Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: ![]() MongoDB
MongoDB
Questa guida alla migrazione fa parte della serie sulla migrazione di database da MongoDB all'API di Azure Cosmos DB for MongoDB. I passaggi critici per la migrazione sono pre-migrazione, migrazione e post-migrazione, come illustrato di seguito.

Migrazione dei dati con Azure Databricks
Azure Databricks è un'offerta platform as a service (PaaS) per Apache Spark. Offre una soluzione per eseguire migrazioni offline in un set di dati su larga scala. È possibile usare Azure Databricks per eseguire una migrazione offline dei database da MongoDB ad Azure Cosmos DB for MongoDB.
La presente esercitazione include informazioni su come:
Effettuare il provisioning di un cluster di Azure Databricks
Aggiungere le dipendenze
Creare ed eseguire notebook Scala o Python
Ottimizzare le prestazioni della migrazione
Risolvere gli errori di limitazione della frequenza che possono essere osservati durante la migrazione
Prerequisiti
Per completare questa esercitazione, è necessario:
- Completare i processi di pre-migrazione, ad esempio stimare la velocità effettiva e scegliere una chiave di partizione.
- Creare un account Azure Cosmos DB for MongoDB.
Effettuare il provisioning di un cluster di Azure Databricks
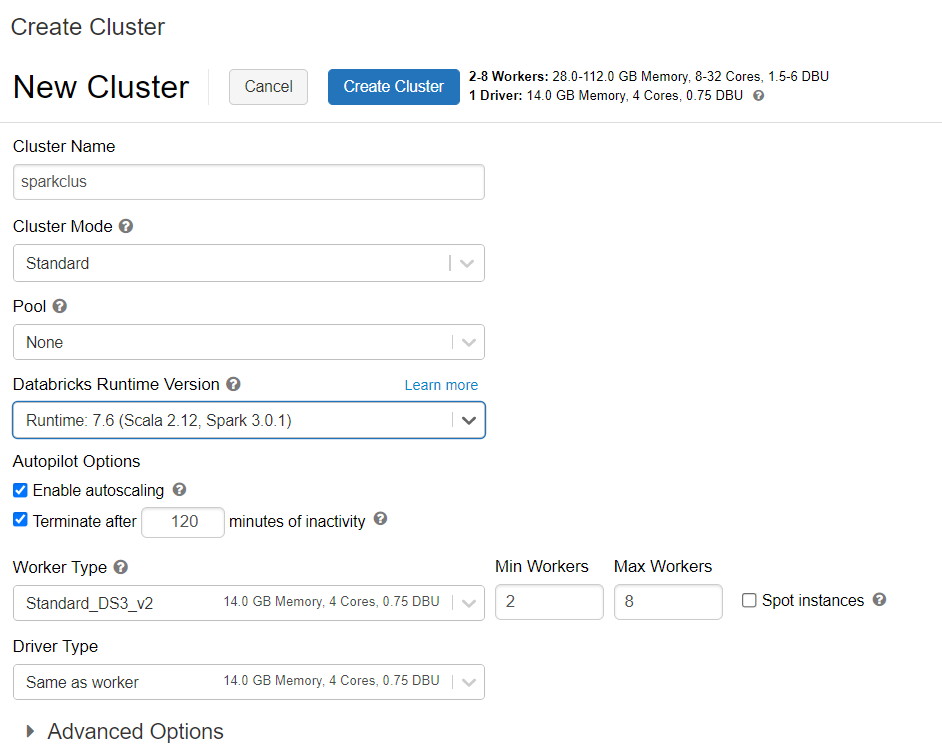
È possibile seguire le istruzioni per effettuare il provisioning di un cluster di Azure Databricks. È consigliabile selezionare Databricks runtime versione 7.6, che supporta Spark 3.0.
Aggiungere le dipendenze
Aggiungere il connettore MongoDB per la libreria Spark al cluster per connettersi agli endpoint di MongoDB nativo e di Azure Cosmos DB for MongoDB. Nel cluster selezionare Librerie>Installa nuova>Maven e quindi aggiungere le coordinate Maven org.mongodb.spark:mongo-spark-connector_2.12:3.0.1.
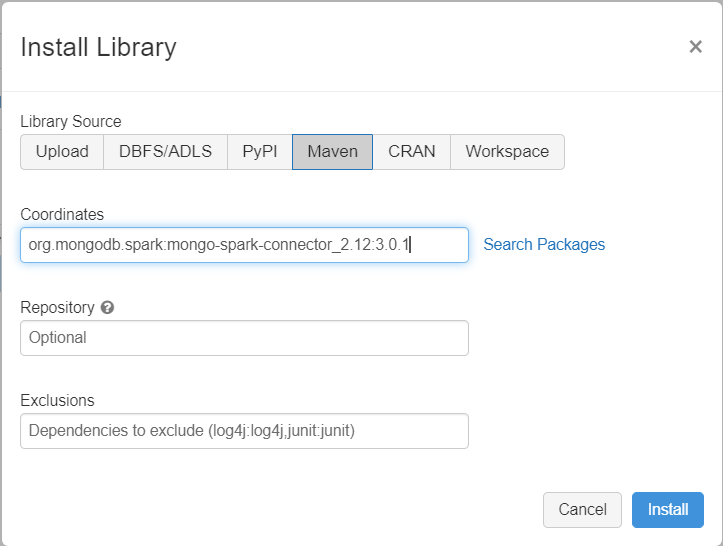
Selezionare Installa e quindi riavviare il cluster al termine dell'installazione.
Nota
Assicurarsi di riavviare il cluster Databricks dopo l'installazione del connettore MongoDB per la libreria Spark.
A questo punto, è possibile creare un notebook Scala o Python per la migrazione.
Creare un notebook Scala per la migrazione
Creare un notebook Scala in Databricks. Assicurarsi di immettere i valori corretti per le variabili prima di eseguire il codice seguente:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Creare un notebook Python per la migrazione
Creare un notebook Python in Databricks. Assicurarsi di immettere i valori corretti per le variabili prima di eseguire il codice seguente:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Ottimizzare le prestazioni della migrazione
Le prestazioni della migrazione possono essere modificate tramite queste configurazioni:
Numero di ruoli di lavoro e core nel cluster Spark: più ruoli di lavoro si traducono in più partizioni di calcolo per l'esecuzione di attività.
maxBatchSize: il valore
maxBatchSizecontrolla la frequenza con cui i dati vengono salvati nella raccolta di Azure Cosmos DB di destinazione. Tuttavia, se il valore di maxBatchSize è troppo elevato per la velocità effettiva della raccolta, possono verificarsi errori di limitazione della frequenza.È necessario modificare il numero di ruoli di lavoro e maxBatchSize, a seconda del numero di executor nel cluster Spark, potenzialmente delle dimensioni (ed è questo il motivo del costo delle UR) di ogni documento scritto e dei limiti di velocità effettiva della raccolta di destinazione.
Suggerimento
maxBatchSize = Velocità effettiva della raccolta/ ( Costo UR per 1 documento * numero di ruoli di lavoro Spark * numero di core della CPU per ruolo di lavoro)
partitioner e partitionKey Spark per MongoDB: il partitioner predefinito usato è MongoDefaultPartitioner e il valore predefinito di partitionKey è _id. È possibile modificare il partitioner assegnando il valore
MongoSamplePartitioneralla proprietà di configurazione di inputspark.mongodb.input.partitioner. Analogamente, partitionKey può essere modificato assegnando il nome del campo appropriato alla proprietà di configurazione di inputspark.mongodb.input.partitioner.partitionKey. Il valore corretto di partitionKey consente di evitare l'asimmetria dei dati (numero elevato di record scritti per lo stesso valore della chiave di partizione).Disabilitare gli indici durante il trasferimento dei dati: per la migrazione di grandi quantità di dati è consigliabile disabilitare gli indici, in particolare l'indice con caratteri jolly nella raccolta di destinazione. Gli indici aumentano il costo delle UR per la scrittura di ogni documento. Eliminando queste UR è possibile contribuire a migliorare la velocità di trasferimento dei dati. Gli indici possono poi essere abilitati dopo la migrazione dei dati.
Risoluzione dei problemi
Errore di timeout (codice errore 50)
È possibile che venga visualizzato un codice errore 50 per le operazioni sul database Azure Cosmos DB for MongoDB. Gli scenari seguenti possono causare errori di timeout:
- La velocità effettiva allocata al database è bassa: assicurarsi che alla raccolta di destinazione sia assegnata una velocità effettiva sufficiente.
- Eccessiva asimmetria dei dati con un elevato volumi di dati. Se si ha una grande quantità di dati di cui eseguire la migrazione in una determinata tabella, ma è presente un'asimmetria significativa nei dati, è possibile che si verifichino limitazioni della frequenza anche se sono presenti diverse unità richiesta di cui è stato effettuato il provisioning nella tabella. Le unità richiesta sono divise equamente tra le partizioni fisiche e una forte asimmetria dei dati può causare un collo di bottiglia delle richieste a una singola partizione. L'asimmetria dei dati implica un numero elevato di record per lo stesso valore della chiave di partizione.
Limitazione della frequenza (codice errore 16500)
È possibile che venga visualizzato un codice errore 16500 per le operazioni sul database Azure Cosmos DB for MongoDB. Si tratta di errori di limitazione della frequenza e possono essere osservati su account meno recenti o su account in cui la funzionalità di ripetizione dei tentativi sul lato server è disabilitata.
- Abilitare la ripetizione dei tentativi sul lato server: abilitare la funzionalità Server Side Retry (SSR) e consentire al server di ripetere automaticamente le operazioni con frequenza limitata.
Ottimizzazione della post-migrazione
Dopo aver eseguito la migrazione dei dati, è possibile connettersi ad Azure Cosmos DB e gestire i dati. È anche possibile seguire altri passaggi post-migrazione, ad esempio l'ottimizzazione dei criteri di indicizzazione, l'aggiornamento del livello di coerenza predefinito o la configurazione della distribuzione globale per l'account Azure Cosmos DB. Per altre informazioni, vedere l'articolo Ottimizzazione della post-migrazione.
Risorse aggiuntive
- Si sta tentando di pianificare la capacità per una migrazione ad Azure Cosmos DB?
- Se si conosce solo il numero di vcore e server nel cluster di database esistente, leggere le informazioni sulla stima delle unità richieste usando vCore o vCPU
- Se si conosce la frequenza delle richieste tipiche per il carico di lavoro corrente del database, leggere le informazioni sulla stima delle unità richieste con lo strumento di pianificazione della capacità di Azure Cosmos DB