Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Azure Cosmos DB per PostgreSQL si trova in un percorso di ritiro e non è più consigliato per i nuovi progetti. Usare invece uno dei due servizi seguenti:
Per i carichi di lavoro PostgreSQL : utilizzare la funzionalità Cluster Elastici di Azure Database per PostgreSQL per sfruttare le capacità di scalabilità orizzontale e distribuita e le funzionalità di PostgreSQL fornite dall'estensione open source Citus. Per indicazioni sulla migrazione, vedere migrare ad Database di Azure per PostgreSQL con Elastic Cluster.
Per i carichi di lavoro NoSQL, utilizzare Azure Cosmos DB per NoSQL per una soluzione di database distribuita che include un accordo sul livello di servizio (SLA) del 99,999% di disponibilità, la scalabilità automatica istantanea e il failover automatico in più aree.
In questa esercitazione si usa Azure Cosmos DB for PostgreSQL per imparare a:
- Creare un cluster
- Usare l'utilità psql per creare uno schema
- Ripartire le tabelle tra i nodi
- Inserire dati di esempio
- Eseguire query sui dati dei tenant
- Condividere dati tra inquilini
- Personalizzare lo schema in base al tenant
Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Creare un cluster
Per creare un cluster di Azure Cosmos DB for PostgreSQL accedere al portale di Azure e seguire questa procedura:
Passare a Creare un cluster di Azure Cosmos DB for PostgreSQL nel portale di Azure.
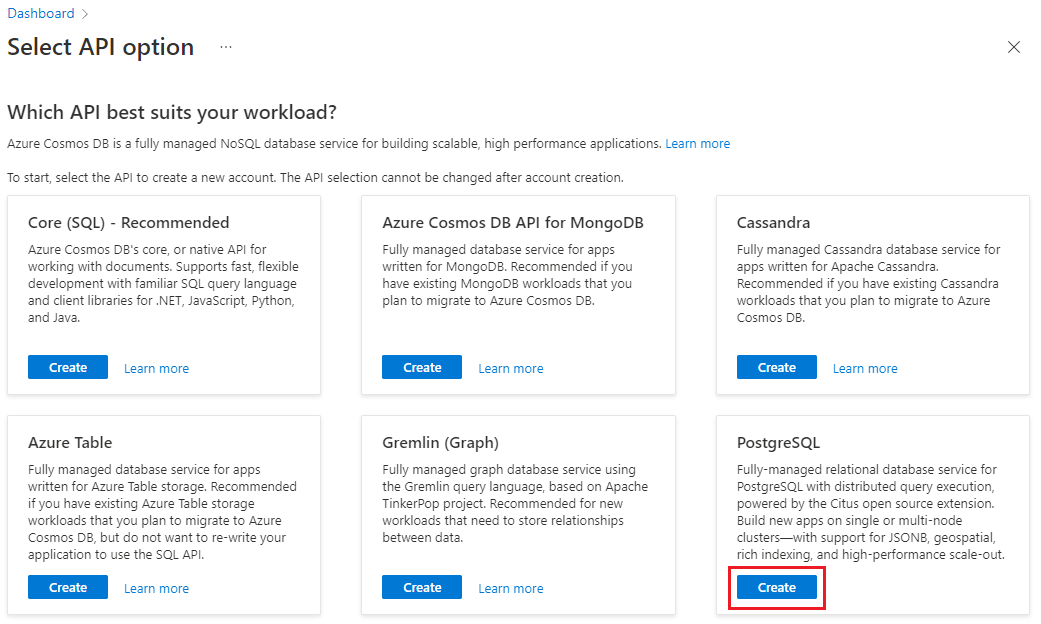
Nel modulo Creazione di un cluster di Azure Cosmos DB per PostgreSQL:
Immettere le informazioni richieste nella scheda Nozioni di base.
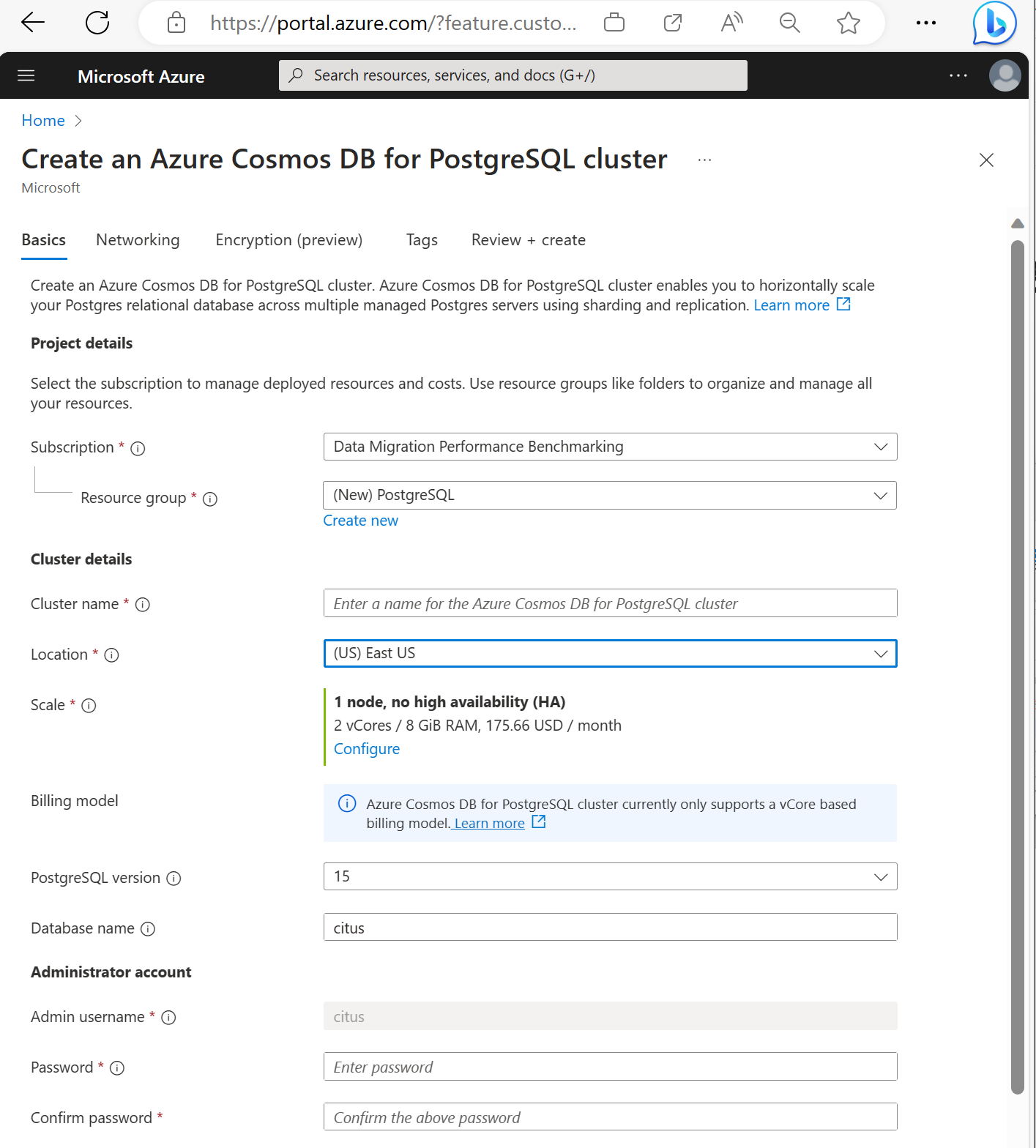
Anche se la maggior parte delle opzioni è autoesplicativa, tenere presente quanto segue:
- Il nome del cluster determina il nome DNS usato dalle applicazioni per la connessione, nel formato
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - È possibile scegliere una versione principale di PostgreSQL, ad esempio 15. Azure Cosmos DB for PostgreSQL supporta sempre la versione Citus più recente per la versione principale selezionata di Postgres.
- Il nome utente amministratore deve essere il valore
citus. - È possibile lasciare il nome del database al valore predefinito 'citus' o definire un proprio nome. Non è possibile rinominare il database dopo il provisioning del cluster.
- Il nome del cluster determina il nome DNS usato dalle applicazioni per la connessione, nel formato
Selezionare Avanti: Rete nella parte inferiore della schermata.
Nella schermata Rete selezionare Consentire l'accesso pubblico dai servizi e dalle risorse di Azure all'interno di Azure a questo cluster.
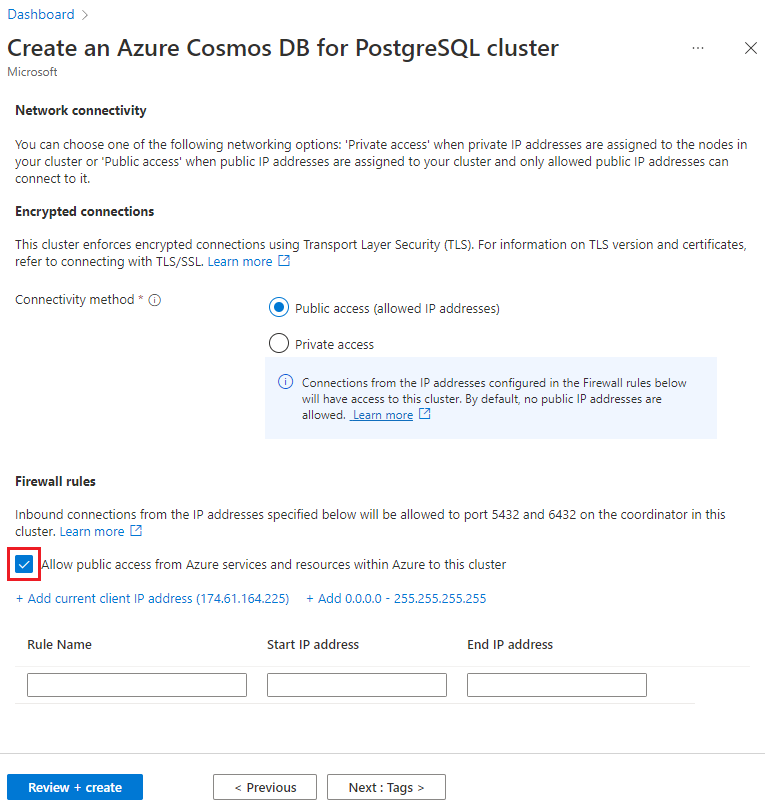
Selezionare Rivedi e crea e, al termine della convalida, selezionare Crea per creare il cluster.
La configurazione richiede alcuni minuti. La pagina viene reindirizzata per monitorare la distribuzione. Quando lo stato cambia da Distribuzione in corso a Distribuzione completata, selezionare Vai alla risorsa.
Usare l'utilità psql per creare uno schema
Dopo la connessione ad Azure Cosmos DB for PostgreSQL tramite psql, è possibile completare alcune attività di base. Questa esercitazione illustra come creare un'app Web che consente agli inserzionisti di tenere traccia delle proprie campagne pubblicitarie.
Poiché l'app può essere usata da più aziende, si creeranno una tabella in cui includere le aziende e un'altra tabella per le campagne pubblicitarie. Nella console di psql eseguire questi comandi:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Ogni campagna pagherà per mostrare annunci. Si aggiungerà quindi una tabella anche per le inserzioni eseguendo il codice seguente in psql dopo il codice mostrato sopra:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Infine si terrà traccia delle statistiche relative ai clic e alle impression per ogni inserzione:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Le tabelle appena create possono ora essere visualizzate nell'elenco delle tabelle di psql eseguendo questo comando:
\dt
Le applicazioni multi-tenant possono applicare l'univocità solo a livello di tenant e pertanto tutte le chiavi primarie ed esterne includono l'ID aziendale.
Ripartire le tabelle tra i nodi
Una distribuzione Azure Cosmos DB for PostgreSQL archivia le righe di tabella in nodi diversi in base al valore di una colonna designata dall'utente. Questa "colonna di distribuzione" indica quale tenant possiede quali righe.
In questa esercitazione si imposterà la colonna di distribuzione come company_id, l'identificatore del tenant. In psql eseguire queste funzioni:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Importante
La distribuzione delle tabelle o l'uso del partizionamento orizzontale basato su schema sono necessari per sfruttare le funzionalità delle prestazioni di Azure Cosmos DB for PostgreSQL. Se non si distribuiscono le tabelle o gli schemi, i nodi di lavoro non possono eseguire query che coinvolgono i rispettivi dati.
Inserire dati di esempio
A questo punto, nella riga di comando normale all'esterno di psql, scaricare i set di dati di esempio:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Tornare quindi in psql ed eseguire il caricamento bulk dei dati. Assicurarsi di eseguire psql nella stessa directory in cui sono stati scaricati i file di dati.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
I dati verranno ora distribuiti tra i nodi di lavoro.
Eseguire query sui dati dei tenant
Quando l'applicazione richiede i dati per un singolo tenant, il database può eseguire la query su un singolo nodo di lavoro. Le query su singolo tenant filtrano i dati in base a un ID di tenant. Ad esempio, la query seguente filtra inserzioni e impression in base all'identificatore company_id = 5. Provare a eseguirla in psql ed esaminare i risultati.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Condividere dati tra inquilini
Fino ad ora tutte le tabelle sono state distribuite da company_id. Tuttavia, alcuni dati non "appartengono" ad alcun tenant in particolare e possono essere condivisi. Ad esempio, tutte le aziende nella piattaforma per inserzioni di esempio possono avere l'esigenza di ottenere informazioni geografiche relative ai destinatari in base agli indirizzi IP.
È quindi opportuno creare una tabella per contenere le informazioni geografiche condivise. Eseguire i comandi seguenti in psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Impostare quindi geo_ips come "tabella di riferimento" per archiviare una copia della tabella in ogni nodo di lavoro.
SELECT create_reference_table('geo_ips');
Caricalo con i dati di esempio. Ricordarsi di eseguire questo comando in psql all'interno della directory in cui è stato scaricato il set di dati.
\copy geo_ips from 'geo_ips.csv' with csv
L'unione della tabella dei clic con geo_ips è efficiente su tutti i nodi. Ecco un join per trovare la posizione di tutti gli utenti che hanno fatto clic su un'inserzione 290. Provare a eseguire la query in psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Personalizzare lo schema in base al tenant
Un singolo tenant potrebbe avere la necessità di archiviare informazioni particolari che non sono richieste da altri. Tutti i tenant condividono tuttavia un'infrastruttura comune con uno schema di database identico. Dove inserire i dati aggiuntivi richiesti?
Una soluzione può essere quella di usare un tipo di colonna aperta, ad esempio JSONB di PostgreSQL. Nel nostro schema è presente un campo JSONB in clicks denominato user_data.
Un'azienda (ad esempio azienda cinque) può usare la colonna per rilevare se l'utente sta usando un dispositivo mobile.
Ecco una query per individuare gli utenti che fanno più clic sull'inserzione, ovvero i visitatori tradizionali o gli utenti di dispositivi mobili.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
È possibile ottimizzare la query per una singola azienda creando un indice parziale.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Più in generale, è possibile creare indici GIN in ogni chiave e valore all'interno della colonna.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Pulire le risorse
Nei passaggi precedenti sono state create risorse di Azure in un cluster. Se non si prevede di avere bisogno di queste risorse in futuro, eliminare il cluster. Selezionare il pulsante Elimina nella pagina Panoramica per il cluster. Quando viene visualizzata la richiesta in una pagina popup, verificare il nome del cluster e selezionare il pulsante Elimina in basso.
Passaggi successivi
In questa esercitazione, hai imparato come configurare un cluster. È stata stabilita la connessione al gruppo con psql, è stato creato uno schema e sono stati distribuiti i dati. Si è inoltre appreso come eseguire query sui dati sia all'interno dei tenant sia tra più tenant e come personalizzare lo schema per ogni tenant.
- Informazioni sui tipi di nodi dei cluster
- Determinare le dimensioni iniziali ottimali per il cluster