Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Azure Cosmos DB per PostgreSQL non è più supportato per i nuovi progetti. Non usare questo servizio per i nuovi progetti. Usare invece uno dei due servizi seguenti:
Usare Azure Cosmos DB per NoSQL per una soluzione di database distribuita progettata per scenari su alta scala con un accordo sul livello di servizio (SLA) di disponibilità del 99.999%, scalabilità automatica istantanea e failover automatico in più regioni.
Usare la funzionalità Cluster elastici di Database di Azure per PostgreSQL per PostgreSQL partizionato usando l'estensione Citus open source.
ID tenant come chiave di partizione
L'ID tenant è la colonna nella radice del carico di lavoro o nella parte superiore della gerarchia nel modello di dati. Ad esempio, in questo schema di e-commerce SaaS, si tratta dell'ID del negozio:
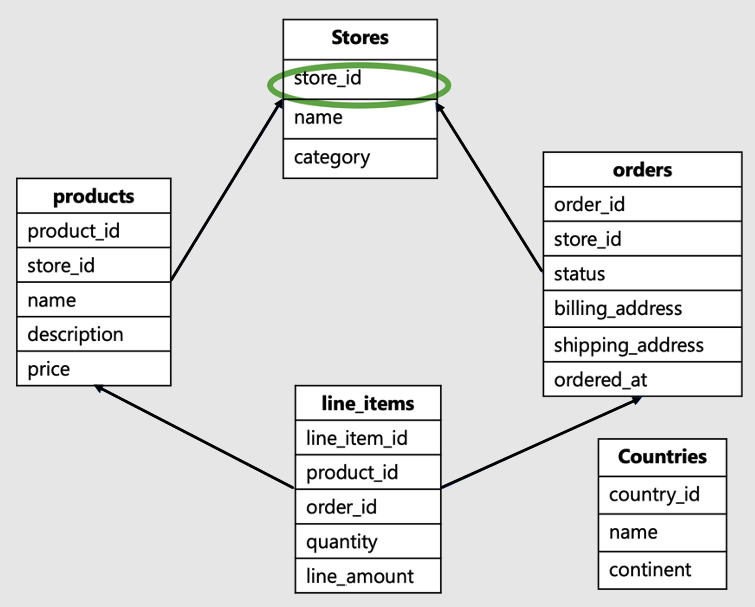
Questo modello di dati sarebbe tipico per un'azienda come Shopify. Ospita siti per più negozi online, dove ciascun negozio interagisce con i propri dati.
- Questo modello di dati include una serie di tabelle: negozi, prodotti, ordini, righe degli articoli e paesi.
- La tabella dei negozi si trova nella parte superiore della gerarchia. I prodotti, gli ordini e gli articoli di riga sono tutti associati ai negozi, quindi inferiori nella gerarchia.
- La tabella dei paesi non è correlata ai singoli negozi, ma si trova tra di essi.
In questo esempio, store_id, che si trova all'inizio della gerarchia, è l'identificatore per il tenant. È la chiave di partizione corretta. La selezione di store_id come chiave di partizione consente di collocare i dati in tutte le tabelle per un singolo archivio in un singolo ruolo di lavoro.
La collocazione delle tabelle per negozio presenta vantaggi.
- Fornisce copertura SQL, ad esempio chiavi esterne e JOIN. Le transazioni per un singolo tenant vengono localizzate in un singolo nodo di lavoro in cui è presente ogni tenant.
- Raggiunge prestazioni nell'ordine di pochi millisecondi. Le query provenienti da un singolo tenant vengono instradate a un singolo nodo invece di essere parallelizzate, il che contribuisce a ottimizzare gli hop di rete e a scalare le risorse di calcolo/memoria.
- È scalabile. Man mano che aumenta il numero di tenant, è possibile aggiungere nodi e ribilanciare i tenant ai nuovi nodi o anche isolare tenant di grandi dimensioni nei propri nodi. L'isolamento del tenant consente di fornire risorse dedicate.
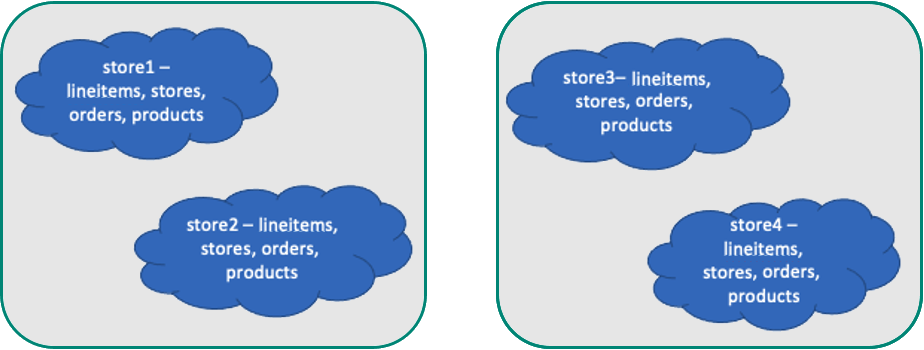
Modello di dati ottimale per le app multi-tenant
In questo esempio è necessario distribuire le tabelle specifiche dell'archivio in base all'ID archivio e rendere countries una tabella di riferimento.
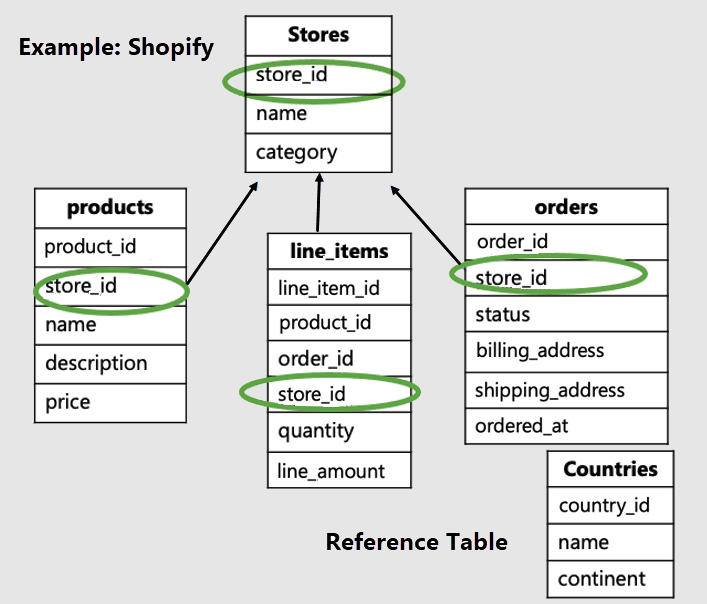
Notare che le tabelle specifiche del tenant hanno l'ID tenant e vengono distribuite. In questo esempio vengono distribuiti negozi, prodotti e line_items. Le altre tabelle sono tabelle di riferimento. Nell'esempio la tabella dei paesi è una tabella di riferimento.
-- Distribute large tables by the tenant ID
SELECT create_distributed_table('stores', 'store_id');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
-- etc for the rest of the tenant tables...
-- Then, make "countries" a reference table, with a synchronized copy of the
-- table maintained on every worker node
SELECT create_reference_table('countries');
Tutte le tabelle di grandi dimensioni devono avere l'ID tenant.
- Se si effettua la migrazione di un'app multi-tenant esistente ad Azure Cosmos DB for PostgreSQL, potrebbe essere necessario denormalizzare alcuni elementi e aggiungere la colonna ID tenant a tabelle di grandi dimensioni se è mancante, per poi compilare nuovamente i valori mancanti della colonna.
- Per le nuove app in Azure Cosmos DB for PostgreSQL, si assicuri che l'ID tenant sia presente in tutte le tabelle specifiche del tenant.
Assicurarsi di includere l'ID tenant nei vincoli di chiave primaria, univoca ed esterna nelle tabelle distribuite sotto forma di chiave composita. Ad esempio, se una tabella ha una chiave primaria di id, trasformarla nella chiave composita (tenant_id,id).
Non è necessario modificare le chiavi per le tabelle di riferimento.
Considerazioni sulle query per ottenere le prestazioni migliori
Le query distribuite che filtrano l'ID tenant vengono eseguite in modo più efficiente nelle app multi-tenant. Assicurati che le tue query siano sempre limitate a un singolo tenant.
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- ← tenant ID filter
È necessario aggiungere il filtro ID tenant anche se le condizioni di filtro originali identificano in modo univoco le righe desiderate. Il filtro ID tenant, apparentemente ridondante, indica ad Azure Cosmos DB for PostgreSQL come instradare la query a un singolo nodo di lavoro.
Analogamente, quando si uniscono due tabelle distribuite, assicurarsi che entrambe le tabelle siano incluse nell'ambito di un singolo tenant. La definizione dell'ambito può essere eseguita assicurandosi che le condizioni di join includano l'ID tenant.
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id -- ← tenant ID in join
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75';
-- ↑ tenant ID filter
Sono disponibili librerie helper per diversi framework applicativi comuni che semplificano l'inclusione di un ID tenant nelle query. Ecco le istruzioni:
Passaggi successivi
È stata completata l'esplorazione della modellazione dei dati per le app scalabili. Il passaggio successivo consiste nel connettere ed eseguire query sul database con il linguaggio di programmazione preferito.