Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: ![]() NoSQL
NoSQL
Questo articolo si basa su alcuni concetti di Azure Cosmos DB, ad esempio la modellazione di dati, il partizionamento e la velocità effettiva con provisioning, per illustrare come affrontare un esercizio di progettazione dei dati reali.
Se in genere si lavora con i database relazionali, saranno già state implementate abitudini e intuizioni su come progettare un modello di dati. A causa dei vincoli specifici, ma anche grazie ai punti di forza di Azure Cosmos DB, la maggior parte di queste procedure consigliate non produce il risultato auspicato e può condurre a soluzioni meno che ottimali. L'obiettivo di questo articolo è guidare l'utente attraverso il processo completo di un caso di utilizzo reale di modellazione in Azure Cosmos DB, dalla modellazione degli elementi alla condivisione del percorso delle entità e al partizionamento del contenitore.
Scaricare o visualizzare un codice sorgente generato dalla community che illustra i concetti presenti in questo articolo.
Importante
Un collaboratore della community ha contribuito a questo esempio di codice e il team di Azure Cosmos DB non supporta la manutenzione.
Scenario
Per questo esercizio, si prenderà in considerazione il dominio di una piattaforma di blog in cui gli utenti possono scrivere dei post. a cui possono anche aggiungere Mi piace e commenti.
Suggerimento
Sono evidenziate in corsivo alcune parole che identificano il tipo di elementi che il modello dovrà modificare.
Sono necessari altri requisiti oltre alle specifiche iniziali:
- Una pagina iniziale in cui sia visualizzato un feed dei post creati di recente
- La possibilità di recuperare tutti i post di un utente, tutti i commenti per un post e tutti i Mi piace per un post
- I post vengono restituiti con il nome utente dei rispettivi autori e il numero di commenti e Mi piace ricevuti
- Anche i commenti e i Mi piace vengono restituiti con il nome utente degli autori
- Quando visualizzati sotto forma di elenchi, i post devono presentare solo un riepilogo troncato del relativo contenuto
Identificare i modelli di accesso principali
Per iniziare, si strutturerà la specifica iniziale identificando i modelli di accesso della soluzione. Quando si progetta un modello di dati per Azure Cosmos DB, è importante comprendere a quali richieste il modello dovrà rispondere per assicurarsi che le gestisca in modo efficiente.
Per semplificare il processo complessivo da seguire, le diverse richieste vengono classificate come comandi o query, prendendo in prestito un vocabolario da CQRS. In CQRS i comandi sono richieste di scrittura (ovvero le finalità di aggiornare il sistema) e le query sono richieste di sola lettura.
Ecco l'elenco delle richieste esposte dalla piattaforma:
- [C1] Creare/modificare un utente
- [Q1] Recuperare un utente
- [C2] Creare/modificare un post
- [Q2] Recuperare un post
- [Q3] Elencare i post di un utente in forma breve
- [C3] Creare un commento
- [Q4] Elencare i commenti a un post
- [C4] Aggiungere Mi piace a un post
- [Q5] Elencare i Mi piace ricevuti da un post
- [Q6] Elencare i x post più recenti in forma breve (feed)
In questa fase, non sono ancora stati considerati i dettagli sul contenuto di ciascuna entità (utente, post, ecc.). Questo passaggio è in genere tra i primi a essere affrontati durante la progettazione in un archivio relazionale. Si inizia con questo passaggio perché è necessario capire come queste entità si traducono in termini di tabelle, colonne, chiavi esterne e così via. È molto meno rilevante per un database di documenti che non applica alcun schema in fase di scrittura.
Il motivo principale per cui è importante identificare i modelli di accesso sin dall'inizio è che questo elenco di richieste diventerà il gruppo di test. Ogni volta che si esegue l'iterazione del modello di dati, si verificheranno le prestazioni e la scalabilità di ciascuna richiesta. Le unità richiesta utilizzate in ogni modello vengono calcolate e quindi ottimizzate. Tutti questi modelli usano i criteri di indicizzazione predefiniti ed è possibile eseguirne l'override tramite l'indicizzazione di proprietà specifiche, che possono migliorare ulteriormente il consumo e la latenza delle UR.
V1: una prima versione
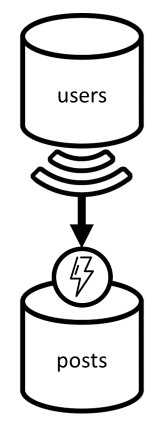
Si inizia con due contenitori: users e posts.
Contenitore utenti
In questo contenitore vengono archiviati solo gli elementi utente:
{
"id": "<user-id>",
"username": "<username>"
}
Il contenitore viene partizionato in base a id, cioè ogni partizione logica al suo interno contiene un solo elemento.
Contenitore post
Questo contenitore ospita entità come post, commenti e like:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Il contenitore viene partizionato in base a postId, cioè ogni partizione logica al suo interno contiene un solo post, tutti i commenti per tale post e tutti i Mi piace per tale post.
È stata introdotta una proprietà type negli elementi archiviati in questo contenitore per distinguere tra i tre tipi di entità in esso ospitati.
Si è anche scelto di fare riferimento ai dati correlati invece di incorporarli (per informazioni dettagliate su questi concetti, consultare questa sezione), per i seguenti motivi:
- non vi è alcun limite al numero di post che un utente può creare
- la lunghezza dei post può essere arbitraria
- non vi è alcun limite al numero di commenti e Mi piace che un post può ricevere
- si vuole avere la possibilità di aggiungere un commento o un Mi piace a un post senza dover aggiornare il post stesso
Valutare le prestazioni del modello
A questo punto verranno valutate le prestazioni e la scalabilità della prima versione. Per ognuna delle richieste identificate in precedenza, vengono misurati la latenza e il numero di unità richiesta che utilizza. Questa misurazione viene eseguita in un set di dati fittizio contenente 100.000 utenti, ciascuno con un numero di post da 5 a 50, e con un massimo di 25 commenti e 100 Mi piace per ogni post.
[C1] Creare/modificare un utente
Questa richiesta è semplice da implementare in quanto è sufficiente creare o aggiornare un elemento nel contenitore users. Le richieste si suddividono perfettamente in tutte le partizioni grazie alla chiave di partizione id.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
7 ms |
5.71 RU |
✅ |
[Q1] Recuperare un utente
Per recuperare un utente si legge l'elemento corrispondente dal contenitore users.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
2 ms |
1 RU |
✅ |
[C2] Creare/modificare un post
Analogamente a [C1], occorre solo scrivere nel contenitore posts.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
9 ms |
8.76 RU |
✅ |
[Q2] Recuperare un post
Si inizia con il recupero del documento corrispondente dal contenitore posts. Questo non è però sufficiente, in base alla specifica dobbiamo anche aggregare il nome utente dell'autore del post, il numero di commenti e i conteggi dei like per il post. Le aggregazioni elencate richiedono l'esecuzione di altre 3 query SQL.
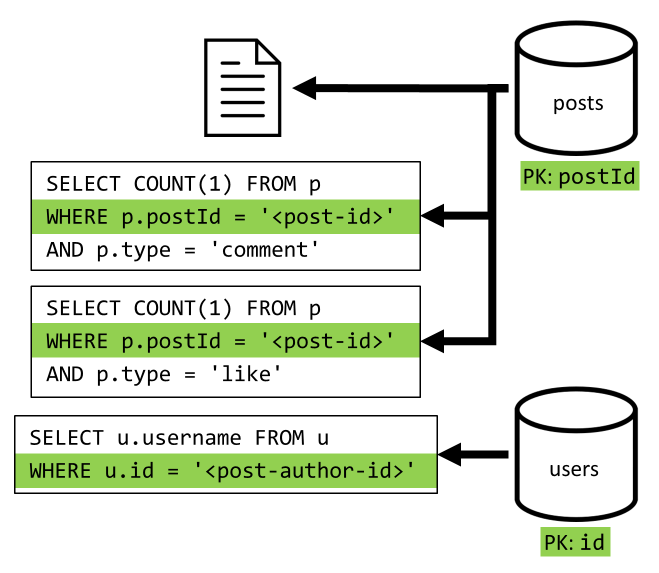
Ognuna delle query aggiuntive filtra la chiave di partizione del rispettivo contenitore, che è proprio ciò che si vuole ottenere per ottimizzare le prestazioni e la scalabilità. Tuttavia, alla fine sarà necessario eseguire quattro operazioni per restituire un singolo post, perciò si procederà a migliorarlo nella prossima iterazione.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
9 ms |
19.54 RU |
⚠ |
[Q3] Elencare i post di un utente in forma breve
In primo luogo, è necessario recuperare i post desiderati con una query SQL che recupera i post corrispondenti a tale utente specifico. Ma è anche necessario eseguire query aggiuntive per aggregare il nome utente dell'autore e i numeri di commenti e Mi piace.
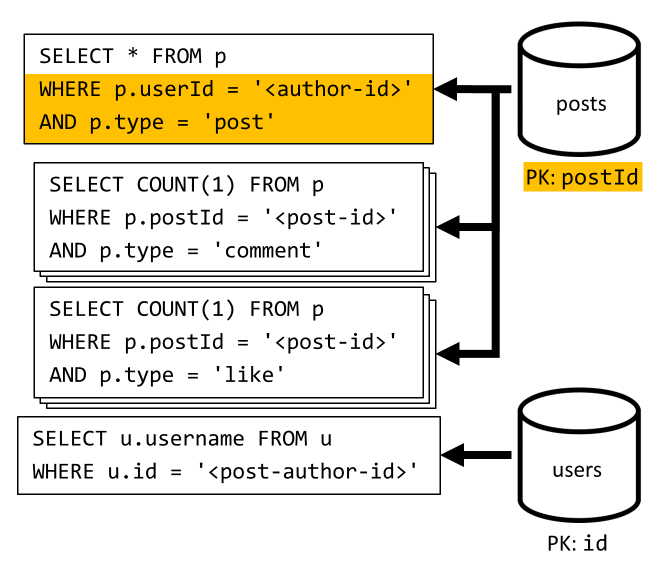
Questa implementazione presenta numerosi svantaggi:
- è necessario eseguire le query che aggregano i numeri di commenti e Mi piace per ogni post restituito dalla prima query
- la query principale non filtra la chiave di partizione del contenitore
posts, causando un fan-out e un'analisi della partizione nell'intero contenitore.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
130 ms |
619.41 RU |
⚠ |
[C3] Creare un commento
Per creare un commento basta scrivere l'elemento corrispondente nel contenitore posts.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
7 ms |
8.57 RU |
✅ |
[Q4] Elencare i commenti a un post
Per iniziare, si esegue una query che recupera tutti i commenti per tale post e, anche in questo caso, è necessario aggregare i nomi utente separatamente per ogni commento.
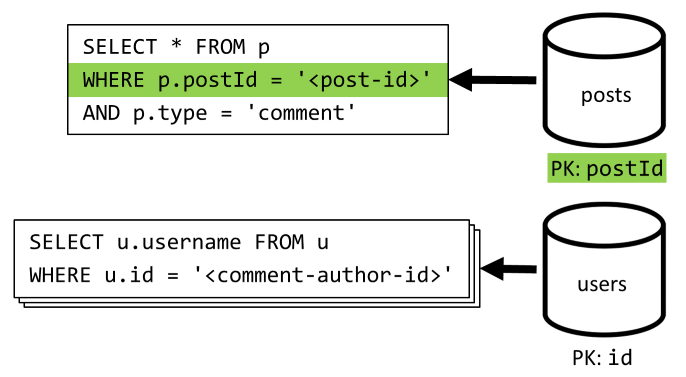
Anche se la query principale filtra la chiave di partizione del contenitore, aggregare separatamente i nomi utente penalizza le prestazioni complessive. Sarà possibile migliorarle in un secondo momento.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
23 ms |
27.72 RU |
⚠ |
[C4] Aggiungere Mi piace a un post
Come per [C3], basta scrivere l'elemento corrispondente nel contenitore posts.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
6 ms |
7.05 RU |
✅ |
[Q5] Elencare i Mi piace ricevuti da un post
Analogamente a [Q4], si esegue una query per i Mi piace ricevuti da tale post, quindi si aggregano i relativi nomi utente.
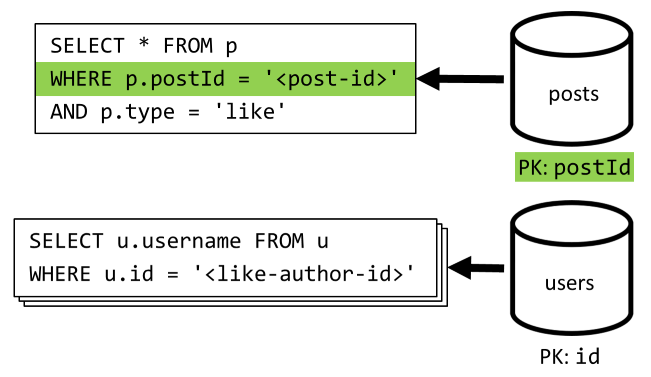
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
59 ms |
58.92 RU |
⚠ |
[Q6] Elencare i x post più recenti in forma breve (feed)
Si recuperano i post più recenti eseguendo la query del contenitore posts per data di creazione decrescente, quindi si aggregano i nomi utente e il numero di commenti e Mi piace per ciascuno dei post.
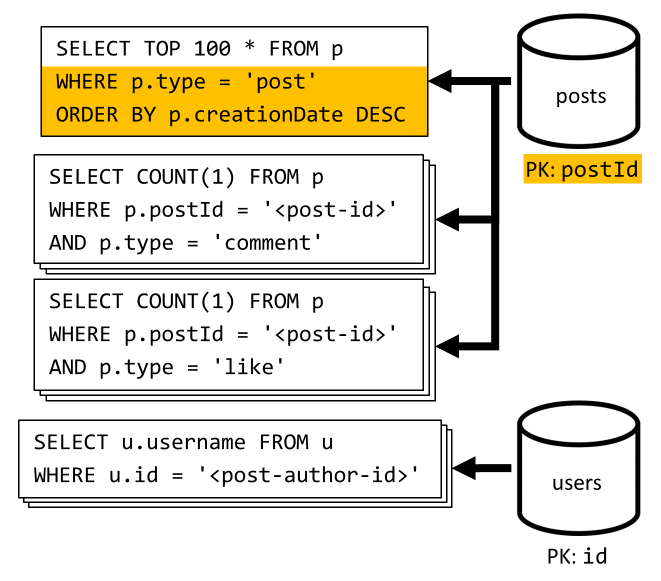
Anche in questo caso, la query iniziale non filtra la chiave di partizione del contenitore posts, che attiva un fan-out dispendioso. Questa situazione è persino peggiore, perché l'obiettivo è un set di risultati più grande e i risultati vengono ordinati con una clausola ORDER BY, che lo rende più dispendioso in termini di unità richiesta.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
306 ms |
2063.54 RU |
⚠ |
Riflessioni sulle prestazioni della V1
Esaminando i problemi di prestazioni affrontati nella sezione precedente, è possibile identificare due classi principali dei problemi:
- alcune richieste richiedono l'esecuzione di più query per raccogliere tutti i dati che dovranno essere restituiti
- alcune query non filtrano la chiave di partizione dei contenitori di destinazione, determinando un fan-out che ostacola la scalabilità.
È possibile risolvere ognuno di questi problemi, a partire dal primo.
V2: introduzione della denormalizzazione per ottimizzare le query di lettura
Il motivo per cui in alcuni casi è necessario eseguire altre richieste è che i risultati della richiesta iniziale non contengono tutti i dati che devono essere restituiti. La denormalizzazione dei dati risolve questo tipo di problema nel set di dati quando si usa un archivio dati non relazionale come Azure Cosmos DB.
In questo esempio, si modificano i post aggiungendo il nome utente del relativo autore, il numero di commenti e il numero di Mi piace:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Si modificano anche i commenti e i Mi piace aggiungendo il nome utente del relativo autore:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Denormalizzazione del numero di commenti e Mi piace
L'obiettivo in questo caso è incrementare il commentCount o il likeCount nel post corrispondente ogni volta che si aggiunge un commento o un Mi piace. Dal momento che postId partiziona il contenitore posts, il nuovo elemento (commento o Mi piace) e il post corrispondente si trovano nella medesima partizione logica. Di conseguenza, è possibile usare una stored procedure per eseguire tale operazione.
Quando si crea un commento ([C3]), anziché aggiungere un nuovo elemento nel contenitore posts viene chiamata la stored procedure seguente in tale contenitore:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Questa stored procedure accetta l'ID del post e il corpo del nuovo commento come parametri, quindi:
- recupera il post
- incrementa il
commentCount - sostituisce il post
- aggiunge il nuovo commento
Dal momento che le stored procedure vengono eseguite come transazioni atomiche, il valore del commentCount e il numero effettivo di commenti saranno sempre sincronizzati.
Ovviamente si chiama una stored procedure simile quando si aggiungono nuovi Mi piace per incrementare il likeCount.
Denormalizzazione dei nomi utente
I nomi utente richiedono un approccio diverso in quanto gli utenti non solo si trovano in partizioni diverse, ma anche in un contenitore diverso. Quando è necessario denormalizzare i dati nelle partizioni e i contenitori, è possibile usare il feed di modifiche del contenitore di origine.
In questo esempio, si usa il feed delle modifiche del contenitore users per reagire ogni volta che gli utenti aggiornano i propri nomi utente. In questo caso, si propaga la modifica chiamando un'altra stored procedure sul contenitore posts:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Questa stored procedure accetta l'ID dell'utente e il nuovo nome utente come parametri, quindi:
- recupera tutti gli elementi corrispondenti all'
userId(che possono essere post, commenti, o Mi piace) - per ognuno di questi elementi
- sostituisce il
userUsername - sostituisce l'elemento
- sostituisce il
Importante
Questa operazione è dispendiosa perché richiede l'esecuzione di questa stored procedure in ogni partizione del contenitore posts. È molto probabile che la maggior parte degli utenti sceglierà un nome utente appropriato durante l'iscrizione e non lo modificherà mai, dunque questo aggiornamento verrà eseguito molto raramente.
Quali sono i miglioramenti delle prestazioni offerti dalla V2?
Verranno ora illustrati alcuni dei miglioramenti delle prestazioni della versione 2.
[Q2] Recuperare un post
Ora che la denormalizzazione è stata applicata, è necessario solo recuperare un singolo elemento per gestire tale richiesta.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
2 ms |
1 RU |
✅ |
[Q4] Elencare i commenti a un post
Anche in questo caso, è possibile fare a meno delle richieste aggiuntive che recuperavano i nomi utente e terminare con una singola query che filtra la chiave di partizione.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
4 ms |
7.72 RU |
✅ |
[Q5] Elencare i Mi piace ricevuti da un post
La stessa esatta situazione di quando si elencano i Mi piace.
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
4 ms |
8.92 RU |
✅ |
V3: assicurarsi che tutte le richieste siano scalabili
Esistono ancora due richieste che non sono state completamente ottimizzate quando si esaminano i miglioramenti generali delle prestazioni. Queste richieste vengono [Q3] e [Q6]. Si tratta di richieste che prevedono query che non filtrano la chiave di partizione dei contenitori di destinazione.
[Q3] Elencare i post di un utente in forma breve
Questa richiesta trae già vantaggio dai miglioramenti introdotti nella V2, permettendo di evitare altre query.

Tuttavia, la query rimanente continua a non filtrare la chiave di partizione del contenitore posts.
Il modo di pensare a questa situazione è semplice:
- Questa richiesta deve filtrare l'
userIdperché occorre recuperare tutti i post di un determinato utente. - Non si ottiene il risultato previsto perché viene eseguita sul contenitore
posts, che non è partizionato in base auserId. - Ovviamente, il problema di prestazioni potrebbe essere risolto eseguendo questa richiesta su un contenitore che partizionato con
userId. - In questo caso, si tratta del contenitore
usersesistente.
Quindi, si introduce un secondo livello di denormalizzazione duplicando interi post nel contenitore users. In questo modo, si ottiene efficacemente una copia dei post, partizionati però lungo dimensioni diverse, rendendo così più efficiente il recupero in base al rispettivo userId.
Il contenitore users contiene ora due tipi di elementi:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
In questo esempio:
- È stato introdotto un campo
typenell'elemento utente per distinguere gli utenti dai post, - è stato anche aggiunto un campo
userIdall'elemento utente, che è ridondante con il campoid, ma è richiesto in quanto il contenitoreusersè ora partizionato conuserId(e nonid, come in precedenza)
Per conseguire tale denormalizzazione, si usa ancora una volta il feed di modifiche. Questa volta, si risponde al feed di modifiche del contenitore posts per inviare post nuovi o aggiornati al contenitore users. In più, dal momento che per elencare i post non è necessario restituirne il contenuto completo, è possibile troncarli nel processo.
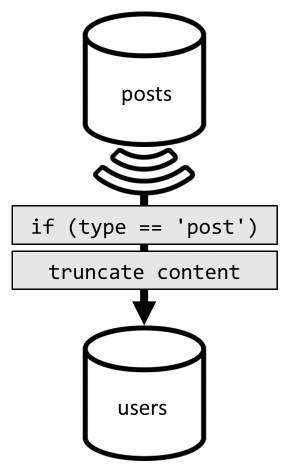
A questo punto è possibile indirizzare la query al contenitore users, filtrando la chiave di partizione del contenitore.

| Latenza | Addebito UR | Prestazioni |
|---|---|---|
4 ms |
6.46 RU |
✅ |
[Q6] Elencare i x post più recenti in forma breve (feed)
In questo caso è necessario affrontare una situazione analoga: anche dopo aver evitato le query aggiuntive, rese superflue dalla denormalizzazione introdotta nella V2, la query rimanente non filtra la chiave di partizione del contenitore:
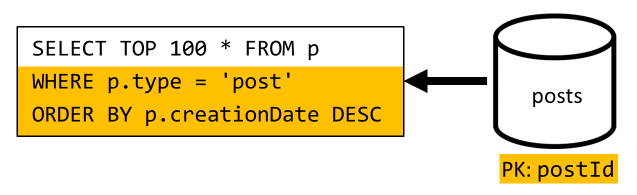
Seguendo lo stesso approccio, per ottimizzare le prestazioni e la scalabilità di questa richiesta, è necessario inviarla a una sola partizione. È possibile raggiungere una singola partizione solo perché è necessario restituire solo un numero limitato di elementi. Per popolare la home page della piattaforma di blogging, è sufficiente ottenere i 100 post più recenti, senza dover impaginare l'intero set di dati.
Dunque, per ottimizzare quest'ultima richiesta, si introduce nella progettazione un terzo contenitore, interamente dedicato a rispondere a questa richiesta. Si esegue la denormalizzazione dei post nel nuovo contenitore feed:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Il campo type partiziona questo contenitore, che è sempre post negli elementi. Questa operazione assicura che tutti gli elementi in questo contenitore si troveranno nella stessa partizione.
Per ottenere la denormalizzazione, è sufficiente utilizzare la pipeline del feed di modifiche introdotta in precedenza per inviare i post al nuovo contenitore. È importante ricordare che è necessario assicurarsi che vengano archiviati solo i 100 post più recenti. In caso contrario, il contenuto del contenitore può eccedere le dimensioni massime di una partizione. Questa limitazione può essere implementata chiamando un post-trigger ogni volta che un documento viene aggiunto nel contenitore:
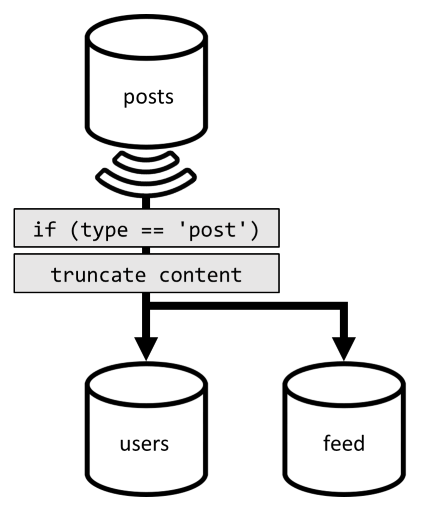
Di seguito è riportato il corpo del post-trigger che tronca la raccolta:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
Il passaggio finale consiste nel reindirizzare la query al nuovo contenitore feed:
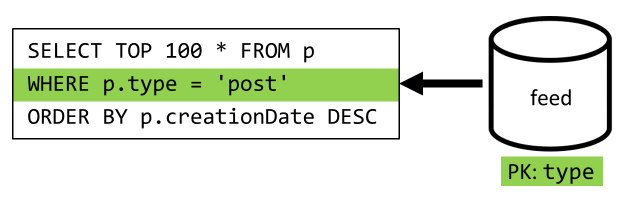
| Latenza | Addebito UR | Prestazioni |
|---|---|---|
9 ms |
16.97 RU |
✅ |
Conclusione
Verranno ora esaminati i miglioramenti complessivi delle prestazioni e della scalabilità introdotti nelle diverse versioni progettate.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms/ 5.71 UR |
7 ms/ 5.71 UR |
7 ms/ 5.71 UR |
| [Q1] | 2 ms/ 1 UR |
2 ms/ 1 UR |
2 ms/ 1 UR |
| [C2] | 9 ms/ 8.76 UR |
9 ms/ 8.76 UR |
9 ms/ 8.76 UR |
| [Q2] | 9 ms/ 19.54 UR |
2 ms/ 1 UR |
2 ms/ 1 UR |
| [Q3] | 130 ms/ 619.41 UR |
28 ms/ 201.54 UR |
4 ms/ 6.46 UR |
| [C3] | 7 ms/ 8.57 UR |
7 ms/ 15.27 UR |
7 ms/ 15.27 UR |
| [Q4] | 23 ms/ 27.72 UR |
4 ms/ 7.72 UR |
4 ms/ 7.72 UR |
| [C4] | 6 ms/ 7.05 UR |
7 ms/ 14.67 UR |
7 ms/ 14.67 UR |
| [Q5] | 59 ms/ 58.92 UR |
4 ms/ 8.92 UR |
4 ms/ 8.92 UR |
| [Q6] | 306 ms/ 2063.54 UR |
83 ms/ 532.33 UR |
9 ms/ 16.97 UR |
È stato ottimizzato uno scenario con intensa attività di lettura
Si sarà notato che gli sforzi sono stati incentrati sul migliorare le prestazioni delle richieste di lettura (query) a scapito delle richieste di scrittura (comandi). In molti casi, le operazioni di scrittura ora attivano la successiva denormalizzazione tramite feed di modifiche, che ne aumenta i costi di calcolo e i tempi di materializzazione.
Questo focus sulle prestazioni di lettura è giustificato dal fatto che una piattaforma di blogging (come la maggior parte delle app social) svolge attività di lettura intense. Un carico di lavoro di lettura elevato indica che la quantità di richieste di lettura che deve servire è in genere ordini di grandezza superiore al numero di richieste di scrittura. È quindi opportuno aumentare il costo di esecuzione delle richieste di scrittura per ridurre quello delle richieste di lettura, migliorandone le prestazioni.
Se si osserva l'ottimizzazione più estrema eseguita, [Q6] è passato da oltre 2000 UR a sole 17 UR, grazie alla normalizzazione dei post a un costo di circa 10 UR per ogni elemento. Dal momento che l'attività principale consisterebbe nel gestire molte più richieste di feed piuttosto che nel creare o aggiornare i post, il costo della denormalizzazione è trascurabile, considerando il risparmio complessivo.
La denormalizzazione può essere applicata in modo incrementale
I miglioramenti della scalabilità esplorati in questo articolo riguardano la denormalizzazione e la duplicazione dei dati nel set di dati. Si noti che non è necessario implementare queste ottimizzazioni sin dal primo momento. Le query che filtrano le chiavi di partizione offrono prestazioni migliori su larga scala, ma le query tra partizioni possono essere accettabili se vengono chiamate raramente o rispetto a un set di dati limitato. Se si sta solo creando un prototipo o lanciando un prodotto con una base utente piccola e controllata, probabilmente è possibile risparmiare questi miglioramenti per un secondo momento. È importante quindi monitorare prestazioni del modello in modo da poter decidere se e quando inserirli.
Il feed di modifiche usato per distribuire gli aggiornamenti negli altri contenitori archivia tutti questi aggiornamenti in modo definitivo. Questa persistenza consente di richiedere tutti gli aggiornamenti dalla creazione del contenitore e delle viste denormalizzate bootstrap come operazione di recupero una tantum anche se il sistema dispone già di molti dati.
Passaggi successivi
Dopo questa introduzione pratica alla modellazione di dati e al partizionamento, consultare gli articoli seguenti per rivedere i concetti che sono stati trattati: