Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Azure Cosmos DB per PostgreSQL si trova in un percorso di ritiro e non è più consigliato per i nuovi progetti. Usare invece uno dei due servizi seguenti:
Per i carichi di lavoro PostgreSQL : utilizzare la funzionalità Cluster Elastici di Azure Database per PostgreSQL per sfruttare le capacità di scalabilità orizzontale e distribuita e le funzionalità di PostgreSQL fornite dall'estensione open source Citus. Per indicazioni sulla migrazione, vedere migrare ad Database di Azure per PostgreSQL con Elastic Cluster.
Per i carichi di lavoro NoSQL, utilizzare Azure Cosmos DB per NoSQL per una soluzione di database distribuita che include un accordo sul livello di servizio (SLA) del 99,999% di disponibilità, la scalabilità automatica istantanea e il failover automatico in più aree.
In questa esercitazione si usa Azure Cosmos DB for PostgreSQL come back-end di archiviazione per più microservizi, illustrando una configurazione di esempio e un'operazione di base di tale cluster. Scopri come:
- Creare un cluster
- Creare ruoli per i microservizi
- Usare l'utilità psql per creare ruoli e schemi distribuiti
- Creare tabelle per i servizi di esempio
- Configurare i servizi
- Eseguire servizi
- Esplorare il database
Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Creare un cluster
Per creare un cluster di Azure Cosmos DB for PostgreSQL accedere al portale di Azure e seguire questa procedura:
Passare a Creare un cluster di Azure Cosmos DB for PostgreSQL nel portale di Azure.
Nel modulo Creazione di un cluster di Azure Cosmos DB per PostgreSQL:
Immettere le informazioni richieste nella scheda Nozioni di base.
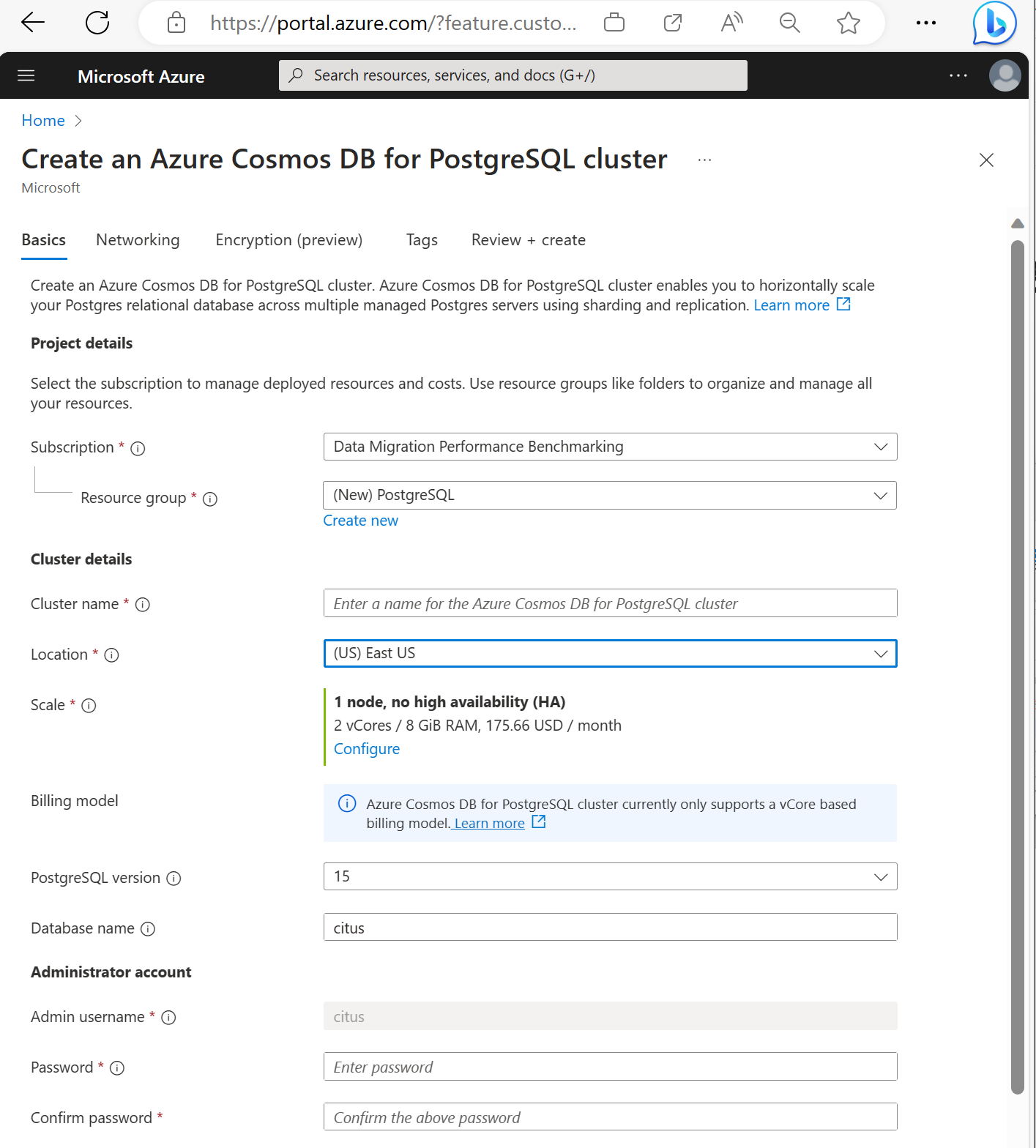
Anche se la maggior parte delle opzioni è autoesplicativa, tenere presente quanto segue:
- Il nome del cluster determina il nome DNS usato dalle applicazioni per la connessione, nel formato
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - È possibile scegliere una versione principale di PostgreSQL, ad esempio 15. Azure Cosmos DB for PostgreSQL supporta sempre la versione Citus più recente per la versione principale selezionata di Postgres.
- Il nome utente amministratore deve essere il valore
citus. - È possibile lasciare il nome del database al valore predefinito 'citus' o definire un proprio nome. Non è possibile rinominare il database dopo il provisioning del cluster.
- Il nome del cluster determina il nome DNS usato dalle applicazioni per la connessione, nel formato
Selezionare Avanti: Rete nella parte inferiore della schermata.
Nella schermata Rete selezionare Consentire l'accesso pubblico dai servizi e dalle risorse di Azure all'interno di Azure a questo cluster.
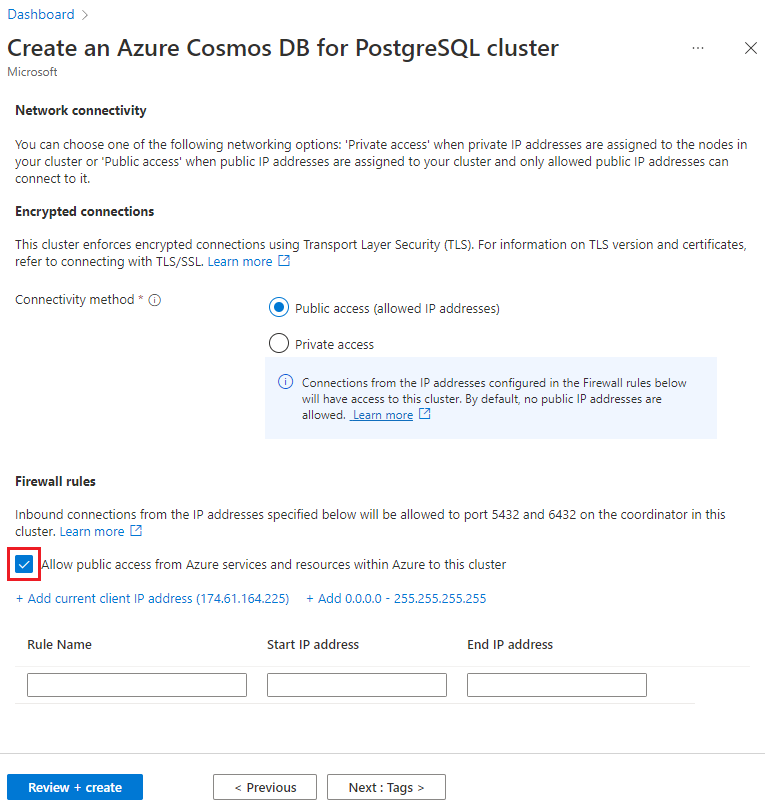
Selezionare Rivedi e crea e, al termine della convalida, selezionare Crea per creare il cluster.
La configurazione richiede alcuni minuti. La pagina viene reindirizzata per monitorare la distribuzione. Quando lo stato cambia da Distribuzione in corso a Distribuzione completata, selezionare Vai alla risorsa.
Creare ruoli per i microservizi
Gli schemi distribuiti sono riposizionabili all'interno di un cluster Azure Cosmos DB for PostgreSQL. Il sistema può ribilanciarli come un'intera unità tra i nodi disponibili, consentendo di condividere in modo efficiente le risorse senza allocazione manuale.
Per impostazione predefinita, i microservizi possiedono il proprio livello di archiviazione, non vengono fatte ipotesi sul tipo di tabelle e dati creati e archiviati. Viene fornito uno schema per ogni servizio e si presuppone che usi un ruolo distinto per connettersi al database. Quando un utente si connette, il nome del ruolo viene inserito all'inizio del search_path, quindi se il ruolo corrisponde al nome dello schema non sono necessarie modifiche dell'applicazione per impostare il search_path corretto.
Nell'esempio vengono usati tre servizi:
- utente
- time
- ping
Seguire i passaggi che descrivono come creare ruoli utente e creare i ruoli seguenti per ogni servizio:
userservicetimeservicepingservice
Usare l'utilità psql per creare schemi distribuiti
Dopo la connessione ad Azure Cosmos DB for PostgreSQL tramite psql, è possibile completare alcune attività di base.
Esistono due modi in cui è possibile distribuire uno schema in Azure Cosmos DB for PostgreSQL:
Chiamando manualmente la funzione citus_schema_distribute(schema_name):
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
SELECT citus_schema_distribute('userservice');
SELECT citus_schema_distribute('timeservice');
SELECT citus_schema_distribute('pingservice');
Questo metodo consente inoltre di convertire gli schemi regolari esistenti in schemi distribuiti.
Annotazioni
È possibile distribuire solo gli schemi che non contengono tabelle distribuite e di riferimento.
L'approccio alternativo consiste nell'abilitare la variabile di configurazione citus.enable_schema_based_sharding:
SET citus.enable_schema_based_sharding TO ON;
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
La variabile può essere modificata per la sessione corrente o in modo permanente nei parametri del nodo coordinatore. Con il parametro impostato su ON, tutti gli schemi creati vengono distribuiti per impostazione predefinita.
È possibile elencare gli schemi attualmente distribuiti eseguendo:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 5 | 0 bytes | userservice
timeservice | 6 | 0 bytes | timeservice
pingservice | 7 | 0 bytes | pingservice
(3 rows)
Creare tabelle per i servizi di esempio
È ora necessario connettersi ad Azure Cosmos DB for PostgreSQL per ogni microservizio. È possibile usare il comando \c per scambiare l'utente all'interno di un'istanza psql esistente.
\c citus userservice
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL
);
\c citus timeservice
CREATE TABLE query_details (
id SERIAL PRIMARY KEY,
ip_address INET NOT NULL,
query_time TIMESTAMP NOT NULL
);
\c citus pingservice
CREATE TABLE ping_results (
id SERIAL PRIMARY KEY,
host VARCHAR(255) NOT NULL,
result TEXT NOT NULL
);
Configurare i servizi
In questa esercitazione viene usato un semplice set di servizi. È possibile ottenerlo clonando questo repository pubblico:
git clone https://github.com/citusdata/citus-example-microservices.git
$ tree
.
├── LICENSE
├── README.md
├── ping
│ ├── app.py
│ ├── ping.sql
│ └── requirements.txt
├── time
│ ├── app.py
│ ├── requirements.txt
│ └── time.sql
└── user
├── app.py
├── requirements.txt
└── user.sql
Prima di eseguire i servizi, tuttavia, modificare i file user/app.py, ping/app.py e time/app.py fornendo la configurazione della connessione per il cluster Azure Cosmos DB for PostgreSQL:
# Database configuration
db_config = {
'host': 'c-EXAMPLE.EXAMPLE.postgres.cosmos.azure.com',
'database': 'citus',
'password': 'SECRET',
'user': 'pingservice',
'port': 5432
}
Dopo aver apportato le modifiche, salvare tutti i file modificati e passare al passaggio successivo dell'esecuzione dei servizi.
Eseguire servizi
Passare a ogni directory dell'app ed eseguirle in un ambiente python personalizzato.
cd user
pipenv install
pipenv shell
python app.py
Ripetere i comandi per il servizio tempo e il servizio ping, dopo di che è possibile usare l'API.
Creare alcuni utenti:
curl -X POST -H "Content-Type: application/json" -d '[
{"name": "John Doe", "email": "john@example.com"},
{"name": "Jane Smith", "email": "jane@example.com"},
{"name": "Mike Johnson", "email": "mike@example.com"},
{"name": "Emily Davis", "email": "emily@example.com"},
{"name": "David Wilson", "email": "david@example.com"},
{"name": "Sarah Thompson", "email": "sarah@example.com"},
{"name": "Alex Miller", "email": "alex@example.com"},
{"name": "Olivia Anderson", "email": "olivia@example.com"},
{"name": "Daniel Martin", "email": "daniel@example.com"},
{"name": "Sophia White", "email": "sophia@example.com"}
]' http://localhost:5000/users
Elencare gli utenti creati:
curl http://localhost:5000/users
Ottenere l'ora corrente:
Get current time:
Eseguire il ping su example.com:
curl -X POST -H "Content-Type: application/json" -d '{"host": "example.com"}' http://localhost:5002/ping
Esplorare il database
Ora che sono state chiamate alcune funzioni API, i dati sono stati archiviati ed è possibile verificare se citus_schemas riflette quanto previsto:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 1 | 112 kB | userservice
timeservice | 2 | 32 kB | timeservice
pingservice | 3 | 32 kB | pingservice
(3 rows)
Quando sono stati creati gli schemi, non è stato indicato ad Azure Cosmos DB for PostgreSQL in quali computer creare gli schemi. L'operazione è stata eseguita automaticamente. È possibile vedere dove risiede ogni schema con la query seguente:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9702 | userservice.users | 112 kB
localhost | 9702 | pingservice.ping_results | 32 kB
Per brevità dell'output di esempio in questa pagina, anziché usare nodename come visualizzato in Azure Cosmos DB for PostgreSQL, viene sostituito con localhost. Si supponga che localhost:9701 sia il ruolo di lavoro 1 e localhost:9702 il ruolo di lavoro 2. I nomi dei nodi nel servizio gestito sono più lunghi e contengono elementi casuali.
È possibile notare che il servizio tempo è giunto sul nodo localhost:9701 mentre l'utente e il servizio ping condividono lo spazio sul secondo ruolo di lavoro localhost:9702. Le app di esempio sono semplicistiche e le dimensioni dei dati sono ignorabili, ma si supponga di essere infastiditi dall'utilizzo non uniforme dello spazio di archiviazione tra i nodi. Sarebbe più opportuno che i due servizi tempo e pin più ridotti risiedano in un computer, mentre quello utente più grande risiede in una posizione separata.
È possibile ribilanciare facilmente il cluster in base alle dimensioni del disco:
select citus_rebalance_start();
NOTICE: Scheduled 1 moves as job 1
DETAIL: Rebalance scheduled as background job
HINT: To monitor progress, run: SELECT * FROM citus_rebalance_status();
citus_rebalance_start
-----------------------
1
(1 row)
Al termine, è possibile verificare l'aspetto del nuovo layout:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9701 | pingservice.ping_results | 32 kB
localhost | 9702 | userservice.users | 112 kB
(3 rows)
In base alle aspettative, gli schemi sono stati spostati e si dispone di un cluster più bilanciato. Questa operazione è stata trasparente per le applicazioni. Non è nemmeno necessario riavviarle: continueranno a gestire le query.
Passaggi successivi
In questa esercitazione si è appreso come creare schemi distribuiti e sono stati eseguiti microservizi usandoli come risorsa di archiviazione. Si è anche appreso come esplorare e gestire Azure Cosmos DB for PostgreSQL partizionato basato su schema.
- Informazioni sui tipi di nodi dei cluster