Usare il contenitore Visione artificiale di Azure con Kubernetes e Helm
Un'opzione per gestire i contenitori di Visione artificiale di Azure in locale consiste nell'usare Kubernetes e Helm. Usando Kubernetes e Helm per definire un'immagine del contenitore di Visione artificiale di Azure, verrà creato un pacchetto Kubernetes. Questo pacchetto verrà distribuito in un cluster Kubernetes locale. Infine, si esaminerà come testare i servizi distribuiti. Per altre informazioni sull'esecuzione di contenitori Docker senza orchestrazione kubernetes, vedere Installare ed eseguire contenitori di Visione artificiale di Azure.
Prerequisiti
I prerequisiti seguenti prima di usare i contenitori di Visione artificiale di Azure in locale:
| Richiesto | Scopo |
|---|---|
| Account Azure | Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. |
| Kubernetes CLI | L'interfaccia della riga di comando di Kubernetes è necessaria per gestire le credenziali condivise dal registro contenitori. Kubernetes è necessario anche prima di Helm, che è il gestore dei pacchetti Kubernetes. |
| Interfaccia della riga di comando di Helm | Installare l'interfaccia della riga di comando Helm, usata per installare un grafico Helm (definizione del pacchetto contenitore). |
| Risorsa di Visione artificiale | Per usare il contenitore, è necessario disporre di: Una risorsa Visione artificiale e la chiave API associata l'URI dell'endpoint. Entrambi i valori sono disponibili nelle pagine Panoramica e Chiavi della risorsa nel portale di Azure e sono necessarie per avviare il contenitore. {API_KEY}: una delle due chiavi della risorsa disponibili nella pagina Chiavi {ENDPOINT_URI}: l'endpoint fornito nella pagina Panoramica |
Raccogliere i parametri necessari
Sono necessari tre parametri principali per tutti i contenitori di Intelligenza artificiale di Azure. Le condizioni di licenza per il software Microsoft devono essere presenti con un valore di accettazione. Sono necessari anche un URI dell’endpoint e una chiave API.
URI endpoint
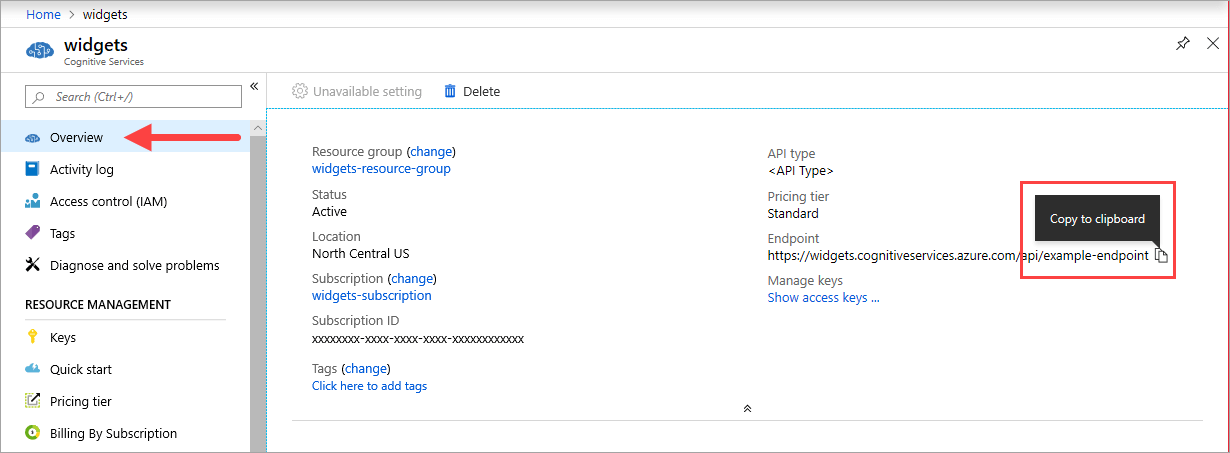
Il {ENDPOINT_URI} valore è disponibile nella pagina panoramica portale di Azure della risorsa dei servizi di intelligenza artificiale di Azure corrispondente. Accedere alla pagina Panoramica e passare il puntatore del mouse sull'endpoint. Verrà visualizzata un'icona Copia negli Appunti. Copiare e usare l'endpoint se necessario.
Chiavi
Il {API_KEY} valore viene usato per avviare il contenitore ed è disponibile nella pagina Chiavi di portale di Azure della risorsa corrispondente dei servizi di intelligenza artificiale di Azure. Accedere alla pagina Chiavi e selezionare l'icona Copia negli Appunti.

Importante
Queste chiavi di sottoscrizione vengono usate per accedere all'API Servizi di Azure AI. Non condividere le chiavi. Archiviarle in modo sicuro. Usare, ad esempio, Azure Key Vault. È anche consigliabile rigenerare queste chiavi regolarmente. Per effettuare una chiamata API è necessaria una sola chiave. Quando si rigenera la prima chiave, è possibile usare la seconda chiave per mantenere l'accesso al servizio.
Computer host
L'host è un computer con architettura basata su x64 che esegue il contenitore Docker. Può essere un computer dell'ambiente locale o un servizio di hosting Docker in Azure, tra cui:
- Servizio Azure Kubernetes.
- Istanze di Azure Container.
- Cluster Kubernetes distribuito in Azure Stack. Per altre informazioni, vedere Deploy Kubernetes to Azure Stack (Distribuire Kubernetes in Azure Stack).
Indicazioni e requisiti per i contenitori
Nota
I requisiti e le raccomandazioni si basano su benchmark con una singola richiesta al secondo e usano un'immagine da 523 KB di una lettera commerciale digitalizzata contenente 29 righe e un totale di 803 caratteri. La configurazione consigliata ha determinato una risposta approssimativamente 2 volte più veloce rispetto alla configurazione minima.
La tabella seguente descrive l'allocazione minima e consigliata di risorse per ogni contenitore Lettura OCR.
| Contenitore | Requisiti minimi | Requisiti consigliati |
|---|---|---|
| Read 3.2 2022-04-30 | 4 core, 8 GB di memoria | 8 core, 16 GB di memoria |
| Lettura 3.2 2021-04-12 | 4 core, 16 GB di memoria | 8 core, 24 GB di memoria |
- Ogni core deve essere di almeno 2,6 gigahertz (GHz) o superiore.
Core e memoria corrispondono alle impostazioni --cpus e --memory che vengono usate come parte del comando docker run.
Connettersi al cluster Kubernetes
Il computer host dovrebbe avere un cluster Kubernetes disponibile. Vedere questa esercitazione sulla distribuzione di un cluster Kubernetes per una conoscenza concettuale della distribuzione di un cluster Kubernetes in un computer host. Altre informazioni sulle distribuzioni sono disponibili nella documentazione di Kubernetes.
Configurare i valori del grafico Helm per la distribuzione
Per iniziare, creare una cartella denominata read. Incollare quindi il contenuto YAML seguente in un nuovo file denominato chart.yaml:
apiVersion: v2
name: read
version: 1.0.0
description: A Helm chart to deploy the Read OCR container to a Kubernetes cluster
dependencies:
- name: rabbitmq
condition: read.image.args.rabbitmq.enabled
version: ^6.12.0
repository: https://kubernetes-charts.storage.googleapis.com/
- name: redis
condition: read.image.args.redis.enabled
version: ^6.0.0
repository: https://kubernetes-charts.storage.googleapis.com/
Per configurare i valori predefiniti del grafico Helm, copiare e incollare il codice YAML seguente in un file denominato values.yaml. Sostituire i commenti # {ENDPOINT_URI} e # {API_KEY} con i propri valori. Configurare resultExpirationPeriod, Redis e RabbitMQ, se necessario.
# These settings are deployment specific and users can provide customizations
read:
enabled: true
image:
name: cognitive-services-read
registry: mcr.microsoft.com/
repository: azure-cognitive-services/vision/read
tag: 3.2-preview.1
args:
eula: accept
billing: # {ENDPOINT_URI}
apikey: # {API_KEY}
# Result expiration period setting. Specify when the system should clean up recognition results.
# For example, resultExpirationPeriod=1, the system will clear the recognition result 1hr after the process.
# resultExpirationPeriod=0, the system will clear the recognition result after result retrieval.
resultExpirationPeriod: 1
# Redis storage, if configured, will be used by read OCR container to store result records.
# A cache is required if multiple read OCR containers are placed behind load balancer.
redis:
enabled: false # {true/false}
password: password
# RabbitMQ is used for dispatching tasks. This can be useful when multiple read OCR containers are
# placed behind load balancer.
rabbitmq:
enabled: false # {true/false}
rabbitmq:
username: user
password: password
Importante
Se i
billingvalori eapikeynon vengono specificati, i servizi scadono dopo 15 minuti. Analogamente, la verifica non riesce perché i servizi non sono disponibili.Se si distribuiscono più contenitori Lettura OCR ed è presente un servizio di bilanciamento del carico, ad esempio in Docker Compose o Kubernetes, è necessario disporre di una cache esterna. Poiché il contenitore di elaborazione e il contenitore della richiesta GET possono essere diversi, una cache esterna archivia i risultati e li condivide tra contenitori. Per informazioni dettagliate sulle impostazioni della cache, vedere Configurare i contenitori Docker di Visione artificiale di Azure.
Creare una cartella templates nella directory read. Copiare e incollare il codice YAML seguente in un file denominato deployment.yaml. Il deployment.yaml file fungerà da modello Helm.
I modelli generano file manifesto, ovvero descrizioni di risorse in formato YAML che Kubernetes può comprendere. - Guida ai modelli di grafico Helm
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: {{.Values.read.image.name}}
image: {{.Values.read.image.registry}}{{.Values.read.image.repository}}
ports:
- containerPort: 5000
env:
- name: EULA
value: {{.Values.read.image.args.eula}}
- name: billing
value: {{.Values.read.image.args.billing}}
- name: apikey
value: {{.Values.read.image.args.apikey}}
args:
- ReadEngineConfig:ResultExpirationPeriod={{ .Values.read.image.args.resultExpirationPeriod }}
{{- if .Values.read.image.args.rabbitmq.enabled }}
- Queue:RabbitMQ:HostName={{ include "rabbitmq.hostname" . }}
- Queue:RabbitMQ:Username={{ .Values.read.image.args.rabbitmq.rabbitmq.username }}
- Queue:RabbitMQ:Password={{ .Values.read.image.args.rabbitmq.rabbitmq.password }}
{{- end }}
{{- if .Values.read.image.args.redis.enabled }}
- Cache:Redis:Configuration={{ include "redis.connStr" . }}
{{- end }}
imagePullSecrets:
- name: {{.Values.read.image.pullSecret}}
---
apiVersion: v1
kind: Service
metadata:
name: read-service
spec:
type: LoadBalancer
ports:
- port: 5000
selector:
app: read-app
Nella stessa cartella templates copiare e incollare le funzioni helper seguenti in helpers.tpl. helpers.tpl definisce funzioni utili per generare il modello Helm.
{{- define "rabbitmq.hostname" -}}
{{- printf "%s-rabbitmq" .Release.Name -}}
{{- end -}}
{{- define "redis.connStr" -}}
{{- $hostMain := printf "%s-redis-master:6379" .Release.Name }}
{{- $hostReplica := printf "%s-redis-replica:6379" .Release.Name -}}
{{- $passWord := printf "password=%s" .Values.read.image.args.redis.password -}}
{{- $connTail := "ssl=False,abortConnect=False" -}}
{{- printf "%s,%s,%s,%s" $hostMain $hostReplica $passWord $connTail -}}
{{- end -}}
Il modello specifica un servizio di bilanciamento del carico e la distribuzione del contenitore/immagine per Read.
Pacchetto Kubernetes (grafico Helm)
Il grafico Helm contiene la configurazione di cui eseguire il pull delle immagini Docker dal registro contenitori mcr.microsoft.com.
Un grafico Helm è una raccolta di file che descrivono un set correlato di risorse Kubernetes. È possibile usare un singolo grafico per distribuire qualcosa di semplice, ad esempio un pod memcached o qualcosa di complesso, ad esempio uno stack completo di app Web con server HTTP, database, cache e così via.
I grafici Helm forniti eseguono il pull delle immagini Docker del servizio Visione artificiale di Azure e del servizio corrispondente dal mcr.microsoft.com registro contenitori.
Installare il grafico Helm nel cluster Kubernetes
Per installare il grafico Helm, è necessario eseguire il comando helm install. Assicurarsi di eseguire il comando di installazione dalla directory sopra la cartella read.
helm install read ./read
Di seguito è riportato un output di esempio che potrebbe verificarsi da un'esecuzione dell'installazione riuscita:
NAME: read
LAST DEPLOYED: Thu Sep 04 13:24:06 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
read-57cb76bcf7-45sdh 0/1 ContainerCreating 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 0s
==> v1beta1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
read 0/1 1 0 0s
Il completamento della distribuzione di Kubernetes può richiedere più minuti. Per verificare che i pod e i servizi siano distribuiti correttamente e disponibili, eseguire il comando seguente:
kubectl get all
Si dovrebbe visualizzare una schermata simile all'output seguente:
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-57cb76bcf7-45sdh 1/1 Running 0 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45h
service/read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 17s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 1/1 1 1 17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-57cb76bcf7 1 1 1 17s
Distribuire più contenitori v3 nel cluster Kubernetes
A partire dalla versione 3 del contenitore, è possibile usare i contenitori in parallelo sia a livello di attività che di pagina.
Per impostazione predefinita, ogni contenitore v3 ha un dispatcher e un ruolo di lavoro di riconoscimento. Il dispatcher è responsabile della suddivisione di un'attività a più pagine in più sottoattività a pagina singola. Il ruolo di lavoro di riconoscimento è ottimizzato per il riconoscimento di un singolo documento di pagina. Per ottenere il parallelismo a livello di pagina, distribuire più contenitori v3 dietro un servizio di bilanciamento del carico e consentire ai contenitori di condividere un'archiviazione e una coda universali.
Nota
Attualmente sono supportati solo Archiviazione di Azure e Coda di Azure.
Il contenitore che riceve la richiesta può suddividere l'attività in sottoattività a pagina singola e aggiungerle alla coda universale. Qualsiasi ruolo di lavoro di riconoscimento da un contenitore meno occupato può utilizzare attività secondarie a pagina singola dalla coda, eseguire il riconoscimento e caricare il risultato nella risorsa di archiviazione. La velocità effettiva può essere migliorata fino a n volte, a seconda del numero di contenitori distribuiti.
Il contenitore v3 espone l'API probe di attività nel percorso /ContainerLiveness. Usare l'esempio di distribuzione seguente per configurare un probe di attività per Kubernetes.
Copiare e incollare il codice YAML seguente in un file denominato deployment.yaml. Sostituire i commenti # {ENDPOINT_URI} e # {API_KEY} con i propri valori. Sostituire il commento con la stringa # {AZURE_STORAGE_CONNECTION_STRING} di connessione di Archiviazione di Azure. Configurare replicas sul numero desiderato, che è impostato su 3 nell'esempio seguente.
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
replicas: # {NUMBER_OF_READ_CONTAINERS}
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: cognitive-services-read
image: mcr.microsoft.com/azure-cognitive-services/vision/read
ports:
- containerPort: 5000
env:
- name: EULA
value: accept
- name: billing
value: # {ENDPOINT_URI}
- name: apikey
value: # {API_KEY}
- name: Storage__ObjectStore__AzureBlob__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
- name: Queue__Azure__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
livenessProbe:
httpGet:
path: /ContainerLiveness
port: 5000
initialDelaySeconds: 60
periodSeconds: 60
timeoutSeconds: 20
---
apiVersion: v1
kind: Service
metadata:
name: azure-cognitive-service-read
spec:
type: LoadBalancer
ports:
- port: 5000
targetPort: 5000
selector:
app: read-app
Esegui il comando seguente:
kubectl apply -f deployment.yaml
Di seguito è riportato un esempio di output che potrebbe verificarsi in seguito a un'esecuzione corretta della distribuzione:
deployment.apps/read created
service/azure-cognitive-service-read created
Il completamento della distribuzione di Kubernetes può richiedere alcuni minuti. Per verificare che i pod e i servizi siano distribuiti correttamente e disponibili, quindi eseguire il comando seguente:
kubectl get all
L'output della console dovrebbe essere simile al seguente.
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-6cbbb6678-58s9t 1/1 Running 0 3s
pod/read-6cbbb6678-kz7v4 1/1 Running 0 3s
pod/read-6cbbb6678-s2pct 1/1 Running 0 3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/azure-cognitive-service-read LoadBalancer 10.0.134.0 <none> 5000:30846/TCP 17h
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 78d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 3/3 3 3 3s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-6cbbb6678 3 3 3 3s
Verificare che il contenitore sia in esecuzione
Per verificare se il contenitore è in esecuzione, sono disponibili diverse opzioni. Individuare l'indirizzo IP esterno e la porta esposta del contenitore in questione, quindi aprire il Web browser di scelta. Usare i vari URL di richiesta seguenti per verificare che il contenitore sia in esecuzione. Gli URL di richiesta di esempio elencati di seguito sono http://localhost:5000, ma il proprio contenitore specifico potrebbe variare. Assicurarsi di usare l'indirizzo IP esterno e la porta esposta del contenitore.
| Richiesta URL | Scopo |
|---|---|
http://localhost:5000/ |
Il contenitore fornisce un home page. |
http://localhost:5000/ready |
Questo URL, richiesto con un'operazione GET, verifica che il contenitore sia pronto per accettare una query sul modello. Questa richiesta può essere usata per i probe di attività e di idoneità di Kubernetes. |
http://localhost:5000/status |
Questo URL, anch'esso richiesto con un'operazione GET, verifica se la chiave API usata per avviare il contenitore sia valida senza che sia necessaria una query sull'endpoint. Questa richiesta può essere usata per i probe di attività e di idoneità di Kubernetes. |
http://localhost:5000/swagger |
Il contenitore fornisce un set completo di documentazione per gli endpoint e una funzionalità Prova. Con questa funzionalità, è possibile immettere le impostazioni in un modulo HTML basato sul Web ed eseguire la query senza scrivere codice. Dopo che la query restituisce il risultato, viene fornito un comando CURL di esempio per illustrare il formato richiesto per il corpo e le intestazioni HTTP. |

Passaggi successivi
Per altre informazioni sull'installazione di applicazioni con Helm nel servizio Azure Kubernetes, vedere qui.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per