Traduttore personalizzato per principianti
Traduttore personalizzato consente di creare un sistema di traduzione che rifletta la terminologia e lo stile specifici dell'azienda, del settore e di un dominio specifico. Il training e la distribuzione di un sistema personalizzato sono operazioni semplici e non richiedono alcuna competenza di programmazione. Il sistema di traduzione personalizzata si integra perfettamente con le applicazioni, i flussi di lavoro e i siti Web esistenti ed è disponibile in Azure tramite lo stesso servizio API Traduzione di testo di Microsoft basato sul cloud che supporta miliardi di traduzioni ogni giorno.
La piattaforma consente agli utenti di creare e pubblicare sistemi di traduzione personalizzati da e verso l'inglese. Traduttore personalizzato supporta più di 60i lingue corrispondenti alle lingue disponibili per la traduzione automatica neurale. Per un elenco completo, vedereLingue supportate da Traduttore.
Un modello di traduzione personalizzata è la scelta giusta?
Un modello di traduzione personalizzata con training ottimale offre traduzioni specifiche del dominio più accurate perché si basa su documenti del dominio tradotti in precedenza per apprendere le traduzioni preferite. Traduttore usa i termini e le frasi nel contesto per produrre traduzioni scorrevoli nella lingua di destinazione rispettando al contempo la grammatica del contesto.
Il training di un modello di traduzione personalizzata completo richiede una notevole quantità di dati. Se non si dispone di almeno 10.000 frasi di documenti sottoposti precedentemente a training, non sarà possibile eseguire il training di un modello di traduzione completo per una lingua. Tuttavia, è possibile eseguire il training di un modello di solo dizionario o usare le traduzioni predefinite di alta qualità disponibili con l'API Traduzione di testo.
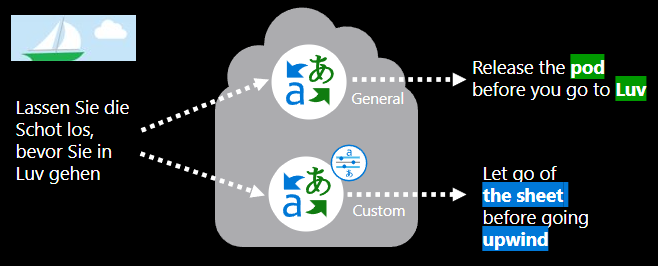
Che cosa implica il training di un modello di traduzione personalizzata?
La creazione di un modello di traduzione personalizzata richiede:
Informazioni sul caso d'uso.
Recupero di dati tradotti nel dominio (preferibilmente tradotti da traduttori umani).
Possibilità di valutare la qualità della traduzione o le traduzioni nella lingua di destinazione.
Come si valuta il caso d'uso?
Avere informazioni chiare sul caso d'uso e su come dovrebbe essere una traduzione corretta è il primo passo verso il recupero di dati di training ottimali. Ecco alcune considerazioni di cui tenere conto:
Qual è il risultato desiderato e come verrà misurato?
Qual è il dominio aziendale?
Sono presenti frasi specifiche del dominio con terminologia e stile simili?
Il caso d'uso rientra in più domini? Se sì, è necessario creare un unico sistema o più sistemi di traduzione?
Ci sono requisiti che influiscono sulla residenza dei dati inattivi e in transito a livello di area?
Gli utenti di destinazione si trovano in una o più aree?
Come recuperare i dati?
La ricerca di dati di qualità nel dominio è spesso un'attività complessa che varia in base alla classificazione degli utenti. Ecco alcune domande che è possibile porsi quando si valutano i dati disponibili:
Le aziende hanno spesso molti dati di traduzione che sono stati accumulati in molti anni di utilizzo della traduzione umana. L'azienda dispone di dati di traduzione precedenti che è possibile usare?
Si dispone di una grande quantità di dati monolingua? I dati monolingua sono dati in una sola lingua. In tal caso, è possibile ottenere traduzioni per questi dati?
È possibile eseguire la ricerca per indicizzazione nei portali online per raccogliere frasi di origine e sintetizzare le frasi di destinazione?
Cosa usare per il materiale di training?
| Origine | Risultato | Regole da seguire |
|---|---|---|
| Documenti di training bilingue | Insegnano al sistema la terminologia e lo stile. | Essere moderati. Qualsiasi traduzione umana in-domain è migliore della traduzione automatica. Aggiungere e rimuovere i documenti man mano che si procede e provare a migliorare il punteggio BLEU. |
| Ottimizzazione dei documenti | Esegue il training dei parametri della traduzione automatica neurale. | Essere rigidi. Comporre questi elementi in modo che siano rappresentativi in modo ottimale di ciò che si intende tradurre in futuro. |
| Documenti di test | Calcolano il punteggio BLEU. | Essere rigidi. Comporre i documenti di test in modo che siano rappresentativi in modo ottimale di ciò che si prevede di tradurre in futuro. |
| Dizionario di espressioni | Forza sempre la traduzione specificata. | Essere restrittivi. Un dizionario di espressioni fa distinzione tra maiuscole e minuscole e qualsiasi parola o espressione elencata viene tradotta nel modo specificato. In molti casi, è preferibile non usare un dizionario di espressioni e consentire al sistema di apprendere. |
| Dizionario di frasi | Forza sempre la traduzione specificata. | Essere rigidi. Un dizionario di frasi non fa distinzione tra maiuscole e minuscole ed adatto per frasi brevi di dominio e comuni. La corrispondenza con una frase del dizionario si verifica se l'intera frase inviata corrisponde alla voce di origine del dizionario. Se solo una parte della frase corrisponde, la corrispondenza con la voce non si verifica. |
Che cos'è un punteggio BLEU?
BLEU (Bilingual Evaluation Understudy) è un algoritmo per valutare la precisione o l'accuratezza del testo tradotto automaticamente da una lingua a un'altra. Traduttore personalizzato usa la metrica BLEU come indicatore dell'accuratezza della traduzione.
Un punteggio BLEU è un numero compreso tra zero e 100. Un punteggio pari a zero indica una traduzione di bassa qualità, in cui nessun elemento nella traduzione corrisponde al riferimento. Un punteggio pari a 100 indica una traduzione perfetta identica al riferimento. Non è necessario ottenere un punteggio pari a 100. Un punteggio BLEU compreso tra 40 e 60 indica una traduzione di alta qualità.
Cosa accade se non si inviano dati di ottimizzazione o test?
Le frasi di ottimizzazione e test rappresentano perfettamente ciò che si prevede di tradurre in futuro. Se non si inviano dati di ottimizzazione o test, Traduttore personalizzato escluderà automaticamente le frasi dai documenti di training da usare come dati di ottimizzazione e test.
| Generato dal sistema | Selezione manuale |
|---|---|
| Pratici. | Consente l'ottimizzazione per esigenze future. |
| Ottimali se i dati di training sono rappresentativi dei testi che si prevede di tradurre. | Offre maggiore libertà di comporre i dati di training. |
| Facile da ripetere quando si aumenta o si riduce il dominio. | Consente un maggior numero di dati e una migliore copertura del dominio. |
| Modifica ogni esecuzione di training. | Rimane statico su esecuzioni di training ripetute |
Come viene elaborato il materiale di training da Traduttore personalizzato?
Per prepararsi al training, i documenti vengono sottoposti a una serie di passaggi di elaborazione e i applicazione dei filtri. Questi passaggi sono illustrati di seguito. La conoscenza del processo di applicazione dei filtri può essere utile per comprendere il numero di frasi visualizzate e i passaggi che è possibile eseguire per preparare i documenti di training per il training con Traduttore personalizzato.
Allineamento di frasi
Se il documento non è in formato XLIFF, XLSX, TMX o ALIGN, Traduttore personalizzato allinea le frasi dei documenti di origine e destinazione tra loro, frase per frase. Traduttore non esegue l'allineamento dei documenti: segue la convenzione di denominazione dei documenti per trovare il documento corrispondente nell'altra lingua. All'interno del documento di origine Traduttore personalizzato tenta di trovare la frase corrispondente nella lingua di destinazione. Per facilitare l'allineamento usa il markup del documento, ad esempio i tag HTML presenti nel documento.
Se viene visualizzata una grande discrepanza tra il numero di frasi nei documenti di origine e di destinazione, il documento di origine potrebbe non essere parallelo o non è stato possibile allinearlo. Le coppie di documenti con una grande differenza (>10%) fra le frasi devono essere controllati attentamente per verificare che siano paralleli.
Estrazione di dati di ottimizzazione e test
I dati di ottimizzazione e test sono facoltativi. Se non vengono inseriti, il sistema rimuoverà una percentuale appropriata dai documenti di training da usare per l'ottimizzazione e il test. La rimozione avviene in modo dinamico come parte del processo di training. Poiché questo passaggio viene eseguito come parte del training, i documenti caricati non sono interessati. È possibile visualizzare i conteggi finali delle frasi usate per ogni categoria di dati (training, ottimizzazione, test e dizionario) nella pagina dei dettagli del modello dopo il corretto completamento del training.
Filtro di lunghezza
- Rimuove le frasi con una sola parola su entrambi i lati.
- Rimuove le frasi con più di 100 parole su entrambi i lati. Cinese, giapponese e coreano sono esenti.
- Rimuove le frasi con meno di tre caratteri. Cinese, giapponese e coreano sono esenti.
- Rimuove le frasi con più di 2.000 caratteri per cinese, giapponese e coreano.
- Rimuove le frasi con meno dell'1% di caratteri alfanumerici.
- Rimuove le voci di dizionario che contengono più di 50 parole.
Spazi vuoti
- Sostituisce qualsiasi sequenza spazio-carattere tra cui le tabulazioni e le sequenze CR/LF con un singolo carattere spazio.
- Rimuove gli spazi iniziali o finali nella frase.
Punteggiatura finale della frase
Sostituisce più caratteri di punteggiatura di fine frase con un solo carattere. Normalizzazione dei caratteri giapponesi.
Converte lettere e cifre a larghezza intera in caratteri a metà larghezza.
Tag XML senza escape
Trasforma i tag senza escape in tag con escape:
Tag Diventa < < > > & & Caratteri non validi
Il traduttore personalizzato rimuove le frasi che contengono il carattere Unicode U+FFFD. Il carattere U+FFFD indica una conversione della codifica non riuscita.
Quali passaggi è necessario eseguire prima del caricamento dei dati?
- Rimuovere le frasi con codifica non valida.
- Rimuovere caratteri di controllo Unicode.
- Se possibile, allineare le frasi (da origine a destinazione).
- Rimuovere le frasi di origine e di destinazione che non corrispondono alle lingue di origine e di destinazione.
- Quando le frasi di origine e di destinazione hanno lingue miste, assicurarsi che le parole non tradotte siano intenzionali, ad esempio nomi di organizzazioni e prodotti.
- Correggere gli errori grammaticali e di digitazione per evitare di insegnare questi errori al modello.
- Anche se il processo di training gestisce le righe di origine e di destinazione contenenti più frasi, è preferibile eseguire il mapping di una frase di origine a una frase di destinazione.
Come si valutano i risultati?
Dopo aver completato correttamente il training del modello, è possibile visualizzare il punteggio BLEU del modello e il punteggio BLEU del modello di base nella pagina dei dettagli del modello. Viene usato lo stesso set di dati di test per generare sia il punteggio BLEU del modello che il punteggio BLEU di base. Questi dati consentono di prendere decisioni informate relative al modello migliore per il caso d'uso.