Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Importante
Il mirroring di Azure Cosmos DB in Microsoft Fabric è ora disponibile per l'API NoSql. Questa funzionalità offre tutte le funzionalità del Collegamento ad Azure Synapse con prestazioni analitiche migliori, la possibilità di unificare il patrimonio di dati con Fabric OneLake e di aprire l'accesso ai dati in formato Delta Parquet. Se si sta valutando il Collegamento ad Azure Synapse, è consigliabile provare a eseguire il mirroring per valutare l'idoneità complessiva per l'organizzazione. Introduzione al mirroring in Microsoft Fabric.
Per iniziare a usare il Collegamento ad Azure Synapse, visitare "Introduzione al Collegamento ad Azure Synapse"
L'archivio analitico di Azure Cosmos DB è un archivio colonne completamente isolato per consentire l'analisi su larga scala dei dati operativi in Azure Cosmos DB, senza alcun impatto sui carichi di lavoro transazionali.
L'archivio transazionale di Azure Cosmos DB è senza schema e consente di eseguire l'iterazione sulle applicazioni transazionali senza dover gestire schemi o indici. Al contrario, l'archivio analitico di Azure Cosmos DB è schematizzato per ottimizzare le prestazioni delle query analitiche. Questo articolo descrive in dettaglio l'archiviazione analitica.
Problemi con l'analisi su larga scala dei dati operativi
I dati operativi multimodello in un contenitore Azure Cosmos DB vengono archiviati internamente in un "archivio transazionale" indicizzato basato su righe. Il formato dell'archivio righe è progettato per consentire letture e scritture transazionali rapide nei tempi di risposta dell'ordine dei millisecondi e query operative. Se il set di dati aumenta di dimensioni elevate, le query analitiche complesse possono risultare costose in termini di velocità effettiva con provisioning sui dati archiviati in questo formato. Il consumo elevato di velocità effettiva con provisioning a sua volta influisce sulle prestazioni dei carichi di lavoro transazionali usati dalle applicazioni e dai servizi in tempo reale.
Tradizionalmente, per analizzare grandi quantità di dati, i dati operativi vengono estratti dall'archivio transazionale di Azure Cosmos DB e archiviati in un livello dati separato. Ad esempio, i dati vengono archiviati in un data warehouse o data lake in un formato appropriato. Questi dati vengono successivamente usati per analisi su larga scala e analizzati con motori di calcolo come i cluster Apache Spark. La separazione dei dati analitici dai dati operativi comporta ritardi per gli analisti che vogliono usare i dati più recenti.
Anche le pipeline ETL diventano complesse quando si gestiscono gli aggiornamenti ai dati operativi rispetto alla gestione dei soli dati operativi appena inseriti.
Archivio analitico orientato alle colonne
L'archivio analitico di Azure Cosmos DB risolve i problemi di complessità e latenza che si verificano con le pipeline ETL tradizionali. L'archivio analitico di Azure Cosmos DB può sincronizzare automaticamente i dati operativi in un archivio colonne separato. Il formato dell'archivio colonne è adatto per l'esecuzione di query analitiche su larga scala in modo ottimizzato, con conseguente miglioramento della latenza di tali query.
Usando Collegamento ad Azure Synapse, è ora possibile creare soluzioni HTAP senza ETL collegandosi direttamente all'archivio analitico di Azure Cosmos DB da Azure Synapse Analytics. Consente di eseguire analisi su larga scala in near real-time sui dati operativi.
Funzionalità dell'archivio analitico
Quando si abilita l'archivio analitico in un contenitore Azure Cosmos DB, viene creato internamente un nuovo archivio colonne in base ai dati operativi presenti nel contenitore. Questo archivio colonne viene salvato in modo permanente separatamente dall'archivio transazionale orientato alle righe per tale contenitore, in un account di archiviazione completamente gestito da Azure Cosmos DB, in una sottoscrizione interna. I clienti non devono dedicare tempo all'amministrazione dell'archiviazione. Gli inserimenti, gli aggiornamenti e le eliminazioni dei dati operativi vengono sincronizzati automaticamente con l'archivio analitico. Non è necessario il feed di modifiche o ETL per sincronizzare i dati.
Archivio colonne per carichi di lavoro analitici su dati operativi
I carichi di lavoro analitici in genere comportano aggregazioni e analisi sequenziali dei campi selezionati. L'archivio analitico dei dati viene archiviato in un ordine di colonna maggiore, consentendo la serializzazione dei valori di ogni campo, se applicabile. Questo formato riduce le operazioni di I/O al secondo necessarie per l'analisi o il calcolo delle statistiche su campi specifici. Migliora notevolmente i tempi di risposta delle query per le analisi su set di dati di grandi dimensioni.
Ad esempio, se le tabelle operative hanno il formato seguente:
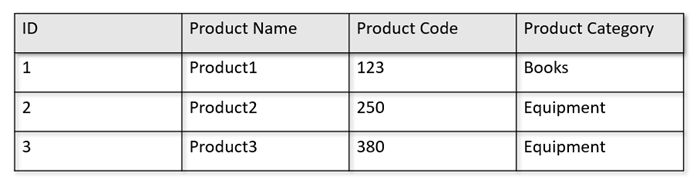
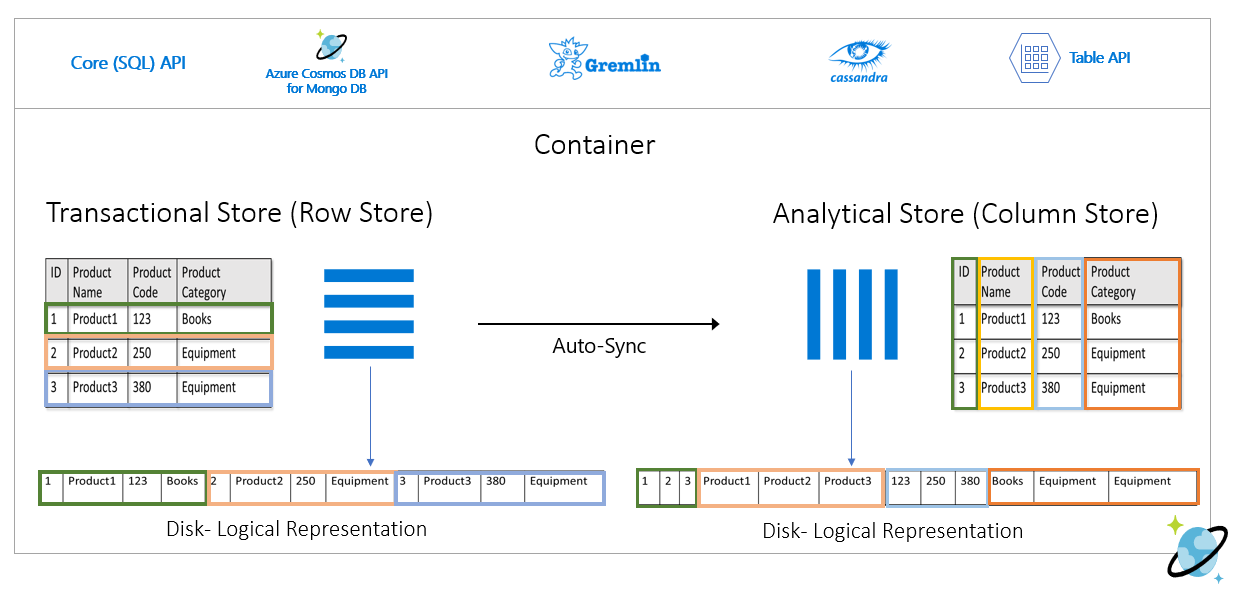
L'archivio righe salva in modo permanente i dati sopra riportati in un formato serializzato, per ogni riga, sul disco. Questo formato consente letture e scritture transazionali più veloci e query operative, ad esempio "restituire informazioni su Product 1". Tuttavia, man mano che le dimensioni del set di dati aumentano e se si vogliono eseguire query analitiche complesse sui dati, può essere costoso. Se, ad esempio, si vogliono ottenere "le tendenze di vendita per un prodotto nella categoria denominata 'Equipment' in diverse business unit e mesi", è necessario eseguire una query complessa. Le analisi di grandi dimensioni in questo set di dati possono risultare costose in termini di velocità effettiva con provisioning e possono anche influire sulle prestazioni dei carichi di lavoro transazionali che alimentano le applicazioni e i servizi in tempo reale.
L'archivio analitico, che è un archivio colonne, è più adatto per tali query perché serializza insieme i campi di dati simili e riduce le operazioni di I/O al secondo del disco.
Nell'immagine seguente viene illustrato l'archivio righe transazionale rispetto all'archivio colonne analitico in Azure Cosmos DB:
Prestazioni separate per carichi di lavoro analitici
Non vi è alcun impatto sulle prestazioni dei carichi di lavoro transazionali a causa di query analitiche, in quanto l'archivio analitico è separato dall'archivio transazionale. Per l'archivio analitico non è necessario allocare unità richiesta separate (UR).
Sincronizzazione automatica
La sincronizzazione automatica si riferisce alla funzionalità completamente gestita di Azure Cosmos DB in cui le operazioni di inserimento, aggiornamento ed eliminazione dei dati operativi vengono sincronizzate automaticamente dall'archivio transazionale all'archivio analitico in tempo quasi reale. La latenza di sincronizzazione automatica è in genere entro 2 minuti. Nei casi di database con velocità effettiva condivisa con un numero elevato di contenitori, la latenza di sincronizzazione automatica dei singoli contenitori potrebbe essere superiore e richiedere fino a 5 minuti.
Al termine di ogni esecuzione del processo di sincronizzazione automatica, i dati transazionali saranno immediatamente disponibili per i runtime di Azure Synapse Analytics:
I pool di Spark di Azure Synapse Analytics possono leggere tutti i dati, inclusi gli aggiornamenti più recenti, tramite tabelle Spark, che vengono aggiornate automaticamente o tramite il comando
spark.read, che legge sempre l'ultimo stato dei dati.I pool SQL Serverless di Azure Synapse Analytics possono leggere tutti i dati, inclusi gli aggiornamenti più recenti, tramite visualizzazioni, che vengono aggiornati automaticamente o tramite
SELECTinsieme ai comandiOPENROWSET, che legge sempre lo stato più recente dei dati.
Nota
I dati transazionali verranno sincronizzati con l'archivio analitico anche se la durata transazionale (TTL) è inferiore a 2 minuti.
Nota
Si noti che se si elimina il contenitore, viene eliminato anche l'archivio analitico.
Scalabilità ed elasticità
L'archivio transazionale di Azure Cosmos DB usa il partizionamento orizzontale per dimensionare in modo elastico l'archiviazione e la velocità effettiva senza tempi di inattività. Il partizionamento orizzontale nell'archivio transazionale fornisce scalabilità ed elasticità nella sincronizzazione automatica per garantire la sincronizzazione dei dati nell'archivio analitico in near real-time. La sincronizzazione dei dati viene eseguita indipendentemente dalla velocità effettiva del traffico transazionale, sia che si tratti di 1000 operazioni al secondo che di un milione di operazioni al secondo, e non influisce sulla velocità effettiva con provisioning nell'archivio transazionale.
Gestione automatica degli aggiornamenti dello schema
L'archivio transazionale di Azure Cosmos DB è senza schema e consente di eseguire l'iterazione sulle applicazioni transazionali senza dover gestire schemi o indici. Al contrario, l'archivio analitico di Azure Cosmos DB è schematizzato per ottimizzare le prestazioni delle query analitiche. Con la funzionalità di sincronizzazione automatica, Azure Cosmos DB gestisce l'inferenza dello schema sugli aggiornamenti più recenti dall'archivio transazionale. Gestisce inoltre per impostazione predefinita la rappresentazione dello schema nell'archivio analitico, che include la gestione dei tipi di dati annidati.
Man mano che lo schema si evolve e le nuove proprietà vengono aggiunte nel tempo, l'archivio analitico presenta automaticamente uno schema unificato di tutti gli schemi cronologici nell'archivio transazionale.
Nota
Nel contesto dell'archivio analitico le strutture seguenti vengono considerate come proprietà:
- "elementi" JSON o "coppie stringa-valore separate da
:". - Oggetti JSON, delimitati da
{e}. - Matrici JSON, delimitati da
[e].
Vincoli dello schema
I vincoli seguenti sono applicabili ai dati operativi in Azure Cosmos DB quando si abilita l'archivio analitico per dedurre e rappresentare correttamente lo schema:
È possibile avere un massimo di 1000 proprietà in tutti i livelli annidati nello schema del documento e una profondità massima di annidamento pari a 127.
- Solo le prime 1000 proprietà sono rappresentate nell'archivio analitico.
- Solo i primi 127 livelli annidati sono rappresentati nell'archivio analitico.
- Il primo livello di un documento JSON è il relativo livello radice
/. - Le proprietà nel primo livello del documento verranno rappresentate come colonne.
Scenari di esempio:
- Se il primo livello del documento ha 2000 proprietà, il processo di sincronizzazione rappresenterà i primi 1000 di essi.
- Se i documenti hanno cinque livelli con 200 proprietà in ognuno di essi, il processo di sincronizzazione rappresenterà tutte le proprietà.
- Se i documenti hanno 10 livelli con 400 proprietà in ognuno di essi, il processo di sincronizzazione rappresenterà completamente i due primi livelli e solo la metà del terzo livello.
Il documento ipotetico seguente contiene quattro proprietà e tre livelli.
- I livelli sono
root,myArraye la struttura annidata all'interno dimyArray. - Le proprietà sono
id,myArray,myArray.nested1emyArray.nested2. - La rappresentazione dell'archivio analitico avrà due colonne,
idemyArray. È possibile usare le funzioni Spark o T-SQL per esporre anche le strutture annidate come colonne.
- I livelli sono
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Mentre i documenti JSON (e le raccolte/contenitori di Azure Cosmos DB) fanno distinzione tra maiuscole e minuscole dal punto di vista dell'univocità, l'archivio analitico no.
- Nello stesso documento: i nomi delle proprietà nello stesso livello devono essere univoci quando confrontati senza distinzione tra maiuscole e minuscole. Ad esempio, il documento JSON seguente ha "Name" e "name" nello stesso livello. Anche se si tratta di un documento JSON valido, non soddisfa il vincolo di univocità e pertanto non sarà completamente rappresentato nell'archivio analitico. In questo esempio, "Name" e "name" sono uguali se confrontati in modo senza distinzione tra maiuscole e minuscole. Verrà rappresentato solo
"Name": "fred"nell'archivio analitico, perché è la prima occorrenza. E"name": "john"non sarà affatto rappresentato.
{"id": 1, "Name": "fred", "name": "john"}- In documenti diversi: le proprietà nello stesso livello e con lo stesso nome, ma in casi diversi, verranno rappresentate all'interno della stessa colonna, usando il formato del nome della prima occorrenza. Ad esempio, i documenti JSON seguenti hanno
"Name"e"name"nello stesso livello. Poiché il primo formato di documento è"Name", questo è ciò che verrà usato per rappresentare il nome della proprietà nell'archivio analitico. In altre parole, il nome della colonna nell'archivio analitico sarà"Name". Verranno rappresentati sia"fred"che"john", nella colonna"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- Nello stesso documento: i nomi delle proprietà nello stesso livello devono essere univoci quando confrontati senza distinzione tra maiuscole e minuscole. Ad esempio, il documento JSON seguente ha "Name" e "name" nello stesso livello. Anche se si tratta di un documento JSON valido, non soddisfa il vincolo di univocità e pertanto non sarà completamente rappresentato nell'archivio analitico. In questo esempio, "Name" e "name" sono uguali se confrontati in modo senza distinzione tra maiuscole e minuscole. Verrà rappresentato solo
Il primo documento della raccolta definisce lo schema iniziale dell'archivio analitico.
- I documenti con più proprietà rispetto allo schema iniziale genereranno nuove colonne nell'archivio analitico.
- Non è possibile rimuovere colonne.
- L'eliminazione di tutti i documenti in una raccolta non reimposta lo schema dell'archivio analitico.
- Il controllo delle versioni dello schema non è disponibile. L'ultima versione dedotta dall'archivio transazionale è ciò che verrà visualizzato nell'archivio analitico.
Attualmente Azure Synapse Spark non è in grado di leggere le proprietà che contengono alcuni caratteri speciali nei nomi, elencati di seguito. Azure Synapse SQL serverless non è interessato.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Nota
Gli spazi vuoti sono elencati anche nel messaggio di errore Spark restituito quando si raggiunge questa limitazione. Ma abbiamo aggiunto un trattamento speciale per gli spazi vuoti, si prega di consultare altri dettagli negli elementi seguenti.
- Se sono presenti nomi di proprietà che usano i caratteri elencati in precedenza, le alternative sono:
- Modificare in anticipo il modello di dati per evitare questi caratteri.
- Poiché attualmente non è supportata la reimpostazione dello schema, è possibile modificare l'applicazione per aggiungere una proprietà ridondante con un nome simile, evitando questi caratteri.
- Usare Feed di modifiche per creare una visualizzazione materializzata del contenitore senza questi caratteri nei nomi delle proprietà.
- Usare l'opzione Spark
dropColumnper ignorare le colonne interessate e caricare tutte le altre colonne in un dataframe. La sintassi è:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark supporta ora le proprietà con spazi vuoti nei nomi. A tale scopo, è necessario usare l'opzione Spark
allowWhiteSpaceInFieldNamesper caricare le colonne interessate in un dataframe, mantenendo il nome originale. La sintassi è:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
I tipi di dati BSON seguenti non sono supportati e non verranno rappresentati nell'archivio analitico:
- Decimal128
- Espressione regolare
- Puntatore DB
- JavaScript
- Simbolo
- MinKey/MaxKey
Quando si usano stringhe DateTime che seguono lo standard UTC ISO 8601, prevedere il comportamento seguente:
- I pool di Spark in Azure Synapse rappresentano queste colonne come
string. - I pool serverless SQL in Azure Synapse rappresentano queste colonne come
varchar(8000).
- I pool di Spark in Azure Synapse rappresentano queste colonne come
Le proprietà con tipi di
UNIQUEIDENTIFIER (guid)vengono rappresentate comestringnell'archivio analitico e devono essere convertite inVARCHARin SQL o instringin Spark per una visualizzazione corretta.I pool SQL serverless in Azure Synapse supportano i set di risultati con un massimo di 1000 colonne e l'esposizione di colonne nidificate conta anche per tale limite. È consigliabile prendere in considerazione queste informazioni nell'architettura e nella modellazione dei dati transazionali.
Se si rinomina una proprietà, in uno o più documenti, verrà considerata una nuova colonna. Se si esegue la stessa ridenominazione in tutti i documenti della raccolta, tutti i dati verranno migrati alla nuova colonna e la colonna precedente verrà rappresentata con valori
NULL.
Rappresentazione dello schema
Nell'archivio analitico sono disponibili due metodi di rappresentazione dello schema, validi per tutti i contenitori nell'account del database. Hanno compromessi tra la semplicità dell'esperienza di query e la praticità di una rappresentazione a colonne più inclusiva per gli schemi polimorfici.
- Rappresentazione dello schema ben definita, opzione predefinita per gli account API per NoSQL e Gremlin.
- Rappresentazione completa dello schema fedeltà, opzione predefinita per gli account API per MongoDB.
Rappresentazione dello schema ben definita
La rappresentazione dello schema ben definita crea una rappresentazione tabulare semplice dei dati indipendenti dallo schema nell'archivio transazionale. La rappresentazione dello schema ben definita presenta le considerazioni seguenti:
- Il primo documento definisce lo schema di base e le proprietà devono avere sempre lo stesso tipo in tutti i documenti. Le uniche eccezioni sono:
- Per i pool SQL Serverless in Azure Synapse: da
NULLa qualsiasi altro tipo di dati. La prima occorrenza non Null definisce il tipo di dati della colonna. Qualsiasi documento che non segue il primo tipo di dati non Null non verrà rappresentato nell'archivio analitico. - Per i pool di Spark e il Change Data Capture di Azure Data Factory in Azure Synapse: da
NULLaINT. L'evoluzione dalle proprietà Null ai tipi di dati diversi da INT non è supportata per i pool di Spark e Azure Data Factory Change Data Capture in Azure Synapse. Il primo valore non Null deve essere un numero intero e qualsiasi documento con un tipo di dati diverso non verrà rappresentato nell'archivio analitico. - Da
floatainteger. Tutti i documenti sono rappresentati nell'archivio analitico. - Da
integerafloat. Tutti i documenti sono rappresentati nell'archivio analitico. Tuttavia, per leggere questi dati con i pool serverless di Azure Synapse SQL, è necessario usare una clausola WITH per convertire la colonna invarchar. E dopo questa conversione iniziale, è possibile convertirlo nuovamente in un numero. Controllare l'esempio seguente, dove il valore iniziale num è un numero intero e il secondo è un valore float.
- Per i pool SQL Serverless in Azure Synapse: da
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Le proprietà che non seguono il tipo di dati dello schema di base non verranno rappresentate nell'archivio analitico. Si considerino ad esempio i documenti seguenti: il primo ha definito lo schema di base dell'archivio analitico. Il secondo documento, dove
idè"2", non ha uno schema ben definito perché la proprietà"code"è una stringa e il primo documento ha"code"come numero. In questo caso, l'archivio analitico registra il tipo di dati di"code"comeintegerper tutta la durata del contenitore. Il secondo documento verrà ancora incluso nell'archivio analitico, ma la relativa proprietà"code"non verrà inclusa.{"id": "1", "code":123}{"id": "2", "code": "123"}
Nota
La condizione precedente non si applica alle proprietà NULL. Ad esempio, {"a":123} and {"a":NULL} è ancora ben definito.
Nota
La condizione precedente non cambia se si aggiorna "code" di "1" del documento a una stringa nell'archivio transazionale. Nell'archivio analitico, "code" verrà mantenuto come integer poiché attualmente non è supportata la reimpostazione dello schema.
- I tipi di matrice devono contenere un solo tipo ripetuto. Ad esempio,
{"a": ["str",12]}non è uno schema ben definito perché la matrice contiene una combinazione di tipi integer e stringa.
Nota
Se l'archivio analitico di Azure Cosmos DB segue la rappresentazione dello schema ben definita e la specifica precedente viene violata da determinati elementi, tali elementi non verranno inclusi nell'archivio analitico.
Prevedere un comportamento diverso per quanto riguarda i diversi tipi nello schema ben definito:
- I pool di Spark in Azure Synapse rappresentano questi valori come
undefined. - I pool SQL serverless in Azure Synapse rappresentano questi valori come
NULL.
- I pool di Spark in Azure Synapse rappresentano questi valori come
Prevedere un comportamento diverso per quanto riguarda i valori espliciti
NULL:- I pool di Spark in Azure Synapse leggono questi valori come
0(zero), e comeundefinednon appena la colonna ha un valore non Null. - I pool SQL serverless in Azure Synapse leggono questi valori come
NULL.
- I pool di Spark in Azure Synapse leggono questi valori come
Prevedere un comportamento diverso per quanto riguarda le colonne mancanti:
- I pool di Spark in Azure Synapse rappresentano queste colonne come
undefined. - I pool serverless SQL in Azure Synapse rappresentano queste colonne come
NULL.
- I pool di Spark in Azure Synapse rappresentano queste colonne come
Soluzioni alternative per le sfide per la rappresentazione
È possibile che un documento precedente, con uno schema non corretto, sia stato usato per creare lo schema di base dell'archivio analitico del contenitore. In base a tutte le regole presentate in precedenza, è possibile ricevere NULL per determinate proprietà durante l'esecuzione di query sull'archivio analitico tramite collegamento ad Azure Synapse. Eliminare o aggiornare i documenti problematici non sarà utile perché la reimpostazione dello schema di base non è attualmente supportata. Le possibili soluzioni sono:
- Per eseguire la migrazione dei dati a un nuovo contenitore, assicurarsi che tutti i documenti abbiano lo schema corretto.
- Abbandonare la proprietà con lo schema errato e aggiungerne uno nuovo con un altro nome con lo schema corretto in tutti i documenti. Esempio: nel contenitore Ordini sono presenti miliardi di documenti in cui la proprietà status è una stringa. Ma il primo documento in tale contenitore ha lo stato definito con integer. Pertanto, un documento avrà lo stato correttamente rappresentato e tutti gli altri documenti avranno
NULL. È possibile aggiungere la proprietà status2 a tutti i documenti e iniziare a usarla, anziché la proprietà originale.
Rappresentazione dello schema con massima fedeltà
La rappresentazione completa dello schema fedeltà è progettata per gestire l'intera ampiezza degli schemi polimorfici nei dati operativi indipendenti dallo schema. In questa rappresentazione dello schema non viene eliminato alcun elemento dall'archivio analitico anche se vengono violati i vincoli dello schema ben definiti (ovvero non vengono violati campi di tipo di dati misti né matrici di tipi di dati misti).
Ciò si ottiene convertendo le proprietà foglia dei dati operativi nell'archivio analitico come coppie JSON key-value, dove il tipo di dati è key e il contenuto della proprietà è value. Questa rappresentazione di oggetto JSON consente query senza ambiguità ed è possibile analizzare singolarmente ogni tipo di dati.
In altre parole, nella rappresentazione dello schema con fedeltà completa, ogni tipo di dati di ogni proprietà di ogni documento genererà una key-valuecoppia in un oggetto JSON per tale proprietà. Ognuno di essi viene conteggiato come uno dei 1000 limiti massimi di proprietà.
Si prenda ad esempio il documento di esempio seguente nell'archivio transazionale:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
L'oggetto annidato address è una proprietà nel livello radice del documento e verrà rappresentata come colonna. Ogni proprietà foglia nell'oggetto address verrà rappresentata come oggetto JSON: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
A differenza della rappresentazione dello schema ben definita, il metodo di fedeltà completa consente la variazione nei tipi di dati. Se il documento successivo in questa raccolta dell'esempio precedente ha streetNo come stringa, verrà rappresentato nell'archivio analitico come "streetNo":{"string":15850}. Nel metodo dello schema ben definito non verrebbe rappresentato.
Mappa dei tipi di dati per lo schema di fedeltà completa
Ecco una mappa dei tipi di dati MongoDB e le relative rappresentazioni nell'archivio analitico in rappresentazione dello schema con fedeltà completa. La mappa seguente non è valida per gli account API NoSQL.
| Tipo dati originale | Suffisso | Esempio |
|---|---|---|
| Doppio | ".float64" | 24,99 |
| Matrice | .array | ["a", "b"] |
| Binario | ".binary" | 0 |
| Booleano | ".bool" | Vero |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULLO | ". NULL" | NULLO |
| Stringa | ".string" | "ABC" |
| Timestamp: | ".timestamp" | Timestamp(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Documento | ".object" | {"a": "a"} |
Prevedere un comportamento diverso per quanto riguarda i valori espliciti
NULL:- I pool di Spark in Azure Synapse leggono questi valori come
0(zero). - I pool SQL serverless in Azure Synapse leggono questi valori come
NULL.
- I pool di Spark in Azure Synapse leggono questi valori come
Prevedere un comportamento diverso per quanto riguarda le colonne mancanti:
- I pool di Spark in Azure Synapse rappresenteranno queste colonne come
undefined. - I pool serverless SQL in Azure Synapse rappresenteranno queste colonne come
NULL.
- I pool di Spark in Azure Synapse rappresenteranno queste colonne come
Prevedere un comportamento diverso per quanto riguarda i valori
timestamp:- I pool di Spark in Azure Synapse leggeranno questi valori come
TimestampType,DateTypeoFloat. Dipende dall'intervallo e dalla modalità di generazione del timestamp. - I pool SQL Serverless in Azure Synapse leggeranno questi valori come
DATETIME2, che vanno da0001-01-01a9999-12-31. I valori oltre questo intervallo non sono supportati e causeranno un errore di esecuzione per le query. In questo caso, è possibile:- Rimuovere la colonna dalla query. Per mantenere la rappresentazione, è possibile creare una nuova proprietà di mirroring della colonna, ma all'interno dell'intervallo supportato. E usarlo nelle query.
- Usare Change Data Capture dall'archivio analitico, senza costi di UR, per trasformare e caricare i dati in un nuovo formato, all'interno di uno dei sink supportati.
- I pool di Spark in Azure Synapse leggeranno questi valori come
Uso dello schema con fedeltà completa con Spark
Spark gestirà ogni tipo di dati come colonna durante il caricamento in un oggetto DataFrame. Si ipotizzi una collezione con i documenti sottostanti.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Mentre il primo documento ha rating come numero e timestamp in formato utc, il secondo documento ha rating e timestamp come stringhe. Supponendo che questa raccolta sia stata caricata in DataFrame senza alcuna trasformazione dei dati, l'output di df.printSchema() è:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
Nella rappresentazione dello schema ben definita, sia rating che timestamp del secondo documento non verranno rappresentati. Nello schema con fedeltà completa è possibile usare gli esempi seguenti per accedere singolarmente a ogni valore di ogni tipo di dati.
Nell'esempio seguente è possibile usare PySpark per eseguire un'aggregazione:
df.groupBy(df.item.string).sum().show()
Nell'esempio seguente è possibile usare PySQL per eseguire un'altra aggregazione:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Uso dello schema con fedeltà completa con SQL
Con gli stessi documenti dell'esempio di Spark precedente, è possibile usare l'esempio di sintassi seguente:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
È possibile implementare trasformazioni usando cast, convert o qualsiasi altra funzione T-SQL per modificare i dati. È anche possibile nascondere strutture di tipi di dati complesse usando le visualizzazioni.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Uso del campo _id MongoDB
Il campo _id MongoDB è fondamentale per ogni raccolta in MongoDB e in origine ha una rappresentazione esadecimale. Come si può notare nella tabella precedente, lo schema con fedeltà completa manterrà le sue caratteristiche, creando una sfida per la visualizzazione in Azure Synapse Analytics. Per una visualizzazione corretta, è necessario convertire il tipo di dati _id come indicato di seguito:
Uso del campo _id MongoDB in Spark
L'esempio seguente funziona nelle versioni di Spark 2.x e 3.x:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Uso del campo _id MongoDB in SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Uso del campo id MongoDB
La proprietà id nei contenitori MongoDB viene sovrascritta automaticamente con la rappresentazione Base64 della proprietà "_id" anche nell'archivio analitico. Il campo "id" è destinato all'uso interno delle applicazioni MongoDB. Attualmente l'unica soluzione alternativa consiste nel rinominare la proprietà "id" in un valore diverso da "id".
Schema di fedeltà completa per gli account NoSQL o Gremlin
È possibile usare lo schema di fedeltà completa per gli account NoSQL, anziché l'opzione predefinita, impostando il tipo di schema quando si abilita Collegamento a Synapse in un account Azure Cosmos DB per la prima volta. Ecco le considerazioni sulla modifica del tipo di rappresentazione dello schema predefinito:
- Attualmente, se si abilita Collegamento a Synapse nell'account API NoSQL usando il portale di Azure, verrà abilitato come schema ben definito.
- Attualmente, se si vuole usare lo schema di fedeltà completa con gli account API NoSQL o Gremlin, è necessario impostarlo a livello di account nello stesso comando dell'interfaccia della riga di comando o di PowerShell che abiliterà Collegamento a Synapse a livello di account.
- Attualmente Azure Cosmos DB per MongoDB non è compatibile con questa possibilità di modificare la rappresentazione dello schema. Tutti gli account MongoDB hanno un tipo di rappresentazione dello schema fedeltà completa.
- La mappa dei tipi di dati dello schema fedeltà completa menzionata in precedenza non è valida per gli account API NoSQL che usano tipi di dati JSON. Ad esempio,
floateintegeri valori sono rappresentati comenumnell'archivio analitico. - Non è possibile reimpostare il tipo di rappresentazione dello schema, da ben definito a fedeltà completa o viceversa.
- Attualmente, gli schemi dei contenitori nell'archivio analitico vengono definiti quando viene creato il contenitore, anche se nell'account del database Collegamento a Synapse non è stato abilitato.
- I contenitori o i grafici creati prima dell'abilitazione di Collegamento a Synapse con schema di fedeltà completa a livello di account avranno uno schema ben definito.
- I contenitori o i grafici creati dopo l'abilitazione di Collegamento a Synapse con schema di fedeltà completa a livello di account avranno uno schema di fedeltà totale.
La decisione del tipo di rappresentazione dello schema deve essere presa contemporaneamente all'abilitazione del collegamento a Synapse nell'account tramite l'interfaccia della riga di comando di Azure o PowerShell.
Con l'interfaccia della riga di comando di Azure:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Nota
Nel comando precedente sostituire create con update per gli account esistenti.
Con PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Nota
Nel comando precedente sostituire New-AzCosmosDBAccount con Update-AzCosmosDBAccount per gli account esistenti.
Durata (TTL) dei dati analitici
Il TTL analitico (ATTL) indica per quanto tempo i dati devono essere conservati nell'archivio analitico per un contenitore.
L'archivio analitico è abilitato quando ATTL è impostato con un valore diverso da NULL e 0. Quando è abilitato, le operazioni di inserimento, aggiornamento ed eliminazione dei dati operativi vengono sincronizzate automaticamente dall'archivio transazionale all'archivio analitico, indipendentemente dalla configurazione della durata dei dati transazionali (TTL). La conservazione di questi dati transazionali nell'archivio analitico può essere controllata a livello di contenitore dalla proprietà AnalyticalStoreTimeToLiveInSeconds.
Le possibili configurazioni ATTL sono:
Se il valore è impostato su
0: l'archivio analitico è disabilitato e non viene replicato alcun dato dall'archivio transazionale all'archivio analitico. Aprire un caso di supporto per disabilitare l'archivio analitico nei contenitori.Se il campo non è impostato, non accade nulla e il valore precedente viene mantenuto.
Se il valore è impostato su
-1: l'archivio analitico conserva tutti i dati cronologici, indipendentemente dalla conservazione dei dati nell'archivio transazionale. Questa impostazione indica che l'archivio analitico ha una conservazione infinita dei dati operativiSe il valore è impostato su un numero intero positivo
n: gli elementi scadranno dall'archivio analiticonsecondi dopo l'ora dell'ultima modifica nell'archivio transazionale. Questa impostazione può essere usata se si vuole conservare i dati operativi per un periodo di tempo limitato nell'archivio analitico, indipendentemente dalla conservazione dei dati nell'archivio transazionale
Alcune informazioni da considerare:
- Dopo aver abilitato l'archivio analitico con un valore ATTL, può essere aggiornato a un valore valido diverso in un secondo momento.
- Anche se è possibile impostare TTTL a livello di contenitore o di elemento, ATTL può essere impostato solo a livello di contenitore.
- È possibile ottenere un periodo di conservazione più lungo dei dati operativi nell'archivio analitico impostando ATTL >= TTTL a livello di contenitore.
- L'archivio analitico può essere creato per eseguire il mirroring dell'archivio transazionale impostando ATTL = TTTL.
- Se si dispone di ATTL più grande di TTTL, in un determinato momento si avranno dati esistenti solo nell'archivio analitico. Questi dati sono di sola lettura.
- Attualmente non vengono eliminati dati dall'archivio analitico. Se si imposta ATTL su un numero intero positivo, i dati non verranno inclusi nelle query e non verranno fatturati. Tuttavia, se si reimposta ATTL su
-1, tutti i dati verranno visualizzati di nuovo, e inizierà la fatturazione per tutto il volume di dati.
Come abilitare l'archivio analitico in un contenitore:
Dal portale di Azure, l'opzione ATTL, quando attivata, è impostata sul valore predefinito -1. È possibile modificare questo valore in "n" secondi passando alle impostazioni del contenitore in Esplora dati.
Da Azure Management SDK, Azure Cosmos DB SDK, PowerShell o l'interfaccia della riga di comando di Azure, l'opzione ATTL può essere abilitata impostandola su -1 o 'n' secondi.
Per altre informazioni, vedere come configurare la durata (TTL) dei dati analitici in un contenitore.
Analisi conveniente sui dati cronologici
La suddivisione in livelli dei dati si riferisce alla separazione dei dati tra le infrastrutture di archiviazione ottimizzate per diversi scenari. Migliorando in tal modo le prestazioni complessive e la convenienza dello stack di dati end-to-end. Con l'archivio analitico, Azure Cosmos DB supporta ora la suddivisione in livelli automatica dei dati dall'archivio transazionale all'archivio analitico con layout di dati diversi. Con l'archivio analitico ottimizzato in termini di costi di archiviazione rispetto all'archivio transazionale, consente di mantenere orizzonti molto più lunghi dei dati operativi per l'analisi cronologica.
Dopo aver abilitato l'archivio analitico, in base alle esigenze di conservazione dei dati dei carichi di lavoro transazionali, è possibile configurare la proprietà transactional TTL in modo che i record vengano eliminati automaticamente dall'archivio transazionale dopo un determinato periodo di tempo. Analogamente, analytical TTL consente di gestire il ciclo di vita dei dati conservati nell'archivio analitico, indipendentemente dall'archivio transazionale. Abilitando l'archivio analitico e configurando le proprietà transazionali e analitiche TTL, è possibile definire facilmente il livello e definire il periodo di conservazione dei dati per i due archivi.
Nota
Quando analytical TTL è impostato su un valore maggiore di transactional TTL, il contenitore avrà dati esistenti solo nell'archivio analitico. Questi dati sono di sola lettura e attualmente non è supportato il livello di documento TTL nell'archivio analitico. Se i dati del contenitore potrebbero richiedere un aggiornamento o un'eliminazione in un determinato momento in futuro, non usare analytical TTL più grande di transactional TTL. Questa funzionalità è consigliata per i dati che non richiederanno aggiornamenti o eliminazioni in futuro.
Nota
Se lo scenario non richiede eliminazioni fisiche, è possibile adottare un approccio logico di eliminazione/aggiornamento. Inserire nell'archivio transazionale un'altra versione dello stesso documento esistente solo nell'archivio analitico, ma richiede un'eliminazione/aggiornamento logico. Ad esempio, con un flag che indica che si tratta di un'eliminazione o di un aggiornamento di un documento scaduto. Entrambe le versioni dello stesso documento coesistono nell'archivio analitico e l'applicazione deve considerare solo l'ultima.
Resilienza
L'archivio analitico si basa su Archiviazione di Azure e offre la seguente protezione da errori fisici:
- Per impostazione predefinita, gli account di database di Azure Cosmos DB allocano l'archivio analitico negli account di archiviazione con ridondanza locale. L'archiviazione con ridondanza locale garantisce almeno il 99,999999999% (11 nove) di durabilità degli oggetti nell'arco di un anno specifico.
- Se un'area geografica dell'account di database è configurata per la ridondanza della zona, viene allocata negli account di archiviazione con ridondanza della zona. È possibile abilitare le zone di disponibilità in un'area dell'account del database Azure Cosmos DB per avere dati analitici di tale area archiviati nell'archiviazione con ridondanza della zona. L'archiviazione con ridondanza della zona offre durabilità per le risorse di archiviazione di almeno il 99,9999999999% (12 9) in un determinato anno.
Per altre informazioni sulla durabilità di Archiviazione di Azure, vedere questo collegamento.
salvataggio dei dati
Anche se l'archivio analitico ha una protezione predefinita contro gli errori fisici, il backup può essere necessario per eliminazioni accidentali o aggiornamenti nell'archivio transazionale. In questi casi, è possibile ripristinare un contenitore e usare il contenitore ripristinato per riempire nuovamente i dati nel contenitore originale o ricompilare completamente l'archivio analitico, se necessario.
Nota
Attualmente non viene eseguito il backup dell'archivio analitico, pertanto non può essere ripristinato. I criteri di backup non possono essere pianificati a tale scopo.
Collegamento a Synapse e archivio analitico, di conseguenza, presenta diversi livelli di compatibilità con le modalità di backup di Azure Cosmos DB:
- La modalità di backup periodica è completamente compatibile con Collegamento a Synapse e queste 2 funzionalità possono essere usate nello stesso account di database.
- Collegamento a Synapse per gli account di database che usano la modalità di backup continuo è disponibile a livello generale.
- La modalità di backup continua per gli account abilitati per Collegamento a Synapse, è in anteprima pubblica. Attualmente non è possibile eseguire la migrazione al backup continuo se il Collegamento ad Azure Synapse è stato disabilitato in una delle raccolte in un account Cosmos DB.
Criteri di backup
Esistono due possibili criteri di backup, e per comprendere come usarli sono molto importanti i dettagli seguenti sui backup di Azure Cosmos DB:
- Il contenitore originale viene ripristinato senza archivio analitico in entrambe le modalità di backup.
- Azure Cosmos DB non supporta la sovrascrittura dei contenitori da un ripristino.
Si vedrà ora come usare i backup e i ripristini dal punto di vista dell'archivio analitico.
Ripristino di un contenitore con TTTL >= ATTL
Quando transactional TTL è uguale o maggiore di analytical TTL, tutti i dati nell'archivio analitico sono ancora presenti nell'archivio transazionale. In caso di ripristino, sono disponibili due situazioni possibili:
- Usare il contenitore ripristinato come sostituzione del contenitore originale. Per ricompilare l'archivio analitico, è sufficiente abilitare Collegamento a Synapse a livello di account e contenitore.
- Usare il contenitore ripristinato come origine dati per riempire o aggiornare i dati nel contenitore originale. In questo caso, l'archivio analitico rifletterà automaticamente le operazioni sui dati.
Ripristino di un contenitore con TTTL < ATTL
Quando transactional TTL è minore di analytical TTL, alcuni dati esistono solo nell'archivio analitico e non si trovano nel contenitore ripristinato. Anche in questo caso, si hanno due possibili situazioni:
- Usare il contenitore ripristinato come sostituzione del contenitore originale. In questo caso, quando si abilita Collegamento a Synapse a livello di contenitore, solo i dati presenti nell'archivio transazionale verranno inclusi nel nuovo archivio analitico. Si noti tuttavia che l'archivio analitico del contenitore originale rimane disponibile per le query, purché il contenitore originale esista. È possibile modificare l'applicazione in modo da eseguire query su entrambi.
- Per usare il contenitore ripristinato come origine dati per riempire o aggiornare i dati nel contenitore originale:
- L'archivio analitico riflette automaticamente le operazioni sui dati presenti nell'archivio transazionale.
- Se si reinseriscono dati rimossi in precedenza dall'archivio transazionale a causa di
transactional TTL, questi dati verranno duplicati nell'archivio analitico.
Esempio:
- Il valore TTTL del contenitore
OnlineOrdersè impostato su un mese e l'impostazione ATTL per un anno. - Quando lo si ripristina su
OnlineOrdersNewe si attiva l'archivio analitico per ricompilarlo, saranno presenti solo un mese di dati nell'archivio transazionale e analitico. - Il contenitore
OnlineOrdersoriginale non viene eliminato e il relativo archivio analitico è ancora disponibile. - I nuovi dati vengono inseriti solo in
OnlineOrdersNew. - Le query analitiche eseguiranno un'operazione UNION ALL dagli archivi analitici mentre i dati originali sono ancora rilevanti.
Se si vuole eliminare il contenitore originale ma non si vogliono perdere i dati dell'archivio analitico, è possibile salvare in modo permanente l'archivio analitico del contenitore originale in un altro servizio dati di Azure. Synapse Analytics offre la possibilità di eseguire join tra i dati archiviati in posizioni diverse. Un esempio: una query di Synapse Analytics unisce i dati dell'archivio analitico con tabelle esterne che si trovano in Archiviazione BLOB di Azure, Azure Data Lake Store e così via.
È importante notare che i dati nell'archivio analitico hanno uno schema diverso da quello presente nell'archivio transazionale. Anche se è possibile generare snapshot dei dati dell'archivio analitico ed esportarli in qualsiasi servizio dati di Azure, senza costi di UR, non è possibile garantire l'uso di questo snapshot per eseguire il feed dell'archivio transazionale. Questo processo non è supportato.
Distribuzione globale
Se si ha un account Azure Cosmos DB distribuito a livello globale, un archivio analitico abilitato per un contenitore sarà disponibile in tutte le aree di tale account. Tutte le modifiche apportate ai dati operativi vengono replicate a livello globale in tutte le aree. È possibile eseguire efficacemente query analitiche sulla copia locale più vicina dei dati in Azure Cosmos DB.
Partizionamento
Il partizionamento dell'archivio analitico è completamente indipendente dal partizionamento nell'archivio transazionale. Per impostazione predefinita, i dati nell'archivio analitico non vengono partizionati. Se le query analitiche hanno filtri usati di frequente, è possibile partizionare in base a questi campi per migliorare le prestazioni delle query. Per altre informazioni, vedere Introduzione al partizionamento personalizzato e Come configurare il partizionamento personalizzato.
Sicurezza
Autenticazione con l'archivio analitico : i metodi di autenticazione supportati variano a seconda che le funzionalità di rete siano abilitate.
Autenticazione basata su chiave: questo scenario è supportato per tutti gli account in tutti gli scenari, inclusi quelli senza endpoint privati o reti virtuali abilitate.
Entità servizio o Identità gestita: l'uso di Entra ID o dell'autenticazione con identità gestita è supportato solo per gli account che non usano endpoint privati o abilitano l'accesso Vnet. Per usare questo tipo di autenticazione, gli utenti devono applicare il controllo degli accessi in base al ruolo del piano dati e creare un nuovo ruolo in sola lettura con queste azioni sui dati elencate di seguito.
- Aggiungi un MyAnalyticsReadOnlyRole personalizzato utilizzando PowerShell e associa le azioni RBAC "readMetadata" e "readAnalytics" al ruolo.
$resourceGroupName = "<myResourceGroup>" $accountName = "<myCosmosAccount>" New-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -Type CustomRole -RoleName 'MyAnalyticsReadOnlyRole' ` -DataAction @( ` 'Microsoft.DocumentDB/databaseAccounts/readMetadata', 'Microsoft.DocumentDB/databaseAccounts/readAnalytics' ) ` -AssignableScope "/"- Elencare le definizioni di ruolo per l'account per ottenere il nuovo ID definizione del ruolo.
$roleDefinitionId = Get-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName- Creare l'assegnazione di ruolo assegnando il nuovo ruolo all'entità MSI di Synapse.
$synapsePrincipalId = "<Synapse MSI Principal>" New-AzCosmosDBSqlRoleAssignment -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -RoleDefinitionId $readOnlyRoleDefinitionId ` -Scope "/" ` -PrincipalId $synapsePrincipalId
Isolamento rete usando endpoint privati: è possibile controllare l'accesso di rete ai dati negli archivi transazionali e analitici in modo indipendente. L'isolamento della rete viene eseguito usando endpoint privati gestiti separati per ogni archivio, all'interno di reti virtuali gestite nelle aree di lavoro di Azure Synapse. Per altre informazioni, vedere l'articolo su come Configurare gli endpoint privati per l'archivio analitico. Nota: per abilitare questa opzione è necessario usare l'autenticazione basata su chiave. Vedere la sezione precedente.
Crittografia dei dati inattivi : la crittografia dell'archivio analitico è abilitata per impostazione predefinita.
Crittografia dei dati con chiavi gestite dal cliente: è possibile crittografare facilmente i dati tra archivi transazionali e analitici usando le stesse chiavi gestite dal cliente in modo automatico e trasparente. Collegamento ad Azure Synapse supporta solo la configurazione delle chiavi gestite dal cliente usando l'identità gestita dell'account Azure Cosmos DB. È necessario configurare l'identità gestita dell'account nei criteri di accesso di Azure Key Vault prima di abilitare Collegamento ad Azure Synapse nell'account. Per altre informazioni, vedere come configurare le chiavi gestite dal cliente usando le identità gestite dell'account Azure Cosmos DB.
Nota
Se si modifica l'account del database da First Party a System o User Assigned Identy e si abilita Collegamento ad Azure Synapse nell'account del database, non sarà possibile tornare all'identità first party perché non è possibile disabilitare Collegamento a Synapse dall'account del database.
Supporto di più runtime di Azure Synapse Analytics
L'archivio analitico è ottimizzato per offrire scalabilità, elasticità e prestazioni per carichi di lavoro analitici senza alcuna dipendenza dai runtime di calcolo. La tecnologia di archiviazione è gestita automaticamente per ottimizzare i carichi di lavoro analitici senza interventi manuali.
È possibile eseguire simultaneamente query sui dati nell'archivio analitico di Azure Cosmos DB da diversi runtime di analisi supportati da Azure Synapse Analytics. Azure Synapse Analytics supporta Apache Spark e il pool SQL serverless con l'archivio analitico di Azure Cosmos DB.
Nota
È possibile leggere dall'archivio analitico solo con i runtime di Azure Synapse Analytics. È anche vero l'opposto, i runtime di Azure Synapse Analytics possono leggere solo dall'archivio analitico. Solo il processo di sincronizzazione automatica può modificare i dati nell'archivio analitico. È possibile scrivere nuovamente i dati nell'archivio transazionale di Azure Cosmos DB usando il pool di Spark di Azure Synapse Analytics usando l'SDK OLTP di Azure Cosmos DB predefinito.
Prezzi
L'archivio analitico segue un modello di prezzi a consumo in base al quale viene addebitato il costo:
Archiviazione: il volume dei dati conservati nell'archivio analitico ogni mese, inclusi i dati cronologici definiti dalla proprietà Analytical TTL.
Operazioni di scrittura analitica: sincronizzazione completamente gestita degli aggiornamenti dei dati operativi nell'archivio analitico dall'archivio transazionale (sincronizzazione automatica)
Operazioni di lettura analitica: le operazioni di lettura eseguite sull'archivio analitico dal pool Spark di Azure Synapse Analytics e dai tempi di esecuzione del pool SQL serverless.
Il prezzo dell'archivio analitico è separato dal modello di prezzi dell'archivio transazioni. Non esiste alcun concetto di UR con provisioning nell'archivio analitico. Per informazioni dettagliate sul modello di prezzi per l'archivio analitico, vedere la pagina dei prezzi di Azure Cosmos DB.
È possibile accedere ai dati nell'archivio di analisi solo tramite collegamento ad Azure Synapse, operazione eseguita nei runtime di Azure Synapse Analytics: pool di Azure Synapse Apache Spark e pool SQL serverless di Azure Synapse. Per informazioni dettagliate sul modello tariffario per accedere ai dati nell'archivio analitico, vedere la pagina dei prezzi di Azure Synapse Analytics.
Per ottenere una stima dei costi di alto livello per abilitare l'archivio analitico in un contenitore di Azure Cosmos DB, dal punto di vista dell'archivio analitico, è possibile usare Azure Cosmos DB Capacity Planner e ottenere una stima dei costi di archiviazione analitica e scrittura delle operazioni.
Le stime delle operazioni di lettura dell'archivio analitico non sono incluse nel calcolatore dei costi di Azure Cosmos DB perché sono una funzione del carico di lavoro analitico. Tuttavia, come stima generale, l'analisi di 1 TB di dati nell'archivio analitico comporta in genere 130.000 operazioni di lettura analitica e comporta un costo di $ 0,065. Ad esempio, se si usano pool SQL serverless di Azure Synapse per eseguire questa analisi di 1 TB, il costo sarà di $ 5,00 in base alla pagina dei prezzi di Azure Synapse Analytics. Il costo totale finale per questa analisi da 1 TB sarebbe di $ 5,065.
Mentre la stima precedente riguarda l'analisi di 1 TB di dati nell'archivio analitico, l'applicazione di filtri riduce il volume di dati analizzati e determina il numero esatto di operazioni di lettura analitica in base al modello di determinazione dei prezzi a consumo. Un modello di verifica relativo al carico di lavoro analitico fornisce una stima più approfondita delle operazioni di lettura analitica. Questa stima non include il costo di Azure Synapse Analytics.
Passaggi successivi
Per altre informazioni, vedere la documentazione seguente:
Vedere il modulo di training su come Progettare l'elaborazione transazionale e analitica ibrida con Azure Synapse Analytics
Introduzione a Collegamento ad Azure Synapse per Azure Cosmos DB
Domande frequenti su Collegamento ad Azure Synapse per Azure Cosmos DB
Casi d'uso di Collegamento ad Azure Synapse per Azure Cosmos DB