Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Oggi più che mai sono disponibili più opzioni sul tipo di database da usare con il carico di lavoro dei dati. Uno dei fattori chiave per la selezione di un database è rappresentato dalle prestazioni del database o del servizio, ma le prestazioni di benchmarking possono essere complesse e soggette a errori. Il framework di benchmarking per database di Azure semplifica il processo di misurazione delle prestazioni con gli strumenti di benchmarking open source più diffusi, con ricette a basso attrito che implementano procedure consigliate comuni. In Azure Cosmos DB for NoSQL il framework implementa procedure consigliate per Java SDK e usa lo strumento open source YCSB. In questa guida si usa questo framework di benchmarking per implementare un carico di lavoro di lettura e acquisire così familiarità con il framework.
Prerequisiti
- Un account Azure con una sottoscrizione attiva. Creare un account gratuitamente.
- Account Azure Cosmos DB for NoSQL. Creare un'API per l'account NoSQL.
- Assicurarsi di annotare l'URI dell'endpoint e la chiave primaria per l'account.
- Account di archiviazione di Azure. Creare un account di archiviazione di Azure.
- Assicurarsi di annotare la stringa di connessione per l'account di archiviazione. Stringa di connessione di Archiviazione di Azure Vies.
- Secondo gruppo di risorse vuoto. Creare un gruppo di risorse.
- Interfaccia della riga di comando di Azure.
Creare risorse dell'account Azure Cosmos DB
Prima di tutto, si creano un database e un contenitore nell'account API esistente per NoSQL.
Passare all'account API esistente per NoSQL nel portale di Azure.
Nel menu della risorsa selezionare Esplora dati.

Nella pagina Esplora dati selezionare l'opzione Nuovo contenitore nella barra dei comandi.
Nella finestra di dialogo Nuovo contenitore creare un nuovo contenitore con le impostazioni seguenti:
Impostazione Valore ID database ycsbTipo di velocità effettiva del database Manualee Quantità di velocità effettiva del database 400ID contenitore usertableChiave di partizione /id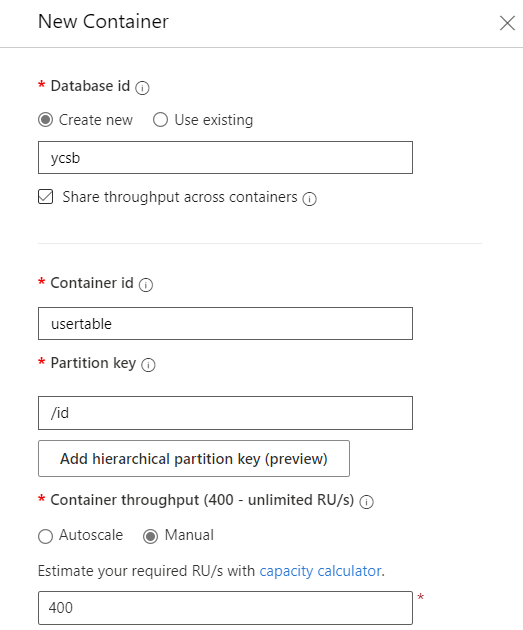

Distribuire il framework di benchmarking in Azure
A questo punto si usa un modello di Azure Resource Manager per distribuire il framework di benchmarking in Azure con la ricetta di lettura predefinita.
Distribuire il framework di benchmarking usando un modello di Azure Resource Manager disponibile in questo collegamento.
Nella pagina Distribuzione personalizzata, i parametri seguenti

Selezionare Rivedi e crea e quindi Crea per distribuire il modello.
Attendere il completamento della distribuzione.
Suggerimento
Per il completamento della distribuzione sarà necessario attendere 5-10 minuti.

Visualizzare i risultati del benchmark
A questo punto, è possibile usare l'account di Archiviazione di Azure esistente per controllare lo stato del processo di benchmark e visualizzare i risultati aggregati. Lo stato viene archiviato usando una tabella di archiviazione e i risultati vengono aggregati in un BLOB di archiviazione usando il formato CSV.
Passare all'account di Archiviazione di Azure esistente nel portale di Azure.
Passare a una tabella di archiviazione denominata ycsbbenchmarkingmetadata e individuare l'entità con una chiave di partizione di
ycsb_sql.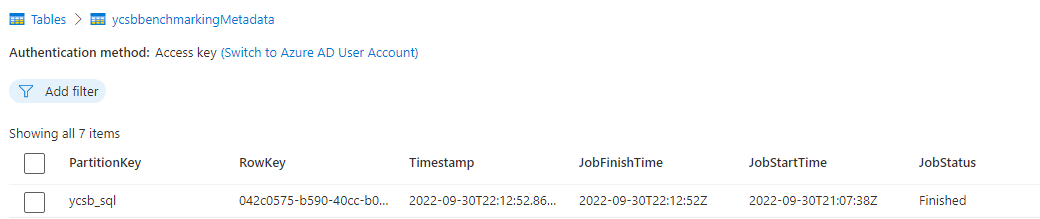
Osservare il campo
JobStatusdell'entità tabella. Inizialmente, lo stato del processo èStartede include un timestamp nella proprietàJobStartTime, ma non la proprietàJobFinishTime.Attendere che il processo abbia lo stato
Finishede includa un timestamp nella proprietàJobFinishTime.Suggerimento
Per terminare il processo sono necessari circa 20-30 minuti.
Passare al contenitore di archiviazione nello stesso account con un prefisso di ycsbbenchmarking-*. Osservare l'output e i BLOB di diagnostica per lo strumento.

Aprire il BLOB aggregation.csv e osservare il contenuto. A questo punto dovrebbe essere presente un set di dati CSV con risultati aggregati di tutti i client di benchmark.
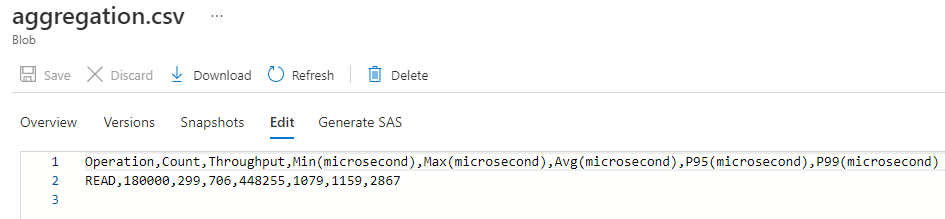
Operation,Count,Throughput,Min(microsecond),Max(microsecond),Avg(microsecond),P9S(microsecond),P99(microsecond) READ,180000,299,706,448255,1079,1159,2867
Ricette
Il framework di benchmarking per database di Azure include ricette per incapsulare le definizioni del carico di lavoro passate allo strumento di benchmarking sottostante per un'esperienza "a 1 clic". Le definizioni del carico di lavoro sono state progettate in base alle procedure consigliate pubblicate dal team di Azure Cosmos DB e dal team dello strumento di benchmarking. Le ricette sono state testate e convalidate per ottenere risultati coerenti.
È possibile prevedere le latenze seguenti per tutte le ricette di lettura e scrittura nel repository GitHub.
Latenza lettura

Latenza scrittura



Problemi comuni
Questa sezione include gli errori comuni che possono verificarsi durante l'esecuzione dello strumento di benchmarking. I log degli errori per lo strumento sono in genere disponibili in un contenitore all'interno dell'account di Archiviazione di Azure.

Se i log non sono disponibili nell'account di archiviazione, questo problema è in genere causato da una stringa di connessione di archiviazione errata o mancante. In questo caso, questo errore viene elencato nel file agent.out all'interno della cartella /home/benchmarking della macchina virtuale client.
Error while accessing storage account, exiting from this machine in agent.out on the VMQuesto errore è elencato nel file agent.out sia nella macchina virtuale client che nell'account di archiviazione se l'URI dell'endpoint di Azure Cosmos DB non è corretto o non raggiungibile.
Caused by: java.net.UnknownHostException: rtcosmosdbsss.documents.azure.com: Name or service not knownQuesto errore è elencato nel file agent.out sia nella macchina virtuale client che nell'account di archiviazione se la chiave di Azure Cosmos DB non è corretta.
The input authorization token can't serve the request. The wrong key is being used….
Passaggi successivi
- Altre informazioni sullo strumento di benchmarking con la guida introduttiva.