Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabella
Tabella
Vivere in una società profondamente interconnessa porta, prima o poi, ad avere a che fare con i social network. I social network vengono usati per rimanere in contatto con amici, colleghi e familiari, ma anche per condividere passioni con persone con interessi simili.
I tecnici e gli sviluppatori si chiederanno probabilmente come vengono archiviati e interconnessi i dati in queste reti. Come sviluppatori, è anche possibile aver ricevuto richieste per creare o progettare un nuovo social network per un mercato di nicchia specifico. La domanda più importante di tutte è: come vengono archiviati tutti questi dati?
Si supponga di dover creare un nuovo social network, in cui gli utenti possano pubblicare articoli con elementi multimediali correlati, ad esempio immagini, video o musica. La pagina di destinazione principale del sito Web includerà un feed di post che gli utenti possono visualizzare e con cui possono interagire. La pagina di destinazione principale del sito Web includerà un feed di post che gli utenti possono visualizzare e con cui possono interagire. Questo esempio potrebbe sembrare piuttosto semplice a prima vista. Si potrebbero approfondire, ad esempio, i feed dell'utente personalizzati influenzati dalle relazioni, ma questi argomenti esulano dagli obiettivi di questo articolo.
Come e dove archiviare i dati?
Si potrebbe avere esperienza di database SQL o conoscere i concetti della modellazione relazionale dei dati. Per iniziare, si potrebbe disegnare un diagramma simile al seguente:
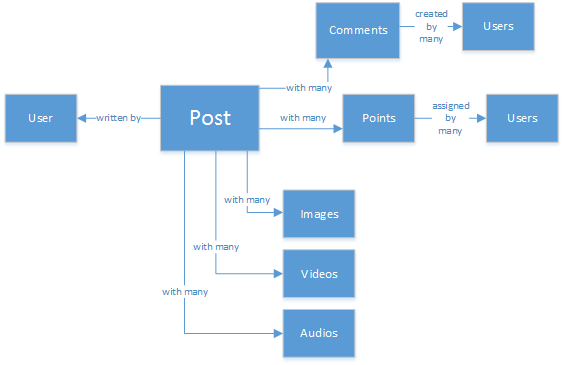
Una struttura di dati perfettamente normalizzata... che non supporta la scalabilità.
Niente da dire sui database SQL, naturalmente. Sono ottimi, ma come ogni modello, procedura e piattaforma software, non sono perfetti per ogni scenario.
Perché SQL non rappresenta la scelta migliore in questo scenario? Esaminiamo la struttura di un singolo post. Per visualizzare il post in un sito Web o un'applicazione, sarebbe necessario eseguire query e unire in join un gran numero di tabelle per mostrare un singolo post. L'ideale sarebbe invece realizzare un flusso di post che vengono caricati e visualizzati sullo schermo in modo dinamico.
Si potrebbe usare un'enorme istanza di SQL con capacità sufficienti per risolvere migliaia di query con numerosi join per rendere disponibile il contenuto. Ma perché mai scegliere questa opzione quando ne esiste una più semplice?
Approccio NoSQL
Questo articolo descrive la modellazione dei dati della piattaforma di social networking con il database NoSQL di Azure Azure Cosmos DB, in modo economicamente conveniente. Viene inoltre spiegato come utilizzare altre funzionalità di Azure Cosmos DB come l'API per Gremlin. Con un approccio NoSQL, che prevede l'archiviazione dei dati in formato JSON e l'applicazione della denormalizzazione, il post che prima risultava complesso può essere trasformato in un singolo documento:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
E può essere ottenuto con una singola query, senza join. Questa query è molto più semplice e lineare e, a livello di budget, permette di ottenere risultati migliori con meno risorse.
Azure Cosmos DB garantisce che tutte le proprietà vengano indicizzate tramite l'indicizzazione automatica. L'indicizzazione automatica può essere persino personalizzata. L'approccio senza schema consente di archiviare documenti con strutture diverse e dinamiche. Ad esempio, potrebbe risultare necessario associare un elenco di categorie o hashtag ai post in un secondo momento. Azure Cosmos DB gestisce i nuovi documenti con gli attributi aggiunti senza lavoro aggiuntivo richiesto da Microsoft.
I commenti per un post possono essere considerati come altri post con una proprietà padre. (Questo approccio semplifica il mapping degli oggetti.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Tutte le interazioni social possono essere archiviate in un oggetto separato come contatori:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Per la creazione di feed è sufficiente creare documenti che possano contenere un elenco di ID di post con un ordine di pertinenza specifico:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
È possibile usare un flusso "più recenti" con i post ordinati per data di creazione. Oppure è possibile creare un flusso "più interessanti" con i post con il maggior numero di Mi piace nelle ultime 24 ore. Si potrebbe anche implementare un flusso personalizzato per ogni utente basato su logica, ad esempio follower e interessi. Rimarrebbe comunque un elenco di post. Il fulcro è come compilare questi elenchi, ma le prestazioni di lettura rimangono invariate. Una volta acquisito uno di questi elenchi, si invia una singola query a Cosmos DB usando la parola chiave IN per ottenere più pagine di post alla volta.
I flussi di feed possono essere creati usando i processi in background dei servizi app di Azure, ovvero Processi Web. Dopo aver creato un post, l'elaborazione in background può essere attivata usando Archiviazione di Azurecode e processi Web attivati con Azure Webjobs SDK, implementando la propagazione post all'interno di flussi in base alla logica personalizzata.
Con questa stessa tecnica è possibile elaborare punteggi e Mi piace relativi ai post in modo posticipato, per creare un ambiente coerente.
I follower sono più complessi. Azure Cosmos DB prevede un limite di dimensioni dei documenti e la lettura/scrittura di documenti di grandi dimensioni può influire sulla scalabilità dell'applicazione. È quindi consigliabile archiviare i follower come documento con questa struttura:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Questa struttura potrebbe funzionare per un utente con poche migliaia di follower. Se alcune celebrità si uniscono alle file, tuttavia, questo approccio porta a una grande dimensione del documento e alla fine potrebbe eventualmente raggiungere il limite di dimensione del documento.
Per risolvere il problema, è possibile adottare un approccio misto. Nel documento delle statistiche utenti è possibile archiviare il numero di follower:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
È possibile archiviare il grafo effettivo dei follower tramite l'API per Gremlin di Azure Cosmos DB, per creare vertici per ogni utente e archi che mantengono le relazioni di tipo "A-segue-B". Con l'API per Gremlin, è possibile ottenere i follower di un determinato utente e creare query più complesse per suggerire persone in comune. Se al grafo si aggiungono le categorie di contenuto che piacciono o a cui sono interessati gli utenti, è possibile avviare esperienze composte che includono l'individuazione intelligente dei contenuti, il suggerimento dei contenuti che interessano ai follower o la ricerca di persone con cui l'utente potrebbe avere molto in comune.
Il documento Statistiche utente può ancora essere usato per creare schede nell'interfaccia utente o anteprime rapide del profilo.
Modello "a gradini" e duplicazione dei dati
Si è probabilmente notato che nel documento JSON che fa riferimento a un post sono presenti molte occorrenze di un utente. Questi duplicati significano che, data la denormalizzazione, le informazioni che descrivono un utente potrebbero essere presenti in più posizioni.
Questo perché query più veloci comportano la duplicazione dei dati. Il problema legato a questo effetto collaterale è che, se i dati di un utente vengono modificati in qualche modo, è necessario trovare e aggiornare tutte le attività eseguite da tale utente. Questo è un aspetto che va risolto.
Il problema viene risolto identificando gli attributi chiave di un utente che sono visualizzati nell'applicazione per ogni attività. Se nell'applicazione sono visibili soltanto il post con il nome e l'immagine dell'autore, perché archiviare tutti i dati dell'utente nell'attributo "createdBy"? Se per ogni commento viene visualizzata solo l'immagine dell'utente, il resto delle informazioni dell'utente in effetti non serve. In questo caso entra in gioco il cosiddetto modello "a gradini".
Si prendano ad esempio le informazioni relative a un utente:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Esaminando queste informazioni è possibile distinguere rapidamente quelle più o meno critiche, creando così dei "gradini":

Il gradino più piccolo è detto UserChunk, l'informazione minima che identifica un utente, e viene usato per la duplicazione dei dati. Riducendo le dimensioni dei dati duplicati alle sole informazioni "visualizzate", si riduce il rischio di aggiornamenti troppo estesi.
Il gradino intermedio è quello dell'utente Si tratta dei dati completi usati nella maggior parte delle query dipendenti dalle prestazioni in Azure Cosmos DB, il più accessibile e critico. Include le informazioni rappresentate da un UserChunk.
Il gradino più grande è quello dell'utente esteso. Include le informazioni cruciali degli utenti e altri dati che non è necessario leggere rapidamente o che hanno un eventuale utilizzo, come il processo di accesso. Questi dati possono essere archiviati al di fuori di Azure Cosmos DB, nel database SQL di Azure o nelle tabelle di Archiviazione di Microsoft Azure.
Suddividere i dati dell'utente e archiviare le informazioni in posizioni diverse risulta utile perché, in termini di prestazioni, le query su documenti di grandi dimensioni hanno un costo maggiore. Mantenere snelli i documenti, con le informazioni essenziali per eseguire tutte le query dipendenti dalle prestazioni per il social network. Archiviare le altre informazioni aggiuntive per possibili scenari come modifiche del profilo completo, accessi, data mining per l'analisi di utilizzo e iniziative legate ai Big Data. Non è in effetti importante se la raccolta dati per il data mining risulta più lenta, perché è in esecuzione in un database SQL di Azure. Quello che conta è che gli utenti abbiano un'esperienza agile e veloce. Un utente archiviato in Azure Cosmos DB sarebbe simile a questo codice:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
Un post invece si presenta come segue:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Quando subentra una modifica che interessa un attributo di un blocco, è possibile trovare facilmente i documenti interessati. È sufficiente usare query che fanno riferimento agli attributi indicizzati, ad esempio SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", quindi aggiornare i blocchi.
La casella di ricerca
Gli utenti generano, fortunatamente, molto contenuto. e devono avere la possibilità di cercare e trovare anche contenuti non presenti direttamente nel proprio flusso di contenuti, perché non seguono gli autori o semplicemente perché si tratta di post vecchi di sei mesi.
Poiché si utilizza Azure Cosmos DB, è possibile implementare facilmente un motore di ricerca tramite Azure AI Search in pochi minuti senza digitare alcun codice oltre a quelli del processo di ricerca e dell'interfaccia utente.
Perché questo processo è così semplice?
Azure AI Search implementa i cosiddetti indicizzatori, ovvero processi in background che si agganciano ai repository di dati e aggiungono, aggiornano o rimuovono automaticamente gli oggetti negli indici. Supportano gli indicizzatori di database SQL di Azure, gli indicizzatori di BLOB di Azure e, soprattutto, gli indicizzatori di Azure Cosmos DB. La transizione delle informazioni da Azure Cosmos DB a Azure AI Search è semplice. Entrambe le tecnologie archiviano le informazioni in formato JSON, pertanto è sufficiente creare l'indice ed eseguire il mapping degli attributi dai documenti da indicizzare. Ecco fatto! A seconda delle dimensioni dei dati, tutto il contenuto è disponibile per la ricerca entro pochi minuti dalla migliore soluzione Di ricerca distribuita come servizio nell'infrastruttura cloud.
Per maggiori informazioni su Azure AI Search, visitare la Guida alla ricerca per autostoppisti.
Conoscenza sottostante
Dopo aver archiviato tutti questi contenuti che continuano ad aumentare, come è possibile mettere tutto questo flusso di informazioni al servizio degli utenti?
È necessario usare le informazioni e imparare dai dati.
Ad esempio, è possibile usare l'analisi del sentimento, includere indicazioni su contenuti consigliati in base alle preferenze dell'utente oppure un Content Moderator automatizzato che garantisca la sicurezza per la famiglia di tutti i contenuti pubblicati dal social network.
Contrariamente a quanto si potrebbe pensare, non è necessario essere dei matematici per estrapolare questi modelli e informazioni da semplici file e database.
Azure Machine Learning, è un servizio cloud completamente gestito che consente di creare flussi di lavoro usando algoritmi in un'interfaccia semplice di trascinamento della selezione, di codificare algoritmi personalizzati in R o di usare alcune delle API già compilate e pronte per l'uso, ad esempio: Analisi del testo, Content Moderator o Raccomandazioni.
Per realizzare uno di questi scenari di Machine Learning, è possibile usare Azure Data Lake per inserire le informazioni provenienti da origini diverse. È anche possibile usare U-SQL per elaborare le informazioni e generare un output che può essere elaborato da Azure Machine Learning.
Un'altra opzione disponibile è quella di utilizzare i Servizi di Azure AI per analizzare i contenuti degli utenti; non solo è possibile comprenderli meglio (analizzando ciò che scrivono con l'API Analisi del testo), ma è possibile anche rilevare contenuti indesiderati o per soli adulti e agire di conseguenza con l'API Visione artificiale. I servizi di intelligenza artificiale di Azure includono molte soluzioni predefinite che non richiedono alcuna conoscenza di Machine Learning da usare.
Un'esperienza social su scala globale
C'è un ultimo articolo, ma non meno importante, che devo affrontare: scalabilità. Quando si progetta un'architettura, ogni componente deve poter essere ridimensionato in modo autonomo. Alla fine sarà necessario elaborare più dati o avere una copertura geografica più ampia. Fortunatamente, realizzare entrambe le attività si rivela un'esperienza chiavi in mano con Azure Cosmos DB.
Cosmos DB supporta il partizionamento dinamico out-of-the-box. e crea automaticamente partizioni in base a una determinata chiave di partizione, definita come attributo nei documenti. La definizione della chiave di partizione corretta deve essere eseguita in fase di progettazione. Per altre informazioni, vedere Partizionamento in Azure Cosmos DB.
Per un'esperienza social, è necessario allineare la strategia di partizionamento al modo in cui si eseguono query e scrittura. (Ad esempio, le letture all'interno della stessa partizione sono consigliabili ed è possibile evitare "hot spot" distribuendo le scritture su più partizioni.) Alcune opzioni sono: partizioni basate su una chiave temporale (giorno/mese/settimana), sulla categoria del contenuto, sull'area geografica o sull'utente. Tutto dipende dal modo in cui si interrogano i dati e si mostrano i dati nella tua esperienza social.
Azure Cosmos DB esegue le query (incluse le aggregazioni) in tutte le partizioni in modo trasparente, quindi non è necessario aggiungere alcuna logica man mano che i dati aumentano.
Con il tempo, aumenterà il traffico e di conseguenza aumenterà il consumo di risorse (misurato in UR o unità richiesta). Leggerai e scriverai più frequentemente man mano che cresce la tua base di utenti. La base utente inizia a creare e leggere altro contenuto. Pertanto, la possibilità di aumentare le unità richieste è fondamentale. Aumentare le unità richieste è facile. Puoi farlo con pochi passaggi nel portale di Azure o emettendo comandi tramite l'API.
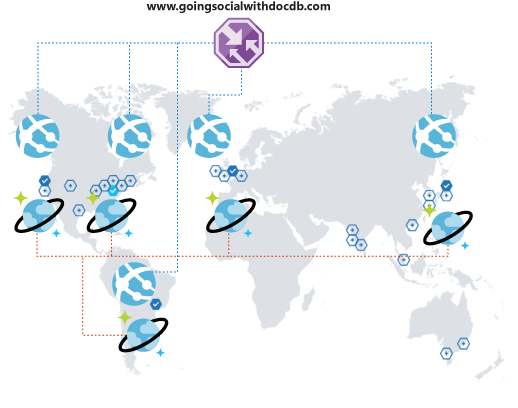
Cosa accade se la piattaforma ha sempre più successo? Si supponga che gli utenti di un altro paese/regione o continente notino la piattaforma e inizino a utilizzarla. È senz'altro una buona notizia,
ma presto ci si rende conto che l'esperienza con la piattaforma non è ottimale. Si tratta di utenti così lontani dall'area in cui si opera che la latenza è terribile. Ed è naturalmente un peccato perdere questi utenti. Ci vorrebbe un modo semplice per estendere la portata globale e questo modo esiste.
Azure Cosmos DB consente di replicare i dati globalmente e in modo trasparente effettuando alcune selezioni e selezionando automaticamente tra le aree disponibili tramite il codice del client. Questo processo significa anche che è possibile avere più aree di failover.
Quando si replicano i dati a livello globale, è necessario assicurarsi che i client possano sfruttarli. Se si usa un front-end Web o si accede alle API da client mobili, è possibile distribuire Gestione traffico di Azure e clonare il Servizio app di Azure in tutte le aree desiderate, usando una configurazione delle prestazioni per supportare la copertura globale estesa. Quando i client accedono alle API o front-end, vengono indirizzati al servizio app più vicino, che a sua volta si connetterà alla replica locale di Azure Cosmos DB.
Conclusione
Questo articolo mette in luce alcune alternative per la creazione di social network interamente in Azure con servizi a costo contenuto. Offre risultati incoraggiando l'uso di una soluzione di archiviazione a più livelli e di una distribuzione dei dati denominata "Scale".
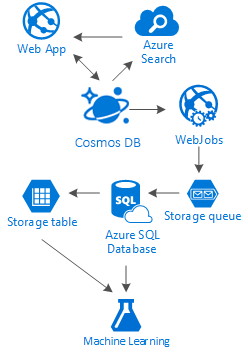
La verità è che non esiste un'unica soluzione infallibile per questo tipo di scenari. È la sinergia creata dall'unione di servizi di alto livello che consente di creare grandi esperienze: la velocità e la libertà di Azure Cosmos DB che rendono possibile la realizzazione di un'applicazione social ottimale, l'intelligenza alla base di una soluzione di ricerca di alto livello come Azure AI Search, la flessibilità dei servizi app di Azure che consentono di ospitare non solo applicazioni indipendenti dal linguaggio, ma anche potenti processi in background, l'espandibilità di Archiviazione di Azure e del database SQL di Azure che permettono di archiviare grandi quantità di dati e la capacità analitica di Azure Machine Learning che consente di creare conoscenza e intelligenza in grado di fornire feedback ai processi, nonché i contenuti più appropriati agli utenti giusti.
Passaggi successivi
Per altre informazioni sui casi d'uso per Azure Cosmos DB, vedere Casi d'uso comuni di Azure Cosmos DB.