Come inserire dati usando pg_azure_storage in Azure Cosmos DB for PostgreSQL
SI APPLICA A: ![]() Azure Cosmos DB for PostgreSQL (basato su estensione database Citus per PostgreSQL)
Azure Cosmos DB for PostgreSQL (basato su estensione database Citus per PostgreSQL)
Questo articolo descrive come usare l'estensione pg_azure_storage PostgreSQL per manipolare e caricare i dati in Azure Cosmos DB for PostgreSQL direttamente da Archiviazione BLOB di Azure (ABS). ABS è un servizio di archiviazione nativo del cloud scalabile, durable e protetto. Queste caratteristiche lo rendono una soluzione ideale per archiviare e spostare i dati esistenti nel cloud.
Preparare il database e l'archiviazione BLOB
Per caricare dati da Archiviazione BLOB di Azure, installare l'estensione PostgreSQL pg_azure_storage nel database:
SELECT * FROM create_extension('azure_storage');
Importante
L'estensione pg_azure_storage è disponibile solo nei cluster Azure Cosmos DB for PostgreSQL che eseguono PostgreSQL 13 e versioni successive.
Per questo articolo è stato preparato un set di dati dimostrativo pubblico. Per usare il proprio set di dati, vedere migrare i dati locali in archiviazione nel cloud per informazioni su come ottenere i set di dati in modo efficiente in Archiviazione BLOB di Azure.
Nota
Selezionando "Contenitore (accesso in lettura anonimo per contenitori e BLOB)" sarà possibile inserire file da Archiviazione BLOB di Azure usando i rispettivi URL pubblici, ed enumerare i contenuti del contenitore senza dover configurare una chiave dell'account in pg_azure_storage. I contenitori impostati sul livello di accesso "Privato (nessun accesso anonimo)" o "BLOB (accesso in lettura anonimo solo per i BLOB)" richiederanno una chiave di accesso.
Elencare i contenuti del contenitore
Per questa procedura è stata creata una dimostrazione dell'account di Archiviazione BLOB di Azure e un contenitore. Il nome del contenitore è github e si trova nell'account pgquickstart. La funzione azure_storage.blob_list(account, container) consente di vedere facilmente quali file sono presenti nel contenitore.
SELECT path, bytes, pg_size_pretty(bytes), content_type
FROM azure_storage.blob_list('pgquickstart','github');
-[ RECORD 1 ]--+-------------------
path | events.csv.gz
bytes | 41691786
pg_size_pretty | 40 MB
content_type | application/x-gzip
-[ RECORD 2 ]--+-------------------
path | users.csv.gz
bytes | 5382831
pg_size_pretty | 5257 kB
content_type | application/x-gzip
È possibile filtrare l'output usando una normale clausola SQL WHERE, o usando il parametro prefix della UDF blob_list. Quest'ultimo filtra le righe restituite sul lato Archiviazione BLOB di Azure.
Nota
L'elenco dei contenuti del contenitore richiede un account e una chiave di accesso, o un contenitore con accesso anonimo abilitato.
SELECT * FROM azure_storage.blob_list('pgquickstart','github','e');
-[ RECORD 1 ]----+---------------------------------
path | events.csv.gz
bytes | 41691786
last_modified | 2022-10-12 18:49:51+00
etag | 0x8DAAC828B970928
content_type | application/x-gzip
content_encoding |
content_hash | 473b6ad25b7c88ff6e0a628889466aed
SELECT *
FROM azure_storage.blob_list('pgquickstart','github')
WHERE path LIKE 'e%';
-[ RECORD 1 ]----+---------------------------------
path | events.csv.gz
bytes | 41691786
last_modified | 2022-10-12 18:49:51+00
etag | 0x8DAAC828B970928
content_type | application/x-gzip
content_encoding |
content_hash | 473b6ad25b7c88ff6e0a628889466aed
Caricare dati da ABS
Caricare i dati con il comando COPY
Per iniziare, creare uno schema campione.
CREATE TABLE github_users
(
user_id bigint,
url text,
login text,
avatar_url text,
gravatar_id text,
display_login text
);
CREATE TABLE github_events
(
event_id bigint,
event_type text,
event_public boolean,
repo_id bigint,
payload jsonb,
repo jsonb,
user_id bigint,
org jsonb,
created_at timestamp
);
CREATE INDEX event_type_index ON github_events (event_type);
CREATE INDEX payload_index ON github_events USING GIN (payload jsonb_path_ops);
SELECT create_distributed_table('github_users', 'user_id');
SELECT create_distributed_table('github_events', 'user_id');
Il caricamento dei dati nelle tabelle diventa semplice, chiamando il comando COPY.
-- download users and store in table
COPY github_users
FROM 'https://pgquickstart.blob.core.windows.net/github/users.csv.gz';
-- download events and store in table
COPY github_events
FROM 'https://pgquickstart.blob.core.windows.net/github/events.csv.gz';
Si noti che l'estensione ha riconosciuto che gli URL forniti al comando COPY provengono da Archiviazione BLOB di Azure e che i file a cui si è fatto riferimento sono stati compressi con Gzip e sono stati già gestiti automaticamente.
Il comando COPY supporta più parametri e formati. Nell'esempio precedente il formato e la compressione sono stati selezionati automaticamente in base alle estensioni dei file. Tuttavia è possibile specificare il formato direttamente, in modo simile al comando normale COPY.
COPY github_users
FROM 'https://pgquickstart.blob.core.windows.net/github/users.csv.gz'
WITH (FORMAT 'csv');
Attualmente l'estensione supporta i formati di file seguenti:
| format | description |
|---|---|
| csv | Formato di valori delimitati da virgole usato da PostgreSQL COPY |
| tsv | Valori delimitati da tabulazioni, formato predefinito PostgreSQL COPY |
| binary | Formato PostgreSQL COPY binario |
| Testo | Un file contenente un singolo valore di testo (ad esempio, JSON o XML di grandi dimensioni) |
Caricare dati con blob_get()
Il comando COPY è pratico, ma limitato in flessibilità. Internamente COPY usa la funzione blob_get, utilizzabile direttamente per modificare i dati in scenari più complessi.
SELECT *
FROM azure_storage.blob_get(
'pgquickstart', 'github',
'users.csv.gz', NULL::github_users
)
LIMIT 3;
-[ RECORD 1 ]-+--------------------------------------------
user_id | 21
url | https://api.github.com/users/technoweenie
login | technoweenie
avatar_url | https://avatars.githubusercontent.com/u/21?
gravatar_id |
display_login | technoweenie
-[ RECORD 2 ]-+--------------------------------------------
user_id | 22
url | https://api.github.com/users/macournoyer
login | macournoyer
avatar_url | https://avatars.githubusercontent.com/u/22?
gravatar_id |
display_login | macournoyer
-[ RECORD 3 ]-+--------------------------------------------
user_id | 38
url | https://api.github.com/users/atmos
login | atmos
avatar_url | https://avatars.githubusercontent.com/u/38?
gravatar_id |
display_login | atmos
Nota
Nella query precedente il file viene recuperato completamente prima che sia applicato LIMIT 3.
Con questa funzione è possibile modificare immediatamente i dati in query complesse ed eseguire importazioni quali INSERT FROM SELECT.
INSERT INTO github_users
SELECT user_id, url, UPPER(login), avatar_url, gravatar_id, display_login
FROM azure_storage.blob_get('pgquickstart', 'github', 'users.csv.gz', NULL::github_users)
WHERE gravatar_id IS NOT NULL;
INSERT 0 264308
Nel comando precedente i dati sono stati filtrati per account con un present gravatar_id e gli accessi sono stati immediatamente convertiti in caratteri maiuscoli.
Opzioni per blob_get()
In alcune situazioni, potrebbe essere necessario controllare esattamente quali tentativi blob_get eseguire usando i parametri decoder,compression e options.
Il decodificatore può essere impostato su auto (impostazione predefinita) o su uno dei valori seguenti:
| format | description |
|---|---|
| csv | Formato di valori delimitati da virgole usato da PostgreSQL COPY |
| tsv | Valori delimitati da tabulazioni, formato predefinito PostgreSQL COPY |
| binary | Formato PostgreSQL COPY binario |
| Testo | Un file contenente un singolo valore di testo (ad esempio, JSON o XML di grandi dimensioni) |
compression può essere auto (impostazione predefinita), none o gzip.
Infine, il parametro options è di tipo jsonb. Sono disponibili quattro funzioni di utilità che consentono di compilare valori.
Ogni funzione di utilità è designata per il decodificatore corrispondente al nome.
| decodificatore | funzione delle opzioni |
|---|---|
| csv | options_csv_get |
| tsv | options_tsv |
| binary | options_binary |
| Testo | options_copy |
Esaminando le definizioni di funzione, è possibile vedere quali sono i parametri supportati dal decodificatore.
options_csv_get - delimitatore, null_string, intestazione, quote, ESC, force_not_null, force_null, content_encoding options_tsv - delimitatore, null_string, content_encoding options_copy - delimitatore, null_string, intestazione, quote, ESC, force_quote, force_not_null, force_null, content_encoding.
options_binary - content_encoding
Sapendo quanto sopra, è possibile eliminare le registrazioni con gravatar_id null durante l'analisi.
INSERT INTO github_users
SELECT user_id, url, UPPER(login), avatar_url, gravatar_id, display_login
FROM azure_storage.blob_get('pgquickstart', 'github', 'users.csv.gz', NULL::github_users,
options := azure_storage.options_csv_get(force_not_null := ARRAY['gravatar_id']));
INSERT 0 264308
Accedere alla risorsa di archiviazione privata
Ottenere il nome e la chiave di accesso dell'account
Senza una chiave di accesso, non sarà consentito presentare l’elenco dei contenitori impostati su Livelli di accesso Privato o BLOB.
SELECT * FROM azure_storage.blob_list('mystorageaccount','privdatasets');ERROR: azure_storage: missing account access key HINT: Use SELECT azure_storage.account_add('<account name>', '<access key>')Nell'account di archiviazione aprire Chiavi di accesso. Copiare il nome dell'account di archiviazione e copiare la chiave dalla sezione key1 (è necessario prima selezionare Mostra accanto alla chiave).
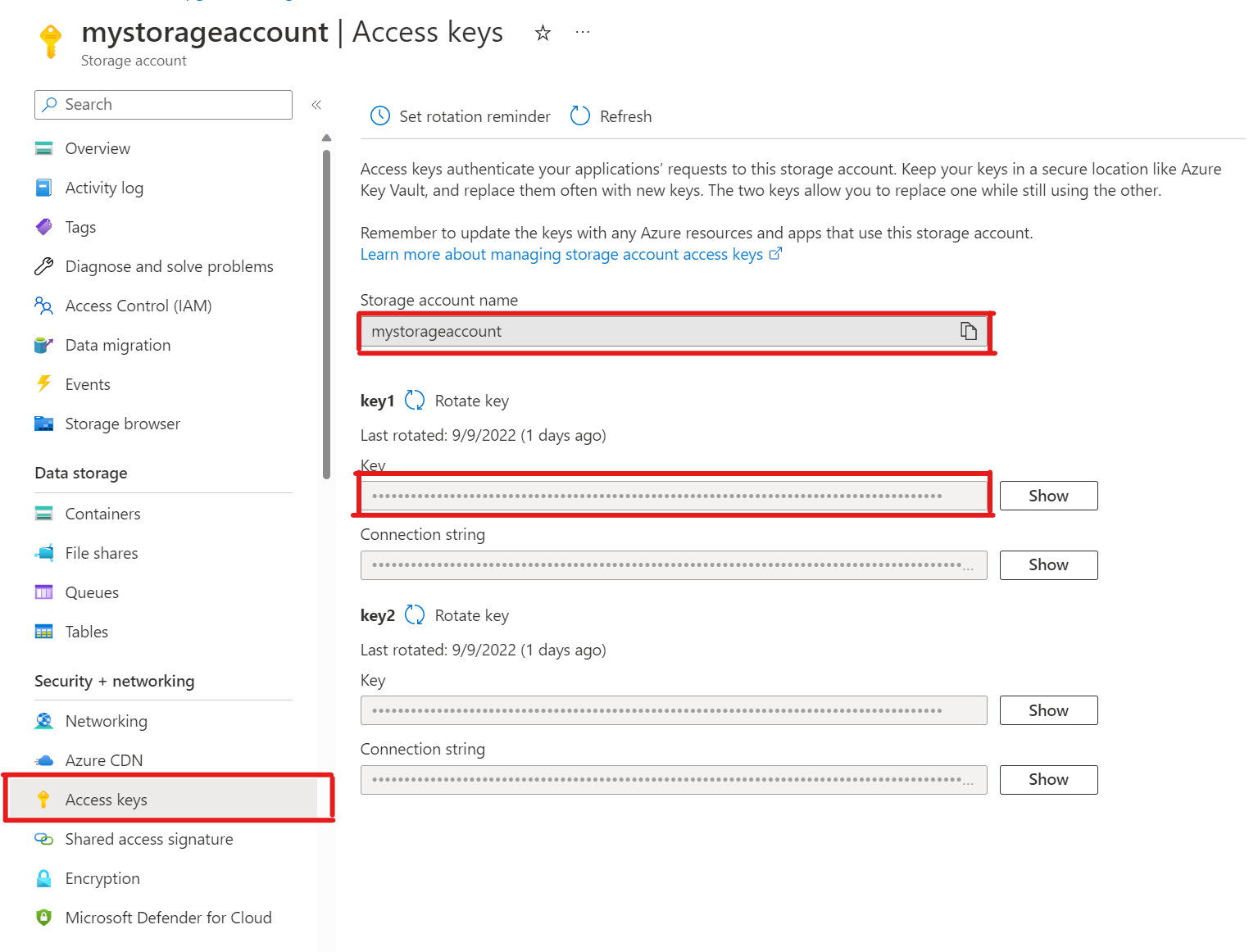
Aggiunta di un account a pg_azure_storage
SELECT azure_storage.account_add('mystorageaccount', 'SECRET_ACCESS_KEY');È ora possibile elencare i contenitori impostati sui livelli di accesso Privato e BLOB per tale archiviazione, ma solo come utente
citus, al quale è concesso il ruoloazure_storage_admin. Se si crea un nuovo utente denominatosupport, per impostazione predefinita non sarà consentito accedere al contenuto del contenitore.SELECT * FROM azure_storage.blob_list('pgabs','dataverse');ERROR: azure_storage: current user support is not allowed to use storage account pgabsConsentire all'utente
supportdi usare uno specifico account di Archiviazione BLOB di AzureLa concessione dell'autorizzazione avviene con la chiamata di
account_user_add.SELECT * FROM azure_storage.account_user_add('mystorageaccount', 'support');È possibile visualizzare gli utenti consentiti nell'output di
account_list, che mostra tutti gli account con chiavi di accesso definite.SELECT * FROM azure_storage.account_list();account_name | allowed_users ------------------+--------------- mystorageaccount | {support} (1 row)Se si decide che l'utente non deve più avere accesso. È sufficiente chiamare
account_user_remove.SELECT * FROM azure_storage.account_user_remove('mystorageaccount', 'support');
Passaggi successivi
A questo punto si è appreso come caricare i dati in Azure Cosmos DB for PostgreSQL direttamente da Archiviazione BLOB di Azure.
- Informazioni su come creare dashboard in tempo reale con Azure Cosmos DB for PostgreSQL.
- Altre informazioni su pg_azure_storage.
- Informazioni su Supporto Postgres COPY.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per