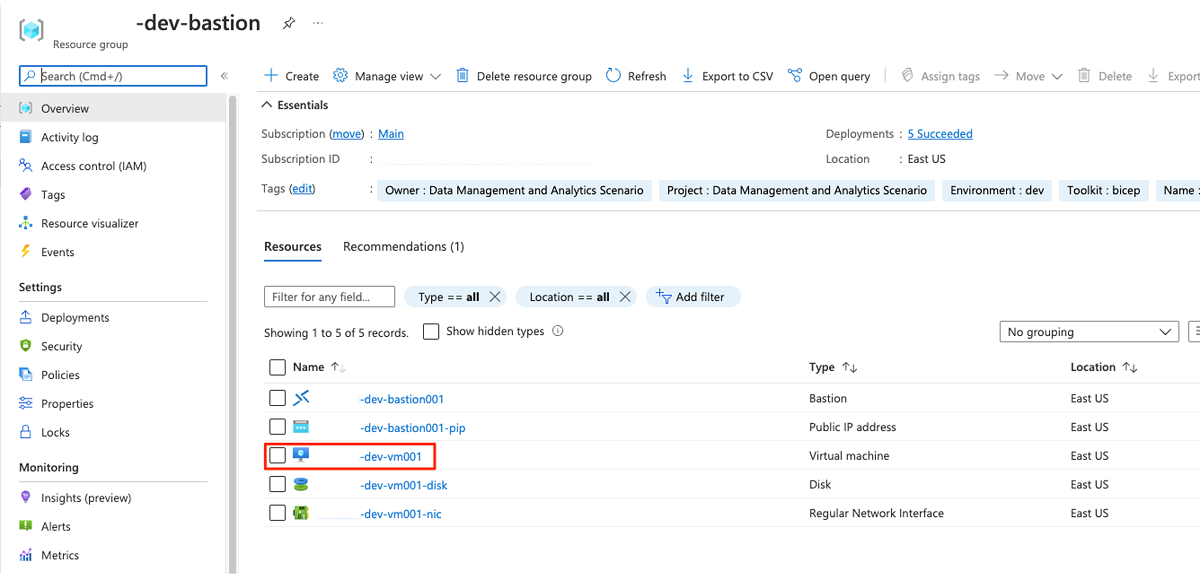
Nella barra dei comandi selezionare Connessione e selezionare Bastion.
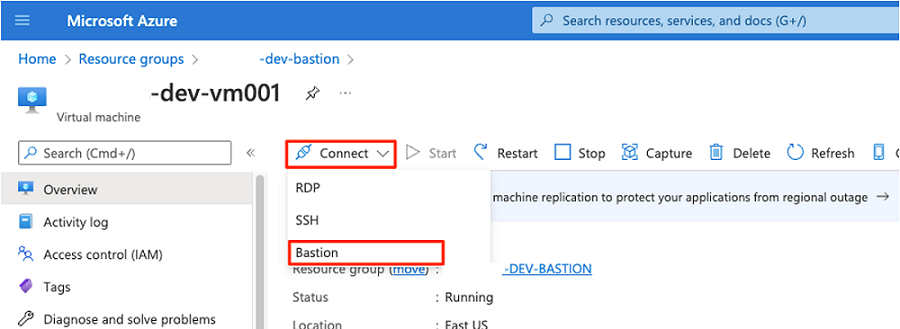
Immettere il nome utente e la password per la macchina virtuale e quindi selezionare Connessione.
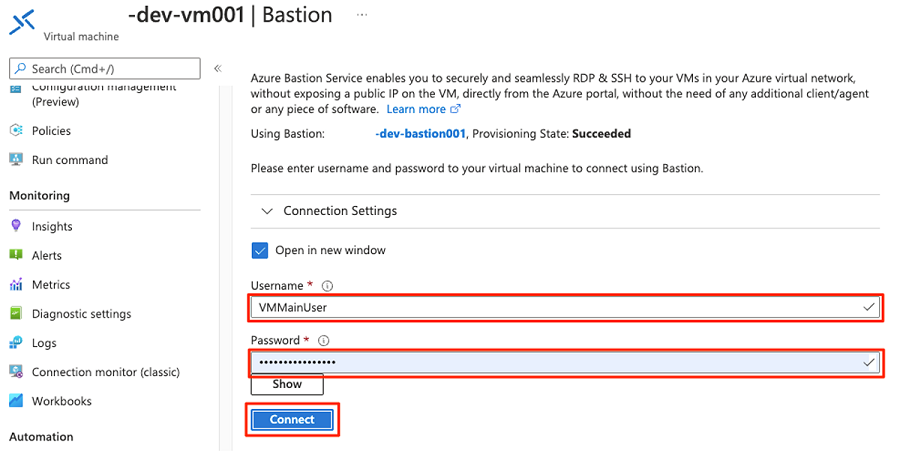
Nel Web browser della macchina virtuale passare alla portale di Azure. Passare al
<DLZ-prefix>-dev-shared-integrationgruppo di risorse e aprire la<DLZ-prefix>-dev-integration-datafactory001data factory.
In Getting started (Introduzione) in Open Azure Data Factory Studio (Apri Azure Data Factory Studio) selezionare Open ( Apri).
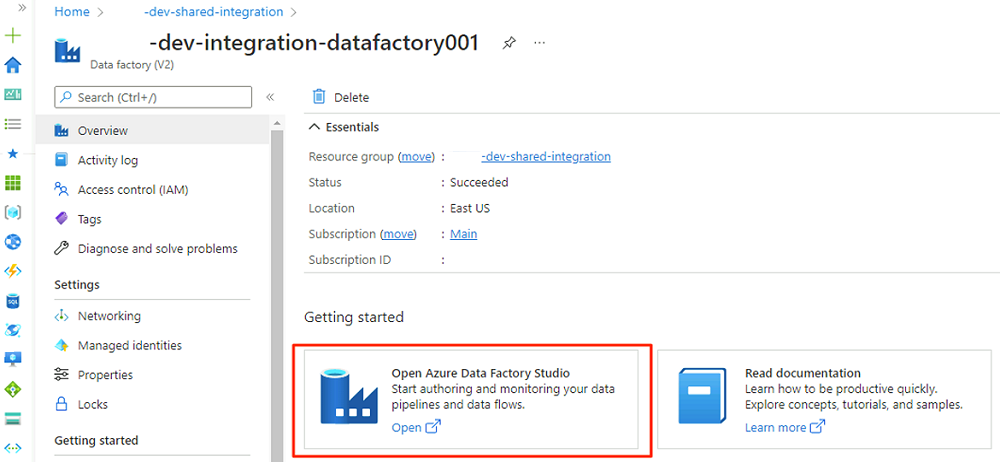
Nel menu di Data Factory Studio selezionare l'icona Gestisci (l'icona è simile a una casella degli strumenti quadrata con una chiave stampata su di essa). Nel menu delle risorse selezionare Endpoint privati gestiti per creare gli endpoint privati necessari per connettere Data Factory ad altri servizi di Azure protetti.
L'approvazione delle richieste di accesso per gli endpoint privati viene descritta in una sezione successiva. Dopo aver approvato le richieste di accesso all'endpoint privato, lo stato di approvazione è Approvato, come nell'esempio seguente dell'account
<DLZ-prefix>devencurdi archiviazione.
Prima di approvare le connessioni dell'endpoint privato, selezionare Nuovo. Immettere Azure SQL per trovare il connettore database SQL di Azure usato per creare un nuovo endpoint privato gestito per la
<DP-prefix>-dev-sqlserver001macchina virtuale SQL di Azure. La macchina virtuale contiene iAdatumCRMdatabase eAdatumERPcreati in precedenza.In Nuovo endpoint privato gestito (database SQL di Azure) immettere data-product-dev-sqlserver001 in Nome. Immettere la sottoscrizione di Azure usata per creare le risorse. In Nome server selezionare
<DP-prefix>-dev-sqlserver001in modo da potersi connettere da questa data factory nelle sezioni successive.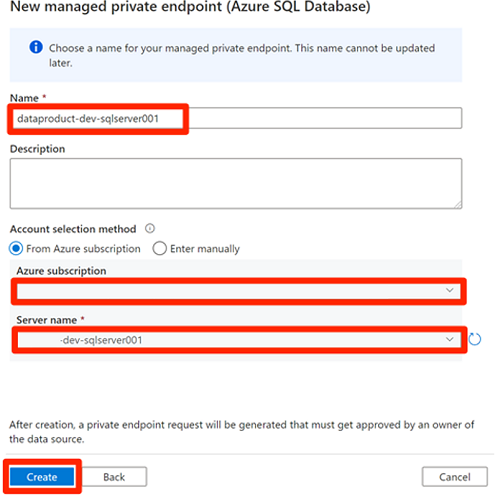



Approvare le richieste di accesso all'endpoint privato
Per concedere a Data Factory l'accesso agli endpoint privati per i servizi necessari, sono disponibili due opzioni:
Opzione 1: in ogni servizio a cui si richiede l'accesso, nella portale di Azure passare all'opzione rete o connessioni endpoint private del servizio e approvare le richieste di accesso all'endpoint privato.
Opzione 2: eseguire gli script seguenti in Azure Cloud Shell in modalità Bash per approvare tutte le richieste di accesso agli endpoint privati necessari contemporaneamente.
# Storage managed private endpoint approval # devencur resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devencur')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # devraw resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devraw')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # SQL Database managed private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-dp001')==\`true\`].name") sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $sqlServerName --type Microsoft.Sql/servers -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $sqlServerName --type Microsoft.Sql/servers --description "Approved" # Key Vault private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-metadata')==\`true\`].name") keyVaultName=$(az keyvault list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'dev-vault001')==\`true\`].name") endPointConnectionID=$(az network private-endpoint-connection list -g $resourceGroupName -n $keyVaultName --type Microsoft.Keyvault/vaults -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].id") az network private-endpoint-connection approve -g $resourceGroupName --id $endPointConnectionID --resource-name $keyVaultName --type Microsoft.Keyvault/vaults --description "Approved" # Purview private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dev-governance')==\`true\`].name") purviewAcctName=$(az purview account list -g $resourceGroupName -o tsv --query "[?contains(@.name, '-dev-purview001')==\`true\`].name") for epn in $(az network private-endpoint-connection list -g $resourceGroupName -n $purviewAcctName --type Microsoft.Purview/accounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") do az network private-endpoint-connection approve -g $resourceGroupName -n $epn --resource-name $purviewAcctName --type Microsoft.Purview/accounts --description "Approved" done
L'esempio seguente illustra come l'account <DLZ-prefix>devraw di archiviazione gestisce le richieste di accesso agli endpoint privati. Nel menu delle risorse per l'account di archiviazione selezionare Rete. Nella barra dei comandi selezionare Connessioni endpoint privato.

Per alcune risorse di Azure, selezionare Connessioni endpoint privati nel menu delle risorse. Un esempio per il server SQL di Azure è illustrato nello screenshot seguente.
Per approvare una richiesta di accesso all'endpoint privato, in Connessioni endpoint privati selezionare la richiesta di accesso in sospeso e quindi selezionare Approva:

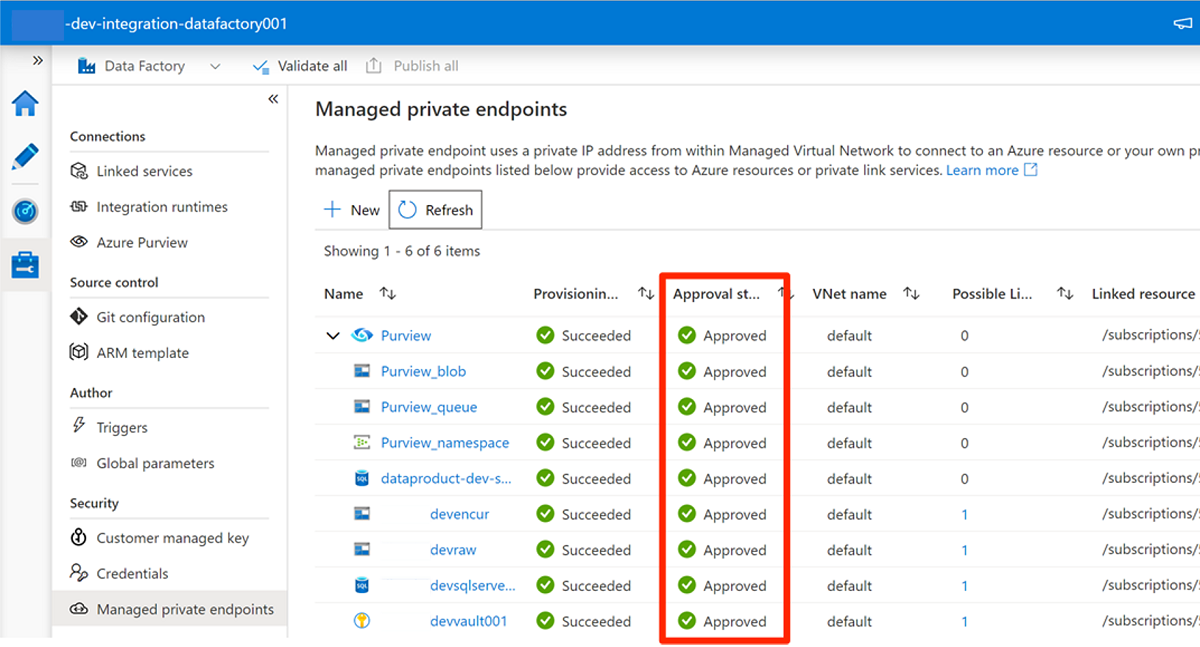
Dopo aver approvato la richiesta di accesso in ogni servizio necessario, potrebbero essere necessari alcuni minuti prima che la richiesta venga visualizzata come Approvata negli endpoint privati gestiti in Data Factory Studio. Anche se si seleziona Aggiorna nella barra dei comandi, lo stato di approvazione potrebbe non essere aggiornato per alcuni minuti.
Al termine dell'approvazione di tutte le richieste di accesso per i servizi necessari, in Endpoint privati gestiti il valore Stato approvazione per tutti i servizi è Approvato:
Assegnazioni di ruolo
Al termine dell'approvazione delle richieste di accesso all'endpoint privato, aggiungere le autorizzazioni del ruolo appropriate per Data Factory per accedere a queste risorse:
- database SQL istanze
AdatumCRMeAdatumERPnel server SQL di<DP-prefix>-dev-sqlserver001Azure - Archiviazione account
<DLZ-prefix>devraw,<DLZ-prefix>devencure<DLZ-prefix>devwork - Account Purview
<DMLZ-prefix>-dev-purview001
Macchina virtuale SQL di Azure
Per aggiungere assegnazioni di ruolo, iniziare con la macchina virtuale SQL di Azure.
<DMLZ-prefix>-dev-dp001Nel gruppo di risorse passare a<DP-prefix>-dev-sqlserver001.Nel menu della risorsa selezionare Controllo di accesso (IAM). Nella barra dei comandi selezionare Aggiungi aggiungi>assegnazione di ruolo.
Nella scheda Ruolo selezionare Collaboratore e quindi avanti.
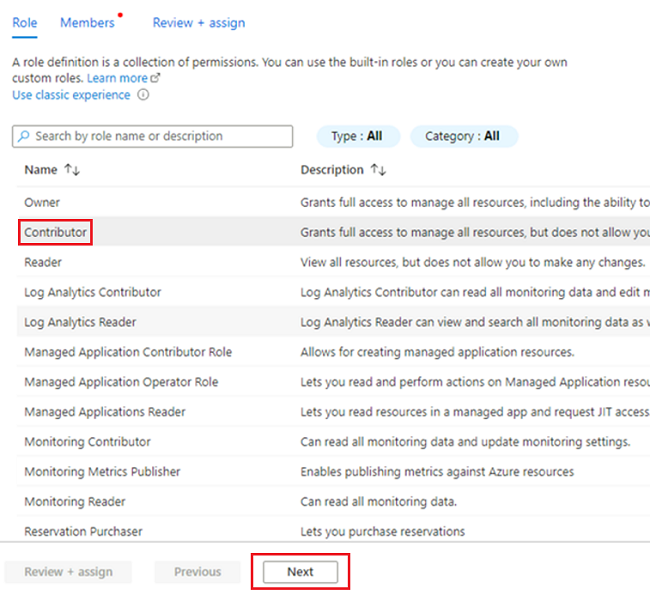
In Membri, per Assegna accesso a, selezionare Identità gestita. In Membri scegliere Seleziona membri.
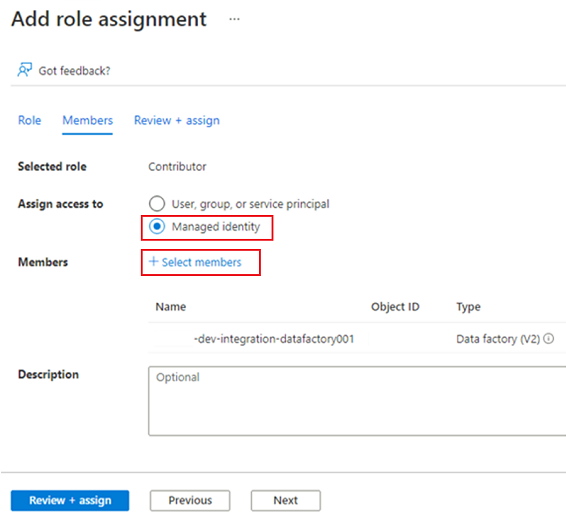
In Selezionare le identità gestite selezionare la sottoscrizione di Azure. Per Identità gestita selezionare Data Factory (V2) per visualizzare le data factory disponibili. Nell'elenco delle data factory selezionare Azure Data Factory <DLZ-prefix-dev-integration-datafactory001>. Scegli Seleziona.
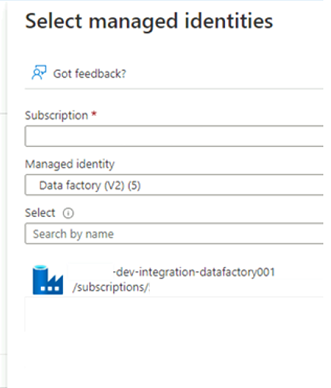
Selezionare Rivedi e assegna due volte per completare il processo.
Account di archiviazione
Assegnare quindi i ruoli necessari agli <DLZ-prefix>devrawaccount di archiviazione , <DLZ-prefix>devencure <DLZ-prefix>devwork .
Per assegnare i ruoli, completare gli stessi passaggi usati per creare l'assegnazione di ruolo del server SQL di Azure. Per il ruolo, tuttavia, selezionare Archiviazione Collaboratore dati BLOB anziché Collaboratore.
Dopo aver assegnato i ruoli per tutti e tre gli account di archiviazione, Data Factory può connettersi e accedere agli account di archiviazione.
Microsoft Purview
Il passaggio finale per aggiungere assegnazioni di ruolo consiste nell'aggiungere il ruolo Di curatore dei dati purview in Microsoft Purview all'account di identità gestita della <DLZ-prefix>-dev-integration-datafactory001 data factory. Completare i passaggi seguenti in modo che Data Factory possa inviare informazioni sugli asset del catalogo dati da più origini dati all'account Purview.
Nel gruppo
<DMLZ-prefix>-dev-governancedi risorse passare all'account<DMLZ-prefix>-dev-purview001Purview.In Purview Studio selezionare l'icona Mappa dati e quindi raccolte.
Selezionare la scheda Assegnazioni di ruolo per la raccolta. In Curatori dei dati aggiungere l'identità gestita per
<DLZ-prefix>-dev-integration-datafactory001: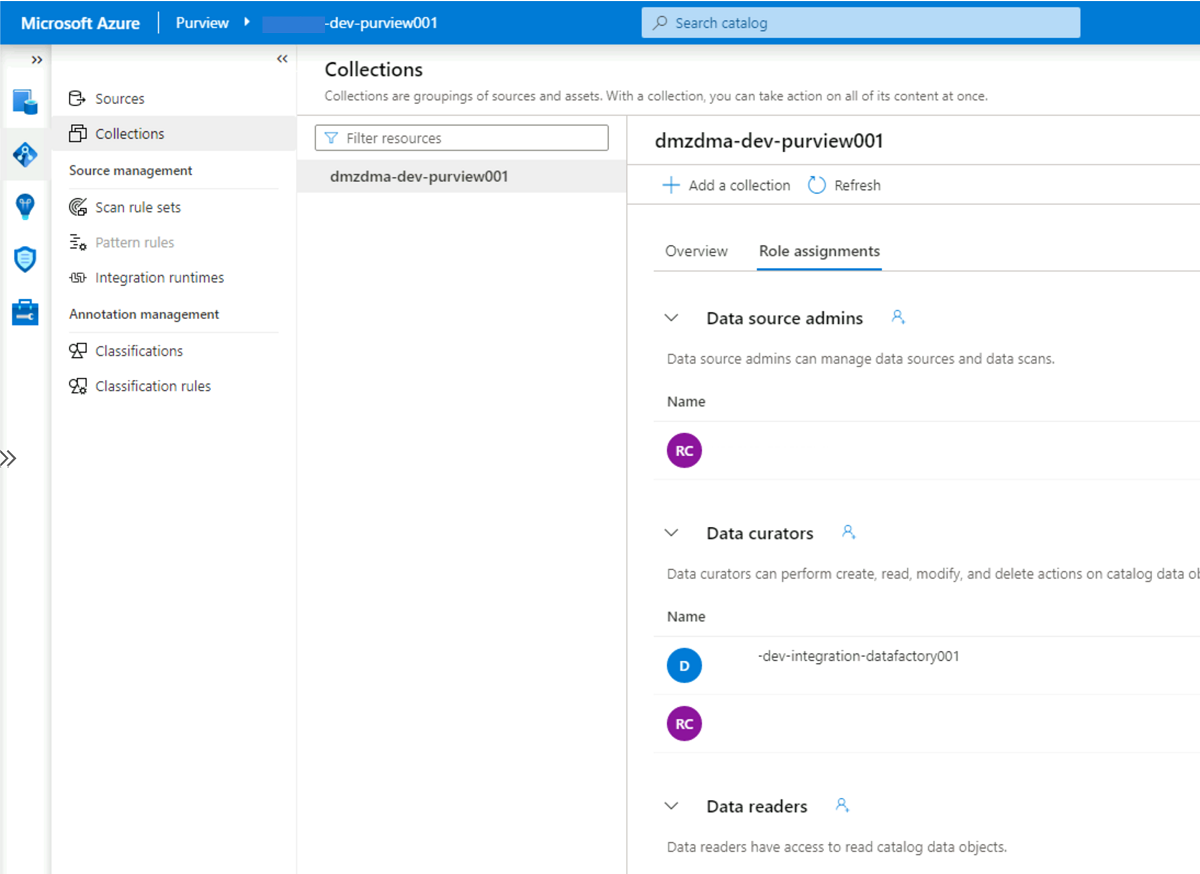
Connessione Data Factory a Purview
Le autorizzazioni sono impostate e Purview può ora visualizzare la data factory. Il passaggio successivo consiste nel fare in modo che <DMLZ-prefix>-dev-purview001 ci si connetta a <DLZ-prefix>-dev-integration-datafactory001.
In Purview Studio selezionare l'icona Gestione e quindi selezionare Data Factory. Selezionare Nuovo per creare una connessione data factory.
Nel riquadro Nuove connessioni data factory immettere la sottoscrizione di Azure e selezionare la
<DLZ-prefix>-dev-integration-datafactory001data factory. Seleziona OK.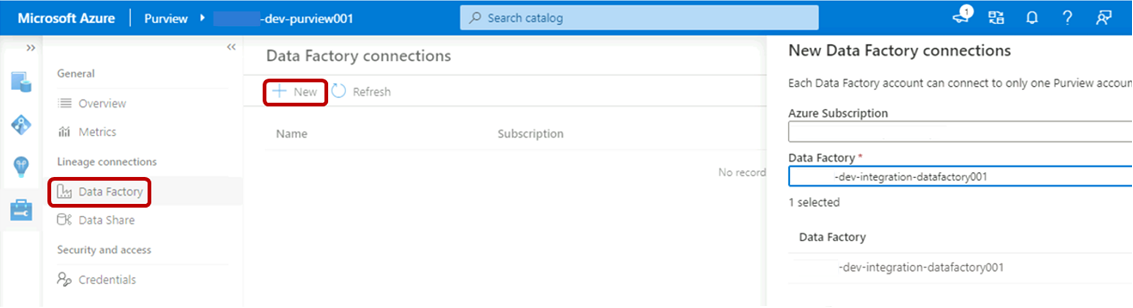
Nell'istanza
<DLZ-prefix>-dev-integration-datafactory001di Data Factory Studio, in Gestisci>Azure Purview aggiornare l'account Azure Purview.L'integrazione
Data Lineage - Pipelinemostra ora l'icona verde Connessione ed.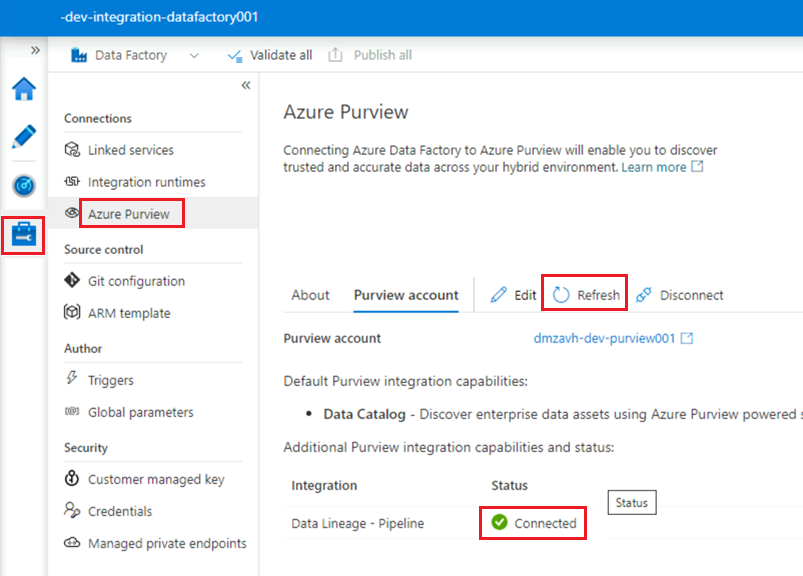

Creare una pipeline ETL
Ora che dispone <DLZ-prefix>-dev-integration-datafactory001 delle autorizzazioni di accesso necessarie, creare un'attività di copia in Data Factory per spostare i dati dalle istanze di database SQL all'account <DLZ-prefix>devraw di archiviazione non elaborato.
Usare lo strumento Copia dati con AdatumCRM
Questo processo estrae i dati dei clienti dall'istanza AdatumCRM di database SQL e li copia nell'archiviazione di Data Lake Archiviazione Gen2.
In Data Factory Studio selezionare l'icona Autore e quindi selezionare Risorse factory. Selezionare il segno più (+) e selezionare Copia dati strumento.
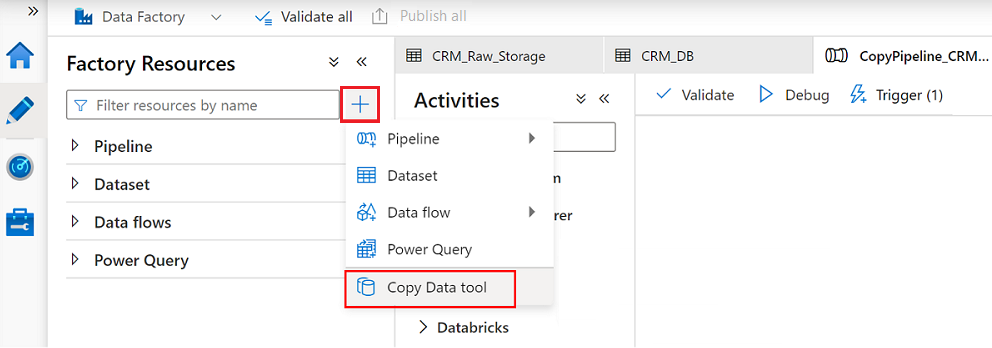
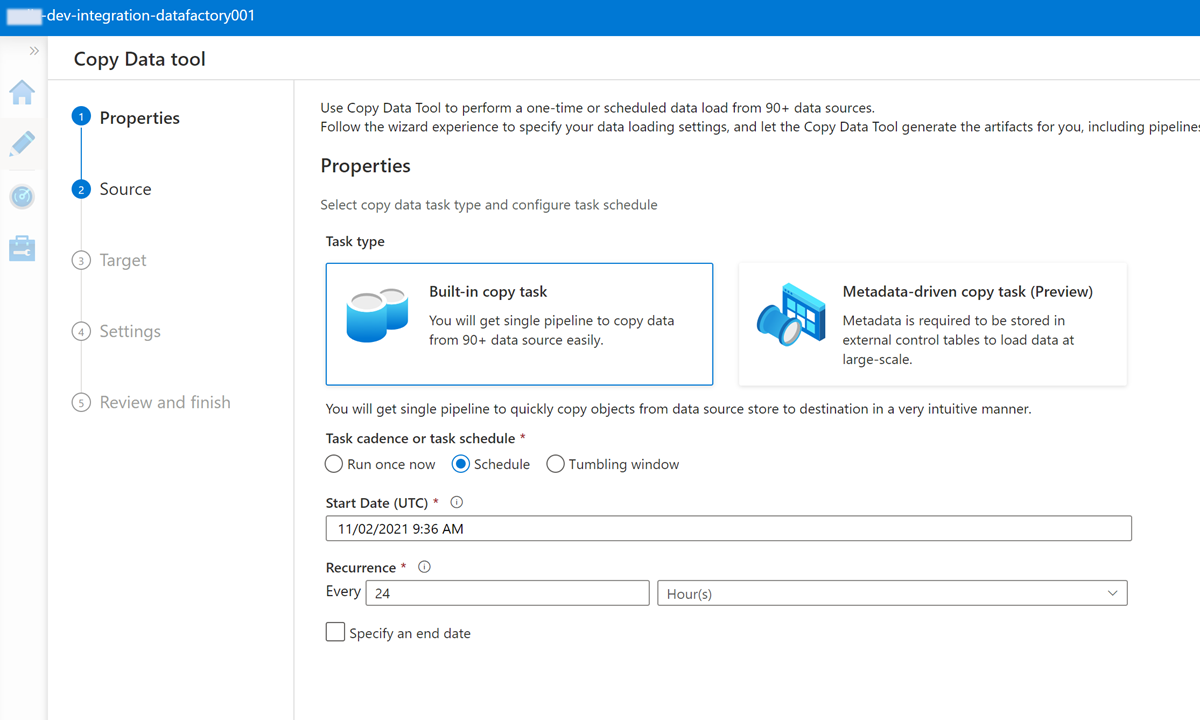
Completare ogni passaggio della procedura guidata Copia dati:
Per creare un trigger per eseguire la pipeline ogni 24 ore, selezionare Pianifica.
Per creare un servizio collegato per connettere questa data factory all'istanza
AdatumCRMdi database SQL nel<DP-prefix>-dev-sqlserver001server (origine), selezionare Nuovo Connessione ion.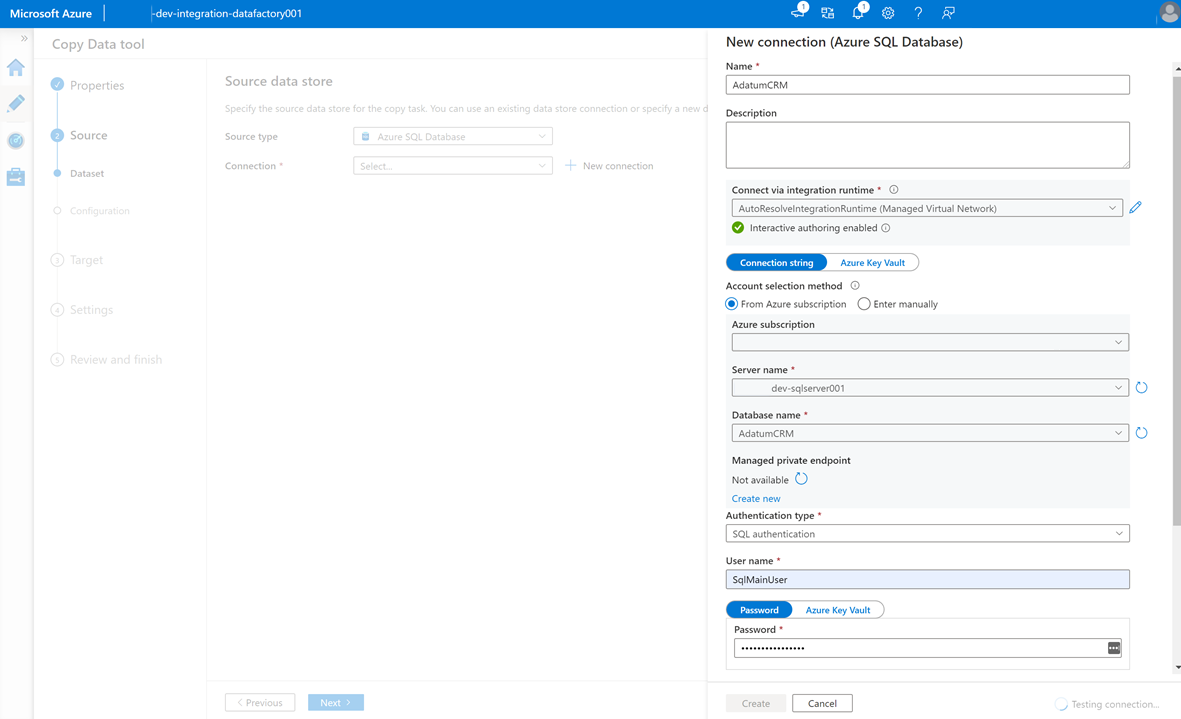
Nota
Se si verificano errori di connessione o accesso ai dati nelle istanze di database SQL o negli account di archiviazione, esaminare le autorizzazioni nella sottoscrizione di Azure. Assicurarsi che la data factory disponga delle credenziali necessarie e delle autorizzazioni di accesso a qualsiasi risorsa problematica.
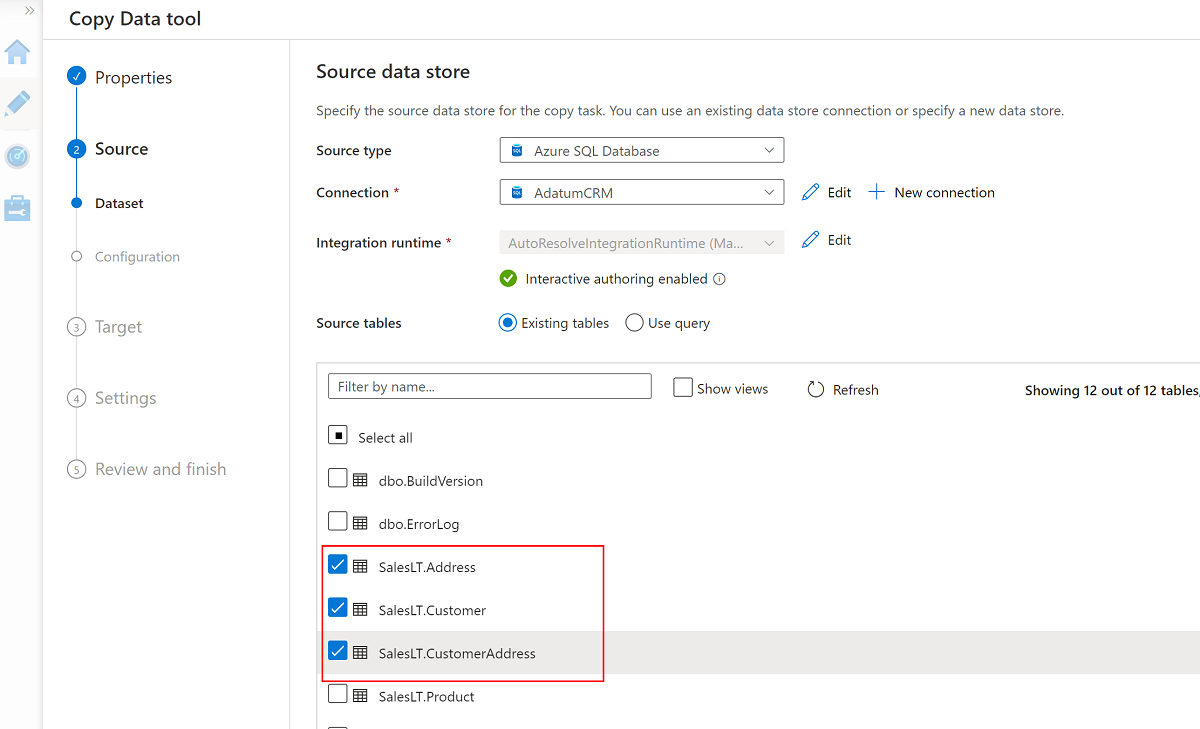
Selezionare queste tre tabelle:
SalesLT.AddressSalesLT.CustomerSalesLT.CustomerAddress
Creare un nuovo servizio collegato per accedere all'archiviazione
<DLZ-prefix>devrawdi Azure Data Lake Archiviazione Gen2 (destinazione).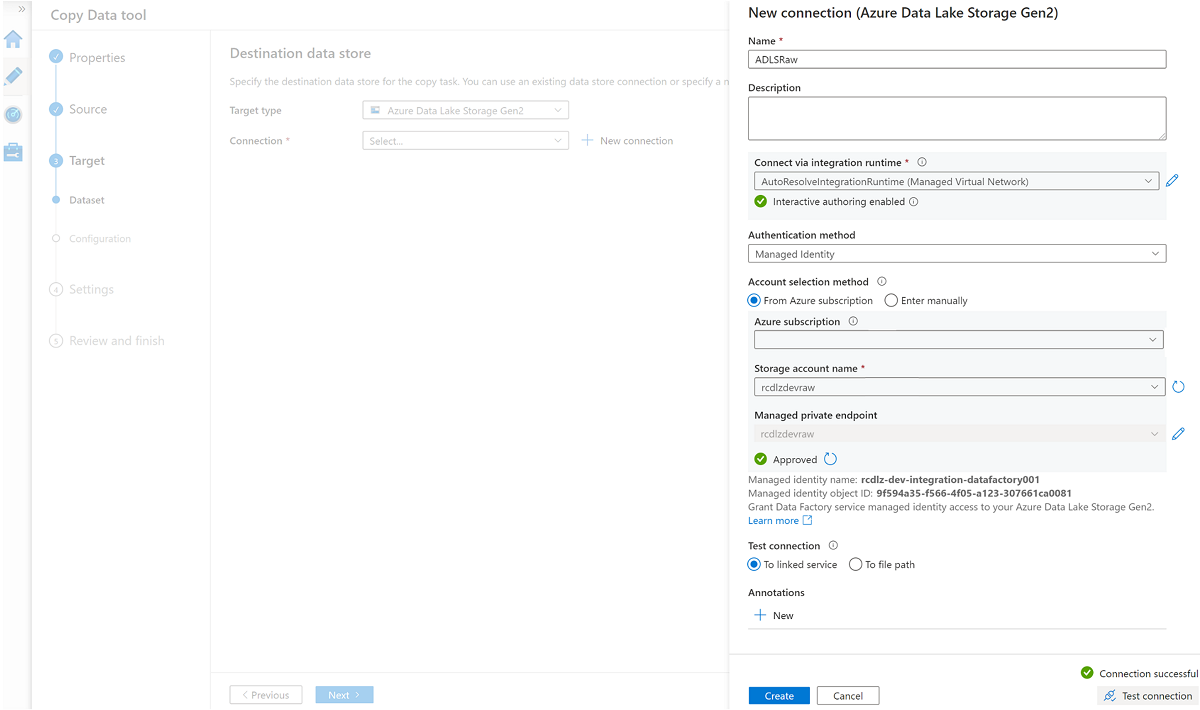
Esplorare le cartelle nella
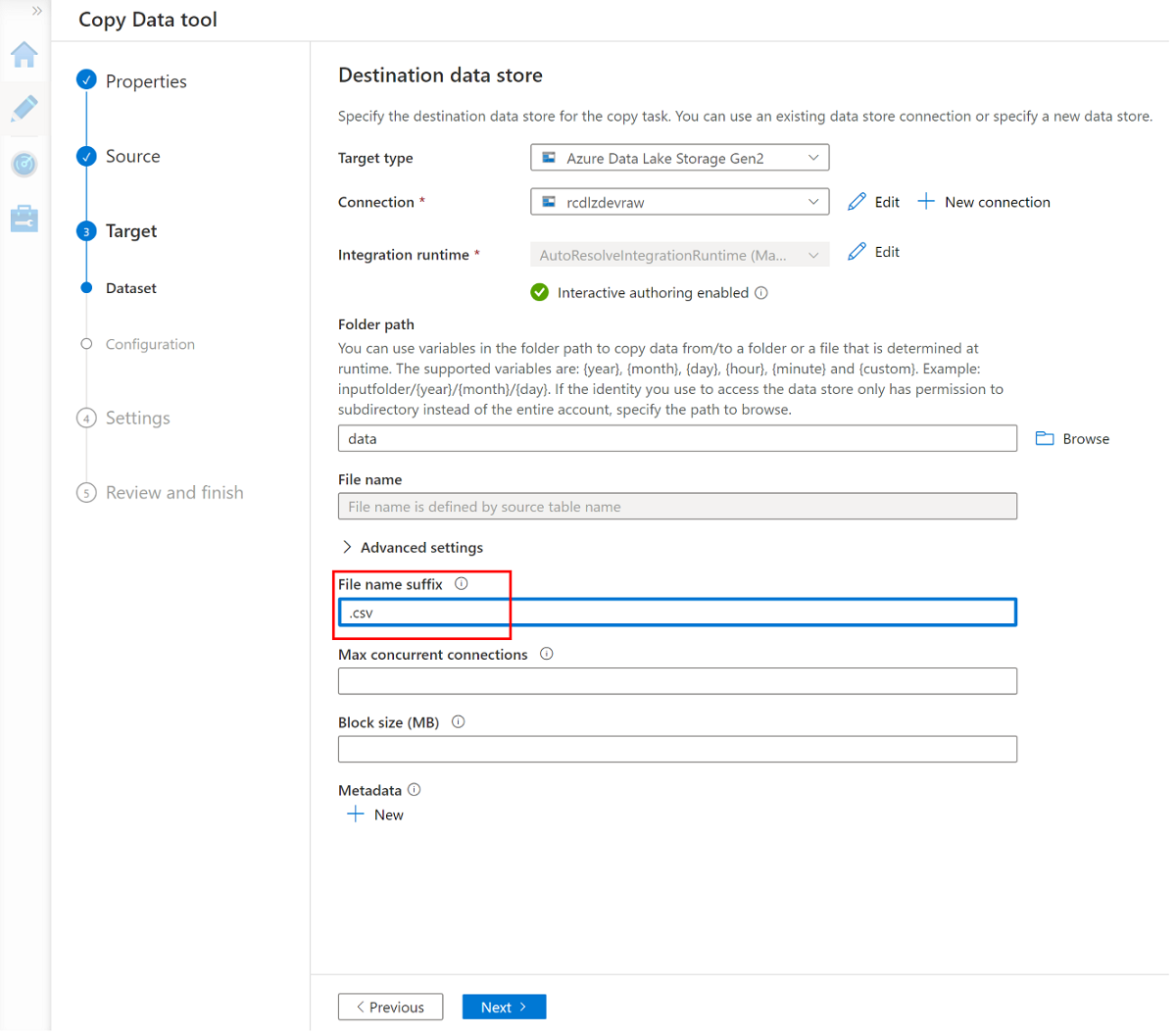
<DLZ-prefix>devrawrisorsa di archiviazione e selezionare Dati come destinazione.
Modificare il suffisso del nome file in csv e usare le altre opzioni predefinite.
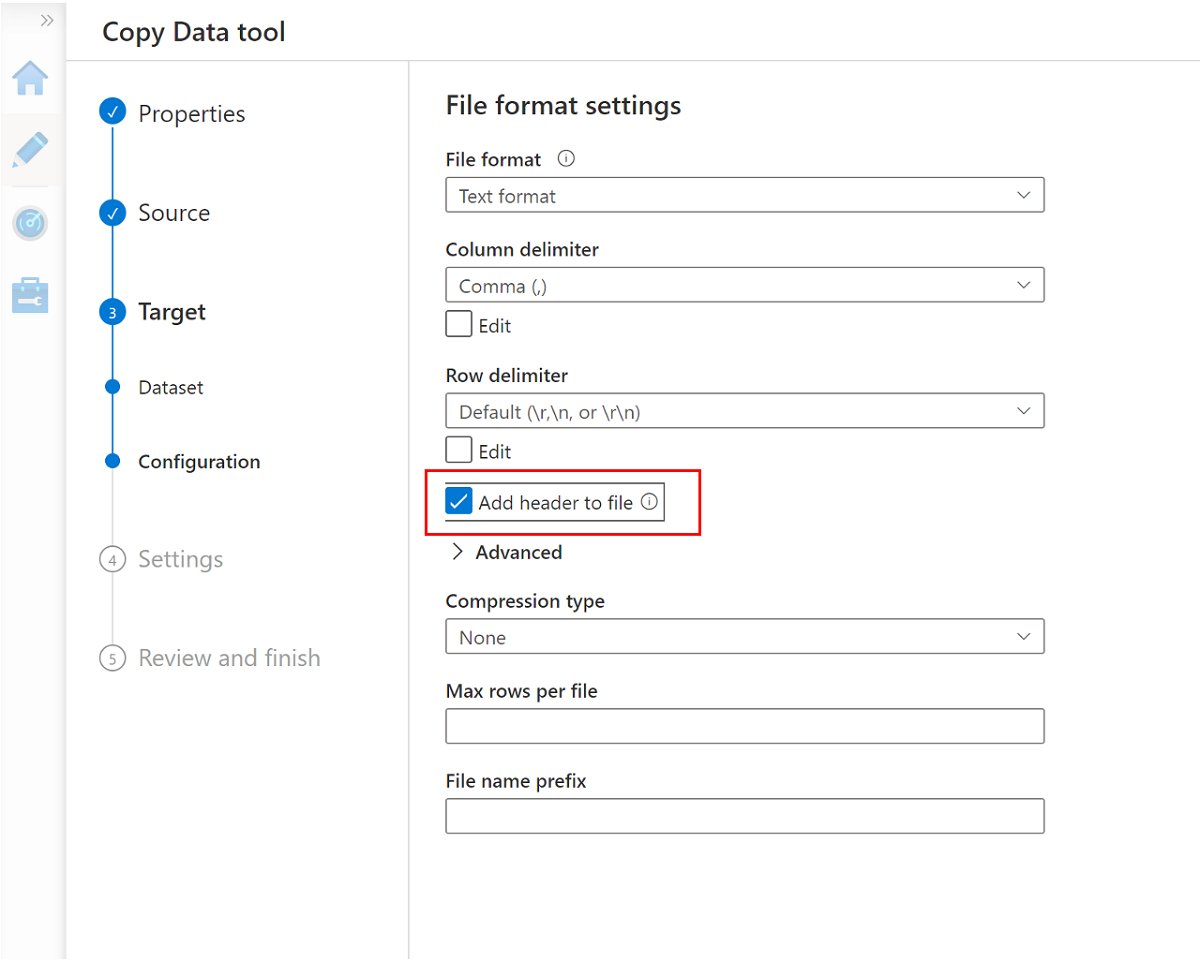
Passare al riquadro successivo e selezionare Aggiungi intestazione al file.
Al termine della procedura guidata, il riquadro Distribuzione completa è simile all'esempio seguente:
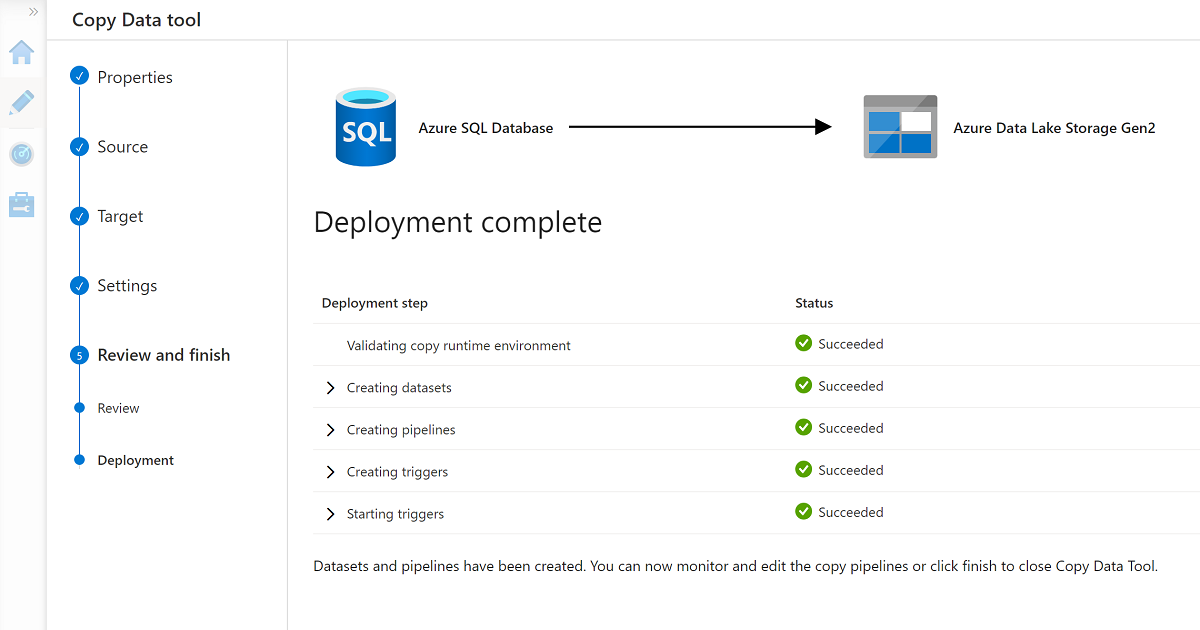




La nuova pipeline è elencata in Pipeline.
Eseguire la pipeline
Questo processo crea tre file con estensione csv nella cartella Data\CRM , uno per ognuna delle tabelle selezionate nel AdatumCRM database.
Rinominare la pipeline
CopyPipeline_CRM_to_Raw.Rinominare i set di dati
CRM_Raw_StorageeCRM_DB.Nella barra dei comandi Risorse factory selezionare Pubblica tutto.
Selezionare la
CopyPipeline_CRM_to_Rawpipeline e nella barra dei comandi della pipeline selezionare Trigger per copiare le tre tabelle da database SQL a Data Lake Archiviazione Gen2.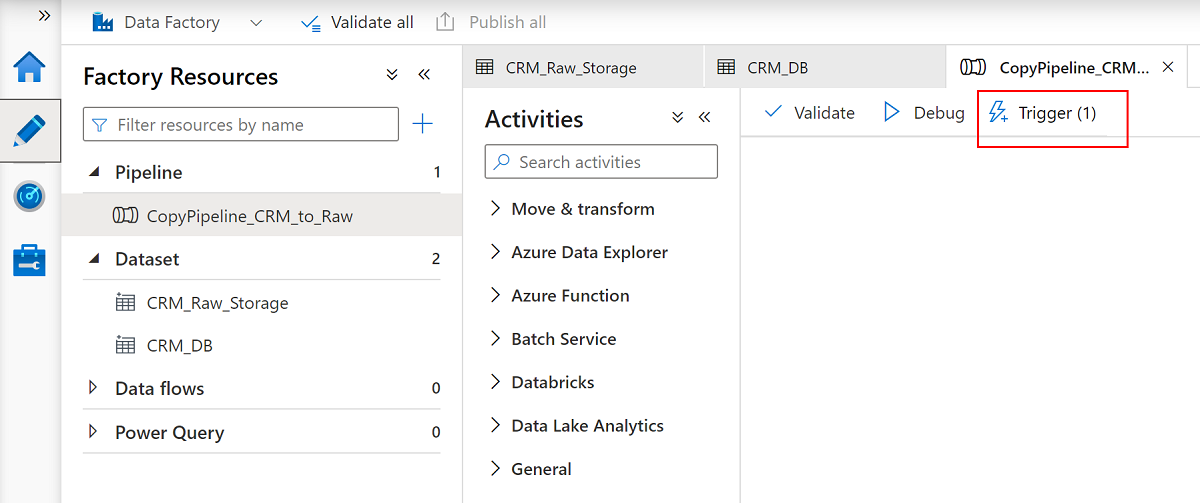
Usare lo strumento Copia dati con AdatumERP
Estrarre quindi i dati dal AdatumERP database. I dati rappresentano i dati di vendita provenienti dal sistema ERP.
Sempre in Data Factory Studio creare una nuova pipeline usando lo strumento Copia dati. Questa volta si inviano i dati di vendita dalla
AdatumERPcartella dei dati dell'account<DLZ-prefix>devrawdi archiviazione, allo stesso modo con i dati CRM. Completare gli stessi passaggi, ma usare ilAdatumERPdatabase come origine.Creare la pianificazione da attivare ogni ora.
Creare un servizio collegato all'istanza
AdatumERPdi database SQL.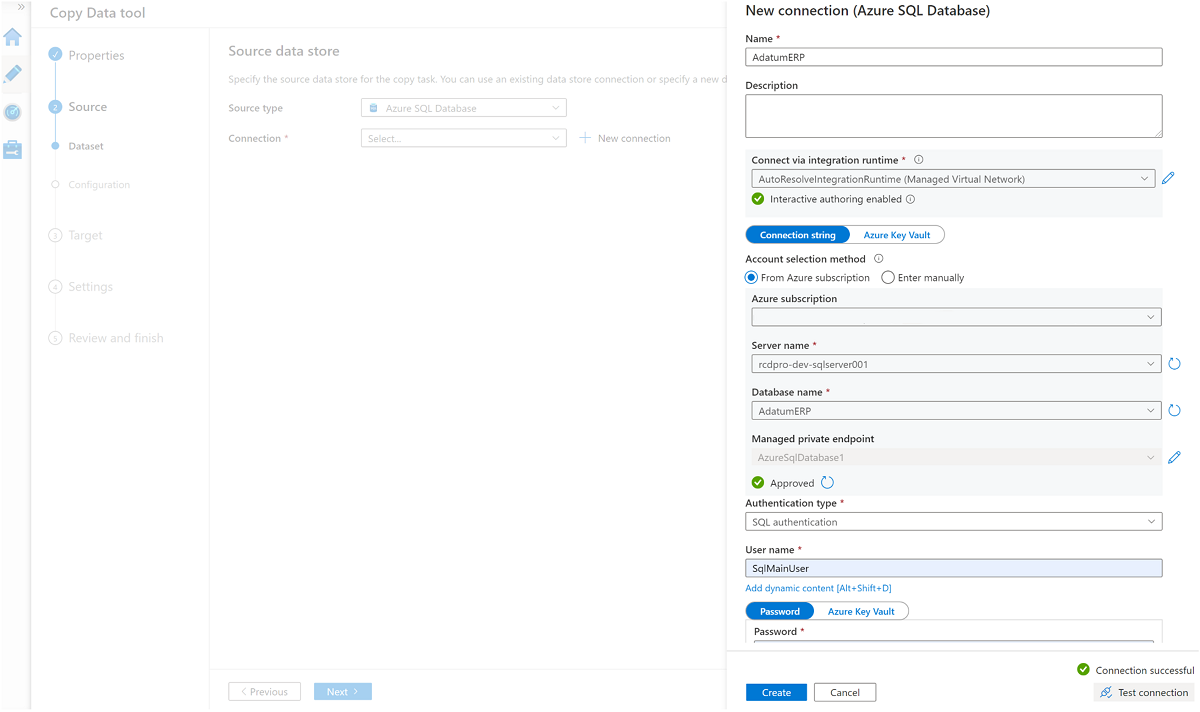
Selezionare queste sette tabelle:
SalesLT.ProductSalesLT.ProductCategorySalesLT.ProductDescriptionSalesLT.ProductModelSalesLT.ProductModelProductDescriptionSalesLT.SalesOrderDetailSalesLT.SalesOrderHeader
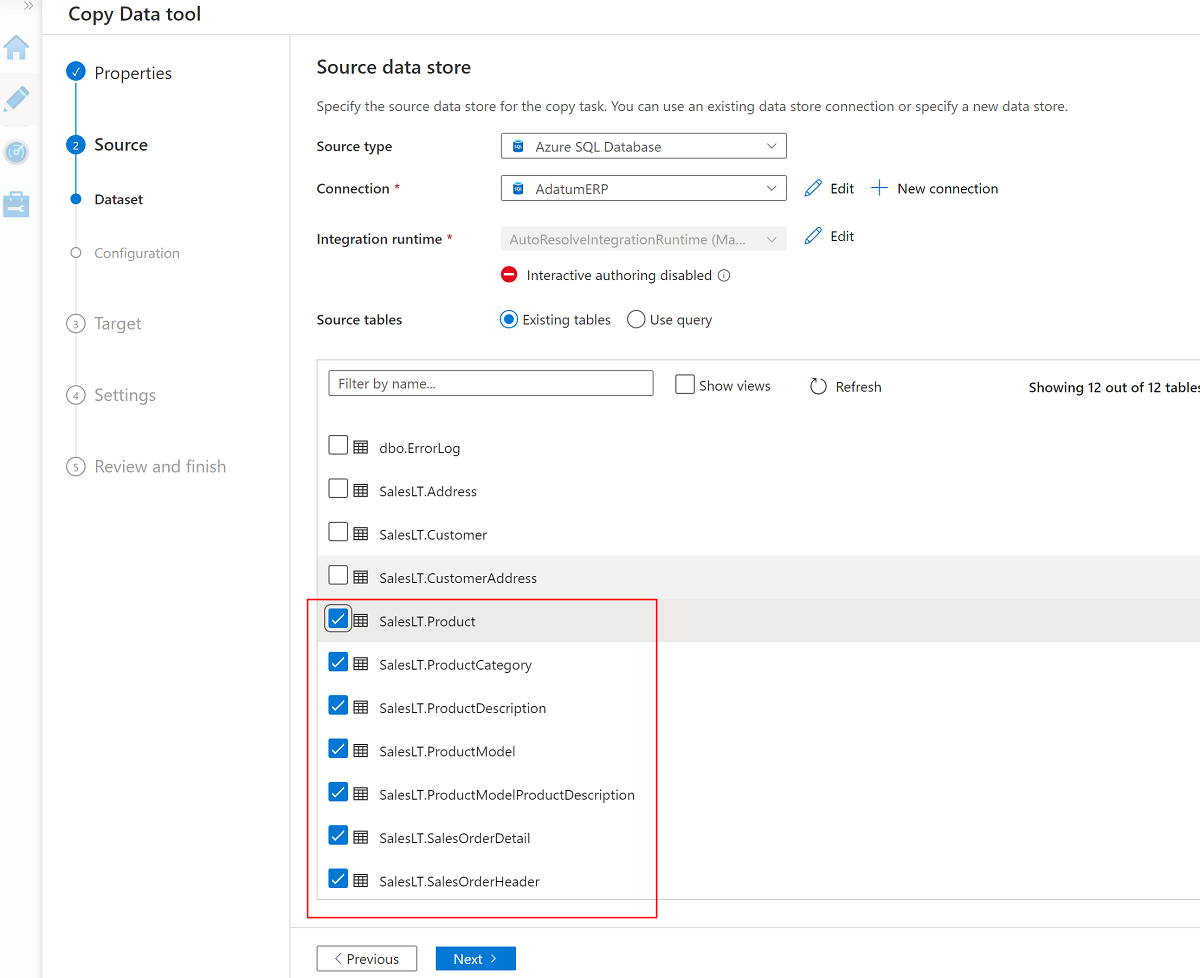
Usare il servizio collegato esistente per l'account
<DLZ-prefix>devrawdi archiviazione e impostare l'estensione del file su csv.
Selezionare Aggiungi intestazione al file.
Completare di nuovo la procedura guidata e rinominare la pipeline
CopyPipeline_ERP_to_DevRaw. Quindi, nella barra dei comandi selezionare Pubblica tutto. Eseguire infine il trigger in questa pipeline appena creata per copiare le sette tabelle selezionate da database SQL a Data Lake Archiviazione Gen2.

Al termine di questi passaggi, 10 file CSV si trovano nell'archiviazione <DLZ-prefix>devraw di Data Lake Archiviazione Gen2. Nella sezione successiva si curano i file nell'archiviazione <DLZ-prefix>devencur di Data Lake Archiviazione Gen2.
Curare i dati in Data Lake Archiviazione Gen2
Al termine della creazione dei 10 file CSV nell'archiviazione <DLZ-prefix>devraw data lake non elaborata Archiviazione Gen2, trasformare questi file in base alle esigenze durante la copia nell'archiviazione di Data Lake Archiviazione Gen2 curato<DLZ-prefix>devencur.
Continuare a usare Azure Data Factory per creare queste nuove pipeline per orchestrare lo spostamento dei dati.
Curare CRM ai dati dei clienti
Creare un flusso di dati che ottiene i file CSV nella cartella Data\CRM in <DLZ-prefix>devraw. Trasformare i file e copiare i file trasformati in formato parquet nella cartella Data\Customer in <DLZ-prefix>devencur.
In Azure Data Factory passare alla data factory e selezionare Orchestrate (Orchestra).
In Generale assegnare alla pipeline
Pipeline_transform_CRMil nome .Nel riquadro Attività espandere Sposta e trasforma. Trascinare l'attività del flusso di dati e rilasciarla nell'area di disegno della pipeline.
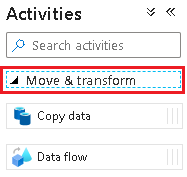
In Aggiunta Flusso di dati selezionare Crea nuovo flusso di dati e assegnare al flusso
CRM_to_Customerdi dati il nome . Selezionare Fine.Nota
Nella barra dei comandi dell'area di disegno della pipeline attivare Debug del flusso di dati. In modalità di debug è possibile testare in modo interattivo la logica di trasformazione in un cluster Apache Spark attivo. Il riscaldamento dei cluster del flusso di dati richiede da 5 a 7 minuti. È consigliabile attivare il debug prima di iniziare lo sviluppo del flusso di dati.

Al termine della selezione delle opzioni nel
CRM_to_Customerflusso di dati, laPipeline_transform_CRMpipeline avrà un aspetto simile a questo esempio: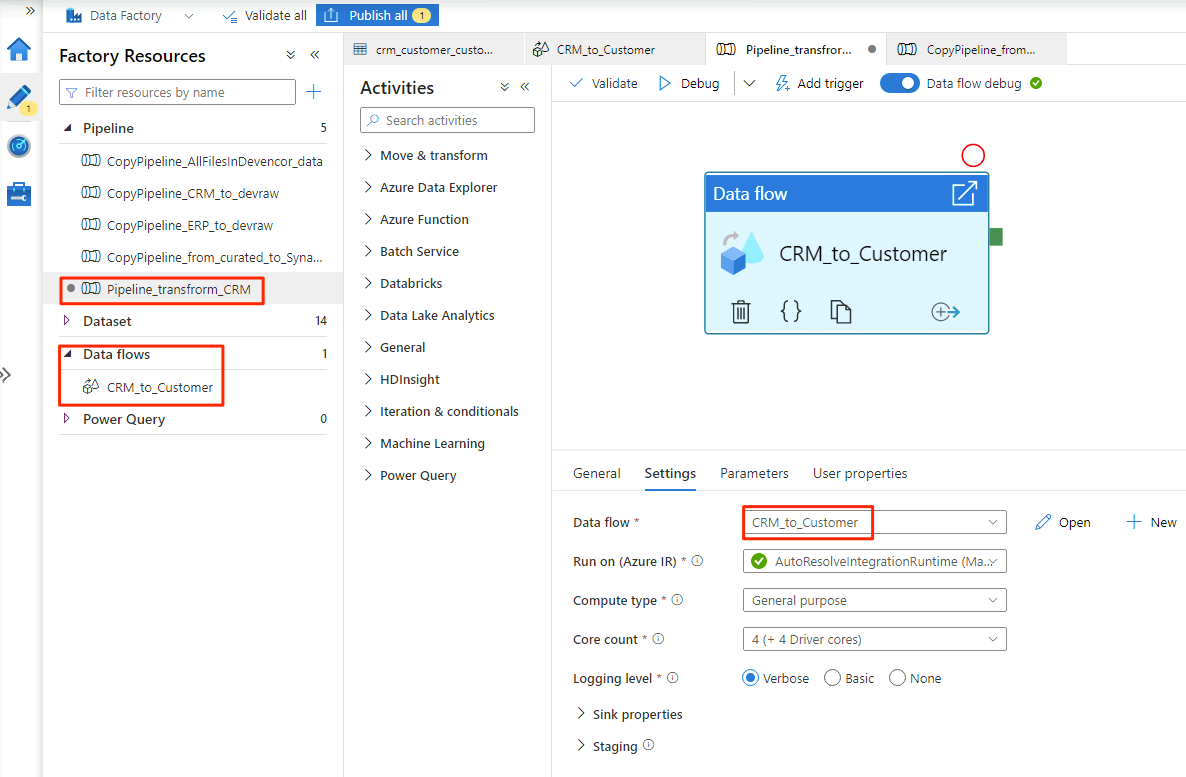
Il flusso di dati è simile all'esempio seguente:
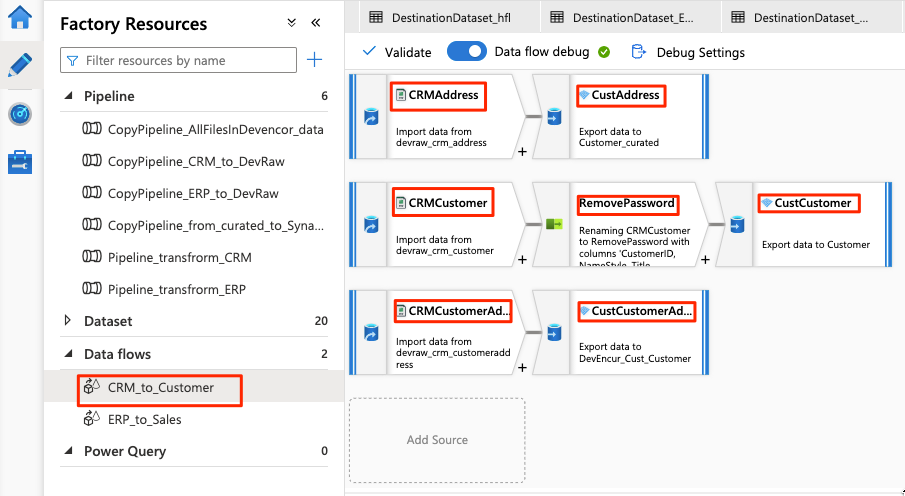
Modificare quindi queste impostazioni nel flusso di dati per l'origine
CRMAddress:Creare un nuovo set di dati da Data Lake Archiviazione Gen2. Usare il formato DelimitedText . Denominare il set di dati
DevRaw_CRM_Address.Connessione il servizio collegato a
<DLZ-prefix>devraw.Selezionare il
Data\CRM\SalesLTAddress.csvfile come origine.
Modificare queste impostazioni nel flusso di dati per il sink associato
CustAddress:Creare un nuovo set di dati denominato
DevEncur_Cust_Address.Selezionare la cartella Data\Customer in
<DLZ-prefix>devencurcome sink.In Impostazioni\Output in un singolo file convertire il file in Address.parquet.
Per il resto della configurazione del flusso di dati, usare le informazioni riportate nelle tabelle seguenti per ogni componente. Si noti che CRMAddress e CustAddress sono le prime due righe. Usarli come esempi per gli altri oggetti.
Un elemento che non si trova in una delle tabelle seguenti è il RemovePasswords modificatore dello schema. Lo screenshot precedente mostra che questo elemento passa tra CRMCustomer e CustCustomer. Per aggiungere questo modificatore dello schema, passare a Selezionare le impostazioni e rimuovere PasswordHash e PasswordSalt.
CRMCustomer restituisce uno schema a 15 colonne dal file con estensione crv. CustCustomer scrive solo 13 colonne dopo che il modificatore dello schema rimuove le due colonne della password.
Tabella completa
| Nome | Object type | Nome del set di dati | Archivio dati | Tipo di formato | Servizio collegato | File o cartella |
|---|---|---|---|---|---|---|
CRMAddress |
source | DevRaw_CRM_Address |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTAddress.csv |
CustAddress |
sink | DevEncur_Cust_Address |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Address.parquet |
CRMCustomer |
source | DevRaw_CRM_Customer |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTCustomer.csv |
CustCustomer |
sink | DevEncur_Cust_Customer |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Customer.parquet |
CRMCustomerAddress |
source | DevRaw_CRM_CustomerAddress |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTCustomerAddress.csv |
CustCustomerAddress |
sink | DevEncur_Cust_CustomerAddress |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\CustomerAddress.parquet |
Tabella ERP to Sales
Ripetere ora passaggi simili per creare una Pipeline_transform_ERP pipeline, creare un ERP_to_Sales flusso di dati per trasformare i file con estensione csv nella cartella Data\ERP in <DLZ-prefix>devrawe copiare i file trasformati nella cartella Data\Sales in <DLZ-prefix>devencur.
Nella tabella seguente sono disponibili gli oggetti da creare nel ERP_to_Sales flusso di dati e le impostazioni da modificare per ogni oggetto. Ogni file con estensione csv viene mappato a un sink parquet .
| Nome | Object type | Nome del set di dati | Archivio dati | Tipo di formato | Servizio collegato | File o cartella |
|---|---|---|---|---|---|---|
ERPProduct |
source | DevRaw_ERP_Product |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProduct.csv |
SalesProduct |
sink | DevEncur_Sales_Product |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\Product.parquet |
ERPProductCategory |
source | DevRaw_ERP_ProductCategory |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductCategory.csv |
SalesProductCategory |
sink | DevEncur_Sales_ProductCategory |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductCategory.parquet |
ERPProductDescription |
source | DevRaw_ERP_ProductDescription |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductDescription.csv |
SalesProductDescription |
sink | DevEncur_Sales_ProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductDescription.parquet |
ERPProductModel |
source | DevRaw_ERP_ProductModel |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductModel.csv |
SalesProductModel |
sink | DevEncur_Sales_ProductModel |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModel.parquet |
ERPProductModelProductDescription |
source | DevRaw_ERP_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductModelProductDescription.csv |
SalesProductModelProductDescription |
sink | DevEncur_Sales_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModelProductDescription.parquet |
ERPProductSalesOrderDetail |
source | DevRaw_ERP_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductSalesOrderDetail.csv |
SalesProductSalesOrderDetail |
sink | DevEncur_Sales_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderDetail.parquet |
ERPProductSalesOrderHeader |
source | DevRaw_ERP_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductSalesOrderHeader.csv |
SalesProductSalesOrderHeader |
sink | DevEncur_Sales_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderHeader.parquet |