Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Si sta cercando una soluzione di database per scenari su larga scala con un contratto di servizio di disponibilità 99.999%, scalabilità automatica immediata e failover automatico in più aree? Prendere in considerazione Azure Cosmos DB per NoSQL.
Si vuole implementare un grafico OLAP (Online Analytical Processing) o eseguire la migrazione di un'applicazione Apache Gremlin esistente? Considera Graph in Microsoft Fabric.
Questo articolo fornisce consigli per l'uso di modelli di dati a grafo. Queste procedure consigliate sono fondamentali per garantire la scalabilità e le prestazioni di un sistema di database a grafo man mano che i dati evolvono. Un modello di dati efficiente è particolarmente importante per i grafici su larga scala.
Requisiti
Il processo descritto in questa guida è basato sui presupposti seguenti:
- Le entità nello spazio del problema sono identificate. Queste entità devono essere utilizzate in modo atomico per ogni richiesta. Questo significa che il sistema di database non è progettato per il recupero dei dati di una singola entità in più richieste di query.
- Sono disponibili informazioni sui requisiti di lettura e scrittura per il sistema di database. Questi requisiti suggeriscono le ottimizzazioni necessarie per il modello di dati a grafo.
- I principi dello standard del grafo delle proprietà di Apache sono ben comprensibili.
Quando è necessario un database a grafo?
Una soluzione di database a grafo può essere usata in modo ottimale se le entità e le relazioni in un dominio dati hanno una delle caratteristiche seguenti:
- Le entità sono altamente connesse tramite relazioni descrittive. Il vantaggio di questo scenario è che le relazioni vengono mantenute nell'archiviazione.
- Sono presenti relazioni cicliche o entità che fanno riferimento a se stesse. Questo modello è spesso un problema quando si usano database relazionali o di documenti.
- Sono presenti relazioni a evoluzione dinamica tra le entità. Questo criterio è applicabile soprattutto a dati gerarchici o con struttura ad albero con numerosi livelli.
- Sono presenti relazioni molti-a-molti tra le entità.
- Sono presenti requisiti di scrittura e lettura per entità e relazioni.
Se i criteri precedenti sono soddisfatti, un approccio al database a grafo offre probabilmente vantaggi per la complessità delle query, la scalabilità del modello di dati e le prestazioni delle query.
Il passaggio successivo consiste nel determinare se il grafo verrà usato per scopi analitici o transazionali. Se il grafo è destinato a essere usato per carichi di lavoro di calcolo ed elaborazione dati pesanti, vale la pena esplorare il connettore Spark di Cosmos DB e la libreria GraphX.
Come usare gli oggetti del grafo
Lo standard del grafo delle proprietà di Apache definisce due tipi di oggetti: vertici e bordi.
Di seguito sono riportate le procedure consigliate per le proprietà negli oggetti grafo:
| Oggetto | Proprietà | Type | Note |
|---|---|---|---|
| Vertici | ID | string | Imposto in modo univoco per partizione. Se non viene specificato un valore al momento dell'inserimento, viene archiviato un GUID generato automaticamente. |
| Vertici | Etichetta | string | Questa proprietà viene usata per definire il tipo di entità rappresentata dal vertice. Se non viene specificato un valore, viene usato un vertice con un valore predefinito. |
| Vertici | Proprietà | Stringa, booleano, numerico | Elenco di proprietà separate archiviate come coppie chiave-valore in ogni vertice. |
| Vertici | Chiave di partizione | Stringa, booleano, numerico | Questa proprietà definisce dove vengono archiviati il vertice e i relativi bordi in uscita. Per altre informazioni, vedere l'articolo sul partizionamento di grafi. |
| Bordi | ID | string | Imposto in modo univoco per partizione. Generato automaticamente per impostazione predefinita. I bordi in genere non devono essere recuperati in modo univoco tramite un ID. |
| Bordi | Etichetta | string | Questa proprietà viene usata per definire il tipo di relazione tra due vertici. |
| Bordi | Proprietà | Stringa, booleano, numerico | Elenco di proprietà separate archiviate come coppie chiave-valore in ogni arco. |
Note
I bordi non richiedono un valore per la chiave di partizione, poiché il valore viene assegnato automaticamente in base al vertice di origine. Per altre informazioni, vedere Usare un grafo partizionato in Azure Cosmos DB.
Linee guida per la modellazione di entità e relazioni
Le linee guida seguenti consentono di acquisire familiarità con la modellazione dei dati per un database a grafo di Azure Cosmos DB per Apache Gremlin. Queste linee guida presuppongono l'esistenza di una definizione di un dominio di dati e di query per tale dominio.
Note
I passaggi seguenti vengono presentati come raccomandazioni. È necessario valutare e testare il modello finale prima di considerarlo come pronto per la produzione. Inoltre, le raccomandazioni sono specifiche per l'implementazione dell'API Gremlin di Azure Cosmos DB.
Modellazione di vertici e proprietà
Il primo passaggio per la creazione di un modello di dati del grafo consiste nell'eseguire il mapping di ogni entità identificata a un oggetto vertice. Un mapping uno-a-uno di tutte le entità ai vertici deve essere un passaggio iniziale e soggetto a modifiche.
Un errore comune consiste nell'eseguire il mapping delle proprietà di una singola entità come vertici separati. Si consideri l'esempio seguente, in cui la stessa entità è rappresentata in due modi diversi:
Proprietà basate su vertici: in questo approccio l'entità usa tre vertici separati e due archi per descrivere le relative proprietà. Pur riducendo la ridondanza, questo approccio implica un incremento della complessità del modello e di conseguenza una maggiore latenza, una maggiore complessità delle query e un aumento del costo di calcolo. Questo modello può anche presentare problemi relativi al partizionamento.
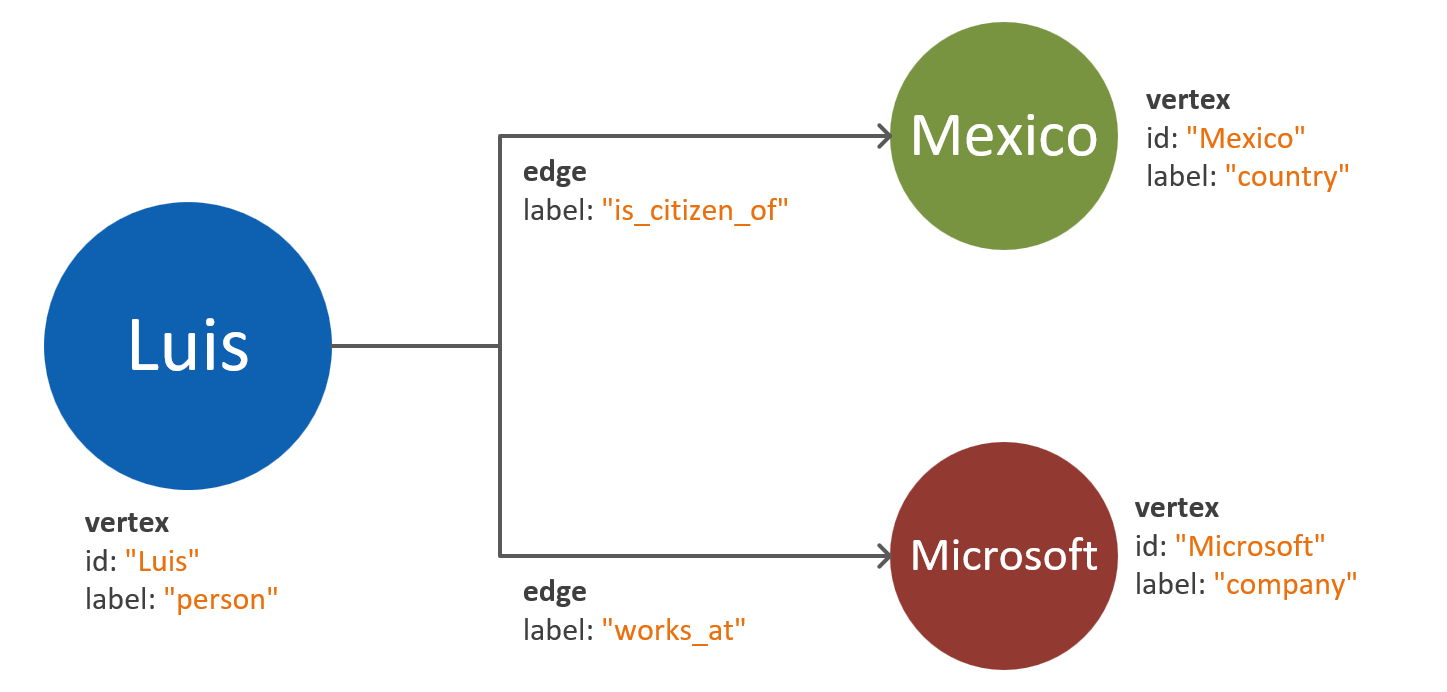
Vertici incorporati nelle proprietà: questo approccio sfrutta i vantaggi dell'elenco di coppie chiave-valore per rappresentare tutte le proprietà dell'entità all'interno di un vertice. Questo approccio riduce la complessità del modello, il che comporta query più semplici e attraversamenti grafico più convenienti.

Note
I diagrammi precedenti mostrano un modello di grafo semplificato che mette a confronto solo i due modi per dividere le proprietà dell'entità.
Il criterio basato su vertici incorporati nelle proprietà offre in genere un approccio più scalabile ed efficiente in termini di prestazioni. L'approccio predefinito a un nuovo modello di dati a grafo deve tendere verso questo modello.
Tuttavia, esistono scenari in cui il riferimento a una proprietà può offrire vantaggi. Ad esempio, se la proprietà a cui viene fatto riferimento viene aggiornata di frequente. Usare un vertice separato per rappresentare una proprietà che cambia costantemente per ridurre al minimo la quantità di operazioni di scrittura richieste dall'aggiornamento.
Modelli di relazione con indicazioni perimetrali
Dopo aver modellato i vertici è possibile aggiungere gli archi per denotare le relazioni tra loro. Il primo aspetto da valutare è la direzione della relazione.
I bordi hanno una direzione predefinita seguita da un attraversamento grafico quando si usano le funzioni out() o outE(). Questa direzione naturale rende l'operazione efficiente, poiché tutti i vertici vengono archiviati con i bordi in uscita.
L'attraversamento grafico nella direzione opposta di un bordo, tramite la funzione in(), comporta sempre una query tra partizioni. Per altre informazioni, vedere l'articolo sul partizionamento di grafi. Se è necessario un attraversamento grafico frequente con la funzione in(), aggiungere bordi in entrambe le direzioni.
È possibile determinare la direzione del bordo usando i predicati .to() o .from() con il passaggio Gremlin .addE(). In alternativa, è possibile usare la libreria dell'executor bulk per l'API Gremlin.
Note
Per impostazione predefinita, i bordi hanno una direzione.
Etichette delle relazioni
L'uso di etichette di relazione descrittive consente di migliorare l'efficienza delle operazioni di risoluzione degli archi. È possibile applicare il criterio nei modi seguenti:
- Usare termini non generici per etichettare una relazione.
- Associare l'etichetta del vertice di origine per l'etichetta del vertice di destinazione con il nome della relazione.
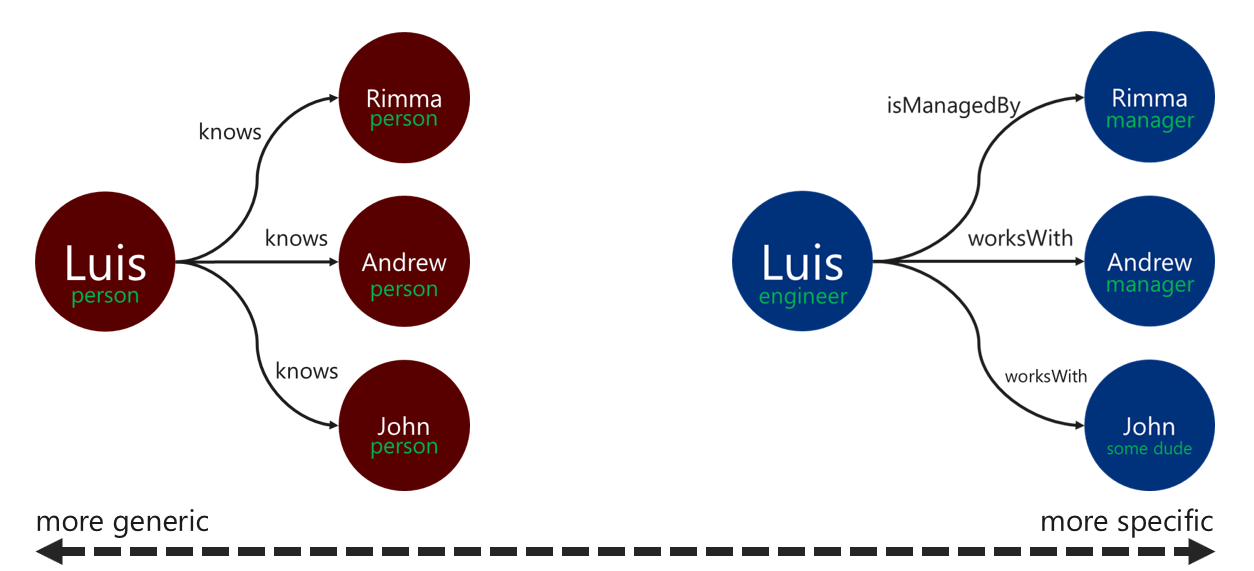
Più è specifica l'etichetta usata dall'attraversamento grafo e meglio vengono filtrati i bordi. Questa decisione può avere un effetto significativo anche sui costi delle query. È possibile valutare il costo della query in qualsiasi momento usando il passaggio executionProfile.