Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Azure Cosmos DB per PostgreSQL non è più supportato per i nuovi progetti. Non usare questo servizio per i nuovi progetti. Usare invece uno dei due servizi seguenti:
Usare Azure Cosmos DB per NoSQL per una soluzione di database distribuita progettata per scenari su alta scala con un accordo sul livello di servizio (SLA) di disponibilità del 99.999%, scalabilità automatica istantanea e failover automatico in più regioni.
Usare la funzionalità Cluster elastici di Database di Azure per PostgreSQL per PostgreSQL partizionato usando l'estensione Citus open source.
Prima di esaminare i passaggi della creazione di una nuova app, è utile visualizzare una rapida panoramica dei termini e dei concetti coinvolti.
Panoramica dell'architettura
Azure Cosmos DB for PostgreSQL offre la potenza di distribuire tabelle e/o schemi tra più computer in un cluster ed eseguire query in modo trasparente sulla stessa query su PostgreSQL normale:
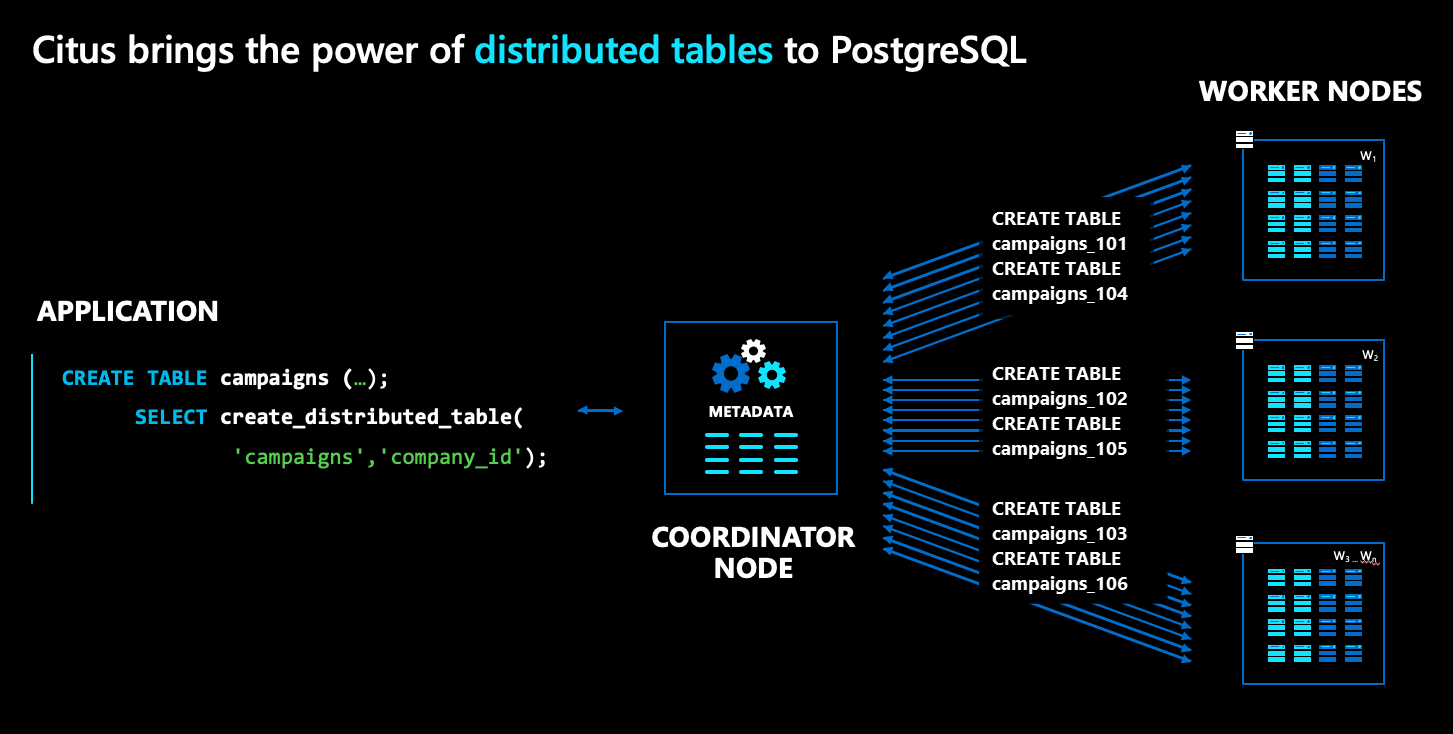
Nell'architettura di Azure Cosmos DB for PostgreSQL sono disponibili più tipi di nodi:
- Il nodo coordinatore archivia i metadati della tabella distribuita ed è responsabile della pianificazione distribuita.
- Al contrario, i nodi di lavoro archiviano i dati effettivi, i metadati ed eseguono il calcolo.
- Sia il coordinatore che i ruoli di lavoro sono database PostgreSQL semplici, con l'estensione
cituscaricata.
Per distribuire una normale tabella PostgreSQL, ad esempio campaigns nel diagramma precedente, eseguire un comando denominato create_distributed_table(). Dopo aver eseguito questo comando, Azure Cosmos DB for PostgreSQL crea in modo trasparente le partizioni per la tabella tra i nodi di lavoro. Nel diagramma le partizioni sono rappresentate come caselle blu.
Per distribuire uno schema PostgreSQL normale, eseguire il comando citus_schema_distribute(). Dopo aver eseguito questo comando, Azure Cosmos DB for PostgreSQL trasforma in modo trasparente le tabelle in tali schemi in una singola tabella con partizioni che possono essere spostate come unità tra i nodi del cluster.
Note
In un cluster senza nodi di lavoro, le partizioni delle tabelle distribuite si trovano nel nodo coordinatore.
Le partizioni sono tabelle PostgreSQL semplici (ma denominate appositamente) che contengono sezioni dei dati. In questo esempio, poiché è stato distribuito campaigns da company_id, le partizioni contengono campagne, in cui le campagne di diverse aziende vengono assegnate a partizioni diverse.
Colonna di distribuzione (nota anche come chiave di partizione)
create_distributed_table() è la funzione magica fornita da Azure Cosmos DB for PostgreSQL per distribuire le tabelle e usare le risorse tra più computer.
SELECT create_distributed_table(
'table_name',
'distribution_column');
Il secondo argomento precedente seleziona una colonna dalla tabella come colonna di distribuzione. Può trattarsi di qualsiasi colonna con un tipo PostgreSQL nativo (con numeri interi e testo più comuni). Il valore della colonna di distribuzione determina le righe in cui vengono inserite le partizioni, motivo per cui la colonna di distribuzione viene chiamata anche chiave di partizione.
Azure Cosmos DB for PostgreSQL decide come eseguire query in base all'uso della chiave di partizione:
| La query implica | Posizione in cui viene eseguita |
|---|---|
| solo una chiave di partizione | nel nodo di lavoro che contiene la partizione |
| più chiavi di partizione | parallelizzata tra più nodi |
La scelta della chiave di partizione determina le prestazioni e la scalabilità delle applicazioni.
- La distribuzione dei dati non uniforme per ogni chiave di partizione (nota anche come asimmetria dei dati) non è ottimale per le prestazioni. Ad esempio, non scegliere una colonna per la quale un singolo valore rappresenta il 50% dei dati.
- Le chiavi di partizione con cardinalità bassa possono influire sulla scalabilità. È possibile usare solo tutte le partizioni in quanto sono presenti valori di chiave distinti. Scegliere una chiave con cardinalità tra centinaia e migliaia.
- L'unione di due tabelle di grandi dimensioni con chiavi di partizione diverse può essere lenta. Scegliere una chiave di partizione comune tra tabelle di grandi dimensioni. Per altre informazioni, vedere coubicazione.
Coubicazione
Un altro concetto strettamente correlato alla chiave di partizione è la coubicazione. Le tabelle partizionate dagli stessi valori di colonna di distribuzione sono raggruppate: le partizioni delle tabelle con percorso condiviso vengono archiviate insieme negli stessi ruoli di lavoro.
Di seguito sono riportate due tabelle partizionate dalla stessa chiave, site_id. Sono coubicate.
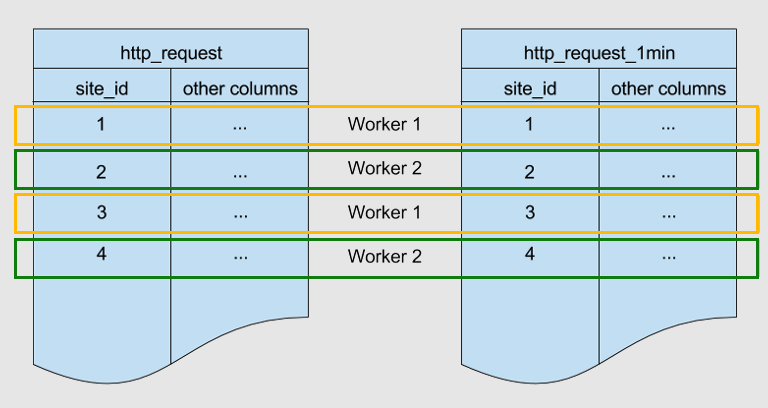
Azure Cosmos DB for PostgreSQL garantisce che le righe con un valore site_id corrispondente in entrambe le tabelle vengano archiviate nello stesso nodo di lavoro. È possibile notare che, per entrambe le tabelle, le righe con site_id=1 vengono archiviate nel ruolo di lavoro 1. Analogamente per altri ID sito.
La coubicazione consente di ottimizzare i file JOIN in queste tabelle. Se si unisce le due tabelle in site_id, Azure Cosmos DB for PostgreSQL può eseguire il join in locale nei nodi di lavoro senza scambiare i dati tra i nodi.
Le tabelle all'interno di uno schema distribuito vengono sempre raggruppate tra loro.